 Foto: Alexander Korolkov / WG
Foto: Alexander Korolkov / WGAm 3. Juni, am letzten Tag des Moskauer Buchfestivals auf dem Roten Platz, sprach der Linguist
Alexander Pipersky über Computerlinguistik. Er sprach über maschinelle Übersetzungen, neuronale Netze, Vektorkartierung von Wörtern und stellte Fragen zu den Grenzen der künstlichen Intelligenz.
Verschiedene Leute hörten der Vorlesung zu. Zu meiner Rechten zum Beispiel pickte eine chinesische Touristin ihre Nase. Natürlich verstand Alexander auch - ein paar zusätzliche Zahlen, Formeln und Wörter über Algorithmen, und die Leute rannten zum nächsten Zelt, um Science-Fiction-Autoren zuzuhören.
Ich bat Alexander, für Habr die "Regieversion" des Vortrags vorzubereiten, in der nichts herausgeschnitten wurde, was zufällige Touristen wiegen könnte. Schließlich fehlte dem größten Teil der Präsentation ein Publikum mit vernünftigen Fragen und allgemein einer guten Diskussion. Ich denke, wir können es hier entwickeln.
Wo fängt die KI an?
Seit kurzem kommunizieren wir ständig mit Computern in Sprache, und alle Arten von Alice, Alexa und Siri antworten uns. Wenn Sie von der Seite schauen, scheint es, dass der Computer uns versteht, Listen relevanter Websites ausgibt, die Adresse des nächsten Restaurants meldet und angibt, wie Sie dorthin gelangen.
Es sieht so aus, als hätten wir es mit einem ziemlich intelligenten Gerät zu tun. Man könnte sogar sagen, dass dieses Gerät über künstliche Intelligenz (KI) verfügt. Obwohl niemand wirklich versteht, was dies bedeutet und wohin die Grenzen gehen.
Wenn uns gesagt wird, "KI erfüllt kreative Funktionen, die als Vorrecht des Menschen gelten" - was bedeutet das? Was sind kreative Funktionen? Welche Funktion ist kreativ und welche nicht? Die Wahl des nächsten chinesischen Restaurants ist ein kreatives Merkmal? Jetzt scheint es, dass höchstwahrscheinlich nicht.
Wir neigen ständig dazu, einem Computer künstliche Intelligenz zu verweigern. Sobald wir uns an die intellektuellen Manifestationen eines Computers gewöhnt haben, sagen wir: "Dies ist keine KI, dies ist völliger Unsinn, Vorlagenaufgaben, nichts Interessantes."
Ein einfaches Beispiel - aus unserer Sicht gibt es nichts Dümmeres als einen Taschenrechner. Es wird in jedem Stand für 50 Rubel verkauft. Nehmen Sie den üblichen 8-Bit-Rechner, drücken Sie auf die Tasten und erhalten Sie das Ergebnis in Sekunden. Du denkst, er denkt einige Dinge. Das ist keine Intelligenz.
Und stellen Sie sich eine solche Maschine im 18. Jahrhundert vor. Es scheint ein Wunder zu sein, denn Berechnung war das Vorrecht des Menschen.
Das gleiche passiert mit der Computerlinguistik. Wir neigen dazu, all ihre Leistungen zu verachten. Ich gebe bei Google eine Abfrage "Puschkins Verse" ein. Er findet eine Seite mit der Aufschrift "A.S. Puschkin - Gedichte. " Es scheint, dass dies? Absolut normales Verhalten. Aber Computerlinguisten mussten Dutzende von Jahren damit verbringen, dass das Wort Gedicht in den Wortgedichten gefunden wurde, dass das Wort Puschkin im Wort Puschkin gefunden wurde und nicht in Puschkin.
Computerschach und maschinelle Übersetzung
Computerlinguistik wurde zur gleichen Zeit wie Computerschach geboren - und auch Schach war einst das Vorrecht des Menschen. Claude Shannon, einer der Begründer der Informatik, schrieb 1950
einen Artikel darüber, wie man einen Computer zum Schachspielen programmiert. Ihm zufolge können wir zwei Arten von Strategien entwickeln.
A - mit umfassender Suche nach Fortsetzungen. Es ist notwendig, alle möglichen Bewegungen in jeder Phase zu testen.
B - iterieren Sie nur über die Erweiterungen, die als vielversprechend bewertet werden.
Die Person verwendet offensichtlich die Strategie B. Der Großmeister geht höchstwahrscheinlich nur die Optionen durch, die seiner Meinung nach vernünftig sind, und gibt in relativ kurzer Zeit einen guten Schritt.
