Zu sagen, was Caches sind, was Ergebnis-Cache ist, wie es in Oracle und in anderen Datenbanken erstellt wird, ist nicht sehr interessant und hübsch. Aber bei bestimmten Beispielen nimmt alles ganz andere Farben an.
Alexander Tokarev (
shtock ) hat seinen Bericht über Highload ++ 2017 basierend auf Fällen erstellt. Und genau auf der Grundlage von Fällen sagte er mir, wann ein selbst erstellter Cache praktisch sein könnte, was der serverseitige Ergebniscache schmerzt und wie er durch einen clientseitigen ersetzt werden kann, und im Allgemeinen habe ich eine Reihe nützlicher Tipps zum Einrichten des Ergebniscaches in Oracle angesprochen.
Über den Redner: Alexander Tokarev arbeitet bei DataArt und befasst sich mit Fragen im Zusammenhang mit Datenbanken, sowohl im Hinblick auf das Erstellen von Systemen von Grund auf als auch auf die Optimierung bestehender Systeme.
Beginnen wir mit ein paar rhetorischen Fragen. Haben Sie mit Oracle Result Cache gearbeitet? Glauben Sie, dass Oracle eine Datenbank ist, die für alle Gelegenheiten geeignet ist? Nach Alexanders Erfahrung verneinen die meisten Menschen die letzte Frage,
einhundert Träumer haben einen Träumer . Aber dank seines Glaubens bewegt sich der Fortschritt.
Übrigens hat Oracle bereits 14 Datenbanken - bisher 14 - was in Zukunft passieren wird, ist unbekannt.
Wie bereits erwähnt, werden alle Probleme und Lösungen in bestimmten Fällen dargestellt. Dies sind zwei Fälle aus DataArt-Projekten und ein Beispiel eines Drittanbieters.
Datenbank-Caches
Zunächst, welche Caches sich in den Datenbanken befinden. Hier ist alles klar:
- Puffercache - Datencache - Cache für Datenseiten / Datenblöcke;
- Anweisungscache - Cache von Anweisungen und ihren Plänen - Cache von Abfrageplan;
- Ergebnis-Cache - Cache der Zeilenergebnisse - Zeilen aus Abfragen;
- Betriebssystem-Cache - Betriebssystem-Cache.
Darüber hinaus wird der Ergebnis-Cache im Großen und Ganzen nur in Oracle verwendet. Er war einmal in MySQL, aber dann wurde er heldenhaft herausgeschnitten. In PostgreSQL ist es auch nicht vorhanden, es ist in der einen oder anderen Form nur im pgpool-Produkt eines Drittanbieters vorhanden.
Fall 1. Händlergewölbe
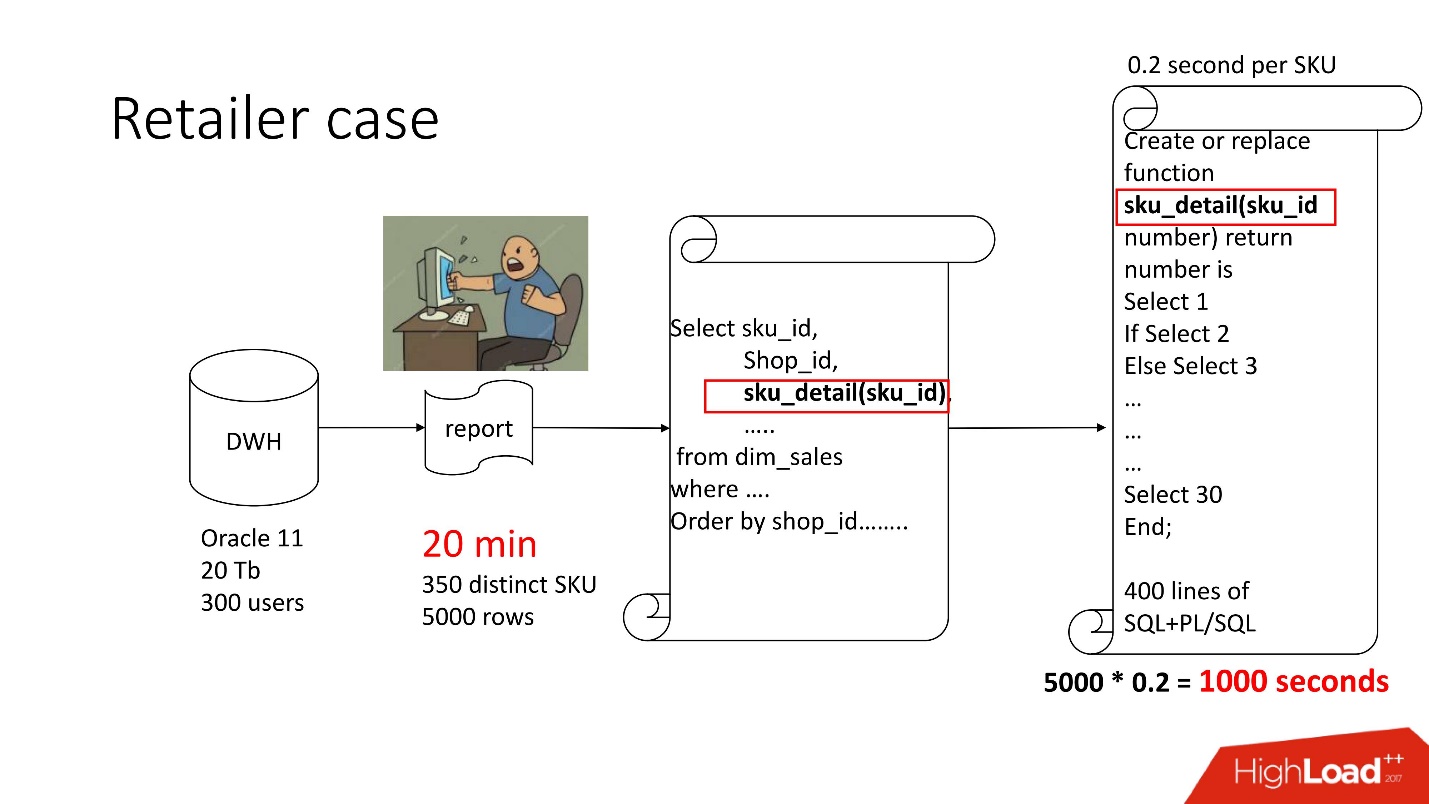
Oben sehen Sie das Produktdiagramm, das wir begleitet haben - das Repository (Oracle 11, 20 TB, 300 Benutzer), und es enthält eine Art trostlosen Bericht, in dem 350 eindeutige Produkte pro 5000 Datenzeilen enthalten waren. Es dauerte ungefähr 20 Minuten, und die Benutzer waren traurig.
Die Präsentation dieses Berichts ist wie alle anderen auf der Highload ++ - Konferenzseite verfügbar.
Dieser Bericht enthält SELECT, JOINs und eine Funktion. Eine Funktion als Funktion, alles wäre in Ordnung, nur berechnet sie einen mysteriösen Parameter namens "Verrechnungspreiswert", es funktioniert für 0,2 s - es scheint nichts zu sein, aber es wird so oft aufgerufen, wie es Zeilen in der Tabelle gibt. Diese Funktion hat seitdem 400 Zeilen SQL + PL / SQL Das Produkt wird unterstützt. Es ist beängstigend, es zu ändern.
Aus dem gleichen Grund konnte result_cache nicht verwendet werden.
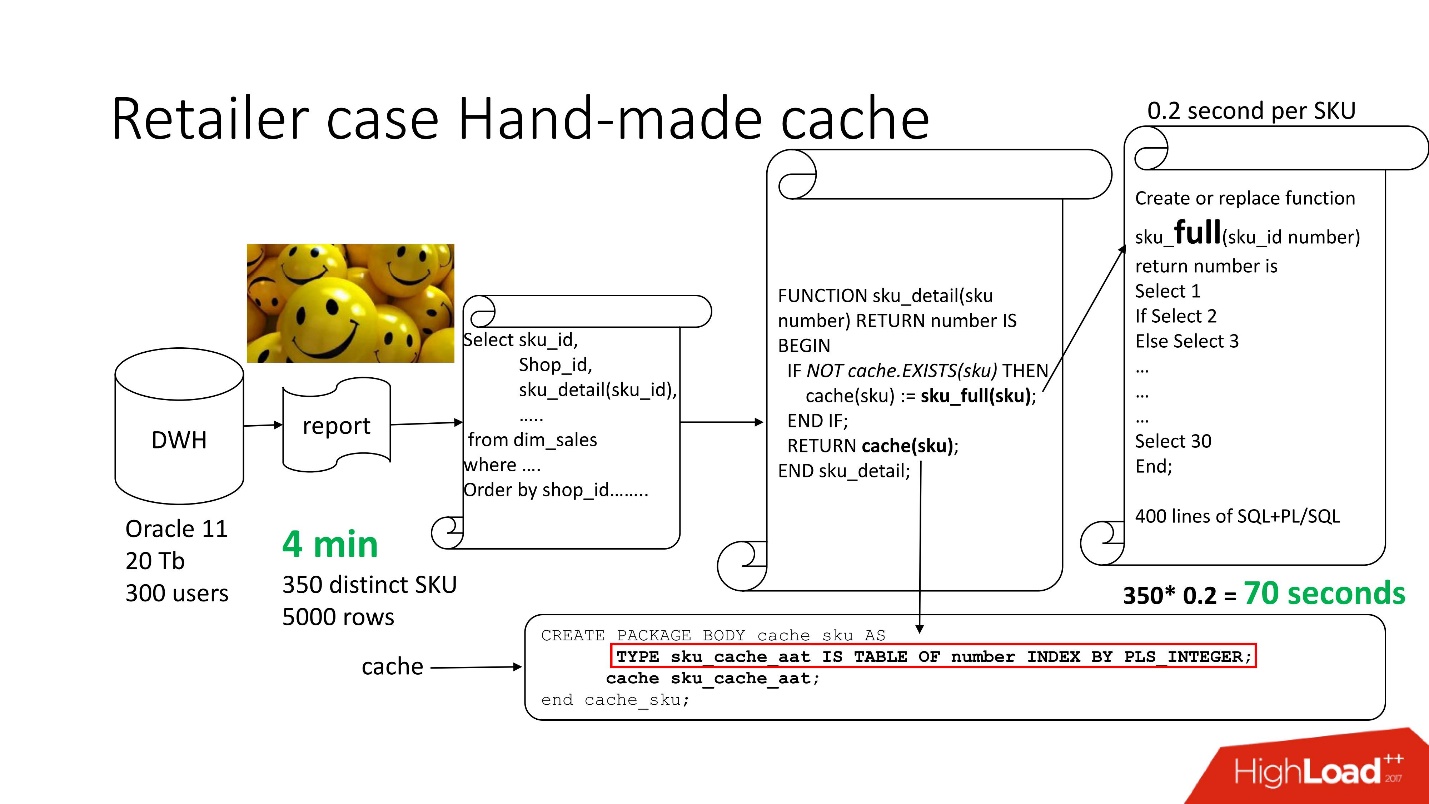
Um das Problem zu lösen, verwenden wir den Standardansatz
mit handgemachtem Caching : Wir belassen die ersten 3 Blöcke der Schaltung so wie sie waren, benennen einfach unsere Funktion sku_detail () in sku_full () um und deklarieren ein assoziatives Array, wobei:
- Schlüssel sind unsere SKUs (Commodity Items),
- Die Werte sind der berechnete Transferumwandlungspreis.
Wir machen die Cache-Funktion (sku) offensichtlich: Wenn unser assoziatives Array keine solche ID enthält, wird unsere Funktion gestartet, das Ergebnis zwischengespeichert, gespeichert und zurückgegeben. Wenn dementsprechend eine solche ID vorliegt, geschieht dies alles nicht. Tatsächlich haben wir einen
On-Demand-Cache erhalten .
Daher haben wir die Anzahl der Funktionsaufrufe auf den tatsächlich benötigten Betrag reduziert.
Die Bearbeitungszeit für Berichte verringerte sich auf 4 Minuten . Alle Benutzer fühlten sich gut.
Handgemachter Cache-Speicher
Die Nachteile und Vorteile dieses Systems werden aus diesem großen intelligenten Bild deutlich, auf das wir viel eingehen werden - dies ist die Speicherarchitektur.
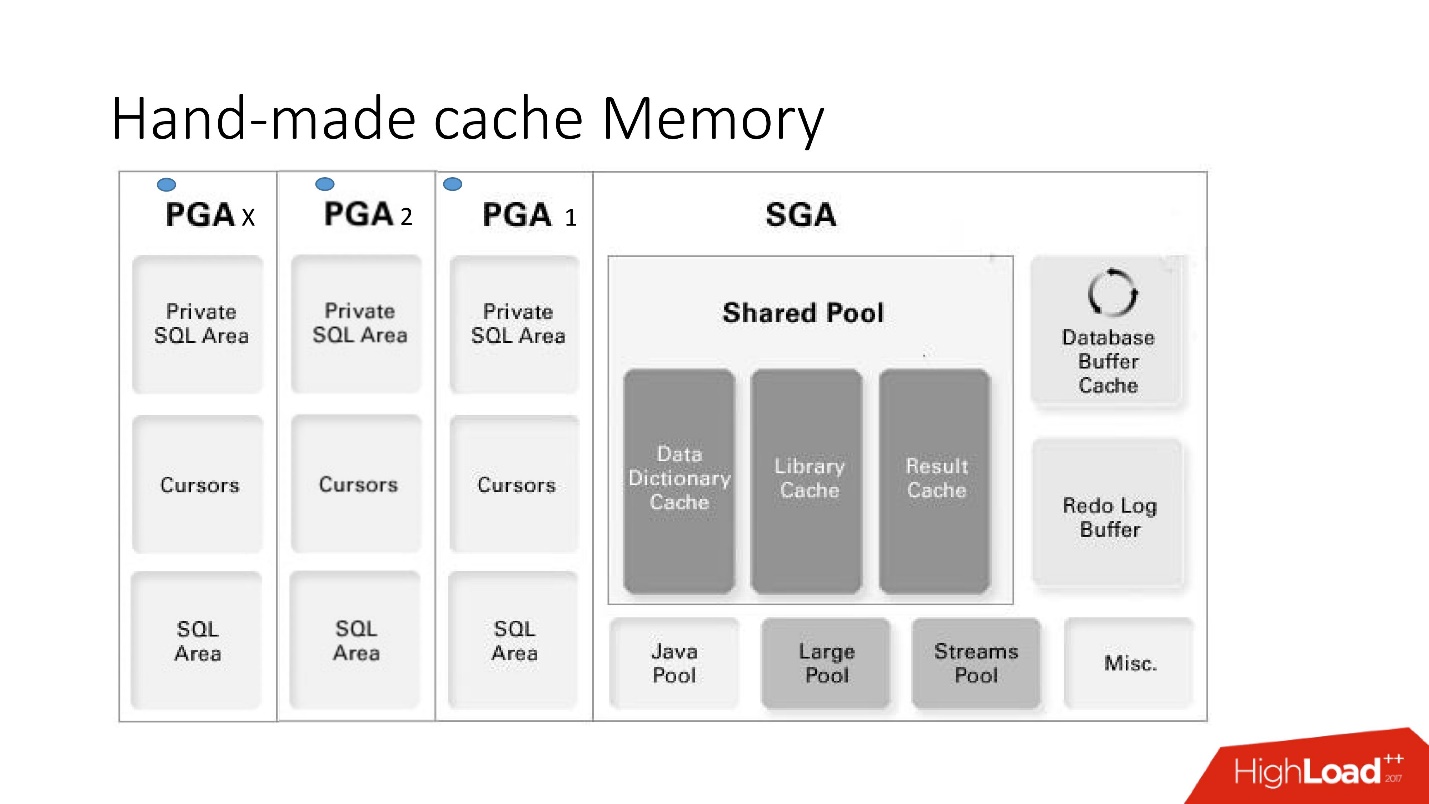
Es ist wichtig zu verstehen, in welchem Speicherbereich sich die Sammlungen befinden. Sie befinden sich in einem Speicherbereich namens PGA.
Der globale Programmbereich wird bei jeder Verbindung zur Datenbank instanziiert. Dies bestimmt die Vor- und Nachteile, da mehr Verbindungen - mehr Speicher und
teurer Speicher, Server , Administratoren - zart sind.

