
Anmerkung
Die Verarbeitung von Daten in Echtzeit genau einmal ( genau einmal ) ist eine äußerst nicht triviale Aufgabe und erfordert einen ernsthaften und durchdachten Ansatz über die gesamte Berechnungskette hinweg. Einige glauben sogar, dass eine solche Aufgabe unmöglich ist . In der Realität möchte ich einen Ansatz haben, der eine fehlertolerante Verarbeitung ohne Verzögerung und die Verwendung verschiedener Datenspeicher ermöglicht und neue, noch strengere Anforderungen an das System stellt: genau einmal gleichzeitig und die Heterogenität der persistenten Schicht. Bisher unterstützt eine solche Anforderung keines der vorhandenen Systeme.
Der vorgeschlagene Ansatz wird konsequent die geheimen Bestandteile und die notwendigen Konzepte aufdecken, die es relativ einfach machen, eine heterogene gleichzeitige, genau einmalige Verarbeitung buchstäblich aus zwei Komponenten zu implementieren.
Einführung
Der Entwickler verteilter Systeme durchläuft mehrere Phasen:
Stufe 1: Algorithmen . Hier werden grundlegende Algorithmen, Datenstrukturen, Programmieransätze wie OOP usw. untersucht. Der Code ist ausschließlich Single-Threaded. Die Anfangsphase des Berufseinstiegs. Es ist jedoch ziemlich kompliziert und kann Jahre dauern.
Stufe 2: Multithreading . Als nächstes stellen sich Fragen, wie man aus Eisen maximale Effizienz herausholen kann. Es gibt Multithreading, Asynchronität, Rennen, Debugging, Strace, schlaflose Nächte ... Viele bleiben in dieser Phase stecken und bekommen irgendwann sogar einen unerklärlichen Nervenkitzel. Aber nur wenige verstehen die Architektur von virtuellem Speicher und Speichermodellen, sperrfreien / wartungsfreien Algorithmen und verschiedenen asynchronen Modellen. Und fast niemand jemals - Multithread-Codeüberprüfung.
Stufe 3: Verteilung . Hier passiert so ein Müll, den weder in einem Märchen noch in einem Stift zu beschreiben ist.
Es scheint, dass etwas kompliziert ist. Wir machen die Transformation: viele Threads -> viele Prozesse -> viele Server. Aber jeder Schritt der Transformation bringt qualitative Veränderungen mit sich, und alle fallen auf das System, zerdrücken es und verwandeln es in Staub.
Hier geht es darum, die Fehlerbehandlungsdomäne und die Verfügbarkeit des gemeinsam genutzten Speichers zu ändern. Wenn vorher immer ein Stück Speicher in jedem Thread verfügbar war und wenn gewünscht, in jedem Prozess, gibt es jetzt kein solches Stück und kann es nicht sein. Jeder für sich, unabhängig und stolz.
Wenn früher ein Fehler im Stream den Stream und den Prozess gleichzeitig vergrub, und das war gut, weil führte nicht zu teilweisen Fehlern, jetzt werden teilweise Fehler zur Norm und jedes Mal vor jeder Aktion denken Sie: „Was wäre wenn?“. Dies ist so ärgerlich und lenkt vom Schreiben der Aktionen selbst ab, dass der Code dadurch nicht zeitweise, sondern um Größenordnungen wächst. Alles wird zu Nudeln der Fehlerbehandlung, Zustandsumschaltung und Kontexterhaltung, Wiederherstellung aufgrund von Fehlern einer Komponente, einer anderen Komponente, Unzugänglichkeit einiger Dienste usw. usw. Nachdem Sie die Überwachung für all diese Dinge vermasselt haben, können Sie auf Ihrem Lieblings-Laptop gut schlafen.
Ob es sich um Multithreading handelt: Ich nahm den Mutex und ging, um das gemeinsame Gedächtnis zum Vergnügen zu zerstören. Schönheit!
Infolgedessen haben wir festgestellt, dass die Schlüssel- und kampferprobten Muster weggenommen wurden und die neuen, um sie zu ersetzen, aus irgendeinem Grund nicht geliefert wurden, und es stellte sich heraus, wie in einem Witz darüber, wie die Fee ihren Zauberstab schwang und der Turm vom Panzer fiel.
Verteilte Systeme verfügen jedoch über eine Reihe bewährter Verfahren und bewährter Algorithmen. Jeder Programmierer mit Selbstachtung sieht es jedoch als seine Pflicht an, bekannte Errungenschaften abzulehnen und trotz der gesammelten Erfahrungen eine beträchtliche Anzahl wissenschaftlicher Artikel und akademischer Forschung zu seinem eigenen Wohl zu fahren. Wenn Sie sich mit Algorithmen und Multithreading beschäftigen können, wie können Sie dann mit der Verteilung in Konflikt geraten? Hier kann es keine zwei Meinungen geben!
