Nachdem ich den Artikel "
Google Neural Machine Translation " gelesen hatte, erinnerte ich mich an die neueste epische maschinelle Übersetzung von Google, die kürzlich im Internet ausgeführt wurde. Wer nicht lange warten kann, geht sofort zum Ende des Artikels.
Nun, für den Anfang eine kleine Theorie:
GNMT ist Googles
NMT- System (Neural Machine Translation), das ein neuronales Netzwerk (
ANN ) verwendet, um die Genauigkeit und Geschwindigkeit der Übersetzung zu erhöhen und insbesondere bessere, natürlichere Übersetzungsoptionen für Text in Google Translate zu erstellen.
Im Fall von GNMT ist dies das sogenannte beispielbasierte Übersetzungsverfahren (
EBMT ), d.h.
Die der Methode zugrunde liegende
ANN lernt aus Millionen von Übersetzungsbeispielen, und im Gegensatz zu anderen Systemen ermöglicht diese Methode die sogenannte
Zero-Shot-Übersetzung , dh die Übersetzung von einer Sprache in eine andere ohne explizite Beispiele für dieses Paar spezifischer Sprachen im Lernprozess (im Trainingsbeispiel).
 Abb. 1. Zero-Shot-Übersetzung
Abb. 1. Zero-Shot-ÜbersetzungDarüber hinaus soll GNMT in erster Linie die Übersetzung von Phrasen und Sätzen verbessern, weil Nur in der Kontextübersetzung können Sie die wörtliche Version der Übersetzung nicht verwenden, und oft wird der Satz völlig anders übersetzt.
Bei der Rückkehr zur Zero-Shot-Übersetzung versucht Google außerdem, eine gemeinsame Komponente hervorzuheben, die für mehrere Sprachen gleichzeitig gültig ist (sowohl bei der Suche nach Abhängigkeiten als auch beim Aufbau von Beziehungen für Sätze und Phrasen).
In Abbildung 2 ist diese Interlingua-Community beispielsweise unter allen möglichen Paaren für Japanisch, Koreanisch und Englisch dargestellt.
 Abb. 2. Interlingua. 3-dimensionale Darstellung von Netzwerkdaten für Japanisch, Koreanisch und Englisch
Abb. 2. Interlingua. 3-dimensionale Darstellung von Netzwerkdaten für Japanisch, Koreanisch und Englisch .
Teil (a) zeigt die allgemeine "Geometrie" solcher Übersetzungen, wobei die Punkte nach Bedeutung gefärbt sind (und dieselbe Farbe für dieselbe Bedeutung in mehreren Sprachpaaren).
Teil (b) zeigt eine Zunahme in einer der Gruppen, Teil © in den Farben der Originalsprache.
GNMT verwendet das große
ANN Deep Learning (
DNN ), das anhand von Millionen von Beispielen die Qualität der Übersetzung verbessern und die kontextbezogene abstrakte Approximation für die am besten geeignete Übersetzungsoption anwenden sollte. Grob gesagt wählt er das beste Ergebnis im Sinne der am besten geeigneten Grammatik der menschlichen Sprache aus, wobei er die Gemeinsamkeit des Aufbaus von Verknüpfungen, Phrasen und Sätzen für mehrere Sprachen berücksichtigt (d. H. Das Interlingua-Modell oder die Interlingua-Ebenen separat hervorhebt und lehrt).
DNN beruht jedoch sowohl im Lernprozess als auch im Arbeitsprozess normalerweise auf statistischen (probabilistischen) Schlussfolgerungen und ist selten an zusätzliche nicht-probabilistische Algorithmen gebunden. Das heißt, Um das bestmögliche Ergebnis zu bewerten, das aus dem Variator hervorgegangen ist, wird die statistisch beste (wahrscheinliche) Option ausgewählt.
All dies hängt natürlich zusätzlich von der Qualität der Trainingsprobe (und / oder der Qualität der Algorithmen bei einem selbstlernenden Modell) ab.
In Anbetracht der Zero-Shot-Übersetzungsmethode und der Erinnerung an eine bestimmte Interlingua-Komponente trat bei Vorhandensein einer positiven logischen Tiefenverbindung für eine Sprache und des Fehlens negativer Komponenten für andere Sprachen ein abstrakter Fehler im Lernprozess auf, und infolgedessen Die Übersetzung einer bestimmten Phrase für eine Sprache wird höchstwahrscheinlich für andere Sprachen oder sogar Sprachpaare wiederholt.
