Ich wurde informiert, dass auf neuen Computern einige Regressionstests langsamer wurden. Eine häufige Sache, es passiert. Falsche Konfiguration irgendwo in Windows oder nicht die optimalsten Werte im BIOS. Diesmal konnten wir jedoch nicht die gleiche "niedergeschlagene" Einstellung finden. Da die Änderung signifikant ist: 9 vs. 19 Sekunden (auf der Karte ist Blau das alte Eisen und Orange das neue), musste ich tiefer graben.
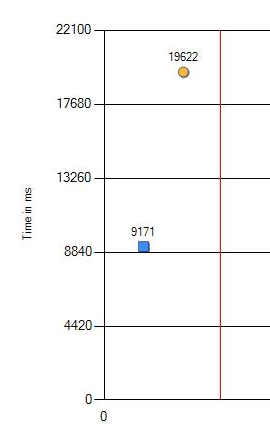
Gleiches Betriebssystem, gleiche Hardware, anderer Prozessor: 2 mal langsamer
Der Leistungsabfall von 9,1 auf 19,6 Sekunden kann definitiv als signifikant bezeichnet werden. Wir haben zusätzliche Überprüfungen mit einer Änderung der Versionen der getesteten Programme, Windows- und BIOS-Einstellungen durchgeführt. Aber nein, das Ergebnis hat sich nicht geändert. Der einzige Unterschied trat nur bei verschiedenen Prozessoren auf. Unten sehen Sie das Ergebnis der neuesten CPU.
Und hier ist die, die zum Vergleich verwendet wird.

Xeon Gold läuft auf einer anderen Architektur namens Skylake, die seit Mitte 2017 neuen Intel-Prozessoren gemeinsam ist. Wenn Sie die neueste Hardware kaufen, erhalten Sie einen Prozessor mit der Skylake-Architektur. Das sind gute Autos, aber wie Tests gezeigt haben, sind Neuheit und Geschwindigkeit nicht dasselbe.
Wenn nichts anderes hilft, müssen Sie den Profiler für eingehende Recherchen verwenden. Lassen Sie uns alte und neue Geräte testen und so etwas bekommen:
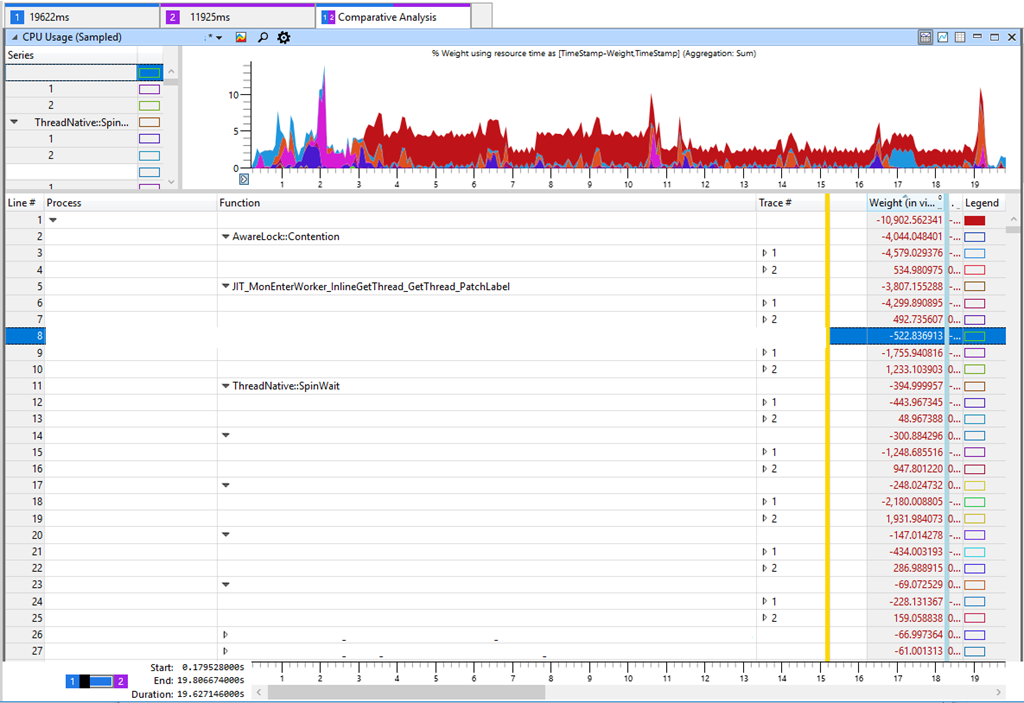
Die Registerkarte in Windows Performance Analyzer (WPA) zeigt in der Tabelle den Unterschied zwischen Trace 2 (11 s) und Trace 1 (19 s). Ein negativer Unterschied in der Tabelle entspricht einem Anstieg des CPU-Verbrauchs in einem langsameren Test. Wenn Sie sich die wichtigsten Unterschiede beim CPU-Verbrauch
ansehen, sehen Sie
AwareLock :: Contention ,
JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel und
ThreadNative.SpinWait . Alles deutet auf ein "Drehen" in der CPU hin [Drehen - ein zyklischer Versuch, eine Sperre zu erhalten, ca. per.], wenn Threads um Blockierung kämpfen. Dies ist jedoch eine falsche Marke, da das Spinnen nicht der Hauptgrund für den Rückgang der Produktivität ist. Die zunehmende Konkurrenz um Sperren bedeutet, dass sich etwas in unserer Software verlangsamt und die Sperre beibehalten hat, was zu einem erhöhten Durchdrehen der CPU führte. Ich habe die Sperrzeit und andere Schlüsselindikatoren wie die Festplattenleistung überprüft, aber ich konnte nichts Sinnvolles finden, das den Leistungsabfall erklären könnte. Dies ist zwar nicht logisch, aber ich bin zurückgekehrt, um die Belastung der CPU mit verschiedenen Methoden zu erhöhen.
