Hallo Habr! Wir setzen unsere experimentelle Artikelserie fort und beobachten, wie Sie in Echtzeit den Prozess der Erstellung eines Spiels auf UWP beeinflussen können. Heute werden wir über die Frage "Wo werden Daten gespeichert?" Sprechen, die in den Reihen der Entwickler ständig auftaucht. Mach mit und teile deine Gedanken in den Kommentaren!
 Ich gebe dem Autor Alexei Plotnikov das Wort.
Ich gebe dem Autor Alexei Plotnikov das Wort.In einem früheren Artikel habe ich das Problem der bequemen Synchronisation von Benutzerdaten zwischen Geräten angesprochen und zunächst das Problem mit der Identifizierung gelöst. Dies ist jedoch der kleinste Teil dessen, was noch zu tun ist, um die Ziele zu erreichen.
Ein viel komplexeres Problem ist die Art und vor allem der Speicherort von Benutzerdaten. Wenn Microsoft eine solche Frage stellt, fällt ihm als Erstes
Microsoft Azure ein . Die Azure-Cloud-Plattform umfasst eine so breite Palette von Diensten, dass es anscheinend keine Aufgaben gibt, die mit ihrer Hilfe nicht gelöst werden können. Ob es wahr ist oder nicht, kann ich nicht beurteilen, aber meine Aufgabe liegt definitiv in der Macht dieser Plattform. Das Wichtigste zuerst.
Wir fangen klein an - was ist eine Wolke? Zum ersten Mal hörte ich 2012 von der Cloud und dann wurde der Ausdruck "Cloud Computing" am häufigsten verwendet. Die ursprüngliche Idee solcher Berechnungen bestand darin, die Rechenarbeit auf verschiedene Geräte zu verteilen, die voneinander entfernt sind. Besonders eindrucksvoll wurde über die Zukunft gesprochen, in der selbst die schwierigsten Aufgaben in wenigen Augenblicken erledigt werden, da die Berechnungen auf alle Computer der Welt verteilt werden.
In der Praxis kam es auf Rechenzentren an, die auf der ganzen Welt verstreut waren und den Verbrauchern ihre Rechenleistung zur Verfügung stellten. Das ursprüngliche Konzept war nur die Verteilung zwischen den Maschinen innerhalb des Rechenzentrums und zwischen den Rechenzentren selbst (meistens innerhalb derselben Region).
Basierend auf dem Vorstehenden können wir davon ausgehen, dass Sie das Wort "Cloud" als vertrauteres "Hosting" wahrnehmen können, mit dem einzigen Unterschied, dass die Leistung der Cloud ohne zusätzlichen Aufwand von Ihrer Seite erweitert werden kann.
Die zweite Frage, die Sie möglicherweise haben, ist, warum Azure? "Da dies ein Artikel im Microsoft-Blog ist, wird der Autor nur über seine Produkte sprechen" - Sie sagen, und Sie werden sich irren. Die Motive für die Verwendung von Azure sind weitaus häufiger anzutreffen. Da es sich um ein Microsoft-Produkt handelt, ist die Integration mit den anderen Produkten, mit deren Hilfe meine Anwendung entwickelt wird, höchstmöglich.
Ich stelle jedoch fest, dass das Unternehmen alle Anstrengungen unternimmt, um die Verwendung von Azure für Entwickler für Android oder iOS attraktiv zu machen. Nun, das zuletzt erwähnte, aber nicht das geringste Problem sind die Kosten für die Nutzung der Cloud. Da ich Inhaber eines BizSpark-Abonnements bin, wurde mir ein monatliches Darlehen für eine Tasche gewährt, deren Zinsen mehr sind als die Deckung meiner Cloud-Anforderungen. Die Bedingungen, die kostenlos zur Verfügung gestellt werden, können jedoch auch die meisten Anforderungen eines privaten Entwicklers abdecken.
Fahren wir nun mit der direkten Auswahl eines Synchronisations- und Datenspeicherungsmechanismus fort. Ich werde nicht schlau sein, als Autodidakt muss ich mich oft mit Technologien auseinandersetzen, von denen ich keine Ahnung habe, bevor ich UWP kennen gelernt habe. Ich habe ähnliche Probleme mithilfe von SQL-Datenbanken gelöst.
UWP verfügt jedoch nicht über die Mittel, um mit klassischen SQL-DBMS zu arbeiten, aber SQLite wird als Alternative angeboten. Nachdem ich mit der Studie begonnen hatte, stellte ich fest, dass eine solche Datenbank integriert ist, die für die bequeme Speicherung und Verwendung lokaler Daten geeignet ist, für die Datenplatzierung jedoch völlig ungeeignet ist im Remote-Speicher. Bereits beim Schreiben dieses Artikels, als die erforderliche Technologie ausgewählt wurde, stieß ich auf eine der Azure-Lösungen im Bereich der Entwicklung mobiler Anwendungen, mit denen Sie Daten aus der SQLite-Tabelle zwischen Geräten synchronisieren können. Nach sorgfältiger Überlegung blieb ich jedoch bei der ersten Wahl.
