Alle modernen Moderationssysteme verwenden entweder
Crowdsourcing oder maschinelles Lernen, das bereits zu einem Klassiker geworden ist. Beim nächsten ML-Training in Yandex sprachen Konstantin Kotik, Igor Galitsky und Alexey Noskov über ihre Teilnahme am Wettbewerb zur Massenidentifizierung beleidigender Kommentare. Der Wettbewerb fand auf der Kaggle-Plattform statt.
- Hallo allerseits! Mein Name ist Konstantin Kotik, ich bin Datenwissenschaftler bei der Firma Button of Life, Student der Physikabteilung und der Graduate School of Business der Moskauer Staatlichen Universität.
Heute erzählen Ihnen unsere Kollegen Igor Galitsky und Alexei Noskov über den Wettbewerb „Toxic Comment Classification Challenge“, bei dem unser DecisionGuys-Team unter 4551 Teams den 10. Platz belegte.
Eine Online-Diskussion von Themen, die uns wichtig sind, kann schwierig sein. Die Beleidigungen, Aggressionen und Belästigungen, die online auftreten, zwingen viele Menschen häufig dazu, die Suche nach verschiedenen geeigneten Meinungen zu für sie interessanten Themen aufzugeben und sich nicht zu äußern.
Viele Plattformen haben Schwierigkeiten, effektiv online zu kommunizieren. Dies führt jedoch häufig dazu, dass viele Communities einfach Benutzerkommentare schließen.
Ein Forschungsteam von Google und einem anderen Unternehmen arbeitet an Tools zur Verbesserung der Online-Diskussion.
Einer der Tricks, auf die sie sich konzentrieren, ist die Untersuchung negativer Online-Verhaltensweisen wie toxischer Kommentare. Dies sind Kommentare, die beleidigend oder respektlos sein oder den Benutzer einfach zwingen können, die Diskussion zu verlassen.

Bisher hat diese Gruppe eine öffentliche API entwickelt, mit der der Grad der Toxizität eines Kommentars bestimmt werden kann. Die aktuellen Modelle machen jedoch immer noch Fehler. Und in diesem Wettbewerb wurden wir, die Kegglers, aufgefordert, ein Modell zu entwickeln, das Kommentare identifizieren konnte, die Bedrohungen, Hass, Beleidigungen und dergleichen enthielten. Und im Idealfall musste dieses Modell besser sein als das aktuelle Modell für ihre API.
Wir haben die Aufgabe der Textverarbeitung: Kommentare zu identifizieren und dann zu klassifizieren. Als Trainings- und Testbeispiele wurden Kommentare von den Wikipedia-Diskussionsseiten bereitgestellt. Es gab ungefähr 160.000 Kommentare im Zug, 154.000 im Test.

Das Trainingsmuster wurde wie folgt markiert. Jeder Kommentar hat sechs Bezeichnungen. Etiketten nehmen den Wert 1 an, wenn der Kommentar diese Art von Toxizität enthält, andernfalls 0. Und es kann sein, dass alle Labels Null sind, ein angemessener Kommentarfall. Oder es kann sein, dass ein Kommentar mehrere Arten von Toxizität enthält, sofort eine Bedrohung und Obszönität.
Aufgrund der Tatsache, dass wir auf Sendung sind, kann ich keine konkreten Beispiele für diese Klassen demonstrieren. In Bezug auf die Testprobe war es für jeden Kommentar erforderlich, die Wahrscheinlichkeit jeder Art von Toxizität vorherzusagen.
Die Qualitätsmetrik ist die über die Toxizitätstypen gemittelte ROC-AUC, d. H. Das arithmetische Mittel der ROC-AUC für jede Klasse separat.
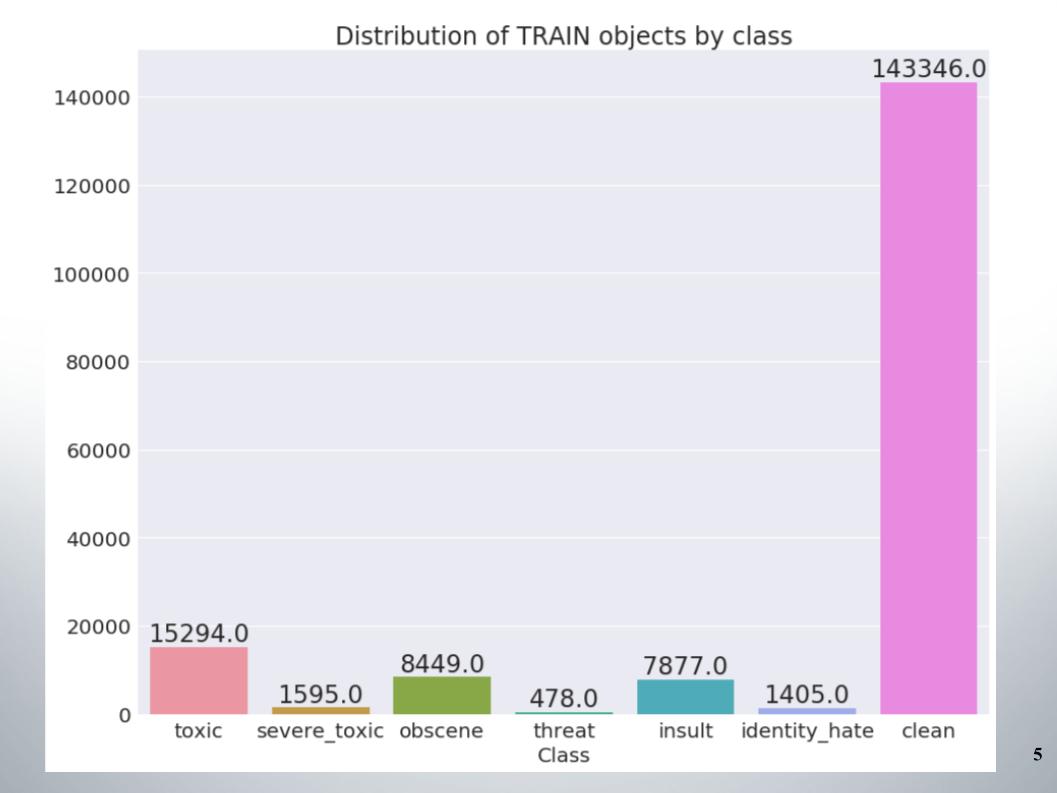
Hier ist die Verteilung der Objekte nach Klassen im Trainingssatz. Es ist ersichtlich, dass die Daten sehr unausgewogen sind. Ich muss sofort sagen, dass unser Team anhand einer Stichprobe von Methoden für die Arbeit mit unausgeglichenen Daten, z. B. Über- oder Unterabtastung, Punkte erzielt hat.

Beim Erstellen des Modells habe ich eine zweistufige Datenvorverarbeitung verwendet. Die erste Stufe ist die grundlegende Vorverarbeitung der Daten. Dies sind die Transformationen der Ansicht auf der Folie. Dadurch wird der Text in Kleinbuchstaben geschrieben und Links, IP-Adressen, Zahlen und Satzzeichen gelöscht.