Es wäre interessant, genau herauszufinden, wo der Prozessor stecken bleibt. WPA verfügt über Spalten für Datei- und Zeilennummern, diese funktionieren jedoch nur mit privaten Zeichen, die wir nicht haben, da dies .NET Framework-Code ist. Das nächstbeste, was wir tun können, ist, die DLL-Adresse abzurufen, unter der sich die Anweisung Image RVA befindet. Wenn Sie diese DLL in den Debugger laden und tun
u xxx.dll+ImageRVAdann sollten wir den Befehl sehen, der die meisten CPU-Zyklen brennt, da dies die einzige "heiße" Adresse ist.
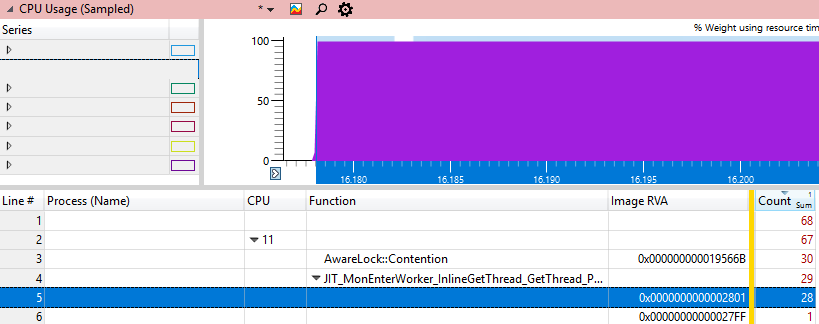
Wir werden diese Adresse mit verschiedenen Windbg-Methoden untersuchen:
0:000> u clr.dll+0x19566B-10
clr!AwareLock::Contention+0x135:
00007ff8`0535565b f00f4cc6 lock cmovl eax,esi
00007ff8`0535565f 2bf0 sub esi,eax
00007ff8`05355661 eb01 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)
00007ff8`05355663 cc int 3
00007ff8`05355664 83e801 sub eax,1
00007ff8`05355667 7405 je clr!AwareLock::Contention+0x144 (00007ff8`0535566e)
00007ff8`05355669 f390 pause
00007ff8`0535566b ebf7 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)Und mit verschiedenen JIT-Methoden:
0:000> u clr.dll+0x2801-10
clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:
00007ff8`051c27f1 5e pop rsi
00007ff8`051c27f2 c3 ret
00007ff8`051c27f3 833d0679930001 cmp dword ptr [clr!g_SystemInfo+0x20 (00007ff8`05afa100)],1
00007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a (00007ff8`051c2817)
00007ff8`051c27fc 418bc2 mov eax,r10d
00007ff8`051c27ff f390 pause
00007ff8`051c2801 83e801 sub eax,1
00007ff8`051c2804 75f9 jne clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x132 (00007ff8`051c27ff)Jetzt haben wir eine Vorlage. In einem Fall ist die Hot-Adresse eine Sprunganweisung und im anderen Fall eine Subtraktion. Vor beiden heißen Anweisungen steht jedoch dieselbe allgemeine Pausenanweisung. Verschiedene Methoden führen denselben Prozessorbefehl aus, was aus irgendeinem Grund sehr lange dauert. Lassen Sie uns die Ausführungsgeschwindigkeit der pause-Anweisung messen und prüfen, ob wir richtig argumentieren.