Infolgedessen sind Systeme fehlerhaft, Daten divergieren und verschlechtern sich, Dienste sind regelmäßig nicht mehr zum Schreiben verfügbar oder sogar vollständig nicht mehr verfügbar, da plötzlich ein Knoten abstürzte, das Netzwerk ausfiel, Java viel Speicher verbrauchte und GC langweilig wurde, und es gibt viele andere Gründe, die sein Ende verzögern könnten an die Behörden.
Doch auch mit bekannten und bewährten Ansätzen wird das Leben nicht einfacher, weil Verteilte zuverlässige Grundelemente sind schwergewichtig und stellen ernsthafte Anforderungen an die Logik des ausführbaren Codes. Daher werden die Ecken wo immer möglich abgeschnitten. Und wie so oft, treten bei schnell geschnittenen Ecken Einfachheit und relative Skalierbarkeit auf, aber die Zuverlässigkeit, Verfügbarkeit und Konsistenz eines verteilten Systems verschwindet.
Im Idealfall möchte ich überhaupt nicht denken, dass unser System verteilt und multithreaded ist, d. H. Arbeiten Sie in der 1. Stufe (Algorithmen), ohne an die 2. (Multithreading + Asynchronität) und 3. (Verteilung) zu denken. Diese Art der Isolierung von Abstraktionen würde die Einfachheit, Zuverlässigkeit und Geschwindigkeit des Schreibens von Code erheblich erhöhen. Leider ist dies derzeit nur in Träumen möglich.
Einzelne Abstraktionen ermöglichen jedoch eine relative Isolation. Eines der typischen Beispiele ist die Verwendung von Coroutinen , bei denen anstelle von asynchronem Code synchron, d. H. Wir gehen von der 2. Stufe zur 1. Stufe über, wodurch wir das Schreiben und die Wartung des Codes erheblich vereinfachen können.
Der Artikel enthüllt sukzessive die Verwendung von sperrfreien Algorithmen, um ein zuverlässiges konsistentes verteiltes skalierbares Echtzeitsystem aufzubauen, d.h. Wie sperrfreie Erfolge der 2. Stufe bei der Implementierung der 3. Stufe helfen und die Aufgabe auf Single-Threaded-Algorithmen der 1. Stufe reduzieren.
Erklärung des Problems
Diese Aufgabe zeigt nur einige wichtige Ansätze und wird als Beispiel für die Einführung von Problemen in den Kontext vorgestellt. Es kann leicht auf komplexere Fälle verallgemeinert werden, was in Zukunft geschehen wird.
Aufgabe: Echtzeit-Streaming-Datenverarbeitung .
Es gibt zwei Zahlenströme. Der Handler liest die Daten dieser Eingabestreams und wählt die letzten Nummern für einen bestimmten Zeitraum aus. Diese Zahlen werden über dieses Zeitintervall gemittelt, d.h. in einem verschiebbaren Datenfenster für eine bestimmte Zeit. Der erhaltene Durchschnittswert muss für die nachfolgende Verarbeitung in die Ausgabewarteschlange geschrieben werden. Wenn die Anzahl der Nummern im Fenster einen bestimmten Schwellenwert überschreitet, erhöhen Sie außerdem den Zähler in der externen Transaktionsdatenbank um eins.
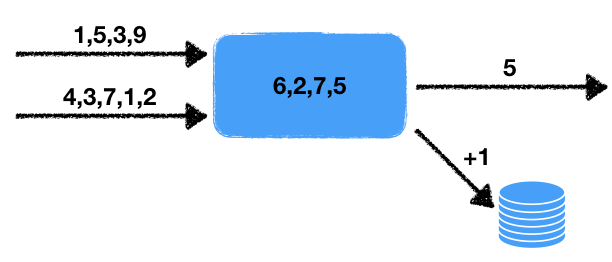
Wir stellen einige Merkmale dieses Problems fest.
- Nichtdeterminismus . Es gibt zwei Ursachen für nicht deterministisches Verhalten: Dies ist ein Messwert aus zwei Streams sowie ein Zeitfenster. Es ist klar, dass das Lesen auf verschiedene Arten durchgeführt werden kann und das Endergebnis davon abhängt, in welcher Reihenfolge die Daten extrahiert werden. Das Zeitfenster ändert auch das Ergebnis von Anfang zu Start als Die Datenmenge im Fenster hängt von der Arbeitsgeschwindigkeit ab.
- Der Zustand des Handlers . Es gibt einen Status des Handlers in Form einer Reihe von Zahlen im Fenster, von denen die aktuellen und nachfolgenden Ergebnisse der Arbeit abhängen. Das heißt, Wir haben einen Stateful Handler.
- Interaktion mit externem Speicher . Der Zählerwert in der externen Datenbank muss aktualisiert werden. Der entscheidende Punkt ist, dass sich die Art des externen Speichers von der Speicherung des Status des Prozessors und der Threads unterscheidet.
All dies hat, wie unten gezeigt wird, schwerwiegende Auswirkungen auf die verwendeten Tools und die möglichen Implementierungsmethoden.
Es bleibt eine kleine Berührung der Aufgabe, die die Aufgabe sofort von einem Bereich jenseits der Komplexität auf ein Unmögliches überträgt: Eine gleichzeitige, genau einmalige Garantie ist erforderlich.
