Hallo! Mein Name ist Sergey, ich arbeite als Chefingenieur in Sbertekh. Ich bin seit ungefähr 10 Jahren im IT-Bereich tätig, von denen 6 mit Datenbanken, ETL-Prozessen, DWH und allem, was mit Daten zu tun hat, befasst sind. In diesem Artikel werde ich über Vertica sprechen - ein analytisches und wirklich säulenförmiges DBMS, das Daten effizient komprimiert, speichert, schnell liefert und sich hervorragend als Big-Data-Lösung eignet.

allgemeine Informationen
Big Data begann sich in den 2000er Jahren zu entwickeln, und es wurden Motoren benötigt, die alles verdauen konnten. Als Reaktion darauf erschien eine Reihe von säulenförmigen DBMS, die für diesen Zweck vorgesehen waren - einschließlich Vertica.
Vertica speichert seine Daten nicht nur in Spalten, sondern auch rational und mit einem hohen Grad an Komprimierung. Außerdem plant es Abfragen effizient und gibt Daten schnell aus. Die Informationen, die in einem klassischen DBMS in Kleinbuchstaben etwa 1 TB Speicherplatz beanspruchen, benötigen auf Vertica etwa 200 bis 300 GB, wodurch wir gute Einsparungen bei den Festplatten erzielen.
Vertica wurde ursprünglich als Spalten-DBMS konzipiert. Andere Basen versuchen im Grunde nur, verschiedene Spaltenmechanismen zu imitieren, aber sie sind nicht immer erfolgreich, da die Engine immer noch für die Verarbeitung von Zeichenfolgen ausgelegt ist. Nachahmer transponieren die Tabelle in der Regel einfach und verarbeiten sie dann mit dem üblichen Linienmechanismus.
Vertica ist fehlertolerant, es hat keinen Steuerknoten - alle Knoten sind gleich. Wenn es Probleme mit einem der Server im Cluster gibt, erhalten wir die Daten weiterhin. Sehr oft ist der rechtzeitige Empfang von Daten für Geschäftskunden von entscheidender Bedeutung, insbesondere zu einem Zeitpunkt, an dem die Berichterstellung geschlossen ist und Sie den Finanzbehörden Informationen zur Verfügung stellen müssen.
Anwendungsbereiche
Vertica ist in erster Linie ein analytisches Data Warehouse. Sie sollten nicht in kleinen Transaktionen darauf schreiben, Sie sollten es nicht auf irgendeine Site schrauben usw. Vertica sollte als eine Art Batch-Schicht betrachtet werden, bei der es sich lohnt, Daten in große Packungen einzutauchen. Bei Bedarf ist Vertica bereit, diese Daten sehr schnell bereitzustellen - Abfragen für Millionen von Zeilen sind in Sekunden erledigt.
Wo kann das nützlich sein? Nehmen Sie zum Beispiel ein Telekommunikationsunternehmen. Vertica kann darin für Geoanalytik, Netzwerkentwicklung, Qualitätsmanagement, gezieltes Marketing, das Studieren von Informationen aus Contact Centern, das Verwalten von Kundenabflüssen und Anti-Betrugs- / Anti-Spam-Lösungen verwendet werden.

In anderen Geschäftsbereichen ist alles ungefähr gleich - zeitnahe und zuverlässige Analysen sind wichtig für den Gewinn. Im Handel zum Beispiel versucht jeder, Kunden irgendwie zu personalisieren, Rabattkarten dafür zu verteilen, Daten darüber zu sammeln, wo, was und wann eine Person gekauft hat usw. Durch die Analyse der Informationsfelder aus all diesen Kanälen können wir sie vergleichen, Modelle erstellen und Entscheidungen treffen, die zu Gewinnwachstum führen.
Eintrittsschwelle
Heutzutage benötigt jeder Arbeitgeber einen Analysten, um zu verstehen, was SQL ist. Wenn Sie ANSI SQL kennen, können Sie als sicherer Vertica-Benutzer bezeichnet werden. Wenn Sie Modelle in Python und R erstellen können, sind Sie nur ein „Masseur“ von Daten. Wenn Sie Linux beherrschen und Grundkenntnisse in der Vertica-Administration haben, können Sie als Administrator arbeiten. Im Allgemeinen ist die Eintrittsschwelle in Vertica niedrig, aber natürlich können alle Nuancen nur durch Füllen einer Hand während des Betriebs herausgefunden werden.