- Vorteile: Alles funktioniert sehr schnell, ist sehr einfach zu erledigen, keine Konfiguration erforderlich, keine Probleme mit der Interprozessbeteiligung.
- Die Nachteile sind verständlich: Wenn gespeicherte Logik im Projekt verboten ist, können sie nicht verwendet werden, es gibt keinen Mechanismus für die automatische Ungültigmachung, und da der Speicher im Cache innerhalb einer Datenbanksitzung und nicht einer Instanz zugewiesen wird, wird sein Verbrauch überbewertet . Darüber hinaus müssen Sie im Fall des Anwendungsfalls des Verbindungspools daran denken, die Caches zu leeren, wenn für jede Sitzung ein anderes Caching vorhanden sein sollte.
Es gibt andere Optionen für handgefertigte Caches, die auf materialisierten Ansichten und temporären Tabellen basieren, aber von diesen wird das Eingabe-Ausgabe-System stark belastet, sodass wir sie hier nicht berücksichtigen. Sie sind eher auf andere Datenbanken anwendbar, in denen solche Probleme normalerweise gelöst werden, indem die gespeicherte Prozedur in einer Zwischentabelle gespeichert und die Daten daraus entnommen werden, bevor auf eine umfangreiche Anforderung zugegriffen wird. Und nur wenn nicht gefunden wurde, was benötigt wird, wird die erste Anfrage aufgerufen.

Das Obige veranschaulicht diesen Ansatz für das Caching-Problem, um eine Liste verwandter Produkte in MsSQL zu erhalten. Im Allgemeinen ist der Ansatz relativ ähnlich, funktioniert jedoch im Datenbankspeicher nicht sowohl hinsichtlich des Abrufs von Daten als auch hinsichtlich der Primärfüllung. Aufgrund dessen
kann er langsamer sein .
Im Allgemeinen wird der selbst erstellte result_cache aktiv verwendet, der datenbankinterne result_cache ist jedoch ein anderer Ansatz für die Implementierung dieser Aufgabe. Es und wie es nicht schnell geklappt hat, werden wir weiter überlegen.
Fall 2. Verarbeitung der Finanzdokumentation
Also unser zweiter Fall.
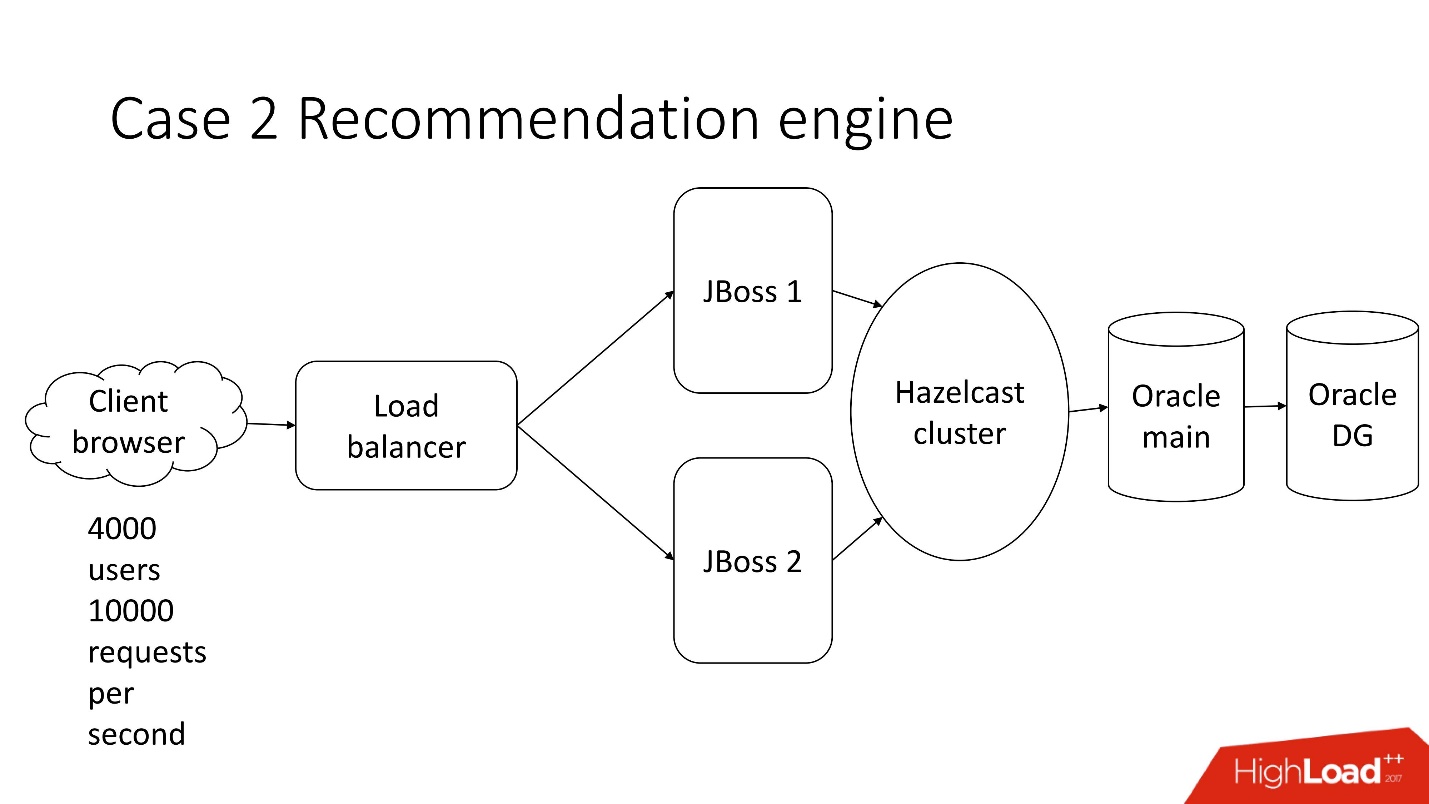
Dies ist ein halbautomatisches Verarbeitungssystem für Finanzdokumentationen - ein trostloses Unternehmen mit einer klassischen Architektur, das Folgendes umfasst:
- Thin Client;
- 4.000 Benutzer, die in verschiedenen Teilen der Welt leben;
- Balancer;
- 2 JBoss zur Berechnung der Geschäftslogik;
- In-Memory-Cluster;
- Kern Oracle;
- Oracle-Backup
Eine der vielen Aufgaben dieses Systems ist die
Berechnung von Empfehlungen .

Es gibt Dokumente. Für jeden Indikator, der vom System nicht automatisch erkannt wird, wird eine Reihe von Indikatoren entweder aus früheren Kundendokumenten oder aus einer ähnlichen Branche oder mit ähnlicher Rentabilität angeboten, während der Indikator mit dem erkannten Wert verglichen wird, um nicht zu viel zu bieten. Wichtig ist, dass die
Dokumente mehrsprachig sind .
Der Benutzer wählt den gewünschten Wert aus und wiederholt den Vorgang für jede leere Zeile.
Vereinfacht gesagt besteht diese Aufgabe aus Folgendem: Dokumente kommen in Form von Schlüssel-Wert-Paaren aus verschiedenen Erkennungssystemen an, und Parameter werden irgendwo erkannt, aber nicht irgendwo. Es muss sichergestellt werden, dass die Benutzer am Ende die Dokumente verarbeiten und alle Werte erkannt werden. Die Empfehlung zielt genau auf die Vereinfachung dieser Aufgabe ab und berücksichtigt:
- Mehrsprachigkeit - ca. 30 Sprachen. Jede Sprache hat ihre eigenen Stämme, Synonyme und andere Merkmale.
- Die vorherigen Daten dieses Kunden oder, falls nicht vorhanden, die Daten eines Kunden aus derselben Branche oder eines Kunden mit ähnlichem Gewinn.
In der Tat sind dies ungefähr 12 sehr komplexe Regeln.
Anfangsannahmen:- Nicht mehr als 100 Benutzer gleichzeitig;
- 2-3 Spalten zur Erkennung;
- 100 Zeilen.
Überhaupt keine Hochlast - alles ist langweilig.
Es ist also Zeit für die Veröffentlichung. Das Einfrieren des Codes ist passiert, Java hat Angst vor Berührungen und die Verarbeitung eines Dokuments dauert mindestens 5 Minuten.
Sie kommen zum Datenbankentwicklungsteam und bitten um Hilfe. Natürlich, denn
wenn sich etwas in der JVM verlangsamt, müssen Sie die Datenbank selbst ändern oder reparieren .