Genau einmal
Genau einmal wird oft zu weit gefasst, was den Begriff selbst entmannt und die ursprünglichen Anforderungen der Aufgabe nicht mehr erfüllt. Wenn es sich um ein System handelt, das lokal auf einem Computer ausgeführt wird, ist alles einfach: Nehmen Sie mehr, werfen Sie weiter. In diesem Fall handelt es sich jedoch um ein verteiltes System, in dem:
- Die Anzahl der Handler kann groß sein: Jeder Handler arbeitet mit seinen eigenen Daten. Darüber hinaus können die Ergebnisse an verschiedenen Stellen hinzugefügt werden, beispielsweise in einer externen Datenbank, die möglicherweise sogar gemischt wird.
- Jeder Handler kann die Verarbeitung plötzlich beenden. Ein fehlertolerantes System impliziert einen fortgesetzten Betrieb, selbst wenn einzelne Teile des Systems ausfallen.
Daher müssen wir darauf vorbereitet sein, dass der Handler fallen kann, und ein anderer Handler sollte die bereits geleistete Arbeit aufnehmen und die Verarbeitung fortsetzen.
Es stellt sich sofort die Frage: Was bedeutet genau einmal , wenn der nicht deterministische Handler funktioniert? Schließlich erhalten wir bei jedem Neustart im Allgemeinen unterschiedliche resultierende Zustände. Die Antwort hier ist einfach: Mit genau einmal gibt es eine solche Systemausführung, bei der jeder Eingabewert genau einmal verarbeitet wird und das entsprechende Ausgabeergebnis ergibt. Darüber hinaus muss sich diese Ausführung nicht physisch auf demselben Knoten befinden. Das Ergebnis sollte jedoch so sein, als ob alles auf einem einzelnen logischen Knoten ohne Abstürze verarbeitet wurde .
Genau einmal gleichzeitig
Um die Anforderungen zu verschärfen, führen wir ein neues Konzept ein: genau einmal gleichzeitig . Der grundlegende Unterschied zu einfach genau einmal ist das Fehlen von Pausen während der Verarbeitung, als ob alles auf demselben Knoten ohne Tropfen und ohne Pausen verarbeitet worden wäre . In unserer Aufgabe benötigen wir zur Vereinfachung der Darstellung genau einmal genau gleichzeitig , um einen Vergleich mit vorhandenen Systemen, die heute nicht verfügbar sind, nicht in Betracht zu ziehen.
Die Konsequenzen einer solchen Anforderung werden nachstehend erörtert.
Transaktion
Damit der Leser noch tiefer von der entstandenen Komplexität durchdrungen ist, schauen wir uns verschiedene schlechte Szenarien an, die bei der Entwicklung eines solchen Systems berücksichtigt werden müssen. Wir werden auch versuchen, einen allgemeinen Ansatz zu verwenden, der es uns ermöglicht, das oben genannte Problem unter Berücksichtigung unserer Anforderungen zu lösen.
Das erste, was mir in den Sinn kommt, ist die Notwendigkeit, den Status des Handlers sowie die Eingabe- und Ausgabestreams aufzuzeichnen. Der Status der Ausgabestreams wird durch eine einfache Warteschlange von Zahlen und der Status der Eingabestreams durch die Position in ihnen beschrieben. Im Wesentlichen ist ein Stream eine unendliche Warteschlange, und eine Position in der Warteschlange legt einen Ort eindeutig fest.

Die folgende naive Implementierung eines Handlers erfolgt mithilfe einer Art Data Warehouse. Zu diesem Zeitpunkt sind die spezifischen Eigenschaften des Repositorys für uns nicht wichtig. Wir werden die Pseco-Sprache verwenden, um die Idee zu veranschaulichen (Pseco: = Pseudocode):
handle(input_queues, output_queues, state): # input_indexes = storage.get_input_indexes() # while true: # items, new_input_indexes = input_queues.get_from(input_indexes) # state.queue.push(items) # duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) output_queues[0].push(avg) if need_update_counter: # (B) db.increment_counter() # (C) storage.save_state(state) # (D) storage.save_queue_indexes(new_input_indexes) # (E) input_indexes = new_input_indexes
Hier ist ein einfacher Single-Threaded-Algorithmus, der Daten aus Eingabestreams liest und die gewünschten Werte gemäß der oben beschriebenen Aufgabe schreibt.
Mal sehen, was passiert, wenn ein Knoten zu beliebigen Zeitpunkten fällt oder wenn die Arbeit wieder aufgenommen wird. Es ist klar, dass im Falle eines Sturzes an den Punkten (A) und (E) alles in Ordnung ist: Entweder wurden die Daten noch nirgendwo aufgezeichnet und wir stellen einfach den Status wieder her und fahren auf dem anderen Knoten fort, oder alle erforderlichen Daten wurden bereits aufgezeichnet und fahren einfach mit dem nächsten Schritt fort.
