Massachusetts Institute of Technology. Vorlesung # 6.858. "Sicherheit von Computersystemen." Nikolai Zeldovich, James Mickens. 2014 Jahr
Computer Systems Security ist ein Kurs zur Entwicklung und Implementierung sicherer Computersysteme. Die Vorträge behandeln Bedrohungsmodelle, Angriffe, die die Sicherheit gefährden, und Sicherheitstechniken, die auf jüngsten wissenschaftlichen Arbeiten basieren. Zu den Themen gehören Betriebssystemsicherheit, Funktionen, Informationsflussmanagement, Sprachsicherheit, Netzwerkprotokolle, Hardwaresicherheit und Sicherheit von Webanwendungen.
Vorlesung 1: „Einführung: Bedrohungsmodelle“
Teil 1 /
Teil 2 /
Teil 3Vorlesung 2: „Kontrolle von Hackerangriffen“
Teil 1 /
Teil 2 /
Teil 3 James Mickens: In der vorherigen Vorlesung haben wir alles über Pufferüberlaufangriffe gelernt, und heute werden wir einige Methoden zum Starten dieser Angriffe weiter diskutieren. Die Grundidee hinter einem Pufferüberlaufangriff lautet wie folgt.

Zunächst stelle ich fest, dass diese Angriffe verschiedene Umstände betreffen. Der erste Umstand, den sie verwenden, ist, dass Systemsoftware häufig in C geschrieben ist.
Mit Systemsoftware meine ich Datenbanken, Compiler, Netzwerkserver und dergleichen. Sie können sich an so etwas wie Ihre Lieblingsbefehlsshell erinnern. All diese „Software“ ist normalerweise in C geschrieben. Warum in C? Zum einen ist es schneller und zum anderen gilt C als Assembler auf hoher Ebene, der die Anforderungen einer Vielzahl von Hardwareplattformen am besten erfüllt. Daher sind alle kritischen Systeme in dieser einfachen Programmiersprache geschrieben. Das Problem mit in C geschriebener Software besteht darin, dass sie wirklich Rohspeicheradressen verwendet und keine Tools oder Softwaremodule zum Überprüfen dieser Adressen hat. In einigen Fällen kann dies katastrophale Folgen haben.
Warum gibt es in C keine Array-Indexprüfung, dh keine Randprüfung? Ein Grund ist, dass die Hardware dies nicht tut. Und Leute, die in C schreiben, wollen normalerweise die schnellstmögliche Programmausführungsgeschwindigkeit. Ein weiterer Grund ist, dass es in C, wie wir später diskutieren, tatsächlich sehr schwierig ist, die Semantik zu definieren, was ein Zeiger ist und inwieweit er wirken sollte. Daher wäre es in einigen Fällen sehr schwierig, Softwareprozesse in C zu automatisieren.
Lassen Sie uns einige Technologien diskutieren, die tatsächlich versuchen, eine Art automatische Speicherverwaltung zu erstellen. Aber wie wir sehen werden, ist keine dieser Methoden vollständig „kugelsicher“.
Darüber hinaus verwenden Pufferüberlaufangriffe x86-Kenntnisse der Architektur, z. B. in welche Richtung der Stapel wächst. Was ist eine Aufrufkonvention für Funktionen? Wie sieht der Stapel aus, wenn Sie auf Funktion C zugreifen? Und wie sehen diese ausgewählten Hauptstrukturen aus, wenn Sie ein Objekt auf dem Heap auswählen?
Schauen wir uns ein einfaches Beispiel an. Dies ist sehr ähnlich zu dem, was Sie in der letzten Vorlesung gesehen haben. Also, hier haben wir eine Standard-Leseanforderung, und dann bekommen wir einen Puffer, hier kommt das kanonische
int i , gefolgt vom berüchtigten get-Befehl. Und unten haben wir andere notwendige Dinge.

Wie wir letzte Woche in der Vorlesung besprochen haben, ist das problematisch, oder? Da dies
eine Operation erhält, werden die Puffergrenzen nicht überprüft. Wenn der Benutzer den Puffer mit Daten füllt und wir diese unsichere Funktion hier verwenden, können wir den Puffer tatsächlich überlaufen lassen. Wir können den gesamten Inhalt des Stapels neu schreiben. Ich möchte Sie daran erinnern, wie es aussieht.
