Stellen Sie Kubernetes HA mit Containerd bereit

Guten Tag liebe Leser von Habr! Am 24. Mai 2018 wurde im offiziellen Kubernetes-Blog ein Artikel mit dem Titel Kubernetes Containerd Integration Goes GA veröffentlicht, in dem angegeben wird, dass die Integration von Containerd in Kubernetes produktionsbereit ist. Außerdem haben Jungs von der Firma Flant eine Übersetzung des Artikels ins Russische in ihrem Blog veröffentlicht, um ein wenig Klarheit von sich selbst zu schaffen. Nachdem ich die Projektdokumentation auf Github gelesen hatte , beschloss ich, Containerd auf "meiner eigenen Haut" zu testen .
Unser Unternehmen hat mehrere Projekte in der Phase "noch sehr weit von der Produktion entfernt". So werden sie unser Experiment; Für sie haben wir uns entschlossen, einen Failover-Cluster von Kubernetes mithilfe von Containerd bereitzustellen und zu prüfen, ob es ein Leben ohne Docker gibt.
Wenn Sie interessiert sind, wie wir es gemacht haben und was daraus wurde, sind Sie bei cat willkommen.
Schema und Einsatzbeschreibung
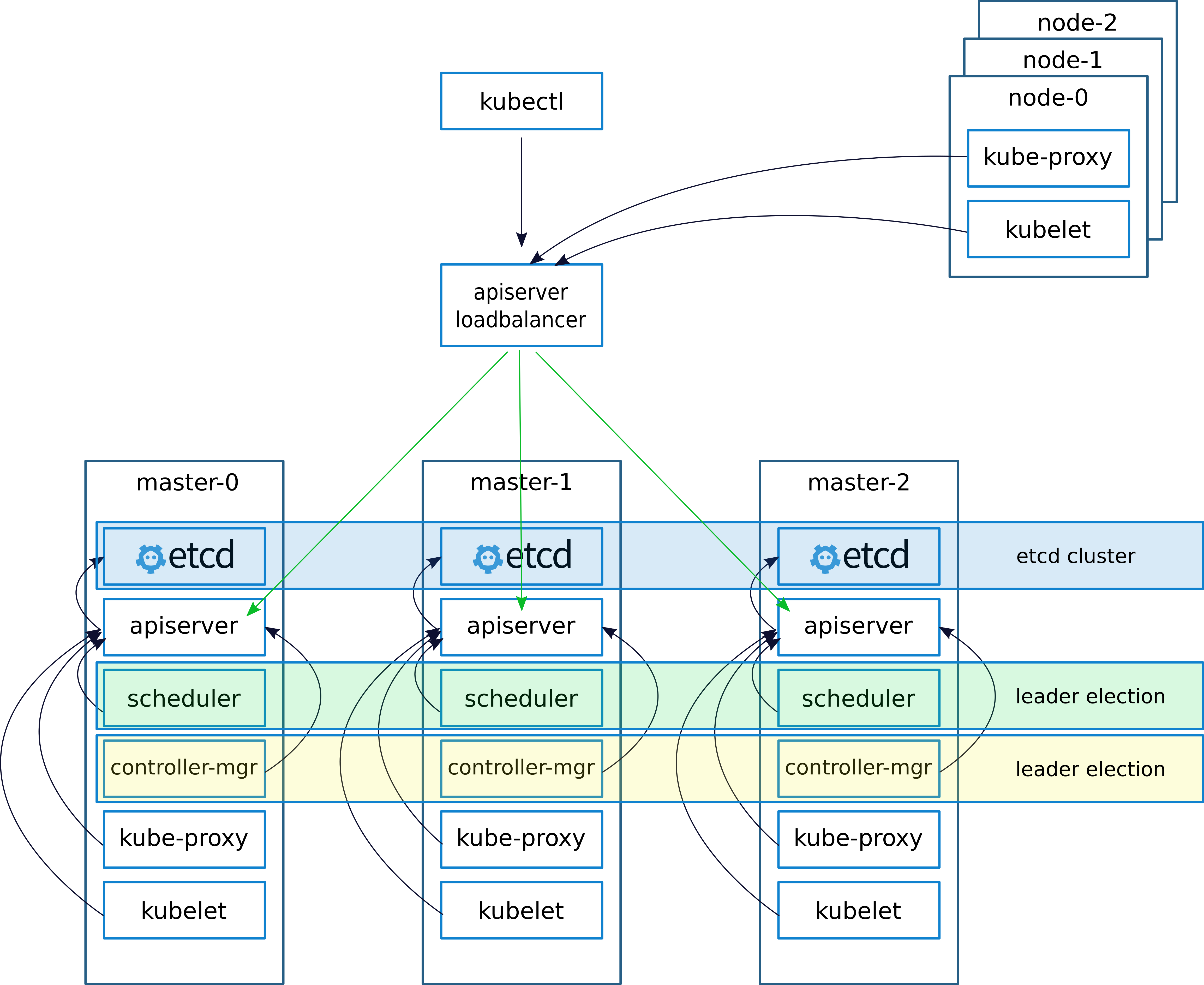
Wie üblich beim Bereitstellen eines Clusters (darüber habe ich in einem früheren Artikel geschrieben
keepalived - Implementierungen von VRRP (Virtual Router Redundancy Protocol) für LinuxKeepalived erstellt eine virtuelle IP (VIRTIP), die auf die IP eines der drei Master "verweist" (eine Subschnittstelle erstellt). Der Keepalived-Daemon überwacht den Zustand der Computer und schließt im Falle eines Fehlers den ausgefallenen Server aus der Liste der aktiven Server aus, indem er VIRTIP auf die IP eines anderen Servers umschaltet. Dies entspricht der "Gewichtung", die bei der Konfiguration von Keepalived auf jedem Server angegeben wurde.