Eigentlich frisches episches Versagen
Alle Bilder können angeklickt werden (als Beweis auf der entsprechenden Google Translate-Seite).Deutsch: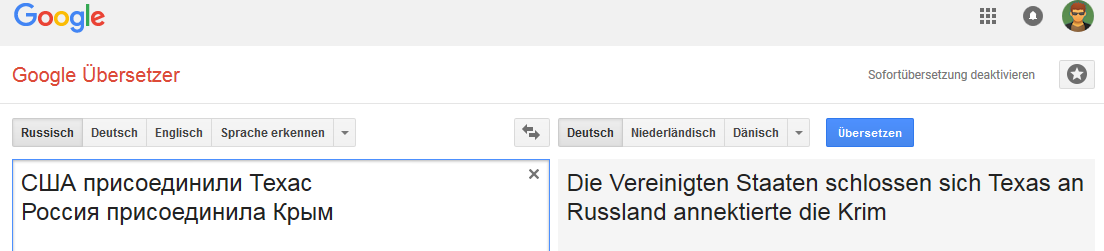 Englisch:
Englisch: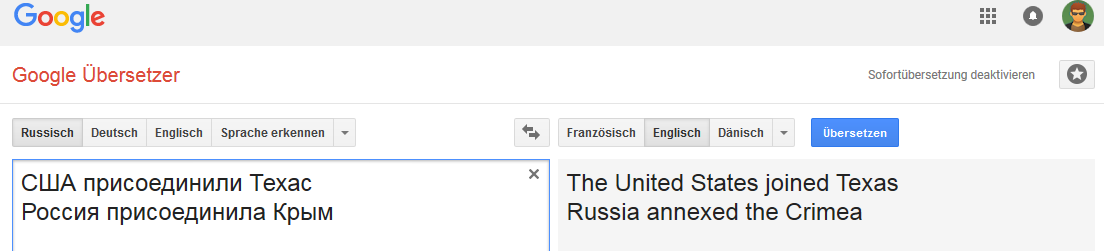 Niederländisch:
Niederländisch: Dänisch:
Dänisch: Französisch:
Französisch:
Usw.
Anstelle einer Schlussfolgerung
Die Verbindung ist für das Wort Russland stabil (in dem Sinne, dass sich die Option „Übertragung“ ändert, wenn Russland beispielsweise durch das russische Reich ersetzt wird).
Und es ist nicht sehr stabil mit bestimmten Änderungen an Phrasen, die nicht typisch für die Übersetzung ins Englische sind, aber beispielsweise für Russisch, Deutsch und Niederländisch üblich sind.
Dies ist leider alles andere als der einzige Fall und das Internet ist voll von allen Arten von Google Translate-Fehlern.
Und es scheint mir, dass sich ein beträchtlicher Teil der vorhandenen Fehler aufgrund einer Kombination mehrerer Faktoren manifestiert, die von der Qualität der Trainingsstichprobe bis zur Qualität der semantischen und morphologischen Analysealgorithmen für eine bestimmte Sprache (und insbesondere des Lernmodells) reichen.
Einmal schlug ein Kollege vor, an der Google Text Normalization Challenge (für Russisch und Englisch) auf kaggle teilzunehmen ...
Bevor ich zustimmte, führte ich eine kleine Analyse der Qualität des Trainingstestmusters für alle Token-Klassen für beide Sprachen durch. Infolgedessen weigerte ich mich, überhaupt teilzunehmen, denn je mehr ich grub, desto stärker war das Gefühl, dass der Wettbewerb wie eine Lotterie aussehen würde oder derjenige, der gewann Am genauesten können alle Fehler wiederholt werden, die bei der halbmanuellen Erstellung des Google-Trainingssatzes gemacht wurden.
Ich wollte sogar einen Artikel zum Thema "Wie man einfach 50K wirft ..." schreiben, aber Zeit - sei es okay.
Wenn jemand plötzlich interessiert ist, werde ich versuchen, ein wenig herauszuarbeiten.
[UPD] Warum ist das eigentlich eine Datei
? Ohne von den Texten, dem „politischen“ Subtext und allen möglichen Versuchen, „eine Person würde auf diese Weise übersetzen“ usw. Themen abzulenken.
1. Dies ist eine falsche Übersetzung. Der Punkt.
2. In diesem veranschaulichenden Fall zeigt GNMT das völlige Fehlen eines Klassifizierungsmodells (im Sinne von
CADM , in dem Google glänzen muss, weil es viele Daten von überall hat). Nur insofern, als die Subjekte in beiden Fällen Länder / Staaten sind und die Ergänzungen geografische Einheiten (Territorium) sind.
Selbst die dümmste Plausibilitätsregel einer unscharfen K-nn-Klassifikation hätte niemals einen solchen Fehler gemacht. Über moderne Algorithmen zur Klassifizierung und Konstruktion (semantischer) Beziehungen schweigen wir bereits.
Wie das Sprichwort sagt, ist nichts Persönliches, einfache Mathematik ... Nun, wenn Google wahllos beschlossen hat, sein Netzwerk mit Ausschnitten aus der Boulevardpresse zu versorgen, dann habe ich schlechte Nachrichten für ihn.
PS Wie ein Professor, den ich respektierte, einmal zu mir sagte: "Es ist manchmal sehr schwierig, einem Specht zu beweisen, dass er ein Specht ist, besonders wenn er sicher ist, dass er schlauer als ein Professor ist."