Auf dem Datenfestival 2 in Minsk bemerkte Vladimir Iglovikov, Bildverarbeitungsingenieur bei Lyft, dass der beste Weg, Data Science zu lernen, darin besteht, an Wettbewerben teilzunehmen, Lösungen anderer zu entwickeln, diese zu kombinieren, Ergebnisse zu erzielen und Ihre Arbeit zu zeigen. Im Rahmen dieses Paradigmas habe ich mich entschlossen, den
Wettbewerb zur Bewertung des Kreditrisikos für Privatkredite genauer zu betrachten und (Anfängern, Wissenschaftlern und vor allem mir selbst) zu erklären, wie solche Datensätze richtig analysiert und Modelle für sie erstellt werden können.
(Bild
von hier )

Die Home Credit Group ist eine Gruppe von Banken und Nichtbanken-Kreditorganisationen, die in 11 Ländern tätig sind (einschließlich Russland als Home Credit and Finance Bank LLC). Ziel des Wettbewerbs ist es, eine Methode zur Bewertung der Kreditwürdigkeit von Kreditnehmern zu erstellen, die keine Bonitätshistorie haben. Was ziemlich edel aussieht - Kreditnehmer dieser Kategorie können oft keinen Kredit von der Bank erhalten und sind gezwungen, sich an Betrüger und Mikrokredite zu wenden. Es ist interessant, dass der Kunde keine Anforderungen an die Transparenz und Interpretierbarkeit des Modells stellt (wie dies normalerweise bei Banken der Fall ist). Sie können alles verwenden, auch ein neuronales Netzwerk.
Die Trainingsstichprobe besteht aus mehr als 300.000 Datensätzen, es gibt ziemlich viele Anzeichen - 122, darunter viele kategoriale (nicht numerische). Schilder beschreiben den Kreditnehmer ausreichend detailliert bis hin zu dem Material, aus dem die Wände seines Hauses bestehen. Ein Teil der Daten ist in 6 zusätzlichen Tabellen enthalten (Daten zum Kreditbüro, zum Kreditkartenguthaben und zu früheren Darlehen). Diese Daten müssen auch irgendwie verarbeitet und in die Hauptdaten geladen werden.
Der Wettbewerb sieht aus wie eine Standardklassifizierungsaufgabe (1 im Feld ZIEL bedeutet Schwierigkeiten bei der Zahlung, 0 bedeutet keine Schwierigkeiten). Es sollte jedoch nicht 0/1 vorhergesagt werden, sondern die Wahrscheinlichkeit von Problemen (die im Übrigen leicht mit den Wahrscheinlichkeitsvorhersagemethoden predict_proba aller komplexen Modelle gelöst werden können).
Auf den ersten Blick ist der Datensatz ein Standard für maschinelles Lernen. Die Organisatoren haben einen hohen Preis von 70.000 US-Dollar angeboten. Infolgedessen nehmen heute mehr als 2.600 Teams am Wettbewerb teil, und der Kampf findet in Tausendstel Prozent statt. Andererseits bedeutet eine solche Popularität, dass der Datensatz auf und ab untersucht wurde und viele Kernel mit guter EDA (Exploratory Data Analisys - Forschung und Analyse von Daten im Netzwerk, einschließlich grafischer Daten), Feature Engineering (Arbeiten mit Attributen) erstellt wurden. und mit interessanten Modellen. (Der Kernel ist ein Beispiel für die Arbeit mit einem Datensatz, den jeder anlegen kann, um anderen Kämpfern seine Arbeit zu zeigen.)
Kernel verdienen Aufmerksamkeit:
Um mit Daten zu arbeiten, wird normalerweise der folgende Plan empfohlen, dem wir folgen werden.
- Das Problem verstehen und sich mit den Daten vertraut machen
- Datenbereinigung und Formatierung
- EDA
- Basismodell
- Modellverbesserung
- Modellinterpretation
In diesem Fall müssen Sie berücksichtigen, dass die Daten sehr umfangreich sind und nicht sofort überlastet werden können. Es ist sinnvoll, schrittweise zu handeln.
Beginnen wir mit dem Importieren der Bibliotheken, die wir für die Analyse benötigen, um mit Daten in Form von Tabellen zu arbeiten, Diagramme zu erstellen und mit Matrizen zu arbeiten.
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
Laden Sie die Daten herunter. Mal sehen, was wir alle haben. Dieser Speicherort im Verzeichnis "../input/" ist übrigens mit der Anforderung verbunden, Ihre Kernel auf Kaggle zu platzieren.
import os PATH="../input/" print(os.listdir(PATH))
['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']Es gibt 8 Tabellen mit Daten (ohne die Tabelle HomeCredit_columns_description.csv, die eine Beschreibung der Felder enthält), die wie folgt miteinander verbunden sind:
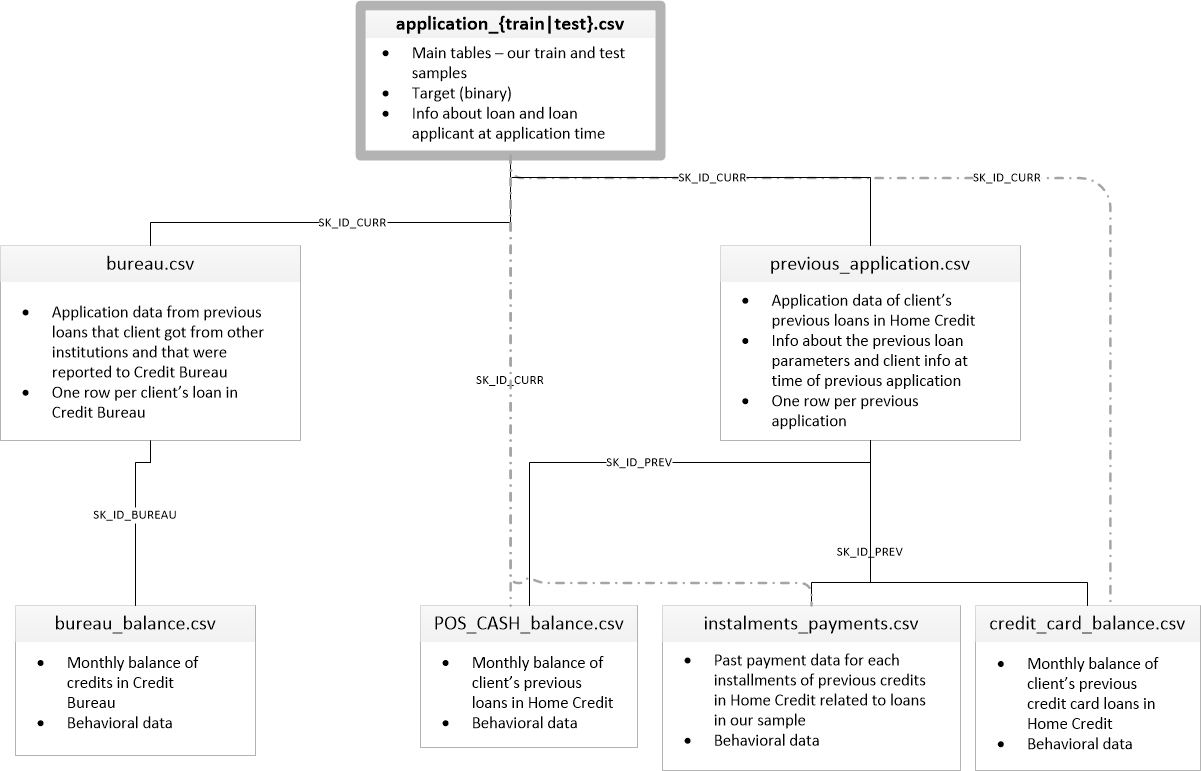
application_train / application_test: Stammdaten, der Kreditnehmer wird durch das Feld SK_ID_CURR identifiziert
Büro: Daten zu früheren Darlehen anderer Kreditinstitute von einem Kreditbüro
office_balance: Monatliche Daten zu früheren Bürodarlehen. Jede Zeile ist der Monat, in dem das Darlehen verwendet wird
vorherige_Anwendung: Frühere Anträge auf Darlehen in Home Credit haben jeweils ein eindeutiges Feld SK_ID_PREV
POS_CASH_BALANCE: Monatliche Daten zu Krediten in Home Credit mit der Ausgabe von Bargeld und Krediten für den Kauf von Waren
credit_card_balance: Monatliche Kreditkartenguthaben in Home Credit
Ratenzahlung_Zahlung: Zahlungsverlauf früherer Kredite bei Home Credit.
Konzentrieren wir uns zunächst auf die Hauptdatenquelle und sehen, welche Informationen daraus extrahiert werden können und welche Modelle erstellt werden sollen. Laden Sie die Basisdaten herunter.