Ganz unten befindet sich das Array "i". Ein Puffer befindet sich darüber, er hat die erste Adresse unten und die letzte oben. In jedem Fall haben wir über dem Puffer den gespeicherten Wert des Lückenindikators - den gespeicherten Wert EBP. Darüber befindet sich die Rücksprungadresse für die Funktion, und noch höher sind einige Dinge aus dem vorherigen Frame.
Und vergessen Sie nicht, dass hier unten links von "i" ein ESP-Stapelzeiger angezeigt wird und ein neuer Unterbrechungszeiger im gespeicherten EBP-Bereich angezeigt wird. Die Rücksprungadresse enthält ESP, und der Rest des vorherigen Frames enthält einen Haltepunkt.

Ich möchte Sie daran erinnern, dass der Stapel überläuft, indem Daten in Richtung dieses Pfeils nach rechts nach oben gesammelt werden. Wenn die get-Operation gestartet wird, beginnen wir, Bytes in den Puffer zu schreiben. Am Ende beginnt sie, alles zu überschreiben, was sich stromaufwärts befindet. Grundsätzlich sollte Ihnen alles bekannt vorkommen.
Was unternimmt ein Angreifer, um dies auszunutzen? Grundsätzlich wird eine lange Datenfolge eingegeben. Daher ist die Schlüsselidee, dass eine solche Technik verwendet werden kann, um anzugreifen.
Und wenn die Rücksprungadresse vom Angreifer erfasst wird, kann er bestimmen, wohin die Funktion nach dem Überlauf springen wird. Das heißt, das einzige, was ein Hacker tun kann, ist, die Absenderadresse abzufangen und zu springen, wohin er will. Meistens führen Angreifer Code mit Berechtigungen aus, um den Abfangprozess zu steuern.
Wenn dieser Prozess beispielsweise eine hohe Priorität hatte, wurde er als Root oder Administrator ausgeführt, unabhängig davon, wie wir den Superuser Ihres bevorzugten Betriebssystems nennen. Jetzt kann dieses Programm, das von einem Angreifer gesteuert wird, mit den Berechtigungen dieser Priorität alles tun, was es will. So kann ein Hacker Dateien lesen oder Spam senden, wenn er einen Mailserver beschädigt hat. Es kann sogar Firewalls besiegen, da die Idee einer Firewall darin besteht, dass sich dahinter „gute“ und dahinter „schlechte“ Maschinen befinden. In der Regel „vertrauen“ sich die Computer in der Firewall gegenseitig. Wenn Sie es schaffen, mindestens einen Computer in einem durch eine Firewall geschützten Netzwerk zu hacken, ist dies großartig. Denn jetzt können Sie einfach die vielen Überprüfungen überspringen, die diese Computer normalerweise in Bezug auf "fremde" Maschinen durchführen, da sie Sie als vertrauenswürdige Person betrachten.
Es gibt eine Sache, über die Sie nachdenken müssten und die ich mir als Student vorgestellt habe:
„Großartig, sie haben uns gezeigt, wie man den Puffer überläuft, aber warum kann das Betriebssystem dies nicht stoppen? Handelt sie nicht als jemand wie die Wächter der Galaxis, der das Gute vor bösen Dingen schützt? "
Es ist wichtig zu beachten, dass das Betriebssystem Sie nicht ständig überwacht. Und die Hardware beobachtet, extrahiert Anweisungen und entschlüsselt sie und macht vieles Ähnliches. Aber was macht das Betriebssystem in erster Näherung? Grundsätzlich werden Seitentabellen eingerichtet, mit denen die Anwendung arbeiten kann. Wenn Sie das Betriebssystem beispielsweise auffordern, ein Netzwerkpaket zu senden, oder eine IPC-Anfrage oder ähnliches stellen möchten, wenden Sie sich an das Betriebssystem, um Hilfe zu erhalten. Das Betriebssystem befolgt jedoch nicht alle Anweisungen, die Ihre Anwendung ausführt. Mit anderen Worten, wenn dieser Puffer voll ist, überwacht das Betriebssystem überhaupt nicht, wie der Speicher dieses Stapels verwendet wird. Der gesamte Adressraum gehört Ihnen als Initiator des Prozesses, und dies gilt nicht für das Betriebssystem. Sie können damit tun, was Sie wollen, und das Betriebssystem kann Ihnen bei Problemen nicht helfen.
