Expressivität ist eine interessante Eigenschaft von Programmiersprachen. Durch einfaches Kombinieren von Ausdrücken können Sie beeindruckende Ergebnisse erzielen. Einige Sprachen lehnen die Idee der Ausdruckskraft absichtlich ab, aber Kotlin ist definitiv keine solche Sprache.
Mit einfachen Sprachkonstrukten und etwas Zucker werden wir versuchen, die SQL in Kotlin-Syntax so nah wie möglich neu zu erstellen.

GitHub Link für Ungeduldige
Unser Ziel ist es, dem Programmierer zu helfen, eine bestimmte Teilmenge von Fehlern in der Kompilierungsphase zu erkennen. Kotlin ist eine stark typisierte Sprache, die uns hilft, ungültige Ausdrücke in der Struktur der SQL-Abfrage zu entfernen. Als Bonus erhalten wir mehr Tippfehlerschutz und Hilfe von der IDE beim Schreiben von Anfragen. Es ist nicht möglich, SQL-Fehler vollständig zu beheben, aber es ist durchaus möglich, einige Problembereiche zu beheben.
In diesem Artikel erfahren Sie mehr über die Kotlin-Bibliothek, mit der Sie SQL-Abfragen in Kotlin-Syntax schreiben können. Wir werfen auch einen Blick auf die Innenseiten der Bibliothek, um zu verstehen, wie dies funktioniert.
Ein bisschen Theorie
SQL steht für Structured Query Language, d. H. Die Struktur der Abfragen ist vorhanden, obwohl die Syntax schlecht ist. Die Sprache wurde so erstellt, dass sie von jedem Benutzer verwendet werden kann, der nicht einmal über Programmierkenntnisse verfügt.
Unter SQL liegt jedoch eine ziemlich mächtige Grundlage in Form der Theorie relationaler Datenbanken - dort ist alles sehr logisch. Um die Struktur von Abfragen zu verstehen, wenden wir uns einer einfachen Auswahl zu:
SELECT id, name
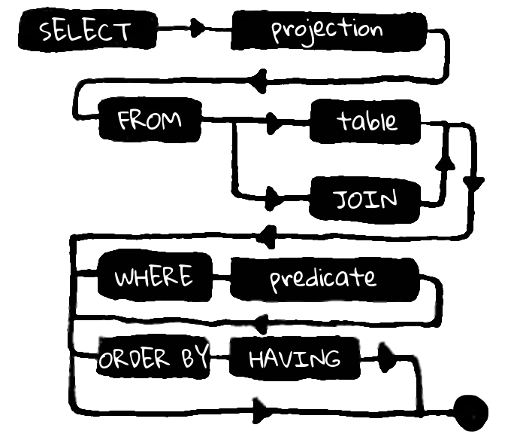
Was ist wichtig zu verstehen: Die Anfrage besteht aus drei aufeinander folgenden Teilen. Jeder dieser Teile hängt zum einen vom vorherigen ab und zum anderen impliziert er einen begrenzten Satz von Ausdrücken, um die Anforderung fortzusetzen. Tatsächlich ist es nicht einmal ganz so: Der FROM-Ausdruck hier ist eindeutig primär in Bezug auf SELECT, weil Welche Felder wir auswählen können, hängt von der Tabelle ab, aus der die Auswahl getroffen wird, aber nicht umgekehrt.
Portierung nach Kotlin
Daher ist FROM in Bezug auf alle anderen Abfragesprachenkonstrukte primär. Aus diesem Ausdruck ergeben sich alle möglichen Optionen zum Fortsetzen der Abfrage. In Kotlin reflektieren wir dies durch die from (T) -Funktion, die ein Eingabeobjekt verwendet, bei dem es sich um eine Tabelle mit einer Reihe von Spalten handelt.