- app_train = pd.read_csv (PATH + 'application_train.csv',)
- app_test = pd.read_csv (PATH + 'application_test.csv',)
- print ("Trainingssatzformat:", app_train.shape)
- print ("Testbeispielformat:", app_test.shape)
- Trainingsbeispielformat: (307511, 122)
- Testmusterformat: (48744, 121)
Insgesamt haben wir 307.000 Datensätze und 122 Zeichen in der Trainingsstichprobe und 49.000 Datensätze und 121 Zeichen im Test. Die Diskrepanz ist offensichtlich auf die Tatsache zurückzuführen, dass die Testprobe kein Zielattribut TARGET enthält, und wir werden es vorhersagen.
Schauen wir uns die Daten genauer an
pd.set_option('display.max_columns', None)
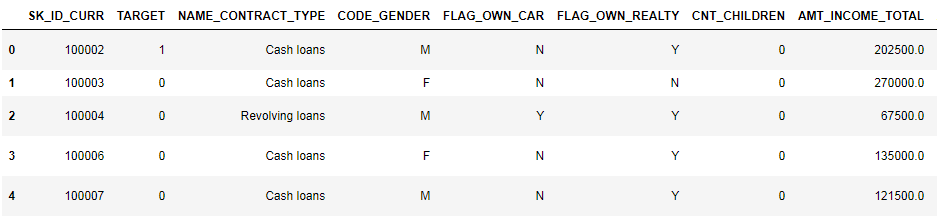
(erste 8 Spalten gezeigt)
Es ist ziemlich schwierig, Daten in diesem Format anzusehen. Schauen wir uns die Liste der Spalten an:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MBRufen Sie detaillierte Anmerkungen nach Feld in der Datei HomeCredit_columns_description auf. Wie Sie aus den Informationen ersehen können, ist ein Teil der Daten unvollständig und ein Teil kategorisch. Sie werden als Objekt angezeigt. Die meisten Modelle arbeiten nicht mit solchen Daten, wir müssen etwas damit anfangen. In diesem Zusammenhang kann die erste Analyse als abgeschlossen betrachtet werden, wir werden direkt zu EDA gehen
Explorative Datenanalyse oder primäres Data Mining
Im EDA-Prozess zählen wir die grundlegenden Statistiken und zeichnen Diagramme, um Trends, Anomalien, Muster und Beziehungen innerhalb der Daten zu finden. Ziel von EDA ist es herauszufinden, was die Daten aussagen können. In der Regel geht die Analyse von oben nach unten - von einem allgemeinen Überblick bis zur Untersuchung einzelner Zonen, die Aufmerksamkeit erregen und von Interesse sein können. Anschließend können diese Erkenntnisse bei der Konstruktion des Modells, der Auswahl der Merkmale für das Modell und seiner Interpretation verwendet werden.
Verteilung der Zielvariablen
app_train.TARGET.value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64 plt.style.use('fivethirtyeight') plt.rcParams["figure.figsize"] = [8,5] plt.hist(app_train.TARGET) plt.show()
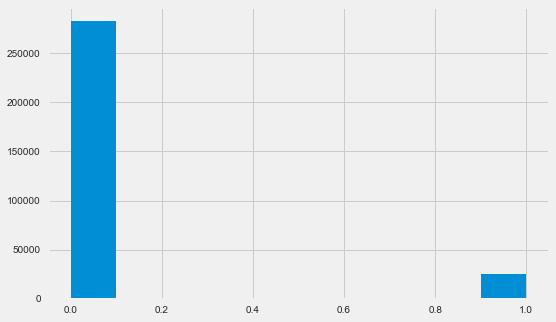
Ich möchte Sie daran erinnern, dass 1 Probleme jeglicher Art mit einer Rückgabe bedeutet, 0 bedeutet keine Probleme. Wie Sie sehen, haben hauptsächlich Kreditnehmer keine Probleme mit der Rückzahlung, der Anteil der Problematik liegt bei etwa 8%. Dies bedeutet, dass die Klassen nicht ausgeglichen sind und dies möglicherweise beim Erstellen des Modells berücksichtigt werden muss.
Fehlende Datenrecherche
Wir haben gesehen, dass der Mangel an Daten ziemlich groß ist. Mal sehen, wo und was fehlt.
122 .
67 .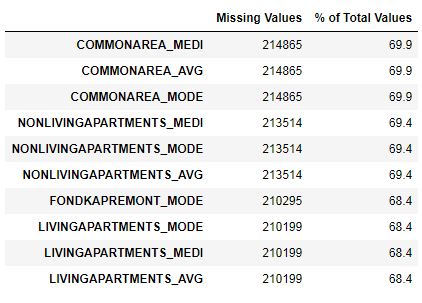
Im Grafikformat:
plt.style.use('seaborn-talk') fig = plt.figure(figsize=(18,6)) miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index() miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index() miss_train["type"] = "" miss_test["type"] = "" missing = pd.concat([miss_train,miss_test],axis=0) ax = sns.pointplot("index",0,data=missing,hue="type") plt.xticks(rotation =90,fontsize =7) plt.title(" ") plt.ylabel(" %") plt.xlabel("")
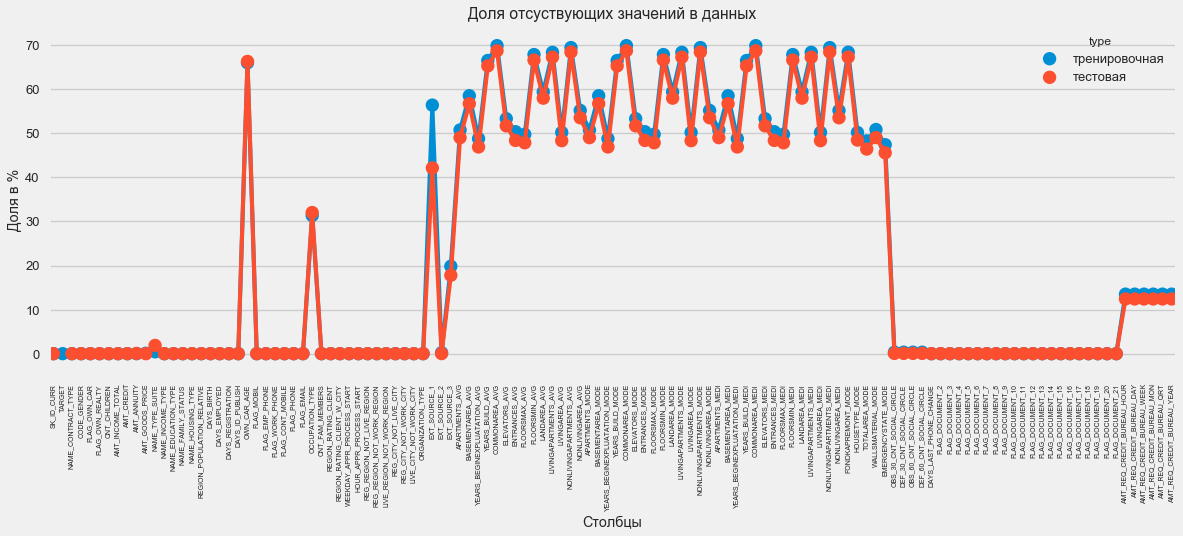
Es gibt viele Antworten auf die Frage, was mit all dem zu tun ist. Sie können es mit Nullen füllen, Sie können Medianwerte verwenden, Sie können nur Zeilen ohne die erforderlichen Informationen löschen. Es hängt alles von dem Modell ab, das wir verwenden möchten, da einige von ihnen perfekt mit fehlenden Werten umgehen. Während wir uns an diese Tatsache erinnern und alles so lassen, wie es ist.
Spaltentypen und kategoriale Codierung
Wie wir uns erinnern. Ein Teil der Spalten ist vom Typ Objekt, dh er hat keinen numerischen Wert, spiegelt jedoch eine Kategorie wider. Schauen wir uns diese Spalten genauer an.
app_train.dtypes.value_counts()
float64 65
int64 41
object 16
dtype: int64 app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64Wir haben 16 Spalten mit jeweils 2 bis 58 verschiedenen Wertoptionen. Im Allgemeinen können Modelle für maschinelles Lernen mit solchen Spalten nichts anfangen (mit Ausnahme einiger, wie z. B. LightGBM oder CatBoost). Da wir verschiedene Modelle im Datensatz ausprobieren möchten, muss hiermit etwas unternommen werden. Grundsätzlich gibt es zwei Ansätze:
- Beschriftungscodierung - Kategorien werden mit den Ziffern 0, 1, 2 usw. versehen und in dieselbe Spalte geschrieben
- One-Hot-Codierung - Eine Spalte wird entsprechend der Anzahl der Optionen in mehrere zerlegt. Diese Spalten geben an, welche Option dieser Datensatz hat.
Unter den populären ist es erwähnenswert,
mittlere Zielcodierung (danke für die Klarstellung
roryorangepants ).
Bei der Etikettencodierung gibt es ein kleines Problem: Sie weist numerische Werte zu, die nichts mit der Realität zu tun haben. Wenn es sich beispielsweise um einen numerischen Wert handelt, ist das Einkommen des Kreditnehmers von 100.000 definitiv höher und besser als das Einkommen von 20.000. Man kann jedoch sagen, dass beispielsweise eine Stadt besser ist als eine andere, weil einer der Wert 100 und die andere 200 zugewiesen wird ?