Später werden wir einige der Dinge besprechen, die das Betriebssystem in Bezug auf Hardware tun kann, um sich gegen diese Art von Angriff zu verteidigen. Ich möchte Sie noch einmal daran erinnern, dass nur die Hardware überwacht, was Sie tun, und darauf reagiert. Damit Sie einige spezielle Schutzarten nutzen können, werden wir dies weiter diskutieren.
So sieht ein Pufferüberlauf aus. Wie werden wir all diese Dinge reparieren?
Eine Möglichkeit, Pufferüberläufe zu verhindern, besteht darin, einfach Fehler im C-Code zu vermeiden. Dies ist ein konstruktiver Ansatz, denn wenn Ihr Programm keine Fehler aufweist, kann der Angreifer diese nicht verwenden. Dies ist jedoch leichter gesagt als getan. Es gibt einige sehr einfache Dinge, die Programmierer tun können, um eine „Hygiene“ der Sicherheit zu gewährleisten. Zum Beispiel können Funktionen wie get, von denen wir jetzt wissen, dass sie als "Go-tos" oder "Capture the Operating System" bezeichnet werden, was eine Sicherheitsverletzung darstellt.
Wenn Sie Ihren Code mit einem modernen Compiler wie GCC oder Visual Studio kompilieren, werden die Nachteile solcher Funktionen angezeigt. Sie werden sagen: "Hey, Sie verwenden eine gefährliche Sache, überlegen Sie besser, ob Sie die Funktion fgets oder andere Funktionen verwenden, mit denen Sie die Einhaltung der Grenzbestimmungen wirklich verfolgen können." Dies ist eines der einfachen Dinge, die Programmierer tun können.
Beachten Sie jedoch, dass viele Anwendungen Puffer tatsächlich manipulieren, ohne auf alle diese Funktionen zurückzugreifen. Dies ist sehr häufig bei Netzwerkservern der Fall, die ihre eigenen Analyseverfahren definieren und dann sicherstellen, dass die Daten wie gewünscht aus dem Puffer abgerufen werden. Wenn Sie sich also einfach auf die Auswahl der richtigen Befehlsfunktionen beschränken, ist es nicht möglich, das Problem vollständig zu lösen.
Ein weiterer Umstand, der diese Herangehensweise an das Problem erschwert, ist, dass es nicht immer offensichtlich ist, dass das Problem durch einen Fehler in einem in C geschriebenen Programm verursacht wird. Wenn Sie jemals an einem in C geschriebenen Großprogramm gearbeitet haben, wissen Sie , wie es bei Funktionskennungen der Fall ist, die 18 Sterne über dem void * -Zeiger haben. Ich denke nur Zeus weiß, was das bedeuten kann, oder? Bei Sprachen wie C kann es selbst einem Programmierer sehr schwer fallen zu verstehen, ob ein Fehler aufgetreten ist oder nicht.
Im Allgemeinen wird eines der Hauptthemen unserer Vorlesungen sein, dass die Sprache C ein Produkt des Teufels ist. Und wir benutzen es nur, weil wir immer schneller sein wollen als alle anderen, oder? Da die Hardware jedoch immer schneller wird, verwenden wir fortgeschrittenere Sprachen, um umfangreichen Systemcode zu schreiben. Es ist jedoch nicht immer sinnvoll, Ihren C-Code zu schreiben, auch wenn Sie glauben, dass er schneller sein wird. Wir werden dieses Problem später diskutieren.

