Vorverarbeitung ist ein allgemeiner Begriff für alle Manipulationen, die mit Daten vor der Übertragung ihres Modells durchgeführt werden, einschließlich Zentrieren, Normalisieren, Verschieben, Drehen, Zuschneiden usw. In der Regel ist in zwei Fällen eine Vorverarbeitung erforderlich.
- Datenbereinigung . Angenommen, einige Artefakte sind in den Bildern vorhanden. Um das Modelltraining zu erleichtern, müssen Artefakte in der Vorverarbeitungsphase entfernt werden.
- Hinzufügung von Daten . Manchmal reichen kleine Datenmengen nicht für ein qualitativ hochwertiges Deep-Model-Training aus. Ein Datenergänzungsansatz ist sehr hilfreich bei der Lösung dieses Problems. Dies ist der Prozess, bei dem jede Datenprobe auf verschiedene Weise transformiert und solche modifizierten Proben zum Datensatz hinzugefügt werden. Auf diese Weise kann die effektive Größe des Datensatzes erhöht werden.
Betrachten wir einige mögliche Transformationsmethoden während der Vorverarbeitung und deren Implementierung durch Keras.

Daten
In diesem und den folgenden Artikeln wird ein Datensatz verwendet, um die emotionale Färbung von Bildern zu analysieren. Es enthält 1.500 Beispiele von Bildern, die in zwei Klassen unterteilt sind - positiv und negativ. Schauen wir uns einige Beispiele an.
 Negative Beispiele
Negative Beispiele Positive Beispiele
Positive BeispieleTransformationen reinigen
Betrachten Sie nun eine Reihe möglicher Transformationen, die häufig zum Bereinigen von Daten verwendet werden, sowie deren Implementierung und Auswirkungen auf Bilder.
Alle Codefragmente finden Sie im Buch
Preprocessing.ipynb .
Neuskalierung
Bilder werden normalerweise im RGB-Format (Rot, Grün, Blau) gespeichert. In diesem Format wird das Bild durch ein dreidimensionales (oder dreikanaliges) Array dargestellt.
 RGB-Zerlegung des Bildes. Karte aus Wikiwand
RGB-Zerlegung des Bildes. Karte aus WikiwandEine Dimension wird für Kanäle verwendet (rot, grün und blau), die anderen beiden repräsentieren den Standort. Somit wird jedes Pixel mit drei Zahlen codiert. Jede Zahl wird normalerweise als vorzeichenloser 8-Bit-Integer-Typ (0 bis 255) gespeichert.
Eine Neuskalierung ist eine Operation, bei der der numerische Datenbereich
geändert wird, indem er einfach durch eine vorgegebene Konstante geteilt wird. In tiefen neuronalen Netzen kann es aufgrund möglicher Überläufe, Optimierungsprobleme, Stabilität usw. erforderlich sein, die Eingabedaten auf einen Bereich von 0 bis 1 zu beschränken.
Zum Beispiel skalieren wir unsere Daten aus dem Bereich [0; 255] auf den Bereich [0; 1]. Im Folgenden verwenden wir die Keras
ImageDataGenerator- Klasse, mit der Sie alle Transformationen im
laufenden Betrieb durchführen können.
Erstellen wir zwei Instanzen dieser Klasse: eine für die transformierten Daten, die andere für die Quelle:

(oder für Standarddaten). Es muss nur die Skalierungskonstante angegeben werden. Darüber hinaus können Sie mit der
ImageDataGenerator- Klasse Daten direkt aus einem Ordner auf Ihrer Festplatte mithilfe der
flow_from_directory- Methode
streamen .
Alle Parameter finden Sie in der
Dokumentation , aber die Hauptparameter sind: der Pfad zum Stream und die Zielbildgröße (wenn das Bild nicht mit der Zielgröße übereinstimmt, schneidet oder erstellt der Generator es einfach). Schließlich erhalten wir eine Probe vom Generator und betrachten die Ergebnisse.
Optisch sind beide Bilder identisch, der Grund dafür ist jedoch, dass Python * -Tools die Größe von Bildern automatisch ändern
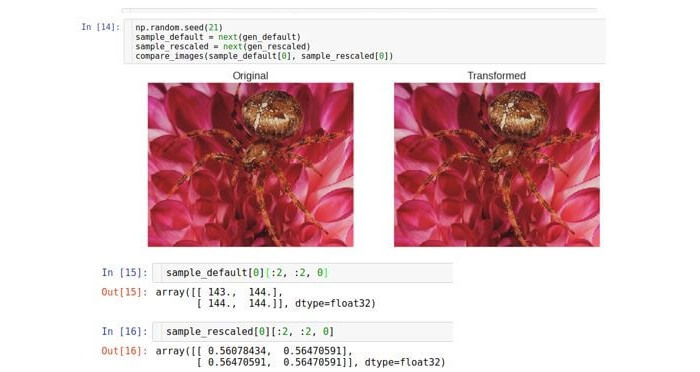
auf den Standardbereich, damit sie auf dem Bildschirm angezeigt werden können. Betrachten Sie Rohdaten (Arrays). Wie Sie sehen können, unterscheiden sich die Rohmassive genau 255-mal.
Graustufen
Eine andere Art der Transformation, die nützlich sein kann, ist
Graustufen , die ein Farb-RGB-Bild in ein Bild konvertiert, in dem alle Farben in Graustufen dargestellt werden. Bei der herkömmlichen Bildverarbeitung kann eine Graustufenübersetzung in Kombination mit einem nachfolgenden Schwellenwert verwendet werden. Dieses Transformationspaar kann verrauschte Pixel zurückweisen und Formen im Bild definieren. Heutzutage werden alle diese Operationen vom Convolutional Neural Network (CNN) ausgeführt, aber die Graustufenkonvertierung als Vorverarbeitungsschritt kann immer noch nützlich sein. Führen Sie diesen Schritt in Keras mit derselben Generatorklasse aus.
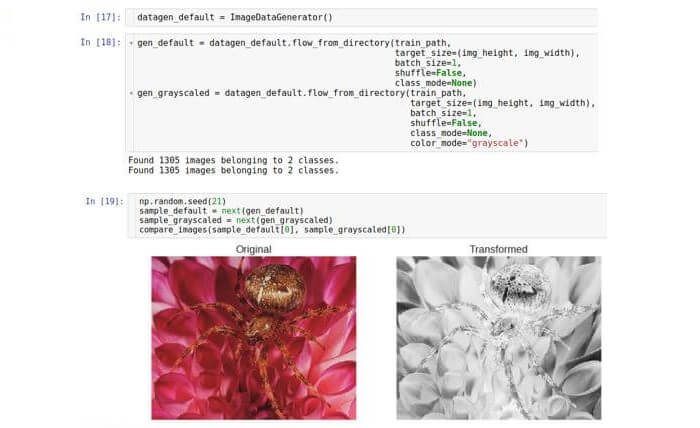
Hier erstellen wir nur eine Instanz der Klasse und nehmen zwei verschiedene Generatoren daraus. Der zweite Generator setzt den Parameter
color_mode auf "Graustufen" (der Standardwert ist "RGB").
Proben zentrieren
Wir haben bereits gesehen, dass die Werte von Rohdaten im Bereich von 0 bis 255 liegen. Somit ist eine Stichprobe eine dreidimensionale Anordnung von Zahlen von 0 bis 255. Angesichts der Prinzipien der Stabilitätsstabilität (Beseitigung des Problems des Verschwindens oder Sättigens von Werten)
kann es erforderlich sein, den Datensatz zu normalisieren so dass der Durchschnitt jeder Datenprobe 0 ist .
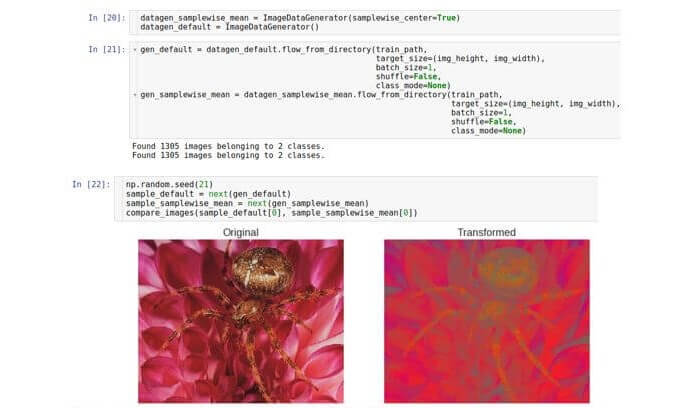
Dazu ist es notwendig, den Durchschnittswert über die gesamte Stichprobe zu berechnen und von jeder Zahl in der gegebenen Stichprobe abzuziehen.
In Keras erfolgt dies mit dem Parameter
samplewise_center .
Normalisierung der Standardabweichung der Proben
Diese Vorverarbeitungsstufe basiert auf der gleichen Idee wie die Zentrierung der Proben, aber anstatt den Durchschnitt auf 0 von zu setzen, setzt sie die Standardabweichung auf 1.