Hardwarearchitektur
Betrachten Sie Vertica auf Cluster-Ebene. Dieses DBMS bietet eine massiv parallele Datenverarbeitung (MPP) in einer verteilten Computerarchitektur - "Shared-Nothing" -, in der im Prinzip jeder Knoten bereit ist, die Funktionen eines anderen Knotens zu übernehmen. Haupteigenschaften:
- Es gibt keinen einzigen Fehlerpunkt
- Jeder Knoten ist unabhängig und unabhängig.
- Es gibt keinen einzigen Verbindungspunkt für das gesamte System.
- Infrastrukturknoten werden dupliziert,
- Daten auf Clusterknoten werden automatisch kopiert.
Der Cluster skaliert problemlos linear. Wir stellen die Server einfach in ein Regal und verbinden sie über eine grafische Oberfläche. Neben seriellen Servern ist die Bereitstellung auf virtuellen Maschinen möglich. Was kann mit der Erweiterung erreicht werden?
- Die Lautstärke für neue Daten erhöht sich
- Erhöhen Sie die maximale Arbeitsbelastung
- Verbesserung der Ausfallsicherheit. Je mehr Knoten im Cluster vorhanden sind, desto geringer ist die Wahrscheinlichkeit, dass der Cluster aufgrund eines Ausfalls ausfällt, und desto näher ist es uns, die Verfügbarkeit rund um die Uhr sicherzustellen.
Es gibt jedoch einige Dinge zu beachten. In regelmäßigen Abständen müssen Knoten zur Wartung aus dem Cluster entfernt werden. Ein weiterer in großen Unternehmen häufig vorkommender Fall ist, dass die Server die Garantie verlieren und von einer produktiven zu einer Testumgebung wechseln. An ihre Stelle treten neue, die unter die Herstellergarantie fallen. Basierend auf den Ergebnissen all dieser Operationen ist eine Neuausrichtung erforderlich. Dies ist ein Prozess, bei dem Daten zwischen Knoten neu verteilt werden - dementsprechend wird die Arbeitslast neu verteilt. Dies ist ein ressourcenintensiver Prozess, der in Clustern mit einer großen Datenmenge die Leistung erheblich beeinträchtigen kann. Um dies zu vermeiden, müssen Sie das Servicefenster auswählen - die Zeit, zu der die Last minimal ist. In diesem Fall werden Benutzer es nicht bemerken.
Projektionen
Um zu verstehen, wie Daten in Vertica gespeichert werden, müssen Sie sich mit einem der Grundkonzepte befassen - der Projektion.
Logische Einheiten der Informationsspeicherung sind Diagramme, Tabellen und Ansichten. Physikalische Einheiten sind Projektionen. Es gibt verschiedene Arten von Projektionen:
- Superprojektion
- Abfragespezifische Projektionen
- Aggregierte Projektionen
Beim Erstellen einer Tabelle wird automatisch eine
Superprojektion erstellt, die alle Spalten unserer Tabelle enthält. Wenn Sie einen der regulären Prozesse beschleunigen müssen, können wir eine spezielle
abfrageorientierte Projektion erstellen, die beispielsweise 3 von 10 Spalten enthält.
Der dritte Typ ist auch für beschleunigungsaggregierte
Projektionen vorgesehen . Ich werde nicht in ihre Unterklassen gehen - das ist nicht sehr interessant. Ich möchte Sie sofort warnen, dass es sich nicht lohnt, Ihre Probleme mit der Ausführung von Abfragen ständig durch Erstellen neuer Projektionen zu lösen. Schließlich wird der Cluster langsamer.