Für alle Modelle wurde diese grundlegende Datenvorverarbeitung verwendet. In der zweiten Phase wurde eine teilweise Vorverarbeitung der Daten durchgeführt - Ersetzen von Emoticons durch die entsprechenden Wörter, Entschlüsseln von Abkürzungen, Korrigieren von Tippfehlern in der Obszönität, Bringen der verschiedenen Arten von Matten in dieselbe Form und Löschen von Bildern. In einigen Kommentaren wurden Links zu Bildern angegeben, wir haben sie einfach entfernt.
Für jedes der Modelle wurde eine teilweise Vorverarbeitung der Daten und ihrer verschiedenen Elemente verwendet. All dies wurde getan, damit die Basismodelle die Kreuzkorrelation zwischen den Basismodellen beim Aufbau einer weiteren Zusammensetzung verringern.
Kommen wir zum interessantesten Teil - dem Erstellen eines Modells.
Ich habe sofort den klassischen Ansatz der Wortsack aufgegeben. Aufgrund der Tatsache, dass bei diesem Ansatz jedes Wort ein separates Attribut ist. Dieser Ansatz berücksichtigt nicht die allgemeine Wortreihenfolge, es wird angenommen, dass die Wörter unabhängig sind. Bei diesem Ansatz erfolgt die Erzeugung des Textes so, dass eine gewisse Verteilung in Wörtern vorliegt. Ein Wort wird zufällig aus dieser Verteilung ausgewählt und in den Text eingefügt.
Natürlich gibt es komplexere generative Prozesse, aber das Wesentliche ändert sich nicht - dieser Ansatz berücksichtigt nicht die allgemeine Wortreihenfolge. Sie können zu Engrammen gehen, aber dort wird nur die Fensterreihenfolge der Wörter berücksichtigt und nicht allgemein. Daher verstand ich auch meine Teamkollegen, dass sie etwas Klügeres verwenden mussten.
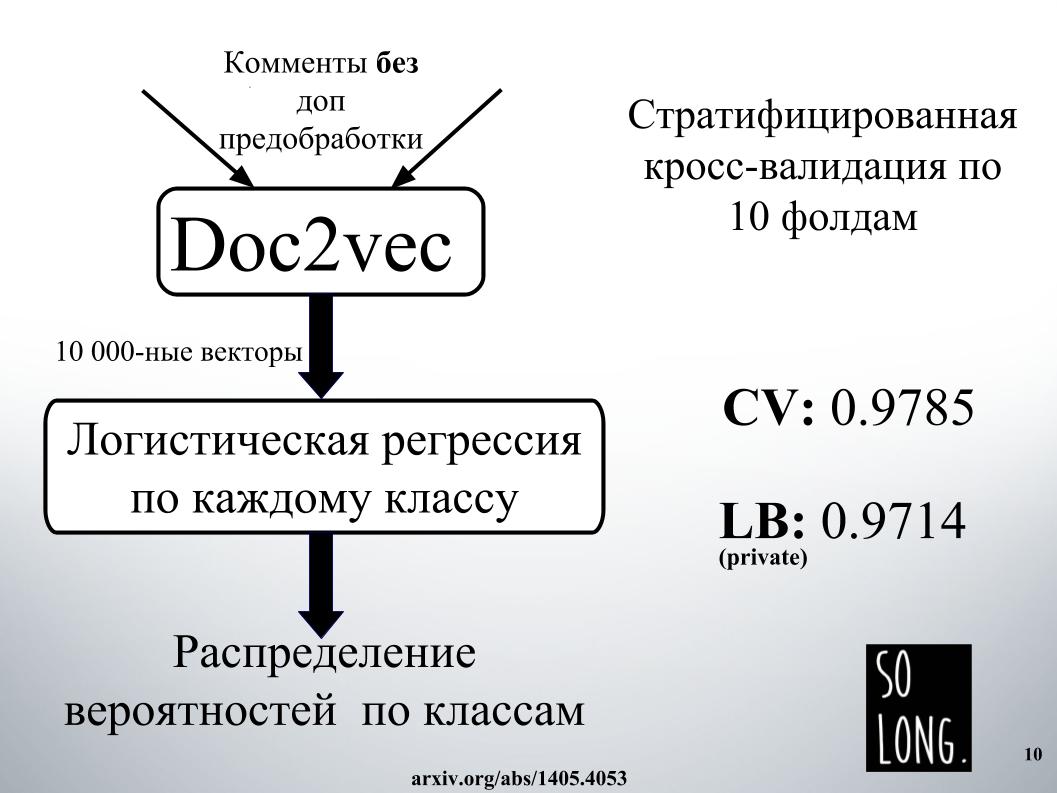
Das erste, was mir in den Sinn kam, war die Verwendung einer Vektordarstellung mit Doc2vec. Dies ist Word2vec plus ein Vektor, der die Eindeutigkeit eines bestimmten Dokuments berücksichtigt. Im Originalartikel wird dieser Vektor als ID-Absatz bezeichnet.
Dann wurde gemäß einer solchen Vektordarstellung die logistische Regression untersucht, wobei jedes Dokument durch einen 10.000-dimensionalen Vektor dargestellt wurde. Die Qualitätsbewertung wurde an einer Kreuzvalidierung von zehn Falten durchgeführt, sie wurde geschichtet, und es ist wichtig zu beachten, dass die logistische Regression für jede Klasse untersucht wurde und sechs Klassifizierungsprobleme separat gelöst wurden. Am Ende war das Ergebnis eine Wahrscheinlichkeitsverteilung nach Klassen.
Die logistische Regression wurde sehr lange trainiert. Ich passte im Allgemeinen nicht in den RAM. In Igor's Einrichtungen verbrachten sie einen Tag irgendwo, um das Ergebnis zu erhalten, wie auf einer Rutsche. Aus diesem Grund haben wir uns aufgrund hoher Erwartungen sofort geweigert, Doc2vec zu verwenden, obwohl es um 1000 verbessert werden könnte, wenn ein Kommentar mit zusätzlicher Datenvorverarbeitung durchgeführt würde.

