Vor kurzem endete der Wettbewerb iMaterialist Challenge (Furniture) in Kaggle, bei dem die Aufgabe darin bestand, Bilder in 128 Arten von Möbeln und Haushaltsgegenständen zu klassifizieren (die sogenannte feinkörnige Klassifizierung, bei der die Klassen sehr nahe beieinander liegen).
In diesem Artikel werde ich den Ansatz beschreiben, der uns mit
m0rtido den dritten Platz
eingebracht hat. Bevor
ich jedoch zum Punkt
komme , schlage ich vor, das natürliche neuronale Netzwerk in meinem Kopf zu verwenden, um dieses Problem zu lösen und die Stühle auf dem Foto unten in drei Klassen zu unterteilen.

Hast du richtig geraten? Ich auch nicht.
Aber hör auf, das Wichtigste zuerst.
Erklärung des Problems
Im Wettbewerb erhielten wir einen Datensatz, in dem 128 Klassen gewöhnlicher Alltagsgegenstände wie Stühle, Fernseher, Pfannen und Kissen in Form von Anime-Figuren präsentiert wurden.
Der Schulungsteil des Datensatzes bestand aus ~ 190.000 Bildern (es ist schwierig, die genaue Anzahl zu ermitteln, da den Teilnehmern nur eine Reihe von Download-URLs zur Verfügung gestellt wurden, von denen einige natürlich nicht funktionierten), und die Verteilung der Klassen war alles andere als einheitlich (siehe anklickbares Bild unten). .

Der Testdatensatz wurde mit 12800 Bildern dargestellt und war perfekt ausbalanciert: Es gab 100 Bilder für jede Klasse. Es wurde auch ein Validierungsdatensatz herausgegeben, der ebenfalls eine ausgewogene Verteilung der Klassen aufwies und genau halb so groß war wie der Testdatensatz.
Die Metrik zur Aufgabenbewertung war
.
Wie haben wir uns entschieden?
Zuerst haben wir die Daten heruntergeladen und einen kleinen Teil mit unseren Augen betrachtet. Anstelle vieler Bilder wurde ein 1x1-Bild oder ein Platzhalter mit einem Fehler heruntergeladen. Wir haben solche Bilder sofort mit einem Skript gelöscht.
Lernen übertragen
Es war offensichtlich, dass es angesichts der verfügbaren Anzahl von Bildern und Zeitlimits keine gute Idee ist, neuronale Netze in diesem Datensatz von Grund auf neu zu trainieren. Stattdessen haben wir den Transfer-Lernansatz verwendet, dessen Idee wie folgt lautet: Das Gewicht des Netzwerks, das für eine Aufgabe trainiert wurde, kann für einen völlig anderen Datensatz verwendet werden und eine anständige Qualität oder sogar eine Erhöhung der Genauigkeit im Vergleich zum Lernen von Grund auf erhalten.
Wie funktioniert es Versteckte Schichten in tiefen neuronalen Netzen fungieren als Merkmalsextraktoren und extrahieren Merkmale, die dann von den oberen Schichten direkt zur Klassifizierung verwendet werden.
Wir haben dies ausgenutzt, indem wir eine Reihe von tiefen CNNs abgeschlossen haben, die zuvor in ImageNet geschult wurden. Für diese Zwecke haben wir Keras und seinen Modellzoo verwendet, wobei der folgende Code ausreichte, um die fertige Architektur zu laden:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
Danach extrahierten wir die sogenannten Engpasszeichen (Merkmale am Ausgang der letzten Faltungsschicht) aus dem Netzwerk und trainierten Softmax mit
Dropout darüber.
Dann haben wir die trainierten „Top“ -Gewichte mit dem Faltungsteil des Netzwerks verbunden und das gesamte Netzwerk auf einmal trainiert.
Code anzeigen. for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
Mit einer solchen Feinabstimmung der Netzwerke konnten wir die folgenden Hacks ausprobieren:
- Datenerweiterung . Um Überanpassung zu bekämpfen, haben wir eine sehr strenge Vergrößerung verwendet: horizontale Reflexion, Zoom, Verschiebungen, Rotationen, Neigungen, Hinzufügen von Farbrauschen, Farbkanalverschiebungen, Training auf fünf Schnittlinien (Winkel und Bildmitte). Wir wollten auch FancyPCA ausprobieren, scheiterten jedoch an fehlenden Computerressourcen.
- TTA Um Klassen für Validierung und Test vorherzusagen, haben wir eine Augmentation verwendet, die etwas weniger aggressiv als während des Trainings ist, und die Ergebnisse der Vorhersagen gemittelt, um die Genauigkeit zu erhöhen.
- Fahrradlernrate . Die zyklische Zunahme und Abnahme des Trainingstempos half den Modellen, nicht in lokalen Tiefs zu stecken.
- Modelltraining für eine Untergruppe von Klassen . Wie Sie auf dem Bild über dem Schnitt sehen können, enthielt der Datensatz Klassen, die sehr nahe beieinander lagen. So nah, dass unsere Modelle bei bestimmten Objektgruppen (z. B. bei Stühlen und Sesseln, die bis zu 8 Klassen repräsentierten) viel falscher waren als bei anderen Objekttypen. Wir haben versucht, ein separates CNN zu trainieren, um nur Stühle zu erkennen, in der Hoffnung, dass ein solches Netzwerk lernen würde, verschiedene Stühle besser zu unterscheiden als ein Allzwecknetzwerk, aber dieser Ansatz führte nicht zu einer Erhöhung der Genauigkeit.
Warum? Ein Teil der Antwort auf diese Frage ist im Bild vor dem Schnitt dargestellt - die Klassen waren so ähnlich, dass Personen, die die Klassenbezeichnungen notierten, selbst mit dem anfänglichen Markup der Daten nicht zwischen ihnen unterscheiden konnten, so dass es nicht möglich wäre, diese Daten mit guter Genauigkeit herauszudrücken. - Spatial Transformer Network . Trotz der Tatsache, dass wir eines der Netzwerke damit trainiert haben und eine ziemlich gute Genauigkeit erhalten haben, wurde es leider nicht in die endgültige Einreichung aufgenommen.
- Gewichtete Verlustfunktion . Um die unausgewogene Verteilung der Klassen auszugleichen, haben wir den gewichteten Verlust verwendet. Dies half sowohl beim Training von Softmax-Tops als auch beim weiteren Training des gesamten Netzwerks. Die Gewichte wurden mit der Funktion von scikit-learn berechnet und dann an die Anpassungsmethode des Modells übergeben:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
Auf diese Weise trainierte Netzwerke machten 90% unseres endgültigen Ensembles aus.
Stapeln von Engpass-Tags
Haftungsausschluss: Wiederholen Sie niemals die später im wirklichen Leben beschriebene Technik.
Wie wir im vorherigen Abschnitt festgestellt haben, können Engpassfunktionen aus in ImageNet geschulten Netzwerken zur Klassifizierung für andere Aufgaben verwendet werden.
m0rtido beschloss, weiter zu gehen und schlug die folgende Strategie vor:
- Wir verwenden alle vorgefertigten Architekturen, die uns zur Verfügung stehen (insbesondere NasNet Large, InceptionV4, Vgg19, Vgg16, InceptionV3, InceptionResnetV2, Resnet-50, Resnet-101, Resnet-152, Xception, Densenet-169, Densenet-121, Densenet-201) ) und extrahieren Sie Engpasszeichen aus ihnen. Wir werden auch die Zeichen für die reflektierten Versionen der Bilder zählen (eine solche minimalistische Vergrößerung).
- Reduzieren Sie die Dimension der Funktionen jedes Modells mithilfe von SAR dreimal, damit sie normal in den uns zur Verfügung stehenden 16-GB-RAM passen.
- Verketten Sie diese Features zu einem großen Feature-Vektor.
- Darüber hinaus werden wir ein mehrschichtiges Perzeptron unterrichten und Vorhersagen generieren. Wir werden auch mit dem Aufbrechen in Falten trainieren und alle diese Vorhersagen mitteln.
Die daraus resultierende monströse Stapelung führte zu einer enormen Steigerung der Genauigkeit des gesamten Ensembles.
Ensemble von Modellen
Nach all dem hatten wir ungefähr zwei Dutzend verdeckte Faltungsnetzwerke sowie zwei Perzeptrone auf Engpasszeichen. Die Frage war: Wie kann man aus all dem eine einzige Vorhersage machen?
In der besten Kaggle-Tradition mussten wir darüber hinaus
stapeln , aber um das OOF-Stapeln durchzuführen, hatten wir weder Zeit noch eine GPU, und das Training eines Top-Level-Modells auf einem Validierungs-Holdout führte zu einer sehr großen Überanpassung. Aus diesem Grund haben wir uns entschlossen, einen ziemlich einfachen Algorithmus für die Erstellung gieriger Ensembles zu implementieren:
- Initialisieren Sie ein leeres Ensemble.
- Wir versuchen, jedes Modell der Reihe nach hinzuzufügen und die Punktzahl zu berücksichtigen. Wir wählen das Modell aus, das die Metrik am meisten erhöht, und fügen es dem Ensemble hinzu. Die Ergebnisse der Vorhersage von Modellen im Ensemble werden einfach gemittelt.