Übrigens war es nicht schwierig, die erste Wahl zu treffen, da Microsoft höflich eine Liste von Technologien erstellt hat, mit denen sich der UWP-Entwickler wahrscheinlich auseinandersetzen müsste. In den neuesten Versionen von Visual Studio wird beim Erstellen eines neuen UWP-Projekts eine Seite mit Empfehlungen für den Einstieg angezeigt, auf der einer der Links "Hinzufügen eines empfohlenen Dienstes" lautet. Wenn Sie auf diesen Link klicken, wird die Registerkarte "Dienst verbinden" geöffnet. Bereits darin wird die Option "Cloud-Speicher mit Azure-Speicherdienst" angezeigt.
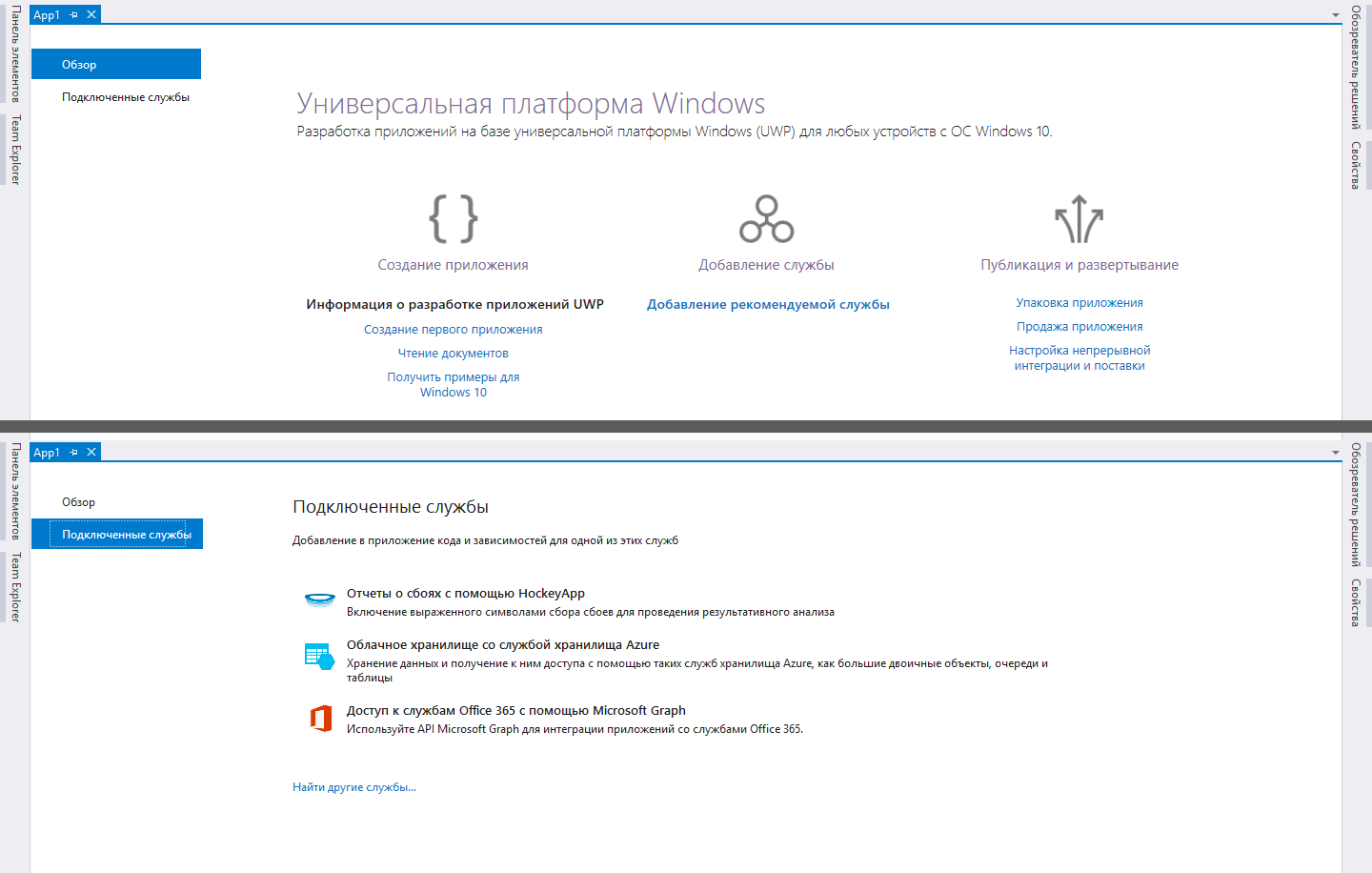
Die Intuition legt nahe, dass dies genau das ist, was Sie brauchen. Ich habe mich daher entschlossen, mich auf eine eingehende Untersuchung dieses Themas zu konzentrieren, um es im Projekt weiter zu verwenden.
Cloud-Speicher besteht aus mehreren Produkten für verschiedene Aufgaben, über die
hier mehr gelesen
werden kann. Ich interessierte mich jedoch hauptsächlich für den Tabellenspeicher, der sich als NoSQL-Datenbank herausstellte.