One-Hot-Codierung ist dagegen sicherer, kann jedoch "zusätzliche" Spalten erzeugen. Wenn wir beispielsweise dasselbe Geschlecht mit One-Hot codieren, erhalten wir zwei Spalten, "männliches Geschlecht" und "weibliches Geschlecht", obwohl eine ausreichen würde, "ist es männlich".
Für einen guten Datensatz wäre es notwendig, Zeichen mit geringer Variabilität mithilfe der Etikettencodierung und allem anderen zu codieren - One-Hot, aber der Einfachheit halber codieren wir alles gemäß One-Hot. Dies hat praktisch keinen Einfluss auf die Berechnungsgeschwindigkeit und das Ergebnis. Der Pandas-Kodierungsprozess selbst ist sehr einfach.
app_train = pd.get_dummies(app_train) app_test = pd.get_dummies(app_test) print('Training Features shape: ', app_train.shape) print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)Da die Anzahl der Optionen in den Auswahlspalten nicht gleich ist, stimmt die Anzahl der Spalten jetzt nicht überein. Ausrichtung ist erforderlich - Sie müssen Spalten aus dem Trainingssatz entfernen, die nicht im Testsatz enthalten sind. Damit ist die Ausrichtungsmethode erforderlich. Sie müssen Achse = 1 angeben (für Spalten).
: (307511, 242)
: (48744, 242)Datenkorrelation
Ein guter Weg, um die Daten zu verstehen, besteht darin, die Pearson-Korrelationskoeffizienten für die Daten relativ zum Zielattribut zu berechnen. Dies ist nicht die beste Methode, um die Relevanz von Features zu zeigen, aber sie ist einfach und ermöglicht es Ihnen, sich ein Bild von den Daten zu machen. Die Koeffizienten können wie folgt interpretiert werden:
- 00-.19 "sehr schwach"
- 20-.39 "schwach"
- 40-.59 "Durchschnitt"
- 60-79 stark
- 80-1.0 "sehr stark"
:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64Somit korrelieren alle Daten schwach mit dem Ziel (mit Ausnahme des Ziels selbst, das natürlich gleich sich selbst ist). Das Alter und einige „externe Datenquellen“ unterscheiden sich jedoch von den Daten. Dies sind wahrscheinlich einige zusätzliche Daten von anderen Kreditorganisationen. Es ist lustig, dass, obwohl das Ziel bei einer Kreditentscheidung als Unabhängigkeit von solchen Daten erklärt wird, wir uns in erster Linie auf diese stützen werden.
Alter
Es ist klar, dass je älter der Kunde ist, desto höher ist die Wahrscheinlichkeit einer Rückkehr (natürlich bis zu einem bestimmten Limit). Aus irgendeinem Grund wird das Alter jedoch in negativen Tagen vor der Ausgabe eines Kredits angegeben, weshalb es positiv mit der Nichtrückzahlung korreliert (was etwas seltsam aussieht). Wir bringen es auf einen positiven Wert und betrachten die Korrelation.
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH']) app_train['DAYS_BIRTH'].corr(app_train['TARGET'])
-0.078239308309827088Schauen wir uns die Variable genauer an. Beginnen wir mit dem Histogramm.
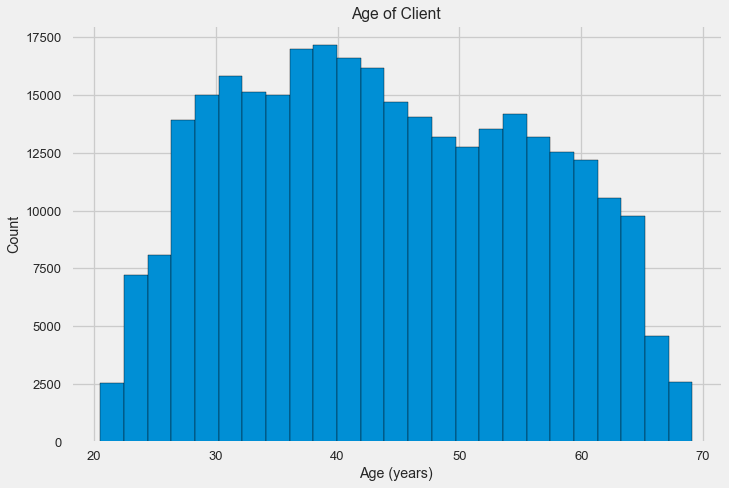
Das Verteilungshistogramm selbst kann ein wenig nützlich sein, außer dass wir keine speziellen Ausreißer sehen und alles mehr oder weniger glaubwürdig aussieht. Um die Auswirkung des Einflusses des Alters auf das Ergebnis zu zeigen, können wir ein Diagramm der Kerndichteschätzung (KDE) erstellen - die Verteilung der Kerndichte, die in den Farben des Zielattributs dargestellt ist. Es zeigt die Verteilung einer Variablen und kann als geglättetes Histogramm interpretiert werden (berechnet als Gaußscher Kern für jeden Punkt, der dann gemittelt wird, um ihn zu glätten).
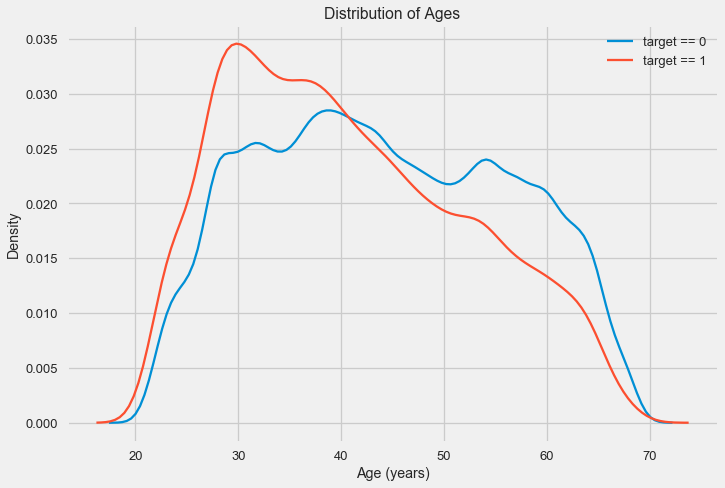
Wie zu sehen ist, ist der Anteil der Ausfälle bei jungen Menschen höher und nimmt mit zunehmendem Alter ab. Dies ist kein Grund, jungen Menschen immer Kredite zu verweigern. Eine solche „Empfehlung“ führt nur zu Einkommens- und Marktverlusten für die Bank. Dies ist eine Gelegenheit, über eine gründlichere Überwachung solcher Kredite, eine Bewertung und möglicherweise sogar eine Art finanzielle Bildung für junge Kreditnehmer nachzudenken.
Externe Quellen
Schauen wir uns die „externen Datenquellen“ EXT_SOURCE und ihre Korrelation genauer an.
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']] ext_data_corrs = ext_data.corr() ext_data_corrs
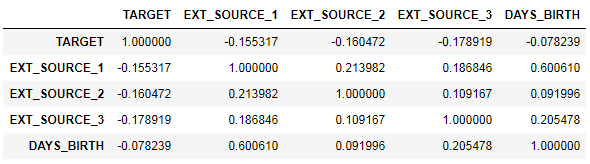
Es ist auch bequem, die Korrelation mithilfe der Heatmap anzuzeigen
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6) plt.title('Correlation Heatmap');
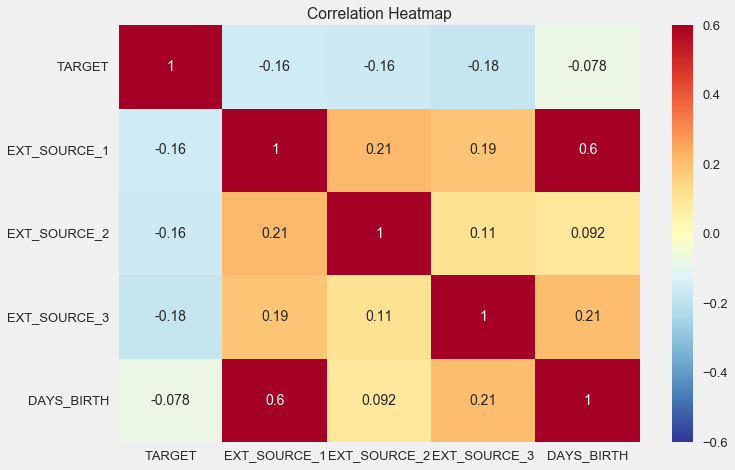
Wie Sie sehen können, zeigen alle Quellen eine negative Korrelation mit dem Ziel. Schauen wir uns die Verteilung von KDE für jede Quelle an.