Strategie A ist schwer umzusetzen. Nach Shannons Berechnung müssen Sie 10 bis
9 Optionen aussortieren, um drei Züge zu zählen. Wenn die Position auf eine Mikrosekunde geschätzt wird (was Mitte des 20. Jahrhunderts sehr optimistisch war), dauert es 17 Minuten, um einen Zug auszuführen. Und drei Schritte vorwärts sind eine unbedeutende Tiefe der Vorhersage.
Die gesamte nachfolgende Geschichte des Schachs besteht in der Entwicklung von Techniken, die es uns ermöglichen, nicht alles zu sortieren, sondern zu verstehen, was aussortiert werden muss und was nicht. Und der Sieg über den Menschen ist bereits endgültig und unwiderruflich erreicht. Der Computer hat vor etwa 20 Jahren den Schachweltmeister umgangen und sich seitdem nur verbessert.
Das beste Programm wurde als Stockfisch angesehen. Letztes Jahr hat AlphaZero 100 Spiele mit ihr gespielt.
| Weiße | Schwarz | Weißer Sieg | Zeichnen | Der Sieg von Schwarz |
|---|
| AlphaZero | Stockfisch | 25 | 25 | 0 |
| Stockfisch | AlphaZero | 0 | 47 | 3 |
AlphaZero ist ein künstliches neuronales Netzwerk, das gerade vier Stunden lang mit sich selbst Schach gespielt hat. Und sie lernte besser zu spielen als alle Programme vor ihr.
Ähnliches geschieht derzeit in der Computerlinguistik - ein Anstieg der Modellierung neuronaler Netze. Gleichzeitig mit maschinellen Übersetzungen begannen sie Mitte des letzten Jahrhunderts mit der Arbeit am Maschinenschach. Seitdem wurden drei Entwicklungsstufen unterschieden.
- Regelbasierte maschinelle ÜbersetzungEs ist sehr einfach gestaltet - so etwas wie im Grammatikunterricht wählt der Computer das Thema, das Prädikat und die Addition aus. Er versteht, mit welchen Worten all dies in eine andere Sprache übersetzt wird, lernt, wie man dort Subjekt, Prädikat, Addition und alles ausdrückt.
Eine solche Übersetzung entwickelte sich über 30 Jahre und hatte nicht viel Erfolg.
- Statistische (Phrasen-) ÜbersetzungDer Computer stützt sich auf eine große Datenbank mit vom Menschen übersetzten Texten. Es wählt die darin enthaltenen Wörter und Phrasen aus, die den Wörtern und Phrasen des Originals entsprechen, sammelt sie in Sätzen in der Zielsprache und gibt das Ergebnis an.
Wenn sie im Internet über die nächsten „20 dümmsten maschinellen Übersetzungen“ schreiben, geht es höchstwahrscheinlich um die Übersetzung von Phrasen. Obwohl er einige Erfolge erzielt hat.
- Übersetzung neuronaler NetzeWir werden mehr über ihn sprechen. Es wurde direkt vor unseren Augen in den Massengebrauch aufgenommen: Google hat Ende 2016 die Übersetzung neuronaler Netze aktiviert. Für Russisch erschien es im März 2017. Yandex brachte Ende 2017 ein Hybridsystem auf den Markt, das auf neuronalen Netzen und Statistiken basiert.
Neuronale Netze
Die Übersetzung neuronaler Netze basiert auf der folgenden Idee: Wenn die Arbeit von Neuronen im Kopf einer Person mathematisch simuliert und reproduziert wird, kann davon ausgegangen werden, dass ein Computer lernt, wie man mit einer Sprache wie einer Person arbeitet.
Schauen Sie sich dazu die Zellen im menschlichen Gehirn an.
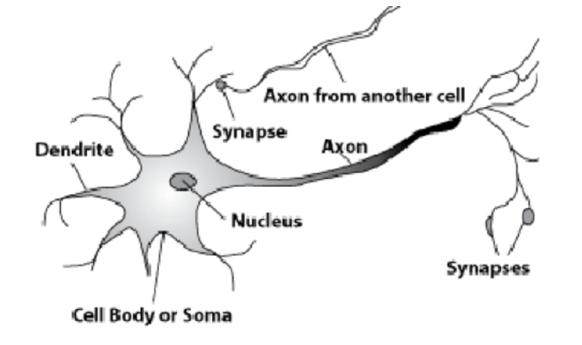
Hier ist ein natürliches Neuron. Ein langer Prozess, ein Axon, verlässt den Kern. Es hängt an Prozessen aus anderen Zellen - Synapsen. Axonen zufolge werden Informationen über einige elektrochemische Prozesse an die Synapsen der Zellzellen übertragen. Aus jeder Zelle tritt nur ein Axon aus, und viele Synapsen können eintreten. Signale breiten sich aus und auf diese Weise werden Informationen übertragen.
