Der erste und
zweite Teil, „Cavium ThunderX2-Evaluierung: Der Arm Server-Traum ist wahr geworden“.
Java-Leistung
SPECjbb 2015 ist ein Java Business Benchmark-Benchmark, mit dem die Leistung von Servern bewertet wird, auf denen typische Java-Anwendungen ausgeführt werden. Es verwendet die neuesten Java 7- und XML-Funktionen und beeinträchtigt die Sicherheit.

Bitte beachten Sie, dass wir die Version von SPECjbb 1.0 auf Version 1.01 aktualisiert haben.

Wir haben SPECjbb mit vier Gruppen von Transaktionsinjektoren und Backends getestet. Der Grund, warum wir den Multi-JVM-Test verwenden, ist, dass er näher an den realen Bedingungen liegt: Mehrere virtuelle Maschinen auf einem Server sind eine gängige Praxis, insbesondere auf Servern mit mehr als 100 Threads. Die Java-Version ist OpenJDK 1.8.0_161.
Jedes Mal, wenn wir die Ergebnisse von SPECjbb veröffentlichen, erhalten wir Kommentare, dass unsere Leistung zu niedrig ist. Aus diesem Grund haben wir uns entschlossen, etwas mehr Zeit zu verbringen und auf verschiedene Einstellungen zu achten.
- Kernel-Einstellungen, wie z. B. Timings des Taskplaners, Löschen des Seitencaches
- Deaktivieren von Energiesparfunktionen, manuelles Konfigurieren des C-Status-Verhaltens.
- Stellen Sie die Lüfter auf maximale Geschwindigkeit ein (wir geben viel Energie für ein paar zusätzliche Leistungspunkte aus).
- Deaktivieren von RAS-Funktionen (z. B. Speicherbereinigung)
- Zahlreiche Einstellungen für verschiedene Java-Parameter ... Es ist unrealistisch, da teure Spezialisten jedes Mal, wenn Sie die Anwendung auf verschiedenen Computern ausführen (was häufig in der Cloud vorkommt), die Einstellungen für einen bestimmten Computer konfigurieren müssen, was außerdem dazu führen kann, dass die Anwendung auf anderen Computern gestoppt wird
- Konfigurieren Sie sehr SKU-spezifische NUMA-Einstellungen und CPU-Zuordnungen. Die Migration zwischen zwei verschiedenen SKUs im selben Cluster kann zu schwerwiegenden Leistungsproblemen führen.
In einer Produktionsumgebung sollte die Einstellung einfach und vorzugsweise nicht zu spezifisch für die Maschine sein. Zu diesem Zweck haben wir zwei Arten von Einstellungen angewendet. Das erste ist ein sehr einfaches Setup zum sofortigen Messen der Leistung, um alles auf einem Server mit 128 GB RAM zu platzieren:
"-server -Xmx24G -Xms24G -Xmn16G"Für das zweite Setup haben wir auf der Suche nach dem besten Durchsatzindikator mit "-XX: + AlwaysPreTouch", "-XX: -UseBiasedLocking" und "specjbb.forkjoin.workers" gespielt. "+ AlwaysPretouch" vor dem Start setzt alle Speicherseiten zurück, wodurch die Auswirkungen der Leistung auf neue Seiten verringert werden. "-UseBiasedLockin" deaktiviert die gesperrte Sperre, die standardmäßig aktiviert ist. Das voreingenommene Sperren gibt einem Thread Priorität, der bereits konkurrierende Daten in den Cache geladen hat. Die Kehrseite der voreingenommenen Verriegelung sind recht komplexe zusätzliche Prozesse (Rebias), die bei einer falsch gewählten Strategie die Leistung verringern können.
Die folgende Grafik zeigt die maximale Leistung für unseren MultiJVM SPECJbb-Benchmark.

ThunderX2 erreicht eine Leistung von 80 bis 85% des Xeon 8176. Diese Zahl reicht aus, um den Xeon 6148 zu übertreffen. Interessanterweise erzielen Intel- und Cavium-Systeme ihre besten Ergebnisse auf unterschiedliche Weise. Im Fall von Dual ThunderX2 haben wir verwendet:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingWährend das Intel-System die beste Leistung erzielte, ließ es eine Offset-Sperre (Standard). Wir haben festgestellt, dass das Intel-System - wahrscheinlich aufgrund der relativ "ungeraden" Anzahl von Threads - eine etwas geringere durchschnittliche Prozessorlast (einige Prozent) und einen größeren L3-Cache aufweist, was das voreingenommene Sperren zu einer guten Strategie für diese Architektur macht.