plt.figure(figsize = (10, 12))
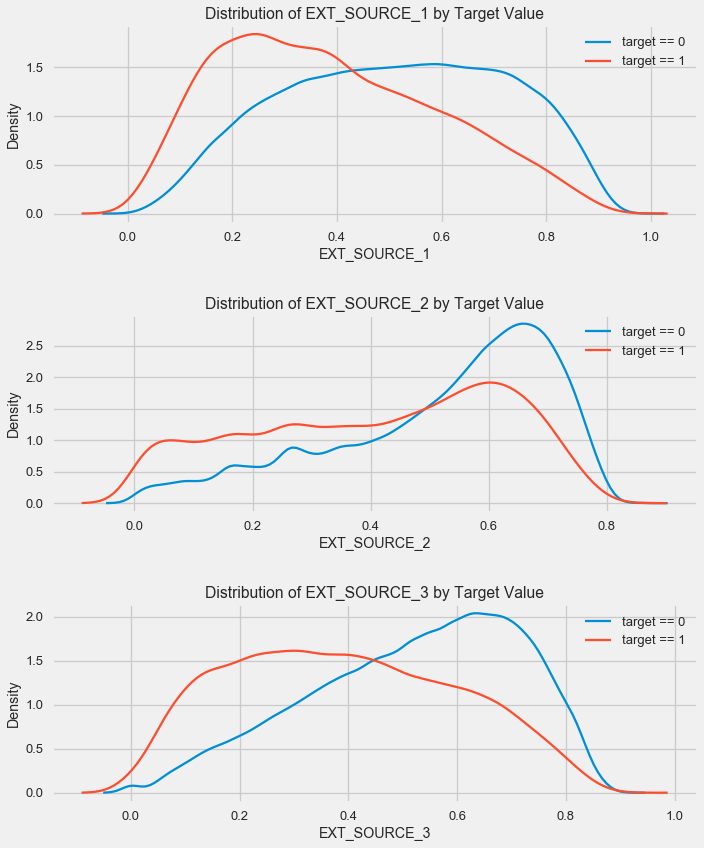
Das Bild ähnelt der Verteilung nach Alter - mit einem Anstieg des Indikators steigt die Wahrscheinlichkeit einer Kreditrendite. Die dritte Quelle ist in dieser Hinsicht die mächtigste. Obwohl die Korrelation mit der Zielvariablen in absoluten Zahlen immer noch in der Kategorie „sehr niedrig“ liegt, werden externe Datenquellen und das Alter für die Erstellung des Modells von höchster Bedeutung sein.
Paar Zeitplan
Um die Beziehung dieser Variablen besser zu verstehen, können Sie ein Paardiagramm erstellen. Darin sehen Sie die Beziehung jedes Paares und ein Histogramm der Verteilung entlang der Diagonale. Oberhalb der Diagonale können Sie das Streudiagramm und darunter - 2d KDE anzeigen.
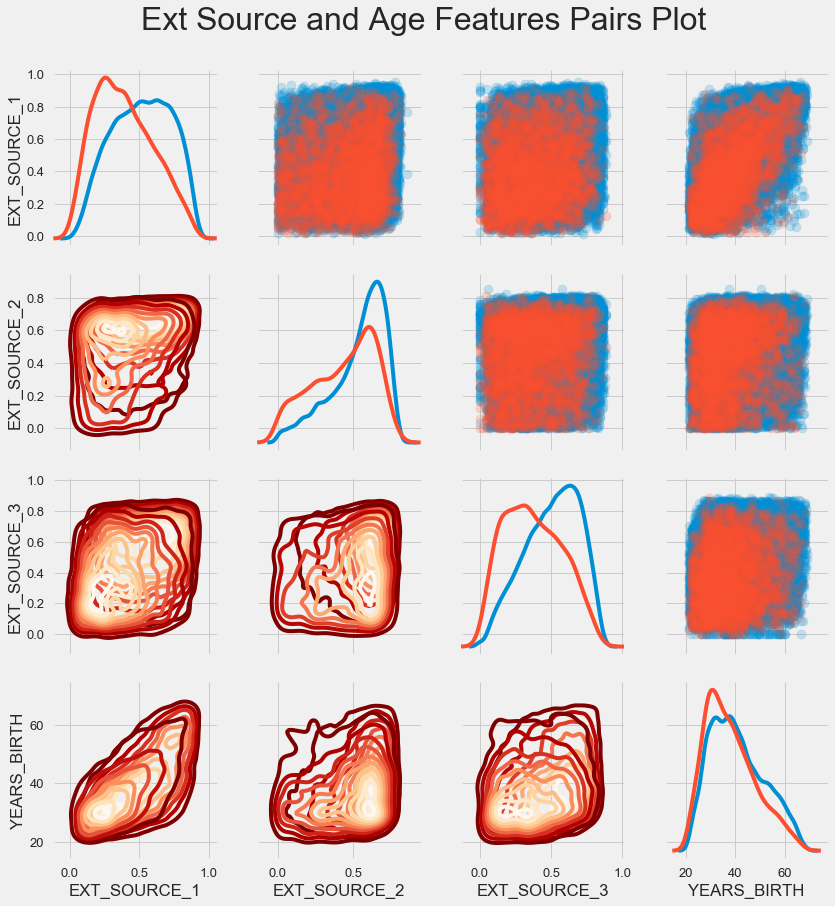
Rückzahlbare Kredite werden in blau angezeigt, nicht rückzahlbar in rot. All dies zu interpretieren ist ziemlich schwierig, aber ein guter Druck auf einem T-Shirt oder einem Bild in einem Museum für moderne Kunst kann aus diesem Bild hervorgehen.
Untersuchung anderer Anzeichen
Lassen Sie uns andere Merkmale und ihre Abhängigkeit von der Zielvariablen genauer betrachten. Da es viele kategoriale gibt (und wir haben es bereits geschafft, sie zu kodieren), benötigen wir wieder die Anfangsdaten. Nennen wir sie etwas anders, um Verwirrung zu vermeiden
application_train = pd.read_csv(PATH+"application_train.csv") application_test = pd.read_csv(PATH+"application_test.csv")
Wir werden auch einige Funktionen benötigen, um die Verteilungen und ihren Einfluss auf die Zielvariable schön darzustellen. Vielen Dank
an sie für den
Autor dieses
Kernels def plot_stats(feature,label_rotation=False,horizontal_layout=True): temp = application_train[feature].value_counts() df1 = pd.DataFrame({feature: temp.index,' ': temp.values})
Wir werden also die Hauptzeichen der Kunden berücksichtigen
Art des Darlehens
plot_stats('NAME_CONTRACT_TYPE')
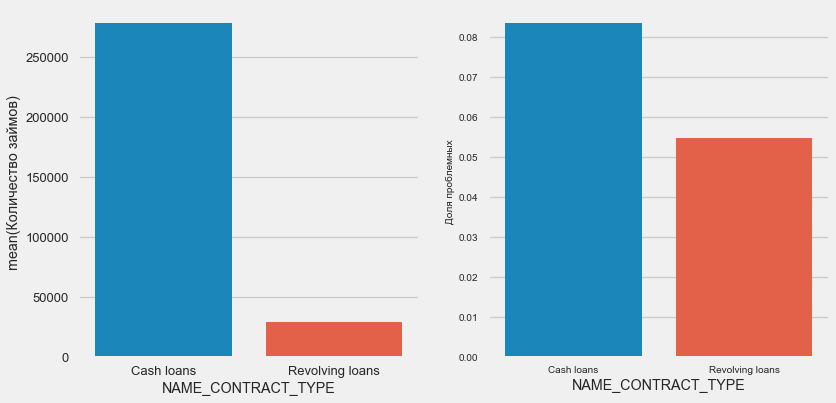
Interessanterweise machen revolvierende Kredite (wahrscheinlich Überziehungskredite oder ähnliches) weniger als 10% der Gesamtzahl der Kredite aus. Gleichzeitig ist der Prozentsatz der Nichtrendite unter ihnen viel höher. Ein guter Grund, die Arbeitsweise dieser Kredite zu überarbeiten und sie vielleicht sogar aufzugeben.
Geschlecht des Kunden
plot_stats('CODE_GENDER')
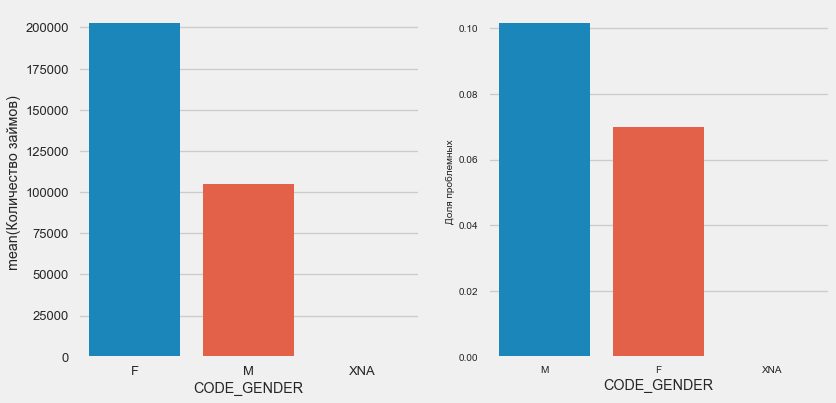
Es gibt fast doppelt so viele weibliche Klienten wie Männer, wobei Männer ein viel höheres Risiko aufweisen.
