Dieser Artikel konzentriert sich auf einige Suchalgorithmen und Beschreibungen bestimmter Bildpunkte. Hier wurde dieses Thema bereits mehr
als einmal angesprochen . Ich werde berücksichtigen, dass die grundlegenden Definitionen dem Leser bereits bekannt sind. Wir werden die heuristischen Algorithmen FAST, FAST-9, FAST-ER, BRIEF, rBRIEF, ORB im Detail untersuchen und die ihnen zugrunde liegenden funkelnden Ideen diskutieren. Zum Teil wird dies eine freie Übersetzung des Wesens mehrerer Artikel sein [1,2,3,4,5], es wird einen Code für "try" geben.

SCHNELLER Algorithmus
FAST, erstmals 2005 in [1] vorgeschlagen, war eine der ersten heuristischen Methoden zum Auffinden einzelner Punkte, die aufgrund ihrer Recheneffizienz große Popularität erlangte. Um zu entscheiden, ob ein bestimmter Punkt C als speziell betrachtet werden soll oder nicht, berücksichtigt diese Methode die Helligkeit von Pixeln auf einem Kreis, der auf Punkt C und Radius 3 zentriert ist:

Wenn wir die Helligkeit der Pixel des Kreises mit der Helligkeit des Zentrums C vergleichen, erhalten wir jeweils drei mögliche Ergebnisse (heller, dunkler, wie es scheint):
$ inline $ \ begin {array} {l} {I_p}> {I_C} + t \\ {I_p} <{I_C} -t \\ {I_C} -t <{I_p} <{I_C} + t \ end {array} $ inline $
Hier ist I die Helligkeit der Pixel, t ist eine vorbestimmte Helligkeitsschwelle.
Ein Punkt wird als speziell markiert, wenn in einer Reihe n = 12 Pixel dunkler oder 12 Pixel heller als die Mitte sind.
Wie die Praxis im Durchschnitt gezeigt hat, mussten für eine Entscheidung etwa 9 Punkte überprüft werden. Um den Prozess zu beschleunigen, schlugen die Autoren vor, zunächst nur vier Pixel mit Zahlen zu überprüfen: 1, 5, 9, 13. Wenn unter ihnen 3 Pixel heller oder dunkler sind, wird eine vollständige Überprüfung an 16 Punkten durchgeführt, andernfalls wird der Punkt sofort als „markiert nicht besonders. " Dies verkürzt die Arbeitszeit erheblich. Für eine Entscheidung im Durchschnitt reicht es aus, nur etwa 4 Punkte eines Kreises abzufragen.
Hier liegt ein bisschen naiver Code
Variable Parameter (im Code beschrieben): Kreisradius (nimmt die Werte 1,2,3 an), Parameter n (im Original n = 12), Parameter t. Der Code öffnet die Datei in.bmp, verarbeitet das Bild und speichert es in out.bmp. Bilder sind gewöhnliche 24-Bit.
Erstellen eines Entscheidungsbaums, Tree FAST, FAST-9
Im Jahr 2006 war es in [2] möglich, eine originelle Idee mithilfe von maschinellem Lernen und Entscheidungsbäumen zu entwickeln.
Das Original FAST hat folgende Nachteile:
- Mehrere benachbarte Pixel können als Sonderpunkte markiert werden. Wir brauchen ein gewisses Maß für die "Stärke" eines Features. Eine der ersten vorgeschlagenen Maßnahmen ist der Maximalwert von t, bei dem der Punkt noch als Sonderwert angenommen wird.
- Ein schneller 4-Punkte-Test wird nicht für n weniger als 12 verallgemeinert. So werden beispielsweise visuell die besten Ergebnisse der Methode mit n = 9 und nicht mit 12 erzielt.
- Ich möchte auch den Algorithmus beschleunigen!
Anstatt eine Kaskade von zwei Tests mit 4 und 16 Punkten zu verwenden, wird vorgeschlagen, alles in einem Durchgang durch den Entscheidungsbaum zu erledigen. Ähnlich wie bei der ursprünglichen Methode werden wir die Helligkeit des Mittelpunkts mit den Punkten auf dem Kreis vergleichen, aber in dieser Reihenfolge, um die Entscheidung so schnell wie möglich zu treffen. Und es stellt sich heraus, dass Sie im Durchschnitt nur für ~ 2 (!!!) Vergleiche eine Entscheidung treffen können.