Die Normalisierung der
Standardabweichung wird durch den Parameter
samplewise_std_normalization gesteuert . Es ist zu beachten, dass diese beiden Methoden zur Normalisierung von Proben häufig zusammen angewendet werden.
Diese Transformation kann in Deep-Learning-Modellen verwendet werden, um die Optimierungsstabilität zu verbessern, indem die Auswirkungen explodierender Gradienten verringert werden.
Feature-Zentrierung
In den beiden vorherigen Abschnitten wurde eine Normalisierungstechnik verwendet, bei der jede einzelne Datenprobe untersucht wurde. Es gibt einen alternativen Ansatz zum Normalisierungsverfahren. Betrachten Sie jede Zahl im Bildarray als Zeichen. Dann ist
jedes Bild ein Merkmalsvektor . Der Datensatz enthält viele solcher Vektoren. Daher können wir sie als eine unbekannte
Verteilung betrachten . Diese Verteilung besteht aus mehreren Parametern und ihre Dimension entspricht der Anzahl der Features, dh Breite × Höhe × 3. Obwohl die tatsächliche Verteilung der Daten unbekannt ist, können Sie versuchen, sie durch Subtrahieren des durchschnittlichen Verteilungswerts zu normalisieren. Es ist zu beachten, dass der Durchschnittswert ein Vektor derselben Dimension ist, dh es ist auch ein Bild. Mit anderen Worten, wir mitteln über den gesamten Datensatz und nicht über eine Stichprobe.
Es gibt einen speziellen Keras-Parameter namens
featurewise_centering , aber leider gab es ab August 2017 einen Fehler bei der Implementierung. Deshalb setzen wir es selbst um. Zunächst betrachten wir den gesamten Datensatz im Speicher (wir können es uns leisten, da es sich um einen kleinen Datensatz handelt). Dazu haben wir die Paketgröße auf die Größe des Datensatzes eingestellt. Dann berechnen wir das Durchschnittsbild über den gesamten Datensatz und subtrahieren es schließlich vom Testbild.
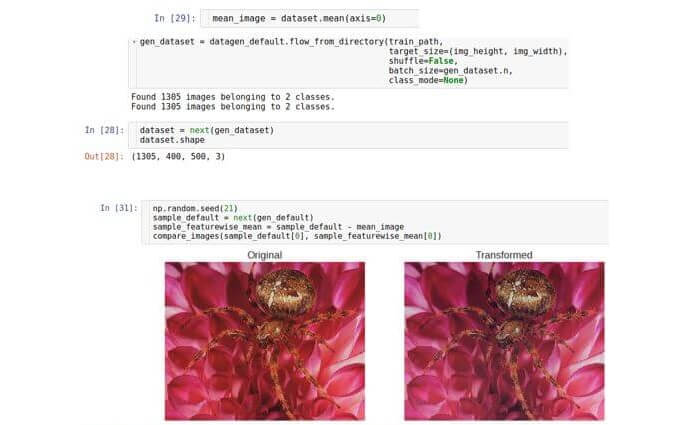
Normalisierung der Standardabweichung der Symptome
Die Idee, die Standardabweichung zu normalisieren, entspricht genau der Idee der Zentrierung. Der einzige Unterschied besteht darin, dass wir nicht den Durchschnitt subtrahieren, sondern durch die Standardabweichung dividieren. Optisch ist das Ergebnis nicht viel anders. Das gleiche passierte