object Employees : Table("employees") { val id = Column("id") val name = Column("name") val organizationId = Column("organization_id") }
Die Funktion gibt ein Objekt zurück, das Methoden enthält, die die mögliche Fortsetzung der Anforderung widerspiegeln. Das from-Konstrukt steht immer an erster Stelle vor allen anderen Ausdrücken, daher umfasst es eine große Anzahl von Erweiterungen, einschließlich des endgültigen SELECT (im Gegensatz zu SQL, bei dem SELECT immer vor FROM steht). Der Code, der der obigen SQL-Abfrage entspricht, sieht folgendermaßen aus:
from(Employees) .where { e -> e.organizationId eq 1 } .select { e -> e.id .. e.name }
Interessanterweise können wir auf diese Weise auch zur Kompilierungszeit ungültiges SQL verhindern. Jeder Ausdruck, jeder Methodenaufruf in der Kette impliziert eine begrenzte Anzahl von Erweiterungen. Wir können die Gültigkeit der Anfrage mit der Kotlin-Sprache kontrollieren. Beispielsweise impliziert der where-Ausdruck keine Fortsetzung in Form eines anderen where und darüber hinaus from, sondern die groupBy-Konstrukte mit orderBy, limit, offset und final select sind alle gültig.
Lambdas wurden als Argumente an die Anweisungen where und select übergeben, um das Prädikat bzw. die Projektion zu konstruieren (wir haben sie bereits erwähnt). Eine Tabelle wird an die Lambda-Eingabe übergeben, damit Sie auf die Spalten zugreifen können. Es ist wichtig, dass die Typensicherheit auch auf dieser Ebene erhalten bleibt. Mithilfe der Operatorüberladung können wir sicherstellen, dass das Prädikat letztendlich ein pseudo-boolescher Ausdruck ist, der nicht kompiliert werden kann, wenn ein Syntaxfehler oder ein typbezogener Fehler vorliegt. Gleiches gilt für die Projektion.
fun where(predicate: (T) -> Predicate): WhereClause<T> fun select(projection: (T) -> Iterable<Projection>): SelectStatement<T>
Mitmachen
Mit relationalen Datenbanken können Sie mit vielen Tabellen und den Beziehungen zwischen ihnen arbeiten. Es wäre schön, dem Entwickler die Möglichkeit zu geben, mit JOIN in unserer Bibliothek zu arbeiten. Glücklicherweise passt das relationale Modell gut zu allem, was zuvor beschrieben wurde - Sie müssen nur die Join-Methode hinzufügen, die unserem Ausdruck eine zweite Tabelle hinzufügt.
fun <T2: Table> join(table2: T2): JoinClause<T, T2>
In diesem Fall verfügt JOIN über Methoden, die denen des FROM-Ausdrucks ähneln. Der einzige Unterschied besteht darin, dass Projektions- und Prädikat-Lambdas jeweils zwei Parameter benötigen, um auf die Spalten beider Tabellen zugreifen zu können.
from(Employees) .join(Organizations).on { e, o -> o.id eq e.organizationId } .where { e, o -> e.organizationId eq 1 } .select { e, o -> e.id .. e.name .. o.name }
Datenverwaltung
Die Datenbearbeitungssprache ist ein SQL-Sprachtool, mit dem Sie neben der Abfrage von Tabellen auch Daten einfügen, ändern und löschen können. Diese Designs passen gut zu unserem Modell. Um das Aktualisieren und Löschen zu unterstützen, müssen wir nur die from- und where-Ausdrücke durch eine Variante mit dem Aufruf der entsprechenden Methoden ergänzen. Um das Einfügen zu unterstützen, führen wir eine zusätzliche Funktion ein.
from(Employees) .where { e -> e.id eq 1 } .update { e -> e.name("John Doe") } from(Employees) .where { e -> e.id eq 0 } .delete() into(Employees) .insert { e -> e.name("John Doe") .. e.organizationId(1) }
Datenbeschreibung
SQL arbeitet mit strukturierten Daten in Form von Tabellen. Tabellen erfordern eine Beschreibung, bevor Sie mit ihnen arbeiten können. Dieser Teil der Sprache wird als Datendefinitionssprache bezeichnet.
Die Anweisungen CREATE TABLE und DROP TABLE sind ähnlich implementiert - die Over-Funktion dient als Ausgangspunkt.
over(Employees) .create { integer(it.id).primaryKey(autoIncrement = true).. text(it.name).unique().notNull().. integer(it.organizationId).foreignKey(references = Organizations.id) }
over(Employees).drop()