Im Falle eines Sturzes an allen anderen Punkten erwarten uns jedoch unerwartete Probleme. Wenn an Punkt (B) ein Abfall auftritt, wird beim Neustart des Handlers der Status wiederhergestellt und der Durchschnittswert in ungefähr demselben Zahlenbereich neu aufgezeichnet. Im Falle eines Abfalls an Punkt (C) zusätzlich zum durchschnittlichen Duplikat ein Duplikat im Inkrement des Werts auf. Und im Falle eines Sturzes in (D) wir einen inkonsistenten Zustand des Handlers: Der Zustand entspricht einem neuen Zeitpunkt und wir lesen die Werte aus den alten Eingabeströmen.

Gleichzeitig ändert sich beim Neuanordnen von Aufnahmevorgängen nichts grundlegend: Inkonsistenzen und Duplikate bleiben erhalten. Wir kommen daher zu dem Schluss, dass alle Aktionen zum Ändern des Status des Handlers im Repository, in der Ausgabewarteschlange und in der Datenbank transaktional ausgeführt werden sollten, d. H. alles ist gleichzeitig atomar.
Dementsprechend ist es notwendig, einen Mechanismus zu entwickeln, damit verschiedene Speicher ihren Zustand transaktional ändern können und nicht unabhängig voneinander, sondern transaktional zwischen allen Speichern gleichzeitig. Natürlich können Sie unseren Speicher in einer externen Datenbank speichern. Bei der Aufgabe wurde jedoch davon ausgegangen, dass das Datenbankmodul und das Modul für das Streaming-Datenverarbeitungsframework getrennt sind und unabhängig voneinander arbeiten. Hier möchte ich den schwierigsten Fall betrachten, weil einfache Fälle sind nicht interessant zu betrachten.
Wettbewerbsfähigkeit
Betrachten Sie die Wettbewerbsausführung genau einmal genauer. Bei einem fehlertoleranten System müssen die Arbeiten ab einem bestimmten Zeitpunkt fortgesetzt werden. Es ist klar, dass dieser Punkt irgendwann in der Vergangenheit liegen wird, weil Um die Leistung aufrechtzuerhalten, ist es unmöglich, alle Momente von Statusänderungen in der Gegenwart und in der Zukunft zu speichern: Entweder das letzte Ergebnis von Operationen oder eine Gruppe von Werten zur Erhöhung des Durchsatzes wird gespeichert. Dieses Verhalten führt uns sofort zu der Tatsache, dass es nach der Wiederherstellung des Status des Prozessors zu einer gewissen Verzögerung der Ergebnisse kommt, die mit zunehmender Größe der Wertegruppe und der Größe des Status zunimmt.
Zusätzlich zu dieser Verzögerung gibt es auch Verzögerungen im System, die mit dem Laden des Zustands auf einen anderen Knoten verbunden sind. Darüber hinaus dauert die Erkennung eines Problemknotens einige Zeit und oft viel. Dies ist vor allem darauf zurückzuführen, dass bei einer kurzen Erkennungszeit häufige Fehlalarme möglich sind, die zu allen möglichen unangenehmen Spezialeffekten führen.
Darüber hinaus stellt sich mit der Zunahme der Anzahl paralleler Prozessoren plötzlich heraus, dass nicht alle gleich gut funktionieren, auch wenn keine Fehler vorliegen. Manchmal treten Blunts auf, die auch zu Verzögerungen bei der Verarbeitung führen. Der Grund für solche Blunts kann vielfältig sein:
- Software : GC-Pausen, Speicherfragmentierung, Allokatorpausen, Kernelunterbrechung und Aufgabenplanung, Probleme mit Gerätetreibern, die zu Verlangsamungen führen.
- Hardware : Hohe Festplatten- oder Netzwerklast, CPU-Drosselung aufgrund von Kühlproblemen, Überlastung usw., Verlangsamung der Festplatte aufgrund technischer Probleme.
Und dies ist keineswegs eine vollständige Liste von Problemen, die Handler verlangsamen können.
Verlangsamung ist dementsprechend eine Selbstverständlichkeit, mit der man leben muss. Manchmal ist dies kein ernstes Problem, und manchmal ist es äußerst wichtig, trotz Ausfällen oder Verlangsamungen eine hohe Verarbeitungsgeschwindigkeit aufrechtzuerhalten.
Sofort entsteht die Idee der Duplizierung von Systemen: Lassen Sie uns für ein und denselben Datenstrom nicht einen, sondern zwei Prozessoren gleichzeitig oder sogar drei ausführen. Das Problem hierbei ist, dass in diesem Fall leicht Duplikate und inkonsistentes Systemverhalten auftreten können. In der Regel sind Frameworks nicht für dieses Verhalten ausgelegt und legen nahe, dass die Anzahl der Handler zu einem bestimmten Zeitpunkt einen nicht überschreitet. Systeme, die die beschriebene Duplizierung der Ausführung ermöglichen, werden genau einmal als gleichzeitig bezeichnet .