Einige Zellen sind mit der Außenwelt verbunden. Sie empfangen Signale, die vom neuronalen Netz weiterverarbeitet werden.
Und hier ist das einfachste mathematische Modell dessen, was wir hier tun können. Ich habe neun zusammenhängende Kreise gezeichnet. Das sind Neuronen.

Die sechs Neuronen auf der linken Seite sind die Eingangsschicht, die ein Signal von der externen Umgebung empfängt. Die Neuronen der zweiten und dritten Schicht berühren nicht die Umgebung, sondern nur mit anderen Neuronen. Wir führen die Regel ein: Wenn mindestens zwei Pfeile von aktivierten Neuronen in das Neuron eintreten, wird auch dieses Neuron aktiviert.
Das neuronale Netzwerk verarbeitet das am Eingang empfangene Signal und letztendlich den rechten Ausgang - das Neuron leuchtet auf oder leuchtet nicht auf. Bei dieser Architektur benötigen Sie zur Aktivierung des rechten Neurons mindestens vier aktivierte Neuronen in der linken Reihe. Wenn 6 oder 5 leuchtet, leuchtet es definitiv auf, wenn es von 0 bis 3 leuchtet, leuchtet es definitiv nicht auf. Wenn jedoch vier brennen, leuchtet sie nur auf, wenn sie gleichmäßig verteilt sind: 2 in der oberen Hälfte und 2 in der unteren.
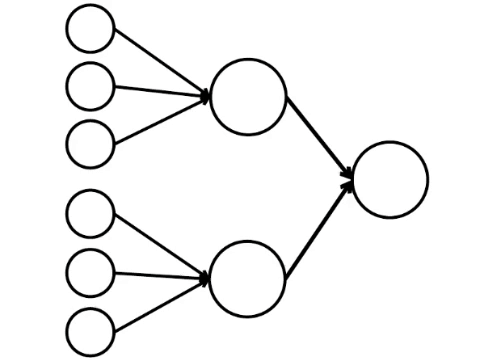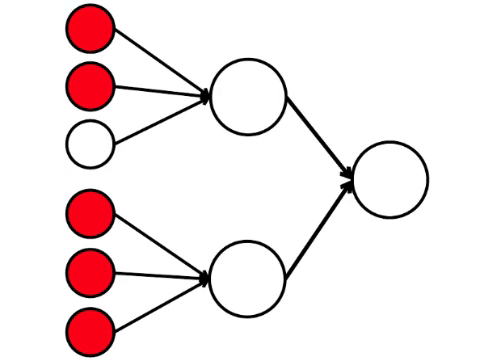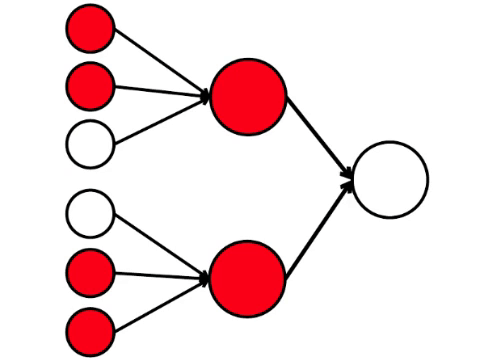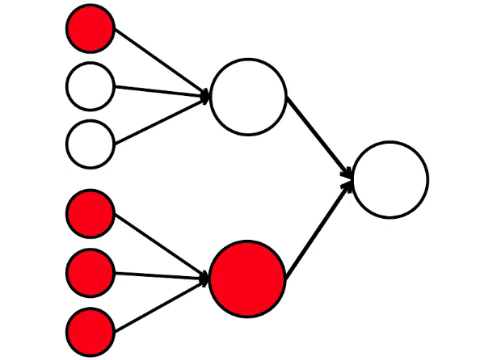
Es stellt sich heraus, dass das einfachste Schema von neun Kreisen zu einem ziemlich verzweigten Argument führt.
Künstliche neuronale Netze funktionieren ähnlich, jedoch normalerweise nicht mit so einfachen Dingen wie „beleuchtet / nicht beleuchtet“ (dh 1 oder 0), sondern mit reellen Zahlen.