Schließlich haben wir Critical-jOPS, das den Durchsatz anhand von Antwortzeitlimits misst.

Durch die aktive Verwendung einer großen Anzahl von Threads können Sie erheblich mehr Critical-JOPS erzielen, indem Sie die RAM-Verteilung auf der JVM erhöhen. Überraschenderweise zeigt das Dual ThunderX2-System mit seiner höheren Anzahl von Streams und seiner niedrigeren Taktrate die beste Zeit, bietet eine hohe Bandbreite und behält eine Reaktionszeit von 99 Prozent bis zu einem bestimmten Grenzwert bei.
Durch Erhöhen der Heap-Größe kann Intel die Lücke leicht schließen (bis zu x2), jedoch auf Kosten der Bandbreite (von -20% bis -25%). Es scheint, dass der Intel-Chip mehr Anpassungen benötigt als ARM. Um dies weiter zu untersuchen, haben wir uns Transparent Huge Pages (THP) zugewandt.
Java-Leistung: große Seiten
Normalerweise spielt für die CPU selten jemand einen anderen in Faktor 3 ab, aber wir haben uns entschlossen, die Angelegenheit eingehender zu untersuchen. Der offensichtlichste Kandidat war Huge Pages, oder wie jeder außer der Linux-Community es "Large Pages" nennt.
Jeder moderne Prozessor speichert virtuelle und physische Speicherzuordnungen in seinen TLBs zwischen. Die „normale“ Seitengröße beträgt 4 KB, sodass der Skylake-Kern mit 1536 Elementen etwa 6 MB pro Kern zwischenspeichern kann. In den letzten 15 Jahren ist die DRAM-Kapazität von einigen GB auf Hunderte von GB gestiegen, weshalb TLB-Fehler zu einem Problem geworden sind. Ein TLB-Fehler ist ziemlich teuer - Sie benötigen einige Speicherzugriffe, um einige Tabellen zu lesen und schließlich eine physikalische Adresse zu finden.
Alle modernen Prozessoren unterstützen große Seiten. In x86-64 (Intel und AMD) ist eine beliebte Option 2 MB, eine 1 GB-Seite ist ebenfalls verfügbar. Inzwischen hat eine große Seite auf ThunderX2 mindestens 0,5 GB. Die Verwendung großer Seiten reduziert die Anzahl der TLB-Fehler (obwohl die Anzahl der Einträge in TLBs bei großen Seiten normalerweise viel geringer ist), verringert jedoch die Anzahl der Speicherzugriffe, die erforderlich sind, wenn ein TLB fehlt.
Es war jedoch an der Zeit, dass Linux diese Funktion auf bequeme Weise unterstützte. Speicherfragmentierung, widersprüchliche und schwer zu konfigurierende Einstellungen, Inkompatibilitäten und insbesondere sehr verwirrende Namen verursachten viele Probleme. Tatsächlich raten viele Softwareanbieter Serveradministratoren immer noch, große Seiten zu deaktivieren.
Lassen Sie uns zu diesem Zweck sehen, was passiert, wenn wir die transparenten riesigen Seiten aktivieren und die besten Einstellungen speichern, die zuvor besprochen wurden.
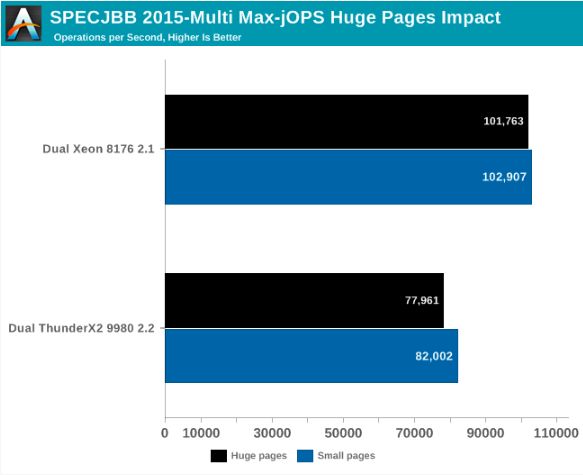
Insgesamt ist die Auswirkung auf die Leistung bei Max-jOPs nicht spektakulär. Dies ist eigentlich eine kleine Regression. Xeon verliert ungefähr 1% seiner Bandbreite, ThunderX2 - ungefähr 5%.
Fahren wir mit der Critical-jOPS-Metrik fort, bei der der Durchsatz als 99. Perzentil des Antwortzeitlimits gemessen wird.

