Ein großes Bergbauunternehmen hatte eine interessante Aufgabe: Es gibt viele Standorte mit IT-Systemen. Sie befinden sich sowohl in Städten als auch in Lagerstätten. Dies sind mehrere Dutzend Regionalbüros sowie Bergbauunternehmen. 500 Kilometer in der Taiga ohne Straße - ganz einfach! In jeder Einrichtung gibt es Geräte, die in eine gemeinsame Infrastruktur „gefaltet“ werden müssen, um zu bestimmen, was und in welchem Zustand sie funktionieren.
Hier wurde nicht nur eine technische Bestandsaufnahme aller Geräte im Netzwerk (Seriennummern, Softwareversionen usw.) benötigt, sondern ein komplettes Überwachungssystem. Warum? Um die Hauptursachen von Unfällen zu identifizieren und umgehend davor zu warnen, Netzwerkkarten zu erstellen, Verbindungen zwischen Geräten herzustellen, den Zustand von Eisen und Kommunikationskanälen zu überwachen, Warnungen zu geben, wie der Support beendet oder neue nicht gemeldete Geräte eingeschaltet werden können usw. Darüber hinaus war eine Integration erforderlich mit CMDB (unter Berücksichtigung von Konfigurationseinheiten), so dass das gesamte Eisen, das das Überwachungssystem "gefunden" hat, mit dem verglichen wird, was in einem bestimmten Zweig registriert ist, dh tatsächlich im Netzwerk.
Ein anderes Überwachungssystem musste mit Telefonie-Asterisk „befreundet“ sein, damit letztere
Im Falle einiger schwerwiegender Notsituationen wie eines Stromausfalls am Standort in Krasnojarsk könnten die Verantwortlichen automatisch schnell angerufen werden. Es bestand auch die Aufgabe, zwischen der Sichtbarkeit von Überwachungsobjekten und den Befugnissen von Benutzergruppen zu unterscheiden. Die Betreiber kümmern sich um die Ausrüstung, Moskau - Moskau, Ingenieure vor Ort - nur um ihr Feld.
Der Kunde wählte zwischen mehreren Überwachungssystemen: 1) Shareware-Produkt; 2) eine der kommerziellen Lösungen; 3) Infosim StableNet-System. Als Ergebnis der Tests wurden die Nachteile des Shareware-Produkts für den Kunden deutlich: Es war langwierig und schwierig zu konfigurieren und verfügte nicht über die erforderliche Funktionalität (im selben Teil zum Beispiel zum Rendern von Verbindungen zwischen Geräten im Netzwerk). Nach dem Auspacken weiß er nicht, wie das geht, aber mit Plugins stellt sich heraus, dass es so lala ist. Das kommerzielle Produkt hatte keine verteilten Überwachungsagenten - diese sind an einem bestimmten Standort installiert und steuern nur ihren „Busch“. Dementsprechend hielten wir in Infosima an - er schloss alle Wunschliste. Und deshalb.
So sieht der InfoSim StableNet-Administrator-Hauptbildschirm aus (dies ist kein Mineralprojekt, sondern eine Testinfrastruktur).
Der Hauptbildschirm, auf dem der aktuelle Netzwerkstatus angezeigt wird:

Links ist das Bedienfeld sichtbar, in dem wir das System konfigurieren und die benötigten Statistiken anzeigen können. Mit der Schaltfläche Analysator können Sie beispielsweise Statistiken für alle Parameter anzeigen, die wir erfassen, insbesondere die Umlaufzeit für einen Zeitraum von einer Stunde für ein bestimmtes Stück Eisen.

Die Schaltfläche Inventar zeigt die Inventardaten von Überwachungsobjekten, Nachbarn und der MAC-Tabelle für jedes Gerät im System an. Unglaublich praktisch: Das Auffinden von Geräteparametern im Netzwerk anhand von Seriennummern, Gerätetypen, Betriebssystemversionen usw. wird erleichtert.

Als zum Beispiel irgendwo weit weg in der Taiga lokale Mitarbeiter einen neuen Schalter installierten und niemandem davon erzählten, wurde er sofort im System sichtbar. Dieses Gerät fällt in einen speziellen Zweig im Gerätebaum „Neue Geräte“ und automatisch in die CMDB.