Beim Erstellen von Projektionen müssen wir bewerten, ob unsere Abfragen genügend Superprojektionen haben. Wenn wir noch experimentieren wollen, fügen wir streng eine neue Projektion hinzu. Wenn Probleme auftreten, ist es einfacher, die Grundursache zu finden. Erstellen Sie für große Tabellen eine segmentierte Projektion. Es ist in Segmente unterteilt, die auf mehrere Knoten verteilt sind, wodurch die Fehlertoleranz erhöht und die Belastung eines Knotens minimiert wird. Wenn die Tablets klein sind, ist es besser, nicht segmentierte Projektionen durchzuführen. Sie werden vollständig auf jeden Knoten kopiert und somit die Leistung erhöht. Ich werde eine Reservierung vornehmen: In Bezug auf Vertica besteht eine "kleine" Tabelle aus etwa 1 Million Zeilen.
Fehlertoleranz
Die Fehlertoleranz in Vertica wird mithilfe des K-Safety-Mechanismus implementiert. Es ist recht einfach in Bezug auf die Beschreibung, aber komplex in Bezug auf die Arbeit auf Motorebene. Es kann mit dem Parameter K-Safety gesteuert werden - es kann einen Wert von 0, 1 oder 2 haben. Dieser Parameter legt die Anzahl der Kopien segmentierter Projektionsdaten fest.
Kopien von Projektionen werden als Buddy-Projektionen bezeichnet. Ich habe versucht, diesen Satz durch den Yandex-Übersetzer zu übersetzen, und es stellte sich heraus, dass es sich um eine „Sidekick-Projektion“ handelt. Google bot Optionen und interessanter. Typischerweise werden diese Projektionen entsprechend ihrem funktionalen Zweck als Partner oder Nachbar bezeichnet. Dies sind Projektionen, die einfach auf benachbarten Knoten gespeichert und somit reserviert werden. Nicht segmentierte Projektionen haben keine Buddy-Projektionen - sie werden vollständig kopiert.
Wie funktioniert es Stellen Sie sich einen Cluster von fünf Maschinen vor. Sei K-Sicherheit gleich 1.

Die Knoten sind nummeriert und darunter befinden sich schriftliche Partnerprojektionen, die auf ihnen gespeichert sind. Angenommen, wir haben einen Knoten getrennt. Was wird?

Knoten 1 enthält eine benutzerfreundliche Projektion von Knoten 2. Daher wächst die Last auf Knoten 1, aber der Cluster hört nicht auf zu arbeiten. Und jetzt diese Situation:
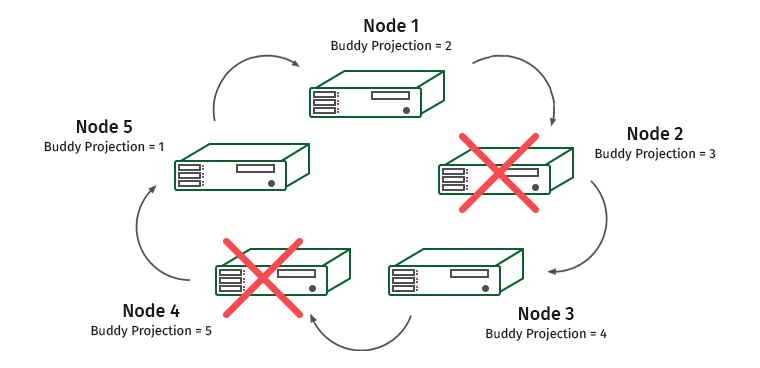
Knoten 3 enthält die Projektion von Knoten 4, und die Knoten 1 und 3 werden überlastet.
Wir erschweren die Aufgabe. K-Sicherheit = 2, deaktiviere zwei benachbarte Knoten.
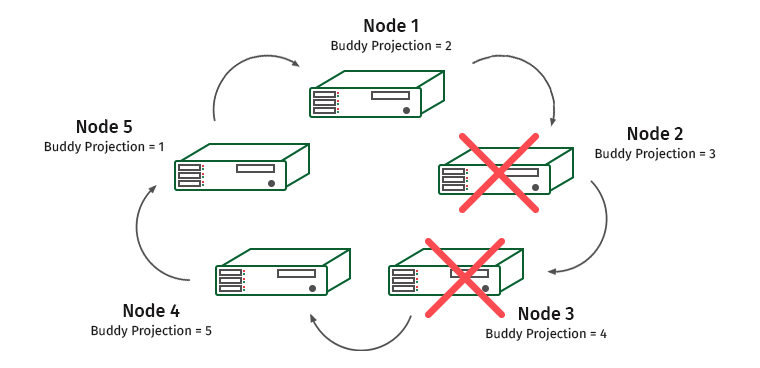
Hier werden die Knoten 1 und 4 überlastet (Knoten 2 enthält die Projektion von Knoten 1 und Knoten 3 enthält die Projektion von Knoten 4).
