
Hallo Habr! Mein Name ist Alexey Pristavko, ich bin der Direktor für Webprojekte bei DataLine. In meinem heutigen Artikel geht es darum, wie Sie Probleme mit der Backend-Leistung von Webanwendungen beheben oder verhindern können.
Dies konzentriert sich auf die Optimierung von Webanwendungen, die unter chronischen Problemen mit Skalierbarkeit, Leistung oder Zuverlässigkeit leiden.
Interessierte - willkommen unter dem Schnitt!
Terminologie
Beginnen wir mit einem Blick auf die Terminologie. Wenn ich über die Leistung von Webprojekten oder Websystemen spreche, meine ich hauptsächlich das Back-End und die Serverkomponente. Was beim Laden von Seiten in einen Browser passiert, ist eine völlig andere Geschichte, die höchstwahrscheinlich einem separaten Artikel gewidmet sein wird.
- Das Maß für die Anwendungsleistung ist die Anzahl der verarbeiteten Anforderungen pro Sekunde (RPS) und deren Ausführungsgeschwindigkeit (TTFB - Time to First Byte).
- Dementsprechend meinen wir unter Systemskalierbarkeit einen Pool von Möglichkeiten zur Erhöhung des RPS.
Nun zur Zuverlässigkeit. Hier müssen zwei Konzepte getrennt werden: Fehlertoleranz und Katastrophenschutz.
- Ausfallsicherheit - Die Fähigkeit eines Systems zum Ausfall, wenn ein oder mehrere Server nicht innerhalb der erforderlichen Parameter weiterarbeiten.
- Systeme mit vollständiger Backup-Redundanz (die sogenannte zweite Schulter), die ohne starken Verlust arbeiten können, wenn eines der Rechenzentren vollständig ausfällt, gelten als katastrophenresistent .
Gleichzeitig ist ein katastrophtolerantes System ein ausfallsicheres System. Eine Situation, in der ein katastrophenresistentes, aber nicht fehlertolerantes System weiterhin nur an einer „Schulter“ arbeitet, ist ganz normal. Wenn jedoch einer der Server ausfällt, fällt auch das System aus.
Nachdem wir die Schlüsselkonzepte herausgefunden und die aktuelle Terminologie aktualisiert haben, ist es an der Zeit, direkt zu den Grundlagen der Optimierung und der Life-Hacks überzugehen.
Wo soll ich mit der Optimierung beginnen?

Wie kann man verstehen, wo man mit der Optimierung beginnen soll? Atmen Sie tief ein und recherchieren Sie die Anwendung, bevor Sie sich auf die Optimierung beeilen.
Stellen Sie sicher, dass Sie ein detailliertes Diagramm zeichnen. Zeigen Sie darauf alle Komponenten der Anwendung und ihre Beziehungen an. Nachdem Sie dieses Schema untersucht haben, können Sie zuvor unauffällige Schwachstellen und potenzielle Fehlerquellen entdecken.
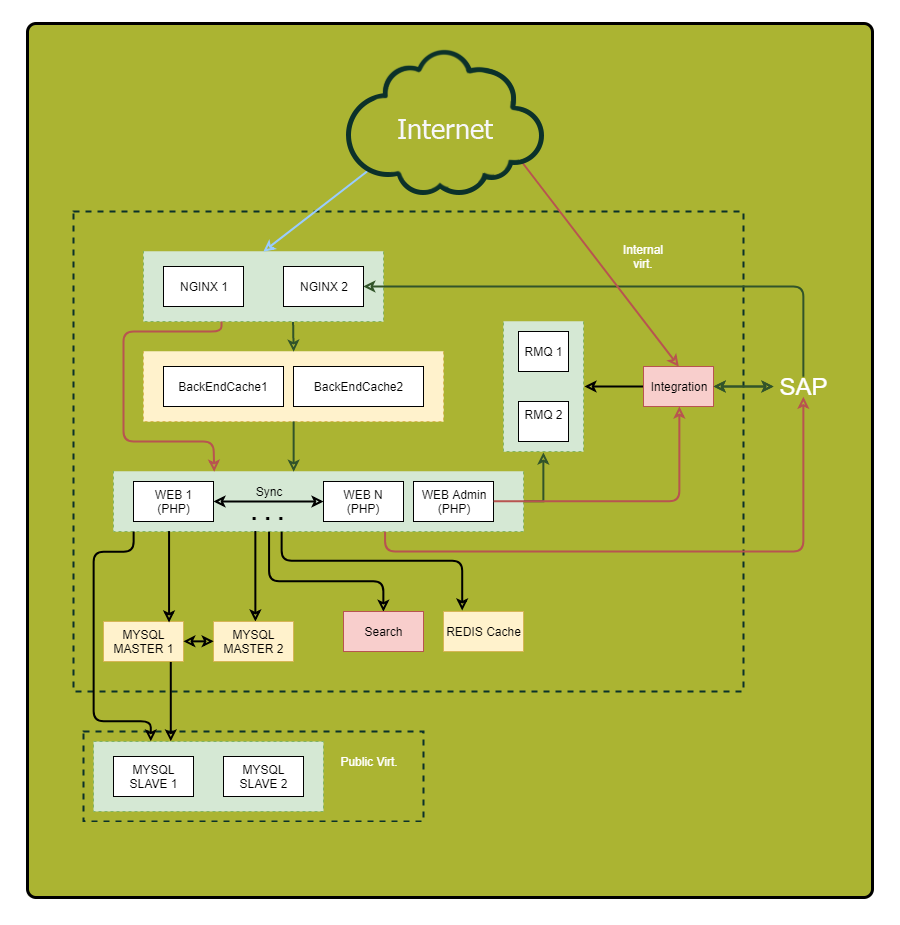
„Was? Wo? Wann? " - Abfragen optimieren