Keepalived-Daemons kommunizieren über VRRP und senden sich gegenseitig Nachrichten an die Adresse 224.0.0.18.
Wenn der Nachbar seine Nachricht nicht gesendet hat, gilt er nach Ablauf der Frist als tot. Sobald der abgestürzte Server seine Nachrichten an das Netzwerk sendet, kehrt alles an seinen Platz zurück
Wir konfigurieren die Arbeit mit dem API-Server auf Kubernetes-Knoten wie folgt.
Konfigurieren Sie nach der Installation des Clusters den Kube-Proxy und ändern Sie den Port von 6443 auf 16443 (Details unten). Auf jedem der Master wird Nginx bereitgestellt, das als Loadbalancer fungiert, Port 16443 überwacht und alle drei Master auf Port 6443 vorverlegt (Details siehe unten).
Durch dieses Schema wurde eine erhöhte Fehlertoleranz sowohl bei Verwendung von Keepalived als auch bei Verwendung von Nginx erzielt. Es wurde ein Ausgleich zwischen den API-Servern auf den Assistenten erreicht.
In einem früheren Artikel habe ich die Bereitstellung von nginx und etcd im Docker beschrieben. In diesem Fall haben wir jedoch kein Docker, sodass Nginx und etcd lokal auf Masterknoten funktionieren.
Theoretisch wäre es möglich, nginx und etcd mithilfe von Containerd bereitzustellen. Bei Problemen würde dieser Ansatz die Diagnose jedoch erschweren. Daher haben wir beschlossen, nicht zu experimentieren und lokal auszuführen.
Beschreibung der Server für die Bereitstellung:
| Name | IP | Dienstleistungen |
|---|
| VIRTIP | 172.26.133.160 | ------ ------. |
| kube-master01 | 172.26.133.161 | kubeadm, kubelet, kubectl, etcd, Containerd, Nginx, Keepalived |
| kube-master02 | 172.26.133.162 | kubeadm, kubelet, kubectl, etcd, Containerd, Nginx, Keepalived |
| kube-master03 | 172.26.133.163 | kubeadm, kubelet, kubectl, etcd, Containerd, Nginx, Keepalived |
| kube-node01 | 172.26.133.164 | Kubeadm, Kubelet, Kubectl, Containerd |
| kube-node02 | 172.26.133.165 | Kubeadm, Kubelet, Kubectl, Containerd |
| kube-node03 | 172.26.133.166 | Kubeadm, Kubelet, Kubectl, Containerd |
Installieren Sie kubeadm, kubelet, kubectl und verwandte Pakete
Alle Befehle werden von root ausgeführt
sudo -i
apt-get update && apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl unzip tar apt-transport-https btrfs-tools libseccomp2 socat util-linux mc vim keepalived
Installieren Sie conteinerd
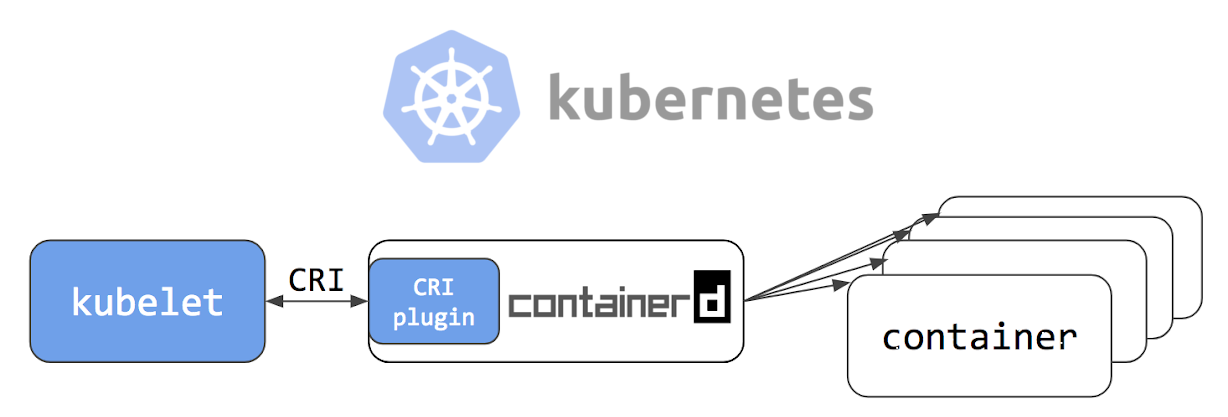
cd / wget https://storage.googleapis.com/cri-containerd-release/cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz tar -xvf cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz
Containerd-Konfigurationen konfigurieren
mkdir -p /etc/containerd nano /etc/containerd/config.toml
Zur Datei hinzufügen:
[plugins.cri] enable_tls_streaming = true
Wir fangen an zu prüfen, ob alles in Ordnung ist
systemctl enable containerd systemctl start containerd systemctl status containerd ● containerd.service - containerd container runtime Loaded: loaded (/etc/systemd/system/containerd.service; disabled; vendor preset: enabled) Active: active (running) since Mon 2018-06-25 12:32:01 MSK; 7s ago Docs: https://containerd.io Process: 10725 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS) Main PID: 10730 (containerd) Tasks: 15 (limit: 4915) Memory: 14.9M CPU: 375ms CGroup: /system.slice/containerd.service └─10730 /usr/local/bin/containerd Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Get image filesystem path "/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs"" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=error msg="Failed to load cni during init, please check CRI plugin status before setting up network for pods" error="cni con Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="loading plugin "io.containerd.grpc.v1.introspection"..." type=io.containerd.grpc.v1 Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start subscribing containerd event" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start recovering state" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg=serving... address="/run/containerd/containerd.sock" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="containerd successfully booted in 0.308755s" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start event monitor" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start snapshots syncer" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start streaming server"
Installieren und ausführen Sie etcd
Wichtiger Hinweis, ich habe den kubernetes Cluster Version 1.10 installiert. Nur ein paar Tage später, zum Zeitpunkt des Schreibens des Artikels, wurde Version 1.11 veröffentlicht. Wenn Sie Version 1.11 installieren, setzen Sie die Variable ETCD_VERSION = "v3.2.17", wenn 1.10, dann ETCD_VERSION = "v3.1.12".
export ETCD_VERSION="v3.1.12" curl -sSL https://github.com/coreos/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin/
Kopieren Sie Konfigurationen aus Gitahab.
git clone https://github.com/rjeka/k8s-containerd.git cd k8s-containerd
Konfigurieren Sie die Variablen in der Konfigurationsdatei.
vim create-config.sh
Beschreibung der Dateivariablen create-config.sh
Einstellungen auf dem lokalen Computer jedes Knotens (jeder Knoten hat seinen eigenen)
K8SHA_IPLOCAL - IP-Adresse des Knotens, auf dem das Skript konfiguriert ist
K8SHA_ETCDNAME - lokaler Computername im ETCD-Cluster
K8SHA_KA_STATE - Rolle in Keepalived. Ein MASTER-Knoten, alle anderen BACKUP.
K8SHA_KA_PRIO - Keepalived-Priorität, der Master hat 102 für die verbleibenden 101, 100. Wenn der Master mit der Nummer 102 fällt, nimmt der Knoten mit der Nummer 101 seinen Platz ein und so weiter.
K8SHA_KA_INTF - Keepalived-Netzwerkschnittstelle. Der Name der Schnittstelle, die beibehalten wird, wird abgehört.
Die allgemeinen Einstellungen für alle Masterknoten sind gleich:
K8SHA_IPVIRTUAL = 172.26.133.160 - virtuelle IP des Clusters.
K8SHA_IP1 ... K8SHA_IP3 - IP- Adressen von Mastern
K8SHA_HOSTNAME1 ... K8SHA_HOSTNAME3 - Hostnamen für Masterknoten. Ein wichtiger Punkt, unter diesen Namen kubeadm generiert Zertifikate.
K8SHA_KA_AUTH - Passwort für Keepalived. Sie können beliebige angeben
K8SHA_TOKEN - Cluster-Token. Kann mit dem Befehl kubeadm token generate generiert werden
K8SHA_CIDR - Subnetzadresse für Herde. Ich benutze Flanell also CIDR 0.244.0.0/16. Achten Sie auf den Bildschirm - in der Konfiguration sollte K8SHA_CIDR = 10.244.0.0 \ / 16 sein
Führen Sie das Skript aus, mit dem nginx, keepalived, etcd und kubeadmin konfiguriert werden
./create-config.sh
Wir starten etcd.
etcd ich hob ohne tls. Wenn Sie tls benötigen, wird in der
offiziellen kubernetes-Dokumentation ausführlich beschrieben, wie Zertifikate für etcd generiert werden.
systemctl daemon-reload && systemctl start etcd && systemctl enable etcd
Statusprüfung
etcdctl cluster-health member ad059013ec46f37 is healthy: got healthy result from http://192.168.5.49:2379 member 4d63136c9a3226a1 is healthy: got healthy result from http://192.168.4.169:2379 member d61978cb3555071e is healthy: got healthy result from http://192.168.4.170:2379 cluster is healthy etcdctl member list ad059013ec46f37: name=hb-master03 peerURLs=http://192.168.5.48:2380 clientURLs=http://192.168.5.49:2379,http://192.168.5.49:4001 isLeader=false 4d63136c9a3226a1: name=hb-master01 peerURLs=http://192.168.4.169:2380 clientURLs=http://192.168.4.169:2379,http://192.168.4.169:4001 isLeader=true d61978cb3555071e: name=hb-master02 peerURLs=http://192.168.4.170:2380 clientURLs=http://192.168.4.170:2379,http://192.168.4.170:4001 isLeader=false
Wenn alles in Ordnung ist, fahren Sie mit dem nächsten Schritt fort.
Konfigurieren Sie kubeadmin
Wenn Sie kubeadm Version 1.11 verwenden, können Sie diesen Schritt überspringen
Konfigurieren Sie die kubeadmin-Konfiguration, damit kybernetes nicht mit Docker, sondern mit Containerd funktioniert
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Fügen Sie nach [Service] eine Zeile zum Block hinzu
Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
Die gesamte Konfiguration sollte folgendermaßen aussehen: [Service] Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock" Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true" Environment="KUBELET_NETWORK_ARGS=--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin" Environment="KUBELET_DNS_ARGS=--cluster-dns=10.96.0.10 --cluster-domain=cluster.local" Environment="KUBELET_AUTHZ_ARGS=--authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt" Environment="KUBELET_CADVISOR_ARGS=--cadvisor-port=0" Environment="KUBELET_CERTIFICATE_ARGS=--rotate-certificates=true --cert-dir=/var/lib/kubelet/pki" ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_SYSTEM_PODS_ARGS $KUBELET_NETWORK_ARGS $KUBELET_DNS_ARGS $KUBELET_AUTHZ_ARGS $KUBELET_CADVISOR_ARGS $KUBELET_CERTIFICATE_ARGS $KUBELET_EXTRA_ARGS
Wenn Sie Version 1.11 installieren und mit CoreDNS anstelle von kube-dns experimentieren und die dynamische Konfiguration testen möchten, kommentieren Sie den folgenden Block in der Konfigurationsdatei kubeadm-init.yaml aus:
feature-gates: DynamicKubeletConfig: true CoreDNS: true
Kubelet neu starten
systemctl daemon-reload && systemctl restart kubelet
Initialisierung des ersten Assistenten
Bevor Sie kubeadm starten, müssen Sie keepalived neu starten und seinen Status überprüfen
systemctl restart keepalived.service systemctl status keepalived.service ● keepalived.service - Keepalive Daemon (LVS and VRRP) Loaded: loaded (/lib/systemd/system/keepalived.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2018-06-27 10:40:03 MSK; 1min 44s ago Process: 4589 ExecStart=/usr/sbin/keepalived $DAEMON_ARGS (code=exited, status=0/SUCCESS) Main PID: 4590 (keepalived) Tasks: 7 (limit: 4915) Memory: 15.3M CPU: 968ms CGroup: /system.slice/keepalived.service ├─4590 /usr/sbin/keepalived ├─4591 /usr/sbin/keepalived ├─4593 /usr/sbin/keepalived ├─5222 /usr/sbin/keepalived ├─5223 sh -c /etc/keepalived/check_apiserver.sh ├─5224 /bin/bash /etc/keepalived/check_apiserver.sh └─5231 sleep 5
Überprüfen Sie, ob VIRTIP pingt
ping -c 4 172.26.133.160 PING 172.26.133.160 (172.26.133.160) 56(84) bytes of data. 64 bytes from 172.26.133.160: icmp_seq=1 ttl=64 time=0.030 ms 64 bytes from 172.26.133.160: icmp_seq=2 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=3 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=4 ttl=64 time=0.056 ms --- 172.26.133.160 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3069ms rtt min/avg/max/mdev = 0.030/0.046/0.056/0.012 ms
Führen Sie danach kubeadmin aus. Stellen Sie sicher, dass Sie die Zeile --skip-preflight-prüfungen einfügen. Kubeadmin sucht standardmäßig nach Docker und schlägt ohne Überspringen mit einem Fehler fehl.
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
Speichern Sie die generierte Zeile, nachdem kubeadm funktioniert hat. Es wird benötigt, um Arbeitsknoten in den Cluster einzugeben.
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Geben Sie als Nächstes an, wo die Datei admin.conf gespeichert ist
Wenn wir als root arbeiten, dann:
vim ~/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf source ~/.bashrc
Befolgen Sie für einen einfachen Benutzer die Anweisungen auf dem Bildschirm.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
Fügen Sie dem Cluster zwei weitere Assistenten hinzu. Kopieren Sie dazu die Zertifikate von kube-master01 nach kube-master02 und kube-master03 in das Verzeichnis / etc / kubernetes /. Zu diesem Zweck habe ich den SSH-Zugriff für root konfiguriert und nach dem Kopieren der Dateien die Einstellungen zurückgegeben.
scp -r /etc/kubernetes/pki 172.26.133.162:/etc/kubernetes/ scp -r /etc/kubernetes/pki 172.26.133.163:/etc/kubernetes/
Führen Sie nach dem Kopieren nach kube-master02 und kube-master03 aus.
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
Installieren Sie das CIDR-Flanell
auf kube-master01 ausführen
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
Die aktuelle Version von Flanel finden Sie in der Dokumentation zu Kubernetes .
Wir warten, bis alle Container erstellt sind.
watch -n1 kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE kube-system kube-apiserver-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-apiserver-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-apiserver-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-controller-manager-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-controller-manager-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-controller-manager-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-dns-86f4d74b45-8c24s 3/3 Running 0 17m 10.244.2.2 kube-master03 kube-system kube-flannel-ds-4h4w7 1/1 Running 0 2m 172.26.133.163 kube-master03 kube-system kube-flannel-ds-kf5mj 1/1 Running 0 2m 172.26.133.162 kube-master02 kube-system kube-flannel-ds-q6k4z 1/1 Running 0 2m 172.26.133.161 kube-master01 kube-system kube-proxy-9cjtp 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master01 1/1 Running 0 18m 172.26.133.161 kube-master01 kube-system kube-scheduler-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03
Wir replizieren kube-dns an alle drei Master
Auf kube-master01 ausführen
kubectl scale --replicas=3 -n kube-system deployment/kube-dns
Installieren und konfigurieren Sie nginx
Installieren Sie auf jedem Masterknoten nginx als Balancer für die Kubernetes-API
Ich habe alle Cluster-Maschinen auf Debian. Von den Nginx-Paketen wird das Stream-Modul nicht unterstützt. Fügen Sie daher die Nginx-Repositorys hinzu und installieren Sie sie aus den Nginx-Repositorys. Wenn Sie ein anderes Betriebssystem haben, lesen Sie die Nginx-Dokumentation .
wget https://nginx.org/keys/nginx_signing.key sudo apt-key add nginx_signing.key echo -e "\n#nginx\n\ deb http://nginx.org/packages/debian/ stretch nginx\n\ deb-src http://nginx.org/packages/debian/ stretch nginx" >> /etc/apt/sources.list apt-get update && apt-get install nginx -y
Nginx-Konfiguration erstellen (falls noch nicht erstellt)
./create-config.sh
nginx.confBenutzer nginx;
worker_processes auto;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
Ereignisse {
worker_connections 1024;
}}
http {
include /etc/nginx/mime.types;
default_type application / octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf;
}}
stream {
Upstream-Apiserver {
Server 172.26.133.161:6443 weight = 5 max_fails = 3 fail_timeout = 30s;
Server 172.26.133.162:6443 weight = 5 max_fails = 3 fail_timeout = 30s;
Server 172.26.133.163:6443 weight = 5 max_fails = 3 fail_timeout = 30s;
} server { listen 16443; proxy_connect_timeout 1s; proxy_timeout 3s; proxy_pass apiserver; }
}}
Wir prüfen, ob alles in Ordnung ist und wenden die Konfiguration an
nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful systemctl restart nginx systemctl status nginx ● nginx.service - nginx - high performance web server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Thu 2018-06-28 08:48:09 MSK; 22s ago Docs: http://nginx.org/en/docs/ Process: 22132 ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf (code=exited, status=0/SUCCESS) Main PID: 22133 (nginx) Tasks: 2 (limit: 4915) Memory: 1.6M CPU: 7ms CGroup: /system.slice/nginx.service ├─22133 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf └─22134 nginx: worker process
Testen Sie den Balancer
curl -k https://172.26.133.161:16443 | wc -l % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 233 100 233 0 0 12348 0 --:--:-- --:--:-- --:--:-- 12944
Konfigurieren Sie kube-proxy für die Arbeit mit dem Balancer
Bearbeiten Sie nach der Konfiguration des Balancers den Port in den Kubernetes-Einstellungen.
kubectl edit -n kube-system configmap/kube-proxy
Ändern Sie die Servereinstellungen in https://172.26.133.160:16443
Als Nächstes müssen Sie kube-proxy so konfigurieren, dass es mit dem neuen Port funktioniert
kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-9cjtp 1/1 Running 1 22h 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 1 22h 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 4 22h 172.26.133.162 kube-
Wir löschen alle Pods, nach dem Entfernen werden sie automatisch mit den neuen Einstellungen neu erstellt
kubectl delete pod -n kube-system kube-proxy-XXX ```bash . ```bash kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-hqrsw 1/1 Running 0 33s 172.26.133.161 kube-master01 kube-system kube-proxy-kzvw5 1/1 Running 0 47s 172.26.133.163 kube-master03 kube-system kube-proxy-zzkz5 1/1 Running 0 7s 172.26.133.162 kube-master02
Hinzufügen von Arbeitsknoten zum Cluster
Führen Sie für jeden Grundton den von kubeadm generierten Befehl aus
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX --cri-socket /run/containerd/containerd.sock --skip-preflight-checks
Wenn die Zeile "verloren" ist, müssen Sie eine neue generieren
kubeadm token generate kubeadm token create <generated-token> --print-join-command --ttl=0
Auf Arbeitsknoten in den Dateien /etc/kubernetes/bootstrap-kubelet.conf und /etc/kubernetes/kubelet.conf
Servervariablenwert zu unserer Virtip
vim /etc/kubernetes/bootstrap-kubelet.conf server: https://172.26.133.60:16443 vim /etc/kubernetes/kubelet.conf server: https://172.26.133.60:16443
Und starten Sie Containerd und Kubernetes neu
systemctl restart containerd kubelet
Dashboard-Installation
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
Erstellen Sie einen Benutzer mit Administratorrechten:
kubectl apply -f kube-dashboard/dashboard-adminUser.yaml
Wir bekommen den Token für den Eintritt:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
Konfigurieren des Dashboard-Zugriffs über NodePort in VIRTIP
kubectl -n kube-system edit service kubernetes-dashboard
Wir ersetzen den Wert von Typ: ClusterIP durch Typ: NodePort und fügen im Abschnitt Port den Wert von nodePort: 30000 hinzu (oder den Port im Bereich von 30000 bis 32000, auf den das Panel zugreifen soll):

Das Panel ist jetzt unter https: // VIRTIP: 30000 verfügbar
Heapster
Installieren Sie als Nächstes Heapster, ein Tool zum Abrufen von Metriken für Clusterkomponenten.
Installation:
git clone https://github.com/kubernetes/heapster.git cd heapster kubectl create -f deploy/kube-config/influxdb/ kubectl create -f deploy/kube-config/rbac/heapster-rbac.yaml
Schlussfolgerungen
Ich habe keine besonderen Probleme bei der Arbeit mit Containerd bemerkt. Einmal gab es eine unverständliche Panne mit einem Herd, nachdem der Einsatz entfernt wurde. Kubernetes glaubte, dass unter gelöscht wurde, aber unter wurde so ein eigenartiger "Zombie". Es blieb auf dem Knoten existieren, aber im erweiterten Status.
Ich glaube, dass Containerd eher als Container-Laufzeit für Kubernetes ausgerichtet ist. Höchstwahrscheinlich wird es in Zukunft als Umgebung für den Start von Microservices in Kubernetes möglich und notwendig sein, unterschiedliche Umgebungen zu verwenden, die sich an unterschiedlichen Aufgaben, Projekten usw. orientieren.
Das Projekt entwickelt sich sehr schnell. Alibaba Cloud hat begonnen, conatinerd aktiv zu nutzen, und betont, dass es die ideale Umgebung für den Betrieb von Containern ist.
Laut den Entwicklern entspricht die Integration von Containerd in die Google Cloud-Plattform Kubernetes nun der Docker-Integration.
Ein gutes Beispiel für das Dienstprogramm crictl console . Ich werde auch einige Beispiele aus dem erstellten Cluster geben:
kubectl describe nodes | grep "Container Runtime Version:"

Der Docker-CLI fehlen die grundlegenden Konzepte von Kubernetes, z. B. Pod und Namespace, während crictl diese Konzepte unterstützt
crictl pods

Und wenn nötig, können wir uns die Container im üblichen Format wie Docker ansehen
crictl ps

Wir können die Bilder sehen, die sich auf dem Knoten befinden
crictl images
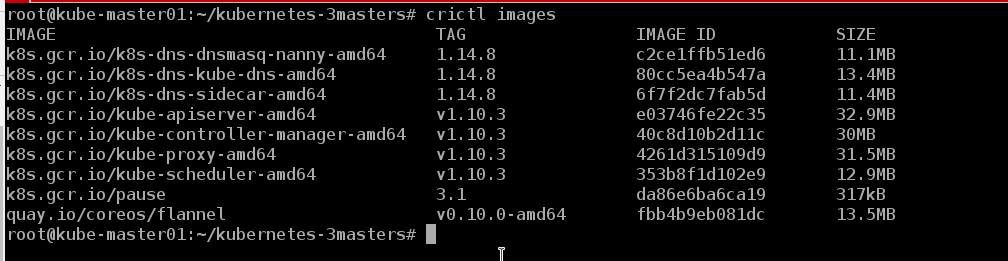
Wie sich herausstellte, ist das Leben ohne Hafenarbeiter :)
Es ist zu früh, um über Fehler und Störungen zu sprechen. Der Cluster arbeitet seit etwa einer Woche mit uns zusammen. In naher Zukunft wird der Test darauf übertragen, und bei Erfolg höchstwahrscheinlich der Entwicklerstand eines der Projekte. Es besteht die Idee, eine Reihe von Artikeln zu DevOps-Prozessen zu verfassen, z. B.: Erstellen eines Clusters, Einrichten eines Ingress-Controllers und Verschieben auf separate Clusterknoten, Automatisieren der Image-Assemblierung, Überprüfen von Images auf Schwachstellen, Bereitstellung usw. In der Zwischenzeit werden wir die Stabilität der Arbeit untersuchen, nach Fehlern suchen und neue Produkte entwickeln.
Dieses Handbuch eignet sich auch zum Bereitstellen eines Failoverclusters mit Docker. Sie müssen Docker nur gemäß den Anweisungen in der offiziellen Kubernetes-Dokumentation installieren und die Schritte zum Installieren von Containerd und zum Konfigurieren der Kubeadm-Konfiguration überspringen.
Oder Sie können Containerd und Docker gleichzeitig auf demselben Host platzieren und, wie die Entwickler versichern, perfekt zusammenarbeiten. Containerd ist die Konbernetes-Containerer-Startumgebung, und Docker ist genau wie Docker)))
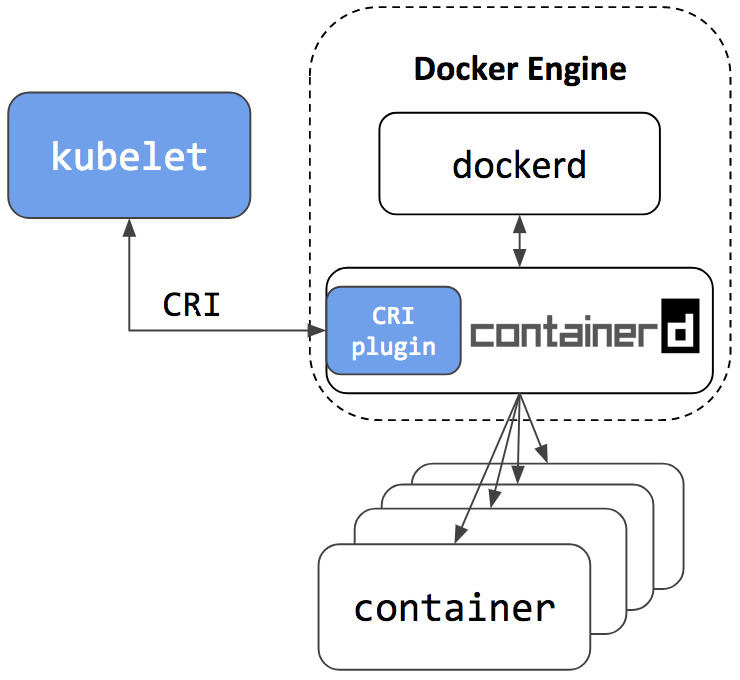
Das Containerd-Repository verfügt über ein
ansible Playbook zum Einrichten eines einzelnen Assistentenclusters. Für mich war es jedoch interessanter, das System mit meinen Händen zu „heben“, um die Konfiguration jeder Komponente genauer zu verstehen und zu verstehen, wie es in der Praxis funktioniert.
Vielleicht werden meine Hände eines Tages reichen und ich werde mein Playbook für die Bereitstellung eines Clusters mit HA schreiben, da ich in den letzten sechs Monaten mehr als ein Dutzend davon bereitgestellt habe und es wahrscheinlich an der Zeit wäre, den Prozess zu automatisieren.
Während des Schreibens dieses Artikels wurde auch die Version kubernetes 1.11 veröffentlicht. Informationen zu den wichtigsten Änderungen finden Sie im Flant-Blog oder im offiziellen Kubernetes-Blog . Wir haben die Testcluster auf Version 1.11 aktualisiert und kube-dns durch CoreDNS ersetzt. Darüber hinaus haben wir die DynamicKubeletConfig-Funktion zum Testen der Funktionen der dynamischen Aktualisierung von Konfigurationen hinzugefügt.
Verwendete Materialien:
Vielen Dank für das Lesen bis zum Ende.
Da Informationen zu Kubernetes, insbesondere zu Clustern, die unter realen Bedingungen betrieben werden, in RuNet sehr knapp sind, sind Hinweise auf Ungenauigkeiten ebenso willkommen wie Kommentare zum allgemeinen Clusterbereitstellungsschema. Ich werde versuchen, sie zu berücksichtigen und entsprechende Korrekturen vorzunehmen. Und ich bin immer bereit, Fragen in den Kommentaren, auf Githab und in allen sozialen Netzwerken zu beantworten, die in meinem Profil angegeben sind.
Mit freundlichen Grüßen Eugene.