Hinweis perev. : Dieser kleine (aber umfangreiche!) Artikel von Michael Hausenblas vom OpenShift-Team von Red Hat hat uns so gut gefallen, dass er fast unmittelbar nach seiner Entdeckung in unsere interne Wissensbasis von Kubernetes aufgenommen wurde. Und da die darin enthaltenen Informationen offensichtlich für die breitere russischsprachige IT-Community nützlich sein werden, freuen wir uns, die Übersetzung zu veröffentlichen.
Wie Sie vielleicht vermutet haben, bezieht sich der Titel dieser Veröffentlichung auf den Pixar-Cartoon „A Bug's Life“ von 1998
(in der russischen Abendkasse hieß er „Adventures of Flick“ oder „The Life of a Insect“ - ca. übersetzt). Kubernetes hat viel mit Arbeitern und Herden gemeinsam. Wir werden den gesamten Lebenszyklus des Herdes aus praktischer Sicht sorgfältig betrachten - insbesondere die Art und Weise, wie Sie das Verhalten beim Starten und Herunterfahren beeinflussen können, sowie die richtigen Ansätze zur Überprüfung des Status der Anwendung.
Unabhängig davon, ob Sie unter sich selbst oder besser über einen Controller wie
Deployment ,
DaemonSet oder
StatefulSet erstellt haben , kann sich under in einer der folgenden Phasen befinden:
- Ausstehend : Der API-Server hat eine Pod-Ressource erstellt und in etcd gespeichert. Diese war jedoch noch nicht geplant, und die Images seiner Container wurden nicht von der Registrierung empfangen.
- Running (funktionsfähig): under wurde dem Knoten zugewiesen und alle Container wurden von kubelet erstellt .
- Erfolgreich (erfolgreich abgeschlossen): Der Betrieb aller Herdcontainer wurde erfolgreich abgeschlossen und sie werden nicht neu gestartet.
- Fehlgeschlagen : Alle Container im Kamin funktionieren nicht mehr und mindestens einer der Container ist ausgefallen.