Achten Sie besonders auf synchrone Anfragen. Ich möchte Sie daran erinnern, dass dies solche Anfragen sind, wenn wir eine Anfrage im selben Thread senden und auf eine Antwort darauf warten. Hier liegen die Gründe für die schweren Bremsen, wenn auf der anderen Seite etwas schief geht. Wenn Sie daher die Anzahl der synchronen Anforderungen reduzieren oder durch asynchrone ersetzen können, tun Sie dies.
Hier sind einige Tricks, mit denen Sie Ihre Anfragen verfolgen können:
- Weisen Sie jeder eingehenden Anforderung eine eindeutige Kennung zu. Nginx hat hierfür eine eingebaute Variable $ request_id. Übergeben Sie die Kennung in den Headern des Backends und schreiben Sie in alle Protokolle. So können Sie Anfragen bequem verfolgen.
- Protokollieren Sie nicht nur das Ende der Anforderung in der externen Komponente, sondern auch deren Anfang. Sie messen also die tatsächliche Dauer des externen Anrufs. Es kann sich erheblich von dem unterscheiden, was Sie auf dem Remote-System sehen, beispielsweise aufgrund von Netzwerkproblemen oder DNS-Bremsen.
So werden die Daten gesammelt. Lassen Sie uns nun die Problempunkte analysieren. Definieren Sie:
- Wo wird die meiste Zeit verbracht?
- Woher kommen die meisten Anfragen?
- Woher kommen die längsten Anfragen?
Als Ergebnis erhalten Sie eine Liste der interessantesten Abschnitte des Systems zur Optimierung.
Tipp: Wenn ein Punkt viele kleine Abfragen "sammelt", versuchen Sie, sie zu einer großen Abfrage zu kombinieren, um den Overhead zu verringern. Die Ergebnisse langer Abfragen sind im Cache häufig sinnvoll.
Wir cachen mit Bedacht
Es gibt allgemeine Caching-Regeln, auf die Sie sich bei der Optimierung verlassen sollten:
- Je näher der Cache am Verbraucher liegt, desto schneller ist der Job. Für die Anwendung ist RAM der nächstgelegene Ort. Für den Benutzer seinen Browser.
- Das Caching beschleunigt die Datenerfassung und reduziert die Belastung der Quelle.
Wenn zehn Webserver dieselben Datenbankabfragen durchführen, führt ein zentraler Zwischencache, beispielsweise in Redis, zu einem höheren Prozentsatz an Treffern (im Vergleich zum lokalen Cache) und verringert die Gesamtlast der Datenbank, wodurch das Gesamtbild erheblich verbessert wird.
Tipp 1: Führen Sie das Zwischenspeichern von Komponenten der fertigen Seite auf der Nginx-Seite mit Edge Side Includes durch. Es passt gut zur Microservice / SOA-Architektur und entlastet das gesamte System, wodurch die Reaktionsgeschwindigkeit erheblich verbessert wird.
Tipp 2: Verfolgen Sie die Größe der Objekte im Cache, die Trefferquote und das Schreib- / Lesevolumen. Je größer das Objekt ist, desto länger dauert die Verarbeitung. Wenn Sie öfter oder öfter in den Cache schreiben als Sie lesen, ist ein solcher Cache nicht Ihr Freund. Es lohnt sich entweder zu entfernen oder darüber nachzudenken, die Wirksamkeit zu erhöhen.