Während der Neuskalierung wird die Konstante manuell angegeben, da die Normalisierung der Standardabweichung nichts anderes ist als eine Neuskalierung mit einer auf bestimmte Weise berechneten Konstante und mit einer einfachen Neuskalierung. Beachten Sie, dass eine ähnliche Idee zur Normalisierung von Datenpaketen das Herzstück einer modernen Deep-Learning-Technik namens
BatchNormalization ist .
Transformation mit dem Zusatz
In diesem Abschnitt werden einige datenabhängige Transformationen betrachtet, die explizit die grafische Natur der Daten verwenden. Diese Arten von Transformationen werden häufig in Datenadditionsverfahren verwendet.
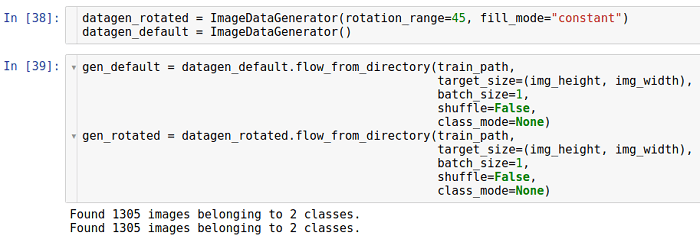
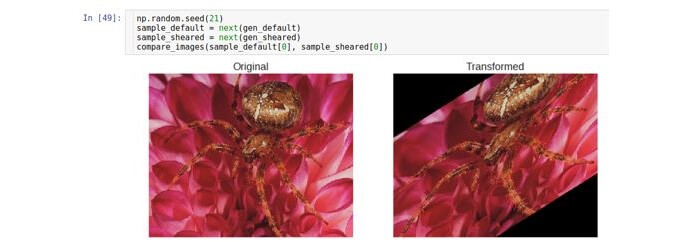
Drehung
Diese Art der Transformation dreht das Bild in eine bestimmte Richtung (im oder gegen den Uhrzeigersinn).
Der Parameter, der die Drehung ermöglicht, heißt
rotationsbereich . Es gibt den Bereich in Grad an, aus dem der Drehwinkel zufällig mit einer gleichmäßigen Verteilung ausgewählt wird. Es ist zu beachten, dass sich die Bildgröße während der Drehung nicht ändert. So können einige Teile des Bildes beschnitten und einige gefüllt werden.
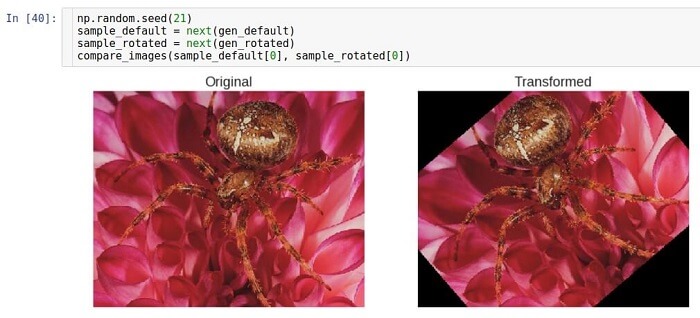
Der
Füllmodus wird mit dem Parameter
fill_mode eingestellt . Es werden verschiedene Füllmethoden unterstützt, aber hier verwenden wir die
Konstantenmethode als Beispiel.
Horizontale Verschiebung
Diese Art der Transformation verschiebt das Bild in eine bestimmte Richtung entlang der horizontalen Achse (links oder rechts).