Der erste Ansatz zur Lösung des Problems besteht darin, Fehler im C-Programmcode zu vermeiden, und der zweite darin, Tools zu erstellen, mit denen Programmierer solche Fehler finden können. Ein Beispiel für ein solches Tool ist die statische Code-Analyse. Später werden wir ausführlich darüber sprechen, und jetzt werde ich sagen, dass die statische Analyse eine Möglichkeit ist, den Quellcode Ihres Programms zu analysieren, bevor es überhaupt startet, und dabei hilft, potenzielle Probleme zu erkennen.
Stellen Sie sich vor, Sie haben eine solche Funktion. Nennen wir sie
void foo (int, * p) . Sie enthält ganzzahlige Daten und einen Zeiger. Angenommen, es wird ein ganzzahliger Offsetwert
int off deklariert. Diese Funktion deklariert einen weiteren Zeiger und fügt ihm einen Offset hinzu:
int * z = p + off . Selbst jetzt, wenn eine Funktion geschrieben wird, kann die statische Code-Analyse uns sagen, dass diese Offset-Variable nicht initialisiert ist.

Durch die Analyse des Programms ist es daher möglich, die Frage zu beantworten, ob unsere Funktion ordnungsgemäß funktioniert. In diesem Beispiel ist es sehr einfach, die Antwort "Nein, wird es nicht" zu sehen, da keine Offset-Initialisierung erfolgt. Statische Analyse ist Software, und wenn Sie den beliebten Compiler zum Erstellen Ihres Codes verwenden, erfahren Sie: „Hey, Kumpel, dieses Ding ist nicht initialisiert. Bist du sicher, dass du genau das tun willst? " Dies ist eines der einfachsten Beispiele für die Verwendung statischer Analysen.
Ein anderes Beispiel betrachtet den Fall, wenn wir einen Zweig einer Funktion haben, dh ihre Ausführung unter einer bestimmten Bedingung.
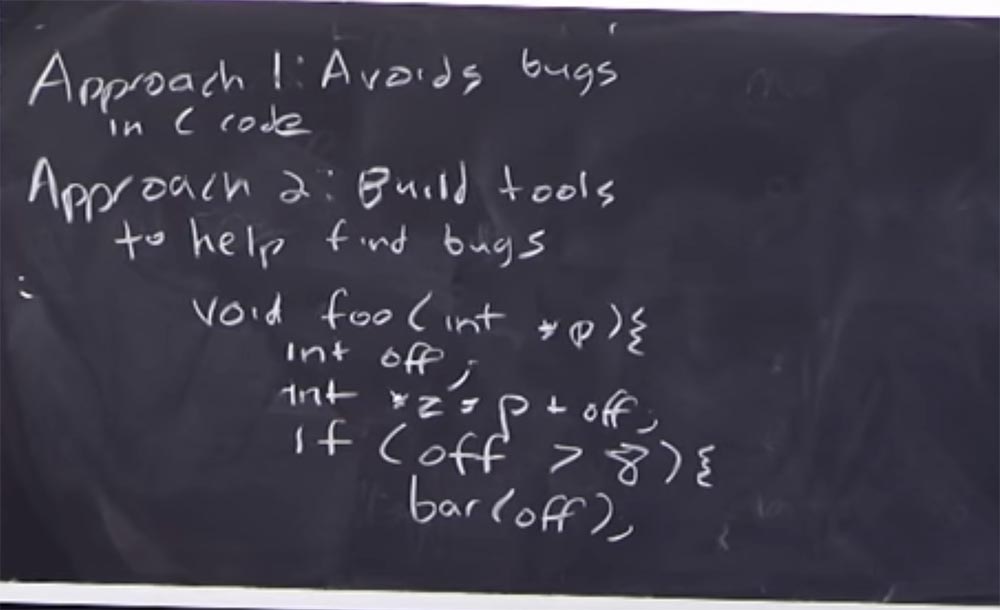
Wenn also der Offset größer als 8 ist,
wenn (aus> 8) , führt dies zu einem Aufruf einer Funktionsleiste
(aus) . Diese Bedingung sagt uns also, was der Versatzwert ist. Selbst wenn wir die Tatsache ignorieren, dass der Versatz nicht initialisiert ist, stellen wir bei der Analyse dieses Zweigs der Funktion fest, dass er größer als 8 sein kann. Wenn wir also mit der statischen Analyse des Balkens beginnen, stellen wir fest, dass der Versatz nur bestimmte Werte annehmen kann. Ich stelle noch einmal fest, dass dies eine sehr oberflächliche Einführung in die statische Analyse ist. Später werden wir dieses Tool genauer betrachten. Dieses Beispiel zeigt jedoch, wie Sie einige Arten von Fehlern erkennen können, auch ohne Code auszuführen.