Überwachungsobjekte werden nicht nur nach seriellen Modellen und Modellen abgefragt, sondern auch zum Laden von Speicher, Schnittstellen usw. Viele Anbieter werden unterstützt - insbesondere Server, Speicher, Telekommunikationsgeräte und Endbenutzer. Wenn etwas fehlt, schreibt der Kunde direkt an uns oder den Verkäufer und es werden neue Eisenstücke hinzugefügt. Alles ist einfach.

Das System lässt sich in MS Active Directory- und RADIUS-Server für die allgemeine Autorisierung und Anwendung von Gruppenrichtlinien integrieren. So sieht die Systemarchitektur aus:
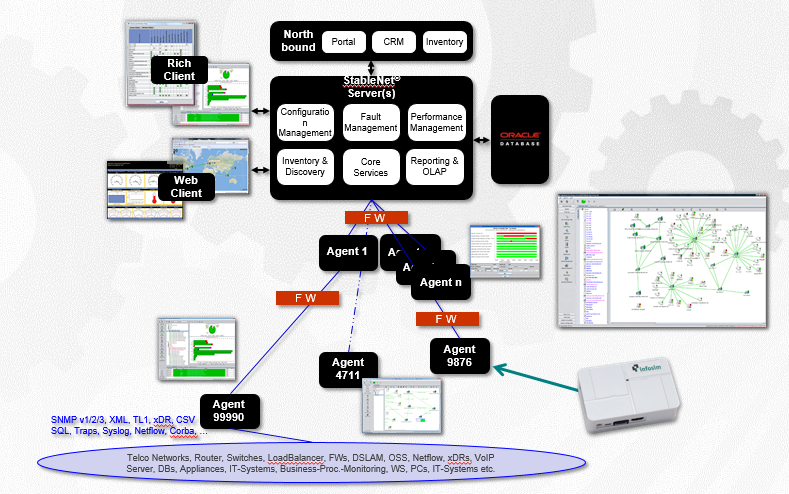
Der zentrale Server ist für die Verarbeitung und Anzeige der von der Hardware gesammelten Statistiken verantwortlich.
Die zweite wichtige Komponente ist der Agent, der für die Abfrage der Ausrüstung und die Überprüfung der Verfügbarkeit von Eisen verantwortlich ist. Es kann mehrere Agenten geben (Remote-Software). Wir haben ein geoverteiltes Thema mit einem Agenten für jeden Standort. Dies ist erforderlich, um den rohen Telemetrieverkehr nicht an die Mutterorganisation weiterzuleiten. Der Kunde verfügt über eine große Anzahl von Standorten, die über teure Satellitenkanäle verbunden sind, sodass nur das Messergebnis gesendet wird. Und eine Datenbank, in der alles gespeichert wird, was gesammelt wird.
Wenn der Remotestandort nicht verfügbar ist, können Mitarbeiter vor Ort eine direkte Verbindung zum Agenten herstellen und den Status ihres „Busches“ des Netzwerks anzeigen, auch ohne Zugriff auf den zentralen Server.
Ein Agent kann ein x64 / x86-Server sein, auf dem RedHat, CentOS, Ubuntu, Windows Server (für große Plattformen) ausgeführt wird, oder ein Mikroagent, der auf kleinen ARM-Computern wie Raspberry PI (für kleine Plattformen) basiert. Wir laden den Kanal nicht mit Eisen-Pings, der Agent macht das und aggregiert bereits Pakete mit Statistiken.

Wir können auch Verzögerungen, Jitter und Jitter-Variationen für Cisco-Geräte (IP SLA) und Huawei (NQA) entfernen. Wenn der Kunde in Zukunft etwas anderes Eisen hinzufügt, hat das Unternehmen keine Probleme. Wir können daher auch helfen, Kanalqualitätsindikatoren zu messen, synthetische Tests durchzuführen und Kommunikationskanäle für Lasttests zwischen Agenten zu testen.
Das Überwachungssystem kann Syslog-Nachrichten und SNMP-Traps von Iron empfangen, filtern und Alarmmeldungen generieren. Es erstellt automatisch die Topologie auf den Ebenen L2 und L3 und basierend darauf werden die Abhängigkeiten von Notfallsituationen (Ursachenanalyse) automatisch konfiguriert. Dies ist sehr cool, da Administratoren über die Grundursache des Unfalls informiert werden können, wodurch sich die für die Behebung des Unfalls erforderliche Zeit verringert. Wenn beispielsweise in einer Kette von fünf Schaltern einer in der Mitte abfällt, wird eine Meldung angezeigt, dass der dritte Schalter (Grundursache) abgefallen ist und der vierte und fünfte aus diesem Grund nicht verfügbar sind.

Die Lösung funktioniert sofort, aber der Prozess kann angepasst werden. Um beispielsweise die Arbeit unseres technischen Supports zu erleichtern, haben wir den Status der unterbrechungsfreien Stromversorgung und den Stromstatus „hinzugefügt“: Wenn die Stromversorgung auf der Baustelle ausgeschaltet wird, erhalten wir anstelle von 30 Alarmen einen für die Stromversorgung. Die Korrelation erfolgt nach Topologie, Benutzern und Regeln.
Es gibt eine Gruppenkonfiguration von Geräten. Sie können die Hardware nicht nur passiv abfragen, sondern auch Konfigurationen wie Einstellungen für die Switches bereitstellen. Vlan oder ntp auf 40 Switches registrieren? Einfach!
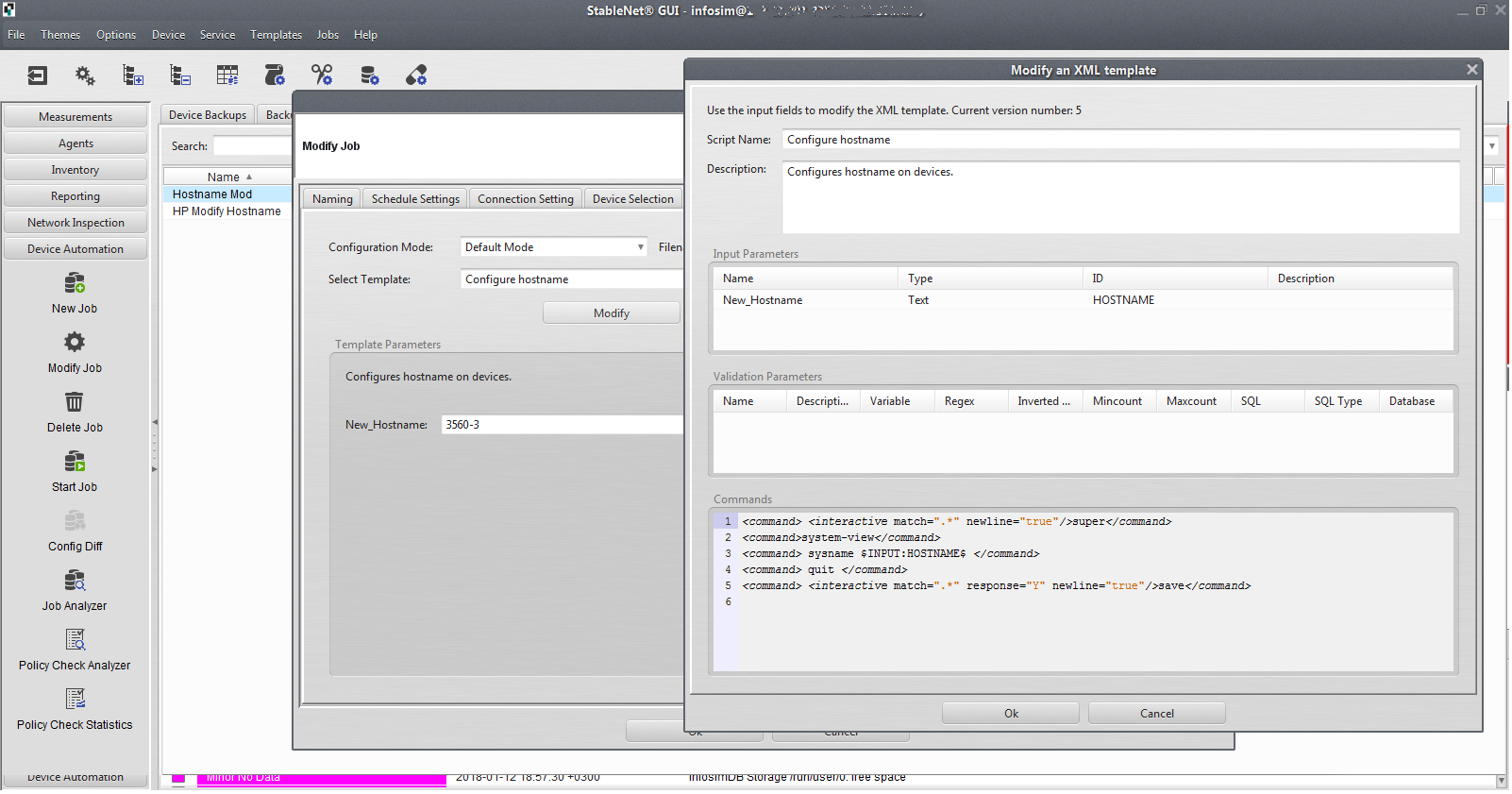
Es ist auch sehr cool, dass das System es dem Kunden ermöglicht, die Gerätekonfiguration nach einem Zeitplan zu sichern: einmal täglich oder während eines Ereignisses Konfigurationen erfassen (z. B. eine Meldung über eine Konfigurationsänderung - Sie können eine Aufgabe einrichten, die in dem Moment ausgeführt wird, in dem das Ereignis eintritt, und die geänderte Konfiguration erfassen). Das Gleiche gilt für die Rampen, für Notfälle. Dies wird bei der „Nachbesprechung“ und der Suche nach den Hauptverantwortlichen für die Konfigurationsänderungen sehr hilfreich sein. Außerdem wird eine aktuelle Datenbank aller Gerätekonfigurationen im Netzwerk erstellt.
Es gibt eine API für die Integration. In unserem Projekt wurde die Überwachung der Integration in CMDB 1C durchgeführt: ITIL Enterprise Information Technology Management zum Speichern aller Informationen über Geräte (Sachanlagen). Die Umfrageinformationen werden mit dem Inhalt der Assets verglichen. Wenn nicht erfasste Geräte erkannt werden, sagt das System: "Hier ist ein unverständlicher Schalter." Finden Sie heraus, was es ist, sie verstopfen alle erforderlichen Felder - Installationsort, Name usw. Die Seriennummer, der Name, die Teilenummer und die Firmware-Version werden von der Hardware bezogen. Als nächstes wird die Aufgabe zur Überwachung gesendet - der Name des Eisenstücks im System wird geändert, es wird auf die richtige Position im Standortbaum gesetzt, die Überwachungseinstellungen werden abhängig von der Art des Eisenstücks angewendet (z. B. sollten Grenzgeräte häufiger abgefragt werden als die übrigen), der Hostname auf dem Gerät selbst wird geändert usw. d.
Feldprozess
Zunächst haben wir die Integration mit AD eingerichtet. Dies hat uns das Leben sowohl bei der Implementierung als auch im späteren Betrieb erleichtert. Sie müssen nicht jedes Mal Konten für Benutzer erstellen und löschen. Das System erhält automatisch alle aktiven Konten von AD. Wenn plötzlich jemand kündigt, deaktiviert das System selbst dieses Konto zu Hause und niemand anderes kann es betreten.