Tipp 3: Verwenden Sie nach Möglichkeit Ihre eigenen Datenbank-Caches. Die richtige Konfiguration kann die Arbeit beschleunigen.
Profile laden
Wir gehen zum Laden von Profilen über. Wie Sie wissen, gibt es zwei Haupttypen: OLAP und OLTP.
- Für OLAP (Online Analytical Processing) ist der pro Sekunde ausgegebene Datenverkehr wichtig.
- Bei OLTP (Online Transaction Processing) ist der Schlüsselindikator die Antwortgeschwindigkeit und das Millisekunden-Timing.
In den meisten Fällen ist es effektiv, diese beiden Lasttypen zu trennen. Zumindest müssen Sie die Datenbank und möglicherweise andere Komponenten des Systems separat optimieren.
Tipp: Leseanforderungen aus dem Admin-Bereich werden normalerweise mit dem OLAP-Typ verarbeitet. Erstellen Sie für diese Aufgabe eine separate Kopie der Datenbank und einen Webserver, um das Hauptsystem auszulagern.
Datenbanken

Wir näherten uns natürlich einer der schwierigsten Phasen der Optimierung - der Datenbankoptimierung.
Ich möchte Sie an die allgemeine Regel erinnern: Je kleiner die Datenbank, desto schneller funktioniert sie. Die Organisation der Datenbank ist entscheidend für die Geschwindigkeit.
Speichern Sie nach Möglichkeit
historische Daten , Anwendungsprotokolle und
häufig verwendete Daten in verschiedenen Datenbanken. Besser noch, poste sie auf verschiedenen Servern. Dies erleichtert nicht nur die Lebensdauer der Hauptdatenbank, sondern bietet auch mehr Platz für weitere Optimierungen. In einigen Fällen können beispielsweise unterschiedliche Indizes für unterschiedliche Lasten verwendet werden. Außerdem vereinfacht die „Einheitlichkeit“ der Last die Lebensdauer des Schedulers und des Abfrageoptimierers des Datenbankservers.
Und noch einmal über die Bedeutung der Planung
Um nicht über Optimierungen zu rätseln, die nicht wirklich benötigt werden, wählen Sie die Hardware basierend auf den Aufgaben.
- Für kleine, aber häufige Anfragen ist es besser, mehr Prozessorkerne zu verwenden.
- Für schwere Anfragen - weniger Kerne mit höherer Taktrate.
Versuchen Sie, das Arbeitsvolumen der Datenbank in den Arbeitsspeicher zu stellen. Wenn dies nicht möglich ist oder eine große Anzahl von Schreibanforderungen vorliegt, ist es an der Zeit, die Datenbanken auf SSDs zu übertragen. Sie erhöhen die Arbeitsgeschwindigkeit mit der Festplatte erheblich.
Skalieren

Oben habe ich die wichtigsten Mechanismen zur Verbesserung der Anwendungsleistung beschrieben, ohne die physischen Ressourcen zu erhöhen.
Jetzt werden wir darüber sprechen, wie Sie eine Skalierungsstrategie auswählen und die Ausfallsicherheit erhöhen.
Es gibt zwei Arten der Systemskalierung:
- vertikal - das Wachstum der Ressourcen unter Beibehaltung der Anzahl der Einheiten;
- horizontal - eine Zunahme der Anzahl von Entitäten.
Wachsen Sie groß
Beginnen wir mit der Auswahl einer vertikalen Skalierungsstrategie.
Betrachten Sie zunächst die
Erhöhung der Systemleistung . Wenn Ihr System auf einem Server funktioniert, müssen Sie wählen, ob Sie die Kapazität des aktuellen Servers erhöhen oder einen anderen kaufen möchten.
Es scheint, dass die erste Option einfacher und sicherer ist. Es wird jedoch weitsichtiger sein, einen weiteren Server zu kaufen und eine große Fehlertoleranz als Bonus für die Produktivität zu erhalten. Ich habe am Anfang des Artikels darüber gesprochen.
Wenn Ihr System über mehrere Server verfügt und Sie die Kapazität bestehender Server erhöhen oder weitere kaufen möchten, achten Sie auf die finanzielle Seite. Beispielsweise kann ein leistungsfähiger Server teurer sein als zwei um 50% „schwächere“. Daher ist es sinnvoll, auf die zweite Kompromissoption einzugehen. Gleichzeitig ist bei einer großen Anzahl von Servern das Verhältnis von Leistung, Stromverbrauch und Kosten eines vollständigen Racks entscheidend.
