Die Stream-Replikation, die 2010 veröffentlicht wurde, ist zu einer der bahnbrechenden Funktionen von PostgreSQL geworden. Derzeit kann fast keine Installation ohne die Verwendung der Streaming-Replikation auskommen. Es ist zuverlässig, einfach zu konfigurieren und ressourcenschonend. Bei allen positiven Eigenschaften können jedoch während des Betriebs verschiedene Probleme und unangenehme Situationen auftreten.
Alexey Lesovsky (
@lesovsky ) auf der Highload ++ 2017 erklärte, wie
verschiedene Arten von Problemen mithilfe integrierter Tools
und Tools von Drittanbietern
diagnostiziert und behoben werden
können . Unter den Kürzungen basiert die Dekodierung dieses Berichts auf einem Spiralprinzip: Zuerst listen wir alle möglichen Diagnosewerkzeuge auf, dann führen wir allgemeine Probleme auf und diagnostizieren sie, dann sehen wir, welche Sofortmaßnahmen ergriffen werden können, und schließlich, wie das Problem radikal behandelt werden kann.
Über den Sprecher : Alexei Lesovsky, Datenbankadministrator bei Data Egret. Eines der beliebtesten Themen von Alexey in PostgreSQL ist das Streaming von Replikationen und das Arbeiten mit Statistiken. Daher befasste sich der Bericht auf Highload ++ 2017 mit der Suche nach Problemen mithilfe von Statistiken und den Methoden zu deren Lösung.
Planen
- Ein bisschen Theorie oder wie die Replikation in PostgreSQL funktioniert
- Tools zur Fehlerbehebung oder was PostgreSQL und die Community haben
- Fehlerbehebungsfälle:
- Probleme: ihre Symptome und Diagnose
- Entscheidungen
- Maßnahmen zu ergreifen, damit diese Probleme nicht auftreten.
Warum das alles? Dieser Artikel hilft Ihnen dabei, die Streaming-Replikation besser zu verstehen und Probleme schnell zu finden und zu beheben, um die Reaktionszeit auf unangenehme Vorfälle zu verkürzen.
Ein bisschen Theorie
PostgreSQL verfügt über eine Entität wie das Write-Ahead-Protokoll (XLOG), ein Transaktionsprotokoll.
Fast alle Änderungen, die an Daten und Metadaten in der Datenbank auftreten, werden in diesem Protokoll aufgezeichnet. Wenn plötzlich ein Unfall auftritt, startet PostgreSQL, liest das Transaktionsprotokoll und stellt die aufgezeichneten Änderungen an den Daten wieder her. Dies gewährleistet Zuverlässigkeit - eine der wichtigsten Eigenschaften von DBMS und PostgreSQL.
Das Transaktionsprotokoll kann auf zwei Arten ausgefüllt werden:
- Wenn Backends einige Änderungen in der Datenbank vornehmen (INSERT, UPDATE, DELETE usw.), werden standardmäßig alle Änderungen synchron im Transaktionsprotokoll aufgezeichnet:
- Der Client hat einen COMMIT-Befehl gesendet, um die Daten zu bestätigen.
- Daten werden im Transaktionsprotokoll aufgezeichnet.
- Sobald die Fixierung erfolgt ist, wird das Backend gesteuert und es kann weiterhin Befehle vom Client empfangen.
- Die zweite Option ist das asynchrone Schreiben in das Transaktionsprotokoll, wenn ein separater dedizierter WAL-Writer-Prozess Änderungen mit einem bestimmten Zeitintervall in das Transaktionsprotokoll schreibt. Dadurch wird eine Steigerung der Backend-Leistung erreicht, da nicht gewartet werden muss, bis der Befehl COMMIT abgeschlossen ist.
Am wichtigsten ist, dass die Streaming-Replikation auf diesem Transaktionsprotokoll basiert. Wir haben mehrere Streaming-Replikationsmitglieder:
- Meister, wo alle Änderungen stattfinden;
- Mehrere Replikate, die das Transaktionsprotokoll vom Master akzeptieren und alle diese Änderungen in ihren lokalen Daten reproduzieren. Dies ist eine Streaming-Replikation.
Beachten Sie, dass alle diese Transaktionsprotokolle im Verzeichnis pg_xlog in $ DATADIR gespeichert sind - dem Verzeichnis mit den wichtigsten DBMS-Datendateien. In der 10. Version von PostgreSQL wurde dieses Verzeichnis in pg_wal / umbenannt, da pg_xlog / nicht selten viel Speicherplatz beansprucht und Entwickler oder Administratoren, die es unwissentlich mit den Protokollen verwechseln, es unachtsam löschen und alles schlecht wird.
PostgreSQL verfügt über mehrere Hintergrunddienste, die an der Streaming-Replikation beteiligt sind. Betrachten wir sie aus Sicht des Betriebssystems.
- Von der Seite des Master-WAL-Absenderprozesses. Dies ist ein Prozess, der Transaktionsprotokolle an Replikate sendet. Jedes Replikat verfügt über einen eigenen WAL-Absender.
- Das Replikat führt wiederum den WAL-Empfängerprozess aus, der Transaktionsprotokolle über die Netzwerkverbindung vom WAL-Absender empfängt und an den Startprozess weiterleitet.
- Der Startvorgang liest die Protokolle und reproduziert im Datenverzeichnis alle Änderungen, die im Transaktionsprotokoll aufgezeichnet sind.
