Der erste Teil, „Cavium ThunderX2-Evaluierung: Der Traum von einem Arm-Server wird wahr“, ist
hierTestkonfiguration und Methodik
Für den ThunderX2-Test wurden alle unsere Tests auf dem 64-Bit-Kernel von Ubuntu Server 17.10, Linux 4.13 durchgeführt. Wir verwenden normalerweise die LTS-Version, aber da Cavium mit dieser speziellen Version von Ubuntu geliefert wird, sind wir nicht das Risiko eingegangen, das Betriebssystem zu ändern. Die Ubuntu-Distribution enthält den GCC 7.2-Compiler.

Sie werden feststellen, dass die DRAM-Menge in unseren Serverkonfigurationen variiert. Der Grund ist einfach: Intel hat 6 Speicherkanäle und Caviums ThunderX2 hat 8 Speicherkanäle.
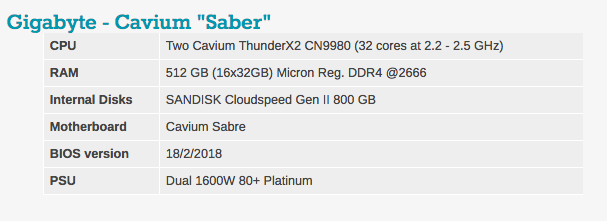
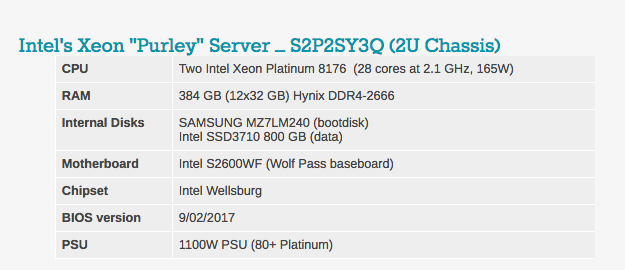
Typische BIOS-Einstellungen finden Sie unten. Es ist erwähnenswert, dass Hyperthreading und Intel Virtualisierungstechnologie enthalten sind.
Sonstige HinweiseBeide Server werden gemäß der europäischen Norm mit 230 V (maximal 16 Ampere) betrieben. Die Raumlufttemperatur wird von unseren Airwell CRAC-Instrumenten auf 23 ° C geregelt und gehalten.
Energieverbrauch
Es ist erwähnenswert, dass das Gigabyte-Sabre-System 500 Watt verbrauchte, wenn es nur Linux ausführte (dh es war größtenteils im Leerlauf). Unter Last verbraucht das System jedoch ungefähr 800 W, was im Prinzip unseren Erwartungen entsprach, da wir zwei 180 W TDP-Chips im Inneren haben. Wie bei frühen Testsystemen üblich, können wir keine genauen Leistungsvergleiche durchführen.
In der Tat behauptet Cavium, dass aktuelle Systeme von HP, Gigabyte und anderen viel effizienter sein werden. Das verwendete Sabre-Testsystem hatte mehrere Probleme mit der Energieverwaltung: falsche Steuerung der Lüfter-Firmware, BMC-Fehler und Netzteil mit zu viel Leistung (1600 W).
Speichersubsystem: Bandbreite
Die Verwendung des Stream-Bandbreiten-Benchmark-Benchmarks von John McCalpin auf den neuesten Prozessoren wird immer schwieriger, das volle Potenzial der Systembandbreite zu messen, wenn die Anzahl der Kern- und Speicherkanäle zunimmt. Wie Sie den folgenden Ergebnissen entnehmen können, ist die Schätzung des Durchsatzes nicht einfach. Das Ergebnis hängt stark von den ausgewählten Einstellungen ab.

Theoretisch hat ThunderX2 33% mehr Bandbreite als Intel Xeon, da der SoC 8 Speicherkanäle im Vergleich zu sechs Intel-Kanälen hat. Diese hohen Durchsatzzahlen werden nur unter sehr spezifischen Bedingungen erreicht und erfordern einige Anpassungen, um die Verwendung von Remote-Speicher zu vermeiden. Insbesondere müssen wir sicherstellen, dass keine Ströme von einem Sockel zum anderen geleitet werden.
