
Im März kämpfte unser Entwicklungsteam mit dem stolzen Namen "Hands-Auki" zwei Tage lang aufmerksam auf den digitalen Feldern des Hackathons AI.HACK. Insgesamt wurden fünf Aufgaben von verschiedenen Unternehmen vorgeschlagen. Wir haben uns auf die Aufgabe von Gazpromneft konzentriert: die Prognose der Kraftstoffnachfrage von B2B-Kunden. Anonymisierten Daten zufolge war es notwendig zu lernen, wie man vorhersagt, wie viel ein bestimmter Kunde in Zukunft kaufen wird, je nach Kraftstoffeinkaufsregion, Kraftstoffnummer, Kraftstoffart, Preis, Datum und Kunden-ID. Mit Blick auf die Zukunft hat unser Team dieses Problem mit höchster Genauigkeit gelöst. Die Kunden wurden in drei Segmente unterteilt: groß, mittel und klein. Zusätzlich zur Hauptaufgabe haben wir für jedes Segment eine Prognose des Gesamtverbrauchs erstellt.
Das Entladen enthielt Daten zu Kundenkäufen für den Zeitraum von November 2016 bis 15. März 2018 (für den Zeitraum vom 1. Januar 2018 bis 15. März 2018 enthielten die Daten KEINE Mengen).
Beispieldaten:
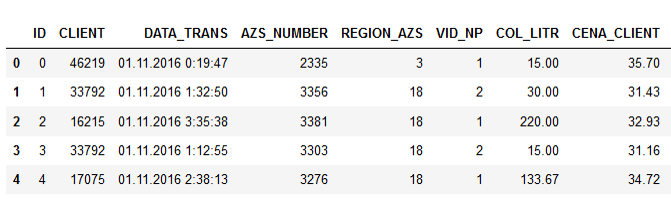
Die Namen der Spalten sprechen für sich, ich denke, es macht keinen Sinn zu erklären.
Zusätzlich zur Schulungsprobe stellten die Organisatoren eine Testprobe für drei Monate dieses Jahres zur Verfügung. Die Preise gelten für Firmenkunden unter Berücksichtigung spezifischer Rabatte, die vom Verbrauch eines bestimmten Kunden, von Sonderangeboten und anderen Punkten abhängen.
Nachdem wir die ersten Daten erhalten hatten, begannen wir, wie alle anderen auch, die klassischen Methoden des maschinellen Lernens auszuprobieren und ein geeignetes Modell zu erstellen, um die Korrelation einiger Zeichen zu erkennen. Wir haben versucht, zusätzliche Funktionen zu extrahieren und Regressionsmodelle (XGBoost, CatBoost usw.) zu erstellen.
Die Erklärung des Problems selbst implizierte zunächst, dass der Kraftstoffpreis die Nachfrage irgendwie beeinflusst, und es ist notwendig, diese Abhängigkeit genauer zu verstehen. Als wir jedoch mit der Analyse der bereitgestellten Daten begannen, stellten wir fest, dass die Nachfrage nicht mit dem Preis korreliert.

Vorzeichenkorrelation:
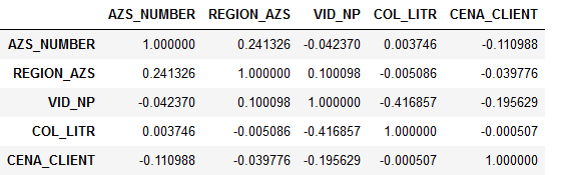
Es stellte sich heraus, dass die Anzahl der Liter praktisch nicht vom Preis abhängt. Dies wurde ganz logisch erklärt. Der Fahrer fährt auf der Autobahn, er muss tanken. Er hat die Wahl: Entweder tankt er an einer Tankstelle, mit der das Unternehmen zusammenarbeitet, oder an einer anderen. Dem Fahrer ist es jedoch egal, wie viel der Kraftstoff kostet - die Organisation zahlt dafür. Deshalb schaltet er einfach zur nächsten Tankstelle ab und füllt den Tank.
Trotz aller Bemühungen und bewährter Modelle war es jedoch nicht möglich, die nach dieser Formel berechnete akzeptable Mindestprognosegenauigkeit (Basislinie) zu erreichen (symmetrischer mittlerer absoluter prozentualer Fehler):
Wir haben alle Optionen ausprobiert, nichts hat funktioniert. Und dann kam einem von uns der Gedanke, auf maschinelles Lernen zu spucken und sich den guten alten Statistiken zuzuwenden: Nehmen Sie einfach den Durchschnittswert für die Kraftstoffart, validieren Sie und sehen Sie, welche Genauigkeit Sie erhalten.
Also haben wir zuerst den Schwellenwert überschritten.
Wir begannen zu überlegen, wie wir das Ergebnis verbessern könnten. Wir haben versucht, Medianwerte nach Kundengruppen, Kraftstoffarten, Regionen und Tankstellennummern zu ermitteln. Das Problem war, dass in den Testdaten etwa 30% der Kunden-IDs in der Trainingsstichprobe fehlten. Das heißt, neue Kunden erschienen im Test. Dies war ein Fehler, den die Organisatoren nicht überprüft haben. Aber wir mussten das Problem selbst lösen. Wir kannten den Verbrauch neuer Kunden nicht und konnten daher keine Prognosen für sie erstellen. Und hier hat maschinelles Lernen einfach geholfen.
In der ersten Phase wurden die fehlenden Daten mit dem Durchschnitts- oder Medianwert für die gesamte Stichprobe gefüllt. Und dann kam die Idee: Warum nicht neue Kundenprofile basierend auf vorhandenen Daten erstellen? Wir haben Kürzungen nach Regionen, wie viele Kunden dort Kraftstoff kaufen, mit welcher Häufigkeit, welchen Typen. Wir haben bestehende Kunden gruppiert, spezifische Profile für verschiedene Regionen erstellt und XGBoost darauf geschult, um dann die Profile neuer Kunden zu „vervollständigen“.
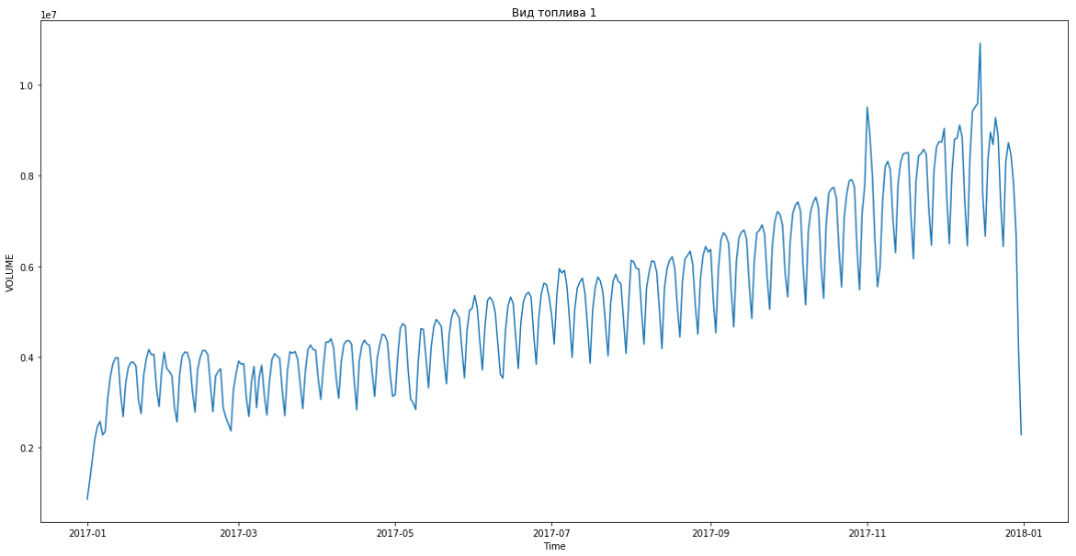
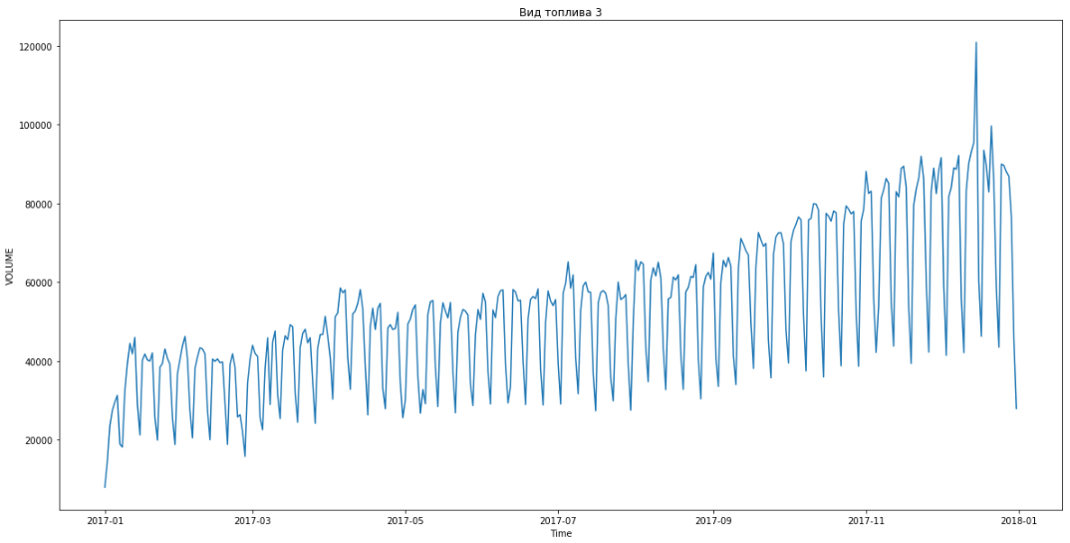
Dies ermöglichte es uns, den ersten Platz einzunehmen. Es blieben noch drei Stunden, bis die Ergebnisse zusammengefasst wurden. Wir waren begeistert und begannen, das Bonusproblem zu lösen - Prognosen nach Segmenten für drei Monate im Voraus.
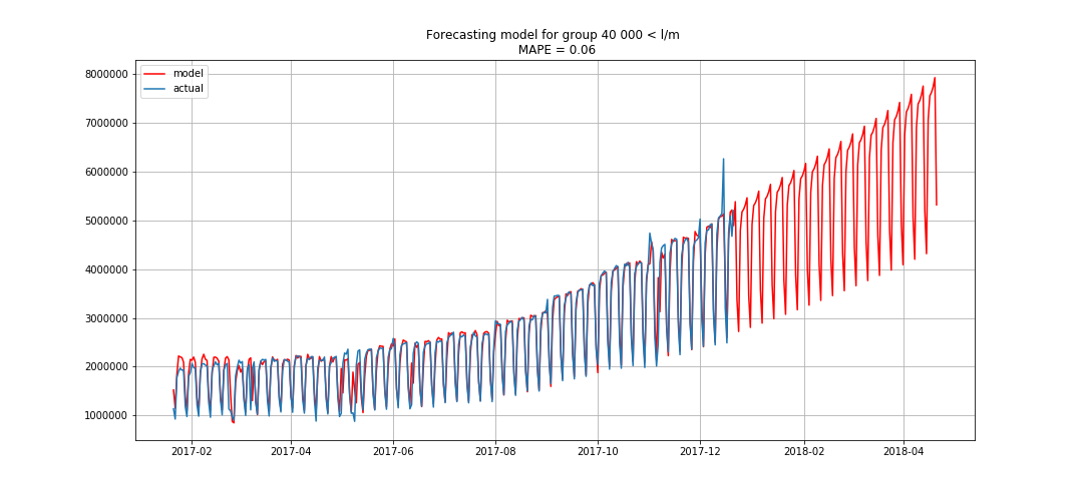
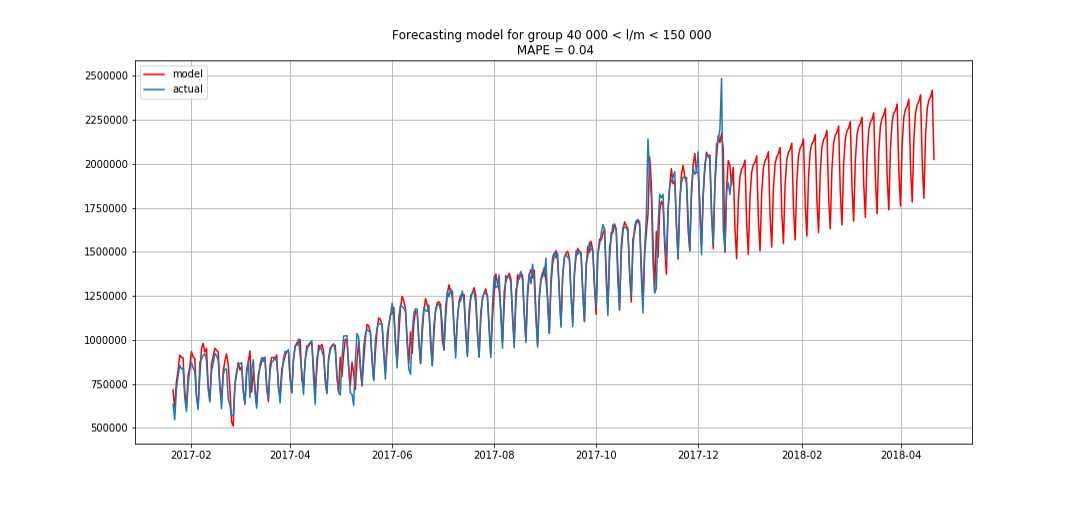