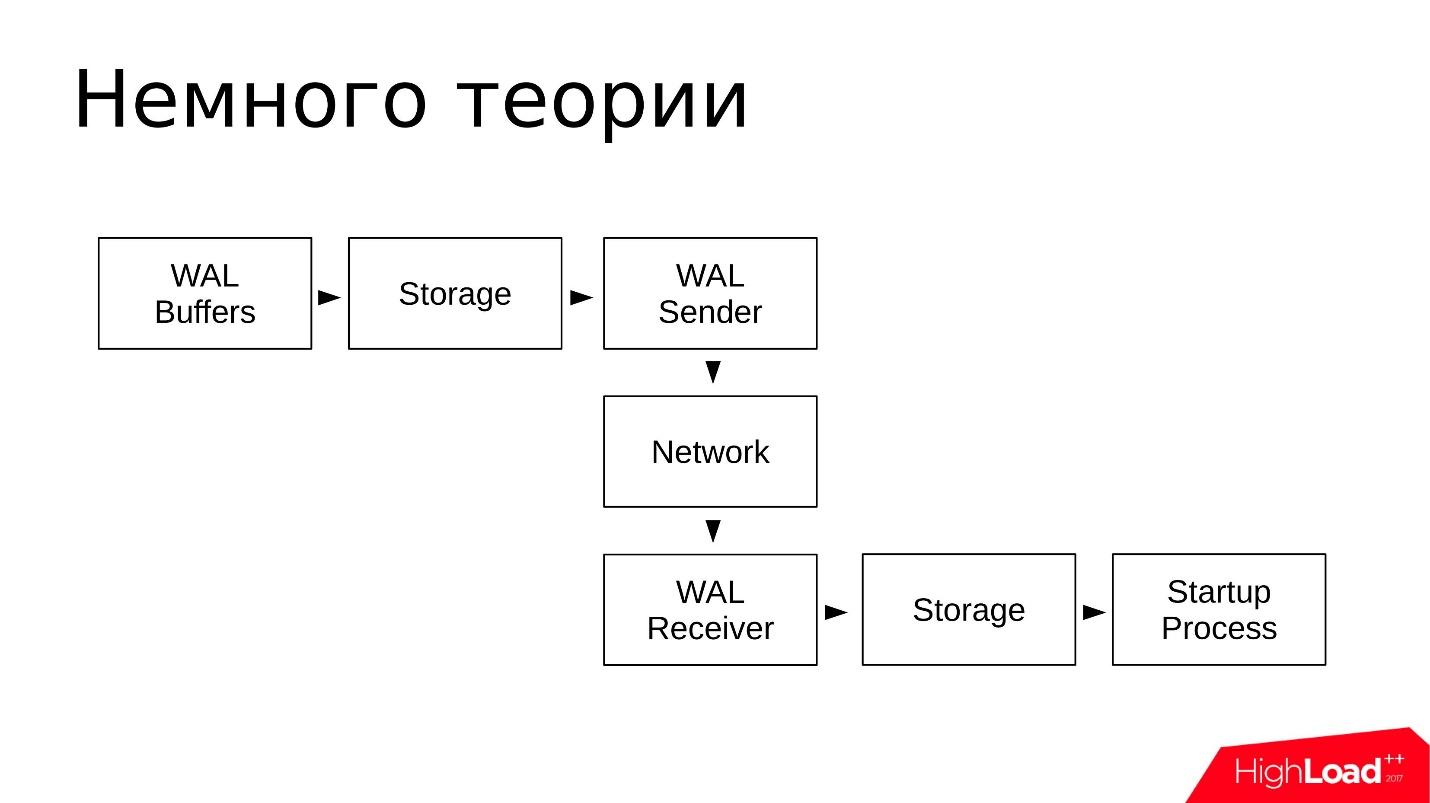
Schematisch sieht es ungefähr so aus:
- Änderungen werden in WAL-Puffer geschrieben, die dann in das Transaktionsprotokoll geschrieben werden.
- Protokolle werden im Verzeichnis pg_wal / gespeichert.
- WAL Sender liest das Transaktionsprotokoll aus dem Repository und überträgt es über das Netzwerk.
- Der WAL-Empfänger empfängt und speichert in seinem Speicher - im lokalen pg_wal /;
- Der Startvorgang liest alles, was akzeptiert und reproduziert wird.
Das Schema ist einfach. Die Stream-Replikation funktioniert sehr zuverlässig und wird seit vielen Jahren hervorragend genutzt.
Tools zur Fehlerbehebung
Lassen Sie uns sehen, welche Tools und Dienstprogramme die Community und PostgreSQL anbieten, um die Probleme bei der Streaming-Replikation zu untersuchen.
Tools von Drittanbietern
Beginnen wir mit Tools von Drittanbietern. Diese Dienstprogramme haben einen eher
universellen Plan und können nicht nur zur Untersuchung von Vorfällen im Zusammenhang mit der Streaming-Replikation verwendet werden. Dies sind im Allgemeinen
Dienstprogramme eines Systemadministrators .
- oben aus dem procps-Paket. Als Ersatz für top können Sie alle Dienstprogramme wie atop, htop und dergleichen verwenden. Sie bieten ähnliche Funktionen.
Mit Hilfe von top betrachten wir: Auslastung der Prozessoren (CPU), durchschnittliche Auslastung (durchschnittliche Auslastung) sowie Speicher- und Swap-Speicherplatznutzung.
- iostat von sysstat und iotop. Diese Dienstprogramme zeigen die Auslastung von Festplattengeräten und welche E / A von Prozessen im Betriebssystem erstellt werden.