Eine weitere Sache, über die Sie nachdenken könnten, ist, dass sie dasselbe tut wie die statische Analyse. Dies ist Software-Fuzzing. Seine Idee ist, dass Sie alle Funktionen in Ihrem Programmcode übernehmen und dann zufällige Werte eingeben. Somit überschneiden sich alle Optionen für die Werte und Formate Ihres Codes. Das heißt, Fuzzing ist ein Tool zum automatischen Suchen nach Schwachstellen, indem ungültige Daten oder Daten im falschen Format an die Programmeingabe gesendet werden. Beispielsweise geben Sie beim Komponententest die Werte 2, 4, 8 und 15 ein und erhalten die Meldung, dass die Zahl 15 wahrscheinlich falsch ist, da alle Zahlen gerade, aber ungerade sind.
Tatsächlich müssen Sie sich ansehen, wie viele Zweige des gesamten Programms Ihren Testcode beeinflussen, da dies normalerweise die Stellen sind, an denen die „Fehler“ versteckt sind. Programmierer denken nicht an solche „Ecken und Winkel“ und als Ergebnis bestehen sie einige Unit-Tests, man kann sagen, die meisten dieser Tests. Sie untersuchen jedoch nicht alle „Ecken und Winkel“ des Programms, und hier kann die statische Analyse helfen. Wieder mit Dingen wie dem Konzept der Einschränkung. In unserem Programmabschnitt ist dies beispielsweise eine Bedingung für die Verzweigung einer Funktion, die einen Versatz von mehr als acht definiert. Somit können wir herausfinden, dass diese Verschiebung statisch ist. Und wenn wir die automatische Fuzzing-Generierung von Eingabedaten basierend auf dieser Einschränkung verwenden, können wir sicherstellen, dass einer der Eingabewerte für den Offset kleiner als 8, einer 8 und einer größer als 8 ist. Ist das klar?

Dies ist also die Hauptidee hinter dem Konzept, Tools zu erstellen, mit denen Programmierer Fehler finden können. Selbst eine teilweise Codeanalyse kann bei der Arbeit mit der C-Sprache sehr nützlich sein. Viele der Tools, die wir uns ansehen werden, um Pufferüberläufe zu verhindern oder die Initialisierung von Variablen zu überprüfen, können nicht alle Probleme des Programmcodes erkennen. Sie können jedoch von praktischem Nutzen sein, um die Sicherheit dieser Programme zu verbessern. Der Nachteil dieser Werkzeuge ist, dass sie nicht vollständig sind. Der voraussichtliche Fortschritt ist kein vollständiger Fortschritt. Daher müssen Sie das Problem des Schutzes vor Exploits sowohl in in C geschriebenen Programmen als auch in anderen Programmen aktiv untersuchen. Wir haben zwei Ansätze zur Lösung des Problems des Pufferüberlaufschutzes untersucht, aber es gibt auch andere Ansätze.
Der dritte Ansatz ist also die Verwendung einer speichersicheren Sprache oder einer Sprache, die die Speichersicherheit gewährleistet. Diese Sprachen umfassen Python, Java, c #. Ich möchte Perl nicht mit ihnen gleichsetzen, weil es von "schlechten Leuten" benutzt wird. Auf diese Weise können Sie eine speichersichere Sprache verwenden, und es sieht so aus, als ob dies das offensichtlichste ist, was Sie tun können. Ich habe Ihnen gerade erklärt, dass C im Grunde ein Assembler-Encoder auf hoher Ebene ist, aber Rohzeiger und andere unerwünschte Dinge bereitstellt. Warum also nicht einfach eine dieser Programmiersprachen auf hoher Ebene verwenden?