NoSQL ist eine schemafreie Datenbank, in der die Tabelle nicht im Voraus strukturiert werden muss. Tatsächlich ist die Tabelle in diesem Fall nur ein Teil des Pfads zum sogenannten Abschnitt. Dies bedeutet, dass eine einzelne Tabelle Zeilen mit beispielsweise drei und fünf Spalten gleichzeitig enthalten kann. Um die Funktionen des Tabellenspeichers vollständig zu verstehen, empfehle ich Ihnen, das
Handbuch sorgfältig zu lesen, aber ich werde dieses Thema aus meiner alltäglichen Sicht betrachten, da sich das Material letztendlich an Anfänger richtet, die ich in diesem Thema bin.
Lassen Sie uns zunächst herausfinden, wie eine NoSQL-Tabelle erstellt wird:1. Registrieren Sie ein
kostenloses Azure-Konto. Wenn Sie ein MSDN- oder BizSpark-Abonnement haben und es bereits in Azure aktiviert ist, können Sie diesen Schritt überspringen. Mit einem kostenlosen Konto erhalten Sie für den ersten Monat ein Darlehen von 200 USD und anschließend freien Zugriff auf eine bestimmte Menge an Ressourcen der meisten Azure-Dienste. In eine verständliche Sprache übersetzt, wird alles so ausgeführt, dass Sie erst bezahlen müssen, wenn Ihr Produkt genug verdient, um die Kosten zu decken, ganz zu schweigen von der Verwendung von Azure für die Selbstbildung.
Aber selbst wenn Sie den freien Schwellenwert überschreiten, sind die Preise für einen Tabellenspeicher viel loyaler als für eine ähnliche Menge von SQL-Datenbanken. Zum Zeitpunkt des Schreibens dieses Artikels habe ich beispielsweise zwei Tabellen mit bisher nur einem Eintrag erstellt. Während 18 Tagen des Berichtszeitraums habe ich mich durchschnittlich 20 bis 30 Mal am Tag an sie gewandt, und für diesen Zeitraum wurden 2 Kopeken vom Guthabenkonto abgeschrieben. Als ich diese Kosten für das geplante Volumen hochskalierte, stellte ich fest, dass sie mehr als durch die potenziellen Einnahmen aus dem Antrag gedeckt sind.
2. Nachdem Sie ein Konto in Azure haben, erstellen wir ein Speicherkonto.
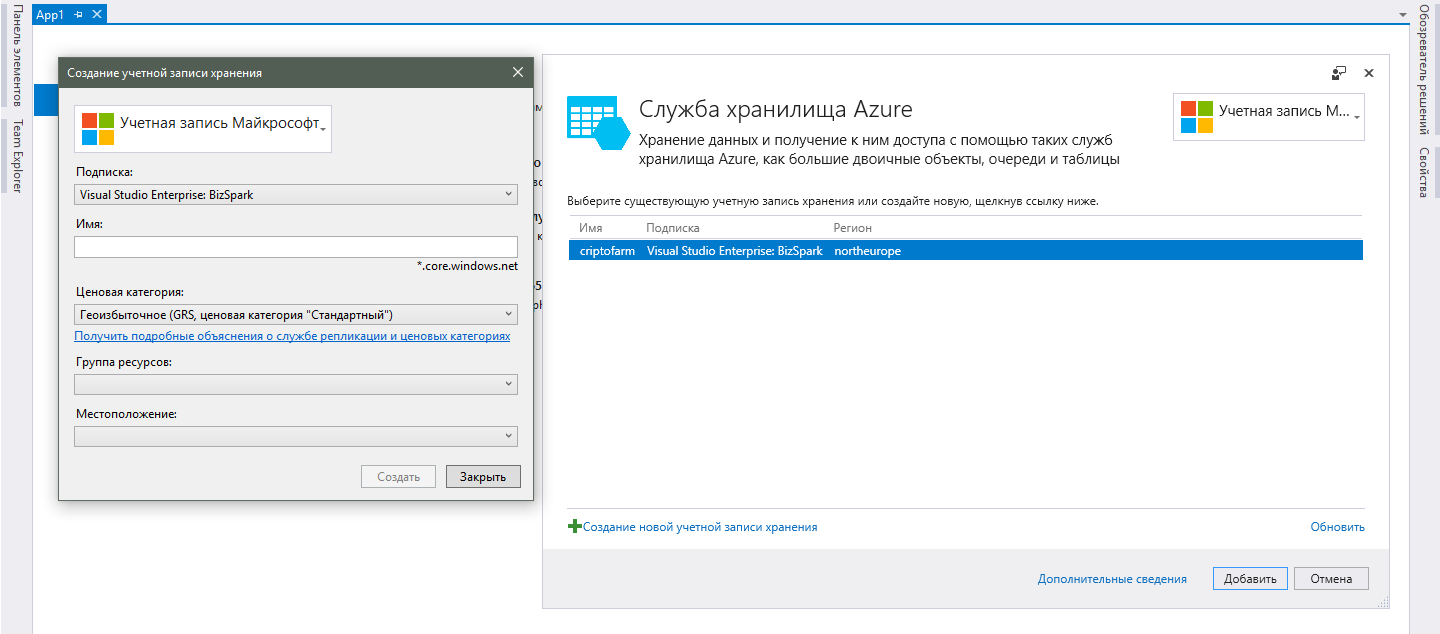
Sie können dies alles auf derselben Visual Studio Services-Verbindungsseite tun, die ich oben beschrieben habe. Wenn Sie diese Seite plötzlich geschlossen haben, können Sie sie öffnen, indem Sie im Projektmappen-Explorer auf „Verbundene Dienste“ doppelklicken. Nach Auswahl des gewünschten Dienstes wird ein Fenster mit den verfügbaren Speicherkonten geöffnet. Um ein neues hinzuzufügen, klicken Sie auf die entsprechende Schaltfläche.