Für Administratoren und das mittlere Management bestand eine sehr dringende Aufgabe darin, viele Berichte zu erhalten. Während des Starts wurden Berichte über die Nutzung und Zugänglichkeit von Kanälen, über die Verfügbarkeit von Drüsen an den Standorten, Top-Notfallsituationen, Berichte über bestimmte Arten von Unfällen, Betriebssystemversionen, Berichte über Änderungen in der Gerätekonfiguration und andere konfiguriert.
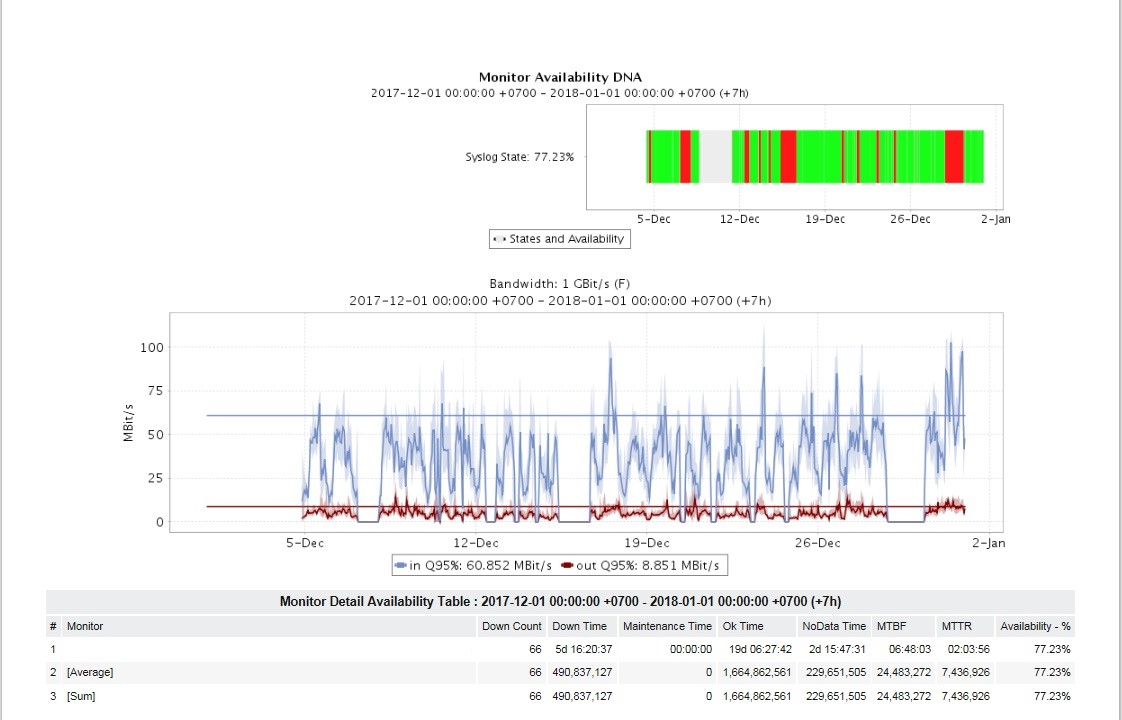
Berichte können im HTML-Format angezeigt und per E-Mail im PDF- und XLSX-Format mit der gewünschten Häufigkeit (einmal pro Tag, Woche, Monat usw.) empfangen werden. Für verschiedene Berichte wurde eine eigene Häufigkeit und persönliche Ausrichtung des Berichtskonsumenten festgelegt.
Das System bietet außerdem die Flexibilität, im Notfall benutzerdefinierte Aktionen zu benachrichtigen und auszuführen, E-Mail-Nachrichten und SMS-Nachrichten (über ein externes SMS-Gateway) zu senden und eigene Skripte zu schreiben, die gestartet werden. Zum Beispiel haben wir in unserem Cloud-Überwachungsdienst einen Telegramm-Bot erstellt, der verantwortliche Mitarbeiter in unserem Betriebsdienst über Notfallsituationen informiert. Es kann auch für verschiedene Parameter abgefragt werden: "CPU, 10.1.1.100" gibt "95%" zurück, aber angesichts der Unterstützung einer mobilen Anwendung scheint dies ein wenig redundant zu sein, obwohl es praktisch ist.
Als nächstes haben wir ein Skript zur Integration in die Telefonzentrale geschrieben. Wenn nun eine megakritische Situation auftritt (Stromausfall an kritischen Standorten oder Rechenzentren), ruft das System verantwortliche Personen auf Mobiltelefonen an und sagt mit einer Stimme wie Siri: „Die Spannung an einem solchen Objekt liegt unter einem kritischen Wert.“ Dies geschieht ganz einfach: Der Unfall wird in einem bestimmten Ordner der Telefonzentrale dupliziert, wo er vom Telefoniedienst verarbeitet wird. Sie müssen lediglich im Voraus die Nummern angeben, bei denen automatisch angerufen werden soll. Tatsächlich haben wir den Prozess der Benachrichtigung der zuständigen Administratoren oder des Managements im Falle eines Unfalls automatisiert. Mit anderen Worten, sie ersetzten die Person, die den Unfall anrufen und melden sollte.
Sehr bequeme Suchfunktion für Benutzer und Drüsen. Der Benutzer ruft an und sagt: "Mein Netzwerk funktioniert nicht." An der IP-Adresse können Sie sofort erkennen, wo es angeschlossen ist (welcher Switch, welcher Port, welche Mohnblume) und wo es zuvor angeschlossen war:

Sie können verschiedene Arten von Grafiktopologien erstellen, die Ingenieuren das Leben erleichtern. Sie müssen zum Beispiel sehen, wo wir eine Art Schalter haben. Es ist ganz einfach: Sie haben es im rechten Zweig gefunden (oder die Suche verwendet) und die Nachbarn geöffnet. Es werden mehrere Nachbarschaftsebenen unterstützt (die erste sind unmittelbare Nachbarn, die zweite sind Nachbarn von Nachbarn usw.). Und Sie können sofort sehen, wo sich unser Switch in der Topologie befindet, welche Ports und wo er angeschlossen ist, welche Mohnadressen sich an den Ports befinden. Oder schauen Sie sich die Protokollkarte OSPF, BGP, EIGRP, STP, PIM, MPLS an - das System verarbeitet und zeichnet dies alles selbst.

Oder sehen Sie visuell, wie sich das Netzwerk auf einer der Websites "anfühlt". Der Einfachheit halber haben wir die Teile der WAN- und LAN-Standorte aufgeteilt und mit separaten Karten gezeichnet. Alle Indikatoren und Links sind interaktiv. Wenn Sie mit der Maus darüber fahren, können Sie den aktuellen Status anzeigen und in ein bestimmtes Gerät fallen. Ich möchte auch darauf hinweisen, dass das Schema von Microsoft Visio, das vom Ingenieur selbst erstellt wurde, als Substrat für einen solchen Bericht verwendet wird. Er sah dieses Schema oft als statisches Bild auf Papier oder auf einem Bildschirm. Jetzt wird es „lebendig“ und bietet Echtzeit-Feedback. Sehr bequem.

Entsprechend den Anforderungen des Kunden wurden Benutzerzugriffsrechte abgegrenzt. Es gibt viele Rollen, aber sie sind flexibel konfiguriert. Angesichts der unterschiedlichen Zeitzonen zwischen Objekten war die Funktion der Arbeitsstunden in Rollen sehr nützlich: zu welcher Zeit, für welche Unfälle, an wen SMS und so weiter.
InfoSim StableNet sammelt Vorfallstatistiken. Nach unserer Erfahrung gibt es in solchen Fällen Probleme mit der geplanten Arbeit - sie verderben die Berichte und verursachen unnötige Sorgen. Hier kann angemerkt werden, dass hier und da Arbeit sein wird: Dann werden die Alarme in den stillen Modus versetzt, und der Bericht zeigt in einer anderen Farbe an, dass diese Ausfallzeit ein Plan ist. Ja, geplante Aktivitäten werden nicht rückwirkend angekündigt.

Wenn nicht genügend Möglichkeiten vorhanden sind, können Sie selbst geschriebene Vorlagen erstellen. Zum Beispiel gab es Motorola Access Points im Projekt. Es gab keine vorgefertigten Vorlagen für sie. Mit dem integrierten „Assistenten“ haben wir Vorlagen erstellt und die Parameter überwacht, die der Kunde sehen wollte (Signalpegel, Signal-Rausch-Verhältnis).
Es gab einen anderen Fall, in dem das System einen russischen Hersteller „nicht verstand“ und den Herstellercode anstelle eines Namens anzeigte. In diesem Fall verfügt das System über Funktionen, mit denen Sie in Sekundenschnelle neue Anbieter und Hardwaremodelle hinzufügen können.
Hier ist die Liste der Funktionen, die das Überwachungssystem dem Kunden derzeit ermöglicht:
- Überwachen Sie die Verfügbarkeit mithilfe von ICMP-Pings.
- Sammeln Sie Informationen mit SNMP.
- Subnetze nach neuer Hardware durchsuchen.
- Senden Sie Berichte nach Zeitraum.
- Implementieren Sie Sicherungskonfigurationen.
- Verfügbarkeit analysieren.
- „Alarm auslösen“ über die Nichtverfügbarkeit von Geräten oder die Ausgabe von Anzeigen außerhalb des normalen Bereichs.
- Skript-SNMP-Traps als Trigger, Syslog-Daten und alle Eingaben.
- In AD integrieren.
- Erkennen Sie automatisch die Gerätekonnektivität (CDP, LLDP, L3-Nachbarschaft) und zeichnen Sie darauf basierend automatisch eine Netzwerkkarte.
- Erstellen Sie "Wetterkarten", um den Status des Netzwerks zu visualisieren und grafische Substrate zu verwenden.
- Erstellen Sie Arbeitsbildschirme (Dashboards), um Betriebsinformationen zum Status des Netzwerks und der Geräte anzuzeigen.
- Führen Sie eine Bestandsaufnahme der Geräte durch (Gerätetyp, Hersteller, Modell, Softwareversion, Zeitpunkt des EoS / EoL-Datums usw.).
- Es gibt eine REST-API für die tiefe Integration mit CMDB 1C und anderen externen Systemen.
- Führen Sie die Gruppenkonfiguration der Geräte über das Überwachungssystem durch.
- Überprüfen Sie die Gerätekonfiguration auf Unternehmensrichtlinien
Referenzen
-
First Line Support Bikes.-
Kommunikationskanäle für Mineralvorkommen.- Meine Mail: DDrozhzhin@croc.ru