Für den Anfang haben wir versucht, auf beiden Architekturen die besten Ergebnisse zu erzielen. Im Fall von Intel hat der ICC-Compiler mit einigen Optimierungen auf niedriger Ebene innerhalb der Stream-Schleifen immer bessere Ergebnisse erzielt. Im Fall des Cavium folgten wir den Anweisungen des Cavium. Grob gesagt ist das resultierende Bild eine Vorstellung davon, welche Bandbreite diese Prozessoren auf ihren Spitzen erreichen können. Um ehrlich zu sein, mit Intel können Sie mit idealen Einstellungen (AVX-512) 200 GB / s erreichen.
Es ist jedoch offensichtlich, dass das ThunderX2-System seinen Prozessorkernen 15 bis 28% mehr Bandbreite bieten kann. Das Ergebnis sind 235 GB / s oder etwa 120 GB / s pro Steckplatz. Dies ist wiederum etwa dreimal so groß wie das ursprüngliche ThunderX.
Speichersubsystem: Verzögerung
Obwohl Bandbreitenmessungen nur für einen kleinen Teil des Servermarktes gelten, hängt fast jede Anwendung stark von der Latenz des Speichersubsystems ab. Bei Versuchen, die Cache- und Speicherlatenz zu messen, haben wir LMBench verwendet. Die Daten, die wir als Ergebnis sehen möchten, sind "Verzögerung beim zufälligen Laden, Schritt = 16 Bytes". Beachten Sie, dass wir die L3-Latenz und die DRAM-Zeitverzögerung in Nanosekunden ausdrücken, da wir keine genauen L3-Cache-Taktwerte haben.
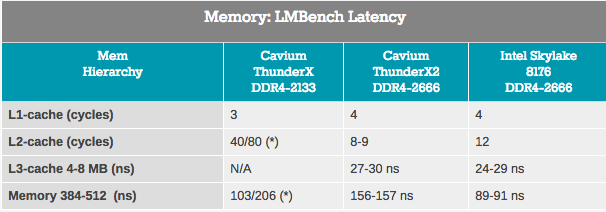
Der Zugriff auf den ThunderX2 L2-Cache erfolgt mit sehr geringer Latenz. Bei Verwendung eines einzelnen Streams sieht der L3-Cache wie ein Konkurrent des integrierten L3-Cache von Intel aus. Als wir jedoch zu DRAM kamen, zeigte Intel eine deutlich geringere Latenz.
Speichersubsystem: TinyMemBench
Um ein tieferes Verständnis der jeweiligen Architekturen zu erlangen, wurde der Open-Source-Test TinyMemBench verwendet. Der Quellcode wurde mit GCC 7.2 kompiliert und die Optimierungsstufe auf -O3 gesetzt. Die Teststrategie ist im Benchmark-Handbuch gut beschrieben:
Die durchschnittliche Zeit wird für zufällige Speicherzugriffe in Puffern verschiedener Größen gemessen. Je größer der Puffer ist, desto größer ist der relative Beitrag von TLB-Cache-Fehlern, L1 / L2- und DRAM-Zugriffen. Alle Zahlen geben die zusätzliche Zeit an, die zur Latenz des L1-Cache hinzugefügt werden muss (4 Zyklen).
Wir haben mit ein und zwei zufälligen Lesevorgängen (ohne große Seiten) getestet, weil wir sehen wollten, wie das Speichersystem mehrere Leseanforderungen verarbeitet.
