Wir teilen weiterhin unsere Erfahrungen bei der Organisation des Data Warehouse, über die wir in einem früheren Beitrag gesprochen haben . Dieses Mal möchten wir darüber sprechen, wie wir CDH-Installationsaufgaben gelöst haben.

CDH-Installation
Wir starten den Cloudera Manager-Server, fügen ihn zum automatischen Laden hinzu und überprüfen, ob er in den aktiven Zustand gewechselt ist:
systemctl start cloudera-scm-server systemctl enable cloudera-scm-server systemctl status cloudera-scm-server
Nachdem es gestiegen ist, folgen wir dem Link "Hostname: 7180 /", melden uns an (admin / admin) und setzen die Installation über die GUI fort. Nach der Autorisierung wird die Installation automatisch gestartet und es wird ein Übergang zur Seite zum Hinzufügen von Hosts zum Cluster vorgenommen:

Es wird empfohlen, alle Hosts hinzuzufügen, die in irgendeiner Weise mit der bereitgestellten Umgebung verbunden sind (auch wenn sie keine Cloudera-Dienste hosten). Dies können Maschinen mit Tools für die kontinuierliche Integration, BI- oder ETL-Tools oder Data Discovery-Tools sein. Durch die Aufnahme dieser Computer in den Cluster können Sie die Gateways der Clusterdienste (Gateways) installieren, die Dateien mit der Konfiguration und dem Speicherort der Clusterdienste enthalten, wodurch die Integration in Programme von Drittanbietern vereinfacht wird. Cloudera Manager bietet außerdem praktische Überwachungstools und die Erstellung von Monitoren für Schlüsselmetriken für alle Cluster-Computer in einem einzigen Fenster, wodurch die Lokalisierung von Problemen während des Betriebs vereinfacht wird. Hosts werden über die Schaltfläche "Neue Suche" hinzugefügt. Es wird ein Übergang zur Seite zum Hinzufügen von Computern zum Cluster vorgenommen, auf der vorgeschlagen wird, ihnen Daten für die Verbindung über SSH bereitzustellen:

Nach dem Hinzufügen der Hosts fahren wir mit der Auswahl der Installationsmethode fort. Da wir die Parsels heruntergeladen haben, wählen wir die Methode "Pakete verwenden (empfohlen)" und müssen nun unser Repository hinzufügen. Wir klicken auf die Schaltfläche "Weitere Optionen", löschen alle dort installierten Standard-Repositorys und fügen die Repository-Adresse mit der CDH-Parsel hinzu - "Hostname / Pakete / CDH /". Nach der Bestätigung sollte rechts neben der Beschriftung „Wählen Sie die Version von CDH aus“ die CDH-Version angezeigt werden, die in der heruntergeladenen Parsel angezeigt wird. Für diese Installationsmethode kann auf dieser Registerkarte nichts konfiguriert werden:

Auf der nächsten Registerkarte werden Sie aufgefordert, das JDK zu installieren. Da wir dies bereits zur Vorbereitung der Installation getan haben, überspringen wir diesen Schritt:

Wenn Sie zur nächsten Registerkarte wechseln, beginnt die Installation der Clusterkomponenten auf den angegebenen Hosts. Nach Abschluss der Installation ist der Übergang zum nächsten Schritt verfügbar. Wenn während der Installation Fehler auftreten (diese Situation ist bei der Installation lokaler Entwicklungsumgebungen aufgetreten ), können Sie deren Details mit dem Befehl "tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log" anzeigen. und indem Sie auf die Schaltfläche Details auf der rechten Seite der Tabelle klicken:

Im nächsten Installationsschritt werden Sie aufgefordert, einen der vorbereiteten Services für die Installation auszuwählen. Zukünftig können Dienste und ihre Rollen manuell konfiguriert werden. Daher ist es nicht sehr wichtig, was auf dieser Registerkarte ausgewählt werden soll. In unserem Fall wurde normalerweise „Core with Impala“ installiert. Auch hier können Sie angeben, dass Cloudera Navigator installiert werden muss. Wenn Sie die Enterprise-Version installieren, sollten Sie dieses nützliche Tool installieren:

Auf der nächsten Registerkarte für Dienste aus dem ausgewählten Satz wird vorgeschlagen, die Rollen und Hosts auszuwählen, auf denen sie installiert werden sollen. Im Folgenden finden Sie einige Richtlinien zum Installieren von Rollen auf Hosts.
HDFS-Rollen
NameNode - wird in einer einzelnen Kopie auf einem der Master-Knoten abgelegt, vorzugsweise dem am meisten entladenen, da dies für den Betrieb des Clusters sehr wichtig ist und einen wesentlichen Beitrag zur Ressourcennutzung leistet.
SecondaryNameNode - wird in einer einzelnen Kopie auf einem der Master-Knoten abgelegt, vorzugsweise nicht auf demselben Knoten wie NameNode (um Fehlertoleranz sicherzustellen).
Balancer - wird in einer einzelnen Kopie auf einem der Master-Knoten platziert.
HttpFS - eine zusätzliche API zu HDFS, die Sie nicht installieren können.
NFS-Gateway - eine sehr nützliche Rolle, mit der Sie HDFS als Netzwerklaufwerk bereitstellen können. Es wird in einer einzelnen Kopie auf einem der Hauptknoten abgelegt.
DataNode - Alle
Datenknoten anlegen.
Bienenstockrollen
Gateway - Hive-Konfigurationsdateien. Es wird auf alle Hosts des Clusters gestellt.
Hive Metastore Server - ein Metadatenserver, der in einer einzigen Kopie auf einem der
Masterknoten installiert ist (z. B. dem, auf dem PostgreSQL installiert ist - dort werden seine Daten gespeichert).
WebHCat - keine Installation erforderlich.
HiveServer2 - wird in einer einzigen Kopie auf demselben Masterknoten wie der Hive Metastore Server installiert (eine Voraussetzung für die gemeinsame Arbeit).
Farbtonrollen
Hue Server - GUI für HDFS wird in einer einzelnen Kopie auf einem der Masterknoten installiert.
Load Balancer - Ein Load Balancer auf der GUI für HDFS wird in einer einzelnen Kopie auf einem der Master-Knoten installiert.
Impala Rollen
Impala StateStore - wird in einer einzelnen Kopie auf einem der Master-Knoten platziert.
Impala Catalog Server - wird in einer einzelnen Kopie auf einem der Master-Knoten abgelegt.
Impala Daemon - Legen Sie alle Datenknoten an (Sie können den Standardwert beibehalten).
Cloudera Manager Services Rollen
Service Monitor, Aktivitätsmonitor, Host Monitor, Berichts-Manager, Ereignisserver und Alert Publisher werden in einer einzigen Kopie auf einem der Master-Knoten installiert.
Oozie Rollen
Oozie Server - wird in einer einzelnen Kopie auf einem der Hauptknoten abgelegt.
Rollen Garn
ResourceManager - wird in einer einzelnen Kopie auf einem der Hauptknoten abgelegt.
JobHistory Server - wird in einer einzelnen Kopie auf einem der
Masterknoten installiert .
NodeManager - Alle
Datenknoten aktivieren (Sie können den Standardwert
beibehalten ).
ZooKeeper-Rollen
ZooKeeper Server - Um die Fehlertoleranz zu gewährleisten, wird er dreifach auf Masterknoten installiert.
Cloudera Navigator-Rollen
Navigator Audit Server - wird in einer einzelnen Kopie auf einem der Masterknoten installiert.
Navigator-Metadatenserver - wird in einer einzelnen Kopie auf einem der Hauptknoten abgelegt.