Wenn das Problem dokumentiert ist, wird es zu einer Funktion.
| CPU | Pause in Nanosekunden |
| Xeon E5 1620v3 3,5 GHz | 4 |
| Xeon® Gold 6126 bei 2,60 GHz | 43 |
Das Anhalten in neuen Skylake-Prozessoren dauert eine Größenordnung länger. Natürlich kann alles schneller und manchmal etwas langsamer werden. Aber
zehnmal langsamer? Es ist eher wie ein Käfer. Eine kleine Suche im Internet nach Pausenanweisungen führt zu
Intels Handbuch , in dem die Skylake-Mikroarchitektur und Pausenanweisungen ausdrücklich erwähnt werden:

Nein, das ist kein Fehler, das ist eine dokumentierte Funktion. Es gibt sogar eine
Seite, auf der die Ausführungszeit fast aller Prozessoranweisungen angegeben ist.
- Sandbrücke 11
- Ivy Bridege 10
- Haswell 9
- Broadwell 9
- SkylakeX 141
Hier wird die Anzahl der Prozessorzyklen angegeben. Um die tatsächliche Zeit zu berechnen, müssen Sie die Anzahl der Zyklen durch die Prozessorfrequenz (normalerweise in GHz) dividieren und die Zeit in Nanosekunden ermitteln.
Dies bedeutet, dass Anwendungen mit hohem Multithreading in .NET auf der letzten Hardware viel langsamer arbeiten können. Jemand hat dies bereits bemerkt und im August 2017
einen Fehler registriert . Das Problem wurde in .NET Core 2.1 und .NET Framework 4.8 Preview
behoben .
Verbesserte Wartezeit in mehreren Synchronisationsprimitiven für eine bessere Leistung auf Intel Skylake und späteren Mikroarchitekturen. [495945, mscorlib.dll, Bug]
Da es jedoch noch ein Jahr vor der Veröffentlichung von .NET 4.8 gibt, habe ich darum gebeten, die Korrekturen zurück zu portieren, damit .NET 4.7.2 auf neuen Prozessoren wieder zur normalen Geschwindigkeit zurückkehrt. Da sich in vielen Teilen von .NET gegenseitig ausschließende Sperren (Spinlocks) existieren, sollten Sie die erhöhte CPU-Auslastung verfolgen, wenn Thread.SpinWait und andere Spinnmethoden funktionieren.

Zum Beispiel verwendet Task.Result intern das Spinnen, sodass ich in anderen Tests eine signifikante Erhöhung der CPU-Auslastung und eine geringere Leistung erwarte.
Wie schlimm ist es
Ich habe mir den .NET Core-Code angesehen, wie lange sich der Prozessor weiter dreht, wenn die Sperre nicht aufgehoben wird, bevor WaitForSingleObject aufgerufen wurde, um den „teuren“ Kontextwechsel zu bezahlen. Ein Kontextwechsel dauert etwa eine Mikrosekunde oder viel länger, wenn viele Threads dasselbe Kernelobjekt erwarten.
