Ende des Winters dieses Jahres fand der Wettbewerb Signal Processing Society - Camera Model Identification der IEEE statt. Ich habe als Mentor an diesem Teamwettbewerb teilgenommen. Über eine alternative Methode der Teambildung, Entscheidung und die zweite Phase unter dem Schnitt.
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
Erklärung des ProblemsAus dem Foto muss das Gerät bestimmt werden, auf dem dieses Foto aufgenommen wurde. Der Datensatz bestand aus Bildern von zehn Klassen: zwei iPhones, sieben Android-Smartphones und eine Kamera. Das Trainingsbeispiel enthielt 275 Bilder jeder Klasse in voller Größe. In der Testprobe wurde nur eine zentrale 512x512-Ernte präsentiert. Darüber hinaus wurde eine von drei Erweiterungen auf 50 Prozent von ihnen angewendet: JPG-Komprimierung, Größenänderung mit kubischer Interpolation oder Gammakorrektur. Es konnten externe Daten verwendet werden.
 Essenz (tm)
Essenz (tm)Wenn Sie versuchen, die Aufgabe in einfacher Sprache zu erklären, wird die Idee im folgenden Bild dargestellt. In der Regel wird modernen neuronalen Netzen beigebracht, Objekte auf einem Foto zu unterscheiden. d.h. Sie müssen lernen, Katzen von Hunden, Pornografie von Badeanzügen oder Panzer von Straßen zu unterscheiden. Gleichzeitig sollte es immer gleichgültig sein, wie und auf welchem Gerät ein Bild von einer Katze und einem Panzer aufgenommen wird.

Im selben Wettbewerb war alles genau umgekehrt. Unabhängig davon, was auf dem Foto gezeigt wird, müssen Sie den Gerätetyp bestimmen. Verwenden Sie also Matrixrauschen, Bildverarbeitungsartefakte, optische Defekte usw. Dies war die zentrale Herausforderung - einen Algorithmus zu entwickeln, der Merkmale von Bildern auf niedriger Ebene erfasst.
Teamwork-FunktionenDie überwiegende Mehrheit der Kaggle-Teams setzt sich wie folgt zusammen: Teilnehmer mit einem Beinahe-Vorsprung in der Rangliste werden zu einem Team zusammengefasst, während jeder von Anfang bis Ende seine Version der Lösung sägt. Ich habe einen
Beitrag über ein typisches Beispiel für eine solche Rede geschrieben. Diesmal sind wir jedoch den anderen Weg gegangen, nämlich: Wir haben die Teile der Entscheidung in Menschen aufgeteilt. Zusätzlich erhielten die drei besten Studententeams gemäß den Wettbewerbsregeln ein Ticket für die zweite Etappe nach Kanada. Als sich das Rückgrat sammelte, haben wir das Team unterbesetzt, um die Regeln einzuhalten.
LösungUm ein gutes Ergebnis bei dieser Aufgabe zu erzielen, musste das folgende Puzzle nach Prioritäten zusammengestellt werden:
- Externe Daten suchen und herunterladen. Dieser Wettbewerb durfte eine unbegrenzte Anzahl externer Daten verwenden. Und ziemlich schnell wurde klar, dass ein großer externer Datensatz schleppte.
- Externe Daten filtern. Menschen veröffentlichen manchmal verarbeitete Bilder, wodurch alle Funktionen des Geräts zerstört werden.
- Verwenden Sie ein zuverlässiges lokales Validierungsschema. Da selbst ein Modell eine Genauigkeit im Bereich von 0,98+ aufwies und im Test nur 2.000 Aufnahmen gemacht wurden, war die Auswahl des Kontrollpunkts des Modells eine separate Aufgabe
- Modelle trainieren. Eine sehr leistungsfähige Basislinie wurde im Forum veröffentlicht. Ohne eine Prise Magie erlaubte er jedoch nur Silber.
DatenerfassungDieser Teil wurde von
Arthur Fattakhov besetzt . Für diese Aufgabe war es recht einfach, externe Daten abzurufen. Dies sind nur Bilder von bestimmten Telefonmodellen. Arthur hat ein Python-Skript geschrieben, das die Bibliothek verwendet, um HTML-Seiten mit dem Namen
BeautifulSoup bequem zu analysieren. Aber zum Beispiel werden auf der Flickr-Albumseite Fotoblöcke dynamisch geladen, und um dies zu
umgehen , musste ich
Selen verwenden , das die Aktion des Browsers emuliert. Insgesamt wurden mehr als 500 GB Fotos von yandex.fotki, flickr, wiki commons heruntergeladen.
DatenfilterungDies war mein einziger Beitrag zur Lösung in Form von Code. Ich habe mir nur angesehen, wie die Rohfotos aussahen, und eine Reihe von Regeln aufgestellt: 1) Die für ein bestimmtes Modell typische Größe 2) Die JPG-Qualität liegt über dem Schwellenwert. 3) Das Vorhandensein der erforderlichen Meta-Tags der Modelle. 4) Die richtige Software, die verarbeitet wurde.
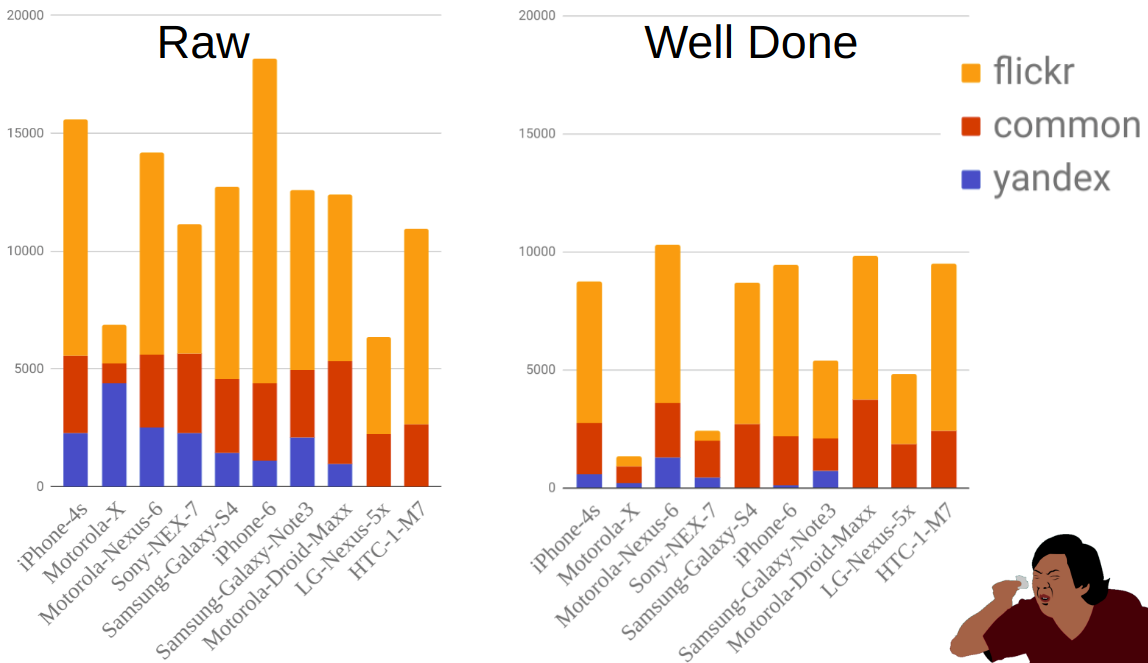
Die Abbildung zeigt die Verteilung der Fotos nach Quelle und Handy vor und nach dem Filtern. Wie Sie zum Beispiel sehen können, ist Moto-X viel kleiner als andere Telefone. Zur gleichen Zeit gab es viele von ihnen vor dem Filtern, aber die meisten von ihnen wurden eliminiert, da es viele Optionen für dieses Telefon gibt und die Besitzer das Modell nicht immer richtig angegeben haben.
ValidierungDie Implementierung des Teils mit Schulung und Validierung wurde von
Ilya Kibardin durchgeführt . Die Validierung an einem Stück Kaggle-Zug funktionierte überhaupt nicht - das Gitter hat eine Genauigkeit von fast 1,0 erreicht, und auf der Rangliste lag es bei etwa 0,96.
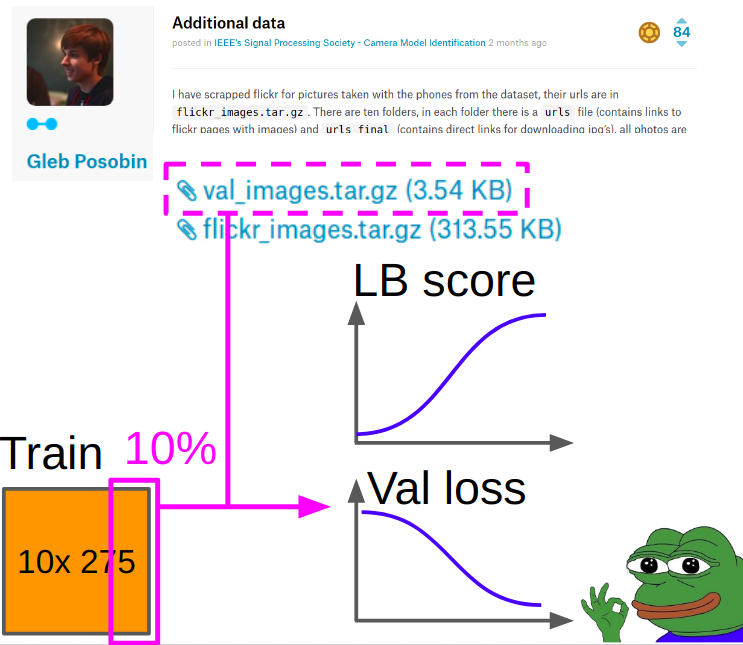
Daher wurden bei der Validierung Bilder von
Gleb Posobin aufgenommen , die er von allen Websites mit telefonischen Bewertungen aufgenommen hat. Es gab einen Fehler: Anstelle des iPhone 6 gab es ein iPhone 6+. Wir haben es durch ein echtes iPhone 6 ersetzt und 10% der Bilder aus dem Zug der Kagla entfernt, um die Klassen auszugleichen.
Beim Lernen wurde die Metrik wie folgt berücksichtigt:
- Wir betrachten Kreuzentropie und Akurasi in der Mitte der Ernte von der Validierung.
- Wir betrachten die Kreuzentropie und Akurasi (Manipulation + Erntezentrum) für jede der 8 Manipulationen und mitteln sie über acht Manipulationen mit einem arithmetischen Mittel.
- Wir addieren die Geschwindigkeit von Punkt 1 und Punkt 2 mit den Gewichten 0,7 und 0,3.
Die besten Kontrollpunkte wurden gemäß der in Abschnitt 3 erhaltenen gewichteten Kreuzentropie ausgewählt.
ModelltrainingIrgendwann mitten im Wettbewerb veröffentlichte
Andres Torrubia den gesamten
Code für seine Entscheidung . Er war so gut in Bezug auf die Genauigkeit der endgültigen Modelle, dass eine Reihe von Teams mit ihm die Rangliste hinaufflogen. Er wurde jedoch in Keras geschrieben und die gewünschte Codeebene.
Die Situation änderte sich ein zweites Mal, als
Ivan Romanov eine
Pytorch-Version dieses Codes veröffentlichte. Es war schneller und außerdem parallel zu mehreren Grafikkarten. Die Codeebene war jedoch immer noch nicht sehr gut, aber das ist nicht so wichtig.
Die Traurigkeit ist, dass diese Jungs auf den Plätzen 30 und 45 landeten, aber in unseren Herzen blieben sie immer an der Spitze.
Ilya in unserem Team nahm Mischas Code und nahm die folgenden Änderungen vor.
Vorverarbeitung:- Aus dem Originalbild wird eine zufällige Beschneidung 960x960 gemacht.
- Mit einer Wahrscheinlichkeit von 0,5 wird eine zufällige Manipulation angewendet. (Je nachdem, ob es verwendet wurde, wird is_manip = 1 oder 0 gesetzt.)
- Eine zufällige Ernte wird 480x480 gemacht
- Es gab zwei Trainingsoptionen: Entweder wird eine zufällige Drehung um 90 Grad in eine bestimmte Richtung vorgenommen (Simulation eines horizontalen / vertikalen Schießens für ein Mobiltelefon) oder eine zufällige Konvertierung der D4-Gruppe.
 Schulung
SchulungDas Training wurde von der gesamten Netzwerk-Feinabstimmung durchgeführt, ohne die Faltungsschichten des Klassifikators einzufrieren (wir hatten viele Daten + intuitiv die Gewichte, die Objekte auf hoher Ebene in Form von Katzen / Hunden extrahieren können, weil wir Funktionen auf niedriger Ebene benötigen).
 Terminplanung:
Terminplanung:Adam mit lr = 1e-4. Wenn sich der Validierungsverlust während 2-3 Epochen nicht mehr verbessert, reduzieren wir lr um die Hälfte. Also zur Konvergenz. Ersetzen Sie Adam durch SGD und lernen Sie drei Zyklen mit einem zyklischen lr von 1e-3 bis 1e-6.
Schlussensemble:Ich bat Ilya, meinen Ansatz aus dem vorherigen Wettbewerb umzusetzen. Für das Filialensemble haben wir 9 Modelle trainiert, aus jedem haben wir die 3 besten Kontrollpunkte ausgewählt, jeder Kontrollpunkt wurde mit TTA vorhergesagt und im Finale wurden alle Vorhersagen durch den geometrischen Mittelwert gemittelt.
 Nachwort der ersten Stufe
Nachwort der ersten StufeInfolgedessen belegten wir den 2. Platz in der Rangliste und den 1. Platz unter den Schülerteams. Dies bedeutet, dass wir im Rahmen der
Internationalen IEEE-Konferenz für Akustik, Sprach- und Signalverarbeitung 2018 in Kanada die 2. Stufe dieses Wettbewerbs erreicht haben. Von den bemerkenswerten war das Team, das den 3. Platz belegte, auch formell Student. Wenn wir die Geschwindigkeit berechnen, stellt sich heraus, dass wir sie mit einem korrekt vorhergesagten Bild umgangen haben.
Final IEEE Signal Processing Cup 2018Nachdem wir alle Bestätigungen erhalten hatten, beschlossen ich, Valery und Andrey, nicht zur zweiten Etappe nach Kanada zu fahren. Ilya und Arthur F. beschlossen zu gehen, sie begannen alles zu arrangieren und erhielten kein Visum. Um einen internationalen Skandal um die Unterdrückung der stärksten Wissenschaftler aus Russland zu vermeiden, durften die Orgien aus der Ferne teilnehmen.
Die Zeitleiste war wie folgt:
03.03 - angesichts der Zugdaten
04.09 - Testdaten ausgegeben
12.04 - wir durften remote teilnehmen
13.04 - Wir haben angefangen zu untersuchen, was mit den Daten da ist
16.04. - endgültig
Merkmale der zweiten StufeIn der zweiten Phase gab es keine Rangliste: Es war notwendig, nur eine Einsendung am Ende zu senden. Das heißt, selbst das Format der Vorhersagen kann nicht überprüft werden. Auch Kameramodelle waren nicht bekannt. Und das bedeutet zwei Dateien gleichzeitig: Es funktioniert nicht mit externen Daten und die lokale Validierung kann sehr unrepräsentativ sein.
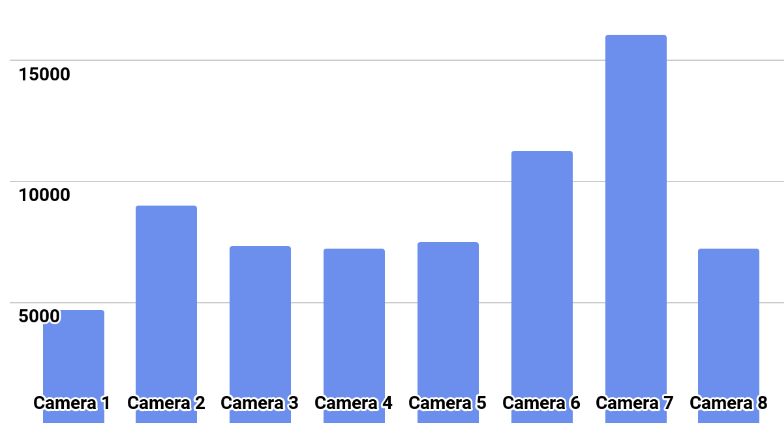
Die Klassenverteilung ist im Bild dargestellt.
LösungWir haben versucht, Modelle mit einem Plan aus der ersten Phase aus den Maßstäben der besten Modelle zu trainieren. Alle Modelle trainierten fröhlich mit einer Genauigkeit von mehr als 0,97 auf ihren Falten, aber beim Test gaben sie Schnittpunkte von Vorhersagen im Bereich von 0,87 an.
Was ich als hartes Overfit interpretiert habe. Deshalb schlug er einen neuen Plan vor:
- Wir nehmen unsere besten Modelle der ersten Stufe als Merkmalsextraktoren.
- Wir nehmen die PCA aus den extrahierten Funktionen, damit alles über Nacht lernt.
- LightGBM lernen.

Die Logik hier ist wie folgt. Neuronale Netze sind bereits darauf trainiert, Merkmale des Sensors, der Optik und des Demo-Algorithmus auf niedriger Ebene zu extrahieren und gleichzeitig nicht am Kontext festzuhalten. Darüber hinaus sind vor dem endgültigen Klassifikator extrahierte Merkmale (tatsächlich logistische Regression) das Ergebnis einer stark nichtlinearen Transformation. Daher könnte man einfach etwas Einfaches lehren, das nicht zu Umschulungen neigt, wie zum Beispiel logistische Regression. Da sich die neuen Daten jedoch stark von den Daten der ersten Stufe unterscheiden können, ist es immer noch besser, etwas Nichtlineares zu trainieren, beispielsweise die Gradientenverstärkung auf Entscheidungsbäumen. Ich habe diesen Ansatz in mehreren Wettbewerben verwendet, in denen ich den Code veröffentlicht habe.
Da es eine Einreichung gab, habe ich keine zuverlässige Möglichkeit, meinen Ansatz zu testen. DenseNet hat sich jedoch als der beste Feature-Extraktor erwiesen. Resnext- und SE-Resnext-Netzwerke zeigten bei der lokalen Validierung eine geringere Leistung. Daher sah die endgültige Entscheidung so aus.
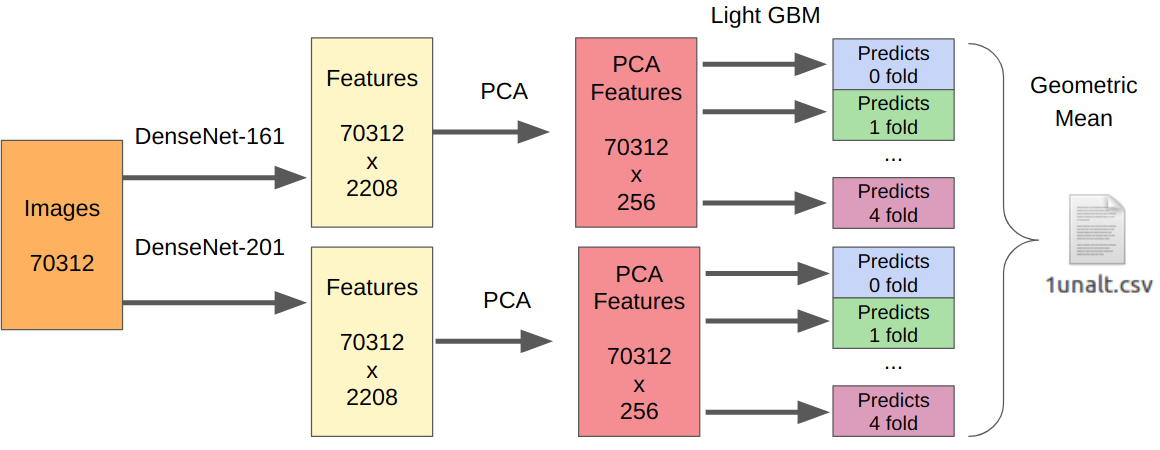
Für den Teil mit Manipulationen muss die Anzahl aller Trainingsmuster mit 7 multipliziert werden, da ich Merkmale aus jeder Manipulation separat extrahiert habe.
NachwortInfolgedessen haben wir in der Endphase den zweiten Platz belegt, aber es gibt viele Vorbehalte. Zunächst wurde der Platz nicht nach der Genauigkeit des Algorithmus vergeben, sondern nach Schätzungen der Präsentation der Jury. Das Team, das den ersten Platz erhielt, machte nicht nur eine Preza, sondern auch eine Live-Demo mit der Arbeit seines Algorithmus. Nun, wir kennen immer noch nicht die Endgeschwindigkeit jedes Teams und die Organisationen geben sie auch nach direkten Fragen nicht in der Korrespondenz bekannt.
Von den lustigen Dingen: In der ersten Phase haben alle Teams unserer Community im Teamnamen [ods.ai] angegeben und die Rangliste ziemlich stark besetzt. Danach beschlossen Kegle-Legenden wie
Inversion und
Giba , sich uns anzuschließen, um zu sehen, was wir hier machten.

Ich habe es wirklich genossen, als Mentor teilzunehmen. Aufgrund der Erfahrung mit der Teilnahme an früheren Wettbewerben konnte ich eine Reihe wertvoller Tipps zur Verbesserung der Grundlinie sowie zum Aufbau einer lokalen Validierung geben. In Zukunft wird ein solches Format mehr als der Fall sein: Kaggle Master / Grandmaster als Architekt der Lösung + 2-3 Kaggle Expert zum Schreiben von Code und Testen von Hypothesen. Meiner Meinung nach ist dies eine reine Win-Win-Situation, da erfahrene Teilnehmer bereits zu faul sind, um Code zu schreiben, und vielleicht nicht so viel Zeit, und Anfänger ein besseres Ergebnis erzielen, keine banalen Fehler durch Unerfahrenheit machen und noch schneller Erfahrungen sammeln.
→
Code unserer Lösung→
Leistung mit ML-Training aufzeichnen