Wir haben die Dokumente untersucht und festgestellt, dass Werte in Schlüssel-Wert-Paaren häufig wiederholt werden - 5-10 Mal. Dementsprechend haben wir uns entschieden, die Datenbank zum Zwischenspeichern zu verwenden, da sie bereits getestet wurde.
Wir haben uns für den serverseitigen Ergebniscache von Oracle entschieden, weil:
- Die Möglichkeiten zur Optimierung von SQL wurden ausgeschöpft, da die Oracle-Volltextsuchmaschine verwendet wird.
- Der Cache wird für doppelte Parameter verwendet.
- Die meisten Daten für Empfehlungen werden einmal pro Stunde neu berechnet, da sie einen Volltextindex verwenden.
- PL / SQL ist verboten .
Oracle-Ergebniscache
Der Ergebnis-Cache - Oracle-Caching von Ergebnissen - hat die folgenden Eigenschaften:
- Dies ist der Speicherbereich, in dem alle Abfrageergebnisse durchsucht werden.
- Lesen Sie konsistent, und seine automatische Ungültigmachung tritt auf;
- Es sind nur minimale Änderungen an der Anwendung erforderlich. Sie können dafür sorgen, dass die Anwendung überhaupt nicht geändert werden muss.
- Bonus - Sie können PL / SQL-Logik zwischenspeichern, dies ist hier jedoch verboten.
Wie aktiviere ich es?Methodennummer 1
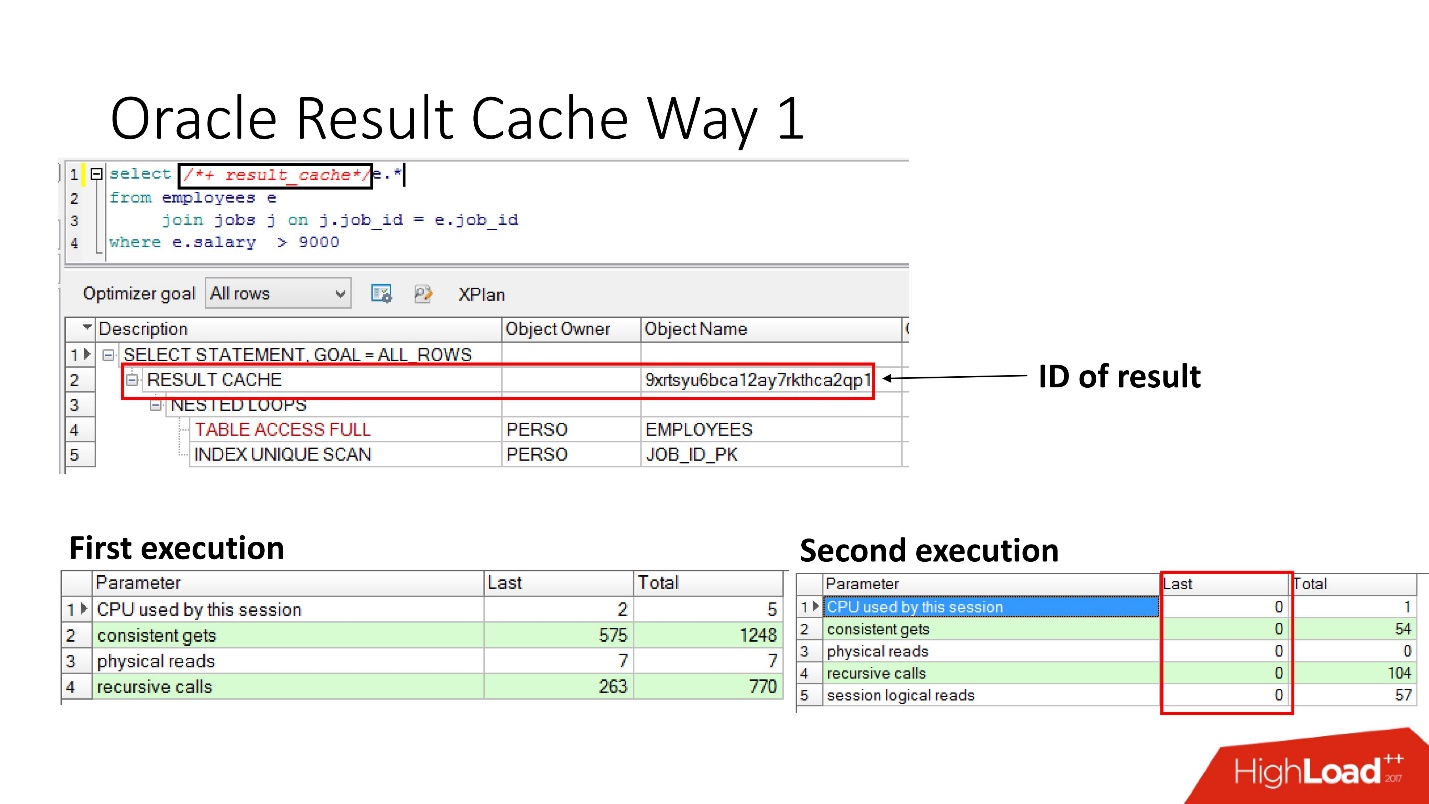
Es ist sehr einfach
, die Anweisung result_cache anzugeben . Die Folie zeigt, dass die Ergebniskennung angezeigt wurde. Dementsprechend führt die Datenbank bei der ersten Ausführung der Abfrage einige Arbeiten aus, während der nachfolgenden Ausführung ist in diesem Fall keine Arbeit erforderlich. Alles ist gut.
Methode Nummer 2
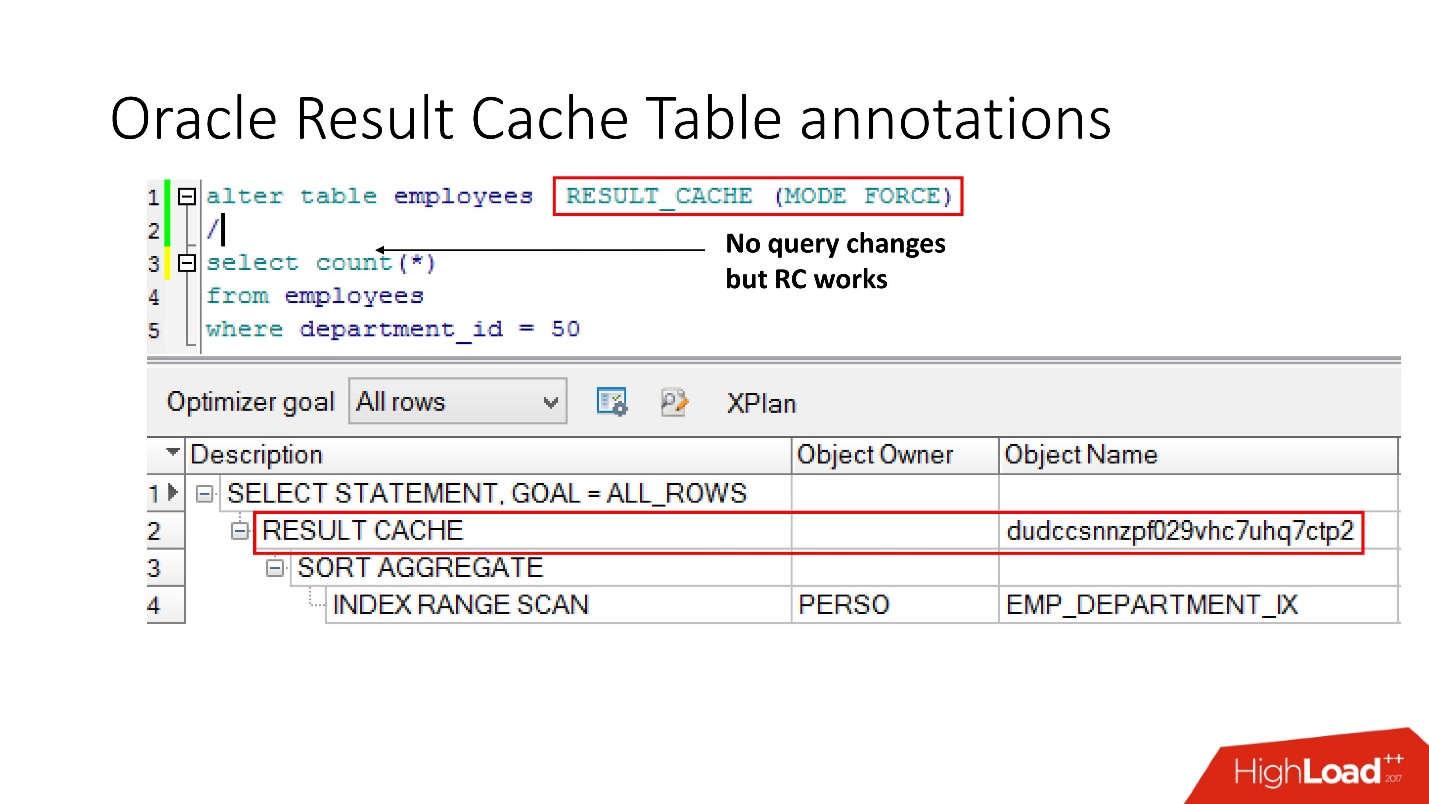
Der zweite Weg ermöglicht es Anwendungsentwicklern, nichts zu tun - dies sind die sogenannten Annotationen. Wir geben ein Häkchen für die Tabelle an, dass die Anforderung an sie in result_cache gestellt werden soll. Dementsprechend gibt es keinen Hinweis, wir berühren die Anwendung nicht und alles befindet sich bereits im result_cache.
Was denken Sie übrigens, wenn sich eine Abfrage auf zwei Tabellen bezieht, von denen eine als result_cache markiert ist und die zweite nicht, wird das Ergebnis einer solchen Abfrage zwischengespeichert?
Die Antwort ist nein, überhaupt nicht.
Damit es zwischengespeichert werden kann, müssen alle an der Abfrage beteiligten Tabellen mit der Annotation result_cache versehen sein.
Abhängigkeitsverfolgung
Es gibt relevante Ansichten, in denen Sie sehen können, welche Abhängigkeiten bestehen.
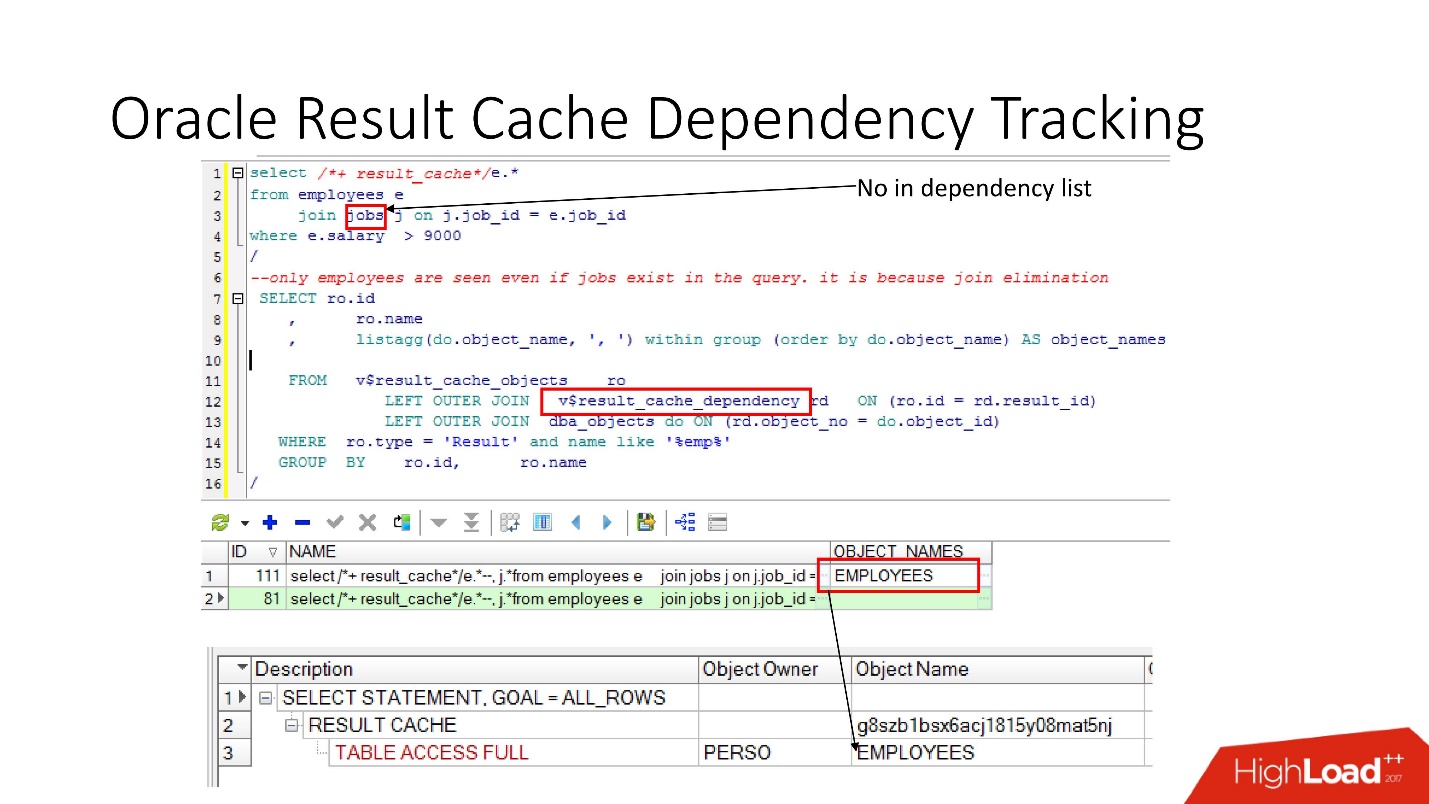
Im obigen Beispiel ist die JOIN-Abfrage eine Tabelle, in der es eine Abhängigkeit gibt. Warum? Weil Oracle die Abhängigkeit nicht nur durch Parsen bestimmt, sondern sie
entsprechend den Ergebnissen des Arbeitsplans implementiert.
In diesem Fall wurde ein solcher Plan ausgewählt, da nur eine Tabelle verwendet wird und die Jobtabelle über eine Fremdschlüsseleinschränkung mit der Mitarbeitertabelle verknüpft ist. Wenn wir die Fremdschlüsseleinschränkung entfernen, die diese Join-Eliminierungstransformation ermöglicht, werden zwei Abhängigkeiten angezeigt, da sich der Plan auf diese Weise ändert.
Oracle verfolgt nicht, was nicht verfolgt werden muss .
In PL / SQL wird die Abhängigkeit zur Laufzeit ausgeführt, sodass Sie dynamisches SQL verwenden und andere Aufgaben ausführen können.
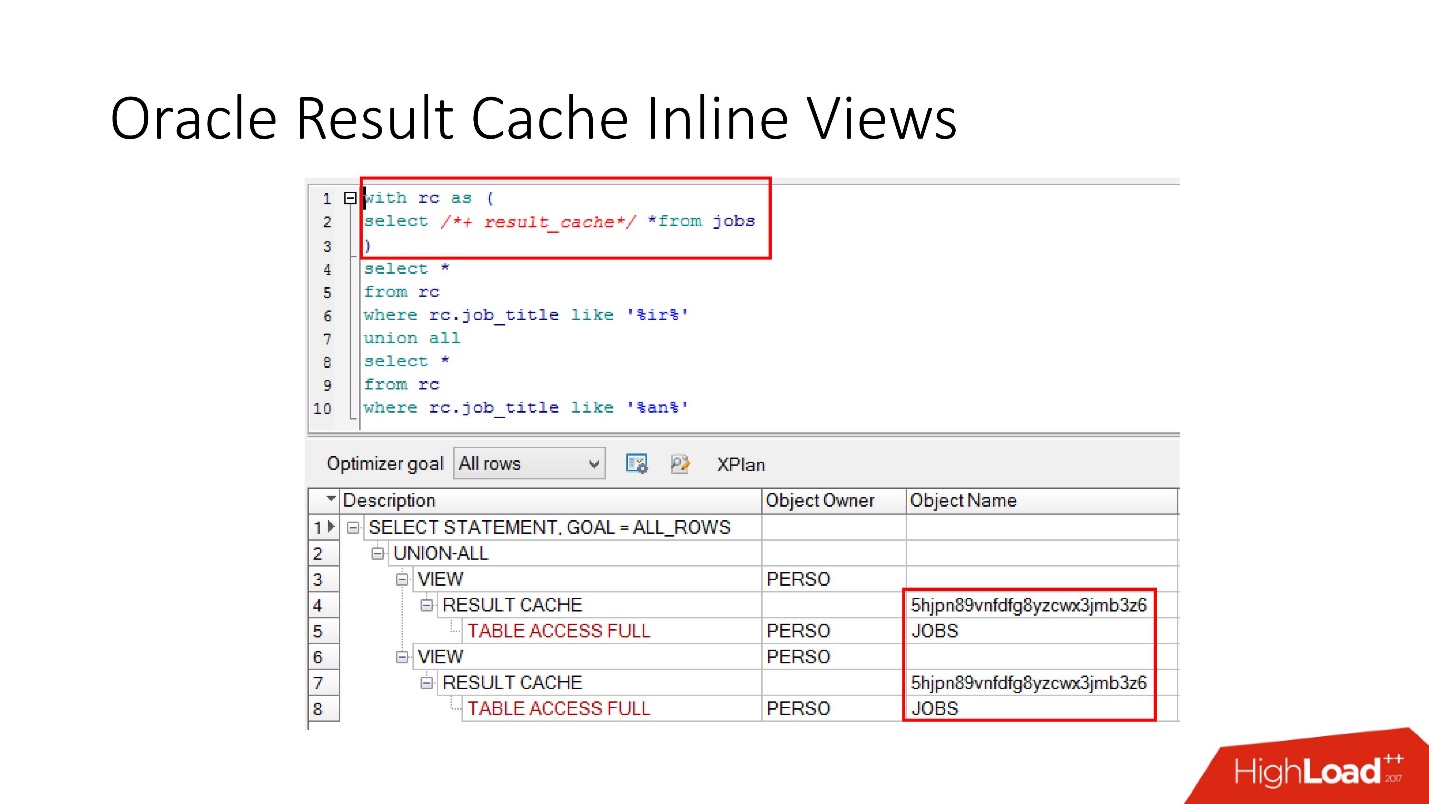
Bitte beachten Sie, dass Sie nicht nur die gesamte Anforderung zwischenspeichern können, sondern
auch die Inline-Ansicht mit und von zwischenspeichern können . Nehmen wir zum einen an, wir brauchen einen Cache, und zum anderen ist es besser, aus der Datenbank zu lesen, um ihn nicht zu belasten. Wir nehmen eine Inline-Ansicht, deklarieren sie erneut als result_cache und stellen fest, dass nur ein Teil zwischengespeichert wird, und für den zweiten greifen wir jedes Mal auf die Datenbank zu.
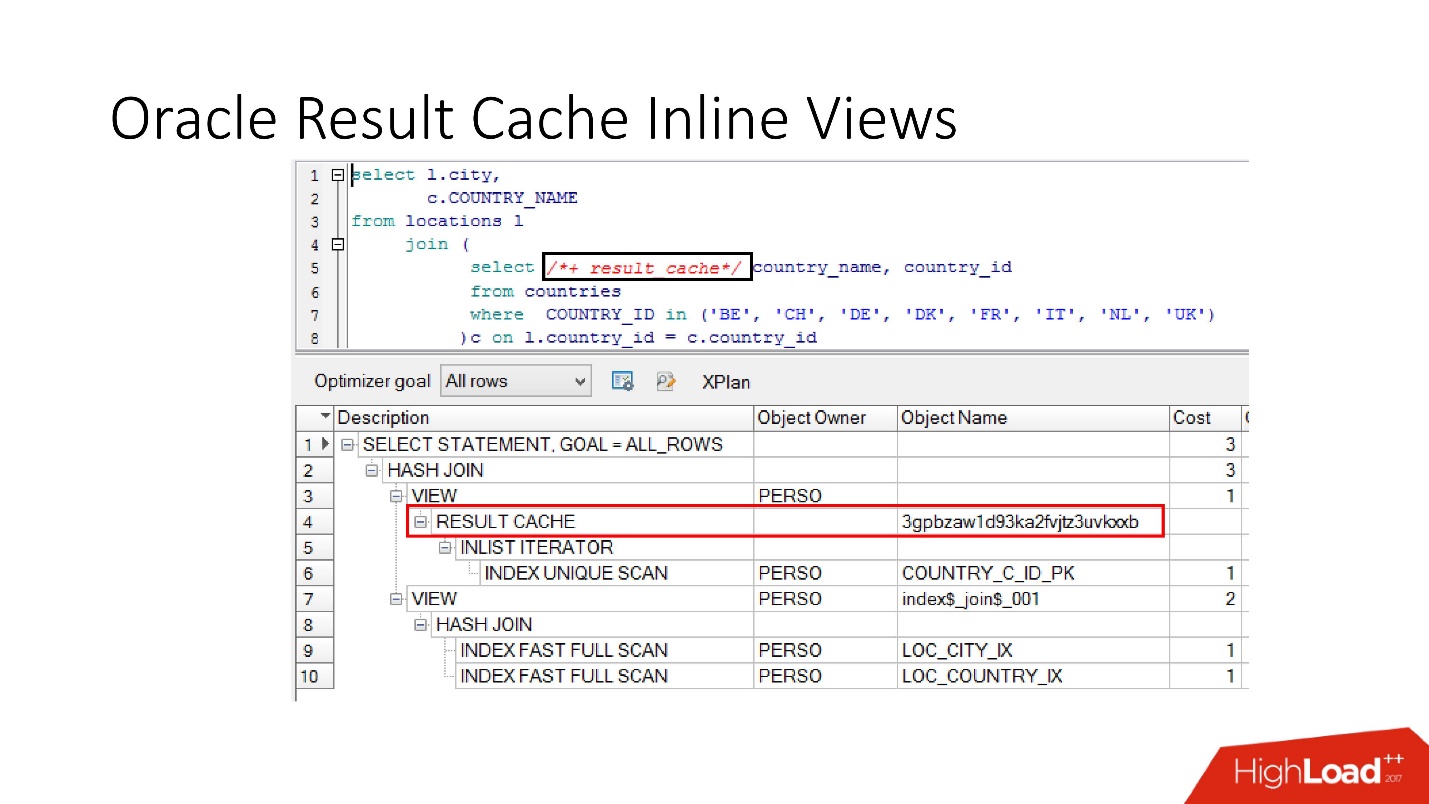
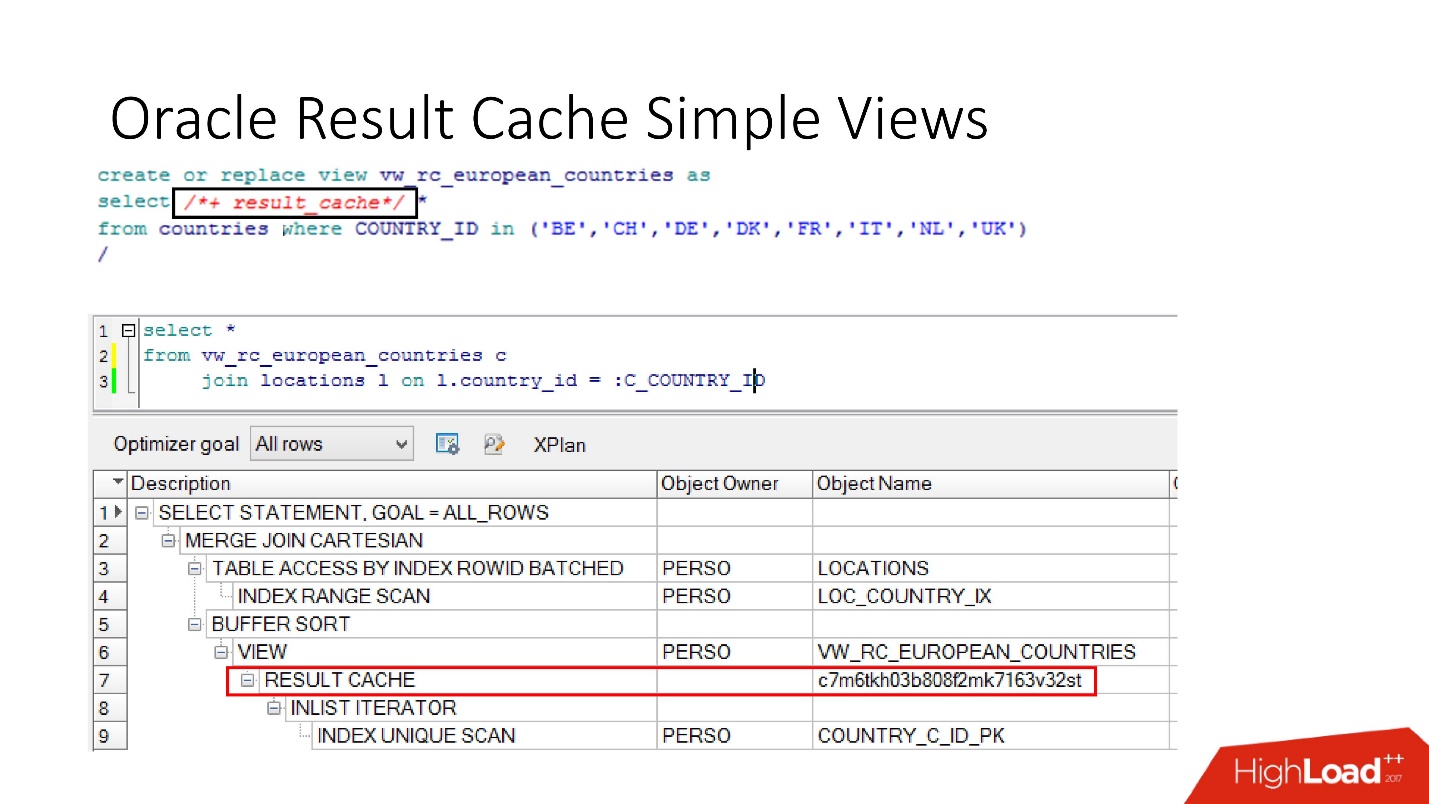
Und schließlich haben die
Datenbanken auch eine Kapselung , obwohl niemand daran glaubt. Wir sehen uns das an, setzen result_cache ein und unsere Programmierer erkennen nicht einmal, dass es zwischengespeichert ist. Unten sehen wir, dass tatsächlich nur ein Teil davon funktioniert.
Behinderung
Lassen Sie uns also sehen, wann Oracle result_cache ungültig macht. Der Status "Veröffentlicht" zeigt den aktuellen Status der Cache-Gültigkeit an. Bei der Anforderung an result_cache befinden sich, wie gesagt, keine Jobs in der Datenbank
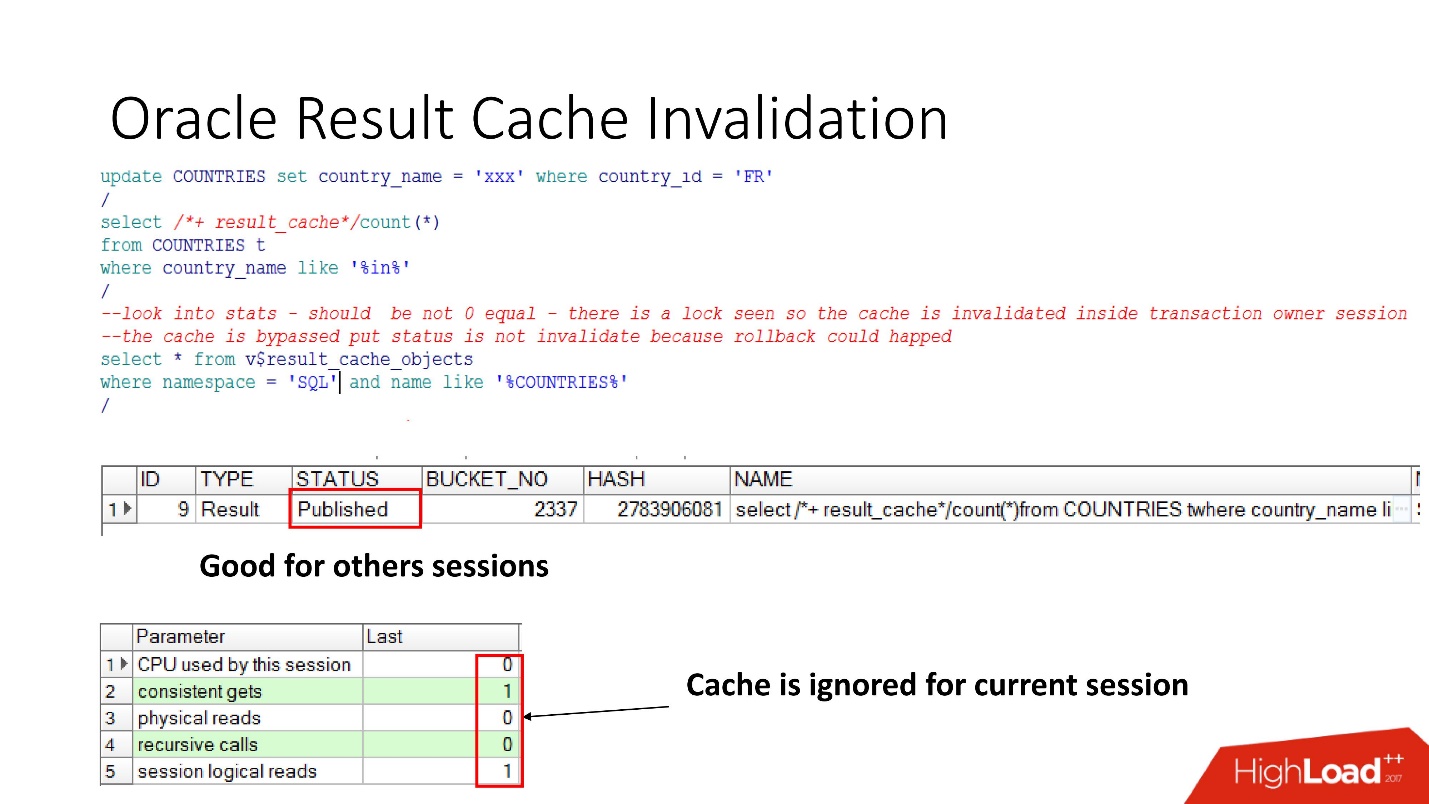
Wenn wir das Update durchgeführt haben, ist der Status immer noch veröffentlicht, da das Update nicht festgeschrieben wurde und andere Sitzungen den alten result_cache sehen sollten. Dies ist die berüchtigte Lesekonsistenz.
In der aktuellen Sitzung werden wir jedoch feststellen, dass die Last weg ist, da in dieser Sitzung der Cache ignoriert wird. Das ist ziemlich vernünftig, machen wir ein Commit - das Ergebnis wird ungültig, alles funktioniert von selbst.