Mit Hilfe von iostat untersuchen wir: Speichernutzung, wie viele Iops im Moment, welcher Durchsatz auf Geräten, welche Verzögerungen bei der Verarbeitung von E / A-Anforderungen (Latenz). Diese ziemlich detaillierten Informationen stammen aus dem procfs-Dateisystem und werden dem Benutzer in visueller Form zur Verfügung gestellt.
- nicstat ist ein Analogon von iostat, nur für Netzwerkschnittstellen. In diesem Dienstprogramm können Sie die Verwendung von Schnittstellen überwachen.
Mit nicstat sehen wir so aus: Ebenso ist die Schnittstellennutzung, einige Fehler, die an Schnittstellen auftreten, der Durchsatz ein sehr nützliches Dienstprogramm.
- pgCenter ist ein Dienstprogramm, das nur mit PostgreSQL funktioniert. Es zeigt PostgreSQL-Statistiken in einer topähnlichen Oberfläche an, und Sie können auch Statistiken zur Streaming-Replikation darin anzeigen.
Mit Hilfe von pgCenter schauen wir: Statistiken zur Replikation. Sie können die Replikationsverzögerung beobachten, sie irgendwie bewerten und zukünftige Arbeiten vorhersagen.
- perf ist ein Hilfsprogramm für eine eingehendere Untersuchung der Ursachen von "Untergrundklopfen", wenn im Betrieb seltsame Probleme auf der PostgreSQL-Codeebene auftreten.
Mit Hilfe von Perf suchen wir: Underground Knocks. Damit perf vollständig mit PostgreSQL funktioniert, muss letzteres mit Debug-Zeichen kompiliert werden, damit Sie den Funktionsstapel in Prozessen anzeigen können und welche Funktionen die meiste CPU-Zeit in Anspruch nehmen.
Alle diese Dienstprogramme werden benötigt,
um Hypothesen zu
testen , die bei der Fehlerbehebung auftreten - wo und was langsamer wird, wo und was Sie reparieren müssen, überprüfen. Diese Dienstprogramme stellen sicher, dass wir auf dem richtigen Weg sind.
Eingebettete Tools
Was bietet PostgreSQL selbst?
Systemansichten
Im Allgemeinen gibt es viele Tools für die Arbeit mit PostgreSQL. Jedes Anbieterunternehmen, das PostgreSQL-Support bietet, bietet seine eigenen Tools an. In der Regel basieren diese Tools jedoch auf internen PostgreSQL-Statistiken. In dieser Hinsicht bietet PostgreSQL Systemansichten, in denen Sie verschiedene Auswahlen treffen und die benötigten Informationen abrufen können. Das heißt, mit einem regulären Client, normalerweise psql, können wir Abfragen durchführen und sehen, was in der Statistik passiert.
Es gibt einige Systemansichten. Um mit der Streaming-Replikation zu arbeiten und Probleme zu untersuchen, benötigen wir nur: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts und pg_stat_activity und pg_stat_archiver.
Es gibt nur wenige davon, aber dieses Set reicht aus, um zu überprüfen, ob es Probleme gibt.
Hilfsfunktionen
Mithilfe von Zusatzfunktionen können Sie Daten aus statistischen Systemdarstellungen entnehmen und in eine für Sie bequemere Form umwandeln. Hilfsfunktionen sind ebenfalls nur wenige Teile.
- pg_current_wal_lsn () (das alte Analogon von pg_current_xlog_location ()) ist die wichtigste Funktion, mit der Sie die aktuelle Position im Transaktionsprotokoll anzeigen können. Ein Transaktionsprotokoll ist eine fortlaufende Folge von Daten. Mit dieser Funktion können Sie den letzten Punkt sehen und die Position abrufen, an der das Transaktionsprotokoll jetzt gestoppt wurde.
- pg_last_wal_receive_lsn (), pg_last_xlog_receive_location () ist eine ähnliche Funktion wie oben, nur für Replikate. Das Replikat empfängt das Transaktionsprotokoll, und Sie können die Position des zuletzt empfangenen Transaktionsprotokolls anzeigen.
- pg_wal_lsn_diff (), pg_xlog_location_diff () ist eine weitere nützliche Funktion. Wir geben ihr zwei Positionen aus dem Transaktionsprotokoll und sie zeigt diff - den Abstand zwischen diesen beiden Punkten in Bytes. Diese Funktion ist immer nützlich, um die Verzögerung zwischen dem Master und den Replikaten in Bytes zu bestimmen.
Eine vollständige Liste der Funktionen kann mit dem Meta-Befehl psql abgerufen werden: \ df * (wal | xlog | lsn | location) *.
Sie können es in psql eingeben und alle Funktionen anzeigen, die wal, xlog, Isn, location enthalten. Es wird ungefähr 20 bis 30 solcher Funktionen geben, und sie liefern auch verschiedene Informationen im Transaktionsprotokoll. Ich empfehle Ihnen, sich vertraut zu machen.
Dienstprogramm Pg_waldump
Vor Version 10.0 hieß es pg_xlogdump. Das Dienstprogramm pg_waldump wird benötigt, wenn wir in die Segmente des Transaktionsprotokolls schauen, herausfinden möchten, welche Ressourceneinträge dort angekommen sind und was PostgreSQL dort geschrieben hat, dh für eine detailliertere Studie.
In Version 10.0 wurden alle Systemansichten, Funktionen und Dienstprogramme, die das Wort xlog enthielten, umbenannt. Alle Vorkommen der Wörter xlog und location wurden durch die Wörter wal bzw. lsn ersetzt. Dasselbe wurde mit dem Verzeichnis pg_xlog gemacht, das zum Verzeichnis pg_wal wurde.