Im neuen Fenster müssen Sie die folgenden Schritte ausführen:- Um zu beginnen, müssen Sie sich mit Ihrem Microsoft-Konto anmelden. Sie müssen das Konto verwenden, an das Ihre Abonnements gebunden sind, oder ein kostenloses Azure-Konto.
- Nachdem Sie sich in Ihrem Konto angemeldet haben, wird Ihr Abonnement (a) im Feld "Abonnement" angezeigt. Bei der Auswahl ist alles einfach, daher sind Kommentare überflüssig.
- Geben Sie im Feld "Name" den gewünschten Namen des Speicherdienstes an. Da dies auch der Domänenname des Dienstes ist, muss er in allen in Azure verfügbaren Konten eindeutig sein und nicht nur in Ihren eigenen.
- Im Feld "Preiskategorie" müssen Sie die Unterschiede zwischen einer Cloud-Plattform und herkömmlichem Hosting verstehen, da Sie durch Klicken auf den Link unter dem Feld eine Preisliste sehen, jedoch keine verständliche Erklärung, die Ihnen jede Option bietet. In der Wildnis der Sitelinks finden Sie natürlich umfassende Informationen zu all diesen Abkürzungen wie GRS und LRS, aber dies ist für den durchschnittlichen Entwickler überflüssig. Es genügt zu verstehen, dass je teurer der Tarif ist, desto mehr Rechenzentren an der Verarbeitung und Speicherung Ihrer Daten beteiligt sind und desto höher ist die Wahrscheinlichkeit ihrer Sicherheit. Für ein kleines Projekt ist die niedrigste LRS-Rate in Ordnung.
- Eine „Ressourcengruppe“ ist eine Kombination mehrerer Azure-Dienste für eine einzelne Verwaltung. In unserem Fall erstellen Sie einen neuen, weisen Sie einen beliebigen Anzeigenamen zu und fahren Sie fort.
- Als letztes müssen Sie den „Standort“ für Ihren Service auswählen. Mit Standort ist der tatsächliche Standort der Rechenzentren gemeint, die für die Arbeit mit unseren Daten verantwortlich sind. Bitte beachten Sie, dass ich im Plural spreche, da es in einer Region mehrere Rechenzentren geben kann und die Arbeit auf diese verteilt werden kann (falls Sie eine beratende Preiskategorie wählen). Wählen Sie diejenige aus, die Ihrer primären Benutzerbasis am nächsten liegt. Wenn Sie jedoch vorhaben, auf der ganzen Welt zu wachsen, und überall auf der Welt maximale Reaktion benötigen, stört Sie niemand für jede regionale Version der Anwendung, ein separates Speicherkonto zu erstellen und die Datensynchronisation zwischen ihnen zu implementieren. Ein hohes Maß an Erweiterbarkeit ist der Hauptvorteil der Cloud.
3. Nachdem Sie das Speicherkonto erstellt haben, wird es der Liste hinzugefügt. Sie können fortfahren, indem Sie auf die Schaltfläche "Hinzufügen" klicken. Das Ergebnis dieser Aktion ist das Hinzufügen eines NuGet-Pakets für die Arbeit mit Azure zum Projekt und das Speichern der Verbindungszeichenfolge in der Datei app.config des Projekts.
Leider ist es nicht möglich, mit Werten aus dieser Datei in UWP (oder möglicherweise mit schrecklichen Krücken) zu arbeiten. Kopieren Sie daher einfach die Verbindungszeichenfolge zum Speicherdienst von dort an eine geeignete Stelle im Projekt und fahren Sie mit dem nächsten Schritt fort.
4. Nun bleibt es, eine Tabelle zu erstellen und damit zu arbeiten. Und hier beginnt die individuelle Arbeit, abhängig von den Aufgaben.