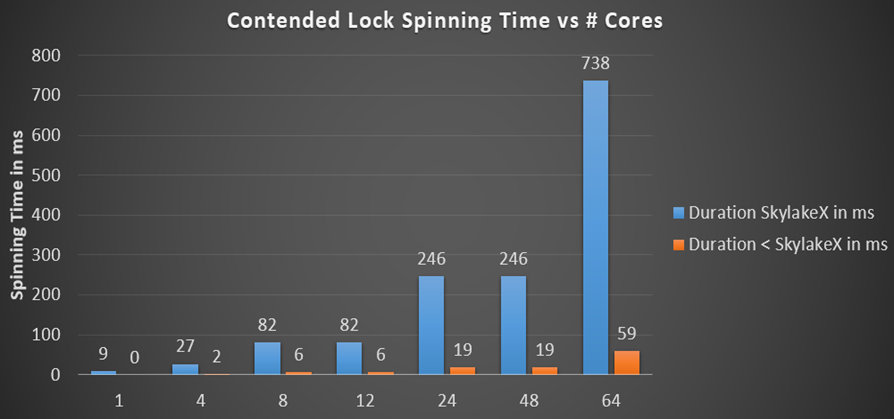
.NET-Sperren multiplizieren die maximale Drehdauer mit der Anzahl der Kerne, wenn wir den absoluten Fall annehmen, in dem der Thread auf jedem Kern dieselbe Sperre erwartet und der Dreh lange genug andauert, damit alle ein wenig arbeiten können, bevor sie für den Kernel-Aufruf bezahlen. Das Drehen in .NET verwendet einen exponentiellen Alterungsalgorithmus, wenn es mit einem Zyklus von 50 Pausenaufrufen beginnt, wobei für jede Iteration die Anzahl der Drehungen verdreifacht wird, bis der nächste Drehzähler ihre maximale Dauer überschreitet. Ich habe die Gesamtdrehdauer pro Prozessor für verschiedene Prozessoren und eine unterschiedliche Anzahl von Kernen berechnet:
Unten finden Sie den vereinfachten Drehcode in .NET Locks:
/// <summary> /// This is how .NET is spinning during lock contention minus the Lock taking/SwitchToThread/Sleep calls /// </summary> /// <param name="nCores"></param> void Spin(int nCores) { const int dwRepetitions = 10; const int dwInitialDuration = 0x32; const int dwBackOffFactor = 3; int dwMaximumDuration = 20 * 1000 * nCores; for (int i = 0; i < dwRepetitions; i++) { int duration = dwInitialDuration; do { for (int k = 0; k < duration; k++) { Call_PAUSE(); } duration *= dwBackOffFactor; } while (duration < dwMaximumDuration); } }
Zuvor lag die Spinnzeit im Millisekundenintervall (19 ms für 24 Kerne), was im Vergleich zur erwähnten Kontextumschaltzeit, die um eine Größenordnung schneller ist, bereits viel ist. Bei Skylake-Prozessoren explodiert die Gesamtspinnzeit für den Prozessor auf einem 24-Bit- oder 48-Core-Computer einfach bis zu 246 ms, einfach weil der Pausenbefehl um das 14-fache verlangsamt wurde. Das ist tatsächlich so? Ich habe einen kleinen Tester geschrieben, um den Gesamtspinn der CPU zu überprüfen - und die berechneten Zahlen entsprechen den Erwartungen. Hier sind 48 Threads auf einer 24-Kern-CPU, die auf eine Sperre warten, die ich Monitor.PulseAll genannt habe:
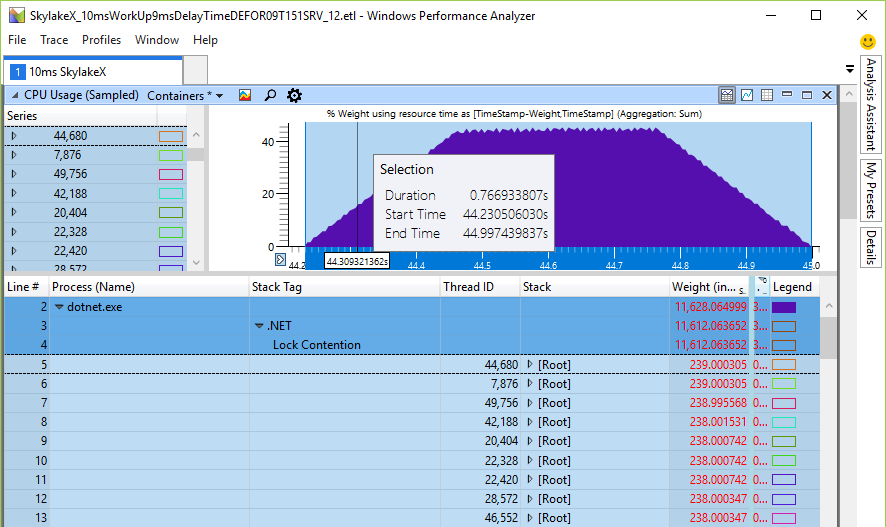
Nur ein Thread gewinnt das Rennen, aber 47 drehen sich weiter, bis sie ihre Herzfrequenz verlieren. Dies ist ein experimenteller Beweis dafür, dass wir wirklich ein Problem mit der CPU-Auslastung haben und sehr lange Drehungen real sind. Dies untergräbt die Skalierbarkeit, da diese Zyklen anstelle der nützlichen Arbeit anderer Threads ablaufen, obwohl der Pausenbefehl einige der gemeinsam genutzten Ressourcen der CPU freigibt und für eine längere Zeit Schlaf bereitstellt. Der Grund für das Drehen ist der Versuch, eine Sperre schneller zu erhalten, ohne auf den Kernel zuzugreifen. In diesem Fall wäre eine Erhöhung der CPU-Belastung nur nominal, hatte jedoch keinerlei Auswirkungen auf die Leistung, da die Kernel andere Aufgaben ausführen. Die Tests zeigten jedoch einen Leistungsabfall bei Operationen mit fast einem Thread, bei denen ein Thread der Arbeitswarteschlange etwas hinzufügt, während der Arbeitsthread ein Ergebnis erwartet und dann eine bestimmte Aufgabe mit dem Arbeitselement ausführt.