In solchen Situationen erkennt die System-Engine, dass einer der Knoten nicht reagiert, und die Last wird auf den benachbarten Knoten übertragen. Es wird verwendet, bis der Knoten wieder hergestellt ist. Sobald dies geschieht, werden die Last und die Daten zurückverteilt. Sobald wir mehr als die Hälfte des Clusters oder der Knoten verlieren, die alle Kopien einiger Daten enthalten, steht der Cluster auf.
Logische Datenspeicherung
Vertica verfügt über für das Schreiben optimierte Speicherbereiche, für das Lesen optimierte Bereiche und einen Tuple Mover-Mechanismus, mit dem Daten vom ersten zum zweiten fließen können.
Bei Verwendung der Operationen COPY, INSERT, UPDATE landen wir automatisch in WOS (Write Optimized Store), einem Bereich, in dem Daten nicht zum Lesen optimiert und nur auf Anforderung sortiert, ohne Komprimierung oder Indizierung gespeichert werden. Wenn die Datenmengen für den WOS-Bereich zu groß sind, sollten sie mithilfe der zusätzlichen DIRECT-Anweisung sofort in ROS geschrieben werden. Andernfalls ist das WOS voll und wir stürzen ab.
Nach Ablauf der in den Einstellungen angegebenen Zeit fließen Daten von WOS in ROS (Read Optimized Store) - eine optimierte, leseorientierte Struktur des Festplattenspeichers. ROS speichert den Großteil der Daten, hier werden sie sortiert und komprimiert. ROS-Daten sind in Lagerbehälter unterteilt. Ein Container besteht aus einer Reihe von Zeilen, die von Übersetzungsoperatoren (COPY DIRECT) erstellt und in einer bestimmten Gruppe von Dateien gespeichert werden.
Unabhängig davon, wo die Daten geschrieben sind - in WOS oder in ROS - sind sie sofort verfügbar. Das Lesen aus WOS ist jedoch langsamer, da die Daten dort nicht gruppiert sind.

Tuple Mover ist ein Reinigungswerkzeug, das zwei Vorgänge ausführt:
- Verschieben - Komprimiert und sortiert Daten in WOS, verschiebt sie in ROS und erstellt neue Container für sie in ROS.
- Mergeout - hinter uns her, wenn wir DIRECT verwenden. Wir sind nicht immer in der Lage, so viele Informationen zu laden, um große ROS-Container zu erhalten. Daher werden kleine ROS-Container regelmäßig zu größeren kombiniert, Daten, die zum Löschen markiert sind, bereinigt, während im Hintergrund gearbeitet wird (entsprechend der in der Konfiguration angegebenen Zeit).
Was sind die Vorteile der Spaltenspeicherung?
Wenn wir Zeilen lesen, dann zum Beispiel, um einen Befehl auszuführen
SELECT 1,11,15 from table1
Wir müssen die ganze Tabelle lesen. Dies ist eine riesige Menge an Informationen. In diesem Fall ist der Spaltenansatz rentabler. Sie können nur die drei Spalten zählen, die wir benötigen, wodurch Speicher und Zeit gespart werden.

Ressourcenzuweisung
Um Probleme zu vermeiden, muss der Benutzer etwas eingeschränkt werden. Es besteht immer die Möglichkeit, dass der Benutzer eine umfangreiche Anfrage schreibt, die alle Ressourcen verschlingt. Standardmäßig nimmt Vertica einen erheblichen Teil des Bereichs Allgemein ein. Außerdem werden separate Bereiche für Tuple Mover-, WOS- und Systemprozesse (Wiederherstellung usw.) hervorgehoben.