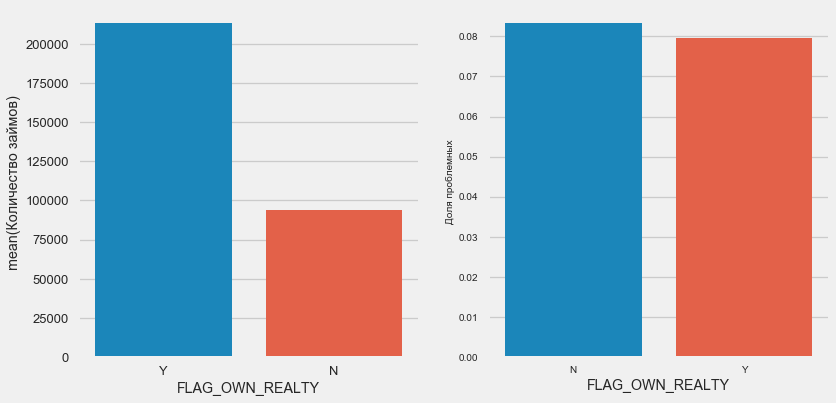
Auto- und Eigentum
plot_stats('FLAG_OWN_CAR') plot_stats('FLAG_OWN_REALTY')
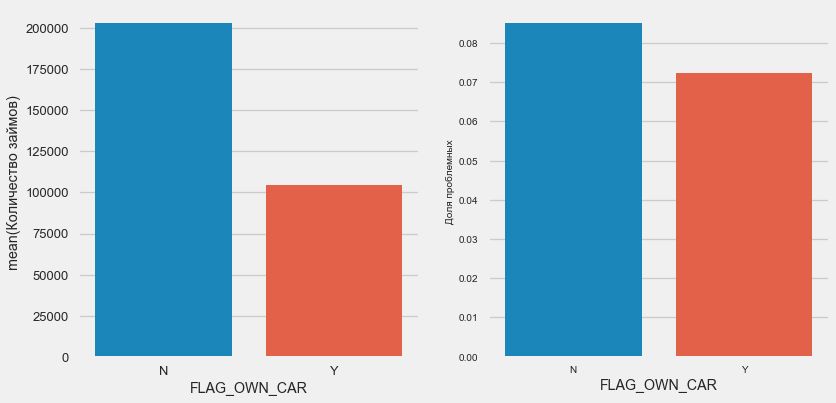
Kunden mit dem Auto sind halb so viel wie "pferdelos". Das Risiko ist fast gleich, Kunden mit der Maschine zahlen etwas besser.
Bei Immobilien ist das Gegenteil der Fall - es gibt halb so wenige Kunden ohne diese. Das Risiko für Immobilienbesitzer ist ebenfalls etwas geringer.
Familienstand
plot_stats('NAME_FAMILY_STATUS',True, True)
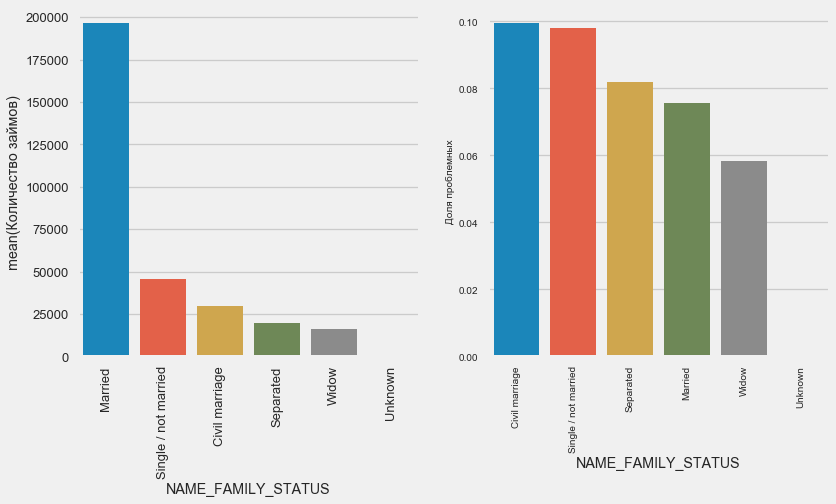
Während die meisten Klienten verheiratet sind, sind Zivil- und Alleinklienten die riskantesten. Witwer weisen ein minimales Risiko auf.
Anzahl der Kinder
plot_stats('CNT_CHILDREN')
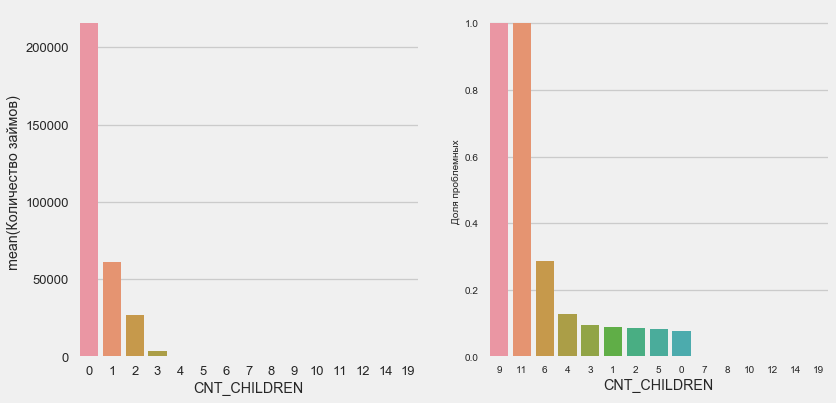
Die meisten Kunden sind kinderlos. Gleichzeitig weisen Kunden mit 9 und 11 Kindern eine vollständige Nichtrückerstattung auf
application_train.CNT_CHILDREN.value_counts()
0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64Wie die Berechnung der Werte zeigt, sind diese Daten statistisch nicht signifikant - nur 1-2 Kunden beider Kategorien. Alle drei gingen jedoch in Verzug, ebenso wie die Hälfte der Kunden mit 6 Kindern.
Anzahl der Familienmitglieder
plot_stats('CNT_FAM_MEMBERS',True)
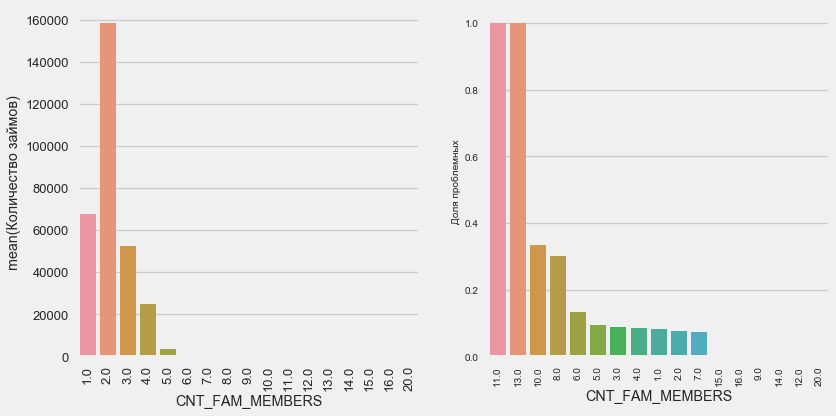
Die Situation ist ähnlich - je weniger Münder, desto höher die Rendite.
Art des Einkommens
plot_stats('NAME_INCOME_TYPE',False,False)
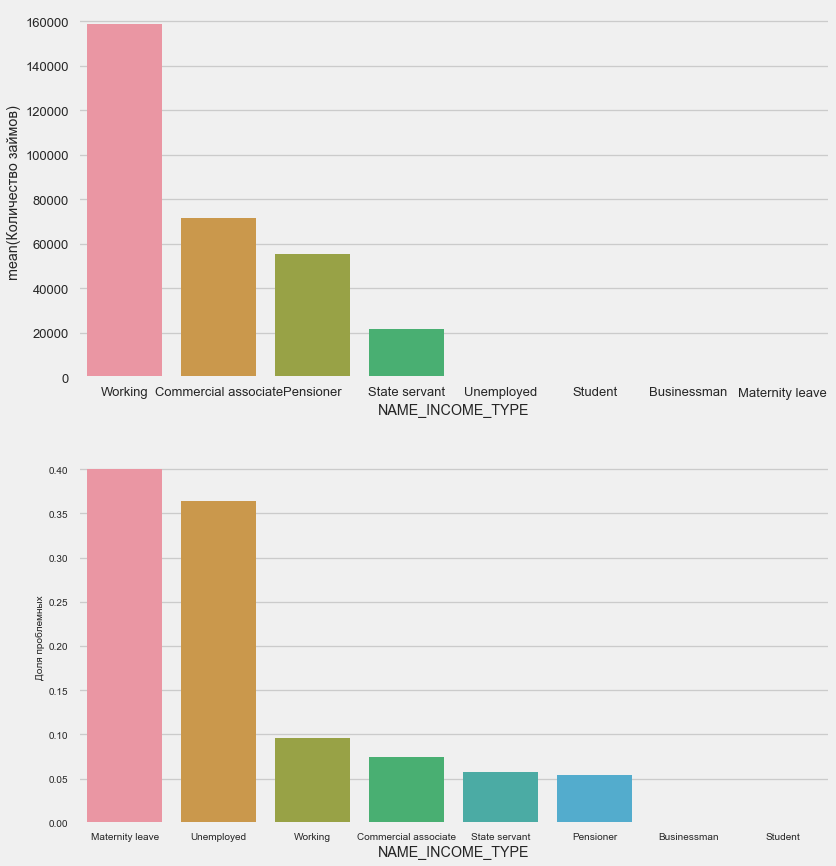
Alleinerziehende Mütter und Arbeitslose werden wahrscheinlich in der Antragsphase abgeschnitten - es gibt zu wenige von ihnen in der Stichprobe. Aber die Probleme zeigen sich stabil.