Die intelligenteren, die wir und die anderen Wettbewerber verwendeten, waren wiederkehrende neuronale Netze. Sie erhalten nacheinander Wörter am Eingang und aktualisieren ihren verborgenen Zustand nach jedem Wort. Igor und ich haben das wiederkehrende GRU-Netzwerk für die Worteinbettung von fastText verwendet. Dies ist insofern besonders, als es viele unabhängige Probleme bei der binären Klassifizierung löst. Prognostizieren Sie das Vorhandensein oder Fehlen des Kontextworts unabhängig voneinander.
Wir haben auch eine Qualitätsbewertung zur Kreuzvalidierung von zehn Falten durchgeführt, die hier nicht geschichtet wurde, und hier wurde die Wahrscheinlichkeitsverteilung sofort nach Klassen ermittelt. Jedes Problem der binären Klassifikation wurde nicht separat gelöst, sondern es wurde sofort ein sechsdimensionaler Vektor erzeugt. Es war eines der besten Einzelmodelle.
Sie fragen, was war das Erfolgsgeheimnis?
Es bestand aus Mischen, es gab viel davon, mit Stapeln und Vernetzen im Ansatz. Der Netzwerkansatz muss als gerichteter Graph dargestellt werden.
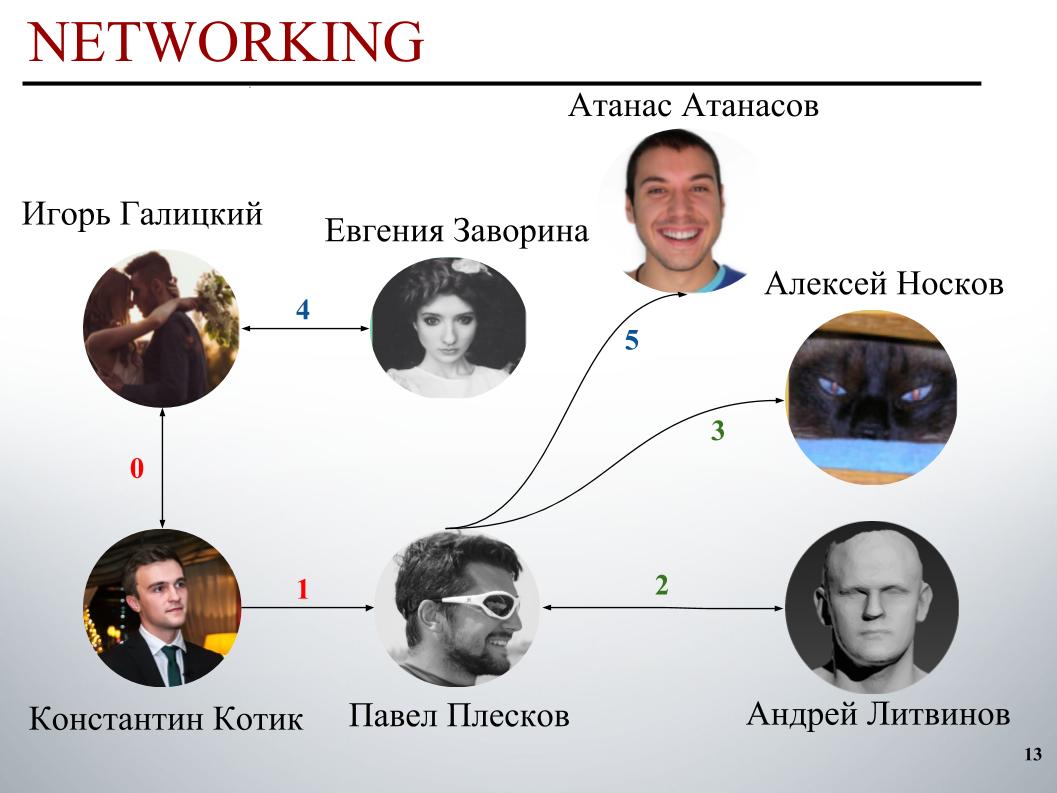