Es scheint - ein Traum! Die Abhängigkeit wird als korrekt angesehen - nur abhängig von der Anforderung. Aber nein, eine Reihe von Nuancen wurden enthüllt.
Oracle produziert Behinderungen und in einer Reihe von nicht offensichtlichen Fällen :
- Bei jedem Aufruf von SELECT FOR UPDATE verschwinden die Abhängigkeiten.
- Wenn die Tabelle nicht indizierte Fremdschlüssel enthält und eine Aktualisierung der mit result_cache gekennzeichneten Tabelle erfolgt, die sich auf nichts auswirkt, sich jedoch in der übergeordneten Tabelle etwas geändert hat, wird der Cache ebenfalls ungültig.
- Dies ist die interessanteste Sache, die das Leben so sehr wie möglich beeinträchtigt - wenn die als result_cache gekennzeichnete Tabelle nicht erfolgreich aktualisiert wurde, hat nichts funktioniert, aber in derselben Transaktion wurden alle anderen Änderungen angewendet, die sich irgendwie auf die erste Tabelle auswirkten result_cache wird zurückgesetzt.
Es gibt immer noch ein solches Antipattern bei result_cache, wenn Entwickler, die gehört haben, dass es so eine coole Sache gibt, denken: „Oh, da ist Speicher! Jetzt nehmen wir eine Anfrage entgegen, die auf 2-3 Partitionen funktioniert - markieren Sie sie am aktuellen und am vorherigen Datum als result_cache und sie wird immer aus dem Speicher genommen! "
Wenn Sie jedoch im Nachhinein Patricia ändern, fliegt der gesamte Cache, da die Einheit der Abhängigkeitsverfolgung in result_cache immer eine Tabelle ist und ich nicht weiß, ob es jemals Partitionen geben wird oder nicht.
Wir dachten und beschlossen, mit solchen Dingen ein Empfehlungssystem zu erstellen:
- Wir werden nicht alle unsere Tabellen zwischenspeichern, wir werden nur die notwendigen nehmen.
- Legen Sie result_cache für die lang laufende Abfrage fest.
Wir haben alles überprüft, Leistungstests durchgeführt,
Verarbeitungszeit - 30 s . Alles ist toll, geh in die Produktion!
Abgestürzt - ging schlafen. Wir kommen am Morgen an. Wir sehen einen Brief: "Die Erkennung dauert mindestens 20 Minuten, die Sitzungen frieren ein." Warum frieren sie? Wie wurden aus
30 Sekunden 20 Minuten ?
Sie begannen zu verstehen, schauten in die Datenbank:
- aktive Sitzungen - 400;
- durchschnittlich Zeilen in einem Dokument zur Anerkennung - 500;
- Spalten mindestens - 5-8;
- Die Anzahl der Sitzungen in der Datenbank entspricht immer der Anzahl der Benutzeranwendungen multipliziert mit 3! Und result_cache mag keinen häufigen Zugriff darauf.
Nach einer internen Untersuchung stellten wir fest, dass Java-Entwickler in drei Threads erkennen.
Wir waren verärgert - eine 5-fache Belastung, ein Abfall, eine Verschlechterung und selbst mit solchen Parametern hätte ein solches Absinken nicht passieren dürfen.
Natürlich müssen Sie verstehen.
Überwachung

Für die Überwachung haben wir zwei wichtige Dinge:
- V $ RESULT_CACHE_OBJECTS - eine Liste aller Objekte;
- V $ RESULT_CACHE_STATISTICS - Aggregierte Statistik des gesamten Ergebniscaches.
MEMORY_REPORT sind Variationen eines Themas, wir werden sie nicht brauchen.
Oracle ist magisch! Es gibt eine großartige Dokumentation, die jedoch für diejenigen gedacht ist, die von anderen Datenbanken wechseln, damit sie lesen und denken, dass Oracle sehr cool ist!
Alle Informationen zu result_cache liegen jedoch nur bei der Unterstützung .

Es gibt eine Nuance, die darin besteht, dass wir, sobald wir uns diesen Objekten zuwenden, um das Problem zu lösen, es verschärfen, indem wir uns endgültig begraben! Bis Oracle12.2, vor dessen Patch es im Oktober letzten Jahres veröffentlicht wurde, machen diese Anforderungen result_cache für den Status und das Schreiben unzugänglich, bis sie vollständig gezählt sind.
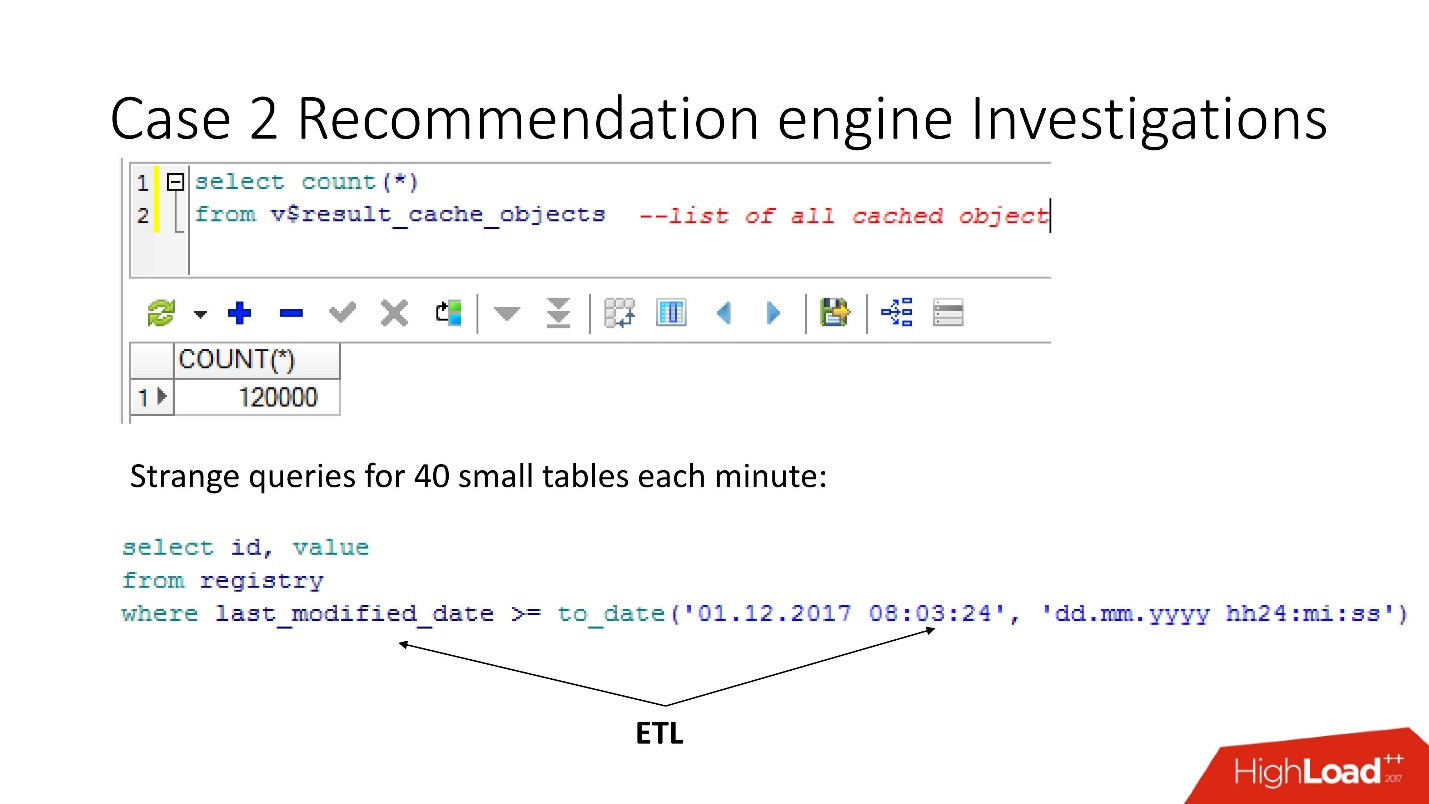
In der Ansicht v $ result_cache_objects haben wir festgestellt, dass die Liste der zwischengespeicherten Objekte Tausende von Einträgen enthält - viel mehr als erwartet. Darüber hinaus waren dies Objekte aus einigen unserer Abfragen in seltsamen Tabellen - kleine Tablets und last_modified_date-Abfragen. Offensichtlich hat
jemand ETL auf unsere Basis gesetzt .
Bevor wir uns bei ETL-Entwicklern beschworen haben, haben wir überprüft, ob die Option result_cache force für diese Tabellen aktiviert ist, und uns daran erinnert, dass wir sie selbst aktiviert haben, da einige dieser Daten häufig von der Anwendung benötigt wurden und das Caching angemessen war.
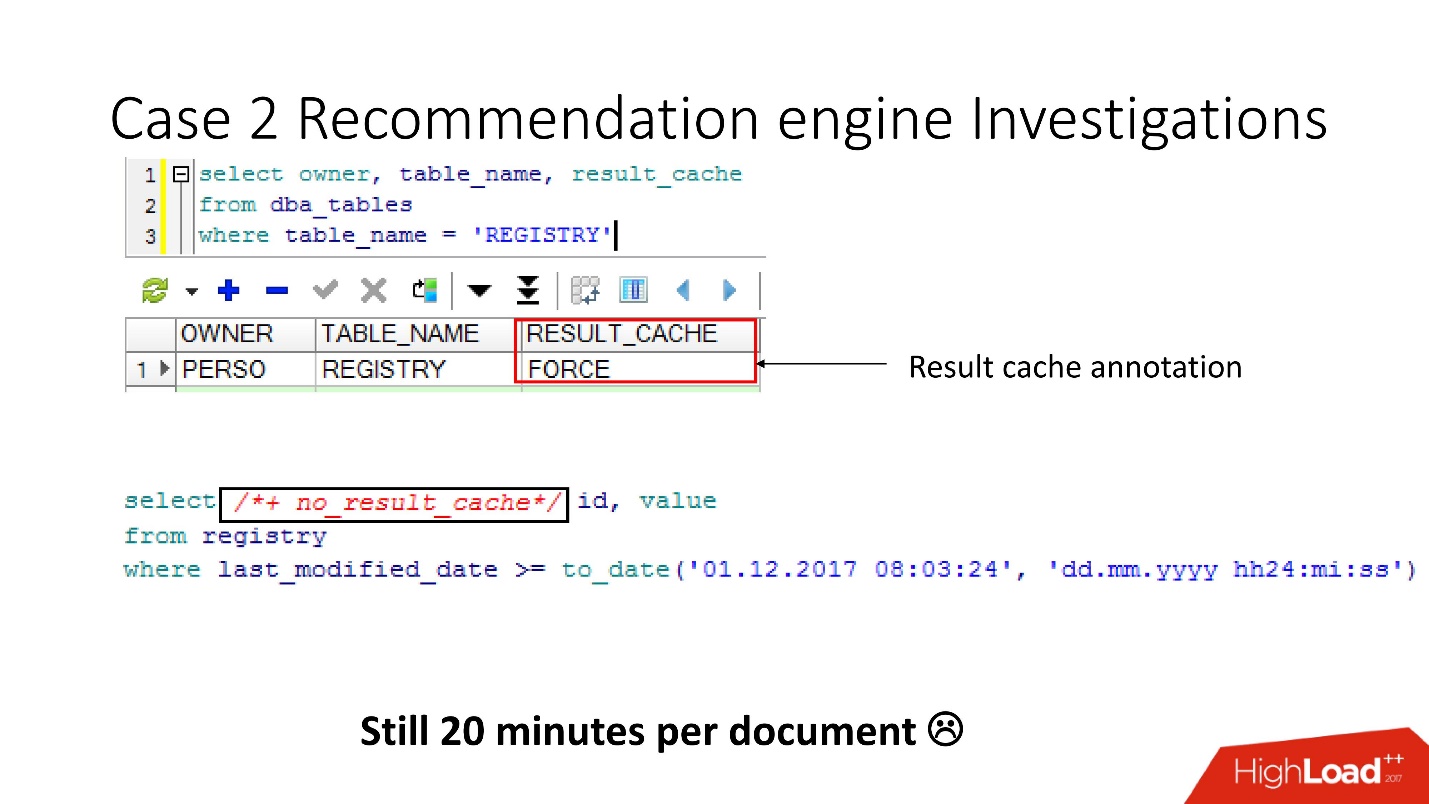
Es stellte sich jedoch heraus, dass
all diese Anfragen nur unseren Cache nehmen und waschen . Glücklicherweise hatten die Entwickler die Möglichkeit, die ETL in der Produktion zu beeinflussen, sodass wir result_cache ändern konnten, um diese winzigen Anforderungen auszuschließen.
Denkst du, es ist einfacher? - Fühl dich nicht besser! Die Anzahl der zwischengespeicherten Objekte nahm ab und stieg dann wieder auf 12.000. Wir untersuchten weiter, was noch zwischengespeichert wurde, da sich die Geschwindigkeit nicht änderte.