Das Salz ist, wie man die richtige Reihenfolge für den Vergleich von Punkten findet. Finden Sie mit maschinellem Lernen. Angenommen, jemand hat für uns auf dem Bild viele Besonderheiten festgestellt. Wir werden sie als eine Reihe von Schulungsbeispielen verwenden, und die Idee ist,
eifrig diejenige auszuwählen, die in diesem Schritt die größte Menge an Informationen als nächsten Punkt liefert. Angenommen, anfangs gab es in unserer Stichprobe 5 singuläre Punkte und 5 nicht singuläre Punkte. In Form einer Tablette wie dieser:
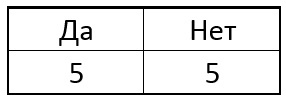
Jetzt wählen wir eines der Pixel p des Kreises und vergleichen für alle singulären Punkte das zentrale Pixel mit dem ausgewählten. Abhängig von der Helligkeit des ausgewählten Pixels in der Nähe jedes bestimmten Punkts kann die Tabelle das folgende Ergebnis haben:
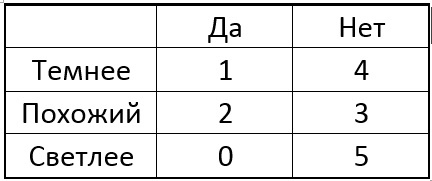
Die Idee ist, einen Punkt p so zu wählen, dass die Zahlen in den Spalten der Tabelle so unterschiedlich wie möglich sind. Und wenn wir jetzt für einen neuen unbekannten Punkt das Vergleichsergebnis „Leichter“ erhalten, können wir bereits sofort sagen, dass der Punkt „nicht speziell“ ist (siehe Tabelle). Der Prozess wird rekursiv fortgesetzt, bis die Punkte nur einer der Klassen in jede Gruppe fallen, nachdem sie in "dunkler wie heller" unterteilt wurden. Es stellt sich ein Baum der folgenden Form heraus:
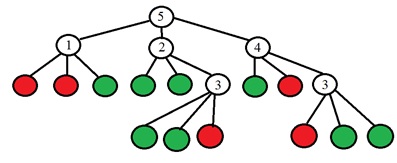
Der Binärwert befindet sich in den Blättern des Baums (Rot ist speziell, Grün ist nicht speziell) und an den anderen Eckpunkten des Baums befindet sich die Nummer des Punkts, der analysiert werden muss. Insbesondere schlagen sie im Originalartikel vor, die Punktnummer durch Ändern der Entropie zu wählen. Die Entropie der Punktmenge wird berechnet:
$$ display $$ H = \ left ({c + \ overline c} \ right) {\ log _2} \ left ({c + \ overline c} \ right) - c {\ log _2} c - \ overline c {\ log _2} \ overline c $$ display $$
c ist die Anzahl der singulären Punkte,
$ inline $ {\ bar c} $ inline $ Ist die Anzahl der nicht singulären Punkte der Menge
Entropieänderung nach Verarbeitungspunkt p:
$$ Anzeige $$ \ Delta H = H - {H_ {dunkel}} - {H_ {gleich}} - {H_ {hell}} $$ Anzeige $$
Dementsprechend wird ein Punkt ausgewählt, für den die Änderung der Entropie maximal ist. Der Aufteilungsprozess stoppt, wenn die Entropie Null ist, was bedeutet, dass alle Punkte entweder singulär sind oder umgekehrt - alle sind nicht speziell. Bei einer Software-Implementierung wird der gefundene Entscheidungsbaum nach alledem in eine Reihe von Konstruktionen vom Typ "if-else" konvertiert.