Zu Beginn des Wettbewerbs bestand das DecisionGuys-Team aus zwei Personen. Dann drückte Pavel Pleskov im ODS Slack-Kanal den Wunsch aus, sich mit jemandem aus den Top 200 zusammenzutun. Zu dieser Zeit waren wir irgendwo auf dem 157. Platz und Pavel Pleskov auf dem 154. Platz, irgendwo in der Nachbarschaft. Igor bemerkte seinen Wunsch mitzumachen und ich lud ihn ins Team ein. Dann schloss sich Andrey Litvinov uns an, dann lud Pavel Großmeister Alexei Noskov in unser Team ein. Igor - Eugene. Und der letzte Partner unseres Teams war der Bulgare Atanas Atanasov, und dies war das Ergebnis eines menschlichen internationalen Ensembles.
Jetzt wird Igor Galitsky erzählen, wie er gru unterrichtet hat, und ausführlicher über die Ideen und Ansätze von Pavel Pleskov, Andrei Litvinov und Atanas Atanasov sprechen.
Igor Galitsky:
- Ich bin Datenwissenschaftler bei Epoch8 und werde über die meisten von uns verwendeten Architekturen sprechen.
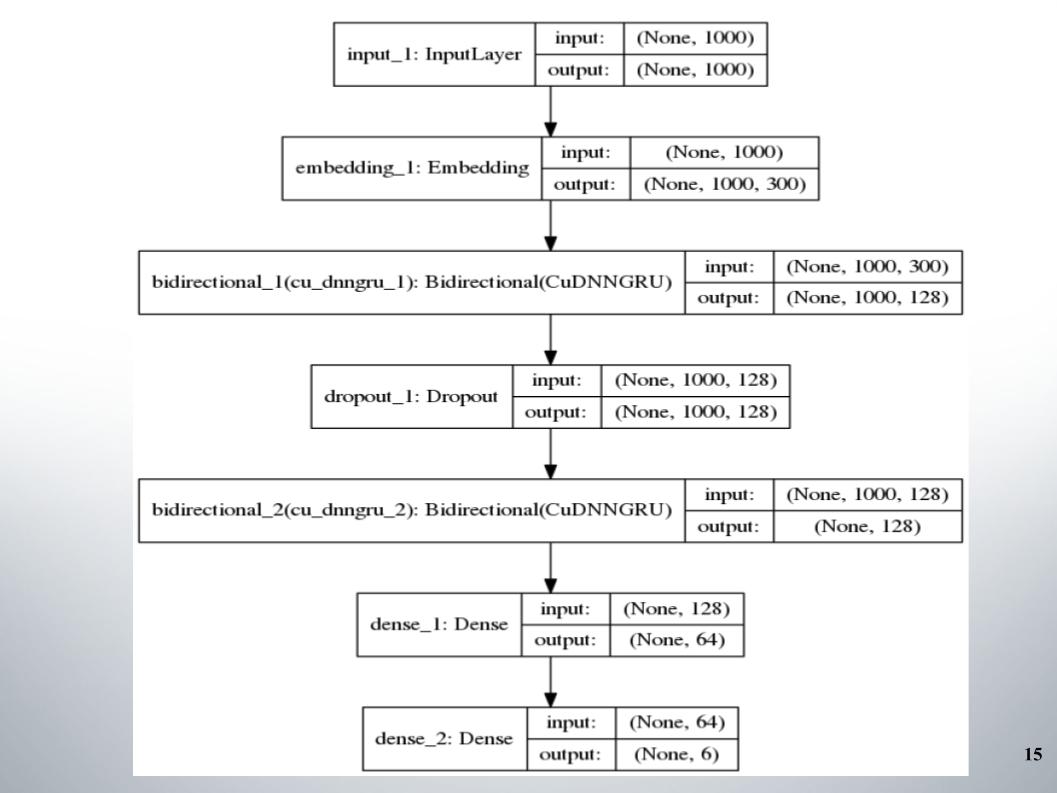
Alles begann mit dem Standard-Didirectional Gru mit zwei Ebenen, fast alle Teams verwendeten es, und fastText, die EL-Aktivierungsfunktion, wurde als Einbettung verwendet.
Es gibt nichts Besonderes zu sagen, einfache Architektur ohne Schnickschnack. Warum hat sie uns so gute Ergebnisse gebracht, mit denen wir einige Zeit in den Top 150 geblieben sind? Wir hatten eine gute Vorverarbeitung des Textes. Es war notwendig, weiterzumachen.