Wir sehen aus - eine Menge Anfragen, und so klug, aber alles unverständlich. Obwohl jeder, der mit Oracle 12 gearbeitet hat, weiß, dass DS SVC eine adaptive Statistik ist. Es wird benötigt, um die Leistung zu verbessern, aber wenn es result_cache gibt, stellt sich heraus, dass es ihn umbringt, weil Wettbewerb stattfindet. Dies ist natürlich
nur zur Unterstützung geschrieben .
Wir wussten, wie die Arbeitsbelastung angeordnet ist, und haben verstanden, dass adaptive Statistiken in unserem Fall unsere Pläne nicht besonders radikal verbessern würden. Deshalb haben wir es heldenhaft ausgeschaltet - das Ergebnis, wie es im geheimen Handbuch geschrieben steht, beträgt 10 Minuten pro Dokument. Nicht schlecht, aber nicht genug.
Riegel
Die Konkurrenz zwischen result_cache und DS SVC beruht auf der Tatsache, dass Oracle Latches hat - leichte kleine Schlösser.

Ohne auf Details zu ihrer Funktionsweise einzugehen, versuchen wir mehrmals, einen benannten Latch zu platzieren - es hat nicht funktioniert - Oracle nimmt auf und schläft ein
Jeder, der sich im Betreff befindet, kann sagen, dass im result_cache zwei Latches mit Fetch auf jeden Block gesetzt werden. Das sind die Details. Es gibt zwei Arten von Latches in result_cache:
1. Latch für den Zeitraum, während wir Daten in result_cache schreiben.

Das heißt, wenn Ihre Anfrage 8 Sekunden lang funktioniert hat, können andere gleiche Anfragen (das Schlüsselwort „same“) für den Zeitraum dieser 8 Sekunden nichts tun, da sie warten, bis die Daten in result_cache geschrieben sind. Andere Anfragen werden aufgezeichnet, warten jedoch nur in der ersten Zeile auf die Sperre. Wie viel sie warten müssen, ist unbekannt. Dies ist der undokumentierte Parameter result_cache_timeout. Danach beginnen sie, result_cache sozusagen zu ignorieren und arbeiten langsam. Sobald jedoch die Sperre der letzten Zeile an der Tür aufgehoben wurde, arbeiten sie automatisch wieder mit result_cache.
2. Die zweite Art von Sperren - von result_cache auch von der ersten bis zur letzten Zeile zu empfangen.
Da der Abruf jedoch aus dem Sofortspeicher stammt, werden sie sehr schnell entfernt.

Denken Sie daran, dass der DBA, wenn er Latches in der Datenbank sieht, sagt: „Latches! Wartezeit - alles ist weg! »Und hier beginnt das interessanteste Spiel:
Überzeugen Sie DBA davon, dass die Wartezeit von den Latches tatsächlich unvergleichlich kürzer ist als die Wiederholungszeit für Abfragen .