Mit dieser Architektur können Sie mehrere Probleme gleichzeitig lösen:
- Ausfallsicheres Verhalten: Wenn einer der Knoten fällt, funktioniert der andere einfach weiter, als wäre nichts passiert. Es ist keine zusätzliche Koordinierung erforderlich, da Der zweite Handler wird unabhängig vom Status des ersten ausgeführt.
- Entfernen von Blunts: Wer zuerst das Ergebnis geliefert hat, ist gut für ihn. Der andere muss nur einen neuen Zustand annehmen und von diesem Moment an fortfahren.
Insbesondere mit diesem Ansatz können Sie eine schwierige, schwierige Langzeitberechnung für eine vorhersehbarere Zeit durchführen, weil die Wahrscheinlichkeit, dass beide dumm werden und deutlich weniger fallen.
Wahrscheinlichkeitsbewertung
Versuchen wir, die Vorteile einer doppelten Leistung zu bewerten. Angenommen, mit dem Handler passiert durchschnittlich jeden Tag etwas: Entweder ist der GC abgestumpft oder der Knoten liegt oder die Container sind krebsartig geworden. Angenommen, wir bereiten Datenpakete in 10 Sekunden vor.
Dann beträgt die Wahrscheinlichkeit, dass während der Erstellung des Pakets etwas passiert, 10 / (24 · 3600) ≃ 1e-4 .
Wenn Sie zwei Handler parallel ausführen, beträgt die Wahrscheinlichkeit, dass beide fliegen, ≃ 1e-8 . Diese Veranstaltung wird also in 23 Jahren stattfinden! Ja, Systeme leben nicht so viel, was bedeutet, dass dies niemals passieren wird!
Wenn die Vorbereitungszeit der Packung noch kürzer ist und / oder Blunts noch seltener auftreten, erhöht sich diese Zahl nur.
Wir kommen daher zu dem Schluss, dass der betrachtete Ansatz die Zuverlässigkeit unseres gesamten Systems erheblich erhöht. Es bleibt nur eine kleine Frage wie diese zu lösen: Wo kann man lesen, wie man ein gleichzeitiges genau einmaliges System erstellt? Und die Antwort ist einfach: Sie müssen hier lesen.
Halbe Transaktion
Für die weitere Diskussion benötigen wir das Konzept einer halben Transaktion . Der einfachste Weg, dies zu erklären, ist ein Beispiel.
Überlegen Sie, ob Sie Geld von einem Bankkonto auf ein anderes überweisen möchten. Der traditionelle Ansatz unter Verwendung von Transaktionen in der Pseco-Sprache kann wie folgt beschrieben werden:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
Was ist jedoch, wenn diese Transaktionen uns nicht zur Verfügung stehen? Mit Sperren kann dies wie folgt erfolgen:
transfer(from, to, amount): # lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
Dieser Ansatz kann zu Deadlocks führen Sperren können in verschiedenen Sequenzen parallel genommen werden. Um dieses Verhalten zu korrigieren, reicht es aus, eine Funktion einzuführen, die gleichzeitig mehrere Sperren in einer deterministischen Reihenfolge aufnimmt (z. B. nach Schlüsseln sortiert), wodurch mögliche Deadlocks vollständig beseitigt werden.
Die Implementierung kann jedoch etwas vereinfacht werden:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # , # .. db.set(db.get...) lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
Dieser Ansatz macht auch den Endzustand konsistent und bewahrt die Invarianten durch die Art der Verhinderung übermäßiger Ausgaben von Geldern. Der Hauptunterschied zum vorherigen Ansatz besteht darin, dass wir in einer solchen Implementierung einen bestimmten Zeitraum haben, in dem sich die Konten in einem inkonsistenten Zustand befinden. Eine solche Operation impliziert nämlich, dass sich der Gesamtzustand der Gelder auf den Konten nicht ändert. In diesem Fall besteht zwischen lock_from.release() und db.lock(to) eine Zeitlücke, in der die Datenbank möglicherweise einen inkonsistenten Wert db.lock(to) : Der Gesamtbetrag kann vom richtigen nach unten abweichen.
Tatsächlich haben wir eine Transaktion für die Überweisung von Geld in zwei halbe Transaktionen aufgeteilt:
- Die erste halbe Transaktion führt einen Scheck durch und zieht den erforderlichen Betrag vom Konto ab.
- Die zweite halbe Transaktion schreibt den abgehobenen Betrag auf ein anderes Konto.
Es ist klar, dass die Aufteilung einer Transaktion in kleinere im Allgemeinen das Transaktionsverhalten verletzt. Und das obige Beispiel ist keine Ausnahme. Wenn jedoch alle Halbtransaktionen in der Kette vollständig erfüllt sind, stimmt das Ergebnis mit allen erhaltenen Invarianten überein. Dies ist genau das, was eine wichtige Eigenschaft einer halben Transaktionskette ist.