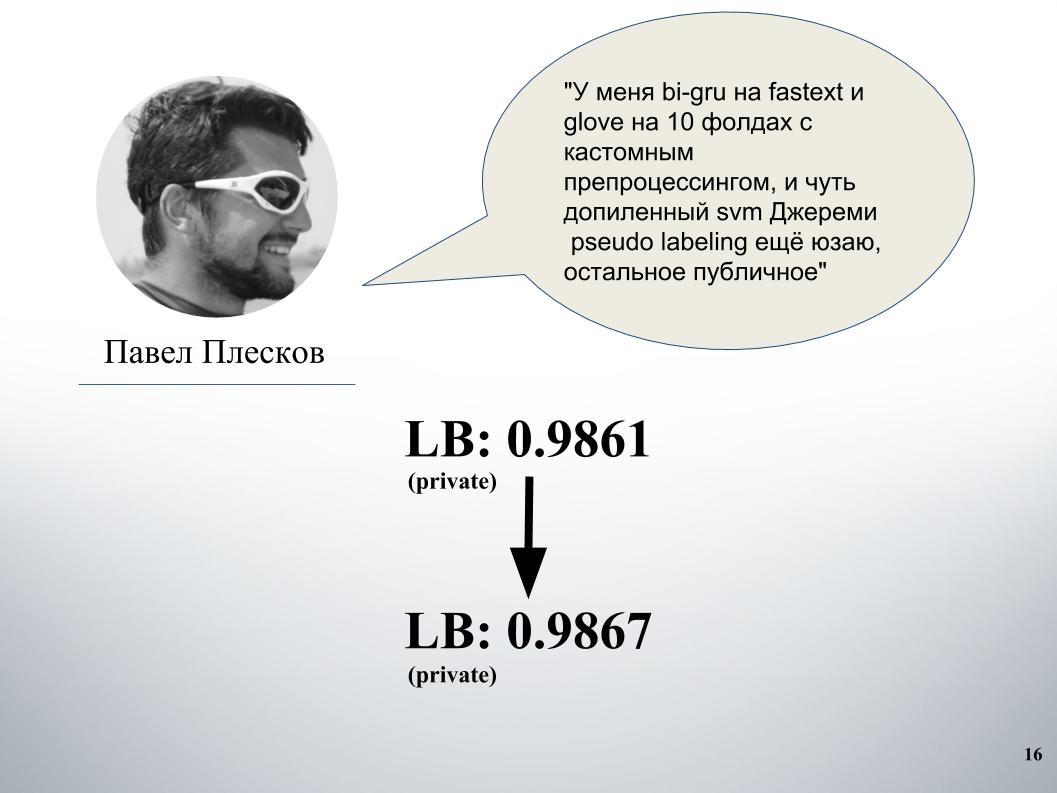
Paul hatte seinen eigenen Ansatz. Nach dem Mischen mit unserem ergab sich ein deutlicher Anstieg. Davor hatten wir eine Mischung aus Gruppe und Modell auf Doc2vec, es gab 61 LB.
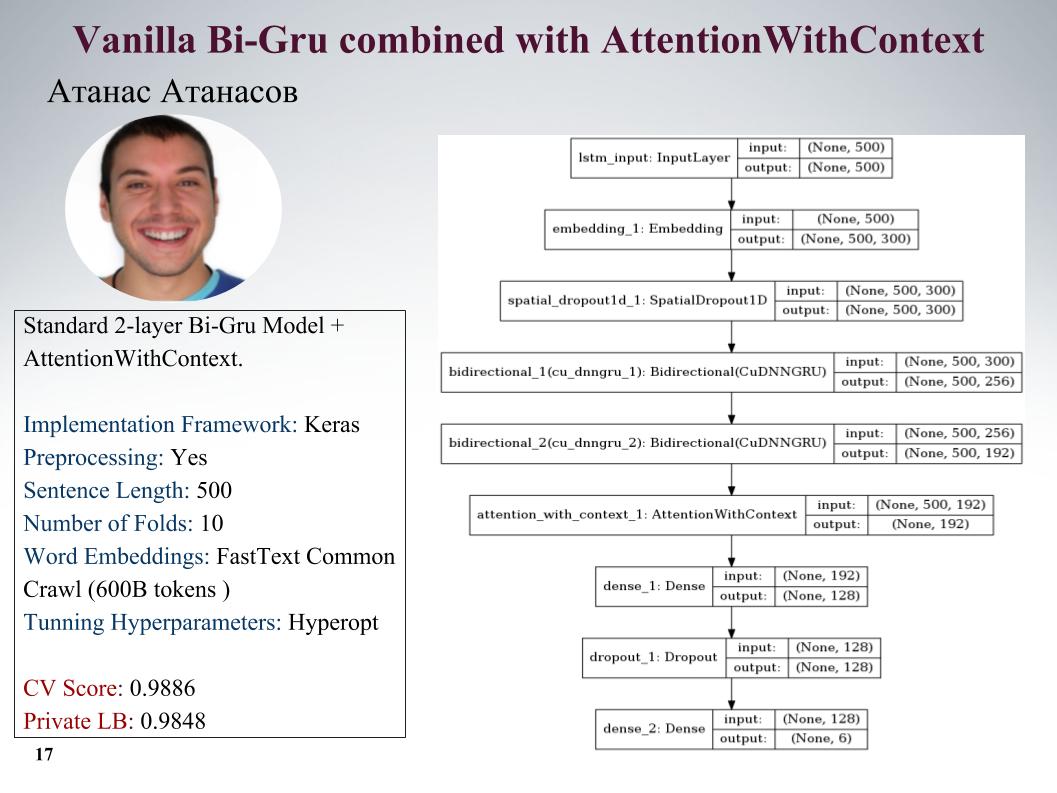
Ich erzähle Ihnen von den Ansätzen von Atanas Atanasov, er ist direkt ein Enthusiast von neuen Artikeln. Hier ist gru mit Aufmerksamkeit, alle Parameter auf der Folie. Er hatte viele wirklich coole Ansätze, aber bis zum letzten Moment nutzte er seine Vorverarbeitung und alle Gewinne wurden ausgeglichen. Geschwindigkeit auf der Rutsche.
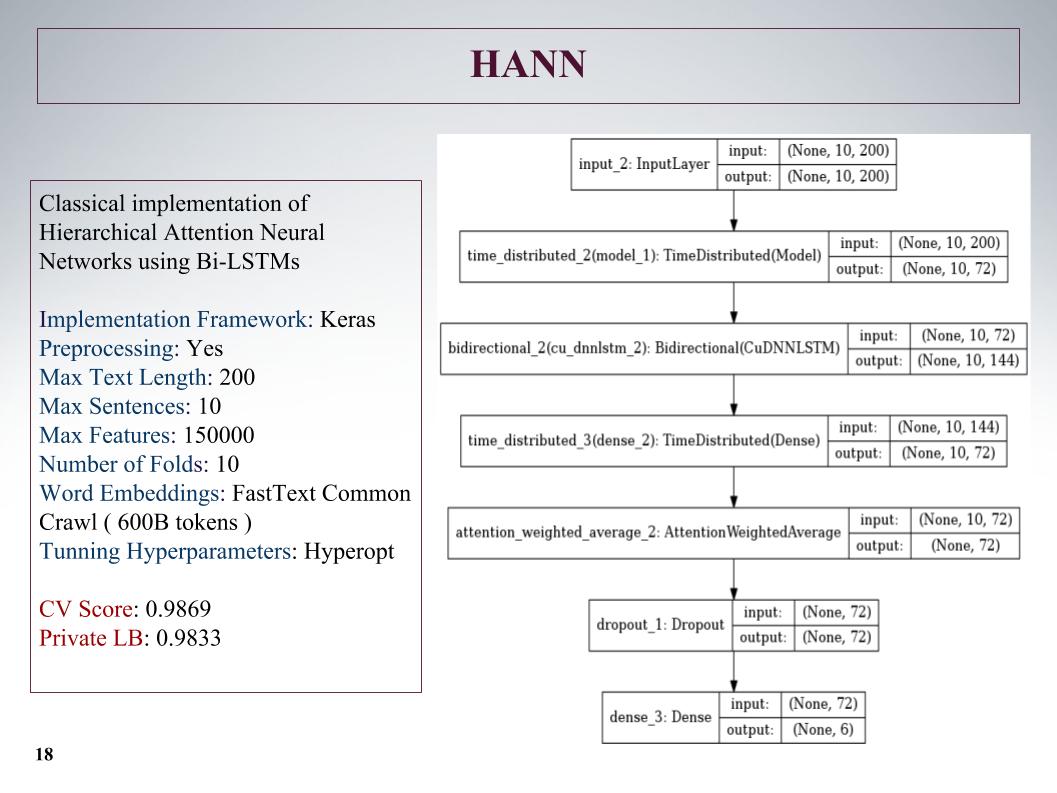
Dann gab es eine hierarchische Aufmerksamkeit, die noch schlechtere Ergebnisse zeigte, da es sich zunächst um ein Netzwerk zur Klassifizierung von Dokumenten handelte, die aus Sätzen bestanden. Er hat es vermasselt, aber der Ansatz ist nicht sehr.
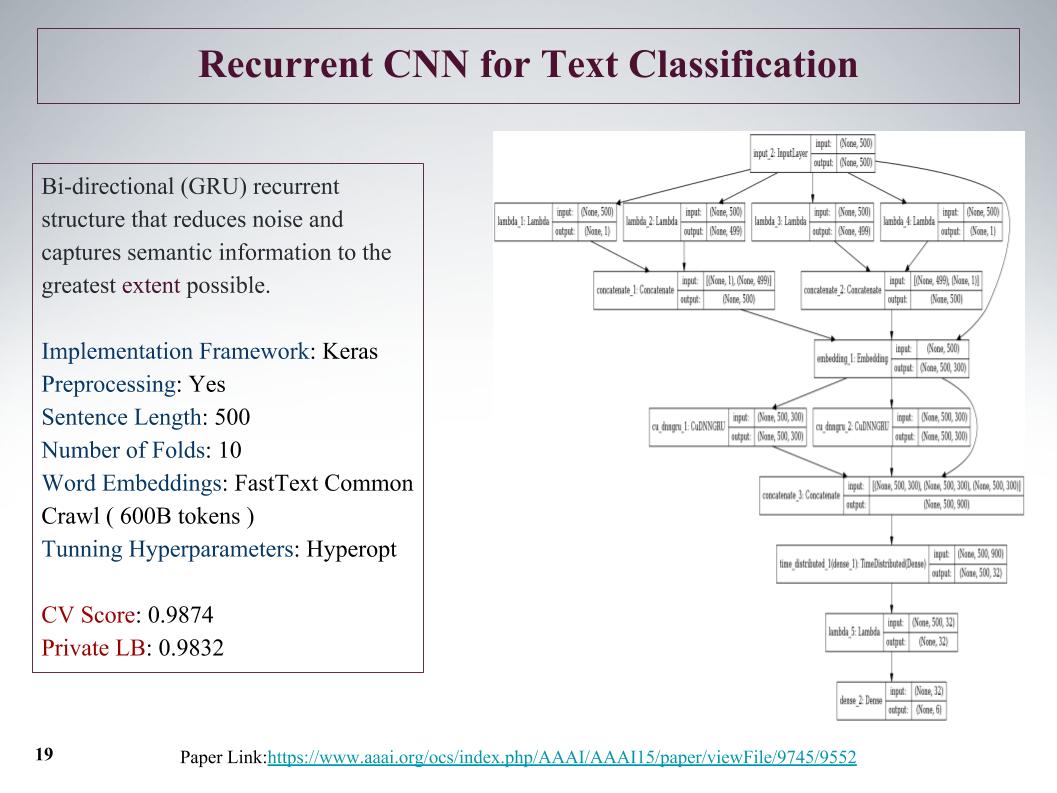
Es gab einen interessanten Ansatz, wir können zunächst von Anfang an und von Ende an Features aus dem Angebot erhalten. Mit Hilfe von Faltungs- und Faltungsschichten erhalten wir Merkmale links und rechts vom Baum. Dies ist vom Anfang bis zum Ende des Satzes, dann verschmelzen sie und laufen erneut durch gru.