- Unbekannt : API Server konnte den Status des Herdes nicht abfragen, normalerweise aufgrund eines Fehlers bei der Interaktion mit Kubelet .
kubectl get pod beim Ausführen von
kubectl get pod , dass in der Spalte
STATUS andere (außer diesen fünf) Nachrichten
CrashLoopBackOff . B.
Init:0/1 oder
CrashLoopBackOff . Dies liegt daran, dass die Phase nur ein Teil des allgemeinen Zustands des Herdes ist. Eine gute Möglichkeit, um herauszufinden, was genau passiert ist, besteht darin,
kubectl describe pod/$PODNAME und den
kubectl describe pod/$PODNAME Events: unten. Sie zeigt eine Liste relevanter Aktionen an: Das Container-Image wurde empfangen, es war geplant, der Container befindet sich in einem „
ungesunden“ Zustand.
Schauen Sie sich nun ein konkretes Beispiel für den Lebenszyklus eines Herdes von Anfang bis Ende an, wie in der folgenden Abbildung dargestellt:
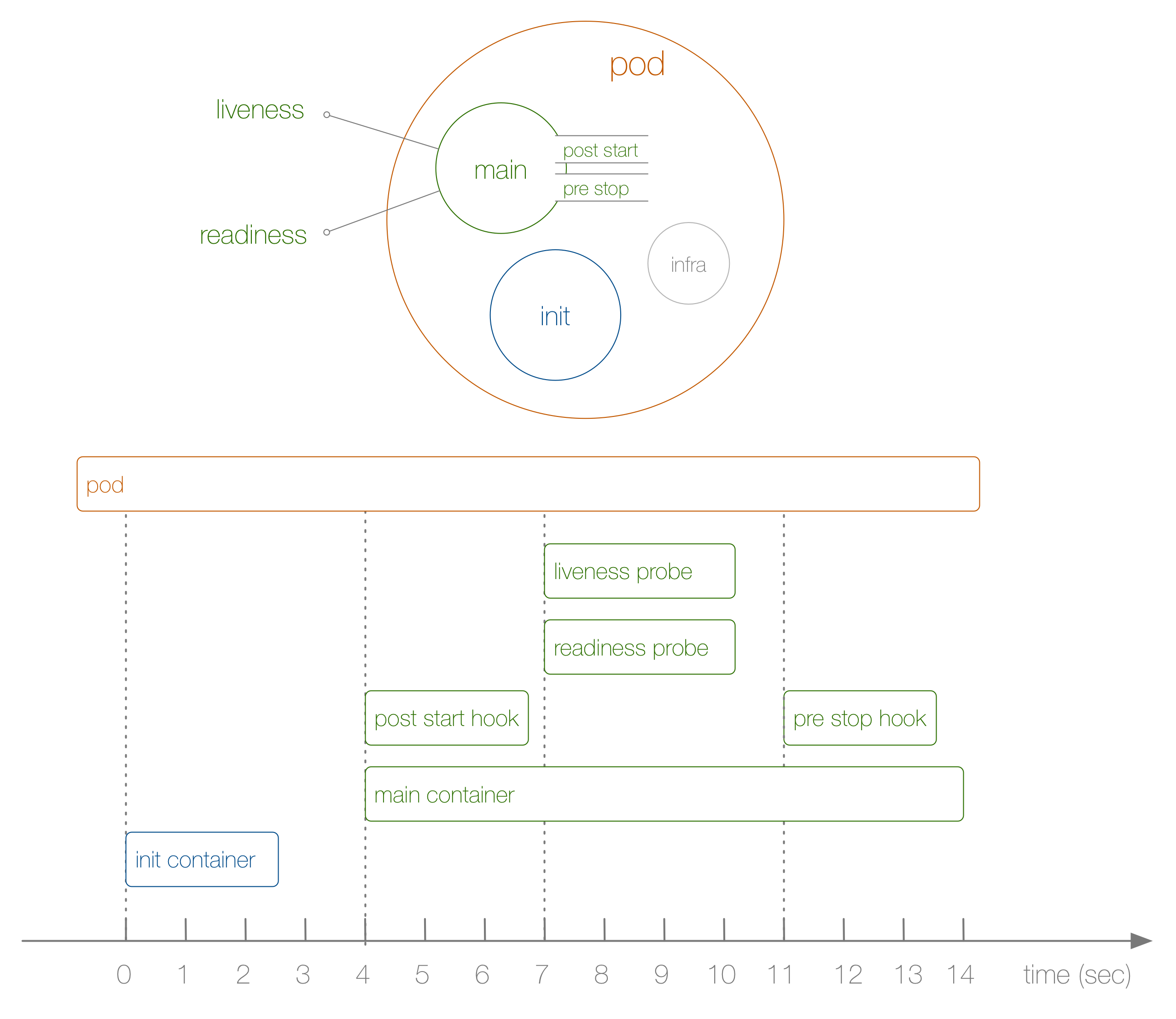
Was ist hier passiert? Die Schritte sind wie folgt:
- Dies ist im Diagramm nicht dargestellt, aber zu Beginn wird ein spezieller Infra-Container gestartet, der die Namespaces einrichtet, mit denen die verbleibenden Container verbunden sind.
- Der erste benutzerdefinierte Container, der gestartet wird , ist der Init-Container . Es kann für Initialisierungsaufgaben verwendet werden.
- Als nächstes werden der Hauptcontainer und der Post-Start- Haken gleichzeitig gestartet; In unserem Fall geschieht dies nach 4 Sekunden. Für jeden Container werden Haken definiert.
- In der 7. Sekunde kommen dann wieder Lebendigkeits- und Bereitschaftstests für jeden Container ins Spiel.
- In der 11. Sekunde, wenn under getötet wird, wird ein Pre-Stop- Hook ausgelöst und der Hauptcontainer wird nach einer Nachfrist getötet. Bitte beachten Sie, dass der Prozess der Pod-Fertigstellung in der Realität etwas komplizierter ist.