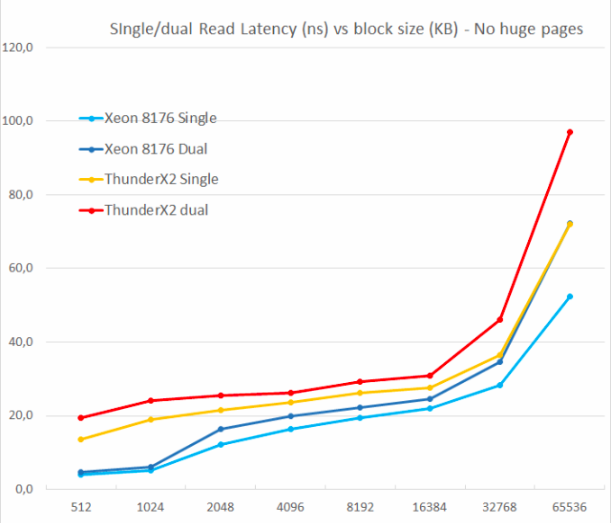
Einer der Hauptnachteile des ursprünglichen ThunderX war die Unfähigkeit, mehrere ausstehende Fehler zu unterstützen. Die Parallelität auf Speicherebene ist ein wichtiges Merkmal für jeden modernen Hochleistungsprozessorkern: Mit seiner Hilfe werden Cache-Fehler vermieden, die zu Back-End-Hunger führen können. Daher ist ein nicht blockierender Cache ein Schlüsselmerkmal für große Kerne.
ThunderX2 leidet dank seines nicht blockierenden Caches überhaupt nicht unter diesem Problem. Genau wie beim Skylake-Kern in Xeon 8176 erhöht der zweite Messwert die Gesamtlatenz nur um 15 bis 30%, nicht um 100%. Laut TinyMemBench hat der Skylake-Kern eine deutlich bessere Latenz. Der 512-KB-Referenzpunkt ist leicht zu erklären: Der Skylake-Kern ruft immer noch von seinem schnellen L2 ab, und der ThunderX2-Kern muss auf L3 zugreifen. Die Zahlen von 1 und 2 MB zeigen jedoch, dass Intel Prefetchers einen ernsthaften Vorteil bieten, da die Latenz der Durchschnitt für den L2- und L3-Cache ist. Die Latenzraten sind im Bereich von 8 bis 16 MB ähnlich, aber sobald wir über L3 (64 MB) hinausgehen, bietet Intels Skylake Speicher mit geringerer Latenz.
Single-Threaded-Leistung: SPEC CPU2006
Um mit der Messung der tatsächlichen Rechenleistung zu beginnen, beginnen wir mit dem SPEC CPU2006-Paket. Erfahrene Leser werden darauf hinweisen, dass SPEC CPU2006 veraltet war, als SPEC CPU2017 erschien. Aufgrund der begrenzten Testzeit und der Tatsache, dass wir ThunderX nicht erneut testen konnten, haben wir uns entschlossen, bei CPU2006 zu bleiben.
Angesichts der Tatsache, dass SPEC ein fast so guter Compiler-Benchmark wie Hardware ist, halten wir es für angemessen, unsere Testphilosophie zu formulieren. Sie müssen die tatsächlichen Indikatoren bewerten und dürfen die Testergebnisse nicht aufblasen. Daher ist es wichtig, so weit wie möglich Bedingungen „wie in der realen Welt“ mit den folgenden Einstellungen zu schaffen (konstruktive Kritik zu diesem Thema ist willkommen):
- 64-Bit-gcc: Der am häufigsten verwendete Compiler unter Linux, ein guter Compiler, der nicht versucht, Tests zu "unterbrechen" (libquantum ...)
- -Ofast: Compiler-Optimierung, die viele Entwickler verwenden können
- -fno-strict-aliasing: Erforderlich, um einige Untertests zu kompilieren
- Basislauf: Jeder Subtest wird auf die gleiche Weise kompiliert
Zunächst müssen Sie die Leistung in Anwendungen messen, in denen aus irgendeinem Grund aufgrund einer „feindlichen Multithread-Umgebung“ eine Verzögerung auftritt. Zweitens müssen Sie verstehen, wie gut die ThunderX LLC-Architektur mit einem einzelnen Thread im Vergleich zur Intel Skylake-Architektur funktioniert. Bitte beachten Sie, dass Sie in diesem speziellen Skylake-Modell die Frequenz auf 3,8 GHz übertakten können. Der Chip arbeitet in fast allen Situationen mit einer Frequenz von 2,8 GHz (28 Threads sind aktiv) und unterstützt 3,4 GHz mit 14 aktiven Threads.