Großer Unterschied! Anstatt zu besiegen, geht Intel über ThunderX2 hinaus. Es sollte jedoch gesagt werden, dass die Leistung mit 4 KB-Seiten anscheinend eine ernsthafte Schwäche in der Intel-Architektur darstellt.
Apache Spark 2.x Benchmarking
Last but not least hat unser Arsenal den Apache Spark-Test. Apache Spark ist die Idee der Big Data-Verarbeitung. Die Beschleunigung von Big-Data-Anwendungen bleibt ein vorrangiges Projekt in dem Universitätslabor, in dem ich arbeite (Sizing Servers Lab, Universität Westflandern). Daher haben wir einen Benchmark erstellt, der viele Spark-Funktionen verwendet und auf der realen Verwendung basiert.

Der Test ist in der obigen Abbildung beschrieben. Wir beginnen mit 300 GB komprimierten Daten, die von CommonCrawl gesammelt wurden. Diese komprimierten Dateien sind eine große Anzahl von Webarchiven. Wir entpacken die Daten im laufenden Betrieb, um lange Wartezeiten zu vermeiden, die hauptsächlich mit dem Speichergerät zusammenhängen. Anschließend extrahieren wir die aussagekräftigen Textdaten mithilfe der Java BoilerPipe-Bibliothek aus den Archiven. Mit dem Stanford CoreNLP Natural Language Processing Tool extrahieren wir Entitäten („Wörter, die etwas bedeuten“) aus dem Text und berechnen dann, welche URLs diese Objekte am häufigsten vorkommen. Der Algorithmus Alternating Lessest Square wird verwendet, um zu empfehlen, welche URLs für ein bestimmtes Thema am interessantesten sind.
Um eine bessere Skalierung zu erreichen, starten wir 4 Künstler. Der Forscher Esley Havenert hat den Spark-Test neu konfiguriert, damit er auf Apache Spark 2.1.1 ausgeführt werden kann.
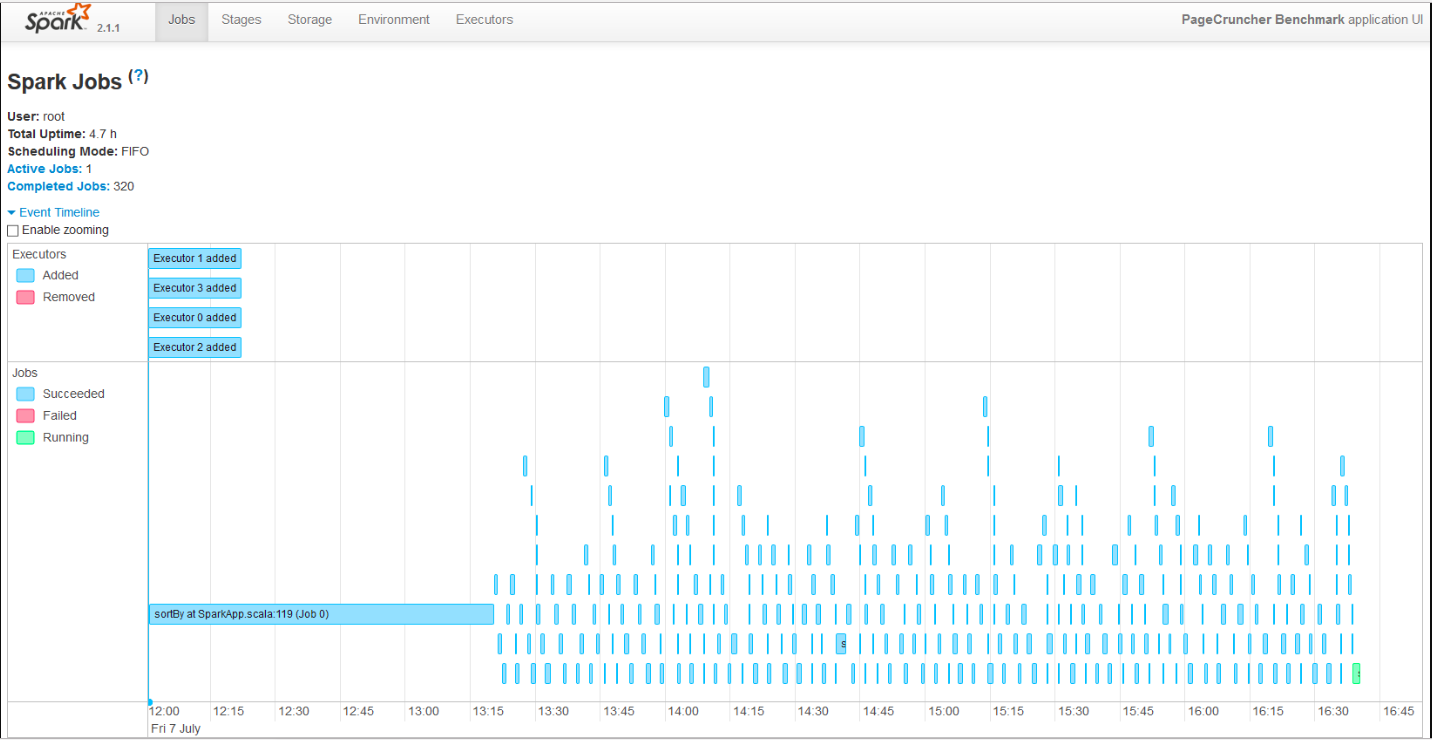
Hier sind die Ergebnisse:

(*) EPYC und Xeon E5 V4 sind älter, arbeiten mit Kernel 4.8 und etwas älterem Java 1.8.0_131 anstelle von 1.8.0_161. Obwohl wir erwarten, dass die Ergebnisse auf dem 4.13-Kernel und Java 1.8.0_161 sehr ähnlich sind, haben wir in Skylake Xeon keinen großen Unterschied zwischen diesen beiden Einstellungen festgestellt.