Wie unsere Erfahrung zeigt,
belegen unsere Messungen,
Latches für result_cache, 10% der Anforderungen selbst .
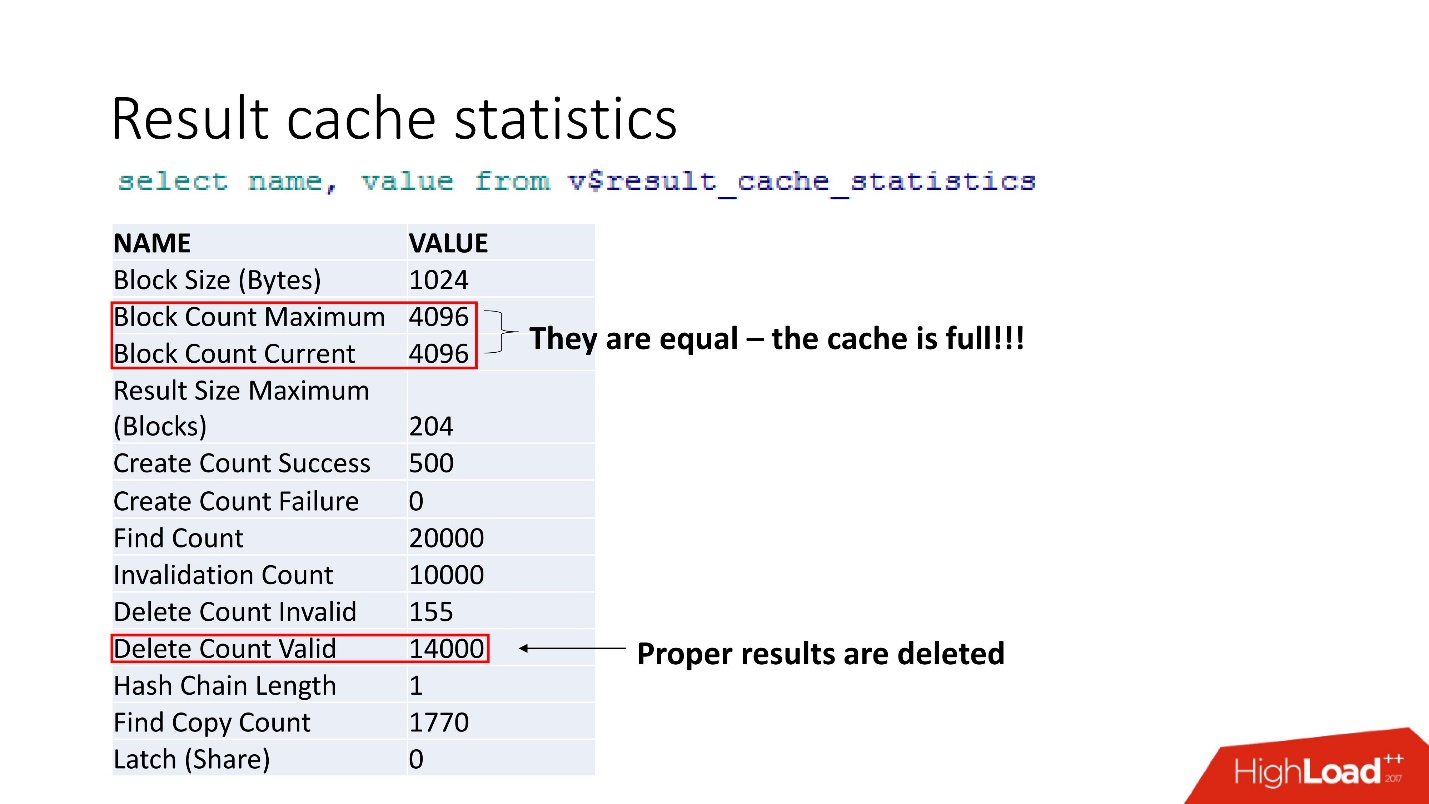
Dies sind aggregierte Statistiken. Die Tatsache, dass alles schlecht ist, kann durch die Tatsache verstanden werden, dass der Cache verstopft ist. Eine weitere Bestätigung ist, dass die richtigen Ergebnisse gelöscht werden. Das heißt, der
Cache wird überschrieben . Es scheint, dass wir klug sind und immer die Größe des Speichers berücksichtigen - wir haben die Zeilengröße unseres zwischengespeicherten Ergebnisses für unsere Empfehlung verwendet, multipliziert mit der Anzahl der Zeilen, und etwas ist schiefgegangen.
 Bei der Unterstützung wurden zwei Fehler gefunden, die besagen, dass bei einem Überlauf von result_cache Leistungseinbußen auftreten . Und dies wurde auch in demselben geheimen Patch behoben.Das Geheimnis ist, dass der Speicher in Blöcken zugewiesen wird. In unserem Fall wurde natürlich die Tatsache hinzugefügt, dass sich die Arbeitsbelastung um das Fünffache erhöhte. Daher muss bei der Berechnung der Speicher nicht mit der Breite Ihrer Daten multipliziert werden, sondern mit der Größe des Blocks, und dann wird es glücklich.Was kann noch angepasst werden?Parameter Meer: Es gibt dokumentierte und nicht dokumentierte Parameter. Tatsächlich benötigen wir nicht alle diese Parameter.
Bei der Unterstützung wurden zwei Fehler gefunden, die besagen, dass bei einem Überlauf von result_cache Leistungseinbußen auftreten . Und dies wurde auch in demselben geheimen Patch behoben.Das Geheimnis ist, dass der Speicher in Blöcken zugewiesen wird. In unserem Fall wurde natürlich die Tatsache hinzugefügt, dass sich die Arbeitsbelastung um das Fünffache erhöhte. Daher muss bei der Berechnung der Speicher nicht mit der Breite Ihrer Daten multipliziert werden, sondern mit der Größe des Blocks, und dann wird es glücklich.Was kann noch angepasst werden?Parameter Meer: Es gibt dokumentierte und nicht dokumentierte Parameter. Tatsächlich benötigen wir nicht alle diese Parameter.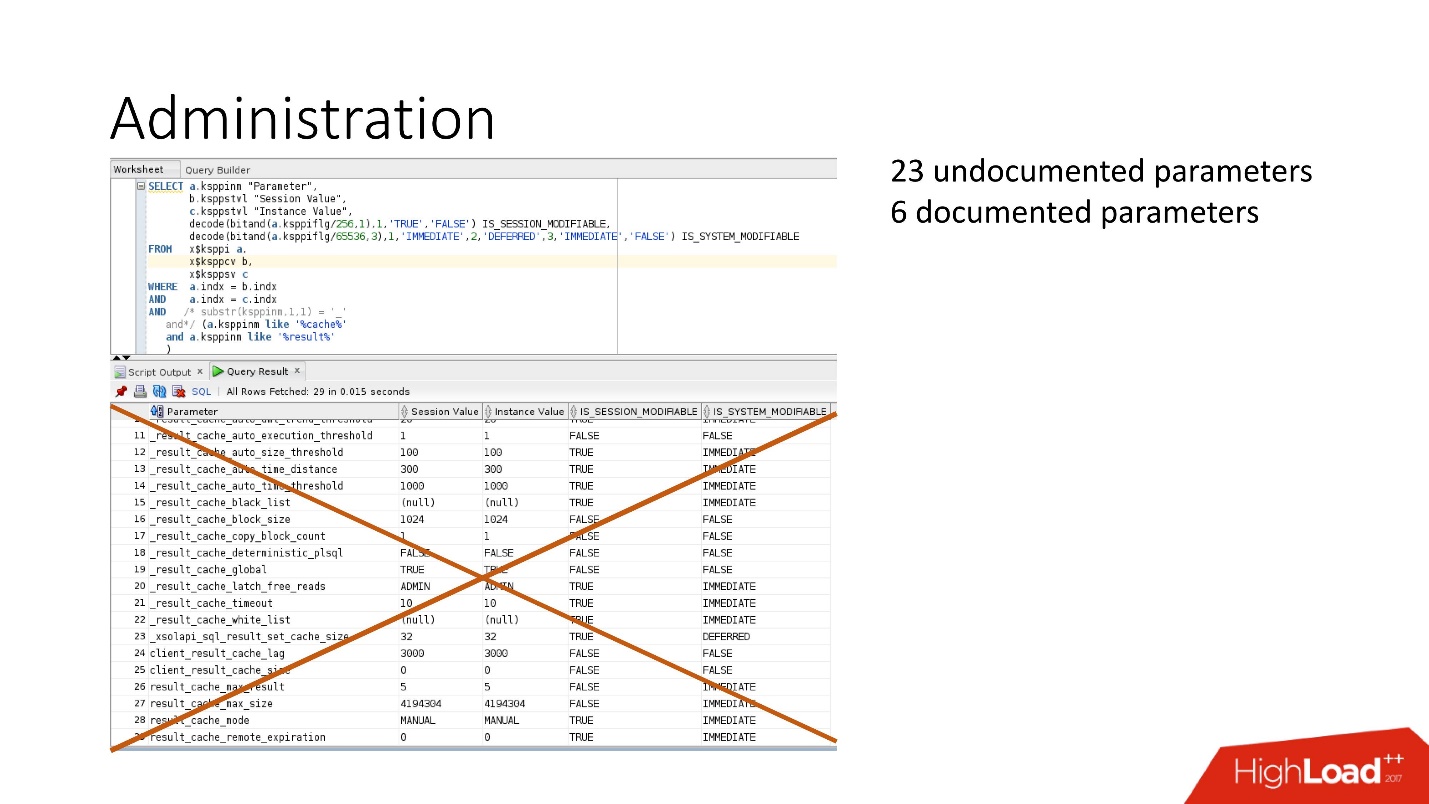 In der Tat sind 4 Parameter ausreichend:
In der Tat sind 4 Parameter ausreichend:- RESULT_CACHE_MAX_SIZE;
- RESULT_CACHE_MAX_RESULT;
- RESULT_CACHE_MODE;
- _RESULT_CACHE_MAX_TIMEOUT.
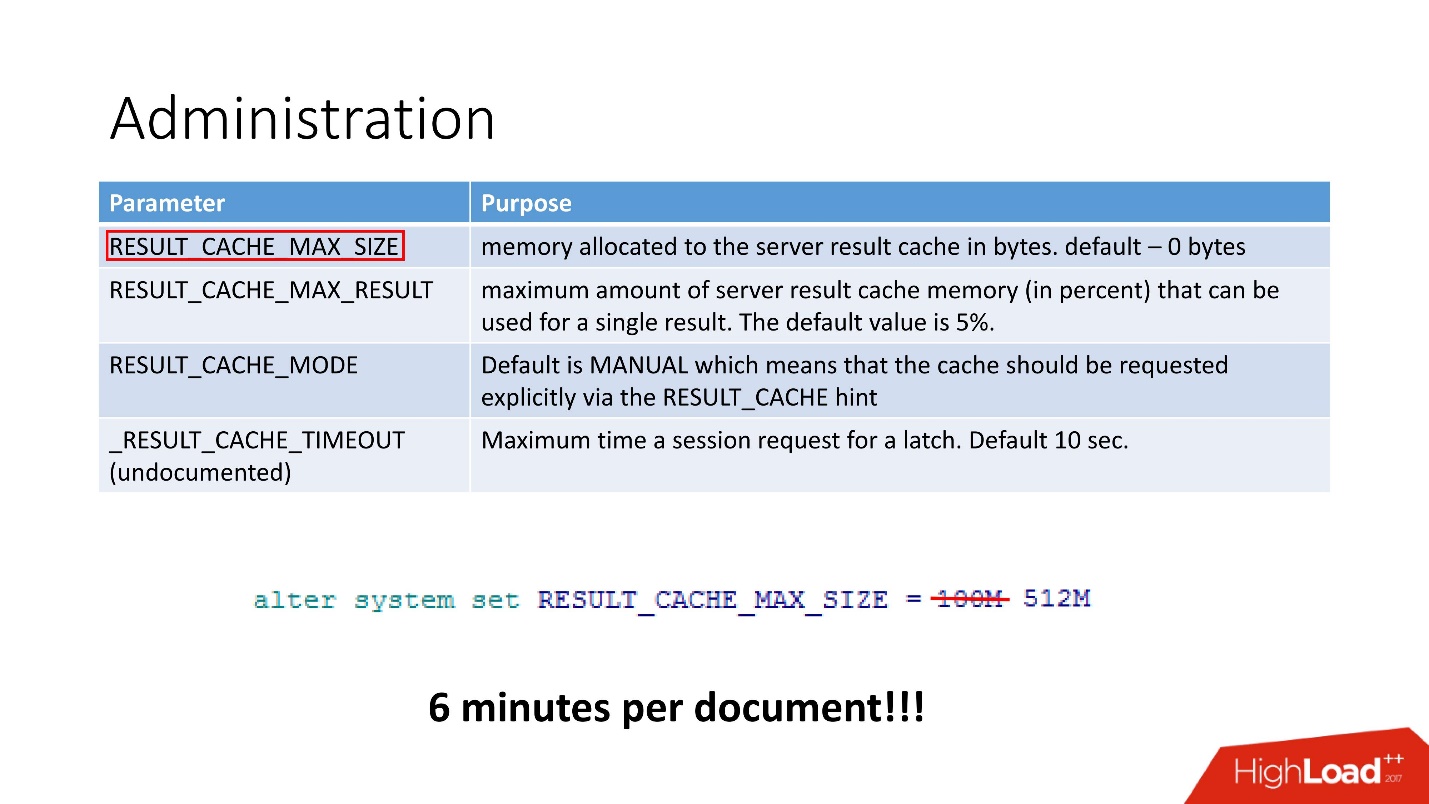
— . , 100 512, 6 .
, - . , Invalidation Count = 10000.
, . , job , . , . job , , .
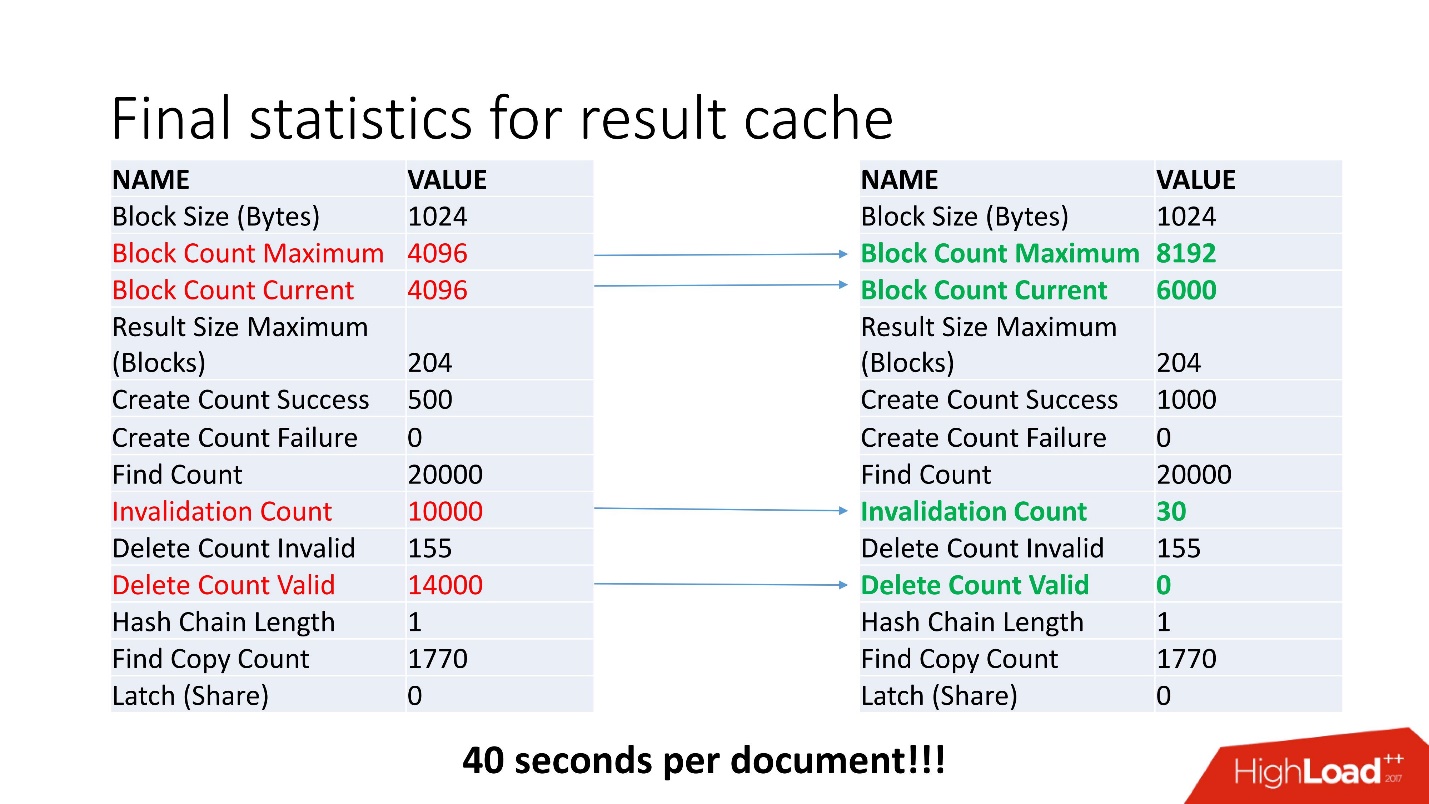
, invalid , .
40 .
, . , , Oracle. !
 SHELFLIVE
SHELFLIVE — , read-consistent , 10 , . . , , .
—
SNAPSHOT . , , read-consistent — .
:

- — SYS.
- . , , Oracle , , . , Oracle , , 12.2 . , external - support, .
- sql pl/sql : current_date, current_time . , current_time, .
- .
- , CLOB, BLOB .
Result cache inside Oracle
Result_cache — Oracle Core. , , job result_cache (, hint, ) , APEX.

, Dynamic sampling , , , result_cache.

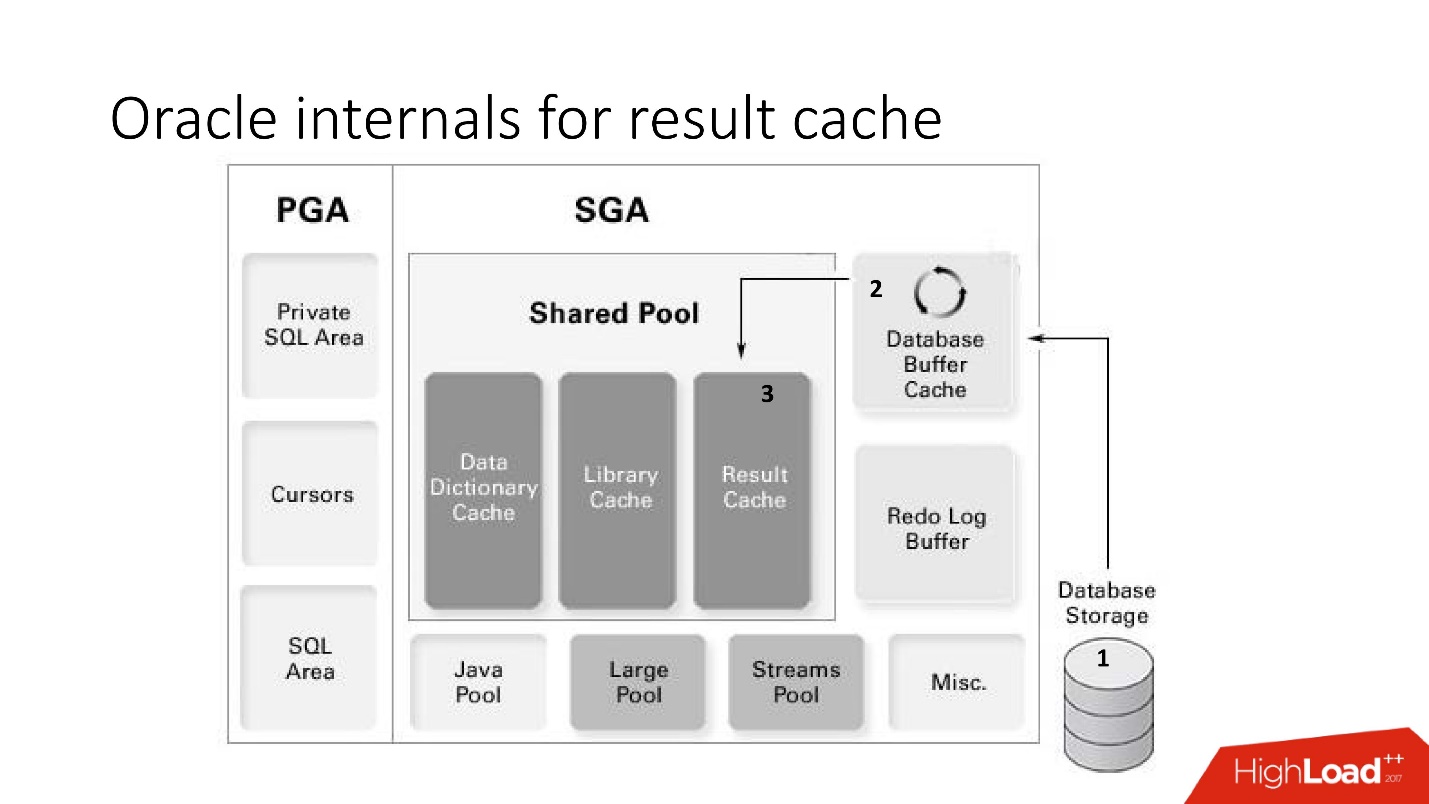
Oracle internals for result cache
result_cache:
- (storage) ;
- result_cache;
- result_cache shared pool.
 Vorteile:
Vorteile:- .
- read-consistent.
- Result_cache, , .
Nachteile:!
, . support Oracle, , 29 2017 .: Oracle E-Business suite result_cache, .