Das Dienstprogramm pg_waldump dekodiert einfach den Inhalt von XLOG-Segmenten in ein für Menschen lesbares Format. Sie können sehen, welche sogenannten Ressourceneinträge während der Arbeit von PostgreSQL in die Segmentprotokolle fallen, welche Indizes und Heap-Dateien geändert wurden und welche Informationen für den Standby-Modus dort angekommen sind. Daher können mit pg_waldump viele Informationen angezeigt werden.
Es gibt jedoch einen Haftungsausschluss, der in der offiziellen Dokumentation geschrieben ist : pg_waldump zeigt möglicherweise leicht falsche Daten an, wenn PostgreSQL ausgeführt wird (Kann falsche Ergebnisse liefern, wenn der Server ausgeführt wird - was auch immer das bedeutet)
Sie können den folgenden Befehl verwenden:
pg_waldump -f - /wal_10 \ $(psql -qAtX - "select pg_walfile_name(pg_current_wal_lsn())")
Dies ist ein Analogon des Befehls tail -f nur für Transaktionsprotokolle. Dieser Befehl zeigt das Ende des Transaktionsprotokolls an, das gerade ausgeführt wird. Sie können diesen Befehl ausführen. Er findet das letzte Segment mit dem letzten Transaktionsprotokolleintrag, stellt eine Verbindung dazu her und zeigt den Inhalt des Transaktionsprotokolls an. Ein etwas kniffliges Team, aber es funktioniert trotzdem. Ich benutze es oft.
Fehlerbehebung bei Fällen
Hier betrachten wir die häufigsten Probleme, die in der Praxis von Beratern auftreten, welche Symptome auftreten können und wie sie diagnostiziert werden können:
Replikationsverzögerungen sind das häufigste Problem . In jüngerer Zeit hatten wir Korrespondenz mit dem Kunden:
- Wir haben die Master-Slave-Replikation zwischen den beiden Servern unterbrochen.
- Verzögerung 2 Stunden erkannt, pg_dump gestartet.
- OK, ich verstehe. Was ist unsere zulässige Verzögerung?
- 16 Stunden bei max_standby_streaming_delay.
- Was passiert, wenn diese Verzögerung überschritten wird? Heulende Sirene?
- Nein, Transaktionen werden geschlagen und der WAL-Wurf wird fortgesetzt.
Wir haben ständig Probleme mit Replikationsverzögerungen und lösen diese fast jede Woche.
Das Anschwellen des Verzeichnisses pg_wal /, in dem Transaktionsprotokollsegmente gespeichert sind, ist ein Problem, das weniger häufig auftritt. In diesem Fall müssen jedoch sofort Maßnahmen ergriffen werden, damit das Problem nicht zu einer Notsituation wird, wenn die Replikate abfallen.
Lange Abfragen , die auf dem Replikat ausgeführt werden, führen zu
Konflikten während der Wiederherstellung . Dies ist eine Situation, in der das Replikat geladen wird. Sie können Leseabfragen für die Replikate ausführen. In diesem Moment beeinträchtigen diese Abfragen die Reproduktion des Transaktionsprotokolls. Es liegt ein Konflikt vor, und PostgreSQL muss entscheiden, ob auf den Abschluss der Abfrage gewartet oder diese abgeschlossen werden soll, und das Transaktionsprotokoll weiter abspielen soll. Dies ist ein Replikationskonflikt oder ein Wiederherstellungskonflikt.
Wiederherstellungsprozess: 100% CPU-Auslastung - Das Wiederherstellen eines Transaktionsprotokolls auf Replikaten dauert 100% der Prozessorzeit. Dies ist auch eine seltene Situation, aber es ist ziemlich unangenehm, weil führt zu einer Erhöhung der Replikationsverzögerung und ist im Allgemeinen schwer zu untersuchen.
Replikationsverzögerungen
Replikationsverzögerungen treten auf, wenn dieselbe Anforderung, die auf dem Master und auf dem Replikat ausgeführt wird, unterschiedliche Daten zurückgibt. Dies bedeutet, dass die Daten zwischen dem Master und den Replikaten inkonsistent sind und es zu Verzögerungen kommt. Das Replikat muss einen Teil der Transaktionsprotokolle reproduzieren, um den Assistenten zu erreichen. Das Hauptsymptom sieht genau so aus: Es gibt eine Abfrage und sie geben unterschiedliche Ergebnisse zurück.
Wie kann man nach solchen Problemen suchen?- Es gibt eine grundlegende Ansicht des Assistenten und der Replikate - pg_stat_replication . Es werden Informationen zu allen WAL-Absendern angezeigt, dh zu Prozessen, die Transaktionsprotokolle senden. Jedes Replikat verfügt über eine separate Zeile, in der Statistiken für dieses bestimmte Replikat angezeigt werden.
- Mit der Hilfsfunktion pg_wal_lsn_diff () können Sie verschiedene Positionen im Transaktionsprotokoll vergleichen und dieselbe Verzögerung berechnen. Mit seiner Hilfe können wir bestimmte Zahlen ermitteln und feststellen, wo wir eine große Verzögerung haben, wo eine kleine und bereits irgendwie auf das Problem reagieren.
- Die Funktion pg_last_xact_replay_timestamp () funktioniert nur auf dem Replikat und ermöglicht es Ihnen, den Zeitpunkt anzuzeigen , zu dem die letzte verlorene Transaktion ausgeführt wurde. Es gibt eine bekannte Funktion now (), die die aktuelle Zeit anzeigt. Wir subtrahieren die Zeit, die uns von der Funktion pg_last_xact_replay_timestamp () angezeigt wird, von der Funktion now () und ermitteln die Zeitverzögerung.