Der Grund ist am einfachsten im Diagramm zu zeigen. Der gegnerische Spin tritt bei jedem Schritt mit einer Verdreifachung des Spinnens auf. Nach jeder Runde wird die Sperre erneut überprüft, um festzustellen, ob der aktuelle Thread sie empfangen kann. Obwohl das Spinnen versucht, ehrlich zu sein und von Zeit zu Zeit zu anderen Themen wechselt, um ihnen zu helfen, ihre Arbeit abzuschließen. Dies erhöht die Wahrscheinlichkeit, dass die Sperre bei der nächsten Prüfung aufgehoben wird. Das Problem ist, dass eine Überprüfung auf einen Take nur am Ende einer vollständigen Spinrunde möglich ist:

Wenn beispielsweise zu Beginn der fünften Runde eine Sperre die Verfügbarkeit signalisiert, können Sie diese erst am Ende der Runde ausführen. Nachdem wir die Schleuderdauer der letzten Runde berechnet haben, können wir den schlimmsten Verzögerungsfall für unseren Fluss abschätzen:

Viele Millisekunden warten, bis das Drehen endet. Ist das ein echtes Problem?
Ich habe eine einfache Testanwendung erstellt, die eine Warteschlange von Verbraucherherstellern implementiert, in der der Workflow jedes Arbeitselement 10 ms lang ausführt und der Verbraucher eine Verzögerung von 1 bis 9 ms vor dem nächsten Arbeitselement hat. Dies reicht aus, um den Effekt zu sehen:
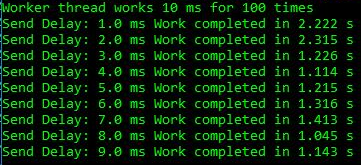