Nehmen wir zum Beispiel ein Netzwerk von 5 Neuronen - zwei in der Eingabeebene, zwei in der Mitte (versteckt) und eines in der Ausgabe. Zwischen allen Neuronen benachbarter Schichten gibt es Verbindungen, denen Zahlen zugeordnet sind - Gewichte. Um herauszufinden, was in einem noch leeren Neuron passiert, machen wir eine sehr einfache Sache: Lassen Sie uns sehen, welche Verbindungen dazu führen, multiplizieren Sie das Gewicht jeder Verbindung mit der Zahl, die im Neuron der vorherigen Schicht geschrieben ist, von der diese Verbindung stammt, und wir werden dies alles zusammenfassen. Im oberen grünen Neuron im Diagramm wird 50 × 1 + 3 × 10 = 80 erhalten, und im unteren - 50 × 0,5 - 3 × 10 = –5.
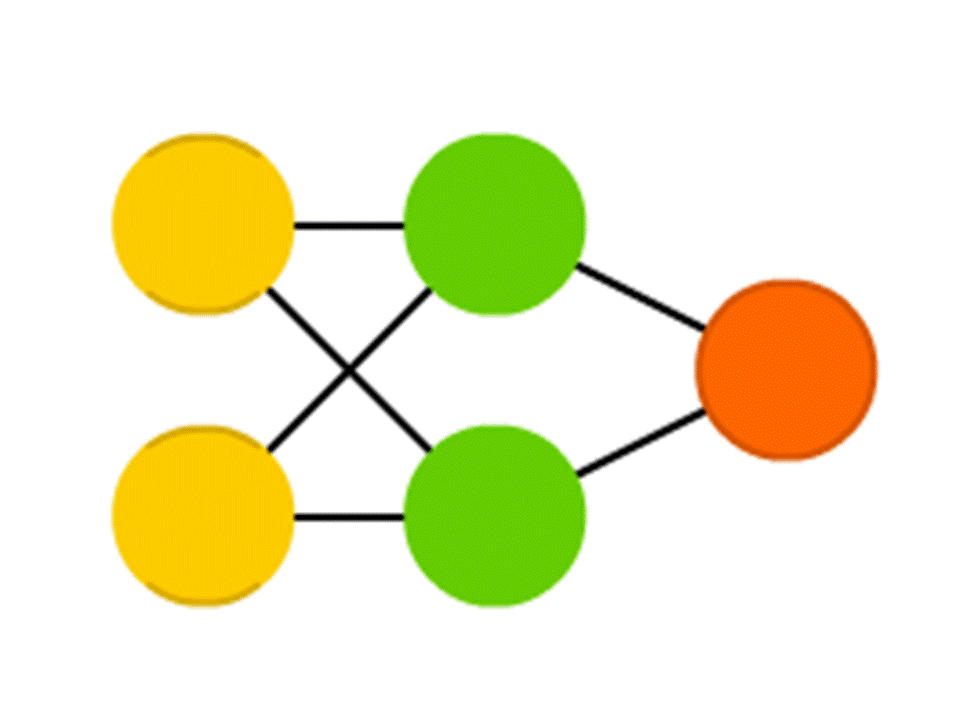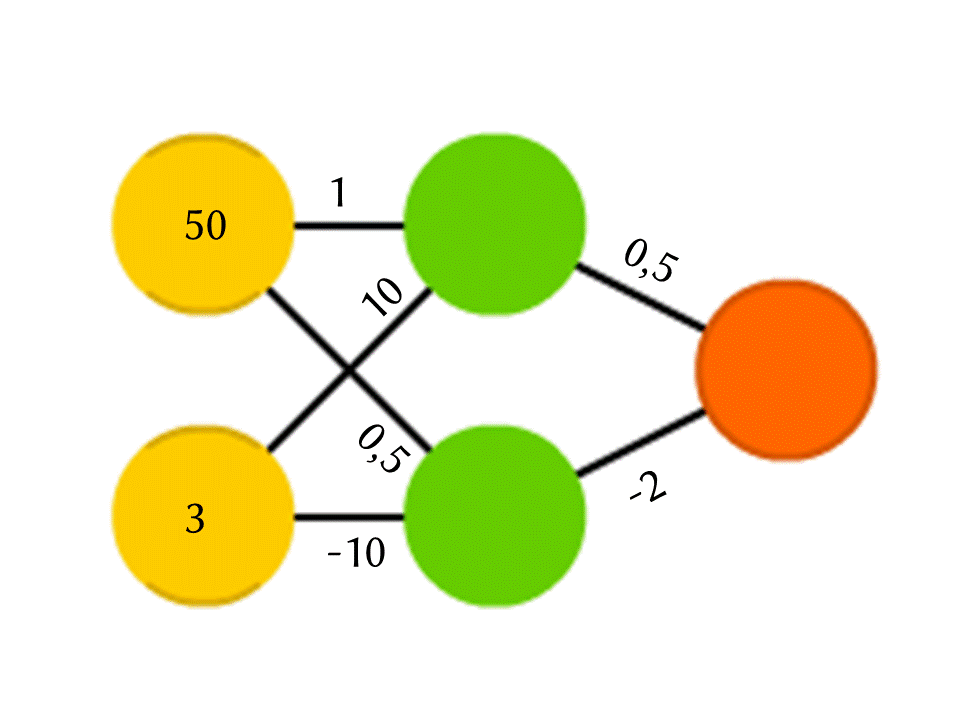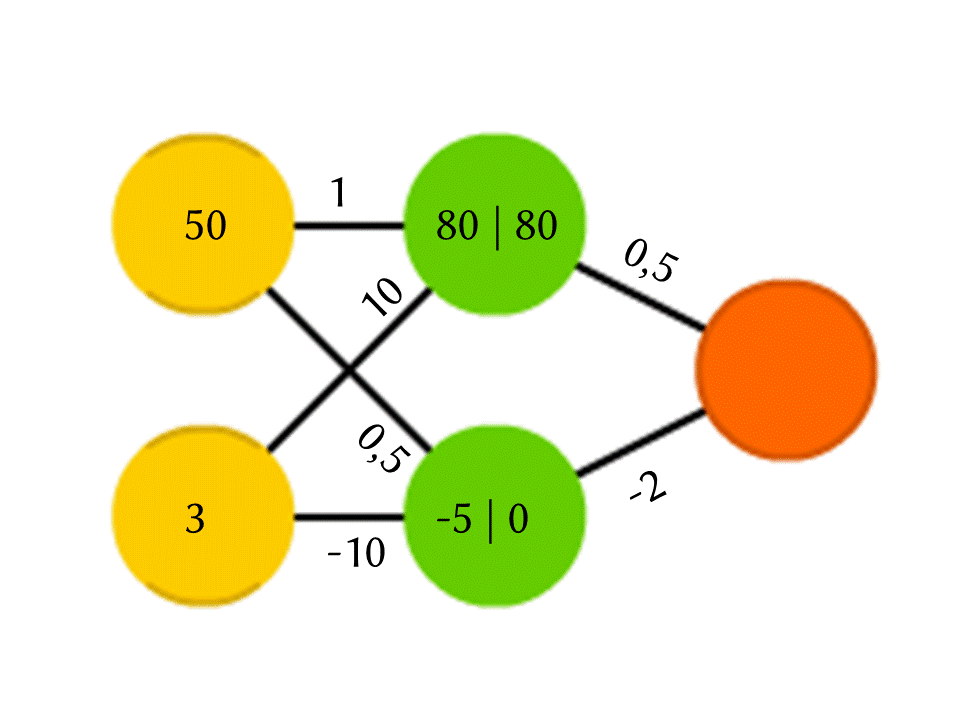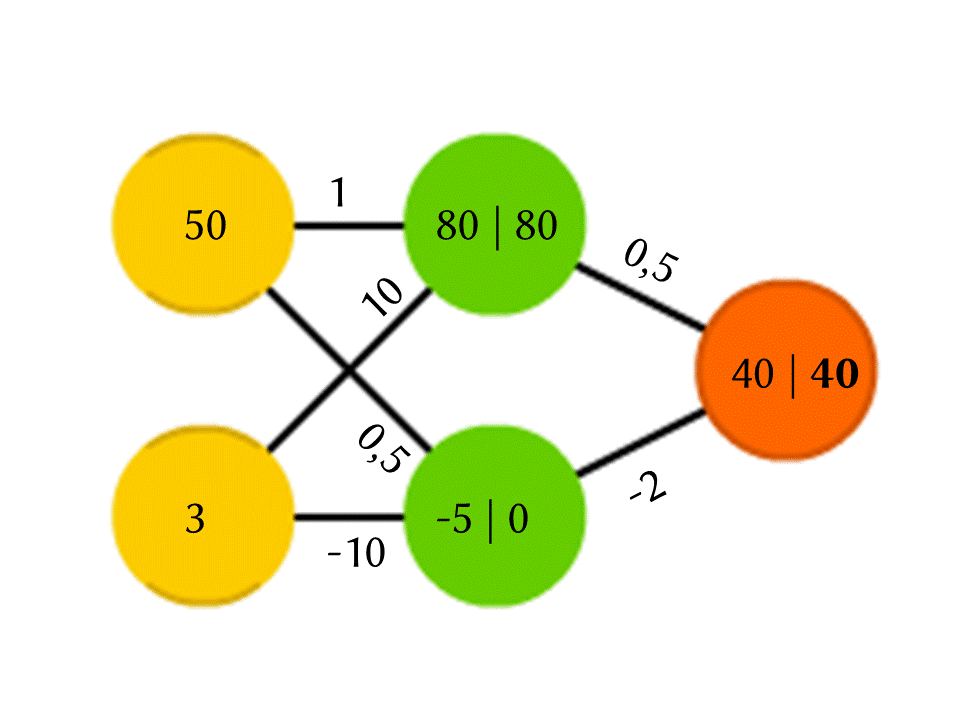
Wenn Sie genau das tun, ist die Ausgabe einfach das Ergebnis der Berechnung einer linearen Funktion der Eingabewerte (in unserem Beispiel werden 25 Y - 0,5 X ausgegeben, wobei X die Zahl im oberen gelben Neuron und Y im unteren ist). Wir sind uns also einig Im Neuron passiert etwas anderes. Die einfachste und gleichzeitig gute Ergebnisfunktion ist ReLU (Rectified Linear Unit): Wenn in einem Neuron eine negative Zahl erhalten wird, geben Sie 0 aus, und wenn sie nicht negativ ist, geben Sie sie unverändert aus.
In unserem Schema wird −5 am Ausgang des unteren grünen Neurons zu 0, und diese Zahl wird in weiteren Berechnungen verwendet. Natürlich ist die Architektur realer neuronaler Netze, die in der Praxis verwendet wird, viel komplizierter als unsere Spielzeugbeispiele, und Gewichte werden nicht von der Decke genommen, sondern durch Training ausgewählt, aber das Prinzip selbst ist wichtig.
Was hat das mit Sprache zu tun?
Am direktesten, vorausgesetzt, wir repräsentieren die Sprache in Form von Zahlen. Wir verschlüsseln jedes Wort und stoßen auf ein solches neuronales Netzwerk.
Hier kommt eine sehr wichtige Errungenschaft der Computerlinguistik zum Einsatz, die vor 50 Jahren in Bezug auf Ideen und in Bezug auf die Umsetzung in den letzten 10 Jahren aktiv entwickelt wurde: die Vektordarstellung von Wörtern.
 Dieses und die nächsten beiden Bilder stammen aus einer Präsentation von Stefan Evert
Dieses und die nächsten beiden Bilder stammen aus einer Präsentation von Stefan EvertDies ist eine Darstellung von Wörtern als Array von Zahlen, basierend auf einer sehr einfachen Überlegung. Um die Bedeutung eines Wortes herauszufinden, schauen wir uns nicht das Wörterbuch an, sondern riesige Textfelder und überlegen, neben denen unser Wort häufiger vorkommt.
Kennen Sie zum Beispiel das Wort Schalldämpfer? Wenn nicht, versuchen Sie zu raten, indem Sie sich die Texte ansehen, in denen das Wort gedämpft ist.
- Ein schwarzer Mantel und eine weiße Kappe. Nun, und immer noch ein unverzichtbarer Schalldämpfer ...
Neben ihm befinden sich Kleidungsstücke, ein Mantel und eine Mütze und wahrscheinlich ein Schalldämpfer. Es ist kaum Essen, kaum ein Element der Architektur.
- Aus irgendeinem Grund wurde in einer stickigen Nacht an seinem Hals ein alter, gestreifter Schalldämpfer besprengt.
Am Hals - das heißt, sie sind keine Socken. Sie können es fangen - anscheinend ist es flexibel, aus Stoff und nicht etwa aus Holz oder Stein.
- Ein nasses Kutsey-Waffeltuch, das Nerzhin wie ein Schalldämpfer an seinem Hals hing.
Wir füllen die Reihe der Beispiele auf und wieder auf, und wenn wir sie betrachten, werden wir allmählich verstehen, was gedämpft ist - so etwas wie ein Schal. Der Computer macht genau das Gleiche, sieht sich den Text an und macht eine einfache Sache - er erfasst die Wörter, die in der Nähe stehen.
Hier sind die ägyptischen Hieroglyphen.
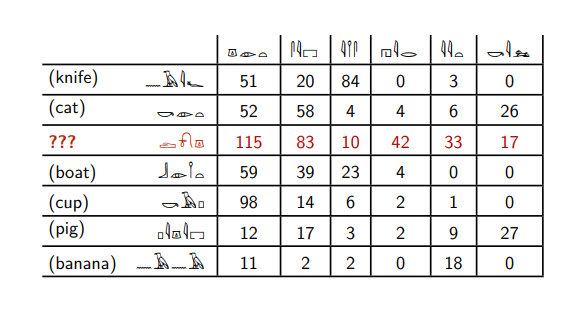
Angenommen, Sie kennen die Bedeutung von sechs von ihnen und möchten verstehen, welche Art von Wort rot hervorgehoben ist. Diese Tabelle gibt an, wie oft diese Wörter neben anderen ägyptischen Hieroglyphen gefunden werden.
Das rote Wort kommt mit dem sechsten Wort vor - genau wie die Wörter
Katze und
Schwein . Und andere Worte kommen bei ihm überhaupt nicht vor.
Das rote Wort kommt beim zweiten Wort viel häufiger vor als beim dritten, im Gegensatz zu den Wörtern
Messer und
Banane . Die Wörter
Katze, Boot, Schwein und
Tasse verhalten sich gleich.
Aufgrund dieser Überlegungen können wir sagen, dass das rote Wort den Wörtern
Katze und
Schwein am ähnlichsten ist - nur treffen sie auf das sechste Wort, sie haben ein ähnliches Verhältnis zwischen dem zweiten und dem dritten.
Und wir werden uns nicht irren, denn das rote Wort ist das Wort
Hund .

Tatsächlich handelt es sich nicht um ägyptische Hieroglyphen, sondern um englische Substantive und Verben, für die angegeben wird, wie oft sie in einer großen Sammlung englischer Texte zusammen vorkommen. Das sechste Wort ist das Verb
kill .
Die Wörter
Katze, Hund und
Schwein stehen häufig rechts vom Wort
töten . Messer, Boote und Bananen werden selten getötet. Wenn Sie möchten, können Sie zwar auf Russisch sagen: „Ich habe mein Boot getötet“, aber das ist eine seltene Sache.
Genau das, was ein Computer tut, wenn er Text verarbeitet. Er glaubt einfach, dass er auf etwas trifft und keine Meisterwerke des Verstehens mehr.
Ferner präsentiert der Computer die Wörter in Form eines bestimmten Satzes von Zahlen: Im obigen Beispiel entspricht das Wort
Hund Zahlen (115; 83; 10; 42; 33; 17). Tatsächlich müssen wir berechnen, wie oft es nicht mit sechs Wörtern, sondern mit allen Wörtern in unseren Texten vorkommt: Wenn wir alle 100.000 verschiedene Wörter haben, assoziieren wir das Wort
Hund mit einem Array von 100.000 Zahlen. Dies ist in der Praxis nicht sehr praktisch, daher werden normalerweise Methoden zum Reduzieren der Dimension verwendet, um die Ergebnisse für jedes Wort in ein Array mit mehreren hundert Elementen Länge umzuwandeln (mehr dazu finden Sie
hier ).
Es gibt vorgefertigte Bibliotheken für Programmiersprachen, mit denen Sie dies tun können: zum Beispiel
gensim für Python. Indem ich ihm das
Brownian English Language Corpus mit einem Volumen von ungefähr 1 Million Wörtern vorlege, kann ich in wenigen Sekunden ein Modell erstellen, in dem das Wort
cat so aussehen wird:

Wir stellen ein Tier dar, mit Haaren, Schwanz, es miaut. Mein Computer, den ich Englisch unterrichtete, repräsentiert das Wort
Katze in Form von hundert Zahlen, die aus den daneben stehenden Wörtern stammen.
Hier ist ein Beispiel in russischem Material von der
RusVectōres- Website. Ich nahm das Wort
Rabe und bat den Computer, mir zu sagen, welche Wörter ihm am ähnlichsten sind - oder mit anderen Worten, die Zahlenmengen, für die Wörter der Zahlenmenge für das Wort
Rabe am ähnlichsten sind.

8 von 10 Wörtern erwiesen sich als Vogelnamen. Der Computer wusste nichts und lieferte ein hervorragendes Ergebnis - ich erkannte, dass Vögel wie eine Krähe aussehen. Aber woher kommen die Worte glühend heiß und ruchenka?
Sie können ratenBei allen dreien wird das Wort Weiß oft verwendet: zu weißer Hitze, unter den weißen Griffen, weiße Krähe.
Neuronale Netze empfangen Zahlenfelder und leiten sie durch sich selbst. Sie liefern ein erstaunlich gutes Ergebnis. Hier ist ein ziemlich komplizierter, philosophischer Text aus einer Rede des Akademikers Andrei Zaliznyak über den Status der Wissenschaft in der modernen Welt. Es wurde vor einem Monat von einem Übersetzer ins Englische übersetzt und erfordert nur minimale redaktionelle Eingriffe.

Hier stellt sich die globale philosophische Frage.
Dies ist das Problem des sogenannten chinesischen Raums - ein Gedankenexperiment an den Grenzen der künstlichen Intelligenz. Es wurde 1980 vom Philosophen John Searle formuliert.
Im Raum sitzt ein Mann, der kein Chinesisch kann. Er erhielt Anweisungen, er hat Bücher, Wörterbücher und zwei Fenster. In einem Fenster erhält er Notizen auf Chinesisch und in einem anderen Fenster gibt er Antworten - auch auf Chinesisch, wobei er ausschließlich nach Anweisungen handelt.
In den Anweisungen heißt es beispielsweise: „Hier haben Sie eine Notiz, finden Sie das Zeichen im Wörterbuch. Wenn es sich um die Hieroglyphe Nr. 518 handelt, geben Sie die Hieroglyphe Nr. 409 in das rechte Fenster ein. Wenn die Hieroglyphe Nr. 711 eingetroffen ist, geben Sie die Hieroglyphe Nr. 35 in das rechte Fenster und so weiter. " Wenn die Person im Raum die Anweisungen gut befolgt und diese Anweisungen gut geschrieben sind, kann die Person auf der Straße, die Notizen gibt und empfängt, davon ausgehen, dass der Raum oder die Person darin Chinesisch kann. Schließlich ist von außen nicht sichtbar, was innen passiert.
Wir alle wissen, dass dies ein Mann ist, dem einfach dumme Anweisungen gegeben wurden. Er führt einige Operationen an ihnen durch, kann aber überhaupt kein Chinesisch. Obwohl es aus Sicht des Betrachters Sprachkenntnisse sind.
Die philosophische Frage - wie verhalten wir uns dazu? Spricht der Raum Chinesisch? Vielleicht kennt der Autor dieser Anleitung die chinesische Sprache? Und vielleicht auch nicht, weil Sie Anweisungen basierend auf einer Reihe von vorgefertigten Fragen und Antworten erteilen können.
Was wissen Chinesen dagegen? Hier kennen Sie die russische Sprache. Was kannst du tun Was ist in deinem Kopf los? Eine Art biochemische Reaktion. Ohren oder Augen erhalten ein bestimmtes Signal, es löst eine Reaktion aus, Sie verstehen etwas. Aber was bedeutet "verstehen"? Was machst du, wenn du verstehst?
Und eine noch kompliziertere Frage: Tun Sie das optimal? Stimmt es, dass Sie mit der Sprache besser arbeiten, als jede Maschine mit der Sprache arbeiten könnte? Können Sie sich vorstellen, dass Sie schlechter Russisch sprechen als jeder andere Computer? Wir vergleichen Siri, Alice immer mit der Art, wie wir uns selbst sprechen, und lachen, wenn sie aus unserer Sicht falsch sprechen. Auf der anderen Seite haben Sie und ich dem Computer viel von dem gegeben, was früher als Vorrecht des Menschen galt. Jetzt können Autos viel besser zählen und Schach spielen, aber vorher konnten sie nicht. Vielleicht passieren ähnliche Dinge mit sprechenden Computern: In 100, 10 oder sogar 5 Jahren erkennen wir, dass die Maschine die Sprache viel besser beherrscht, viel mehr versteht und im Allgemeinen ein viel besserer Muttersprachler ist als wir.
Was tun mit der Tatsache, dass eine Person verwendet wird, um sich durch Sprache zu definieren? Immerhin sagen sie, dass nur eine Person die Sprache spricht. Was wird passieren, wenn wir den Sieg am Computer in diesem Bereich erkennen?
Hinterlassen Sie Ihre Fragen in den Kommentaren. Vielleicht können wir etwas später ein Interview mit Alexander machen. Oder vielleicht kommt er selbst in einen Kommentar zu unserer Einladung und spricht mit allen Interessierten.