Wir verlieren vorübergehend an Konsistenz und erwerben dennoch ein weiteres nützliches Merkmal: die Unabhängigkeit des Betriebs und damit eine bessere Skalierbarkeit. Die Unabhängigkeit manifestiert sich in der Tatsache, dass eine halbe Transaktion jedes Mal mit nur einer Zeile arbeitet, ihre Daten liest, prüft und ändert, ohne mit anderen Daten zu kommunizieren. Auf diese Weise können Sie eine Datenbank mischen, deren Transaktionen nur mit einem Shard funktionieren. Darüber hinaus kann dieser Ansatz im Fall von heterogenen Repositories verwendet werden, d.h. Halbtransaktionen können bei einem Speichertyp beginnen und bei einem anderen enden. Es sind solche nützlichen Eigenschaften, die in Zukunft verwendet werden.
Es stellt sich eine berechtigte Frage: Wie kann man Half-Trance in verteilten Systemen implementieren und nicht harken? Um dieses Problem zu beheben, müssen Sie den sperrfreien Ansatz berücksichtigen.
Schlossfrei
Wie Sie wissen, verbessern sperrfreie Ansätze manchmal die Leistung von Multithread-Systemen, insbesondere im Fall eines wettbewerbsfähigen Zugriffs auf die Ressource. Es ist jedoch völlig offensichtlich, dass ein solcher Ansatz in verteilten Systemen verwendet werden kann. Lassen Sie uns genauer untersuchen, was sperrenfrei ist und warum diese Eigenschaft bei der Lösung unseres Problems hilfreich sein wird.
Einige Entwickler verstehen manchmal nicht ganz, was sperrenfrei ist. Der engstirnige Blick deutet darauf hin, dass dies etwas mit Anweisungen für Atomprozessoren zu tun hat. Es ist wichtig zu verstehen, dass lock-free die Verwendung von „Atomen“ bedeutet, das Gegenteil ist nicht der Fall, das heißt, Nicht alle „Atomics“ geben ein sperrenfreies Verhalten.
Eine wichtige Eigenschaft des sperrfreien Algorithmus ist, dass mindestens ein Thread Fortschritte im System macht. Aber aus irgendeinem Grund schreiben viele diese Eigenschaft als Definition zu (es ist eine so stumpfe Definition, die zum Beispiel auf Wikipedia zu finden ist ). Hier muss eine wichtige Nuance hinzugefügt werden: Fortschritte werden auch bei Stumpfen eines oder mehrerer Threads erzielt. Dies ist ein sehr kritischer Punkt, der oft übersehen wird und schwerwiegende Auswirkungen auf ein verteiltes System hat.
Warum negiert das Fehlen einer Fortschrittsbedingung von mindestens einem Thread das Konzept eines sperrfreien Algorithmus? Tatsache ist, dass in diesem Fall auch der übliche Spinlock sperrfrei ist. In der Tat wird derjenige, der das Schloss genommen hat, Fortschritte machen. Gibt es einen Thread mit Fortschritt => sperrenfrei?
Lock-free bedeutet natürlich ohne Sperren, während Spinlock mit seinem Namen anzeigt, dass es sich um eine echte Sperre handelt. Aus diesem Grund ist es wichtig, auch bei Blunts eine Bedingung für den Fortschritt hinzuzufügen. Schließlich können diese Verzögerungen unbegrenzt dauern, weil Die Definition sagt nichts über die obere Zeitlinie aus. Und wenn ja, dann sind solche Verzögerungen in gewissem Sinne gleichbedeutend mit dem Abschalten von Flüssen. In diesem Fall führen sperrfreie Algorithmen in diesem Fall zu Fortschritten.
Aber wer hat gesagt, dass sperrfreie Ansätze ausschließlich für Multithread-Systeme gelten? Durch Ersetzen von Threads im selben Prozess auf demselben Knoten durch Prozesse auf verschiedenen Knoten und des gemeinsam genutzten Speichers der Threads durch gemeinsam genutzten verteilten Speicher erhalten wir einen sperrfreien verteilten Algorithmus.
Ein Knotenabfall in einem solchen System entspricht einer Verzögerung bei der Ausführung eines Threads für einige Zeit, weil Es ist Zeit, die Arbeit wiederherzustellen. Gleichzeitig ermöglicht der sperrfreie Ansatz anderen Teilnehmern des verteilten Systems, weiter zu arbeiten. Darüber hinaus können spezielle sperrfreie Algorithmen parallel zueinander ausgeführt werden, um eine Wettbewerbsänderung zu erkennen und Duplikate auszuschneiden.
Der genau einmalige Ansatz impliziert das Vorhandensein eines konsistenten verteilten Speichers. Solche Speicher stellen in der Regel eine riesige persistente Schlüsselwerttabelle dar. Mögliche Operationen: set , get , del . Für den sperrfreien Ansatz ist jedoch eine kompliziertere Operation erforderlich: CAS oder Compare-and-Swap. Lassen Sie uns diese Operation, die Verwendungsmöglichkeiten sowie die daraus resultierenden Ergebnisse genauer betrachten.