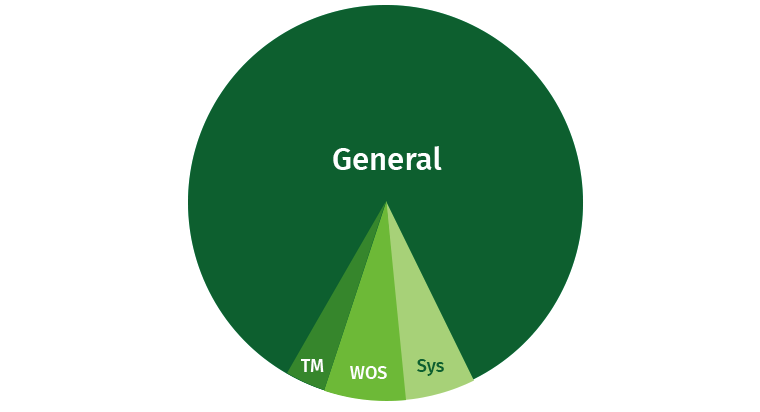
Versuchen wir, diese Ressourcen gemeinsam zu nutzen. Wir erstellen Bereiche für Autoren, für Leser und für langsame Abfragen mit niedriger Priorität.

Wenn wir uns die Systemtabellen ansehen, in denen unsere Ressourcen gespeichert sind - Ressourcenpools -, werden wir viele Parameter sehen, mit denen Sie alles feiner einstellen können. Zu Beginn sollten Sie sich nicht damit befassen. Es ist besser, sich einfach darauf zu beschränken, den Speicher für bestimmte Aufgaben abzuschneiden. Wenn Sie Erfahrung sammeln und zu 100% sicher sind, dass Sie alles richtig machen, können Sie experimentieren.
Zu den Thin-Einstellungen gehören die Ausführungspriorität, Wettbewerbssitzungen und die Menge des zugewiesenen Speichers. Und selbst mit Prozessoren können wir Abhilfe schaffen. Um mit diesen Einstellungen arbeiten zu können, müssen Sie volles Vertrauen in die Richtigkeit Ihrer Aktionen haben. Daher ist es besser, die Unterstützung des Unternehmens in Anspruch zu nehmen und das Recht zu haben, Fehler zu machen.
Unten finden Sie ein Beispiel für eine Anforderung, anhand derer Sie die Einstellungen des allgemeinen Pools anzeigen können:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |ANSI SQL und andere Funktionen
- Mit Vertica können Sie in SQL-99 schreiben - alle Funktionen werden unterstützt.
- Verica verfügt über hervorragende Analysefunktionen - sogar Tools für maschinelles Lernen sind enthalten
- Vertica kann Texte indizieren
- Vertica verarbeitet halbstrukturierte Daten
Integration
Vertica ist wie alle aktuellen Tools stark in andere Systeme integriert. Kann gut mit HDFS (Hadoop) arbeiten. In früheren Versionen konnte Vertica nur Daten von HDFS bestimmter Formate herunterladen, aber jetzt kann es alles, funktioniert mit allen Formaten, zum Beispiel ORC und Parkett. Es kann sogar Dateien als externe Tabellen anhängen und seine Daten in ROS-Containern direkt auf HDFS speichern. In der achten Version von Vertica wurde eine signifikante Optimierung der Arbeitsgeschwindigkeit mit HDFS, ein Metadatenkatalog und das Parsen dieser Formate durchgeführt. Sie können einen Vertica-Cluster direkt auf einem Hadoop-Cluster erstellen.
Ab Version 7.2 kann Vertica mit Apache Kafka arbeiten - wenn jemand einen Nachrichtenbroker benötigt.
Vertica 8 bietet volle Unterstützung für Spark. Es ist möglich, Daten von Spark nach Vertica und umgekehrt zu kopieren.
Fazit
Vertica ist eine gute Option für die Arbeit mit Big Data, für die nicht viel Eingabewissen erforderlich ist. Dieses DBMS verfügt über umfassende Analysefunktionen. Von den Minuspunkten - diese Lösung ist nicht Open Source, aber Sie können versuchen, sie kostenlos mit einem Limit von 1 TB und drei Knoten bereitzustellen - reicht dies aus, um zu verstehen, ob Sie Vertica benötigen oder nicht.