Die Größe der Verschiebung kann mit dem Parameter
width_shift_range bestimmt und als Teil der Gesamtbildbreite gemessen werden.
Vertikale Verschiebung
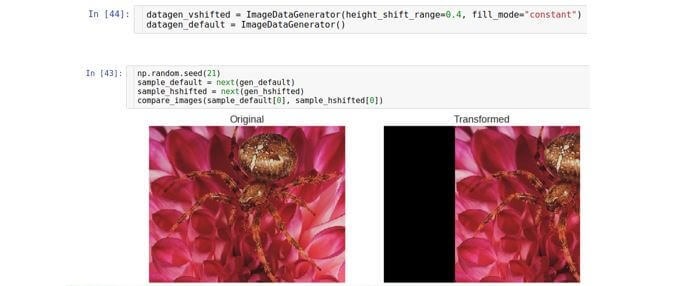
Verschiebt das Bild entlang der vertikalen Achse (nach oben oder unten). Der Parameter, der den Verschiebungsbereich steuert, wird als
height_shift- Generator bezeichnet und auch als Teil der Gesamthöhe des Bildes gemessen.
Beschneiden
Eine Zuschneidekonvertierung oder ein Zuschneiden verschiebt jeden Punkt in vertikaler Richtung um einen Betrag, der proportional zum Abstand von diesem Punkt zum Bildrand ist. Beachten Sie, dass im allgemeinen Fall die Richtung nicht vertikal sein muss und beliebig ist.
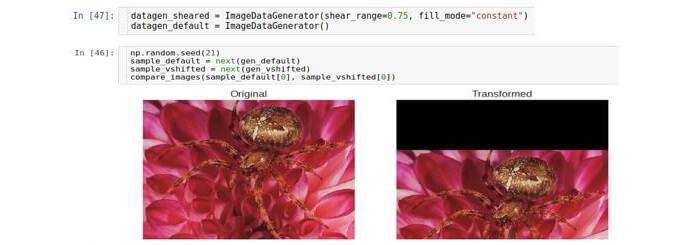
Der Parameter, der die Verschiebung
steuert, heißt
Scherbereich und entspricht dem Abweichungswinkel (im Bogenmaß) zwischen der horizontalen Linie im Originalbild und dem Bild (im mathematischen Sinne) dieser Linie im transformierten Bild.
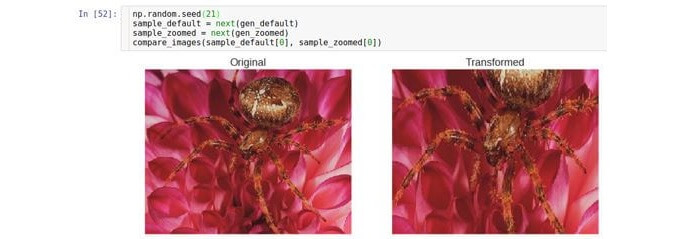
Vergrößern / Verkleinern

Diese Art der Transformation nähert sich dem Originalbild an oder entfernt es. Der Parameter
zoom_range steuert den Zoomfaktor.
Wenn
zoom_range beispielsweise 0,5 ist, wird der Zoomfaktor aus dem Bereich [0,5, 1,5] ausgewählt.
Horizontaler Flip

Kippt das Bild relativ zur vertikalen Achse. Sie kann mit dem Parameter
horizontal_flip ein- oder ausgeschaltet werden.
Vertikaler Flip

Dreht das Bild um die horizontale Achse. Der Parameter
vertical_flip (vom Typ Boolean) steuert das Vorhandensein oder Fehlen dieser Transformation.
Kombination
Wir wenden alle beschriebenen Arten von Transformationen des Komplements gleichzeitig an und sehen, was passiert. Denken Sie daran, dass die Parameter für alle Transformationen zufällig aus einem bestimmten Bereich ausgewählt werden. Daher müssen wir eine Reihe von Stichproben mit einem signifikanten Grad an Diversität erhalten.
Wir initiieren
ImageDataGenerator mit allen verfügbaren Parametern und überprüfen den roten Hydranten auf dem Bild.

Beachten Sie, dass der
konstante Füllmodus nur zur besseren Visualisierung verwendet wurde. Jetzt werden wir einen erweiterten Auffüllmodus verwenden, der als
nächster bezeichnet wird . In diesem Modus wird dem leeren Pixel die Farbe des nächsten vorhandenen Pixels zugewiesen.
Fazit
Dieser Artikel bietet einen Überblick über die grundlegenden Techniken für die Bildvorverarbeitung, z. B. Skalieren, Normalisieren, Drehen, Verschieben und Zuschneiden. Sie demonstrierten auch die Implementierung dieser Transformationstechniken unter Verwendung von Keras und ihre Einführung in den Deep-Learning-Prozess sowohl technisch (
ImageDataGenerator- Klasse) als auch ideologisch (
Datenergänzung ).