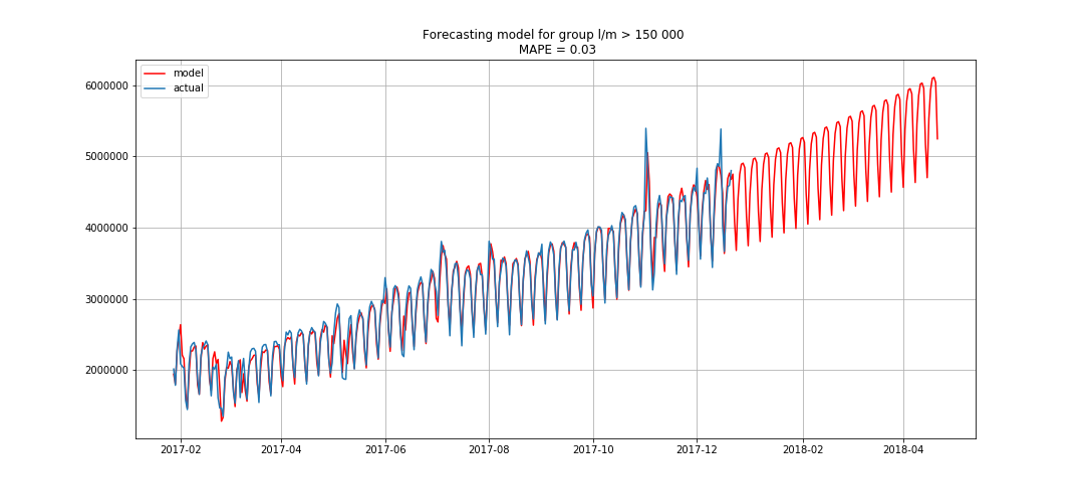
Blau zeigt reale Daten, Rot - Prognose. Der Fehler lag zwischen 3% und 6%. Könnte noch genauer berechnet werden, zum Beispiel unter Berücksichtigung von saisonalen Spitzen und Feiertagen.
Während wir dies taten, holte uns ein Team ein und verbesserte unser Ergebnis alle 15 bis 20 Minuten. Auch wir begannen uns aufzuregen und beschlossen, etwas zu tun, falls sie uns einholen sollten.
Parallel dazu wurde ein anderes Modell erstellt, bei dem die Statistiken nach Signifikanzgrad geordnet wurden. Die Genauigkeit war geringfügig geringer als die des ersten. Und als die Konkurrenz uns schlug, haben wir versucht, beide Modelle zu kombinieren. Dies führte zu einem leichten Anstieg der Metrik - bis zu 37,24671%. Infolgedessen haben wir unseren ersten Platz wiedererlangt und ihn bis zum Ende beibehalten.
Für den Sieg erhielt unser Ruki-Auki-Team eine Urkunde über 100.000 Rubel, Ehre, Respekt und ... voller Selbstachtung ging ich ins Spa! ;)
Entwicklungsteam von Jet Infosystems