Tatsache ist, dass Sie vor dem Erstellen von Tabellen sorgfältig über die Architektur zum Speichern Ihrer Daten nachdenken sollten. Das Arbeiten mit dem Tabellenspeicher ist so bequem, dass das Erstellen einer neuen Tabelle direkt aus dem Code nur wenige Zeilen umfasst. Mit dieser Bequemlichkeit besteht natürlich der Wunsch, jedem Benutzer eine separate Tabelle zuzuweisen, da die ultimative Aufgabe darin besteht, Daten zwischen seinen Geräten zu synchronisieren. Wenn Sie jedoch mit einer unbekannten Technologie arbeiten, sollten Sie keine voreiligen Entscheidungen treffen und die Vor- und Nachteile sorgfältig abwägen. Ein spezieller
Artikel im Handbuch kann
Ihnen dabei helfen, die richtige Entscheidung zu treffen. Machen Sie sich jedoch bereit, ihn mehrmals neu zu lesen, da es sehr schwierig ist, alle Daten sofort zu lernen, insbesondere unter Berücksichtigung der Masse neuer Begriffe.
Ich werde die Geschichte unter Berücksichtigung der Tatsache fortsetzen, dass Sie das Handbuch noch gelesen und einige der Funktionen der Arbeit mit der Tischspeicherung verstanden haben. Zum Beispiel wurde mir klar, dass eine Tabelle konzeptionell keine isolierte Einheit ist, sondern vielmehr ein Ort für eine logische Gruppierung von Datensätzen. Dies ist leicht zu verstehen, wenn Sie die Tabelle als Ordner präsentieren, in dem Sie Datendateien speichern. Ein Ordner selbst nimmt keinen Speicherplatz ein und ist kein integraler Bestandteil von Dateien, sondern definiert lediglich einen Teil des Pfads zu Dateien, die logisch, aber nicht erforderlich sind, um in diesem Ordner gespeichert zu werden.
Die Schlussfolgerung daraus ist recht einfach: Niemand stört sich daran, die Einstellungen aller Benutzer in einer Tabelle zu speichern. Hauptsache, das Wertepaar in den Spalten PartitionKey und RowKey ist in der Tabelle eindeutig. Dies wird in meinem Projekt erneut implementiert, da die Benutzer-ID als PartitionKey fungiert und beispielsweise die Zeichenfolge "UserName" als RowKey, mit der wir den eindeutigen Datensatz bestimmen können, in dem der Benutzername gespeichert ist. Aber wie ich oben sagte, müssen wir alle Vor- und Nachteile abwägen, also lasst uns abwägen:
- "Für" eine separate Tabelle für die Daten jedes Benutzers ist die Bequemlichkeit bei der Wahrnehmung der Datenstruktur. Wenn wir die Tabelle als Ordner mit Dateien betrachten, ist es logisch, dass sich alle Dateien eines Benutzers im selben Ordner befinden, und es ist üblicher, mit einer solchen Architektur zu arbeiten.
- Alle anderen Faktoren sprechen gegen eine separate Tabelle. Benutzerdaten in einer separaten Tabelle - dies ist praktisch genau, bis die Anzahl solcher Tabellen in Tausenden liegt. Da sich das Speicherkonto auf einer höheren Ebene über der Tabelle befindet, wird für sie keine andere Gruppierung bereitgestellt.
Angesichts der potenziellen Benutzerbasis besteht die Gefahr, dass wir in Tausenden von einzelnen Tabellen ertrinken und diejenigen verlieren, die einen Prioritätswert haben. Gleichzeitig vereinfacht das Speichern der Einstellungen aller Benutzer in einer Tabelle die Verwaltung und das Arbeiten mit Daten, um statistische Informationen zu sammeln oder soziale Funktionen zu implementieren.
Darüber hinaus können Sie aufgrund der geringen Kosten für die Verwendung des Tabellenspeichers alle Daten gemäß der erforderlichen Logik in separaten Tabellen duplizieren. Insbesondere plane ich, eine zusätzliche Tabelle mit dem Benutzernamen, einem Link zum Avatar und einem Hinweis auf die Zugehörigkeit zum Land zu erstellen, die für Bewertungstabellen oder andere soziale Funktionen verwendet wird, die der Anwendung hinzugefügt werden können.
Wenn Sie also die Datenspeicherstruktur herausgefunden haben, fügen wir endlich eine neue Tabelle hinzu. Da wir uns geweigert haben, es auf Codeebene zu erstellen, bleiben zwei Optionen: über das Azure-Webportal oder über das spezielle Microsoft Azure Storage Explorer-Tool, das von storageexplorer.com heruntergeladen werden kann. In beiden Fällen muss das gewünschte Speicherkonto ausgewählt und im Abschnitt "Tables / Tables Service" die Option "+ Table / Create Table" ausgewählt werden. Geben Sie im angezeigten Dialogfeld den gewünschten Namen ein und übernehmen Sie die Änderungen.
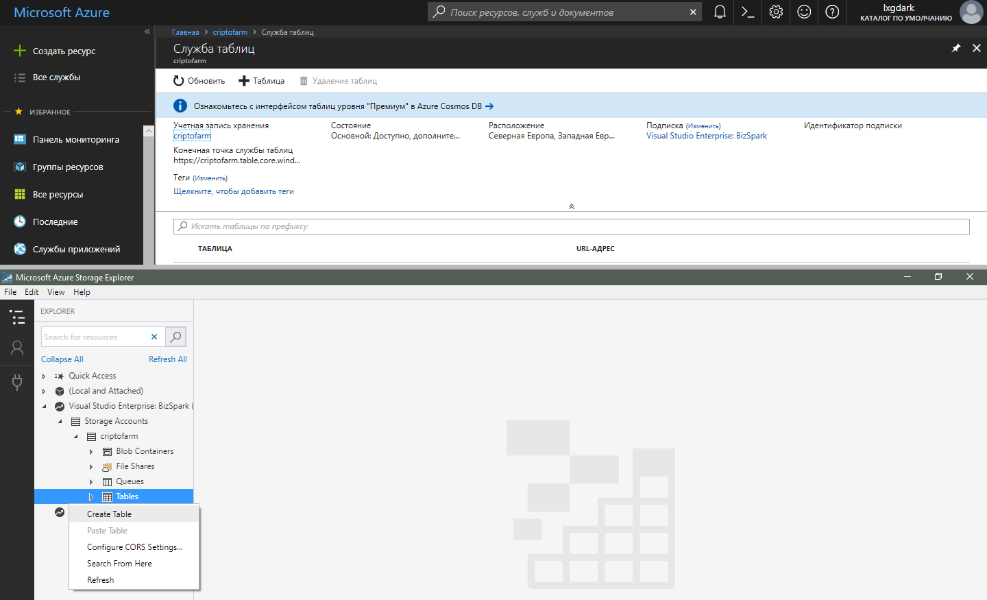
Danach können Sie problemlos mit der neuen Tabelle aus dem Code arbeiten.
Die Hauptoperationen, die ich mit der Tabelle ausführen werde, sind das Einfügen und Extrahieren von Zeilen, die in der Tabellenspeicherterminologie als "Entitäten" bezeichnet werden. Ein solcher Begriff ist leichter zu verstehen, wenn Sie feststellen, dass Sie zum Einfügen und Abrufen einer Entität eine Klasse zuordnen müssen, die von TableEntity von Microsoft.WindowsAzure.Storage.Table geerbt wurde. Die Nachfolgerklasse enthält bereits einige erforderliche Felder, z. B. PartitionKey (Abschnittsname) und RowKey (Zeilenname). Die Felder, die wir unabhängig voneinander implementieren, sind Spalten in der Zeile (Entitätseigenschaften).
Stellen Sie sich ein Beispiel für eine Tabelle vor, in der eine Liste aller Spieler mit Namen, Avatar und Länderzugehörigkeit gespeichert wird.
: Imports Microsoft.WindowsAzure.Storage Imports Microsoft.WindowsAzure.Storage.Table
Ich habe mich entschlossen, die Methoden für die Arbeit mit der Tabelle in eine separate Klasse einzuteilen, um das Arbeiten an verschiedenen Stellen der Anwendung zu vereinfachen. Erstellen Sie es und fügen Sie sofort die zuvor bekannten Konstanten hinzu:
Public Class AzureWorker Private Const AzureStorageConnectionString As String = " , app.config" Private Const GamerListTableNameString As String = "GamerList" ' … End Class
Jetzt müssen wir eine Klasse erstellen, die wir der Entität (Zeile) in der Tabelle zuordnen:
Private Class GamerListClodTableDataClass Inherits TableEntity Public Const RowKeyValue As String = "UserID" Public Sub New () RowKey = RowKeyValue End Sub Public Property UserName As String = "" Public Property UserountryID As String = "" Public Property UserAvatar As String = "" End Class
Die zuzuordnende Klasse muss von TableEntity geerbt sein und Felder für die Daten enthalten, die in die Tabelle eingefügt werden sollen. Beachten Sie, dass das Festlegen von Werten für einen RowKey oder PartitionKey auf Klassenebene nicht erforderlich ist. In meinem Fall wird der RowKey jedoch festgelegt, da er unabhängig von anderen Eingaben unveränderlich ist.
Da Sie zu diesem Zeitpunkt wahrscheinlich die Essenz der Arbeit mit dem Tabellenspeicher nicht vollständig verstanden haben, werde ich die in dieser Phase festgelegte Logik erläutern. Der schnellste Weg, mit einer Tabelle zu arbeiten, besteht darin, die Entität nach dem Namen der Zeichenfolge und dem Abschnittsnamen abzufragen. Daher müssen Sie diese Daten im Voraus kennen. Darüber hinaus muss die Kombination von PartitionKey und RowKey innerhalb der Tabelle eindeutig sein. Dies bedeutet, dass es logisch ist, eine eindeutige Benutzer-ID in einen dieser Schlüssel zu schreiben und dem zweiten Schlüssel einen Namen zuzuweisen, den wir immer kennen. Genau dies wird in der GamerListClodTableDataClass-Klasse ausgeführt.
Die letzte vorbereitende Phase vor direkten Abfragen an die Tabelle ist die Erstellung des Objekts in einer separaten Funktion:
Private Shared Function GetCloudTable(tableName As String) As CloudTable Dim storageAccount As CloudStorageAccount = CloudStorageAccount.Parse(AzureStorageConnectionString) Dim tableClient As CloudTableClient = storageAccount.CreateCloudTableClient() Dim table As CloudTable = tableClient.GetTableReference(tableName) Return table End Function
Dies geschieht, um den Code nicht jedes Mal zu duplizieren, wenn wir Daten in die Tabelle lesen oder schreiben möchten. Bitte beachten Sie, dass dieser Code keine direkten Anforderungen an die Cloud stellt und ohne Probleme ausgeführt wird, wenn keine Verbindung besteht. Er erstellt lediglich Schritt für Schritt ein Tabellenobjekt aus vorhandenen Daten, z. B. der Speicherverbindungszeichenfolge und dem Tabellennamen.
Lassen Sie uns abschließend direkt mit der Tabelle arbeiten und zunächst die aktuellen Benutzerdaten speichern:
Public Shared Async Function SavedOrUpdateUserData(u As UserManager) As Task(Of Boolean) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim UserDataClodTableData As New GamerListClodTableDataClass With {.PartitionKey = u.UserId, .UserName = u.UserName.Trim, .UserountryID = u.UserountryID, .UserAvatar = "https://apis.live.net/v5.0/" & u.UserId & "/picture"} Dim insertOperation As TableOperation = TableOperation.InsertOrReplace(UserDataClodTableData) Await table.ExecuteAsync(insertOperation) Return True End If Catch ex As Exception End Try Return False End Function
Die Anforderung wird als asynchrone Funktion gestellt, damit der aufrufende Code das Ergebnis der Ausführung erhalten kann (True bei Erfolg und False bei Fehler). Außerdem wird ein Parameter vom Typ UserManager an die Funktion übergeben, die auf die Klasse mit Benutzerdaten verweist. Wir haben eine solche Klasse in einem früheren Artikel erstellt. Der einzige Unterschied besteht darin, dass in dieser Version ein Feld UserountryID vorhanden ist, in dem Daten zum Land des Benutzers gespeichert werden.
Bei Abfragen an die Tabelle müssen Sie zuerst das Objekt mithilfe der Verbindungszeichenfolge zum Repository und des Tabellennamens erstellen (wir haben diesen Prozess zuvor in eine separate Funktion gestellt). Als Nächstes sollten Sie die Existenz der Tabelle überprüfen. Obwohl wir sicher sind, dass wir eine Tabelle mit diesem Namen haben, kann ein Fehler auftreten, z. B. aufgrund mangelnder Netzwerkverbindung oder aufgrund eines Fehlers in der Cloud (weshalb dieser Code im Try / Block abgelegt wird Fang). Bevor Sie in die Tabelle schreiben, müssen Sie eine Instanz der UserDataClodTableData-Klasse erstellen, den Feldern den erforderlichen Wert zuweisen und erst dann die InsertOrReplace-Operation erstellen. Wie Sie dem Namen der Operation entnehmen können, wird eine neue Zeile in die Tabelle eingefügt, wenn Zeilen mit demselben PartitionKey- und RowKey-Paar nicht in der Tabelle vorhanden sind, und die Daten ersetzt, wenn eine solche Zeile bereits vorhanden ist. Nun, das endgültige ExecuteAsync-Team wird tatsächlich die geplante Aktion auf der Tischspeicherseite ausführen.
Das Lesen von Daten aus einer Tabelle ist so einfach wie das Schreiben. Fordern wir zum Beispiel einen Benutzernamen an:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim retrieveOperation As TableOperation = TableOperation.Retrieve(Of GamerListClodTableDataClass)(id, GamerListClodTableDataClass.RowKeyValue) Dim retrievedResult As TableResult = Await table.ExecuteAsync(retrieveOperation) If retrievedResult.Result IsNot Nothing Then Return CType(retrievedResult.Result, GamerListClodTableDataClass).UserName End If End If Catch ex As Exception End Try Return "" End Function
Dieser Code unterscheidet sich fast nicht vom vorherigen und beginnt auch damit, ein Tabellenobjekt zu erstellen und seine Existenz zu überprüfen. Außerdem erstellen wir wie bei der Aufzeichnung eine Operation, diesmal jedoch eine Extraktionsoperation, für die die Angabe von PartitionKey und RowKey erforderlich ist. Danach extrahieren wir das Ergebnis mit ExecuteAsync und arbeiten mit dem resultierenden Objekt vom Typ TableResult. Dabei wird die Result-Eigenschaft in den Typ der zugeordneten Klasse umgewandelt und der Benutzername extrahiert.
Das Arbeiten mit einer Tabelle ist nicht auf Lese- und Schreibvorgänge beschränkt und unterstützt viele verschiedene Skripte. Sie können beispielsweise eine Abfrage erstellen, mit der alle Entitäten mit dem angegebenen PartitionKey oder alle Entitäten mit dem angegebenen Feld extrahiert werden. Es ist jedoch wichtig, die Geschwindigkeit solcher Vorgänge sowie die Datenmenge zu berücksichtigen, die über das Netzwerk übertragen wird.