Art der Aktivität
plot_stats('OCCUPATION_TYPE',True, False)
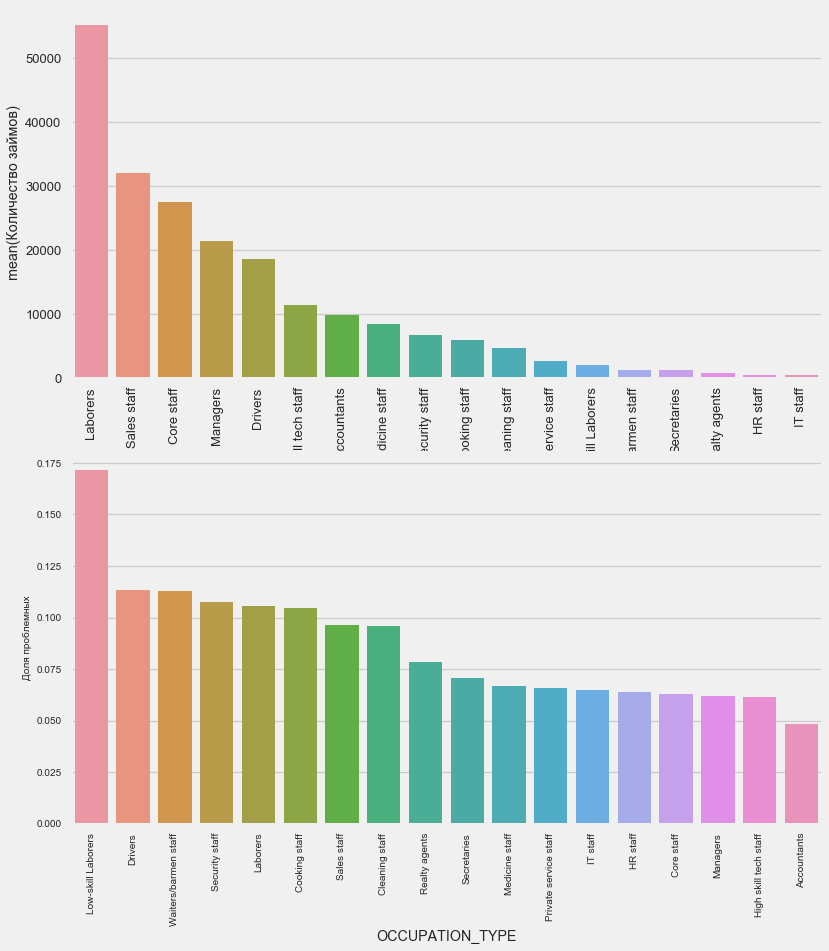
application_train.OCCUPATION_TYPE.value_counts()
Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64Es ist für Fahrer und Sicherheitsbeamte von Interesse, die zahlreich sind und häufiger Probleme haben als andere Kategorien.
Bildung
plot_stats('NAME_EDUCATION_TYPE',True)
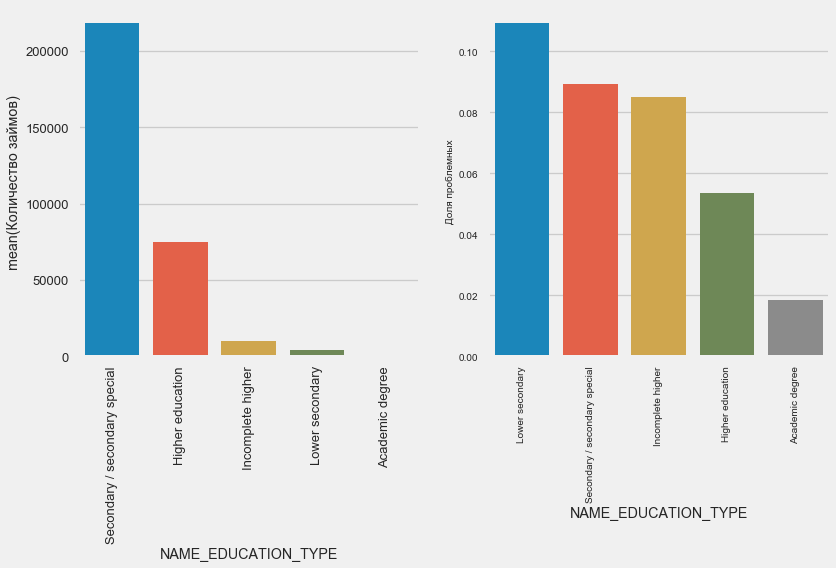
Je höher die Ausbildung, desto besser ist natürlich die Wiederholung.
Art der Organisation - Arbeitgeber
plot_stats('ORGANIZATION_TYPE',True, False)
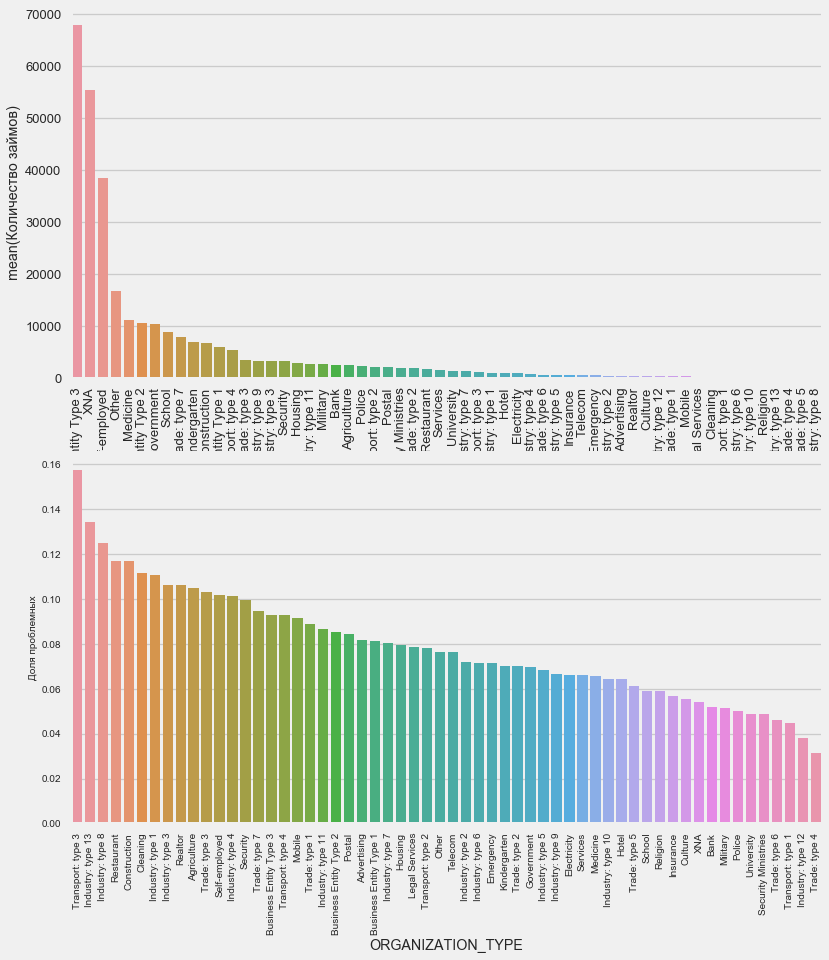
Der höchste Prozentsatz der Nichtrückgabe wird bei Transport: Typ 3 (16%), Branche: Typ 13 (13,5%), Branche: Typ 8 (12,5%) und Restaurant (bis zu 12%) beobachtet.
Kreditvergabe
Berücksichtigen Sie die Verteilung der Kreditbeträge und ihre Auswirkungen auf die Rückzahlung
plt.figure(figsize=(12,5)) plt.title(" AMT_CREDIT") ax = sns.distplot(app_train["AMT_CREDIT"])
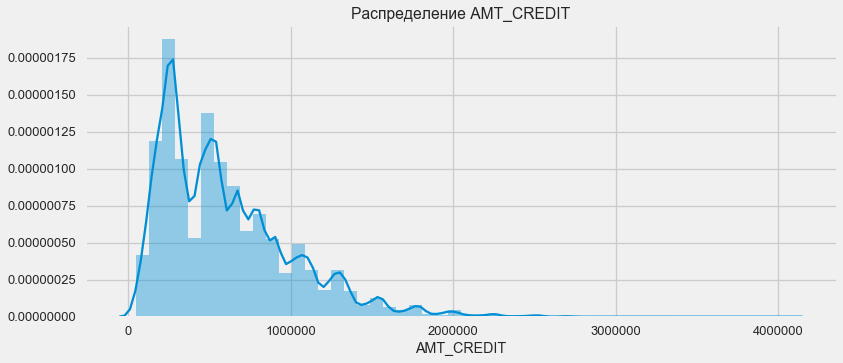
plt.figure(figsize=(12,5))
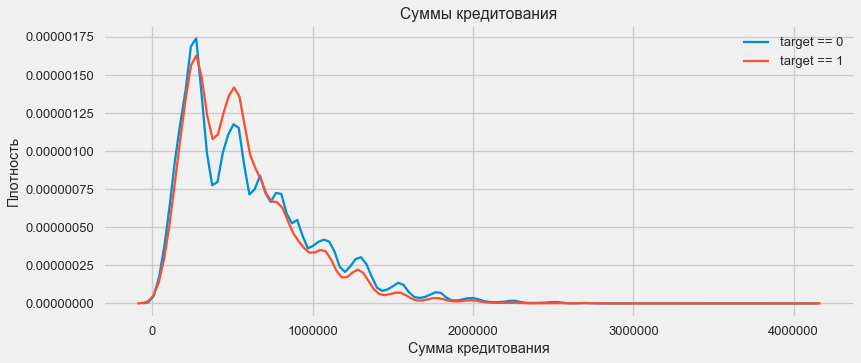
Wie das Dichtediagramm zeigt, werden robuste Mengen häufiger zurückgegeben
Dichteverteilung
plt.figure(figsize=(12,5)) plt.title(" REGION_POPULATION_RELATIVE") ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])
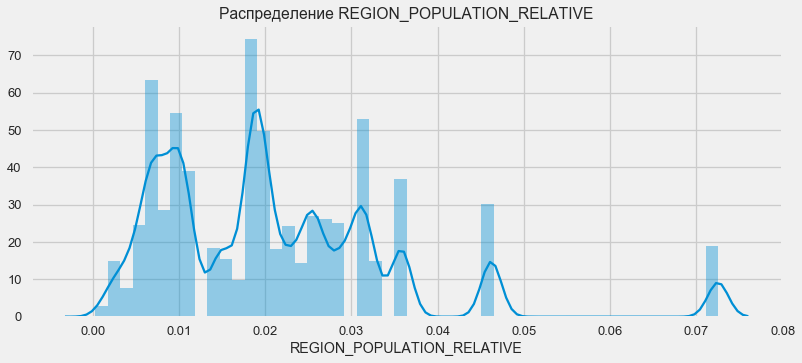
plt.figure(figsize=(12,5))
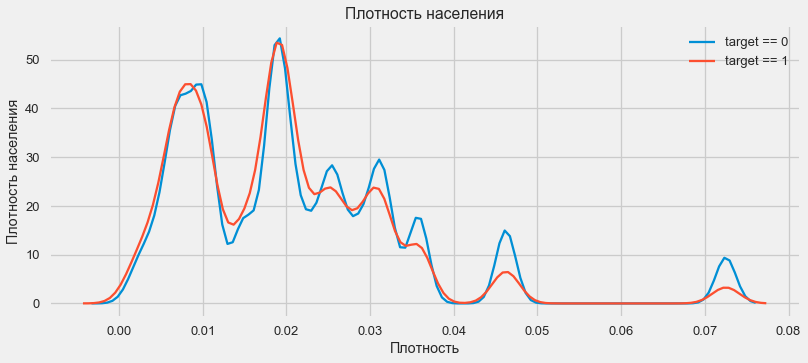
Kunden aus bevölkerungsreicheren Regionen zahlen Kredite tendenziell besser.
So erhielten wir eine Vorstellung von den Hauptmerkmalen des Datensatzes und deren Einfluss auf das Ergebnis. Wir werden nichts spezielles mit den in diesem Artikel aufgeführten tun, aber sie können sich in zukünftigen Arbeiten als sehr wichtig herausstellen.
Feature Engineering - Feature-Konvertierung
Wettbewerbe auf Kaggle werden durch Transformation von Zeichen gewonnen - derjenige, der aus den Daten die nützlichsten Zeichen erstellen kann, gewinnt. Zumindest für strukturierte Daten sind Gewinnmodelle jetzt grundsätzlich verschiedene Optionen zur Erhöhung des Gradienten. In den meisten Fällen ist es effizienter, Zeit mit der Konvertierung von Attributen zu verbringen, als Hyperparameter einzurichten oder Modelle auszuwählen. Ein Modell kann immer noch nur aus den Daten lernen, die an es übertragen wurden. Die Hauptverantwortung für das Datum des Wissenschaftlers liegt darin, sicherzustellen, dass die Daten für die Aufgabe relevant sind.
Der Prozess der Transformation von Merkmalen kann die Erstellung neuer verfügbarer Daten, die Auswahl der wichtigsten verfügbaren Daten usw. umfassen. Wir werden diesmal Polynomzeichen versuchen.
Polynomzeichen
Die Polynommethode zum Erstellen von Features besteht darin, dass wir einfach Features erstellen, die dem Grad der verfügbaren Features und ihren Produkten entsprechen. In einigen Fällen können solche konstruierten Merkmale eine stärkere Korrelation mit der Zielvariablen aufweisen als ihre „Eltern“. Obwohl solche Methoden häufig in statistischen Modellen verwendet werden, sind sie beim maschinellen Lernen viel seltener. Allerdings. Nichts hindert uns daran, sie auszuprobieren, zumal Scikit-Learn eine Klasse speziell für diese Zwecke hat - PolynomialFeatures -, die Polynom-Features und ihre Produkte erstellt. Sie müssen nur die ursprünglichen Features selbst und den maximalen Grad angeben, in dem sie erhöht werden müssen. Wir verwenden die stärksten Effekte auf das Ergebnis von 4 Attributen und Grad 3, um das Modell nicht zu komplizieren und eine Überanpassung zu vermeiden (Übertraining des Modells - seine übermäßige Anpassung an das Trainingsmuster).
: (307511, 35)
get_feature_names poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']Insgesamt 35 Polynom- und Ableitungsmerkmale. Überprüfen Sie ihre Korrelation mit dem Ziel.
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64Einige Zeichen zeigen also eine höhere Korrelation als das Original. Es ist sinnvoll, mit und ohne sie zu lernen (wie viel mehr beim maschinellen Lernen kann dies experimentell bestimmt werden). Erstellen Sie dazu eine Kopie der Datenrahmen und fügen Sie dort neue Funktionen hinzu.
: (307511, 277)
: (48744, 277)Modelltraining
Grundstufe
In den Berechnungen müssen Sie von einer grundlegenden Ebene des Modells ausgehen, unter die es nicht mehr möglich ist, zu fallen. In unserem Fall könnte dies für alle Testkunden 0,5 sein - dies zeigt, dass wir überhaupt keine Ahnung haben, ob der Kunde das Darlehen zurückzahlen wird oder nicht. In unserem Fall wurden bereits Vorarbeiten durchgeführt und komplexere Modelle können verwendet werden.Logistische Regression
Um die logistische Regression zu berechnen , müssen wir Tabellen mit codierten kategorialen Merkmalen erstellen, die fehlenden Daten ausfüllen und normalisieren (auf Werte von 0 bis 1 bringen). All dies führt den folgenden Code aus: from sklearn.preprocessing import MinMaxScaler, Imputer
: (307511, 242)
: (48744, 242)Wir verwenden die logistische Regression von Scikit-Learn als erstes Modell. Nehmen wir das Entlaubungsmodell mit einer Korrektur - wir senken den Regularisierungsparameter C, um eine Überanpassung zu vermeiden. Die Syntax ist normal - wir erstellen ein Modell, trainieren es und prognostizieren die Wahrscheinlichkeit mit Predict_Proba (wir brauchen Wahrscheinlichkeit, nicht 0/1). from sklearn.linear_model import LogisticRegression
Jetzt können Sie eine Datei zum Hochladen auf Kaggle erstellen. Erstellen Sie einen Datenrahmen aus der Kunden-ID und der Wahrscheinlichkeit einer Nichtrückgabe und laden Sie ihn hoch. submit = app_test[['SK_ID_CURR']] submit['TARGET'] = log_reg_pred submit.head()
SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694 submit.to_csv('log_reg_baseline.csv', index = False)
Das Ergebnis unserer titanischen Arbeit: 0,673, mit dem besten Ergebnis für heute ist 0,802.Verbessertes Modell - Zufälliger Wald
Logreg zeigt sich nicht sehr gut. Versuchen wir, ein verbessertes Modell zu verwenden - einen zufälligen Wald. Dies ist ein viel leistungsfähigeres Modell, das Hunderte von Bäumen bauen und ein viel genaueres Ergebnis erzielen kann. Wir benutzen 100 Bäume. Das Schema der Arbeit mit dem Modell ist das gleiche, völlig standardmäßige - Laden des Klassifikators, Training. Vorhersage. from sklearn.ensemble import RandomForestClassifier
Das zufällige Waldergebnis ist etwas besser - 0,683Trainingsmodell mit Polynommerkmalen
Jetzt haben wir ein Modell. Das macht zumindest etwas - es ist Zeit, unsere Polynomzeichen zu testen. Machen wir dasselbe mit ihnen und vergleichen wir das Ergebnis. poly_features_names = list(app_train_poly.columns)
Das Ergebnis eines zufälligen Waldes mit Polynommerkmalen ist schlechter geworden - 0,633. Was die Notwendigkeit ihrer Verwendung stark in Frage stellt.Gradientenverstärkung
— « » . «» . .
from lightgbm import LGBMClassifier clf = LGBMClassifier() clf.fit(train, train_labels) predictions = clf.predict_proba(test)[:, 1]
LightGBM — 0,735,—
— ( ). , , .
feature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
0.01 = 158
, 4 . — , ,
Hinzufügen von Daten aus anderen Tabellen
Jetzt werden wir sorgfältig über zusätzliche Tabellen nachdenken und darüber, was damit gemacht werden kann. Beginnen Sie sofort mit der Vorbereitung der Tische für das weitere Training. Löschen Sie jedoch zuerst die umfangreichen Tabellen der Vergangenheit aus dem Speicher, löschen Sie den Speicher mit dem Garbage Collector und importieren Sie die für die weitere Analyse erforderlichen Bibliotheken. import gc
Importieren Sie Daten und entfernen Sie sofort die Zielspalte in einer separaten Spalte data = pd.read_csv('../input/application_train.csv') test = pd.read_csv('../input/application_test.csv') prev = pd.read_csv('../input/previous_application.csv') buro = pd.read_csv('../input/bureau.csv') buro_balance = pd.read_csv('../input/bureau_balance.csv') credit_card = pd.read_csv('../input/credit_card_balance.csv') POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv') payments = pd.read_csv('../input/installments_payments.csv')
Codieren Sie sofort kategoriale Features. Wir haben dies bereits zuvor getan und die Trainings- und Testmuster separat codiert und dann die Daten ausgerichtet. Versuchen wir einen etwas anderen Ansatz - wir werden alle diese kategorialen Zeichen finden, die Datenrahmen kombinieren, aus der Liste der gefundenen kodieren und dann die Stichproben erneut in Trainings- und Testmuster unterteilen. categorical_features = [col for col in data.columns if data[col].dtype == 'object'] one_hot_df = pd.concat([data,test]) one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features) data = one_hot_df.iloc[:data.shape[0],:] test = one_hot_df.iloc[data.shape[0]:,] print (' ', data.shape) print (' ', test.shape)
(307511, 245)
(48744, 245)Kreditbürodaten zum monatlichen Kreditsaldo.
buro_balance.head()
 MONTHS_BALANCE - Die Anzahl der Monate vor dem Datum der Beantragung eines Darlehens. Schauen Sie sich die "Status" genauer an.
MONTHS_BALANCE - Die Anzahl der Monate vor dem Datum der Beantragung eines Darlehens. Schauen Sie sich die "Status" genauer an. buro_balance.STATUS.value_counts()
C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64Status bedeuten Folgendes:- geschlossen, dh zurückgezahltes Darlehen. X ist ein unbekannter Status. 0 - aktuelles Darlehen, keine Kriminalität. 1 - Verzögerung von 1-30 Tagen, 2 - Verzögerung von 31-60 Tagen usw. bis Status 5 - Das Darlehen wird an einen Dritten verkauft oder abgeschrieben.Hier können beispielsweise folgende Zeichen unterschieden werden: buro_grouped_size - die Anzahl der Einträge in der Datenbank buro_grouped_max - der maximale Kreditsaldo buro_grouped_min - der minimale KreditsaldoUnd all diese Kreditstatus können codiert werden (wir verwenden die Unstack-Methode und hängen die empfangenen Daten seitdem an die Buro-Tabelle an SK_ID_BUREAU ist hier und da gleich. buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size() buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max() buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min() buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False) buro_counts_unstacked = buro_counts.unstack('STATUS') buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',] buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU') del buro_balance gc.collect()
Allgemeine Informationen zu Kreditauskunfteien
buro.head()
 (Die ersten 7 Spalten werden angezeigt.) Es gibt eineganze Reihe von Daten, die Sie im Allgemeinen einfach mit One-Hot-Encoding codieren können, gruppieren nach SK_ID_CURR, durchschnittlich und auf die gleiche Weise für den Beitritt zur Haupttabelle vorbereiten
(Die ersten 7 Spalten werden angezeigt.) Es gibt eineganze Reihe von Daten, die Sie im Allgemeinen einfach mit One-Hot-Encoding codieren können, gruppieren nach SK_ID_CURR, durchschnittlich und auf die gleiche Weise für den Beitritt zur Haupttabelle vorbereiten buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object'] buro = pd.get_dummies(buro, columns=buro_cat_features) avg_buro = buro.groupby('SK_ID_CURR').mean() avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU'] del avg_buro['SK_ID_BUREAU'] del buro gc.collect()
Daten zu früheren Anwendungen
prev.head()
 In ähnlicher Weise codieren wir kategoriale Merkmale, mitteln und kombinieren sie über die aktuelle ID.
In ähnlicher Weise codieren wir kategoriale Merkmale, mitteln und kombinieren sie über die aktuelle ID. prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object'] prev = pd.get_dummies(prev, columns=prev_cat_features) avg_prev = prev.groupby('SK_ID_CURR').mean() cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count() avg_prev['nb_app'] = cnt_prev['SK_ID_PREV'] del avg_prev['SK_ID_PREV'] del prev gc.collect()
Kreditkartenguthaben
POS_CASH.head()

POS_CASH.NAME_CONTRACT_STATUS.value_counts()
Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64Wir codieren kategoriale Merkmale und bereiten eine Tabelle zum Kombinieren vor le = LabelEncoder() POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Kartendaten
credit_card.head()
 (erste 7 Spalten)Ähnliche Arbeit
(erste 7 Spalten)Ähnliche Arbeit credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Zahlungsdaten
payments.head()
 (Die ersten 7 Spalten werden angezeigt.)Erstellen wir drei Tabellen - mit Durchschnitts-, Minimal- und Maximalwerten aus dieser Tabelle.
(Die ersten 7 Spalten werden angezeigt.)Erstellen wir drei Tabellen - mit Durchschnitts-, Minimal- und Maximalwerten aus dieser Tabelle. avg_payments = payments.groupby('SK_ID_CURR').mean() avg_payments2 = payments.groupby('SK_ID_CURR').max() avg_payments3 = payments.groupby('SK_ID_CURR').min() del avg_payments['SK_ID_PREV'] del payments gc.collect()
Tabellenverknüpfung
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3 gc.collect() print (' ', data.shape) print (' ', test.shape) print (' ', y.shape)
(307511, 504)
(48744, 504)
(307511,)Und tatsächlich werden wir diesen doppelten Tisch mit einem Gradienten-Boost treffen! from lightgbm import LGBMClassifier clf2 = LGBMClassifier() clf2.fit(data, y) predictions = clf2.predict_proba(test)[:, 1]
das Ergebnis ist 0,770.OK, zum Schluss versuchen wir eine komplexere Technik mit Falten in Falten, Kreuzvalidierung und Auswahl der besten Iteration. folds = KFold(n_splits=5, shuffle=True, random_state=546789) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) feature_importance_df = pd.DataFrame() feats = [f for f in data.columns if f not in ['SK_ID_CURR']] for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier( n_estimators=10000, learning_rate=0.03, num_leaves=34, colsample_bytree=0.9, subsample=0.8, max_depth=8, reg_alpha=.1, reg_lambda=.1, min_split_gain=.01, min_child_weight=375, silent=-1, verbose=-1, ) clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=100, early_stopping_rounds=100
Full AUC score 0.785845Letzter Treffer bei Kaggle 0.783Wohin als nächstes gehen
Arbeiten Sie auf jeden Fall weiter mit Schildern. Durchsuchen Sie die Daten, wählen Sie einige der Zeichen aus, kombinieren Sie sie und hängen Sie zusätzliche Tabellen auf andere Weise an. Sie können mit Hyperparametern Mogheli experimentieren - viele Richtungen.Ich hoffe, diese kleine Zusammenstellung hat Ihnen moderne Methoden zur Erforschung von Daten und zur Erstellung von Vorhersagemodellen gezeigt. Lerne Daten, nimm an Wettbewerben teil, sei cool!Und wieder Links zu den Kerneln, die mir bei der Vorbereitung dieses Artikels geholfen haben. Der Artikel wird auch in Form eines Laptops auf Github veröffentlicht. Sie können ihn herunterladen, datieren und ausführen und experimentieren.Will Koehrsen. Beginnen Sie hier: Eine sanfte Einführungsban. HomeCreditRisk: Umfangreiche EDA + Baseline [0.772]Gabriel Preda. Home Credit Default Risk Extensive EDAPavan Raj. Loan repayers v/s Loan defaulters — HOME CREDITLem Lordje Ko. 15 lines: Just EXT_SOURCE_xShanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERINGDmitriy Kisil. Good_fun_with_LigthGBM