Im modernen Internet enthalten mehr als 630 Millionen Websites, von denen jedoch nur 6% russischsprachige Inhalte enthalten. Die Sprachbarriere ist das Hauptproblem der Wissensverbreitung zwischen Netzwerkbenutzern, und wir glauben, dass sie nicht nur durch den Unterricht von Fremdsprachen, sondern auch durch die automatische maschinelle Übersetzung im Browser gelöst werden muss.
Heute werden wir Habr-Lesern von zwei wichtigen technologischen Veränderungen im Yandex.Browser-Übersetzer erzählen. Erstens verwendet die Übersetzung ausgewählter Wörter und Phrasen jetzt ein Hybridmodell, und wir erinnern uns, wie sich dieser Ansatz von der Verwendung ausschließlich neuronaler Netze unterscheidet. Zweitens berücksichtigt das neuronale Netzwerk des Übersetzers nun die Struktur von Webseiten, deren Merkmale wir auch unter dem Schnitt diskutieren werden.
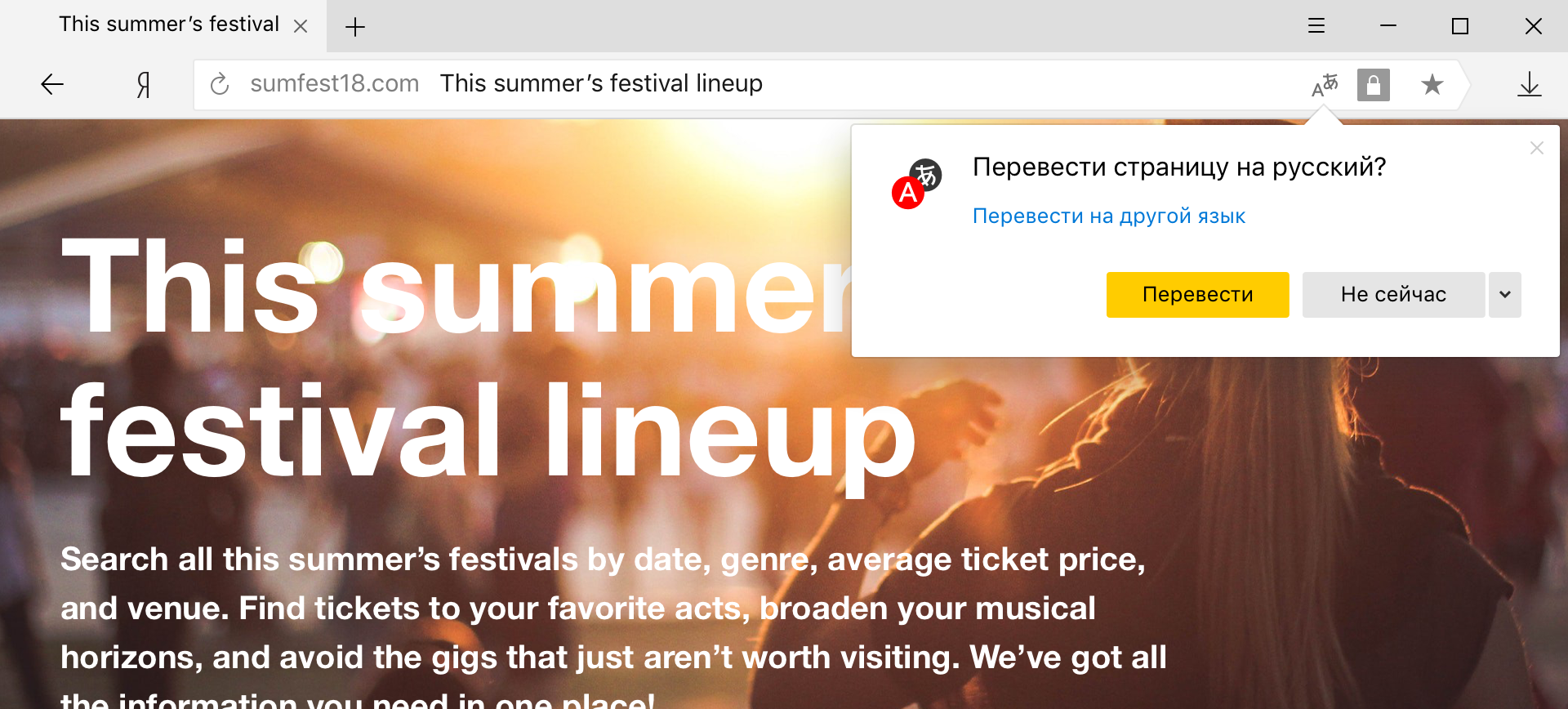
Hybrider Wort- und Phrasenübersetzer
Die ersten maschinellen Übersetzungssysteme basierten auf
Wörterbüchern und Regeln (tatsächlich handgeschriebene Stammgäste), die die Qualität der Übersetzung bestimmten. Professionelle Linguisten haben jahrelang daran gearbeitet, immer detailliertere manuelle Regeln zu entwickeln. Diese Arbeit war so zeitaufwändig, dass nur den beliebtesten Sprachpaaren ernsthafte Aufmerksamkeit geschenkt wurde, aber selbst im Rahmen dieser Sprachen kamen die Maschinen schlecht zurecht. Lebendige Sprache ist ein sehr komplexes System, das die Regeln schlecht befolgt. Noch schwieriger ist es, die Korrespondenzregeln der beiden Sprachen zu beschreiben.
Die einzige Möglichkeit, die Maschine ständig an sich ändernde Bedingungen anzupassen, besteht darin, unabhängig von einer großen Anzahl paralleler Texte zu lernen (identische Bedeutung, jedoch in verschiedenen Sprachen geschrieben). Dies ist der statistische Ansatz für die maschinelle Übersetzung. Der Computer vergleicht parallele Texte und zeigt unabhängig voneinander Muster an.
Ein
statistischer Übersetzer hat sowohl Vor- als auch Nachteile. Einerseits erinnert er sich gut an seltene und komplexe Wörter und Sätze. Wenn sie in parallelen Texten gefunden wurden, merkt sich der Übersetzer diese und setzt die korrekte Übersetzung fort. Andererseits kann das Ergebnis der Übersetzung dem zusammengesetzten Puzzle ähnlich sein: Das Gesamtbild scheint verständlich zu sein, aber wenn Sie genau hinschauen, können Sie sehen, dass es aus einzelnen Teilen besteht. Der Grund ist, dass der Übersetzer einzelne Wörter in Form von Bezeichnern präsentiert, die in keiner Weise die Beziehung zwischen ihnen widerspiegeln. Dies entspricht nicht der Wahrnehmung von Sprache durch Menschen, wenn Wörter davon abhängen, wie sie verwendet werden, wie sie sich auf andere Wörter beziehen und wie sie sich von ihnen unterscheiden.
Neuronale Netze helfen, dieses Problem zu lösen. Die in der neuronalen maschinellen Übersetzung verwendete Vektordarstellung von Wörtern (Worteinbettung) stimmt in der Regel jedes Wort mit einem Vektor überein, der mehrere hundert Zahlen lang ist. Vektoren werden im Gegensatz zu einfachen Identifikatoren aus einem statistischen Ansatz während des Trainings eines neuronalen Netzwerks gebildet und berücksichtigen die Beziehung zwischen Wörtern. Ein Modell kann beispielsweise erkennen, dass, da „Tee“ und „Kaffee“ häufig in ähnlichen Kontexten vorkommen, beide Wörter im Kontext des neuen Wortes „Verschütten“ möglich sein sollten, von dem beispielsweise nur eines in den Trainingsdaten gefunden wurde.
Der Prozess des Lehrens von Vektordarstellungen ist jedoch statistisch deutlich anspruchsvoller als das mechanische Speichern von Beispielen. Darüber hinaus ist nicht klar, was mit diesen seltenen Eingabewörtern zu tun ist, die nicht oft genug erfüllt wurden, damit das Netzwerk eine akzeptable Vektordarstellung für sie erstellen kann. In dieser Situation ist es logisch, beide Methoden zu kombinieren.
Seit letztem Jahr verwendet Yandex.Translator ein
Hybridmodell . Wenn der Übersetzer Text vom Benutzer empfängt, gibt er ihn an beide Systeme weiter - sowohl an das neuronale Netzwerk als auch an den statistischen Übersetzer. Dann bewertet ein Algorithmus, der auf der
CatBoost- Trainingsmethode basiert, welche Übersetzung besser ist. Bei der Bewertung werden Dutzende von Faktoren berücksichtigt - von der Länge des Satzes (kurze Sätze werden vom statistischen Modell besser übersetzt) bis zur Syntax. Die als die beste anerkannte Übersetzung wird dem Benutzer angezeigt.
Es ist das Hybridmodell, das jetzt in Yandex.Browser verwendet wird, wenn der Benutzer bestimmte Wörter und Ausdrücke auf der Seite für die Übersetzung auswählt.
Dieser Modus ist besonders praktisch für diejenigen, die im Allgemeinen eine Fremdsprache sprechen und nur unbekannte Wörter übersetzen möchten. Wenn Sie beispielsweise anstelle des üblichen Englisch auf Chinesisch stoßen, ist es hier schwierig, auf einen Seitenübersetzer zu verzichten. Es scheint, dass der Unterschied nur im Umfang des übersetzten Textes liegt, aber nicht so einfach.
Web Neural Network Translator
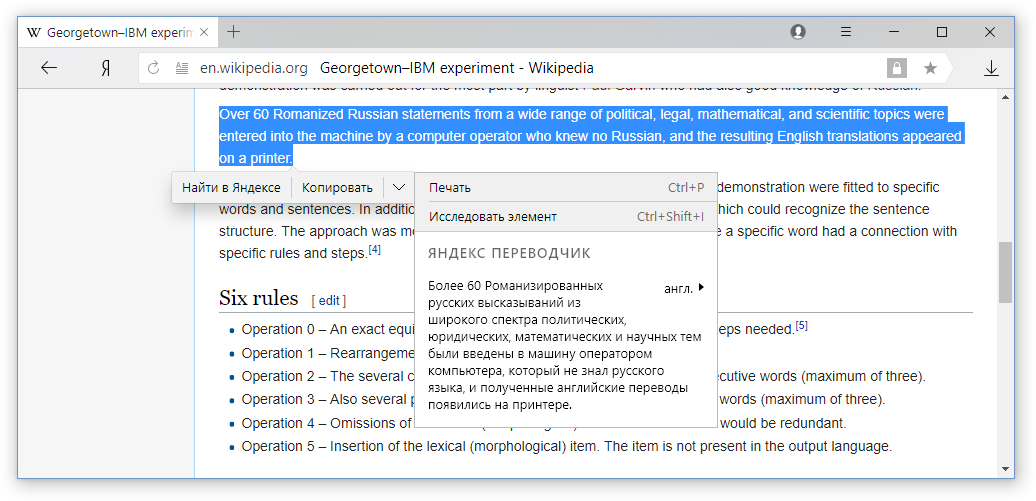
Von der Zeit des
Georgetown-Experiments bis fast heute wurden alle maschinellen Übersetzungssysteme darauf trainiert, jeden Satz des Quelltextes einzeln zu übersetzen. Während eine Webseite nicht nur eine Reihe von Sätzen ist, sondern ein strukturierter Text, in dem sich grundlegend unterschiedliche Elemente befinden. Betrachten Sie die Grundelemente der meisten Seiten.
Überschrift . Normalerweise heller und großer Text, den wir sofort sehen, wenn Sie zur Seite gehen. Die Überschrift enthält häufig die Essenz der Nachrichten. Daher ist es wichtig, sie korrekt zu übersetzen. Dies ist jedoch schwierig, da der Text im Titel klein ist und Sie einen Fehler machen können, ohne den Kontext zu verstehen. Bei der englischen Sprache ist dies noch komplizierter, da englischsprachige Überschriften häufig Phrasen mit nicht traditioneller Grammatik, Infinitiven oder sogar fehlenden Verben enthalten. Zum Beispiel kündigte
Game of Thrones Prequel an .
Navigation Wörter und Ausdrücke, die uns beim Navigieren auf der Website helfen. Zum Beispiel sind "Startseite", "Zurück" und "Mein Konto" kaum eine Übersetzung in "Startseite", "Zurück" und "Mein Konto" wert, wenn sie sich im Menü der Website und nicht im Veröffentlichungstext befinden.
Der Haupttext . Bei ihm ist alles einfacher, er unterscheidet sich kaum von gewöhnlichen Texten und Sätzen, die wir in Büchern finden können. Aber auch hier ist es wichtig, die Konsistenz der Übersetzungen sicherzustellen, dh sicherzustellen, dass innerhalb derselben Webseite dieselben Begriffe und Konzepte auf dieselbe Weise übersetzt werden.
Für eine qualitativ hochwertige Übersetzung von Webseiten reicht es nicht aus, ein neuronales Netzwerk oder ein Hybridmodell zu verwenden. Sie müssen auch die Struktur der Seiten berücksichtigen. Und dafür mussten wir uns mit vielen technologischen Schwierigkeiten auseinandersetzen.
Klassifizierung von Textsegmenten . Dazu verwenden wir wieder CatBoost und Faktoren, die sowohl auf dem Text selbst als auch auf dem HTML-Markup von Dokumenten basieren (Tag, Textgröße, Anzahl der Links pro Texteinheit, ...). Die Faktoren sind ziemlich heterogen, daher zeigt CatBoost (basierend auf Gradientenverstärkung) die besten Ergebnisse (Klassifizierungsgenauigkeit liegt über 95%). Eine Segmentklassifizierung allein reicht jedoch nicht aus.
Ungleichgewicht in den Daten . Traditionell lernen Yandex.Translator-Algorithmen Texte aus dem Internet. Es scheint, dass dies eine ideale Lösung für die Schulung eines Übersetzers von Webseiten ist (mit anderen Worten, das Netzwerk lernt aus Texten der gleichen Art wie die Texte, für die wir es verwenden werden). Sobald wir jedoch gelernt hatten, verschiedene Segmente voneinander zu trennen, fanden wir eine interessante Funktion. Im Durchschnitt machen Inhalte etwa 85% des gesamten Textes auf Websites aus, während Titel und Navigation jeweils nur 7,5% ausmachen. Denken Sie auch daran, dass sich die Überschriften und Navigationselemente in Stil und Grammatik deutlich vom Rest des Textes unterscheiden. Diese beiden Faktoren zusammen führen zu dem Problem des Datenversatzes. Für ein neuronales Netzwerk ist es rentabler, die Merkmale dieser sehr schlecht dargestellten Segmente im Trainingssatz einfach zu ignorieren. Das Netzwerk lernt, nur den Haupttext gut zu übersetzen, wodurch die Qualität der Übersetzung der Überschriften und der Navigation leidet. Um diesen unangenehmen Effekt zu neutralisieren, haben wir zwei Dinge getan: Für jedes Paar paralleler Sätze haben wir eine der drei Arten von Segmenten (Inhalt, Titel oder Navigation) als Metainformation zugeordnet und die Konzentration der beiden letzteren im Schulungsgebäude künstlich auf 33% erhöht begann häufiger ähnliche Beispiele für das lernende neuronale Netzwerk zu zeigen.
Multitasking lernen . Da wir jetzt in der Lage sind, Texte auf Webseiten in drei Klassen von Segmenten zu unterteilen, scheint es eine natürliche Idee zu sein, drei separate Modelle zu trainieren, von denen jedes die Übersetzung seiner eigenen Art von Texten - Überschriften, Navigation oder Inhalt - bewältigen wird. Das funktioniert wirklich gut, aber das Schema funktioniert noch besser, wenn wir ein neuronales Netzwerk trainieren, um alle Arten von Texten gleichzeitig zu übersetzen. Der Schlüssel zum Verständnis liegt in der Idee des
Multi-Task-Lernens (MTL): Wenn es einen internen Zusammenhang zwischen mehreren maschinellen Lernaufgaben gibt, kann ein Modell, das lernt, diese Probleme gleichzeitig zu lösen, lernen, jedes der Probleme besser zu lösen als ein engmaschiges Spezialmodell!
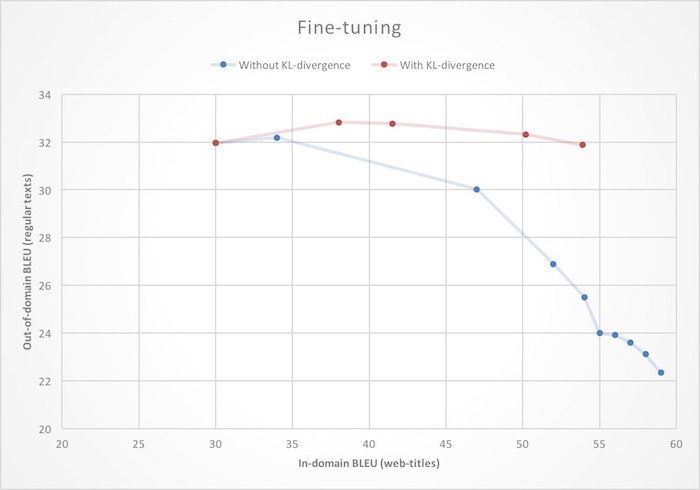
Feinabstimmung . Wir hatten bereits eine sehr gute maschinelle Übersetzung, daher wäre es unvernünftig, einen neuen Übersetzer für Yandex.Browser von Grund auf auszubilden. Es ist logischer, ein Basissystem für die Übersetzung gewöhnlicher Texte zu verwenden und es für die Arbeit mit Webseiten neu zu trainieren. Im Zusammenhang mit neuronalen Netzen wird dies häufig als Feinabstimmung bezeichnet. Wenn Sie sich dieser Aufgabe jedoch direkt nähern, d. H. Nur um die neuronalen Netzwerkgewichte mit den Werten aus dem fertigen Modell zu initialisieren und mit dem Lernen neuer Daten zu beginnen, kann es zu einer Domänenverschiebung kommen: Wenn Sie lernen, steigt die Qualität der Übersetzung von Webseiten (innerhalb der Domäne), aber die Qualität der Übersetzung gewöhnlicher (außerhalb der Domäne) ) Texte werden fallen. Um dieses unangenehme Merkmal während der Umschulung zu beseitigen, legen wir dem neuronalen Netz eine zusätzliche Einschränkung auf, die es verbietet, die Gewichte im Vergleich zum Ausgangszustand zu stark zu ändern.
Mathematisch wird dies ausgedrückt, indem der Verlustfunktion der Term hinzugefügt
wird, dh der Kullback-Leibler-Abstand (KL-Divergenz) zwischen den Wahrscheinlichkeitsverteilungen des nächsten Wortes, das von der Quelle erzeugt wird, und den umgeschulten Netzwerken. Wie Sie in der Abbildung sehen können, führt dies dazu, dass die Verbesserung der Qualität der Übersetzung von Webseiten nicht mehr zu einer Verschlechterung der Übersetzung von Klartext führt.
 Polieren von Frequenzphrasen aus der Navigation
Polieren von Frequenzphrasen aus der Navigation . Während der Arbeit an einem neuen Übersetzer haben wir Statistiken zu den Texten verschiedener Segmente von Webseiten gesammelt und eine interessante gesehen. Texte, die sich auf Navigationselemente beziehen, sind ziemlich standardisiert, daher handelt es sich häufig um dieselben Vorlagenphrasen. Dies ist ein so starker Effekt, dass mehr als die Hälfte aller im Internet gefundenen Navigationsphrasen nur zweitausend der häufigsten ausmachen.
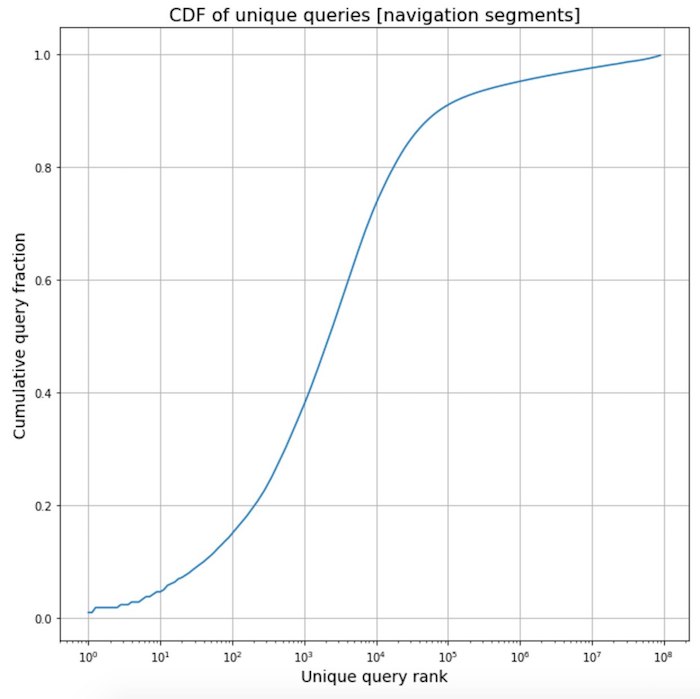
Natürlich haben wir dies ausgenutzt und unseren Übersetzern mehrere Tausend der häufigsten Sätze und deren Übersetzungen zur Überprüfung gegeben, um ihre Qualität absolut sicher zu stellen.
Externe Ausrichtungen. Es gab eine weitere wichtige Anforderung für einen Webseitenübersetzer im Browser - er sollte das Markup nicht verzerren. Wenn sich HTML-Tags außerhalb von Sätzen oder an deren Grenzen befinden, treten keine Probleme auf. Wenn der Satz beispielsweise
zwei unterstrichene Wörter enthält , möchten wir in der Übersetzung „zwei
unterstrichene Wörter“ sehen. Das heißt, Als Ergebnis der Übertragung müssen zwei Bedingungen erfüllt sein:
- Das unterstrichene Fragment in der Übersetzung muss dem unterstrichenen Fragment im Quelltext entsprechen.
- Die Konsistenz der Übersetzung an den Rändern des unterstrichenen Fragments sollte nicht verletzt werden.
Um dieses Verhalten sicherzustellen, übersetzen wir zuerst den Text wie gewohnt und bestimmen dann mithilfe statistischer Modelle der wortweisen
Ausrichtung die Entsprechung zwischen Fragmenten des ursprünglichen und des übersetzten Textes. Dies hilft zu verstehen, was hervorgehoben werden muss (kursiv hervorheben, als Hyperlink formatieren, ...).
Kreuzungsbeobachter . Die von uns trainierten leistungsstarken Übersetzungsmodelle für neuronale Netze erfordern auf unseren Servern (sowohl CPU als auch GPU) erheblich mehr Rechenressourcen als die statistischen Modelle früherer Generationen. Gleichzeitig lesen Benutzer die Seiten nicht immer bis zum Ende, sodass das Senden des gesamten Textes von Webseiten an die Cloud nicht erforderlich ist. Um Serverressourcen und Benutzerverkehr zu sparen, haben wir dem Übersetzer beigebracht, die
Intersection Observer-API zu verwenden, um nur den Text zu senden, der auf dem Bildschirm zur Übersetzung angezeigt wird. Dadurch konnten wir den Verkehrsverbrauch für Übersetzungen um mehr als das Dreifache reduzieren.
Einige Worte zu den Ergebnissen der Einführung eines Übersetzers für neuronale Netze unter Berücksichtigung der Struktur von Webseiten in Yandex.Browser. Um die Qualität von Übersetzungen zu beurteilen, verwenden wir die BLEU * -Metrik, die Übersetzungen von einer Maschine und einem professionellen Übersetzer vergleicht und die Qualität der maschinellen Übersetzung auf einer Skala von 0 bis 100% bewertet. Je näher die maschinelle Übersetzung an der menschlichen Übersetzung liegt, desto höher ist der Prozentsatz. Normalerweise bemerken Benutzer eine Qualitätsänderung, wenn die BLEU-Metrik um mindestens 3% wächst. Der neue Yandex.Browser-Übersetzer verzeichnete eine Steigerung von fast 18%.

Die maschinelle Übersetzung ist eine der komplexesten, heißesten und erforschten Aufgaben im Bereich der Technologien für künstliche Intelligenz. Dies liegt an seiner rein mathematischen Attraktivität und seiner Relevanz in der modernen Welt, in der jede Sekunde eine unglaubliche Menge an Inhalten im Internet in verschiedenen Sprachen erstellt wird. Die maschinelle Übersetzung, die bis vor kurzem hauptsächlich zum Lachen führte (denken Sie an
Maushersteller ), hilft Benutzern heutzutage, Sprachbarrieren zu überwinden.
Die ideale Qualität ist noch weit entfernt, daher werden wir uns weiterhin auf dem neuesten Stand der Technik in diese Richtung bewegen, damit Yandex.Browser-Benutzer beispielsweise über Runet hinausgehen und überall im Internet nützliche Inhalte für sich finden können.