Das obige Beispiel ist unter dem Gesichtspunkt der Abfragegeschwindigkeit am optimalsten, da das Adressierungssystem höchstwahrscheinlich eine Entität entlang des Pfads "Speichername \ Tabellenname \ PartitionKey + RowKey" findet. Um jedoch nur einen Namen zu erhalten, laden wir die gesamte Entität als Ganzes, was nicht vorteilhaft ist auf die Menge der übertragenen Daten.
Das Folgende ist ein modifizierter Funktionscode, der die maximale Abfrageoptimierung berücksichtigt:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim projectionQuery As TableQuery(Of DynamicTableEntity) = New TableQuery(Of DynamicTableEntity)().Where(TableQuery.CombineFilters(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, id), "and", TableQuery.GenerateFilterCondition("RowKey", QueryComparisons.Equal, GamerListClodTableDataClass.RowKeyValue))).Select({"UserName"}) Dim resolver As EntityResolver(Of String) = Function(pk, rk, ts, props, etag) Return props("UserName").StringValue End Function Dim result As TableQuerySegment(Of String) = Await table.ExecuteQuerySegmentedAsync(projectionQuery, resolver, Nothing) If result.Count > 0 Then Return result(0) End If End If Catch ex As Exception End Try Return "" End Function
Anstatt ein Operationsobjekt zu erstellen, erstellen wir in diesem Code ein Anforderungsobjekt, das verschiedene Methoden enthält, um zu bestimmen, was als Ergebnis abgerufen werden muss. Die Where-Methode erstellt einen Filter, der angibt, dass nur die Zeilen zurückgegeben werden müssen, für die PartitionKey und RowKey den angegebenen Werten entsprechen, und die nächste Auswahl gibt an, dass nur die Spalte Benutzername ausgewählt werden muss.
Bei einer solchen Abfrage ist es nicht sinnvoll, das Ergebnis mit einer Klasse zu vergleichen. Daher wird das IDictionary als Rückgabewert verwendet, wobei der Schlüssel der Name der Spalte und der Wert der Inhalt ist. Da die Funktion ExecuteQuerySegmentedAsync nicht weiß, welches Ergebnis ihrer Ausführung erhalten wird, ist es möglich (und in diesem Fall erforderlich), einen EntityResolver-Delegaten zu übergeben, der auf eine Funktion verweist, die den gewünschten Wert aus dem Wörterbuch übernimmt. Das Ergebnis all dessen wird TableQuerySegment, in dessen erstem Index der Name des angeforderten Benutzers gespeichert ist.
Im Allgemeinen können Sie durch die Verwendung von Abfragen anstelle der grundlegenden Extraktionsoperation die Möglichkeiten der Arbeit mit einer Tabelle erheblich erweitern. Seien Sie jedoch vorsichtig, da hier im Gegensatz zu klassischem SQL die Geschwindigkeit der Abfrageverarbeitung direkt von den Parametern abhängt. Niemand stört Sie daran, eine Abfrage auszuführen, um alle Benutzerdatensätze abzurufen, deren Namen dem angegebenen entsprechen. Eine solche Abfrage ist jedoch länger als das Gegenstück in SQL. Um dies zu lernen,
verweise ich Sie noch einmal auf den oben erwähnten Leitfaden zum Tischdesign. Außerdem empfehle ich Ihnen, den
Artikel zu lesen , der Beispiele für die Arbeit mit der Tabellenspeicherung enthält.
Wichtig! Die Linkartikel verwenden Code für klassische .NET-Anwendungen und unterscheiden sich von der UWP-Implementierung. Glücklicherweise ist dieser Unterschied nicht signifikant und die Analoga sind intuitiv (meistens liegen die Unterschiede im Async-Präfix).Abschließend werde ich die Ergebnisse der Verwendung des Azure-Speichers in meinem Projekt im Moment mitteilen. Beim ersten Start, nachdem ich die Benutzer-ID erhalten und Daten von der Live-ID heruntergeladen habe, schlage ich vor, dass er einen Alias (Spitznamen) wählt, falls der im Profil gespeicherte Name nicht zu ihm passt. Anschließend wird der eingegebene Kurzname in der UserManager-Klasse anstelle der Standardklasse gespeichert, und alle diese Daten werden in der GamerList-Tabelle gespeichert. Beim nächsten Start wird die Benutzer-ID im Hintergrund empfangen und ein Alias vom Geschäft angefordert. Infolgedessen sieht der Benutzer seinen Spitznamen im Spiel und nicht den Namen aus dem Standardprofil.
Auch in Zukunft wird eine Tabelle mit einer Liste von Benutzern nützlich sein, um soziale Funktionen in das Spiel einzugeben, und jetzt habe ich mindestens eine Anwendung für diese Daten entwickelt. Bei der Implementierung dieser Aufgabe helfen mir Azure-Tools wie Warteschlangenspeicher und Azure-Funktionen erneut, aber ich werde in einem der folgenden Artikel darauf eingehen.