- Wenn keines der Modelle die Leistung verbessert, gehen wir das Ensemble durch und versuchen, Modelle daraus zu entfernen. Wenn sich herausstellt, dass ein Modell entfernt wird, damit sich die Punktzahl verbessert, tun wir dies und kehren zu Schritt 2 zurück.
Als Metrik wurde ausgewählt
. Diese Formel wurde empirisch so gewählt, dass
und
Es stellte sich heraus, dass es ungefähr gleich groß war. Eine solche integrale Metrik korrelierte gut mit
sowohl bei der Validierung als auch in einer öffentlichen Rangliste.
Darüber hinaus spielte die Tatsache, dass wir bei jeder Iteration ein Modell hinzufügten oder entfernten (d. H. Die Modellgewichte blieben immer ganze Zahlen), die Rolle einer Art Regularisierung, die es dem Ensemble nicht ermöglichte, sich unter den Validierungsdatensatz anzupassen.
Infolgedessen umfasste das Ensemble die folgenden Modelle:
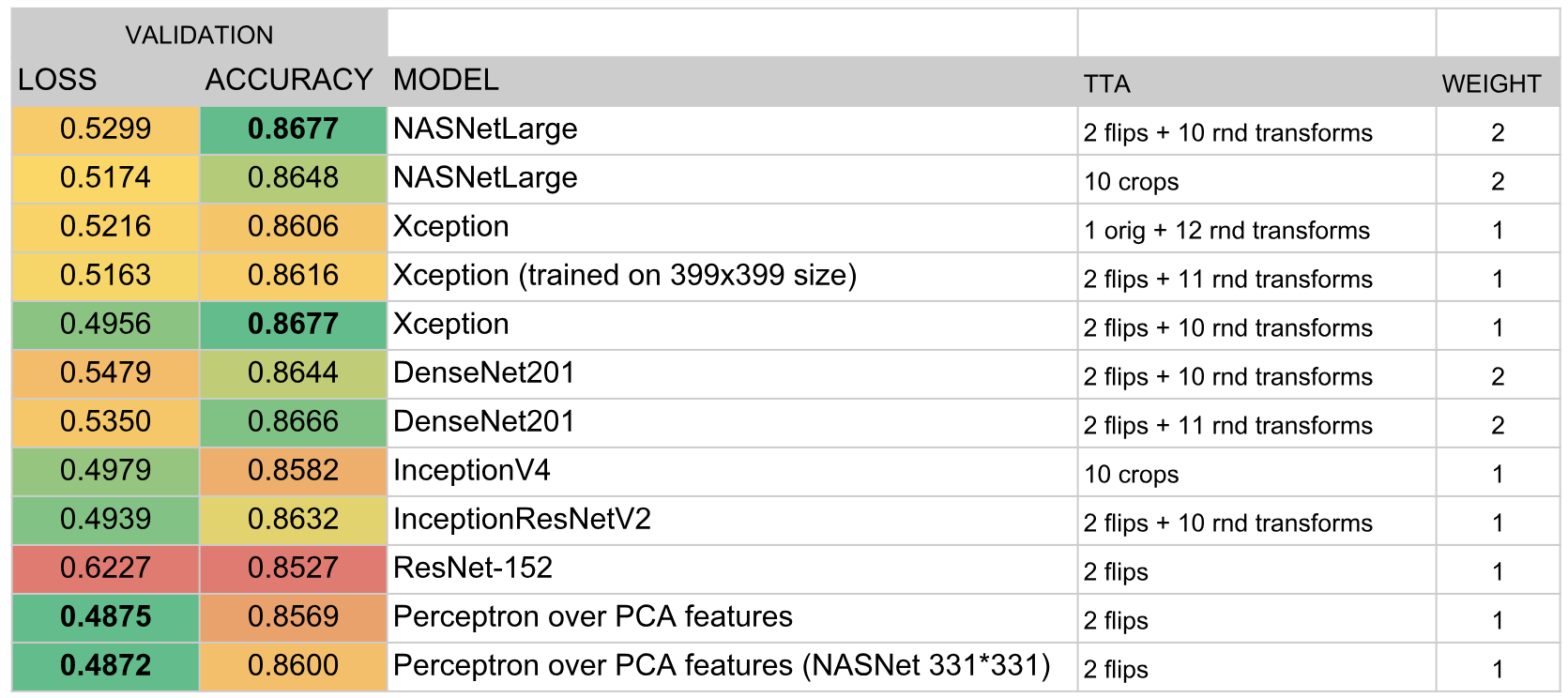
Ergebnisse
Nach den Ergebnissen des Wettbewerbs haben wir den dritten Platz belegt. Der Schlüssel zum Erfolg schien mir die erfolgreiche Wahl des Ensemble-Algorithmus und die enorme Zeit, die
m0rtido und ich in die Ausbildung einer großen Anzahl von Modellen investiert haben.