, , . support , , .

:
- - ;
- , , , , v$result_cache_memory dbms_result_cache.memory_report, .
, , , v_result_cache_objects .
, support note — support , .

, , : - . , , :
- hint result_cache;
- hint no result_cache;
- black_list, , , -.
?,
— . Oracle , .
Clientseitiger Ergebniscache

Das Diagramm seines Geräts ist oben dargestellt. Dies sind die Hauptkomponenten der Datenbank und des Treibers.
Beim ersten Zugriff auf die Clientseite geht der Ergebniscache in die vorkonfigurierte Datenbank, empfängt die Größe des Clientcaches aus der Datenbank und installiert diesen Cache bei der ersten Verbindung einmalig auf dem Client. Die zwischengespeicherte Abfrage greift zuerst auf die Datenbank zu und schreibt Daten in den Cache. Die verbleibenden Threads fordern einen gemeinsam genutzten Treibercache an, wodurch Serverspeicher und -ressourcen gespart werden. Übrigens sendet der Treiber manchmal abhängig von der Auslastung Statistiken über die Verwendung des Caches an die Datenbank, die dann angezeigt werden können.
Eine interessante Frage ist, wie kommt es zu einer Behinderung?Es gibt zwei Arten der Ungültigmachung, die durch den Parameter Invalidierungsverzögerung geschärft werden. Auf diese Weise lässt Oracle zu, dass der Treibercache nicht konsistent ist.
Der erste Modus wird verwendet, wenn Anforderungen häufig gestellt werden und die Invalidierungsverzögerung nicht auftritt. In diesem Fall wird der Stream in die Datenbank verschoben, die Caches aktualisiert und die Daten daraus gelesen.
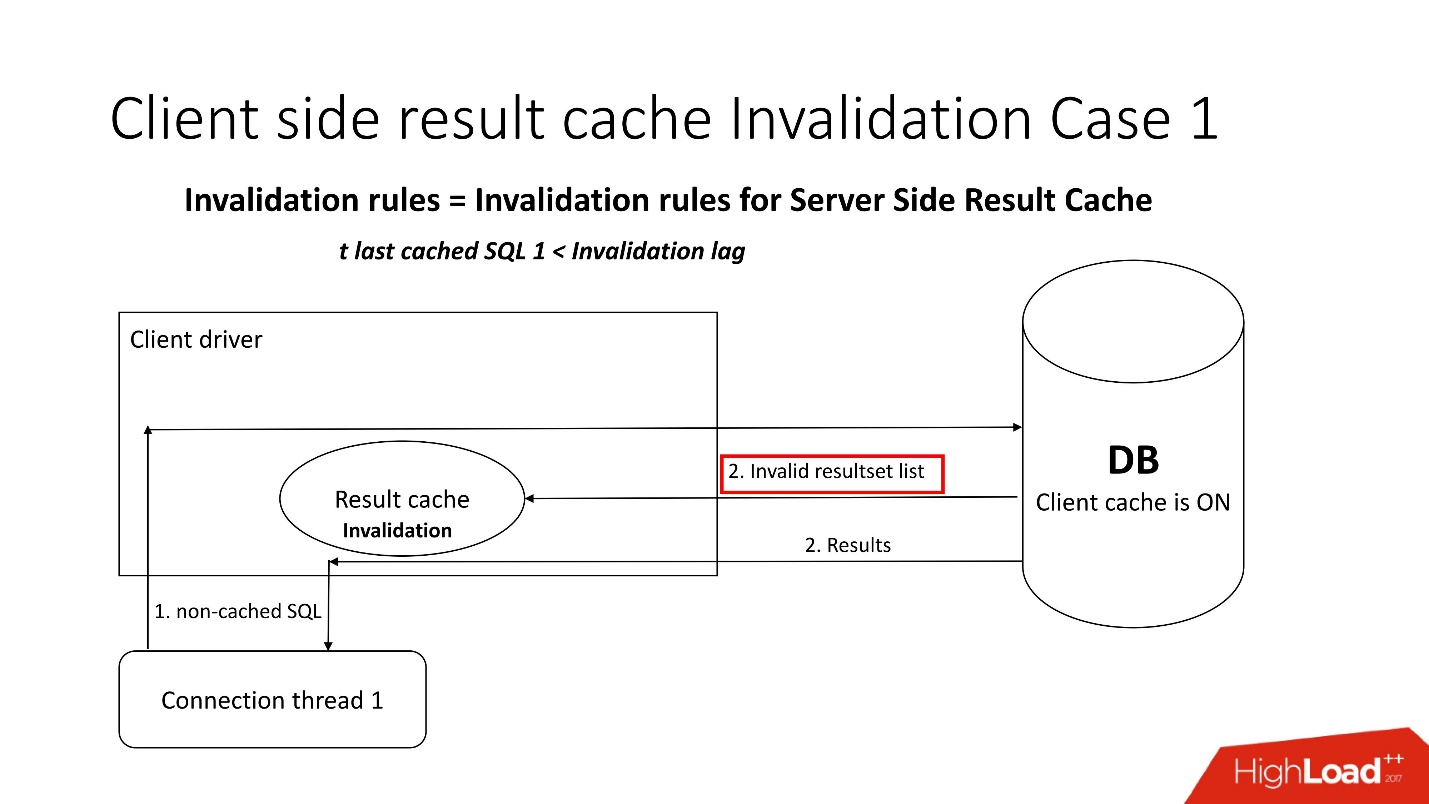
Wenn die Invalidierungsverzögerung fehlschlägt, wird für jede nicht zwischengespeicherte Anforderung, die sich auf die Datenbank bezieht, zusätzlich zu den Abfrageergebnissen eine Liste ungültiger Objekte angezeigt. Dementsprechend werden sie im Cache als ungültig markiert, und alles funktioniert wie im Bild aus dem ersten Szenario.
Im zweiten Fall, wenn mehr Zeit als die Invalidierungsverzögerung vergangen ist, geht der client result_cache selbst in die Datenbank und sagt: "Geben Sie mir eine Liste der Änderungen!" Das heißt, er selbst behält seinen angemessenen Zustand bei.
Das Konfigurieren des clientseitigen Ergebniscaches ist sehr einfach . Es gibt 2 Möglichkeiten:
- CLIENT_RESULT_CACHE_LAG - Cache-Verzögerungswert;
- CLIENT_RESULT_CACHE_SIZE - Größe (mindestens 32 KB, maximal 2 GB).

Aus Sicht des Anwendungsentwicklers unterscheidet sich der Client-Cache nicht sehr vom Server-Cache, sondern sie haben auch den Hinweis result_cache eingegeben. Wenn dies der Fall ist, wird es nur vom Client verwendet - sowohl unter .NET als auch unter Java.

Nachdem ich 10 Iterationen der Abfrage durchgeführt hatte, erhielt ich Folgendes.

Der erste Aufruf ist die Erstellung, dann 9 Cache-Zugriffe. Die Tabelle zeigt an, dass der Speicher auch in Blöcken zugeordnet ist. Achten Sie auch auf SELECT - es ist nicht sehr intuitiv. Um ehrlich zu sein, bevor ich damit anfing, wusste ich nicht einmal, dass es eine solche Darstellung von
GV$SESSION_CONNECT_INFO . Warum Oracle es nicht direkt in diese Tabelle aufgenommen hat (und dies ist eine Tabelle, keine Ansicht), konnte ich nicht verstehen. Deshalb glaube ich, dass diese Funktionalität nicht sehr beliebt ist, obwohl sie meiner Meinung nach sehr nützlich ist.
Vorteile des Client-Caching:- billiger Client-Speicher;
- jeder verfügbare Treiber - JDBC, .NET usw.;
- minimale Auswirkung auf den Anwendungscode.
- Reduzierung der Belastung der CPU, der E / A und allgemein der Datenbank;
- Sie müssen nicht alle Arten von Smart-Caching-Ebenen und APIs lernen und verwenden.
- keine Riegel.
Nachteile:- Konsistenz beim Lesen mit Verzögerung - im Prinzip ist dies nun ein Trend;
- benötigen Oracle OCI Client;
- Beschränkung auf 2 GB pro Client, aber im Allgemeinen sind 2 GB viel;
- Für mich persönlich ist die Hauptbeschränkung ein paar Informationen über die Produktion.
Bei der Unterstützung, die wir immer bei der Arbeit mit result_cache verwenden, habe ich nur 5 Fehler gefunden. Dies deutet darauf hin, dass es höchstwahrscheinlich nur wenige Menschen brauchen.
Also bringen wir alles zusammen, was oben gesagt wurde.
Handgemachter Cache
Schlechte Szenarien:- Sofortige Änderung - Wenn der Cache nach dem Ändern der Daten sofort irrelevant wird. Bei selbst erstellten Caches ist es schwierig, bei Änderungen an den Objekten, auf denen sie basieren, die richtige Ungültigmachung zu erstellen.
- Wenn die Verwendung von in der Datenbank gespeicherter Logik durch Entwicklungsrichtlinien verboten ist.
Gute Szenarien:- Es gibt ein starkes Datenbankentwicklungsteam.
- Implementierte PL / SQL-Logik.
- Es gibt Einschränkungen, die verhindern, dass andere Caching-Techniken verwendet werden.
Serverseitiger Ergebniscache
Schlechte Szenarien:- Viele verschiedene Ergebnisse, die nur den gesamten Cache waschen;
- Anforderungen dauern länger als _RESULT_CACHE_TIMEOUT oder dieser Parameter ist falsch konfiguriert.
- Ergebnisse von sehr großen Sitzungen werden in parallelen Threads in den Cache geladen.
Gute Szenarien:- Angemessene Anzahl zwischengespeicherter Ergebnisse.
- Relativ kleine Datensätze (200–300 Zeilen).
- Ziemlich teures SQL, sonst wird die ganze Zeit an Latches gehen.
- Mehr oder weniger statische Tabellen.
- Es gibt einen DBA, der im Falle von etwas kommt und alle rettet.
Clientseitiger Ergebniscache
Schlechte Szenarien:- Wenn das Problem der sofortigen Behinderung auftritt.
- Dünne Treiber erforderlich.
Gute Szenarien:- Es gibt ein normales Entwicklungsteam für die mittlere Schicht.
- Es wird bereits viel SQL verwendet, ohne dass eine externe Caching-Schicht verwendet wird, die problemlos verbunden werden kann.
- Es gibt Einschränkungen für die Drüsen.
Schlussfolgerungen
Ich glaube, dass meine Geschichte über serverseitige Ergebnis-Cache-Schmerzen handelt, daher lauten die Schlussfolgerungen wie folgt:
- Bewerten Sie die Speichergröße immer korrekt unter Berücksichtigung der Anzahl der Abfragen und nicht der Anzahl der Ergebnisse, d. H.: Blöcke, APEX, Job, adaptive Statistiken usw.
- Haben Sie keine Angst, automatische Cache-Leergutoptionen (Snapshot + Shelflife) zu verwenden.
- Überladen Sie den Cache nicht mit Anforderungen, während Sie große Datenmengen laden. Deaktivieren Sie zuvor result_cache. Erwärmen Sie den Cache.
- Stellen Sie sicher, dass _result_cache_timeout Ihren Erwartungen entspricht.
- Verwenden Sie FORCE NIEMALS für die gesamte Datenbank. Benötigen Sie eine Datenbank im Speicher? Verwenden Sie eine spezielle In-Memory-Lösung.
- Überprüfen Sie, ob die FORCE-Option für einzelne Tabellen geeignet ist, damit sie nicht wie bei einer ETL eines Drittanbieters funktioniert.
- Entscheiden Sie, ob die adaptiven Statistiken so gut sind wie von Oracle beschrieben (_optimizer_ads_use_result_cache = false).
Highload ++ Siberia am kommenden Montag ist der Zeitplan fertig und wird auf der Site veröffentlicht. Es gibt mehrere Berichte zum Thema dieses Artikels:
- Alexander Makarov (CFT GC) wird am Beispiel der Oracle-Datenbank eine Methode zur Identifizierung von Engpässen auf der Serverseite der Software demonstrieren .
- Ivan Sharov und Konstantin Poluektov erklären Ihnen, welche Probleme bei der Migration des Produkts auf neue Versionen der Oracle-Datenbank auftreten, und versprechen , Empfehlungen zur Organisation und Durchführung solcher Arbeiten zu geben.
- Nikolay Golov erklärt Ihnen, wie Sie die Datenintegrität in einer Microservice-Architektur ohne verteilte Transaktionen und enge Konnektivität sicherstellen können.
Treffen Sie mich in Nowosibirsk!