Auch Bi-GRU mit Aufmerksamkeitsblock. Dies ist eines der besten auf privat war ein ziemlich tiefes Netzwerk, zeigte gute Ergebnisse.

Der nächste Ansatz besteht darin, Funktionen so weit wie möglich hervorzuheben. Nach der Schicht des wiederkehrenden Netzwerks machen wir drei weitere parallele Faltungsschichten. Und hier haben wir nicht so lange Sätze genommen, sie auf 250 gekürzt, aber aufgrund von drei Windungen ergab dies ein gutes Ergebnis.

Es war das tiefste Netzwerk. Wie Atanas sagte, wollte er nur etwas Großes und Interessantes lehren. Als gewöhnliches Faltungsraster, das aus Textmerkmalen gelernt hat, sind die Ergebnisse nichts Besonderes.

Dies ist ein ziemlich interessanter neuer Ansatz. 2017 gab es einen Artikel zu diesem Thema, der für ImageNet verwendet wurde. Dort konnten wir das vorherige Ergebnis um 25% verbessern. Sein Hauptmerkmal ist, dass eine kleine Schicht parallel zum Faltungsblock gestartet wird, die die Gewichte für jede Faltung in diesem Block lehrt. Sie ging sehr cool vor, obwohl sie die Sätze gekürzt hatte.
Das Problem ist, dass die maximale Länge der Sätze in diesen Aufgaben 1.500 Wörter erreichte, es gab sehr große Kommentare. Andere Teams hatten auch Gedanken darüber, wie sie dieses große Angebot einfangen und finden können, weil nicht alles sehr vorangetrieben ist. Und viele sagten, dass es am Ende des Satzes eine sehr wichtige Infa gab. Leider wurde dies bei all diesen Ansätzen nicht berücksichtigt, da der Anfang berücksichtigt wurde. Vielleicht würde dies zu einer weiteren Steigerung führen.

Hier ist die AC-BLSTM-Architektur. Die Quintessenz ist, dass, wenn die untere Unterteilung in zwei Teile zusätzlich zur Aufmerksamkeit ein kluges Ziehen ist, aber parallel dazu immer noch normal ist und dies alles konkretisiert wird. Auch gute Ergebnisse.

Und Atanas sein ganzer Zoo von Models, dann war es eine coole Mischung. Zusätzlich zu den Modellen selbst habe ich einige Textfunktionen hinzugefügt, normalerweise Länge, Anzahl der Großbuchstaben, Anzahl der schlechten Wörter, Anzahl der Zeichen, alles hinzugefügt. Kreuzvalidierung von fünf Falten und ausgezeichnete Ergebnisse auf privatem LB 0.9867.
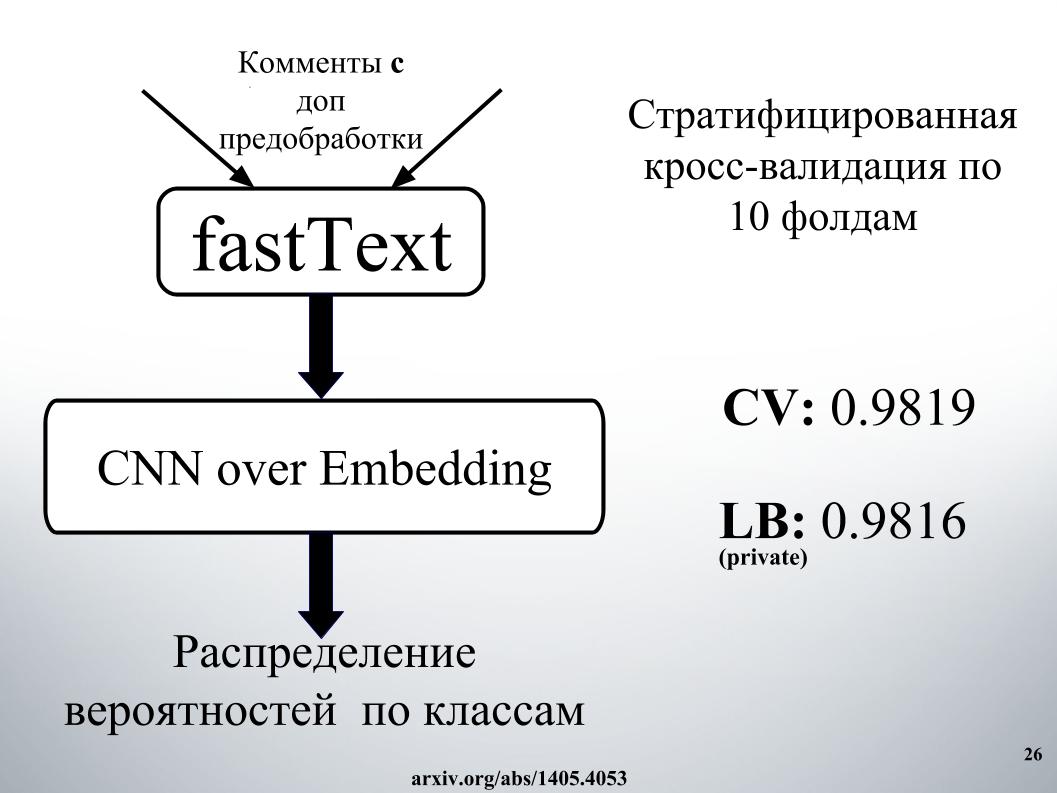
Und beim zweiten Ansatz unterrichtete er mit einer anderen Einbettung, aber die Ergebnisse waren schlechter. Meistens haben alle fastText verwendet.
Ich wollte über den Ansatz unseres anderen Kollegen Andrei mit dem Spitznamen Laol bei ODS sprechen. Er hat viele öffentliche Kernel unterrichtet, er hat sie getrunken, als wäre er aus sich heraus, und das hat wirklich sehr coole Ergebnisse gebracht. Sie könnten das alles nicht tun, aber nehmen Sie einfach ein paar verschiedene öffentliche Kernel, selbst auf tf-idf gibt es alle Arten von gru-Konvolutionären.
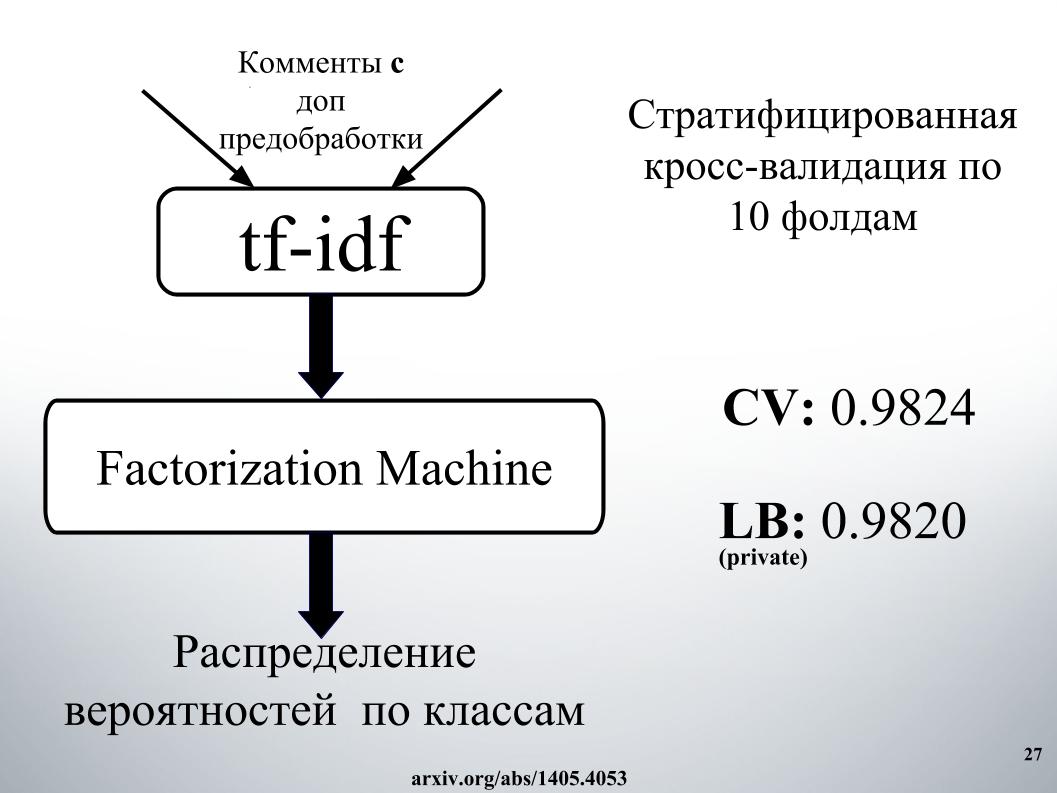
Er hatte einen der besten Ansätze, mit denen wir lange in den Top 15 blieben, bis Alexey und Atanas zu uns kamen, er kombinierte das Mischen und Stapeln von all dem. Und auch ein sehr cooler Moment, den meines Wissens keines der Teams genutzt hat, haben wir dann auch Features aus den Ergebnissen der Organisator-API gemacht. Darüber erzähl Alex weiter.
Alexey Noskov:
- Hallo. Ich erzähle Ihnen von dem Ansatz, den ich verwendet habe, und wie wir ihn abgeschlossen haben.