Der letzte Schritt des Algorithmus ist die Unterdrückung von Nichtmaxima, um einen von mehreren benachbarten Punkten zu erhalten. Die Entwickler schlagen vor, das ursprüngliche Maß basierend auf der Summe der absoluten Differenzen zwischen dem Mittelpunkt und den Punkten des Kreises in dieser Form zu verwenden:
$$ display $$ V = \ max \ left ({\ sum \ limit_ {x \ in {S_ {bright}}} {\ left | {{I_x} - {I_p}} \ right | - t, \ sum \ Limits_ {x \ in {S_ {dark}}} {\ left | {{I_p} - {I_x}} \ right | - t}}} \ right) $$ display $$
Hier
$ inline $ {S_ {bright}} $ inline $ und
$ inline $ {S_ {dark}} $ inline $ Gruppen von Pixeln sind heller und dunkler, t ist der Schwellenhelligkeitswert,
$ inline $ {I_p} $ inline $ - Helligkeit des zentralen Pixels,
$ inline $ {{I_x}} $ inline $ - Helligkeit des Pixels auf dem Kreis. Sie können den Algorithmus mit dem
folgenden Code ausprobieren. Der Code wird aus OpenCV übernommen und von allen Abhängigkeiten befreit. Führen Sie ihn einfach aus.
Entscheidungsbaum optimieren - FAST-ER
FAST-ER [3] ist ein Algorithmus der gleichen Autoren wie der vorherige, ein schneller Detektor ist ähnlich aufgebaut, die optimale Folge von Punkten wird ebenfalls zum Vergleich gesucht, ein Entscheidungsbaum wird ebenfalls erstellt, jedoch unter Verwendung einer anderen Methode - der Optimierungsmethode.
Wir verstehen bereits, dass ein Detektor als Entscheidungsbaum dargestellt werden kann. Wenn wir ein Kriterium zum Vergleichen der Leistung verschiedener Bäume hatten, können wir dieses Kriterium maximieren, indem wir verschiedene Baumvarianten sortieren. Als solches Kriterium wird vorgeschlagen, "Wiederholbarkeit" zu verwenden.
Die Wiederholbarkeit zeigt, wie gut die einzelnen Punkte einer Szene aus verschiedenen Winkeln erfasst werden. Für ein Paar von Bildern wird ein Punkt als "nützlich" bezeichnet, wenn er auf einem Rahmen gefunden wird und theoretisch auf einem anderen gefunden werden kann, d. H. Blockieren Sie nicht die Elemente der Szene. Und der Punkt heißt "wiederholt" (wiederholt), wenn er auch im zweiten Frame gefunden wird. Da die Kameraoptik nicht ideal ist, befindet sich der Punkt auf dem zweiten Bild möglicherweise nicht im berechneten Pixel, sondern irgendwo in der Nähe. Die Entwickler nahmen eine Nachbarschaft von 5 Pixeln. Wir definieren Wiederholbarkeit als das Verhältnis der Anzahl der wiederholten Punkte zur Anzahl der nützlichen:
$$ Anzeige $$ R = \ frac {{{N_ {wiederholt}}}} {{{N_ {nützlich}}} $$ Anzeige $$
Um den besten Detektor zu finden, wird eine Tempersimulationsmethode verwendet. Es gibt bereits einen
ausgezeichneten Artikel über Habré über ihn. Kurz gesagt, das Wesentliche der Methode ist wie folgt:
- Es wird eine erste Lösung für das Problem ausgewählt (in unserem Fall handelt es sich um eine Art Detektorbaum).
- Wiederholbarkeit wird berücksichtigt.
- Der Baum wird zufällig geändert.
- Wenn die modifizierte Version nach dem Kriterium der Wiederholbarkeit besser ist, wird die Modifikation akzeptiert, und wenn sie schlechter ist, kann sie mit einer gewissen Wahrscheinlichkeit, die von einer reellen Zahl namens "Temperatur" abhängt, entweder akzeptiert werden oder nicht. Mit zunehmender Anzahl von Iterationen fällt die Temperatur auf Null.
Außerdem umfasst der Aufbau des Detektors jetzt nicht mehr wie zuvor 16 Punkte des Kreises, sondern 47, aber die Bedeutung ändert sich überhaupt nicht:

Nach der simulierten Glühmethode definieren wir drei Funktionen:
• Kostenfunktion k. In unserem Fall verwenden wir die Wiederholbarkeit als Wert. Es gibt jedoch ein Problem. Stellen Sie sich vor, dass alle Punkte auf jedem der beiden Bilder als Singular erkannt werden. Dann stellt sich heraus, dass die Wiederholbarkeit 100% ist - Absurdität. Auf der anderen Seite, auch wenn wir einen bestimmten Punkt in zwei Bildern gefunden haben und diese Punkte übereinstimmen - die Wiederholbarkeit ist ebenfalls 100%, aber das interessiert uns auch nicht. Und deshalb schlugen die Autoren vor, dies als Qualitätskriterium zu verwenden:
$$ display $$ k = \ left ({1 + {{\ left ({\ frac {{{w_r}}} {R}} \ right)} ^ 2}} \ right) \ left ({1 + \ frac {1} {N} \ sum \ limit_ {i = 1} {{{\ left ({\ frac {{{d_i}}} {{{w_n}}} right)} ^ 2}} \ rechts) \ links ({1 + {{\ links ({\ frac {s} {{{w_s}}}} rechts)} ^ 2}} \ rechts) $$ display $$
r ist die Wiederholbarkeit
$ inline $ {{d_i}} $ inline $ Ist die Anzahl der erkannten Winkel auf Bild i, N ist die Anzahl der Bilder und s ist die Größe des Baums (Anzahl der Eckpunkte). W sind benutzerdefinierte Methodenparameter.]
• Funktion der Temperaturänderung über die Zeit:
$$ display $$ T \ left (I \ right) = \ beta \ exp \ left ({- \ frac {{\ alpha I}} {{{I _ {\ max}}} \ right) $$ display $$
wo
$ inline $ \ alpha, \ beta $ inline $ Sind die Koeffizienten, ist Imax die Anzahl der Iterationen.
• Eine Funktion, die eine neue Lösung generiert. Der Algorithmus nimmt zufällige Änderungen am Baum vor. Wählen Sie zunächst einen Scheitelpunkt aus. Wenn der ausgewählte Scheitelpunkt ein Blatt eines Baumes ist, gehen wir mit gleicher Wahrscheinlichkeit wie folgt vor:
- Ersetzen Sie den Scheitelpunkt durch einen zufälligen Teilbaum mit der Tiefe 1
- Ändern Sie die Klasse dieses Blattes (Singular-Nicht-Singular-Punkte)
Wenn dies KEIN Blatt ist:
- Ersetzen Sie die Nummer des getesteten Punktes durch eine Zufallszahl von 0 bis 47
- Ersetzen Sie den Scheitelpunkt durch ein Blatt mit einer zufälligen Klasse
- Tauschen Sie zwei Teilbäume von diesem Scheitelpunkt aus
Die Wahrscheinlichkeit P, die Änderung bei Iteration I zu akzeptieren, ist:
$ inline $ P = \ exp \ left ({\ frac {{k \ left ({i - 1} \ right) - k \ left (i \ right)}} {T}} \ right) $ inline $
k ist die Kostenfunktion, T ist die Temperatur, i ist die Iterationszahl.
Diese Änderungen am Baum ermöglichen sowohl das Wachstum des Baumes als auch dessen Reduzierung. Die Methode ist zufällig und garantiert nicht, dass der beste Baum erhalten wird. Führen Sie die Methode viele Male aus und wählen Sie die beste Lösung aus. Im Originalartikel werden sie beispielsweise 100 Mal pro 100.000 Iterationen ausgeführt, was 200 Stunden Prozessorzeit in Anspruch nimmt. Wie die Ergebnisse zeigen, ist das Ergebnis besser als Tree FAST, insbesondere bei verrauschten Bildern.
KURZER Deskriptor
Nachdem die singulären Punkte gefunden wurden, werden ihre Deskriptoren berechnet, d.h. Sätze von Merkmalen, die die Nachbarschaft jedes einzelnen Punktes charakterisieren. BRIEF [4] ist ein schneller heuristischer Deskriptor, der aus 256 binären Vergleichen zwischen der Helligkeit der Pixel in einem
verschwommenen Bild aufgebaut ist. Der binäre Test zwischen den Punkten x und y ist wie folgt definiert:
$$ display $$ \ tau \ left ({P, x, y} \ right): = \ left \ {{\ begin {array} {* {20} {c}} {1: p \ left (x \ rechts) <p \ left (y \ right)} \\ {0: p \ left (x \ right) \ ge p \ left (y \ right)} \ end {array}} \ right. $$ display $$

Im ursprünglichen Artikel wurden verschiedene Methoden zur Auswahl von Punkten für binäre Vergleiche berücksichtigt. Wie sich herausstellte, besteht eine der besten Möglichkeiten darin, Punkte mithilfe einer Gaußschen Verteilung um ein zentrales Pixel zufällig auszuwählen. Diese zufällige Folge von Punkten wird einmal ausgewählt und ändert sich nicht weiter. Die Größe der betrachteten Nachbarschaft des Punktes beträgt 31 x 31 Pixel, und die Unschärfeöffnung beträgt 5.
Der resultierende binäre Deskriptor ist resistent gegen Änderungen der Beleuchtung, perspektivische Verzerrungen, wird schnell berechnet und verglichen, ist jedoch sehr instabil gegenüber Rotationen in der Bildebene.
ORB - schnell und effizient
Die Entwicklung all dieser Ideen war der ORB-Algorithmus (Oriented FAST and Rotated BRIEF) [5], bei dem versucht wurde, die BRIEF-Leistung während der Bildrotation zu verbessern. Es wird vorgeschlagen, zuerst die Orientierung des Singularpunkts zu berechnen und dann binäre Vergleiche gemäß dieser Orientierung durchzuführen. Der Algorithmus funktioniert folgendermaßen:
1) Feature-Punkte werden mithilfe des schnellen FAST-Baums im Originalbild und in mehreren Bildern aus der Miniaturpyramide erkannt.
2) Für die erkannten Punkte wird das Harris-Maß berechnet, Kandidaten mit einem niedrigen Wert des Harris-Maßes werden verworfen.
3) Der Orientierungswinkel des Singularpunktes wird berechnet. Dazu werden zunächst die Helligkeitsmomente für die Nachbarschaft des Singularpunktes berechnet:
$ inline $ {m_ {pq}} = \ sum \ limit_ {x, y} {{x ^ p} {y ^ q} I \ left ({x, y} \ right)} $ inline $
x, y - Pixelkoordinaten, I - Helligkeit. Und dann der Orientierungswinkel des singulären Punktes:
$ inline $ \ theta = {\ rm {atan2}} \ left ({{m_ {01}}, {m_ {10}}} \ right) $ inline $
All dies nannten die Autoren die "Schwerpunktorientierung". Als Ergebnis erhalten wir eine bestimmte Richtung für die Nachbarschaft des singulären Punktes.
4) Mit dem Orientierungswinkel des Singularpunkts dreht sich die Folge von Punkten für binäre Vergleiche im BRIEF-Deskriptor entsprechend diesem Winkel, zum Beispiel:
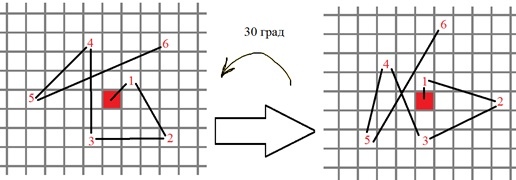
Formal werden die neuen Positionen für die binären Testpunkte wie folgt berechnet:
$$ display $$ \ left ({\ begin {array} {* {20} {c}} {{x_i} '} \\ {{y_i}'} \ end {array}} \ right) = R \ left (\ theta \ right) \ cdot \ left ({\ begin {array} {* {20} {c}} {{x_i}} \\ {{y_i}} \ end {array}} \ right) $$ Anzeige $$
5) Basierend auf den empfangenen Punkten wird der BRIEF-Binärdeskriptor berechnet
Und das ist ... nicht alles! Es gibt ein weiteres interessantes Detail in ORB, das einer gesonderten Erläuterung bedarf. Tatsache ist, dass in dem Moment, in dem wir alle singulären Punkte auf einen Nullwinkel „drehen“, die zufällige Auswahl von binären Vergleichen im Deskriptor nicht mehr zufällig ist. Dies führt dazu, dass sich erstens einige binäre Vergleiche als voneinander abhängig herausstellen und zweitens ihr Durchschnitt nicht mehr gleich 0,5 ist (1 ist heller, 0 ist dunkler, wenn die Auswahl zufällig war, es war durchschnittlich 0,5). All dies verringert die Fähigkeit des Deskriptors, einzelne Punkte untereinander zu unterscheiden, erheblich.
Lösung - Sie müssen im Lernprozess die „richtigen“ Binärtests auswählen. Diese Idee hat den gleichen Geschmack wie das Baumtraining für den FAST-9-Algorithmus. Angenommen, wir haben bereits eine Reihe einzelner Punkte gefunden. Berücksichtigen Sie alle möglichen Optionen für binäre Tests. Wenn die Nachbarschaft 31 x 31 ist und der Binärtest ein Paar von 5 x 5 Teilmengen ist (aufgrund von Unschärfe), gibt es viele Optionen für die Auswahl von N = (31-5) ^ 2. Der Suchalgorithmus für "gute" Tests lautet wie folgt:
- Wir berechnen das Ergebnis aller Tests für alle singulären Punkte
- Ordnen Sie die gesamte Testreihe entsprechend ihrem Abstand vom Durchschnitt von 0,5 an
- Erstellen Sie eine Liste mit den ausgewählten "guten" Tests. Rufen Sie die Liste R auf.
- Fügen Sie den ersten Test aus dem sortierten Satz zu R hinzu
- Wir nehmen den nächsten Test und vergleichen ihn mit allen Tests in R. Wenn die Korrelation größer als der Schwellenwert ist, verwerfen wir den neuen Test, andernfalls fügen wir ihn hinzu.
- Wiederholen Sie Schritt 5, bis Sie die erforderliche Anzahl von Tests eingegeben haben.
Es stellt sich heraus, dass die Tests so ausgewählt werden, dass einerseits der Durchschnittswert dieser Tests so nahe wie möglich bei 0,5 liegt, andererseits die Korrelation zwischen verschiedenen Tests minimal ist. Und das brauchen wir. Vergleichen Sie, wie es war und wie es wurde:
Glücklicherweise ist der ORB-Algorithmus in der OpenCV-Bibliothek in der Klasse cv :: ORB implementiert. Ich benutze Version 2.4.13. Der Klassenkonstruktor akzeptiert die folgenden Parameter:
nfeatures - maximale Anzahl von Einzelpunkten
scaleFactor - Multiplikator für die Bildpyramide, mehr als eine. Wert 2 implementiert die klassische Pyramide.
Ebenen - die Anzahl der Ebenen in der Bildpyramide.
edgeThreshold - Die Anzahl der Pixel am Bildrand, an denen einzelne Punkte nicht erkannt werden.
firstLevel - lass Null.
WTA_K - Die Anzahl der Punkte, die für ein Element des Deskriptors erforderlich sind. Wenn gleich 2, wird die Helligkeit von zwei zufällig ausgewählten Pixeln verglichen. Dies ist, was benötigt wird.
scoreType - wenn 0, dann wird harris als Merkmalsmaß verwendet, andernfalls - das FAST-Maß (basierend auf der Summe der Module der Helligkeitsunterschiede an den Punkten des Kreises). Das FAST-Maß ist etwas weniger stabil, aber schneller.
patchSize - Die Größe der Nachbarschaft, aus der zufällige Pixel zum Vergleich ausgewählt werden. Der Code sucht und vergleicht die einzelnen Punkte in zwei Bildern, "templ.bmp" und "img.bmp".
Codecv::Mat img_object=cv::imread("templ.bmp", 0); std::vector<cv::KeyPoint> keypoints_object, keypoints_scene; cv::Mat descriptors_object, descriptors_scene; cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
Wenn jemand geholfen hat, die Essenz der Algorithmen zu verstehen, ist dies nicht umsonst. An alle Habr.
Referenzen:
1. Zusammenführen von
Punkten und Linien für die Hochleistungsverfolgung2.
Maschinelles Lernen zur schnellen Kurvenerkennung3.
Schneller und besser: Ein Ansatz des maschinellen Lernens zur Eckenerkennung4.
KURZDARSTELLUNG: Binär robuste, unabhängige Elementarfunktionen5.
ORB: eine effiziente Alternative zu SIFT oder SURF