Cas
CAS oder Compare-and-Swap ist das wichtigste und wichtigste Synchronisationsprimitiv für sperrfreie und wartungsfreie Algorithmen. Sein Wesen kann durch das folgende Pseco veranschaulicht werden:
CAS(var, expected, new): # , atomic, atomic: if var.get() != expected: return false var.set(new) return true
Manchmal geben sie zur Optimierung nicht true oder false , sondern den vorherigen Wert, weil Sehr oft werden solche Operationen in einer Schleife ausgeführt. Um den expected Wert zu erhalten, müssen Sie ihn zuerst lesen:
CAS_optimized(var, expected, new): # , atomic, atomic: current = var.get() if current == expected: var.set(new) return current # CAS CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
Dieser Ansatz kann eine Lesung speichern. Im Rahmen unserer Überprüfung werden wir eine einfache Form von CAS , weil Falls gewünscht, kann eine solche Optimierung unabhängig durchgeführt werden.
Bei verteilten Systemen wird jede Änderung versioniert. Das heißt, Zuerst lesen wir den Wert aus dem Speicher und erhalten die aktuelle Version der Daten. Und dann versuchen wir zu schreiben und erwarten, dass sich die Version der Daten nicht geändert hat. In diesem Fall wird die Version jedes Mal erhöht, wenn die Daten aktualisiert werden:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
Mit diesem Ansatz können Sie die Aktualisierung von Werten genauer steuern und so das ABA-Problem vermeiden. Insbesondere wird die Versionierung von Etcd und Zookeeper unterstützt.
Beachten Sie die wichtige Eigenschaft, die die Verwendung von CAS_versioned Operationen bietet. Tatsache ist, dass eine solche Operation unbeschadet der übergeordneten Logik wiederholt werden kann. Bei der Multithread-Programmierung hat diese Eigenschaft keinen besonderen Wert, da Wenn die Operation dort fehlgeschlagen ist, wissen wir mit Sicherheit, dass sie nicht zutraf. Bei verteilten Systemen wird diese Invariante verletzt, weil Die Anfrage erreicht möglicherweise den Empfänger, aber die erfolgreiche Antwort ist nicht mehr vorhanden. Daher ist es wichtig, Anforderungen erneut senden zu können, ohne befürchten zu müssen, Invarianten der Logik auf hoher Ebene zu brechen.
Diese Eigenschaft CAS_versioned die Operation CAS_versioned . Tatsächlich kann dieser Vorgang endlos wiederholt werden, bis die tatsächliche Antwort des Empfängers zurückgegeben wird. Dies führt wiederum zu einer ganzen Reihe von Fehlern im Zusammenhang mit der Netzwerkinteraktion.
Beispiel
Schauen wir uns an, wie Sie basierend auf CAS_versioned und CAS_versioned von einem Konto auf ein anderes übertragen können, das beispielsweise zu verschiedenen Kopien von Etcd gehört. Hier CAS_versioned ich davon aus, dass die CAS_versioned Funktion basierend auf der bereitgestellten API bereits entsprechend implementiert ist.
withdraw(from, amount): # CAS- while true: # version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS- while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
Hier haben wir unsere Operation in halbe Transaktionen unterteilt und führen jede halbe Transaktion über die Operation CAS_versioned . Mit diesem Ansatz können Sie unabhängig mit jedem Konto arbeiten und heterogenen Speicher verwenden, der nicht miteinander verbunden ist. Das einzige Problem, das uns hier erwartet, ist der Geldverlust im Falle eines Rückgangs des aktuellen Prozesses im Intervall zwischen den halben Transaktionen.
Warteschlange
Um fortzufahren, müssen Sie eine Ereigniswarteschlange implementieren. Die Idee ist, dass Handler für die Kommunikation untereinander eine geordnete Nachrichtenwarteschlange benötigen, in der keine Daten verloren gehen oder dupliziert werden. Dementsprechend wird jede Interaktion in der Handlerkette auf diesem Grundelement aufbauen. Es ist auch ein nützliches Tool zum Analysieren und Überwachen eingehender und ausgehender Datenströme. Darüber hinaus können Mutationen des Status der Handler auch über die Warteschlange durchgeführt werden.
Die Warteschlange besteht aus zwei Operationen:
- Fügen Sie am Ende der Warteschlange eine Nachricht hinzu.
- Empfangen einer Nachricht aus der Warteschlange am angegebenen Index.
In diesem Zusammenhang erwäge ich aus mehreren Gründen nicht, Nachrichten aus der Warteschlange zu entfernen:
- Mehrere Prozessoren können aus derselben Warteschlange lesen. Das Entfernen der Synchronisation ist eine nicht triviale, wenn auch nicht unmögliche Aufgabe.
- Es ist nützlich, eine Warteschlange für ein relativ langes Intervall (Tag oder Woche) zum Debuggen und Überwachen aufrechtzuerhalten. Der Nutzen dieser Eigenschaft ist schwer zu überschätzen.
- Sie können alte Elemente entweder planmäßig löschen oder TTL für die Warteschlangenelemente festlegen. Es ist wichtig sicherzustellen, dass die Prozessoren die Daten verarbeiten können, bevor der Besen eintrifft und alles bereinigt. Wenn die Verarbeitungszeit in der Größenordnung von Sekunden und die TTL in der Größenordnung von Tagen liegt, sollte nichts davon passieren.
