Big Business und Bloody Enterprise haben seit langem einen Ersatz für erwachsene Rdbds für DWH und Analytics gefunden. DWH bewegt sich massiv in Richtung DataLake und Hadoop. Es scheint, dass kleine Unternehmen nicht mehr viel Sinn machen, Analysen auf einem seriösen Rsbd zu starten. Angesichts der wachsenden Anzahl von Kernen, die auch für kleine Unternehmen verfügbar sind, ist es wenig sinnvoll, eine vollwertige Version eines Subtyps für Erwachsene wie Oracle zu lizenzieren. Standard Edition Oracle ist zwar für Sockets lizenziert, schneidet aber gleichzeitig die wichtigsten Funktionen aus. Erstens gibt es in der Standardausgabe keine Partitionierung
gibt es nur eine Partitionierungsansicht - Tabellenfreigabe nach Art von Postgres, die nur in bestimmten Situationen hilfreich sein kann. Zweitens gibt es keinen vollwertigen Standby, Parallelbetrieb wird eingestellt. Der RAC-Cluster ist auf vier Sockets beschränkt. Infolgedessen stoßen Sie mit dem modernen Datenwachstum schnell auf die Einschränkungen der Standard Edition, und der Lizenzpreis der Enterprise Edition macht diese Aufgabe sinnlos. In Oracle muss nicht nur der Battle Server, sondern auch der Standby-Server lizenziert werden, während die Enterprise Edition vom Core lizenziert wird. Cluster-, Partitionierungs- und DataGuard / Standby-Optionen erfordern eine separate Lizenzierung sowie einen Kern. Infolgedessen zieht sogar ein Einstiegsserver mit 16 Kernen und seinem Standard für EE-Lizenzen viele hunderttausende Dollar ein, und selbst die blutige Unternehmensverwaltung fällt in Ohnmacht.
Wir müssen in Khadupov nach einer Alternative suchen. Ich habe versucht, einige Anforderungen für eine Datenpräsentation, die auf Parkettdateien in einem Backup basiert, mit Oracle Standard auf 8 xeon-Kernen, 196 GB Frames, einem bestimmten Enterprise Store mit HDD- und SSD-Cache zu vergleichen, der mit mehreren weiteren Systemen durchsucht werden kann. Die erste Abfrage betrifft 4 Tabellen. In Oracle belegten sie 62, 12, 6,5 und 3,5 GB. In einer Platte, die größer als etwa 880 Millionen Zeilen ist. In einem Anforderungsplan war wie folgt:
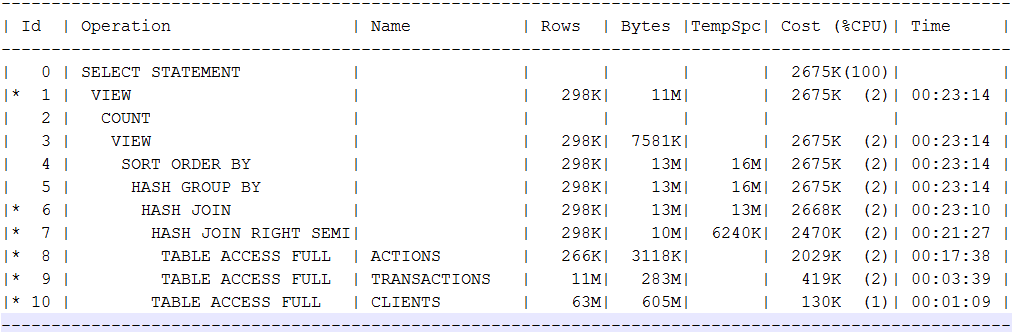
In dem Plan wollte ich speziell die Fullscans und Hashjoins sehen, die für meine analytischen Abfragen typisch sind. In der Realität dauert die Anforderung einer Standardversion von Oracle etwa 7 Minuten. Spark 2.3, das über spark2-submit an 14 Executoren mit 4 Kernen / 16 GB Frames gestartet wurde, gibt innerhalb einer Minute eine Antwort auf fast dieselbe Anfrage von 10.000 Festplatten. Cloudera Impala, die mit Garn und Funken auf demselben Cluster drückt (Impalad auf 8 Knoten, Ressourcen vergleichbar mit 14 Executoren mit 4 Kernen), gibt in 11-12 Sekunden eine stabile Antwort. Gleichzeitig läuft Impala ständig parallel zur Last, wodurch die zwischengespeicherten Daten gewaschen werden sollen.
Spiele mit Blockgröße, die auf die Oracle EE-Edition mit Parallelität und Partitionierung für Erwachsene umsteigen, hätten die Ausführungszeit wahrscheinlich um ein Vielfaches verkürzt, aber ich bezweifle leicht, dass die Zeit sogar mit der von Spark vergleichbar wäre. Auf der anderen Seite ermöglichen es Ihnen nur 3-4 Knoten des praktisch kostenlosen Cloudera Hadoop im Wesentlichen, in die übliche SQL zu gelangen, die Geschwindigkeit, für die Oracle unvergleichlich viel Geld hätte.
Oracle sollte ernsthaft über Lizenzrichtlinien nachdenken, wenn große Fans wie ich keinen Grund finden, für die Enterprise Edition zu bezahlen.