Nach der Rollenverteilung gibt es eine Registerkarte mit einer kurzen Liste der Einstellungen für installierte Dienste. Ihre Änderung ist nach der Installation verfügbar und kann zu diesem Zeitpunkt unverändert bleiben:

Nach den Diensteinstellungen gibt es eine Datenbankkonfiguration für die Dienste, die sie benötigen. Wir geben den vollständigen Namen des Hosts, auf dem PostgreSQL installiert ist, in die Listenfelder "Datenbanktyp" ein, wählen das entsprechende Element aus und geben in den verbleibenden Feldern die Daten für die Verbindung mit den entsprechenden Datenbanken an. Nachdem Sie alle Daten eingegeben haben, klicken Sie auf die Schaltfläche „Verbindung testen“ und überprüfen Sie, ob die Datenbanken verfügbar sind. Wenn ja, wird auf der rechten Seite der Tabelle gegenüber jeder der Datenbanken die Aufschrift „Erfolgreich“ angezeigt:

Alles ist bereit für die Bereitstellung von Diensten. Gehen Sie zur nächsten Registerkarte und beobachten Sie diesen Vorgang. Wenn wir alles richtig gemacht haben, werden alle Schritte erfolgreich abgeschlossen. Andernfalls wird der Vorgang in einem der Schritte unterbrochen und das Fehlerprotokoll wird durch Drücken des Pfeils verfügbar:

Herzlichen Glückwunsch - CDH läuft!

Sie können mit der Installation zusätzlicher Parsels fortfahren.
Zusätzliche Parsels einstellen
In Fällen, in denen der grundlegende Satz von CHD-Diensten nicht ausreicht oder eine neuere Version erforderlich ist, können Sie zusätzliche Parsels installieren, die die verfügbare Liste der Dienste erweitern, die im Cluster bereitgestellt werden können. Während unseres Projekts benötigten wir den Dienst Spark Version 2.2, um die entwickelten Aufgaben und die Funktionsweise der Data Discovery-Tools zu starten. Es ist nicht Teil von CDH, installieren Sie es daher separat. Klicken Sie dazu auf die Schaltfläche „Hosts“ und wählen Sie das Dropdown-Listenelement „Pakete“ aus:

Eine Registerkarte mit Parsels wird geöffnet, auf der eine Liste der von diesem Cloudera Manager verwalteten Cluster und der darauf installierten Parsels angezeigt wird. Um eine Parsel mit Spark 2.2 hinzuzufügen, wählen Sie den gewünschten Cluster aus und klicken Sie auf die Schaltfläche „Konfiguration“ in der oberen rechten Ecke.

Wir klicken auf die Schaltfläche "+", in der angezeigten Zeile geben wir die Adresse des Repositorys mit dem Spark 2.2-Parsel ("Hostname / Pakete / Funken /") an und klicken auf die Schaltfläche "Änderungen speichern":

Nach diesen Manipulationen sollte eine neue mit dem Namen SPARK2 in der Liste der Parsels auf der vorherigen Registerkarte angezeigt werden. Zunächst wird es als zum Herunterladen verfügbar angezeigt. Der nächste Schritt besteht darin, es durch Klicken auf die Schaltfläche „Herunterladen“ herunterzuladen:

Das heruntergeladene Parsel muss auf den Clusterknoten verteilt sein, damit Dienste von dort installiert werden können. Klicken Sie dazu auf die Schaltfläche „Verteilen“, die rechts in der Zeile mit der SPARK2-Parsel angezeigt wird:

Der letzte Schritt bei der Arbeit mit dem Paket besteht darin, es zu aktivieren. Wir aktivieren es, indem wir auf die Schaltfläche "Aktivieren" klicken, die auf der rechten Seite der Zeile mit der Parsel angezeigt wird:

Nach der Bestätigung steht der von uns benötigte Service für die Installation zur Verfügung. Aber es gibt Nuancen. Um einige Dienste im Cluster zu installieren, müssen Sie neben der Installation der Parsel weitere Aktionen ausführen. Normalerweise wird dies auf der offiziellen Website im Abschnitt zur Installation und Aktualisierung dieses Dienstes beschrieben (hier ist ihr Beispiel für Spark 2 - www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html ). In diesem Fall müssen Sie die Spark 2-CSD-Datei (verfügbar auf der Seite Versions- und Verpackungsinformationen - www.cloudera.com/documentation/spark2/latest/topics/spark2_packaging.html ) herunterladen , mit Cloudera Manager auf dem Host installieren und diese neu starten. Lassen Sie es uns tun - laden Sie diese Datei herunter, übertragen Sie sie auf den gewünschten Host und führen Sie die Befehle aus den Anweisungen aus:
mv SPARK2_ON_YARN-2.1.0.cloudera1.jar /opt/cloudera/csd/ chown cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar chmod 644 /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar systemctl restart cloudera-scm-server
Wenn Cloudera Manager gestartet wird, ist alles bereit, Spark 2 zu installieren. Klicken Sie im Hauptbildschirm auf den Pfeil rechts neben dem Clusternamen und wählen Sie im Dropdown-Menü den Eintrag "Dienst hinzufügen":

Wählen Sie in der Liste der für die Installation verfügbaren Dienste den gewünschten aus:

Wählen Sie auf der nächsten Registerkarte die Abhängigkeiten für den neuen Dienst aus. Zum Beispiel die, bei der die Liste breiter ist:

Als Nächstes wird die Registerkarte mit der Auswahl der Rollen und Hosts angezeigt, auf denen sie installiert werden sollen, ähnlich wie bei der Installation von CDH. Es wird empfohlen, dass Sie die Verlaufsserverrolle in einer einzelnen Kopie auf einem der Hauptknoten und das Gateway auf allen Clusterservern platzieren:

Nach Auswahl der Rollen wird vorgeschlagen, die während der Installation des Dienstes am Cluster vorgenommenen Änderungen zu überprüfen und zu bestätigen. Hier können Sie standardmäßig alles belassen:

Durch die Bestätigung von Änderungen wird die Installation des Dienstes im Cluster gestartet. Wenn alles richtig gemacht wurde, wird die Installation erfolgreich abgeschlossen:
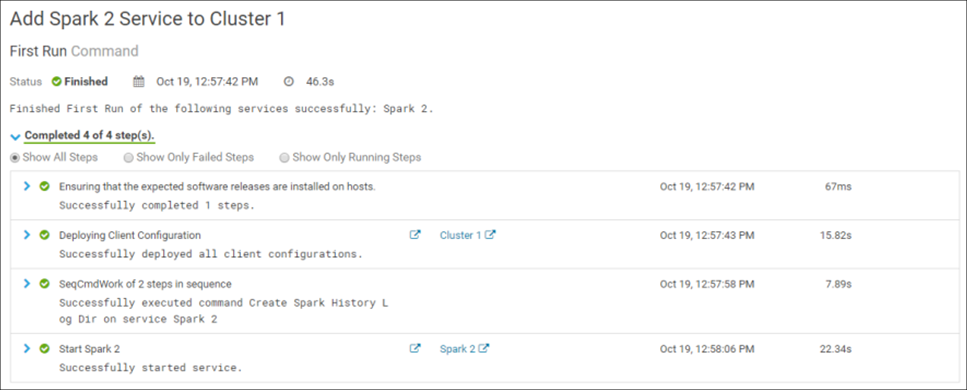
Glückwunsch! Spark 2 wurde erfolgreich im Cluster installiert:

Sie müssen den Cluster neu starten, um den Installationsvorgang abzuschließen. Danach ist alles bereit zu gehen.
Während der Installationsphase des Dienstes können Fehler auftreten. Bei der Installation in einer der Umgebungen war es beispielsweise nicht möglich, die Rolle des Spark 2-Gateways bereitzustellen. Die Lösung für dieses Problem wurde durch Kopieren des Inhalts der Datei / var / lib / alternatives / spark2-conf vom Host, auf dem diese Rolle erfolgreich installiert wurde, in eine ähnliche Datei auf dem Problemcomputer unterstützt. Um Installationsfehler zu diagnostizieren, können Sie bequem die Protokolldateien der entsprechenden Prozesse verwenden, die im Ordner / var / run / cloudera-scm-agent / process / gespeichert sind.
Das ist alles für heute. Der nächste Beitrag in der Reihe behandelt das Thema der Verwaltung von CDH-Clustern.