Bei Verzögerungen von 1-2 ms beträgt die Gesamtdauer 2,2-2,3 s, während in anderen Fällen die Arbeit bis zu 1,2 s schneller ist. Dies zeigt, dass übermäßiges Drehen der CPU nicht nur ein kosmetisches Problem in Anwendungen mit Über-Threading ist. Es schadet wirklich dem einfachen Threading des Produzenten-Konsumenten, das nur zwei Threads enthält. Für den obigen Lauf sprechen die ETW-Daten für sich selbst: Es ist die Zunahme des Spinnens, die die beobachtete Verzögerung verursacht:
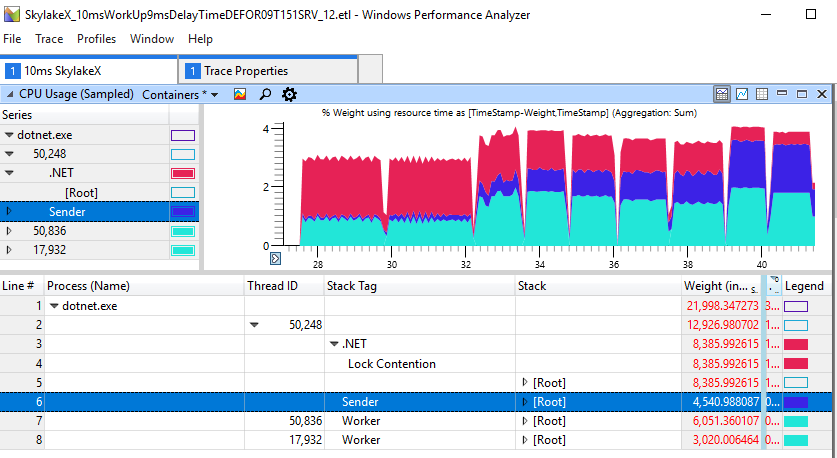
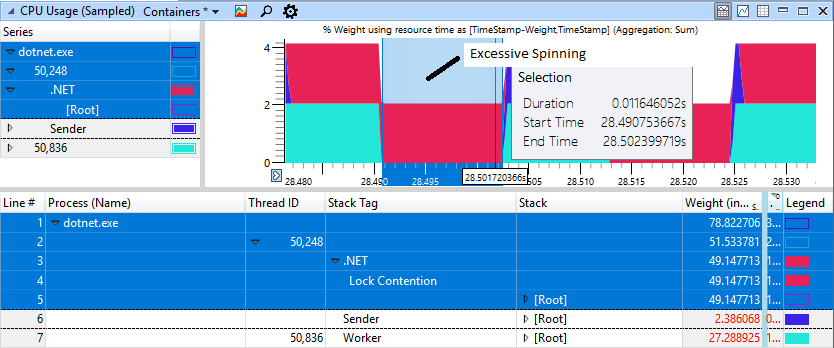
Wenn Sie sich den Abschnitt mit „Bremsen“ genau ansehen, werden sich im roten Bereich 11 ms drehen, obwohl der Arbeiter (hellblau) seine Arbeit beendet und das Schloss vor langer Zeit gegeben hat.
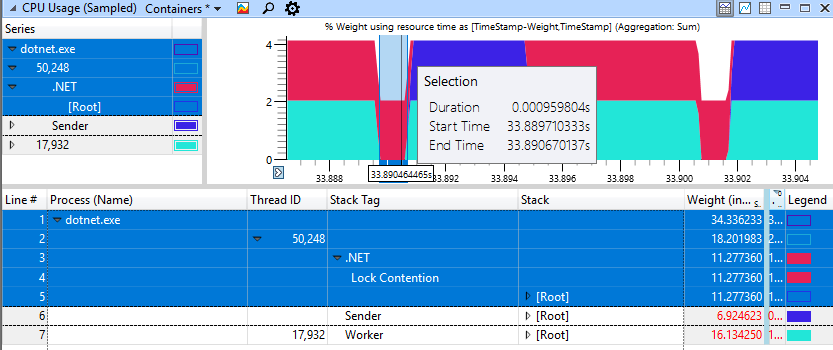
Ein schneller nicht-degenerativer Fall sieht viel besser aus, hier wird nur 1 ms für das Drehen zum Blockieren aufgewendet.
Ich habe die
Testanwendung SkylakeXPause verwendet . Das
Zip-Archiv enthält Quellcode und Binärdateien für .NET Core und .NET 4.5. Zum Vergleich habe ich .NET 4.8 Preview mit Fixes und .NET Core 2.0 installiert, das immer noch das alte Verhalten implementiert. Die Anwendung wurde für .NET Standard 2.0 und .NET 4.5 entwickelt und erzeugt sowohl exe als auch dll. Jetzt können Sie das alte und das neue Spinnverhalten nebeneinander überprüfen, ohne etwas reparieren zu müssen. Dies ist sehr praktisch.