Wie bin ich zu der obigen Sequenz und ihrem Timing gekommen? Zu diesem
Zweck haben wir die folgende
Bereitstellung verwendet , die speziell zum Verfolgen der Reihenfolge von Ereignissen erstellt wurde (sie ist an sich nicht sehr nützlich):
kind: Deployment apiVersion: apps/v1beta1 metadata: name: loap spec: replicas: 1 template: metadata: labels: app: loap spec: initContainers: - name: init image: busybox command: ['sh', '-c', 'echo $(date +%s): INIT >> /loap/timing'] volumeMounts: - mountPath: /loap name: timing containers: - name: main image: busybox command: ['sh', '-c', 'echo $(date +%s): START >> /loap/timing; sleep 10; echo $(date +%s): END >> /loap/timing;'] volumeMounts: - mountPath: /loap name: timing livenessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): LIVENESS >> /loap/timing'] readinessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): READINESS >> /loap/timing'] lifecycle: postStart: exec: command: ['sh', '-c', 'echo $(date +%s): POST-START >> /loap/timing'] preStop: exec: command: ['sh', '-c', 'echo $(date +%s): PRE-HOOK >> /loap/timing'] volumes: - name: timing hostPath: path: /tmp/loap
Beachten Sie, dass ich den folgenden Befehl ausgeführt habe, um den Pod während des Betriebs des Hauptcontainers zwangsweise herunterzufahren:
$ kubectl scale deployment loap --replicas=0
Wir haben uns eine bestimmte Abfolge von Ereignissen in Aktion angesehen und sind nun bereit, mit den Praktiken im Bereich des Lebenszyklusmanagements von Herden fortzufahren. Sie sind wie folgt:
- Verwenden Sie Init-Behälter, um den Herd für den normalen Betrieb vorzubereiten. Um beispielsweise externe Daten abzurufen, Tabellen in der Datenbank zu erstellen oder auf die Verfügbarkeit des Dienstes zu warten, von dem er abhängt. Bei Bedarf können Sie viele Init-Container erstellen, die alle erfolgreich abgeschlossen werden müssen, bevor reguläre Container gestartet werden.
livenessProbe immer livenessProbe und readinessProbe . Das erste wird von kubelet 'Ohm verwendet, um zu verstehen, ob und wann der Container neu gestartet werden muss , und das Bereitstellungs -Ohm, um zu entscheiden, ob das fortlaufende Update erfolgreich war. Der zweite wird vom Dienst verwendet , um die Richtung des Verkehrs zum U- Boot zu bestimmen. Wenn diese Proben nicht definiert sind, geht Kubelet für beide davon aus, dass sie erfolgreich abgeschlossen wurden. Dies führt zu zwei Konsequenzen: a) Die Neustartrichtlinie kann nicht angewendet werden. B) Die Container im Herd empfangen sofort Datenverkehr von dem Dienst, mit dem sie konfrontiert sind, und selbst wenn sie noch mit dem Startvorgang beschäftigt sind.- Verwenden Sie Haken, um den Container ordnungsgemäß zu initialisieren und vollständig zu zerstören. Dies ist beispielsweise nützlich, wenn eine Anwendung funktioniert, auf deren Quellcode Sie keinen Zugriff haben oder die Sie nicht ändern können, die jedoch eine Initialisierung oder Vorbereitung für den Abschluss erfordert, z. B. das Löschen von Datenbankverbindungen. Beachten Sie, dass das Herunterfahren des API-Servers, des Endpoint-Controllers und des Kube-Proxys bei Verwendung des Dienstes einige Zeit dauern kann (z. B. Löschen der entsprechenden Einträge aus iptables). Das Beenden Ihrer Arbeit unter kann sich daher auf Anwendungsanfragen auswirken. Um dieses Problem zu lösen, reicht häufig ein einfacher Hook mit einem Sleep-Anruf aus.
- Zum Debuggen und zum allgemeinen Verständnis, warum es nicht mehr funktioniert, kann die Anwendung in
/dev/termination-log schreiben und Sie können Nachrichten mit kubectl describe pod … Diese Standardeinstellungen werden über terminationMessagePath und / oder über terminationMessagePolicy in der Unterspezifikation geändert. Weitere Informationen finden Sie in der API-Referenz .
In dieser Veröffentlichung werden
Initialisierer nicht behandelt (einige Details dazu finden Sie am Ende dieses Materials - ca. übersetzt ) . Dies ist ein völlig neues Konzept, das in Kubernetes 1.7 eingeführt wurde. Initialisierer arbeiten innerhalb der
Steuerebene (API-Server), anstatt sich im
Kubelet- Kontext zu befinden, und können verwendet werden, um die Herde beispielsweise mit Beiwagencontainern oder der Durchsetzung von Sicherheitsrichtlinien anzureichern. Darüber hinaus wurden
PodPresets nicht berücksichtigt, was in Zukunft durch ein flexibleres Konzept von Initialisierern ersetzt werden kann.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: