Zuletzt haben wir einen Datenwissenschaftler im Team gesucht (und gefunden - hallo,
nik_son und Arseny!). Während des Gesprächs mit den Kandidaten haben wir festgestellt, dass viele Menschen ihren Job wechseln möchten, weil sie etwas „am Tisch“ tun.
Zum Beispiel übernehmen sie die komplexe Prognose, die der Leiter vorgeschlagen hat, aber das Projekt stoppt, weil das Unternehmen nicht versteht, was und wie es in die Produktion einbezogen werden soll, wie man Gewinne erzielt und wie man die für das neue Modell aufgewendeten Ressourcen „zurückerobert“.

HeadHunter hat keine große Rechenleistung wie Yandex oder Google. Wir verstehen, wie schwierig es ist, komplexe ML in die Produktion zu bringen. Viele Unternehmen gehen daher auf die Tatsache ein, dass die einfachsten linearen Modelle in die Produktion übernommen werden.
Bei der nächsten Implementierung von ML im Empfehlungssystem und bei der Suche nach offenen Stellen stießen wir auf eine Reihe klassischer "Rechen". Achten Sie auf sie, wenn Sie ML zu Hause implementieren möchten: Vielleicht hilft Ihnen diese Liste, nicht auf sie
zuzugreifen und Ihren eigenen, persönlichen Rechen zu finden .
Rechen Nr. 1: Data Scientist - Freier Künstler
In jedem Unternehmen, das damit beginnt, maschinelles Lernen, einschließlich neuronaler Netze, in seine Arbeit einzuführen, besteht eine Lücke zwischen dem, was der Datenwissenschaftler tun möchte, und dem, was der Produktion zugute kommt. Einschließlich, weil das Unternehmen nicht immer erklären kann, was Nutzen ist und wie er helfen kann.
Wir gehen folgendermaßen damit um: Wir diskutieren alle aufkommenden Ideen, setzen aber nur um, was dem Unternehmen zugute kommt - jetzt oder in Zukunft. Wir forschen nicht im luftleeren Raum.
Nach jeder Implementierung oder jedem Experiment berücksichtigen wir die Qualität, die Ressourcen und die wirtschaftlichen Auswirkungen und aktualisieren unsere Pläne.
Rechen Nummer 2: Aktualisieren von Bibliotheken
Dieses Problem tritt bei vielen auf. Es erscheinen viele neue und praktische Bibliotheken, von denen vor ein paar Jahren noch niemand oder gar nichts gehört hat. Ich möchte die neuesten Bibliotheken verwenden, weil sie bequemer sind.
Es gibt jedoch mehrere Hindernisse:
1. Wenn das Produkt beispielsweise das 14. Ubuntu verwendet, befinden sich höchstwahrscheinlich einfach keine neuen Bibliotheken darin. Die Lösung besteht darin, den Dienst an Docker zu übertragen und die Python-Bibliotheken mithilfe von pip (anstelle von Deb-Paketen) zu installieren.
2. Wenn ein codeabhängiges Format für die Datenspeicherung verwendet wird (z. B. pickle), werden die verwendeten Bibliotheken eingefroren. Das heißt, wenn das maschinelle Lernmodell unter Verwendung der Scikit-Learn-Bibliothek der Version 15 erhalten und im Pickle-Format gespeichert wurde, wird für die korrekte Modellwiederherstellung die Scikit-Learn-Bibliothek der Version 15 benötigt. Sie können nicht auf die neueste Version aktualisieren, und dies ist eine viel heimtückischere Falle als in Absatz 1 beschrieben.
Es gibt zwei Möglichkeiten:
- Verwenden Sie zum Speichern von Modellen ein codeunabhängiges Format
- immer in der Lage sein, jedes Modell neu zu trainieren. Wenn Sie dann die Bibliothek aktualisieren, müssen Sie alle Modelle trainieren und mit der neuen Version der Bibliothek speichern.
Wir haben den zweiten Weg gewählt.
Rechen Nummer 3: Arbeiten Sie mit alten Modellen
In einem alten, erlernten Modell etwas Neues zu tun, ist weniger nützlich als in einem neuen Modell etwas Einfaches zu tun. Am Ende stellt sich oft heraus, dass die Einführung einfacherer, aber frischerer Modelle nützlicher ist und der Aufwand geringer ist. Es ist wichtig, sich daran zu erinnern und immer den Umfang der gemeinsamen Anstrengungen bei der Suche nach Mustern zu berücksichtigen.
Rechen Nummer 4: nur lokale Experimente
Viele Data Science-Experten experimentieren gerne lokal auf ihren Servern für maschinelles Lernen. Nur die Produkte haben keine solche Flexibilität: Infolgedessen werden eine Reihe von Gründen aufgedeckt, aus denen es unmöglich ist, diese Experimente in die Produktion zu ziehen.
Es ist wichtig, die Kommunikation zwischen dem DS-Spezialisten und den Vertriebsingenieuren für ein gemeinsames Verständnis zu konfigurieren - wie dieses oder jenes Modell in der Produktion funktioniert, ob die erforderliche Leistung und physische Fähigkeit zur Einführung vorhanden sind. Je komplexer die Modelle und Faktoren sind, desto schwieriger ist es außerdem, sie zuverlässig zu machen und sie jederzeit wieder trainieren zu können. Im Gegensatz zu Kaggle-Wettbewerben ist es in der Produktion oft besser, Zehntausendstel auf lokale Metriken und sogar einen kleinen Online-KPI zu verzichten, aber die Implementierung der Modellversion ist viel einfacher, ergebnisstabiler und einfacher in Bezug auf Rechenressourcen.
Miteigentum am Code (Entwickler und Datenwissenschaftler wissen, wie der von anderen Entwicklern geschriebene Code funktioniert), Wiederverwendung von Zeichen und Metaattributen in verschiedenen Modellen sowohl im Lernprozess als auch bei der Arbeit mit Produkten (wir werden von unterstützt us Framework), Unit- und Autotests, die wir sehr oft fahren, Code-Integration mit Retesting. Wir legen die endgültigen Modelle in Git-Repositories und verwenden sie auch in der Produktion.
Rechen Nummer 5: Nur Produkt testen
Jeder unserer Entwickler und Datenwissenschaftler hat seinen eigenen Prüfstand, manchmal keinen. Die Hauptkomponenten der Produktion HH werden darauf bereitgestellt. Es ist teuer, zahlt sich aber für Qualität und Entwicklungsgeschwindigkeit aus. Es ist notwendig, aber nicht genug. Wir laden nicht nur die Modelle, die bereits in Produktion sind, sondern auch diejenigen, die bald dort sein werden. Dies hilft zu verstehen, dass Modelle, die für 5% der Benutzer perfekt auf lokalen Maschinen, Prüfständen oder in der Produktion funktionieren und bei 100% eingeschaltet sind, zu schwer sind.
Wir verwenden mehrere Teststufen. Wir überprüfen den Code sehr schnell (dies ist der entscheidende Punkt) - beim Hinzufügen oder Ändern von Komponenten im Repository wird der Code gesammelt, Einheiten- und Autotests werden für die entsprechenden Komponenten ausgeführt, bei Bedarf werden sie auch manuell erneut getestet - und wenn etwas nicht stimmt, geben Sie eine Antwort "Deiner ist kaputt, entscheide."
Rechen Nummer 6: lange Berechnungen und Fokusverlust
Wenn ein Modell beispielsweise eine Woche zum Trainieren benötigt, kann die Konzentration auf die Aufgabe leicht verloren gehen, da zu einem anderen Projekt gewechselt wird. Wir versuchen, Entwicklern und Datenwissenschaftlern nicht mehr als zwei Aufgaben in einer Hand zu geben. Und nicht mehr als eine Dringlichkeit, damit Sie darauf umschalten können, sobald Berechnungen oder A / B-Experimente dafür abgeschlossen sind. Diese Regel ist notwendig, um den Fokus nicht zu verlieren, und aus Angst, dass einige dieser Aufgaben im Allgemeinen Gefahr laufen, verloren zu gehen, und ein anderer Teil, der viel später als nötig eingeführt wird.
Wir traten auf einen Rechen, gaben aber nicht auf
Wir haben kürzlich ein Experiment zur Einführung neuronaler Netze in ein Empfehlungssystem abgeschlossen. Es begann mit der Tatsache, dass der interne Hackathon in zwei Tagen ein Modell für die Vorhersage von Antworten durch Lebenslauf schrieb, das die Suche nach geeigneten Stellen erheblich erleichterte.
Aber später haben wir gelernt: Um es in die Produktion zu bringen, müssen Sie fast alles aktualisieren - zum Beispiel das Dual-Use-System, das Zeichen berücksichtigt und Modelle lehrt, an Docker übertragen und Bibliotheken für maschinelles Lernen aktualisieren.
Wie war es
Wir haben das DSSM-Modell mit einem einschichtigen neuronalen Netzwerk verwendet. Im ursprünglichen Microsoft-Artikel wurde ein dreischichtiges neuronales Netzwerk verwendet, aber wir konnten keine Qualitätsverbesserungen mit zunehmender Anzahl von Schichten feststellen, sodass wir uns für eine Schicht entschieden haben.

Kurzum:
- Der Abfragetext und der Leerstellenkopf werden in zwei Symboltrigrammvektoren konvertiert. Wir verwenden Trigger mit 20.000 Zeichen.
- Der Trigrammvektor wird dem Eingang eines einschichtigen neuronalen Netzwerks zugeführt. Am Eingang der neuronalen Netzwerkschicht gibt es 20.000 Zahlen, am Ausgang 64. Im Wesentlichen ist das neuronale Netzwerk eine 20.000 x 64-Matrix, mit der der Eingangs-Trigrammvektor der Dimension 1 x 20 000 multipliziert wird. Ein konstanter Vektor der Dimension 1 x 64 wird zum Multiplikationsergebnis addiert Die Ausgabe eines solchen neuronalen Netzes entspricht der Anfrage (oder dem Titel der Vakanz).
- Das Skalarprodukt des Abfrage-Dssm-Vektors und des Leerstellen-Header-Dssm-Vektors wird berechnet. Die Sigmoid-Funktion wird auf die Arbeit angewendet. Das Endergebnis ist das dssm-Metazeichen.
Als wir versuchten, dieses Modell zum ersten Mal einzubeziehen, wurden die lokalen Metriken besser, aber als wir versuchten, es in den A / B-Test einzubeziehen, stellten wir fest, dass es keine Verbesserung gab.
Danach haben wir versucht, die zweite Schicht von Neuronen auf 256 zu erhöhen - eingeführt von 5% der Benutzer: Es stellte sich heraus, dass das Empfehlungssystem und die Suche besser wurden, aber als Sie das Modell zu 100% einschalteten, stellte sich plötzlich heraus, dass es zu schwer war.
Wir haben analysiert, warum das Modell so schwer ist, das Stemming entfernt und erneut mit diesem neuronalen Netzwerk experimentiert. Und erst danach, nachdem sie den ganzen Weg zurückgelegt hatten, stellten sie fest, dass das Modell nützlich ist: Die Anzahl der Antworten im Empfehlungssystem stieg um 700 pro Tag und bei der Suche nach allen Nachzählungen um 4200.
Die Einführung eines solchen nicht sehr komplexen neuronalen Netzwerks ermöglicht es unseren Kunden, täglich mehrere Dutzend zusätzliche Mitarbeiter über hh.ru einzustellen, und während der Implementierung haben wir einen erheblichen Teil der großen Probleme besiegt. Daher planen wir, unsere neuronalen Netze weiterzuentwickeln. Es ist geplant, allgemeines Stemming und zusätzliche Lemmatisierung zu versuchen, die Volltexte der offenen Stelle zu verarbeiten und wieder aufzunehmen, Experimente mit der Topologie durchzuführen (versteckte Schichten und möglicherweise RNN / LSTM).
Das Wichtigste, was wir mit diesem Modell gemacht haben:
- Lassen Sie das Experiment nicht in der Mitte fallen.
- Wir haben die Indikatoren für die Antwortsteigerung berechnet und festgestellt, dass sich die Arbeit an diesem Modell gelohnt hat. Es ist sehr wichtig zu verstehen, welchen Nutzen jede solche Implementierung bringt.
Interessanterweise ist das Modell, das wir erstellt und schließlich dem Produkt hinzugefügt haben, der auf die Matrix angewendeten Hauptkomponentenmethode (PCA) sehr ähnlich [Abfragetext, Dokumenttitel, ob es einen Klick gab]. Das heißt, zu einer Matrix, in der eine Zeile einer eindeutigen Abfrage entspricht, einer Spalte zu einem eindeutigen Leerstellenkopf; Der Wert in der Zelle ist 1, wenn der Benutzer nach dieser Anforderung auf eine freie Stelle mit dieser Überschrift geklickt hat, und 0, wenn kein Klick stattgefunden hat.
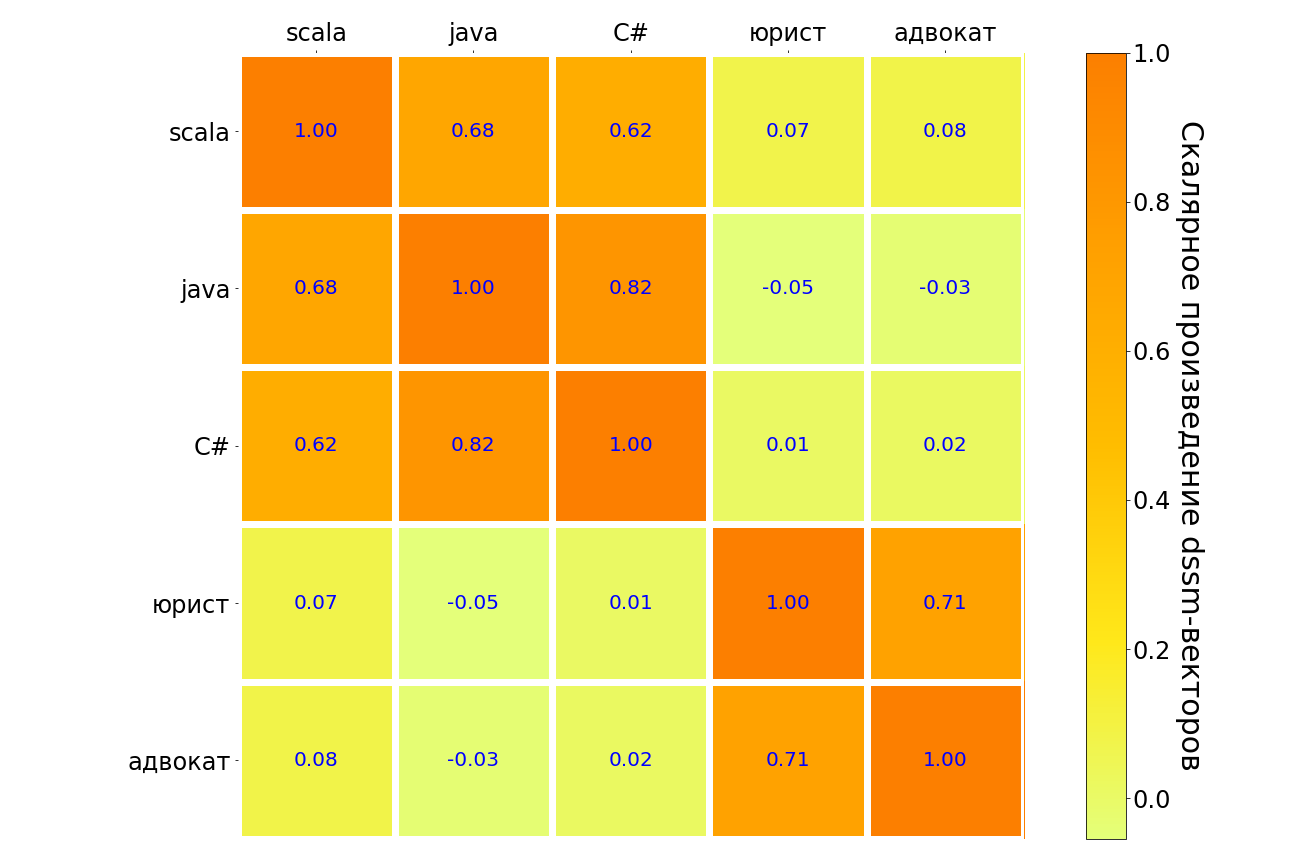
Die Ergebnisse der Anwendung dieses Modells auf Scala-, Java-, C # -, "Anwalt" - und "Anwalt" -Anfragen sind in der folgenden Tabelle aufgeführt. Ähnliche Bedeutungspaare werden im Gegensatz zu - hell - dunkel hervorgehoben. Es ist ersichtlich, dass das Modell die Verbindung zwischen verschiedenen Programmiersprachen versteht, es besteht eine starke Verbindung zwischen der Anfrage "Anwalt" und "Anwalt". Aber zwischen dem "Anwalt" und jeder Programmiersprache ist die Verbindung sehr schwach.
Irgendwann möchte ich wirklich aufgeben - die Experimente laufen, aber sie "entzünden" sich nicht. An diesem Punkt kann es für einen Datenwissenschaftler nützlich sein, das Team zu unterstützen und die Vorteile erneut zu berechnen: Es kann sich lohnen, die Stewardess zu begraben und nicht zu versuchen, das tote Pferd zu reiten. Dies ist kein Misserfolg, sondern ein erfolgreiches Experiment mit einem negativen Ergebnis. Oder nachdem Sie die Vor- und Nachteile abgewogen haben, führen Sie ein weiteres Experiment durch, das „schießt“. So ist es uns passiert.