Bildverarbeitung ist heutzutage ein sehr heißes Thema. Um das Problem der Erkennung von Store-Tags mithilfe neuronaler Netze zu lösen, haben wir das TensorFlow-Framework gewählt.
In diesem Artikel wird genau erläutert, wie Sie damit mehrere Objekte auf demselben Ladenpreisschild lokalisieren und identifizieren sowie deren Inhalt erkennen können.
Eine ähnliche Aufgabe zum Erkennen von IKEA-Preisschildern wurde bei Habré bereits mit klassischen Bildverarbeitungswerkzeugen
gelöst, die in der OpenCV-Bibliothek verfügbar sind.
Unabhängig davon möchte ich darauf hinweisen, dass die Lösung sowohl auf der SAP HANA-Plattform in Verbindung mit Tensorflow Serving als auch auf der SAP Cloud Platform funktionieren kann.
Die Aufgabe, den Preis von Waren zu erkennen, ist relevant für Käufer, die Preise miteinander "fummeln" und ein Geschäft für Einkäufe auswählen möchten, und für Einzelhändler - sie möchten die Preise der Wettbewerber in Echtzeit kennenlernen.
Genug der Texte - gehe zur Technik!
ToolkitFür die Erkennung und Klassifizierung von Bildern verwendeten wir Faltungs-Neuronale Netze, die in der TensorFlow-Bibliothek implementiert sind und über die Objekterkennungs-API gesteuert werden können.
Die TensorFlow-Objekterkennungs-API ist ein auf TensorFlow basierender Open-Source-Metaframe, der die Erstellung, Schulung und Bereitstellung von Modellen für die Objekterkennung vereinfacht.
Nach dem Erkennen des gewünschten Objekts wurde die Texterkennung mit Tesseract, einer Bibliothek zur Zeichenerkennung, durchgeführt. Seit 2006 gilt Tesseract als eine der genauesten OCR-Bibliotheken, die in Open Source verfügbar sind.
Es ist möglich, dass Sie eine Frage stellen - warum wird nicht die gesamte Verarbeitung auf TF durchgeführt? Die Antwort ist sehr einfach - es würde erheblich mehr Zeit für die Implementierung erfordern, aber es gab sowieso nicht viel davon. Es war einfacher, die Verarbeitungsgeschwindigkeit zu opfern und einen fertigen Prototyp zusammenzubauen, als sich mit einer selbst erstellten OCR zu beschäftigen.
Erstellung und Vorbereitung eines DatensatzesZunächst war es notwendig, Materialien für die Arbeit zu sammeln. Wir haben 3 Geschäfte besucht und ungefähr 400 Fotos von verschiedenen Preisschildern auf einer Handykamera im automatischen Modus aufgenommen
Beispielfotos: Abb. 1. Beispiel eines Preisschildbildes
Abb. 1. Beispiel eines Preisschildbildes Abb. 2. Beispiel eines Preisschildbildes
Abb. 2. Beispiel eines PreisschildbildesDanach müssen Sie alle Fotos von Preisschildern verarbeiten und markieren. Beim Sammeln von Bildern haben wir versucht, qualitativ hochwertige Bilder (ohne Artefakte) zu sammeln: Preisschilder mit ungefähr demselben Format, ohne Unschärfe, erhebliche Rotationen usw. Dies wurde durchgeführt, um einen weiteren Vergleich des Inhalts auf dem realen Preisschild und seinem digitalen Bild zu ermöglichen. Wenn wir das neuronale Netzwerk jedoch nur auf die verfügbaren Bilder hoher Qualität trainieren, führt dies ganz natürlich dazu, dass das Vertrauen des Modells in die Identifizierung verzerrter Beispiele erheblich sinkt. Um das neuronale Netzwerk so zu trainieren, dass es gegen solche Situationen resistent ist, haben wir das bekannte Verfahren zum Erweitern des Trainingssatzes mit verzerrten Versionen von Bildern verwendet (Augmentation). Als Ergänzung zum Trainingsbeispiel haben wir Algorithmen aus der Imgaug-Bibliothek angewendet: Verschiebungen, kleine Kurven, Gaußsche Unschärfe, Rauschen. Der Probe wurden verzerrte Bilder hinzugefügt, wodurch sie um das Fünffache erhöht wurde (von 300 auf 1.500 Bilder).