Dafür gibt es mehrere Gründe. Erstens gibt es in diesen Sprachen viele Elemente des von C geerbten Codes. Alles ist in Ordnung, wenn Sie ein neues Projekt starten und eine der Hochsprachen verwenden, die die Speichersicherheit dafür gewährleisten. Aber was wäre, wenn Sie eine große Binärdatei oder eine große Quelldistribution erhalten würden, die in C geschrieben und 10-15 Jahre lang gepflegt wurde? Dies war ein Generationsprojekt. Ich meine, sogar unsere Kinder werden weiter daran arbeiten ? In diesem Fall können Sie nicht sagen: "Ich schreibe einfach alles in C # um und verändere die Welt!".
Und das Problem liegt nicht nur in der C-Sprache, es gibt Systeme, vor denen Sie noch mehr Angst haben sollten, da sie Fortran- und COBOL-Codes verwenden, Dinge aus dem Bürgerkrieg. Warum passiert das? Weil wir als Ingenieure denken wollen, dass wir einfach alles selbst bauen können, und es wird großartig sein, es wird so sein, wie ich will, und ich werde meine Variablen so aufrufen, wie ich will.
In der realen Welt passiert dies jedoch nicht. Sie erscheinen bei der Arbeit, und Sie haben dieses System, das bereits existiert, und Sie schauen sich die Basis des Codes an und überlegen, warum es nicht das tut, was benötigt wird? Und dann sagen sie zu Ihnen: "Hören Sie, wir werden alles tun, was Sie wollen, aber nur in der zweiten Version des Programms, und jetzt müssen Sie das machen, was wir arbeiten müssen, weil die Kunden sonst ihr Geld zurücknehmen."
Wie gehen wir also mit dem großen Problem der erzwungenen Verwendung von Legacy-Code um? Wie Sie wissen, besteht einer der Vorteile von Systemen mit fehlerhafter Definition von Grenzen darin, dass sie mit diesem veralteten Code perfekt funktionieren. Dies ist einer der Gründe, warum Sie das Problem des Pufferüberlaufs nicht beseitigen können, indem Sie einfach zu Sprachen wechseln, die eine sichere Speichernutzung bieten.

Was ist, wenn wir einfachen Zugriff auf Hardware benötigen? Zum Beispiel, um Treiber und andere Dinge zu aktualisieren.
Ein weiteres Problem tritt auf, wenn Sie Zugriff auf Geräte auf niedriger Ebene benötigen, was beim Schreiben von Treibern für einige Geräte der Fall ist. In diesem Fall benötigen Sie wirklich die Vorteile, die C bietet, z. B. die Möglichkeit, Register und ähnliche Funktionselemente zu betrachten.
Darüber hinaus besteht die Notwendigkeit, C zu verwenden, wenn Sie sich Gedanken über die Systemleistung machen. , , , . , , . , , memory-safe . , JIT. , Java, Java Script. , , «». , . , «» x86.
, , -. , , JVM, - Java. , - . , - JVM , . , , . . , , .
, , 86. JIT- , . JIT- , .
, JavaScript , , «» 32- , . JIT-, «» . , , JIT-, , , .

«» , asm.js – JavaScript, , , . , , , JavaScript , . JavaScript, JavaScript, C ++.
, -, IO. . , , , , . «» , .
. , - . , C C++, , . Python, , , . . .
, , , .
, . , . , . , «» , . , C C++, .
, ? , , ? ?
. , – . , - , . , . , -, , . IP , , . , - . , , . , , «» .
, , , , , , . , - , . , , , . , , , , , , .

, . stack canaries, « », , . « » , , , . , , .
Zeichnen wir ein Diagramm unseres Stapels. Wir müssen sicherstellen, dass der Angreifer zuerst "in den Kanarienvogel gelangt", bevor er die Absenderadresse erreicht. Und wenn wir dies erkennen können, bevor wir von der Funktion zurückkehren, können wir "böse" erkennen.28:30 minFortsetzung:MIT-Kurs "Computer Systems Security". Vorlesung 2: „Kontrolle von Hackerangriffen“, Teil 2Die Vollversion des Kurses finden Sie hier .Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?