Im Allgemeinen positioniert Cavium ThunderX2 CN9980 (1795 US-Dollar) als "besser als 6148" (3072 US-Dollar), einen Prozessor, der mit 2,6 GHz (20 Threads) arbeitet und problemlos 3,3 GHz erreicht (bis zu 16 Threads aktiv) ) Auf der anderen Seite wird Intel-SKU in vielen Situationen einen signifikanten 30-prozentigen Vorteil bei der Taktrate haben (3,3 GHz gegenüber 2,5 GHz).
Cavium entschied sich, das Frequenzdefizit durch die Anzahl der Kerne zu kompensieren und bot 32 Kerne an - das sind 60% mehr als beim Xeon 6148 (20 Kerne). Es ist erwähnenswert, dass eine größere Anzahl von Kernen in vielen Anwendungen (z. B. Amdahl) zu einer Verringerung der Rendite führt. Wenn Cavium Intels dominante Position mit ThunderX2 erschüttern möchte, sollte jeder Kern zumindest eine wettbewerbsfähige Leistung in der realen Welt bieten. In diesem Fall sollte ThunderX2 mindestens 66% (2,5 gegenüber 3,8) Single-Threaded-Skylake-Leistung bieten.
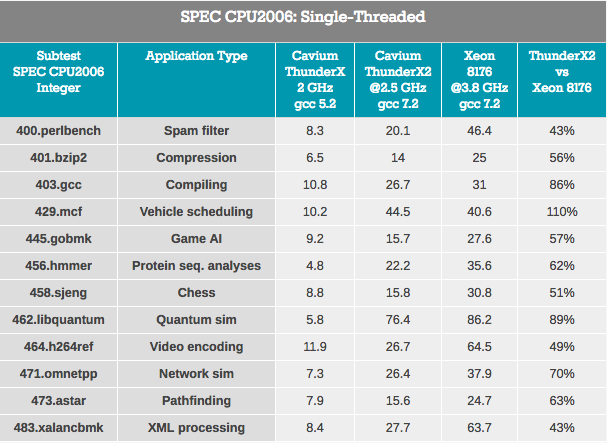
Die Ergebnisse sind verschwommen, da ThunderX2 mit ARMv8-Code (AArch64) arbeitet und Xeon x86-64-Code verwendet.
Zeigerverfolgungstests - Die XML-Verarbeitung (auch große OoO-Puffer) und das Auffinden von Pfaden, die normalerweise von einem großen L3-Cache abhängen, um die Auswirkungen der Zugriffslatenz zu verringern, sind für ThunderX2 am schlimmsten. Es kann davon ausgegangen werden, dass eine höhere Latenz des DRAM-Systems die Leistung beeinträchtigt.
Arbeitslasten, bei denen der Einfluss der Verzweigungsvorhersage höher ist (zumindest bei x86-64: ein höherer Prozentsatz bei der Auswahl des falschen Zweigs) - gobmk, sjeng, hmmer - sind nicht die besten Lasten für ThunderX2.
Es ist auch erwähnenswert, dass Perlbench-, Gobmk-, Hmmer- und H264Ref-Anweisungen bekanntermaßen vom größeren L2-Cache von Skylake (512 KB) profitieren. Wir zeigen Ihnen nur einige Teile des Puzzles, aber zusammen können sie helfen, das Bild zusammenzusetzen.
Positiv zu vermerken ist, dass ThunderX2 für gcc gut funktioniert hat, das hauptsächlich im L1- und L2-Cache funktioniert (daher auf eine geringe L2-Latenz angewiesen ist), und die Auswirkungen der Leistung von Verzweigungsprädiktoren sind minimal. Im Allgemeinen ist der beste Test für TunderX2 mcf (Verteilung von Fahrzeugen im öffentlichen Verkehr), der, wie Sie wissen, den L1-Datencache fast vollständig überspringt und sich auf den L2-Cache stützt, und dies ist die Stärke von ThunderX2. Mcf stellt auch Anforderungen an die Speicherbandbreite. Libquantum ist ein Test, der den größten Bedarf an Speicherbandbreite hat. Die Tatsache, dass Skylake eine ziemlich mittelmäßige Single-Threaded-Bandbreite bietet, ist wahrscheinlich auch der Grund, warum ThunderX2 auf libquantum und mcf so gut abschneidet.