readonly object _LockObject = new object(); int WorkItems; int CompletedWorkItems; Barrier SyncPoint; void RunSlowTest() { const int processingTimeinMs = 10; const int WorkItemsToSend = 100; Console.WriteLine($"Worker thread works {processingTimeinMs} ms for {WorkItemsToSend} times"); // Test one sender one receiver thread with different timings when the sender wakes up again // to send the next work item // synchronize worker and sender. Ensure that worker starts first double[] sendDelayTimes = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; foreach (var sendDelay in sendDelayTimes) { SyncPoint = new Barrier(2); // one sender one receiver var sw = Stopwatch.StartNew(); Parallel.Invoke(() => Sender(workItems: WorkItemsToSend, delayInMs: sendDelay), () => Worker(maxWorkItemsToWork: WorkItemsToSend, workItemProcessTimeInMs: processingTimeinMs)); sw.Stop(); Console.WriteLine($"Send Delay: {sendDelay:F1} ms Work completed in {sw.Elapsed.TotalSeconds:F3} s"); Thread.Sleep(100); // show some gap in ETW data so we can differentiate the test runs } } /// <summary> /// Simulate a worker thread which consumes CPU which is triggered by the Sender thread /// </summary> void Worker(int maxWorkItemsToWork, double workItemProcessTimeInMs) { SyncPoint.SignalAndWait(); while (CompletedWorkItems != maxWorkItemsToWork) { lock (_LockObject) { if (WorkItems == 0) { Monitor.Wait(_LockObject); // wait for work } for (int i = 0; i < WorkItems; i++) { CompletedWorkItems++; SimulateWork(workItemProcessTimeInMs); // consume CPU under this lock } WorkItems = 0; } } } /// <summary> /// Insert work for the Worker thread under a lock and wake up the worker thread n times /// </summary> void Sender(int workItems, double delayInMs) { CompletedWorkItems = 0; // delete previous work SyncPoint.SignalAndWait(); for (int i = 0; i < workItems; i++) { lock (_LockObject) { WorkItems++; Monitor.PulseAll(_LockObject); } SimulateWork(delayInMs); } }
Schlussfolgerungen
Dies ist kein .NET-Problem. Alle Spinlock-Implementierungen, die die pause-Anweisung verwenden, sind betroffen. Ich habe den Kern von Windows Server 2016 schnell überprüft, aber es gibt kein solches Problem an der Oberfläche. Es scheint, dass Intel so freundlich war - und angedeutet hat, dass einige Änderungen in der Herangehensweise an das Spinnen erforderlich sind.
Ein Fehler für .NET Core wurde im August 2017 gemeldet, und im September 2017 wurden
ein Patch und eine Version von .NET Core 2.0.3 veröffentlicht. Der Link zeigt nicht nur die hervorragende Reaktion der .NET Core-Gruppe, sondern auch die Tatsache, dass das Problem vor einigen Tagen im Hauptzweig behoben wurde, sowie eine Diskussion über zusätzliche Spinning-Optimierungen. Leider bewegt sich Desktop .NET Framework nicht so schnell, aber angesichts der Vorschau von .NET Framework 4.8 haben wir zumindest konzeptionelle Beweise dafür, dass die dortigen Fixes auch implementierbar sind. Jetzt warte ich darauf, dass der Backport für .NET 4.7.2 .NET mit voller Geschwindigkeit und auf der letzten Hardware verwendet. Dies ist der erste Fehler, den ich gefunden habe und der direkt mit Leistungsänderungen aufgrund eines CPU-Befehls zusammenhängt. ETW bleibt der Hauptprofiler in Windows. Wenn ich könnte, würde ich Microsoft bitten, die ETW-Infrastruktur auf Linux zu portieren, da aktuelle Linux-Profiler immer noch Mist sind. Sie haben kürzlich interessante Kernelfunktionen hinzugefügt, aber es gibt noch keine Analysetools wie WPA.
Wenn Sie mit .NET Core 2.0 oder dem Desktop .NET Framework auf den neuesten Prozessoren arbeiten, die seit Mitte 2017 veröffentlicht wurden, sollten Sie bei Problemen mit Leistungseinbußen Ihre Anwendungen auf jeden Fall mit einem Profiler überprüfen - und auf .NET Core und hoffentlich bald auf aktualisieren .NET Desktop Meine Testanwendung informiert Sie über das Vorhandensein oder Fehlen eines Problems.
D:\SkylakeXPause\bin\Release\netcoreapp2.0>dotnet SkylakeXPause.dll -check
Did call pause 1,000,000 in 3.5990 ms, Processors: 8
No SkylakeX problem detectedoder
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1,000,000 in 3.6195 ms, Processors: 8
No SkylakeX problem detectedDas Tool meldet ein Problem, wenn Sie an .NET Framework ohne das entsprechende Update und am Skylake-Prozessor arbeiten.
Ich hoffe, Sie fanden die Untersuchung dieses Problems genauso spannend wie ich. Um das Problem wirklich zu verstehen, müssen Sie ein Mittel zur Reproduktion erstellen, mit dem Sie experimentieren und nach Einflussfaktoren suchen können. Der Rest ist nur langweilige Arbeit, aber jetzt kann ich die Ursachen und Folgen eines zyklischen Versuchs, die CPU zu sperren, viel besser verstehen.