In der 10. Version von pg_stat_replication wurden zusätzliche Felder angezeigt, die die Zeitverzögerung anzeigen, die bereits im Assistenten vorhanden ist. Daher ist diese Methode bereits veraltet, kann jedoch verwendet werden.
Es gibt eine kleine Falle. Wenn der Assistent längere Zeit keine Transaktionen enthält und keine Transaktionsprotokolle generiert, zeigt die letzte Funktion eine zunehmende Verzögerung an. Tatsächlich ist das System einfach im Leerlauf, es gibt keine Aktivität, aber bei der Überwachung können wir sehen, dass die Verzögerung zunimmt. Diese Falle ist es wert, in Erinnerung zu bleiben.
Die Ansicht ist wie folgt.

Es enthält Informationen zu jedem WAL-Absender und mehrere Felder, die für uns wichtig sind. Dies ist in erster Linie
client_addr - die Netzwerkadresse des verbundenen Replikats (normalerweise eine IP-Adresse) und eine Reihe von
lsn- Feldern (in älteren Versionen wird dies als Standort bezeichnet). Ich werde etwas weiter darauf
eingehen .
In der 10. Version wurden
Verzögerungsfelder angezeigt - dies ist eine zeitliche Verzögerung, dh ein besser lesbares Format. Die Verzögerung kann entweder in Bytes oder in der Zeit ausgedrückt werden - Sie können wählen, was Ihnen am besten gefällt.
In der Regel verwende ich diese Anfrage.

Dies ist nicht die komplexeste Abfrage, die pg_stat_replication in einem bequemeren und verständlicheren Format druckt. Hier benutze ich folgende Funktionen:
- pg_wal_lsn_diff () zum Lesen von Diffs. Aber zwischen was denke ich, sind Unterschiede? Wir haben mehrere Felder - sent_lsn, write_lsn, flush_lsn, replay_lsn. Durch die Berechnung des Unterschieds zwischen dem aktuellen und dem vorherigen Feld können wir genau verstehen, wo wir zurückgeblieben sind und wo genau die Verzögerung auftritt.
- pg_current_wal_lsn () , das die aktuelle Position des Transaktionsprotokolls anzeigt. Hier sehen wir uns den Abstand zwischen der aktuellen Position im Protokoll und der gesendeten an - wie viele Transaktionsprotokolle generiert, aber nicht gesendet wurden.
- sent_lsn , write_lsn - So viel wird an das Replikat gesendet, aber nicht aufgezeichnet. Das heißt, es befindet sich jetzt irgendwo im Netzwerk oder wurde von einem Replikat empfangen, aber noch nicht aus Netzwerkpuffern in den Festplattenspeicher geschrieben.
- write_lsn, flush_lsn - dies wird geschrieben, aber nicht vom Befehl fsync ausgegeben - als ob geschrieben, kann sich aber irgendwo im RAM im Seiten-Cache des Betriebssystems befinden. Sobald wir fsync ausführen, werden die Daten mit der Festplatte synchronisiert, werden dauerhaft gespeichert und alles scheint zuverlässig zu sein.
- replay_lsn, flush_lsn - Daten werden ausgegeben, fsync ausgeführt, aber nicht repliziert.
- current_wal_lsn und replay_lsn sind eine Art Gesamtverzögerung, die alle vorherigen Positionen umfasst.
Einige Beispiele

Das Replikat 10.6.6.8 ist oben hervorgehoben. Sie hat eine
ausstehende Verzögerung , sie hat einige Transaktionsprotokolle erstellt, aber sie werden immer noch nicht gesendet und liegen auf dem Master. Höchstwahrscheinlich gibt es ein Problem mit der Netzwerkleistung. Wir werden dies mit dem Dienstprogramm nicstat überprüfen.
Wir werden nicstat starten, siehe Schnittstellenauslastung, wenn es dort Probleme und Fehler gibt. Wir können diese Hypothese also testen.

Die
Schreibverzögerung ist oben markiert. Tatsächlich ist diese Verzögerung ziemlich selten, ich sehe sie fast nicht als groß an. Das Problem kann bei Festplatten liegen, und wir verwenden das Dienstprogramm iostat oder iotop. Wir untersuchen die Verwendung von Festplattenspeichern, die von den Prozessen erstellt werden, und finden dann heraus, warum.

Verzögerungen beim
Löschen und Wiedergeben - Meistens tritt die Verzögerung dort auf, wenn das Festplattengerät auf dem Replikat keine Zeit hat, einfach alle vom Master eingehenden Änderungen zu verlieren.
Auch mit den Dienstprogrammen iostat und iotop untersuchen wir, was mit der Festplattenauslastung passiert und warum die Bremsen.
Und der letzte
total_lag ist eine nützliche Metrik für Überwachungssysteme. Wenn unser Schwellenwert total_lag überschritten wird, wird ein Kontrollkästchen in der Überwachung aktiviert und wir beginnen zu untersuchen, was dort passiert.
Hypothesentest
Jetzt müssen Sie herausfinden, wie Sie ein bestimmtes Problem weiter untersuchen können. Ich habe bereits gesagt, wenn dies eine Netzwerkverzögerung ist, müssen wir überprüfen, ob mit dem Netzwerk alles in Ordnung ist.