Für mich war alles einfach genug: 10-fache Kreuzvalidierung, Modelle, die auf verschiedenen Vektoren mit unterschiedlicher Vorverarbeitung vorab trainiert wurden, damit sie mehr Vielfalt im Ensemble hatten, eine kleine Erweiterung und zwei Entwicklungszyklen. Die erste, die im Grunde genommen am Anfang funktionierte, trainierte eine bestimmte Anzahl von Modellen, untersuchte Kreuzvalidierungsfehler, anhand welcher Beispiele offensichtliche Fehler auftreten, und korrigierte die Vorverarbeitung auf dieser Grundlage, da nur klarer ist, wie sie behoben werden können.
Und der zweite Ansatz, der am Ende mehr verwendet wurde, lehrte einige Modelle, betrachtete Korrelationen, fand Blöcke von Modellen, die schwach miteinander korreliert sind, und stärkte den Teil, der aus ihnen bestand. Dies ist die Kreuzvalidierungskorrelationsmatrix zwischen meinen Modellen.
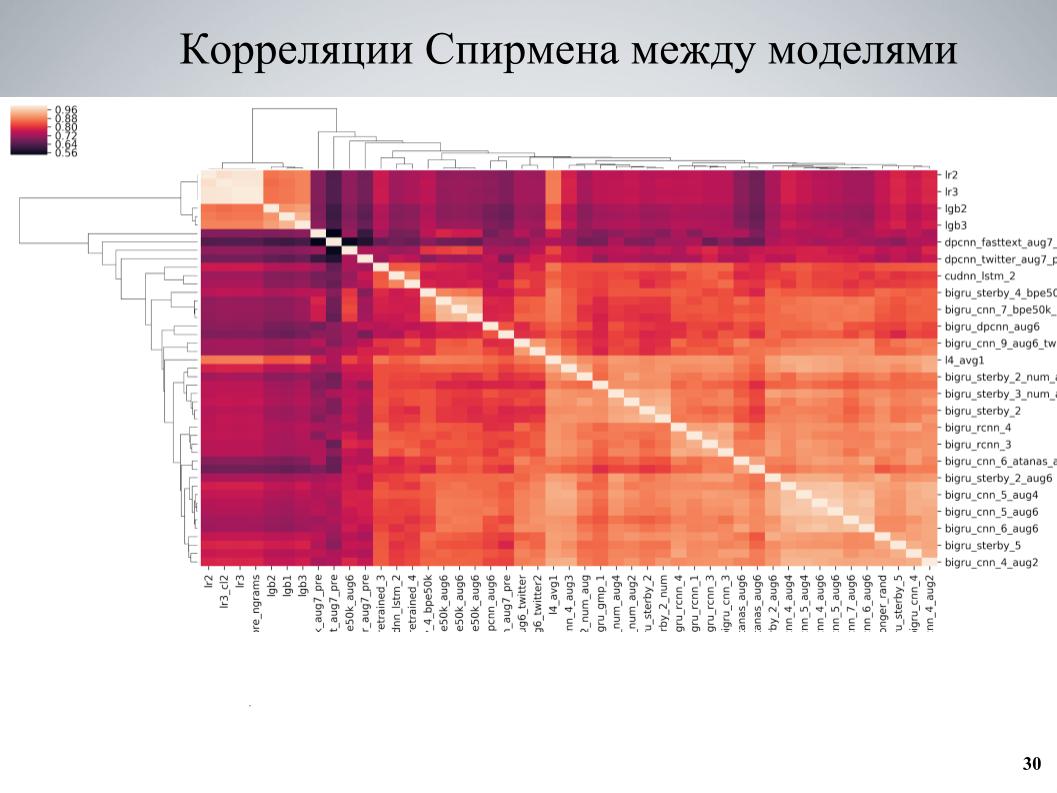
Es ist ersichtlich, dass es an einigen Stellen eine Blockstruktur aufweist, während einige Modelle von guter Qualität waren, sie schwach mit den anderen korrelierten und sehr gute Ergebnisse erzielt wurden, als ich diese Modelle als Grundlage nahm und ihnen verschiedene Variationen beibrachte, die sich in verschiedenen unterscheiden Hyperparameter oder Vorverarbeitung und dann dem Ensemble hinzugefügt.

Zur Erweiterung hat die Idee, die Pavel Ostyakov im Forum veröffentlicht hat, am meisten ausgelöst. Es bestand darin, dass wir einen Kommentar aufnehmen, ihn in eine andere Sprache übersetzen und dann zurück können. Durch die doppelte Übersetzung wird eine Neuformulierung erhalten, etwas geht etwas verloren, aber insgesamt wird ein ähnlicher, leicht unterschiedlicher Text erhalten, der auch klassifiziert werden kann und dadurch den Datensatz erweitert.
Und der zweite Ansatz, der nicht so viel geholfen hat, aber auch geholfen hat, ist, dass Sie versuchen können, zwei willkürliche Kommentare zu nehmen, die normalerweise nicht sehr lang sind, sie zu kleben und eine Kombination von Etiketten oder ein wenig Lust als Etikett auf das Ziel zu nehmen, wenn es nur eines gibt Sie enthielten ein Etikett.
Beide Ansätze haben gut funktioniert, wenn sie nicht im Voraus auf den gesamten Satz angewendet wurden, sondern um die Beispiele zu ändern, auf die die Erweiterung in jeder Epoche angewendet werden sollte. In jeder Ära, in der ein Stapel gebildet wird, wählen wir beispielsweise 30% der Beispiele aus, für die Übersetzungen verwendet werden. Vielmehr wählen wir im Voraus, irgendwo parallel, bereits im Speicher, einfach die Version für die Übersetzung basierend darauf aus und fügen sie während des Trainings dem Stapel hinzu.