Die Datenverarbeitung ist sehr parallel und belastet den Prozessor sehr intensiv, erfordert jedoch für die Phasen des "Mischens" viel Interaktion mit dem Speicher. Der Zeitaufwand für die Kommunikation mit dem Speichergerät ist vernachlässigbar. Die ALS-Phase skaliert nicht über viele Threads, macht jedoch weniger als 4% der gesamten Testzeit aus.
ThunderX2 bietet 87% der Leistung des doppelt so teuren EPYC 7601. Da dieser Indikator gut mit der Anzahl der Kerne skaliert, können wir davon ausgehen, dass der Xeon 6148 etwa 4,8 Punkte erzielen wird. on Apache Spark Während ThunderX2 das Xeon Platinum 8176 nicht wirklich bedrohen kann, bietet es das Gleiche wie das Gold 6148 und sein Bruder für viel weniger Geld.
Und was am Ende
Zusammenfassend zeigen unsere SPECInt-Tests, dass die ThunderX2-Kerne noch einige Mängel aufweisen. Unser erster negativer Eindruck ist, dass der intensive Verzweigungscode - insbesondere in Kombination mit den üblichen L3-Cache-Fehlern (hohe DRAM-Verzögerung) - eher langsam arbeitet. Daher wird es Sonderfälle geben, in denen ThunderX2 nicht die beste Wahl ist.
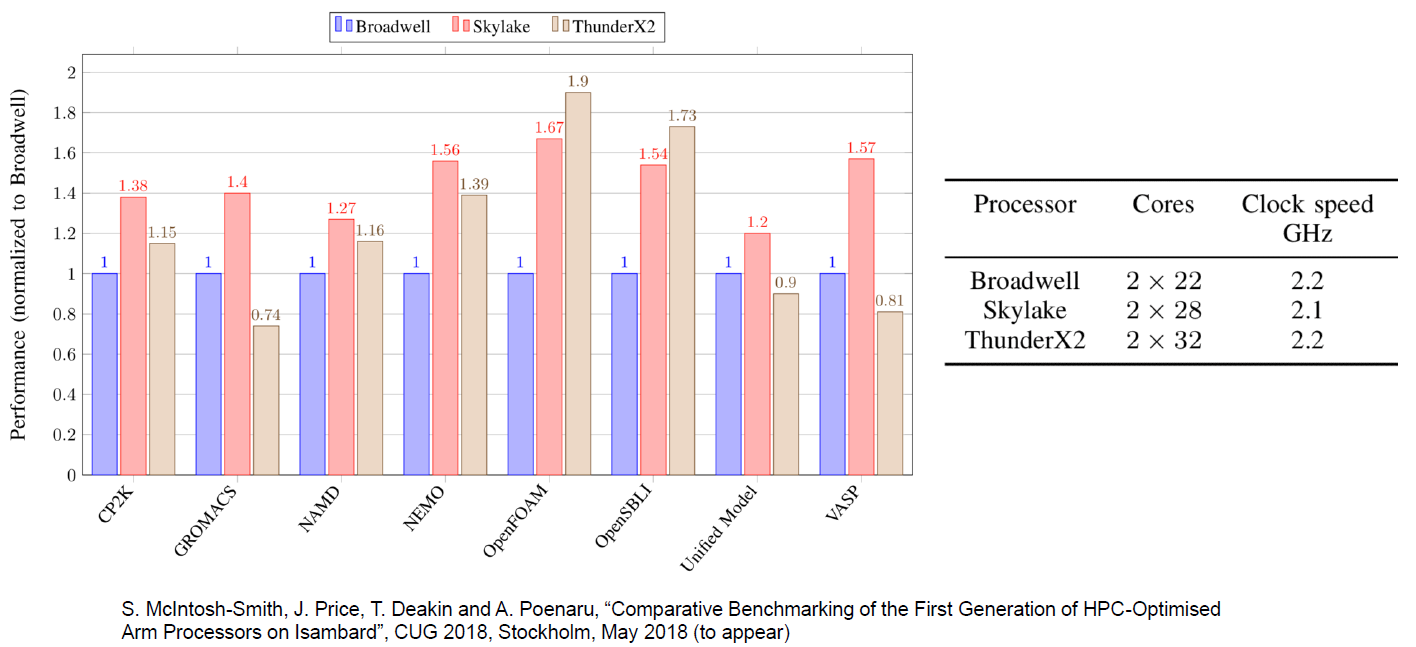
Zusätzlich zu einigen Nischenmärkten sind wir jedoch ziemlich sicher, dass ThunderX2 eine solide Leistung erbringen wird. Beispielsweise bestätigen Leistungsmessungen, die von unseren Kollegen an der Universität Bristol durchgeführt wurden, unsere Annahme, dass intensive HPC-Workloads wie OpenFoam (CFD) und NAMD.run unter ThunderX2 gut funktionieren
Aufgrund der Ergebnisse früher Tests der Server-Software, die wir durchgeführt haben, können wir angenehm überrascht sein. ThunderX2-Leistung für einen Dollar sowohl auf Java Server (SPECJbb) als auch auf Big Data-Verarbeitung - jetzt - bei weitem die beste auf dem Servermarkt. Wir müssen den AMD EPYC-Prozessor und die Goldversion der aktuellen Generation (Skylake) von Xeon erneut testen, aber gleichzeitig wird es sehr schwierig sein, 80-90% der Leistung des 8176-Prozessors für ein Viertel seiner Kosten zu übertreffen.
Als zusätzlichen Vorteil für Cavium und ThunderX2 sollte erwähnt werden, dass das Arm Linux-Ökosystem bereits 2018 ausgereift ist. Spezialisierte Linux-Kernel und andere Tools werden nicht mehr benötigt. Sie installieren einfach den Ubuntu-, Red Hat- oder Suse-Server und können die Bereitstellung und Installation von Software aus Standard-Repositorys automatisieren. Dies ist eine signifikante Verbesserung gegenüber dem, was wir beim Start von ThunderX erlebt haben. Bereits im Jahr 2016 konnte eine einfache Installation aus regulären Ubuntu-Repositorys Probleme verursachen.
Insgesamt ist ThunderX2 also ein sehr starker Rivale. Dies kann für EPYC AMD noch gefährlicher sein als für Intels Skylake Xeon, da sowohl Cavium als auch AMD um dieselbe Kundengruppe konkurrieren, da Intel möglicherweise aufgegeben wird. Dies liegt an der Tatsache, dass Kunden, die in teure Unternehmenssoftware (Oracle, SAP) investiert haben, auf der Hardwareseite weniger kostensensitiv sind und daher viel seltener auf eine neue Hardwareplattform wechseln. Und diese Leute haben in den letzten 5 Jahren in Intel investiert, da dies die einzige Option war.
Dies bedeutet wiederum, dass diejenigen, die flexibler und preisbewusster sind, wie Hosting- und Cloud-Anbieter, jetzt einen alternativen Arm-Server mit einem hervorragenden Verhältnis von Leistung zu Dollar auswählen können. Und da HP, Cray, Pengiun, Gigabyte, Foxconn und Inventec ThunderX2-basierte Systeme anbieten, gibt es keinen Mangel an Qualitätslieferanten.
Kurz gesagt, ThunderX2 ist der erste SoC, der auf dem CPU-Servermarkt mit Intel und AMD konkurriert. Und das ist eine angenehme Überraschung: Endlich ist eine Lösung für Arm-Server erschienen!
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?