Mittlerweile bieten fast alle Hoster 1 Gbit / s oder sogar 10 Gbit / s an, sodass eine
verstopfte Bandbreite das unwahrscheinlichste Szenario ist . In der Regel müssen Sie sich die Fehler ansehen. nicstat enthält Informationen zu Fehlern an den Schnittstellen. Sie können feststellen, dass Probleme mit Treibern auftreten, entweder mit der Netzwerkkarte selbst oder mit Kabeln.
Wir untersuchen
Speicherprobleme mit iostat und iotop. iostat wird benötigt, um das allgemeine Bild des Festplattenspeichers anzuzeigen: Geräterecycling, Gerätebandbreite, Latenz. iotop - für genauere Recherchen, wenn wir herausfinden müssen, welcher Prozess das Festplattensubsystem lädt. Wenn es sich um einen Prozess eines Drittanbieters handelt, kann dieser einfach erkannt und abgeschlossen werden, und möglicherweise verschwindet das Problem.
Zunächst betrachten wir
Wiederherstellungsverzögerungen und Replikationskonflikte durch top oder pg_stat_activity: Welche Prozesse werden ausgeführt, welche Anforderungen werden ausgeführt, ihre Ausführungszeit wird ausgeführt, wie lange sie ausgeführt werden. Wenn es sich um lange Abfragen handelt, schauen wir uns an, warum sie lange funktionieren, nehmen sie auf, verstehen und
optimieren sie - wir werden die Abfragen selbst untersuchen.
Wenn dies eine
große Anzahl von Transaktionsprotokollen ist, die vom Assistenten generiert wurden, können wir dies an
pg_stat_activity erkennen . Möglicherweise werden dort einige Sicherungsprozesse gestartet, eine Art Vakuum wurde gestartet (pg_stat_progress_vacuum) oder der Prüfpunkt wird ausgeführt. Das heißt, wenn zu viele Transaktionsprotokolle generiert werden und das Replikat einfach keine Zeit hat, es zu verarbeiten, kann es irgendwann einfach abfallen, und dies wird ein Problem für uns sein.
Und natürlich
pg_wal_lsn_diff () , um die Verzögerung zu bestimmen und festzustellen, wo wir die Verzögerung speziell haben - im Netzwerk, auf Festplatten oder auf Prozessoren.
Lösungsoptionen
Netzwerk- / SpeicherproblemeHier ist alles recht einfach, aber aus Sicht der Konfiguration ist dies normalerweise nicht gelöst. Sie können einige Muttern festziehen, aber im Allgemeinen gibt es zwei Möglichkeiten:
- Überprüfen Sie die Arbeitslast
Überprüfen Sie, welche Anforderungen ausgeführt werden. Möglicherweise werden Migrationen gestartet, die viele Transaktionsprotokolle generieren, oder es kann sich um Datenübertragung, Löschung oder Einfügung handeln.
Jeder Prozess, der Transaktionsprotokolle generiert, kann zu Transaktionsverzögerungen führen . Alle Daten im Assistenten werden so schnell wie möglich generiert. Wir haben eine Änderung an den Daten vorgenommen, sie an das Replikat gesendet, und das Replikat kann damit umgehen oder fehlschlagen. Dies betrifft den Assistenten nicht. Hier kann eine Verzögerung auftreten, und Sie müssen etwas damit tun.
Die dümmste Option - vielleicht sind wir auf die Leistung von Eisen gestoßen, und Sie müssen sie nur ändern. Dies können alte Festplatten oder SSDs von schlechter Qualität oder ein Plug-in für die Leistung eines RAID-Controllers sein. Hier erkunden wir nicht mehr die Basis selbst, sondern überprüfen die Leistung unserer Drüsen.
WiederherstellungsverzögerungenWenn aufgrund langer Anforderungen Replikationskonflikte auftreten, die zu einer Erhöhung der Wiedergabeverzögerung führen, werden
zunächst lange Anforderungen gesendet , die auf dem Replikat ausgeführt werden, da sie die Wiedergabe von Transaktionsprotokollen verzögern.
Wenn lange Abfragen mit der Nichtoptimalität der SQL-Abfrage selbst zusammenhängen (wir finden dies mithilfe von EXPLAIN ANALYZE heraus), müssen Sie diese Abfrage nur anders angehen und neu schreiben. Oder es besteht die Möglichkeit, ein
separates Replikat für die Berichterstellung von Abfragen zu konfigurieren. Wenn wir Berichte erstellen, die lange funktionieren, müssen sie an ein separates Replikat gesendet werden.
Es besteht immer noch die Möglichkeit,
nur zu warten . Wenn wir eine Verzögerung von einigen Kilobyte oder sogar zehn Megabyte haben, dies jedoch für akzeptabel halten, warten wir nur, bis die Anforderung abgeschlossen ist, und die Verzögerung löst sich von selbst auf. Dies ist auch eine Option, und es kommt häufig vor, dass dies akzeptabel ist.
High Volume WALWenn wir ein großes Volumen an Transaktionsprotokollen generieren, müssen wir dieses
Volumen pro Zeiteinheit reduzieren, damit das Replikat weniger Transaktionsprotokolle kauen muss.
Dies erfolgt normalerweise
über die Konfiguration . Teillösung beim Setzen des Parameters full_page_writes = off. Diese Option aktiviert / deaktiviert die Aufzeichnung vollständiger Bilder wechselnder Seiten im Transaktionsprotokoll. Dies bedeutet, dass, wenn wir den Servicevorgang zum Schreiben eines Prüfpunkts (CHECKPOINT) hatten und das nächste Mal, wenn wir einen Datenblock im Bereich der gemeinsam genutzten Puffer ändern, das vollständige Bild dieser Seite in das Transaktionsprotokoll aufgenommen wird und nicht nur die Änderung selbst. Bei allen nachfolgenden Änderungen auf derselben Seite werden nur Änderungen im Transaktionsprotokoll protokolliert. Und so weiter zum nächsten Kontrollpunkt.