Wachsen Sie weit
Bei der horizontalen Skalierung geht es um Fehlertoleranz und Clustering. Im allgemeinen Fall ist die Fehlertoleranz der gesamten Lösung umso höher, je mehr Instanzen einer Entität vorhanden sind.
Wahrscheinlich möchten Sie als erstes
Anwendungsserver skalieren. Das erste Hindernis hierfür ist die Organisation der Arbeit mit zentralisierten Datenquellen. Neben Datenbanken sind dies auch Sitzungsdaten und statische Inhalte. Folgendes empfehle ich Ihnen:
- Verwenden Sie zum Speichern von Sitzungen Couchbase, nicht das übliche Memcached, da es mit demselben Protokoll arbeitet, aber im Gegensatz zu memcached Clustering unterstützt.
- Alle statischen Daten , insbesondere große Mengen an Bildern und Dokumenten, werden separat gespeichert und mit Nginx und nicht aus dem Anwendungscode bereitgestellt. Dies spart Geld bei den Flows und vereinfacht das Infrastrukturmanagement.
Datenbank "aufrufen"
Datenbanken sind schwer zu skalieren. Hierfür gibt es zwei Haupttechniken: Sharding und Replikation. Betrachten Sie sie.
Während der
Replikation fügen wir dem System vollständig identische Kopien der Datenbank hinzu, während wir logisch getrennte Teile und Shards teilen. Gleichzeitig ist es äußerst wünschenswert, das Sharding parallel zur Replikation (Replikation) jedes Shards durchzuführen, um die Fehlertoleranz nicht zu verlieren.
Denken Sie daran: Oft besteht ein Datenbankcluster aus einem Masterknoten, der den Schreibstrom übernimmt, und mehreren Slaveknoten, die zum Lesen verwendet werden. Unter dem Gesichtspunkt der Fehlertoleranz ist dies etwas besser als bei einem einzelnen Server, da die Gesamtfehlertoleranz durch das am wenigsten stabile Element des Systems bestimmt wird.
Schemata mit mehr als zwei Datenbankassistenten (Ringtopologie) ohne Bestätigung des Datensatzes auf jedem Server leiden sehr häufig unter Inkonsistenzen. Bei einem Ausfall eines der Server ist es äußerst schwierig, die logische Integrität der Daten im Cluster wiederherzustellen.
Tipp: Wenn es in Ihrem Fall nicht sinnvoll ist, mehrere Master-Server zu haben, sollten Sie die architektonische Möglichkeit in Betracht ziehen, dass das System mindestens eine Stunde lang ohne Master arbeitet. Im Falle eines Unfalls haben Sie Zeit, den Server ohne Ausfallzeiten des gesamten Systems auszutauschen.
Tipp: Wenn Sie mehr als 2 Datenbankmaster behalten müssen, empfehlen wir Ihnen, NoSQL-Lösungen in Betracht zu ziehen, da viele von ihnen über integrierte Mechanismen verfügen, um Daten in einen konsistenten Zustand zu bringen.
Vergessen Sie beim Streben nach Fehlertoleranz auf keinen Fall, dass die Replikation Sie
nur gegen physische Serverausfälle versichert. Es wird nicht vor einer Beschädigung der logischen Daten aufgrund eines Benutzerfehlers gespeichert.
Denken Sie daran: Alle wichtigen Daten müssen gesichert und als unabhängige, nicht bearbeitbare Kopie gespeichert werden.
Anstelle einer Schlussfolgerung
Zum Schluss noch ein paar Leistungstipps zum Sichern:
Tipp 1: Ziehen Sie Daten aus einem separaten Datenbankreplikat, damit der aktive Server nicht überlastet wird.
Tipp 2: Halten Sie eine zusätzliche, leicht "verzögerte" zeitliche Nachbildung der Datenbank bereit. Im Falle eines Unfalls wird dies dazu beitragen, die Menge der verlorenen Daten zu reduzieren.
Die in diesem Artikel vorgestellten Methoden und Techniken sollten niemals blind angewendet werden, ohne die aktuelle Situation zu analysieren und zu verstehen, was Sie erreichen möchten. Möglicherweise tritt eine "Überoptimierung" auf, und das resultierende System ist nur 10% schneller, aber 50% anfälliger für Unfälle.
Das ist alles Wenn Sie Fragen haben, beantworte ich diese gerne in den Kommentaren.