SPEC CPU2006 Cont: Kernbasierte Leistung mit SMT
Über die Single-Thread-Leistung hinaus sollte auch die Multi-Thread-Leistung innerhalb eines einzelnen Kerns berücksichtigt werden. Die Vulcan-Prozessorarchitektur wurde ursprünglich für die Verwendung von SMT4 entwickelt, um die Kerne geladen zu halten und den Gesamtdurchsatz zu erhöhen. Darüber werden wir jetzt sprechen.
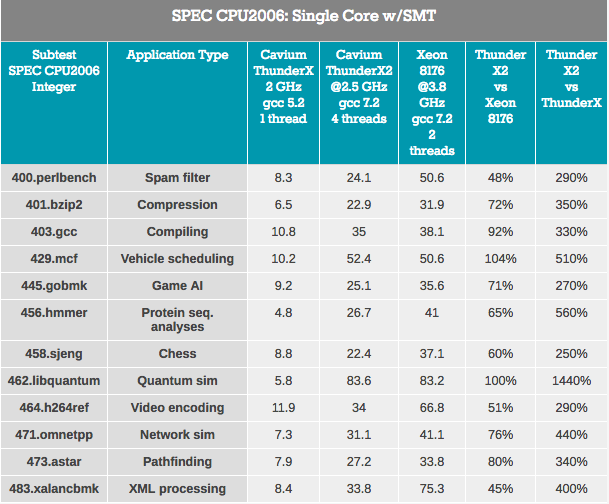
Erstens hat der ThunderX2-Kern gegenüber dem ersten ThunderX-Kern viele bedeutende Verbesserungen erfahren. Selbst mit Blick auf libquantum kann dieser Test auf dem älteren ThunderX-Kernel nach einigen Verbesserungen und Optimierungen am Compiler problemlos dreimal schneller ausgeführt werden. Nun, der neue ThunderX2 ist nicht weniger als 3,7-mal schneller als sein älterer Bruder. Diese Überlegenheit von IPC beseitigt alle Vorteile des vorherigen ThunderX.
Wenn wir uns die Auswirkungen von SMT ansehen, sehen wir im Durchschnitt, dass 4-Wege-SMT die ThunderX2-Leistung um 32% verbessert. Dies reicht von 8% für die Videokodierung bis 74% für die Pfadfindung. Intel gewinnt unterdessen 18% von seiner 2-Wege-SMT, von 4% auf 37% in denselben Szenarien.
Insgesamt beträgt die Leistungssteigerung von ThunderX2 32%, was ziemlich gut ist. Hier stellt sich jedoch die offensichtliche Frage: Wie unterscheidet es sich von anderen SMT4-Architekturen? Beispielsweise weist IBM POWER8, das auch SMT4 unterstützt, im selben Szenario einen Anstieg von 76% auf.
Dies ist jedoch kein Vergleich zwischen Ähnlichem und Ähnlichem, da der IBM-Chip ein viel breiteres Back-End hat: Er kann 10 Befehle verarbeiten, während der ThunderX2-Kern auf 6 Befehle pro Zyklus beschränkt ist. Der POWER8-Kern ist gefräßiger: Der Prozessor kann nur 10 dieser "ultra-breiten" Kerne in einem Leistungsbudget von 190 W bei 22 nm Prozess aufnehmen. Eine weitere Leistungssteigerung durch die Verwendung von SMT4 erfordert höchstwahrscheinlich noch größere Kerne und wirkt sich wiederum ernsthaft auf die Anzahl der in ThunderX2 verfügbaren Kerne aus. Trotzdem ist es interessant, diesen Anstieg von 32% in der Zukunft zu betrachten.
Im nächsten (3) Teil:
- Java-Leistung
- Java-Leistung: riesige Seiten
- Apache Spark 2.x Benchmarking
- Zusammenfassung
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?