Ein interessanter Unterschied waren die bei BPE trainierten Modelle. Es gibt ein SentencePiece - einen Google-Tokenizer, mit dem Sie sich in Token aufteilen können, in denen es überhaupt kein UNK gibt. Ein begrenztes Wörterbuch, in dem eine Zeichenfolge in einige Token unterteilt ist. Wenn die Anzahl der Wörter im realen Text größer als die Zielgröße des Wörterbuchs ist, beginnen sie, in kleinere Teile zu zerfallen, und es wird ein Zwischenansatz zwischen den Modellen auf Zeichenebene und auf Wortebene erhalten.
Dort werden zwei Hauptkonstruktionsalgorithmen verwendet: BPE und Unigram. Für den BPE-Algorithmus war es einfach genug, vorab trainierbare Einbettungen im Netzwerk zu finden, und mit einem festen Vokabular - ich hatte gerade ein gutes 50.000-Vokabular - konnte ich auch Modelle trainieren, die ein gutes (unhörbares - ca. Ed.) Ergaben. als üblich auf fastText, aber sie waren sehr schwach mit allen anderen korreliert und gaben einen guten Schub.
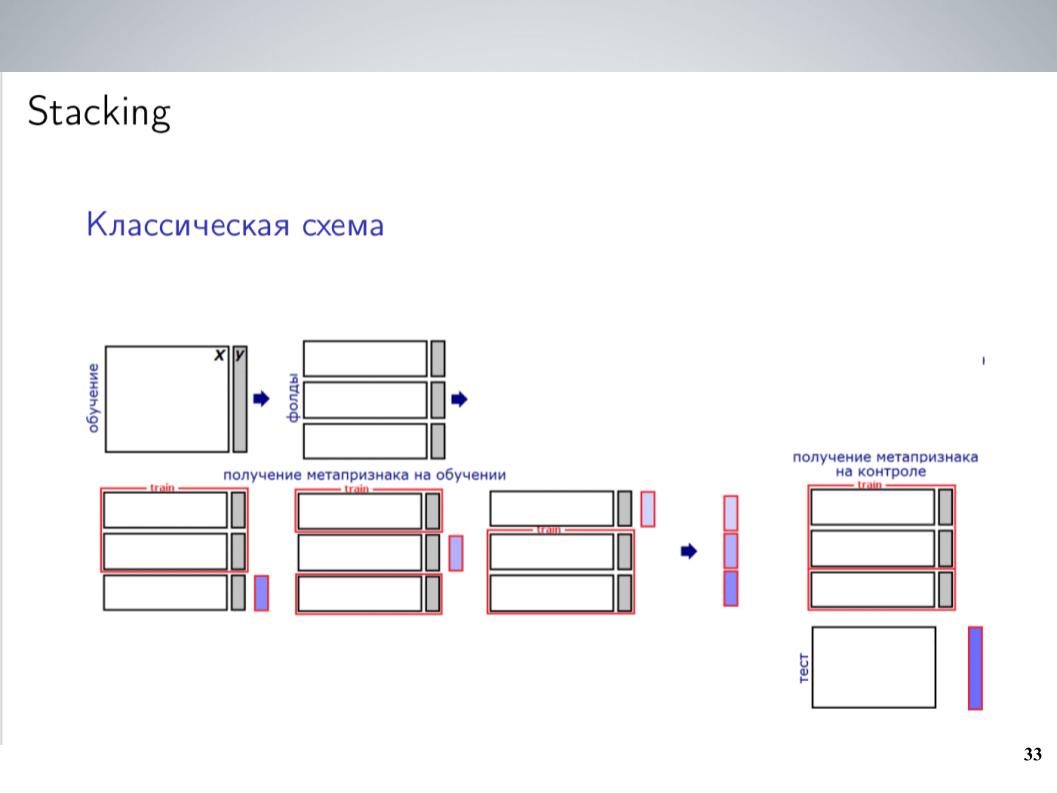
Dies ist ein klassisches Stapelschema. In der Regel habe ich vor dem Kombinieren zum größten Teil des Wettbewerbs einfach alle meine Modelle ohne Gewichte gemischt. Dies ergab die besten Ergebnisse. Aber nach der Fusion konnte ich ein etwas komplexeres Schema bekommen, was am Ende einen guten Schub gab.

Ich hatte eine große Anzahl von Modellen. Einfach alle in eine Art Stapler werfen? Es hat nicht sehr gut funktioniert, er hat umgeschult, aber da die Modelle Gruppen waren, die ziemlich stark korreliert waren, habe ich sie einfach in diese Gruppen zusammengefasst. Innerhalb jeder Gruppe habe ich gemittelt und 5-7 Gruppen sehr ähnlicher Modelle erhalten, von denen als Merkmale für Die nächste Ebene verwendete gemittelte Werte. Ich habe LightGBM darauf trainiert, 20 Starts mit verschiedenen Beispielen abgehört, ein bisschen Metafunktionalität hochgeladen, ähnlich wie Atanas, und am Ende hat es endlich funktioniert, was der einfachen Mittelwertbildung einen gewissen Schub verlieh.

Vor allem habe ich die API hinzugefügt, die Andrei gefunden hat und die einen ähnlichen Satz von Labels enthält. Die Organisatoren bauten zunächst Modelle für sie. Da es ursprünglich anders war und die Teilnehmer es nicht verwendeten, war es unmöglich, es einfach mit denen zu vergleichen, die wir vorhersagen mussten. Aber wenn es sich als Meta-Feature in ein gut funktionierendes Stacking stürzen würde, würde es einen wunderbaren Schub geben, insbesondere in der TOXIC-Klasse, die anscheinend am schwierigsten in der Rangliste war und es uns ermöglichte, am Ende buchstäblich am letzten Tag an mehrere Stellen zu springen .

Da wir vor den endgültigen Einreichungen festgestellt haben, dass das Stapeln und die API für uns so gut funktionieren, hatten wir wenig Zweifel daran, wie gut dies auf privat portiert werden würde. Es hat sehr verdächtig gut funktioniert, daher haben wir zwei Einreichungen nach dem folgenden Prinzip ausgewählt: eine - eine Mischung aus Modellen ohne zuvor empfangene API sowie das Stapeln mit Metaphysik aus der API. Hier stellte sich heraus, dass 0,9880 öffentlich und 0,9874 privat waren. Hier sind meine Noten verwirrt.

Und die zweite ist eine Mischung aus Modellen ohne API, ohne Stacking und ohne LightGBM, da befürchtet wurde, dass dies eine Art geringfügige Umschulung für die Öffentlichkeit ist, und wir könnten damit losfliegen. Es ist passiert, sie sind nicht weggeflogen und als Ergebnis haben wir mit dem Ergebnis von 0,9876 auf privat den zehnten Platz erreicht. Das ist alles.