Nach dem Prüfpunkt zeichnen wir das vollständige Bild der Seite auf. Dies wirkt sich auf das Volumen des aufgezeichneten Transaktionsprotokolls aus. Wenn es pro Zeiteinheit ziemlich viele Checkpoints gibt, nehmen wir an, dass 4 Checkpoints pro Stunde durchgeführt werden und es viele ganzseitige Bilder gibt, ist dies ein Problem. Sie können die Aufnahme von Vollbildern deaktivieren. Dies wirkt sich auf die Lautstärke der WAL aus. Aber auch dies ist eine halbe Sache.
Hinweis: Die Empfehlung zum Deaktivieren von full_page_writes sollte sorgfältig geprüft werden, da der Autor während des Berichts vergessen hat zu klären, dass das Deaktivieren eines Parameters unter bestimmten Umständen in Notfallsituationen auftreten kann (Beschädigung des Dateisystems oder seines Protokolls, teilweises Schreiben in Blöcke usw.). potenziell beschädigte Datenbankdateien. Seien Sie daher vorsichtig, wenn Sie den Parameter deaktivieren, kann dies das Risiko einer Datenbeschädigung in Notfallsituationen erhöhen.Eine weitere halbe Maßnahme besteht darin
, das Intervall zwischen den Kontrollpunkten zu verlängern . Standardmäßig wird der Prüfpunkt alle 5 Minuten durchgeführt, was häufig vorkommt. In der Regel wird dieses Intervall auf 30 bis 60 Minuten erhöht. Dies ist eine akzeptable Zeit, für die alle schmutzigen Seiten mit der Festplatte synchronisiert werden können.
Die Hauptlösung besteht natürlich darin,
unsere Arbeitsbelastung zu untersuchen - welche schweren Vorgänge dort stattfinden, die mit dem Ändern der Daten verbunden sind, und möglicherweise zu versuchen, diese Änderungen in Stapeln vorzunehmen.
Angenommen, wir haben eine Tabelle, wir möchten mehrere Millionen Datensätze daraus löschen. Die beste Option besteht darin, diese Millionen nicht sofort mit einer Anfrage zu löschen, sondern sie in Packungen von 100 bis 200.000 zu zerlegen, damit zum einen kleine WAL-Mengen erzeugt werden, zum anderen hat das Vakuum Zeit, die gelöschten Daten zu durchlaufen, und daher war die Verzögerung nicht so groß und kritisch.
Schwellung pg_wal /
Lassen Sie uns nun darüber sprechen, wie Sie feststellen können, dass das Verzeichnis pg_wal / geschwollen ist.
Theoretisch hält PostgreSQL es auf der Ebene bestimmter Konfigurationsdateien immer in einem für sich optimalen Zustand und sollte in der Regel nicht über bestimmte Grenzen hinauswachsen.
Es gibt einen Parameter max_wal_size, der den Maximalwert bestimmt. Außerdem gibt es den Parameter wal_keep_segments - eine zusätzliche Anzahl von Segmenten, die der Master für das Replikat speichert, wenn das Replikat plötzlich längere Zeit nicht verfügbar ist.
Nachdem wir die Summe von max_wal_size und wal_keep_segments berechnet haben, können wir grob abschätzen, wie viel Speicherplatz das Verzeichnis pg_wal / belegt. Wenn es schnell wächst und viel mehr Platz als der berechnete Wert einnimmt, bedeutet dies, dass ein Problem vorliegt und Sie etwas dagegen tun müssen.
Wie erkennt man solche Probleme?
Unter dem Linux-Betriebssystem gibt es den
Befehl du -csh . Wir können einfach den Wert überwachen und überwachen, wie viele Transaktionsprotokolle wir dort haben. Behalte ein kalkuliertes Etikett, wie viel er schuldet und wie viel er tatsächlich nimmt, und reagiere irgendwie auf Änderungen der Zahlen.
Ein weiterer Ort, den wir uns ansehen, sind die
Ansichten pg_replication_slots und
pg_stat_archiver . Die häufigsten Gründe, warum pg_wal / viel Speicherplatz beansprucht, sind vergessene Replikationssteckplätze oder fehlerhafte Archivierung. Andere Gründe haben auch einen Platz zu sein, aber in meiner Praxis waren sie sehr selten.
Und natürlich gibt es immer Fehler in den PostgreSQL-Protokollen, die dem Archivierungsbefehl zugeordnet sind. Leider gibt es keine weiteren Gründe für pg_wal / overflow. Wir können dort nur Archivfehler abfangen.
Optionen für Probleme:
Schweres CRUD - schwere Datenaktualisierungsvorgänge - schweres INSERT, DELETE, UPDATE, verbunden mit dem Ändern mehrerer Millionen Zeilen. Wenn PostgreSQL eine solche Operation ausführen muss, ist klar, dass eine große Menge an Transaktionsprotokoll generiert wird. Es wird in pg_wal / gespeichert, wodurch der belegte Speicherplatz vergrößert wird. Das heißt, wie ich bereits sagte, ist es eine gute Praxis, sie einfach in Pakete zu zerlegen und nicht das gesamte Array, sondern jeweils 100, 200, 300 Tausend zu aktualisieren.