Um die Elemente zu speichern und die Addition effektiv zu implementieren, benötigen wir:
- Der Wert mit dem aktuellen Index. Dieser Index zeigt auf das Ende der Warteschlange zum Hinzufügen von Elementen.
- , .
lock-free
: . :
- CAS .
- .
, , .
- lock-free . , , . Lock-free? Nein! , 2 : . lock-free, — ! , , , . . , .. , .
- . , . .
, lock-free .
Lock-free
, , : , .. , :
push(queue, value): # index = queue.get_current_index() while true: # , # var = queue.at(index) # = 0 , .. # , if var.CAS_versioned(0, value): # , queue.update_index(index + 1) break # , . index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # cur_index, version = queue.get_current_index_versioned() # , # , . if cur_index >= index: # - , # break if queue.current_index_var().CAS_versioned(version, index): # , break # - . # , ,
. , ( — , , ). lock-free . ?
, push , ! , , .
. : . , - , - . , , .. . . ? , .. , , .
, , . Das heißt, . , , . , .
, . , . , , . , .
, , , .
. .
, :
- , .. stateless.
- , — .
, , concurrent exactly-once .
:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
. :
handle(input, output, state): # index = state.get() while true: value = input.get(index) output.push(value) index += 1 # state.set(index)
exactly-once . , , , .
exactly-once , , . .., , , , , — :
# get_next_index(queue): index = queue.get_index() # while queue.has(index): # queue.push index = max(index + 1, queue.get_index()) return index # . # true push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # queue.update_index(index + 1) return true return false handle(input, output, state): # # {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # : , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # , input_index += 1 # , push_at false, # fsm_state = {PREPARING, input_index} state.set(fsm_state)
push_at ? , . , , , . , . . - , lock-free .
, :
- : .
- , : .
: concurrent exactly-once .
? :
- , ,
push_at false. . - , . , , .
concurrent exactly-once ? , , . , . .
:
# , , # .. true, # true. # false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # , , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # , # if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

, . , .
kernel panic, , .. . . : , . , .
, , .
: .
: , , , , :
# : # - input_queues - # - output_queues - # - state - # - handler - : state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes case {HANDLING, user_state, input_indexes}: # inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # , next_indexes = next(inputs, input_indexes) # # user_state, outputs = handler(user_state, inputs) # , # fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # , # output_index = output_queues[output_pos].get_next_index() # fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # if output_queues[output_pos].push_at_idempotent( value, output_index ): # , output_pos += 1 # , PREPARING. # # fsm_state = if output_pos == len(outputs): # , # {HANDLING, user_state, input_indexes} else: # # , # {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

: HANDLING . , .., , . , . , PREPARING WRITING , . , HANDLING .
, , , . , . , .
. . .

:
my_handler(state, inputs): # state.queue.push(inputs) # duration state.queue.trim_time_window(duration) # avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none none ]
, , concurrent exactly-once handle .
:
handle_db(input_queue, db): while true: # tx = db.begin_transaction() # . # , # index = tx.get_current_index() # tx.write_current_index(index + 1) # value = intput_queue.get(index) if value: # tx.increment_counter() tx.commit() # , , #
. Weil , , , , concurrent exactly-once . .
— . , , .
, , . , , .
. , . Weil , . . .
— . , , . , - , , . , .. , , .
. , , . , , .
. , . : , . , .
, , :
- , . .
- . , .
- . , . , , . Das heißt, . : .
, , -, , -, .
, . :
transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
withdraw , , deposit : ? deposit - (, , ), . , , , , ? , , - , .
, , , . , , , . , . , , . Weil , , . , : , — .
, .
: , , , , . , - :
, , .
, , .. , , . , .
: lock-free , . , .. , .
CAS . , :
# , handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # ... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # , output_index
, . . :
- PREPARING . , .
- WRITING . . , PREPARING .
, . , , — . :
- . , , .. , .
- , .. . , .
, lock-free , , .
, . , Stale Read , . — CAS: . :
- Distributed single register — (, etcd Zookeeper):
- Linearizability
- Sequential consistency
- Transactional — (, MySQL, PostgreSQL ..):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional — NewSQL :
- Strict Consistency
: ? , , . , , CAS . , , Read My Writes .
Fazit
exactly-once . , .. , , , . , , , , .. , .
lock-free .
:
- : .
- : .
- : : exactly-once .
- Concurrent : .
- Real-time : .
- Lock-free : , .
- Deadlock free : , .
- Race condition free : .
- Hot-hot : .
- Hard stop : .
- No failover : .
- No downtime : .
- : , .
- : .
- : .
- : .
, . Aber das ist eine andere Geschichte.

:
- Concurrent exactly-once.
- Semi-transactions .
- Lock-free two-phase commit, .
- .
- lock-free .
- .
Literatur
[1] : ABA.
[2] Blog: You Cannot Have Exactly-Once Delivery
[3] : .
[4] : 3: .
[5] : .