Zum Markieren des Bildes und Auswählen von Objekten wurde das öffentlich zugängliche Programm LabelImg verwendet. Sie können die erforderlichen Objekte im Bild mit einem Rechteck auswählen und jede Klasse dem Begrenzungsrahmen zuweisen. Alle Koordinaten und Beschriftungen der erstellten Rahmen für jedes Foto werden in einer separaten XML-Datei gespeichert.
Die folgenden Objekte stachen auf jedem Foto hervor: Produktpreisschild, Produktpreis, Produktname und Produktbarcode auf dem Preisschild. In einigen Beispielen von Bildern, in denen dies logisch gerechtfertigt war, wurden die Bereiche mit Überlappungen markiert.
 Abb. 3. Ein Beispiel für ein Foto eines Paares von Preisschildern, die in LabelImg markiert sind. Bereiche mit Produktbeschreibung, Preis und Barcode werden hervorgehoben.
Abb. 3. Ein Beispiel für ein Foto eines Paares von Preisschildern, die in LabelImg markiert sind. Bereiche mit Produktbeschreibung, Preis und Barcode werden hervorgehoben. Abb. 4. Ein Beispiel für ein Foto eines in LabelImg gekennzeichneten Preisschilds. Bereiche mit Produktbeschreibung, Preis und Barcode werden hervorgehoben.
Abb. 4. Ein Beispiel für ein Foto eines in LabelImg gekennzeichneten Preisschilds. Bereiche mit Produktbeschreibung, Preis und Barcode werden hervorgehoben.Nachdem alle Fotos verarbeitet und markiert wurden, bereiten wir den Datensatz mit der Trennung aller Fotos und Tag-Dateien in ein Trainings- und Testmuster vor. Nehmen Sie normalerweise 80% der Trainingsprobe auf 20% der Testprobe und mischen Sie sie nach dem Zufallsprinzip.
Als nächstes müssen auf dem Computer, auf dem das Modell trainiert wird, alle erforderlichen Bibliotheken installiert werden. Zunächst installieren wir die TensorFlow-Bibliothek für maschinelles Lernen. Abhängig vom Typ Ihres Systems müssen Sie eine zusätzliche Bibliothek für die Datenverarbeitung auf der GPU installieren. Installieren Sie als Nächstes die Tensorflow-Objekterkennungs-API-Bibliothek und zusätzliche Bibliotheken für die Arbeit mit Bildern und Grafiken. Unten finden Sie eine Liste der Bibliotheken, die wir in unserer Arbeit verwendet haben:
TensorFlow-GPU v1.5, CUDA v9.0, cuDNN v7.0
Protobuf 3+, Python-tk, Pillow 1.0, lxml, tf Slim, Jupyter-Notizbuch, Matplotlib
Tensorflow, Cython, Cocoapi; Opencv-Python; PandasWenn alle Installationsschritte abgeschlossen sind, können Sie mit der Vorbereitung der Daten und der Einstellung der Lernparameter fortfahren.
ModelltrainingUm unser Problem zu lösen, haben wir zwei Versionen des vorab trainierten neuronalen Netzwerks MobileNet V2 und Faster-RCNN V2 im Coco-Dataset als Bildeigenschaftsextraktoren verwendet. Die Modelle wurden in 4 neue Klassen umgeschult: Preisschild, Produktbeschreibung, Preis, Barcode. Als Hauptmodell haben wir uns für MobileNet V2 entschieden, ein relativ einfaches Modell, mit dem wir akzeptable Qualität bei angenehmer Geschwindigkeit liefern können. Mit MobileNet V2 können Sie die Bilderkennung auch auf einem mobilen Gerät implementieren.
Zunächst müssen Sie der Tensorflow Object Detection-API-Bibliothek die Anzahl der Beschriftungen sowie die Namen dieser Beschriftungen mitteilen.
Das letzte, was Sie vor dem Training tun müssen, ist, eine Verknüpfungszuordnung zu erstellen und die Konfigurationsdatei zu bearbeiten. Die Beschriftungszuordnung informiert das Modell und ordnet Klassennamen Klassenidentifikationsnummern für jedes Objekt zu.

Schließlich müssen Sie die Lernquellen für die Objekterkennung konfigurieren, um zu bestimmen, welches Modell und welche Parameter für das Training verwendet werden. Dies ist der letzte Schritt vor Beginn des Trainings.

Der Trainingsvorgang wird mit dem folgenden Befehl gestartet:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/mobilenet.config
Wenn alles richtig konfiguriert ist, initialisiert TensorFlow die Umschulung des neuronalen Netzwerks. Die Initialisierung kann bis zu 30 Sekunden dauern, bevor das eigentliche Training beginnt. Wenn das neuronale Netzwerk bei jedem Schritt umgeschult wird, wird der Wert der Algorithmusfehlerfunktion (Verlust) angezeigt. Für MobileNet V2 beträgt der Anfangswert der Verlustfunktion ungefähr 20. Das Modell sollte trainiert werden, bis die Verlustfunktion auf einen Wert von ungefähr 2 abfällt. Um den Lernprozess des neuronalen Netzwerks zu visualisieren, können Sie das praktische Dienstprogramm TensorBoard verwenden.
: tensorboard
Der Befehl initialisiert die Weboberfläche auf dem lokalen Computer, die unter localhost: 6006 verfügbar sein wird. Nach dem Stoppen kann der Trainingsvorgang später mithilfe von Kontrollpunkten fortgesetzt werden, die alle 5 Minuten gespeichert werden.
Erkennung von Preisschildern und deren ElementenWenn das Training abgeschlossen ist, besteht der letzte Schritt darin, einen neuronalen Netzwerkgraphen zu erstellen. Dies erfolgt über den Konsolenbefehl, bei dem Sie unter den Sternchen die größte Anzahl von cpkt-Dateien angeben müssen, die im Trainingsverzeichnis vorhanden sind.
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2.config --trained_checkpoint_prefix training/model.ckpt-**** --output_directory inference_graph
Nach diesem Vorgang ist der Objekterkennungsklassifizierer betriebsbereit. Um die Bilderkennung zu überprüfen, reicht es aus, ein Skript auszuführen, das mit der Tensorflow-Objekterkennungsbibliothek geliefert wird und das zuvor trainierte Modell und Fotos zur Erkennung angibt. Ein Standardbeispiel für Python-Skripte finden Sie
hier .
In unserem Beispiel dauert es ungefähr 1,5 Sekunden, um ein Foto mit dem Modell ssd mobilet auf einem einfachen Laptop zu erkennen.
 Abb. 5. Das Ergebnis der Erkennung von Bildern mit Preisschildern im Testmuster
Abb. 5. Das Ergebnis der Erkennung von Bildern mit Preisschildern im Testmuster Abb. 6. Das Ergebnis der Erkennung von Bildern mit Preisschildern im Testmuster
Abb. 6. Das Ergebnis der Erkennung von Bildern mit Preisschildern im TestmusterWenn wir davon überzeugt sind, dass die Preisschilder normal erkannt werden, muss das Modell lernen, Informationen aus einzelnen Elementen zu lesen: dem Preis der Waren, dem Namen der Waren und einem Strichcode. Zu diesem Zweck stehen in Python Bibliotheken zur Erkennung von Zeichen und Barcodes in Fotografien zur Verfügung - Pyzbar und Tesseract.
Bevor Sie Zeichen und Barcodes in einem Foto erkennen, müssen Sie dieses Foto in die von uns benötigten Elemente schneiden, um die Geschwindigkeit zu erhöhen und unnötige Informationen nicht zu erkennen, die nicht im Preisschild enthalten sind. Es ist auch notwendig, die Koordinaten von Objekten, die das Modell erkannt hat, zusammen mit ihren Klassen herauszuziehen.

Dann verwenden wir diese Koordinaten, um unser Foto in Teile zu schneiden, um nur den erforderlichen Bereich zu erkennen.


 Abb. 7. Ein Beispiel für hervorgehobene Teile des Preisschilds
Abb. 7. Ein Beispiel für hervorgehobene Teile des PreisschildsAls nächstes übertragen wir alle ausgeschnittenen Bereiche in die Bibliotheken: Der Produktname und der Preis des Produkts werden an tesseract und der Barcode an pyzbar übertragen, und wir erhalten das Erkennungsergebnis.

 Abb. 8. Ein Beispiel für erkannten Inhalt ist der Preisschildbereich.
Abb. 8. Ein Beispiel für erkannten Inhalt ist der Preisschildbereich.Zu diesem Zeitpunkt kann die Text- und Barcode-Erkennung Probleme verursachen, wenn das Originalbild eine niedrige Auflösung oder Unschärfe aufweist. Wenn der Preis aufgrund der großen Zahlen auf dem Preisschild normal erkannt werden kann, sind der Produktname und der Barcode schlecht oder gar nicht definiert. Zu diesem Zweck wird empfohlen, keine kleinen Fotos zur Erkennung zu verwenden und auch Bilder ohne Rauschen und starke Verzerrungen hochzuladen - beispielsweise ohne den richtigen Fokus.
Beispiel für eine schlechte Bilderkennung:



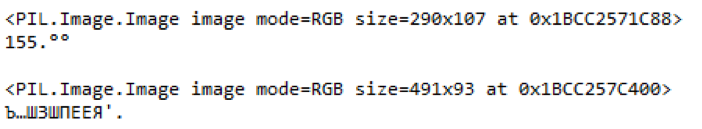 Abb. 9. Ein Beispiel für hervorgehobene Teile eines unscharfen Preisschilds und erkannten Inhalts
Abb. 9. Ein Beispiel für hervorgehobene Teile eines unscharfen Preisschilds und erkannten InhaltsIn diesem Beispiel können Sie sehen, dass die Bibliothek den Namen der Waren nicht verarbeiten konnte, wenn der Preis der Waren im Bild von schlechter Qualität mehr oder weniger korrekt erkannt wurde. Und der Barcode ist überhaupt nicht erkennbar.
Der gleiche Text in guter Qualität.

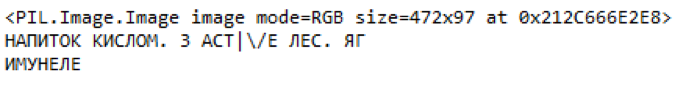 Abb. 10. Beispiel für hervorgehobene Preisschildteile und anerkannten InhaltSchlussfolgerungen
Abb. 10. Beispiel für hervorgehobene Preisschildteile und anerkannten InhaltSchlussfolgerungenAm Ende ist es uns gelungen, ein Modell von akzeptabler Qualität mit einem geringen Prozentsatz an Fehlern und einem hohen Prozentsatz an Erkennung relevanter Objekte zu erhalten. Schneller-RCNN Inception V2 hat eine bessere Erkennungsqualität als MobileNet SSD V2, ist jedoch in der Geschwindigkeit um eine Größenordnung schlechter, was eine erhebliche Einschränkung darstellt.
Die erhaltene Genauigkeit der Preisschilderkennung bei einer verzögerten Stichprobe von 50 Bildern beträgt 100%, dh alle Preisschilder wurden auf allen Fotos erfolgreich identifiziert. Die Erkennungsgenauigkeit von Bereichen mit Barcode und Preis betrug 90%. Die Erkennungsgenauigkeit des Textbereichs beträgt 85%. Die Genauigkeit der Preisablesung betrug etwa 95% und der Text 80-85%. Zusätzlich präsentieren wir als Experiment das Ergebnis der Preisschilderkennung, das sich vollständig von den Preisschildern im Trainingsbeispiel unterscheidet.
 Abb. 11. Ein Beispiel für die Erkennung atypischer Preisschilder, die nicht im Trainingssatz enthalten sind.
Abb. 11. Ein Beispiel für die Erkennung atypischer Preisschilder, die nicht im Trainingssatz enthalten sind.Wie Sie sehen können, sind die Modelle auch bei Preisschildern, die sich erheblich von Trainingspreisschildern unterscheiden, nicht fehlerfrei, aber auf dem Preisschild können wichtige Objekte erkannt werden.
Was könnte man noch tun?1) Kürzlich wurde ein cooler Artikel über automatische Augmentation veröffentlicht, dessen Ansatz verwendet werden kann
2) Das fertig trainierte Modell kann und sollte wesentlich komprimiert werden
3) Beispiele für die Veröffentlichung abgeschlossener Dienste in SCP und TFS
Bei der Vorbereitung des Prototyps und dieses Artikels wurden die folgenden Materialien verwendet:1.
Bringen Sie maschinelles Lernen (TensorFlow) mit SAP HANA in das Unternehmen2.
SAP Leonardo ML Foundation - Bringen Sie Ihr eigenes Modell mit (BYOM)3.
GitHub-Repository zur Erkennung von TensorFlow-Objekten4.
IKEA Check Recognition Article5.
Artikel über die Vorteile von MobileNet6.
Artikel zur TensorFlow-ObjekterkennungDer Artikel wurde erstellt von:
Sergey Abdurakipov, Dmitry Buslov, Alexey Khristenko