Ein vergessener oder nicht verwendeter Replikationssteckplatz ist ein weiteres häufiges Problem. Menschen verwenden häufig die logische Replikation für einige ihrer Aufgaben: Sie konfigurieren Busse, die Daten an Kafka senden, senden Daten an eine Drittanbieteranwendung, die die logische Replikation in ein anderes Format dekodiert und sie irgendwie verarbeitet.
Die logische Replikation funktioniert normalerweise über Slots . Es kommt vor, dass wir einen Replikationssteckplatz eingerichtet, mit der Anwendung gespielt, festgestellt haben, dass diese Anwendung nicht zu uns passt, die Anwendung deaktiviert, gelöscht haben
und die Replikationssteckplätze weiterhin aktiv sind .
PostgreSQL für jeden Replikationssteckplatz speichert Segmente des Transaktionsprotokolls, falls eine Remoteanwendung oder ein Replikat erneut eine Verbindung zu diesem Steckplatz herstellt, und der Assistent kann ihnen diese Transaktionsprotokolle senden.
Aber die Zeit vergeht, niemand stellt eine Verbindung zum Slot her, Transaktionsprotokolle werden gesammelt und irgendwann nehmen sie 90% des Speicherplatzes ein. Wir müssen herausfinden, was es ist, warum so viel Platz benötigt wird. In der Regel muss dieser vergessene und nicht verwendete Steckplatz nur entfernt werden, und das Problem wird gelöst. Aber dazu später mehr.
Eine andere Option könnte ein
defekter archive_command sein . Wenn wir eine Art externes Transaktionsprotokoll-Repository haben, das wir für Disaster Recovery-Aufgaben aufbewahren, wird normalerweise ein Archivierungsbefehl eingerichtet, seltener wird pg_receivexlog eingerichtet. Der in archive_command registrierte Befehl ist sehr oft entweder ein separater Befehl oder ein Skript, das Segmente des Transaktionsprotokolls aus pg_wal / entnimmt und in den Archivspeicher kopiert.
Es kommt vor, dass wir eine Art Upgrade von Systempaketen durchgeführt haben, zum Beispiel in rsync die Version geändert, die Flags aktualisiert oder geändert wurden oder in einem anderen Befehl, der im Archivbefehl verwendet wurde, das Format ebenfalls geändert hat - und das Skript oder das Programm selbst, das in angegeben ist archive_command bricht ab. Folglich werden Archive nicht mehr kopiert.
Wenn der Archivierungsbefehl mit einer Ausgabe von nicht 0 gearbeitet hat, wird eine entsprechende Meldung in das Protokoll geschrieben, und das Segment verbleibt im Verzeichnis pg_wal /.
Bis wir feststellen, dass unser Archivteam kaputt ist, werden sich Segmente ansammeln und der Ort wird auch irgendwann enden.
Reihe von Notfallmaßnahmen (100% genutzter Raum):1.
CRUD , — pg_terminate_backend().
- , , , .. , pg_wal/, .
2.
root — reserved space ratio (ext filesystems).
ext ext 5%. , , 5% — . , , 1% , tune2fs -m 1. PostgreSQL , . 100% .
3.
(LVM, ZFS,...).
LVM ZFS, LVM ZFS, , , . , .
4. —
, , HE pg_wal/ .
, , , . ! PostgreSQL , . , , , .
, pg_xlog/ pg_wal/ — log , , , , - — !
, 100% CPU, .
workload . , ? , - , -. : , tablespace, tablespace.
. , , , , , , .
— .checkpoints_segments/max_wal_size, wal_keep_segments . , , — 10-20 wal_keep_segments, max_wal_size. , . PostgreSQL pg_wal/ .
pg_replication_slots — . ,
, — . , , . .
WAL, ,
pg_stat_archiver , . ,
, , , .
checkpoint . , , . , PostgreSQL .
, checkpoint .
, , — . - , . , .
— PostgreSQL :
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
2 — , , . : , , . ( 30 ),
PostgreSQL — .
. , , . - , timeout . — ALTER, , .
. , tablespace , tablespace. , , - — .
?
pg_stat_databases, pg_stat_databases_conflicts . , . , .
,
. , . , . , , , .
Was zu tun ist?
, — :
- max_standby_streaming_delay ( ). , . .
- hot_stadby_feedback ( /). , vacuum - , . bloat . , , , hot_stadby_feedback .
- DBA — . , . , , , - , .
- , , , , DBA — , , . max_standby_streaming_delay . , . , , , . — , .
Recovery process: 100% CPU usage
, , ,
100% . , , 100%. , pg_stat_replication, , replay, , .
:
- top — — 100% CPU usage recovery process;
- pg_stat_replication — , , .
, . , :
- perf top/record/report ( debug—);
- GDB;
- pg_waldump.
, , . workload,
. , , PostgreSQL shared buffers ( ). .
,
. - workload, - , - : « , - ».
pgsql-hackers ,
pgsql-bugs , , . , .
—
- , , .
Zusammenfassung
. , , , .
. , , , , , — .
,
, — . , , , .
, ,
— , , .
Nützliche Links
, Highload++ Siberia , 25 26 . , , .
- MySQL ClickHouse.
- , Oracle.
- Nikolay Golov erklärt Ihnen, wie Sie Transaktionen implementieren, wenn sich Geld in einem Dienst befindet, Dienste in einem anderen und jeder Dienst seine eigene isolierte Basis hat.
- Yuri Nasretdinov wird ausführlich erklären, warum VK ClickHouse benötigt, wie viele Daten gespeichert sind und vieles mehr.