 Hallo! Mein Name ist Marco, ich arbeite für Badoo in der Plattformabteilung. Wir haben viele Dinge in Go geschrieben, und diese sind oft entscheidend für die Systemleistung. Deshalb biete ich Ihnen heute eine Übersetzung eines Artikels an, der mir sehr gut gefallen hat und der Ihnen sicher sehr nützlich sein wird. Der Autor zeigt Schritt für Schritt, wie er mit Leistungsproblemen umgegangen ist und wie sie diese gelöst haben. Einschließlich Sie werden mit den umfangreichen Werkzeugen vertraut gemacht, die in Go für solche Arbeiten verfügbar sind. Viel Spaß beim Lesen!
Hallo! Mein Name ist Marco, ich arbeite für Badoo in der Plattformabteilung. Wir haben viele Dinge in Go geschrieben, und diese sind oft entscheidend für die Systemleistung. Deshalb biete ich Ihnen heute eine Übersetzung eines Artikels an, der mir sehr gut gefallen hat und der Ihnen sicher sehr nützlich sein wird. Der Autor zeigt Schritt für Schritt, wie er mit Leistungsproblemen umgegangen ist und wie sie diese gelöst haben. Einschließlich Sie werden mit den umfangreichen Werkzeugen vertraut gemacht, die in Go für solche Arbeiten verfügbar sind. Viel Spaß beim Lesen!Vor einigen Wochen habe ich den Artikel „
Guter Code gegen schlechten Code in Go “ gelesen
, in dem der Autor Schritt für Schritt demonstriert, wie eine echte Anwendung umgestaltet wird, die echte Geschäftsprobleme löst. Es konzentriert sich darauf, „schlechten Code“ in „guten Code“ umzuwandeln: idiomatischer, verständlicher, unter vollständiger Nutzung der Besonderheiten von Go. Der Autor wies jedoch auch auf die Bedeutung der Leistung der betreffenden Anwendung hin. Die Neugier stieg in mich auf: Versuchen wir es zu beschleunigen!
Das Programm liest grob gesagt die Eingabedatei, analysiert sie Zeile für Zeile und füllt die Objekte im Speicher.
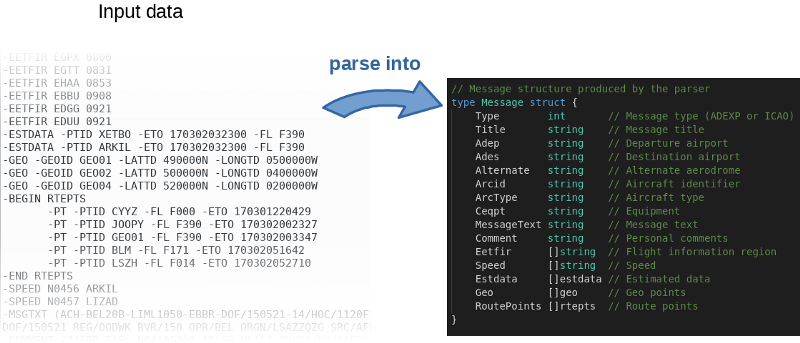
Der Autor hat nicht nur den
Quellcode auf GitHub gepostet, sondern auch einen Benchmark geschrieben. Das ist eine großartige Idee. Tatsächlich lud der Autor alle ein, mit dem Code herumzuspielen und ihn zu beschleunigen. Verwenden Sie den folgenden Befehl, um die Ergebnisse des Autors zu reproduzieren:
$ go test -bench=.
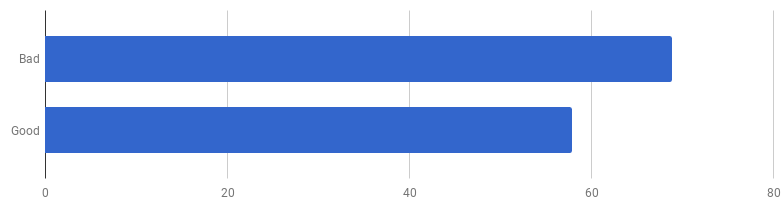 μs pro Anruf (weniger - besser)
μs pro Anruf (weniger - besser)Es stellt sich heraus, dass auf meinem Computer „guter Code“ 16% schneller ist. Können wir es beschleunigen?
Nach meiner Erfahrung besteht ein Zusammenhang zwischen Codequalität und Leistung. Wenn Sie den Code erfolgreich überarbeitet, sauberer und weniger verbunden gemacht haben, haben Sie ihn höchstwahrscheinlich schneller gemacht, weil er weniger überladen war (und es gibt keine unnötigen Anweisungen mehr, die zuvor vergeblich ausgeführt wurden). Vielleicht haben Sie während des Refactorings einige Optimierungsmöglichkeiten bemerkt, oder jetzt haben Sie nur noch die Möglichkeit, diese zu nutzen. Wenn Sie den Code jedoch noch produktiver gestalten möchten, müssen Sie sich wahrscheinlich von der Einfachheit lösen und verschiedene Hacks hinzufügen. Sie sparen wirklich Millisekunden, aber die Qualität des Codes wird darunter leiden: Es wird schwieriger, ihn zu lesen und darüber zu sprechen, er wird fragiler und flexibler.
 Wir besteigen den Berg der Einfachheit und steigen dann von ihm ab
Wir besteigen den Berg der Einfachheit und steigen dann von ihm abDies ist ein Kompromiss: Wie weit sind Sie bereit zu gehen?
Um die Arbeit an der Beschleunigung richtig zu priorisieren, besteht die optimale Strategie darin, Engpässe zu finden und sich auf diese zu konzentrieren. Verwenden Sie dazu die Profiling-Tools.
pprof und
trace sind deine Freunde:
$ go test -bench=. -cpuprofile cpu.prof $ go tool pprof -svg cpu.prof > cpu.svg
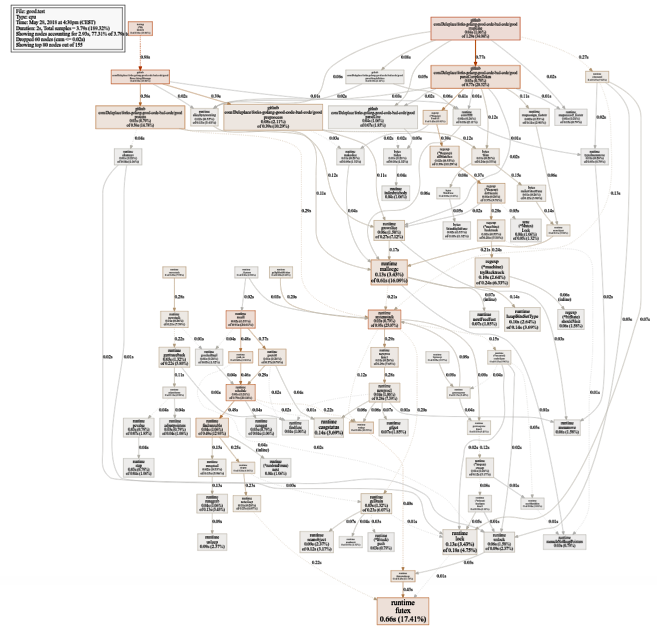 Ein ziemlich großes Diagramm der CPU-Auslastung (klicken für SVG)
Ein ziemlich großes Diagramm der CPU-Auslastung (klicken für SVG) $ go test -bench=. -trace trace.out $ go tool trace trace.out
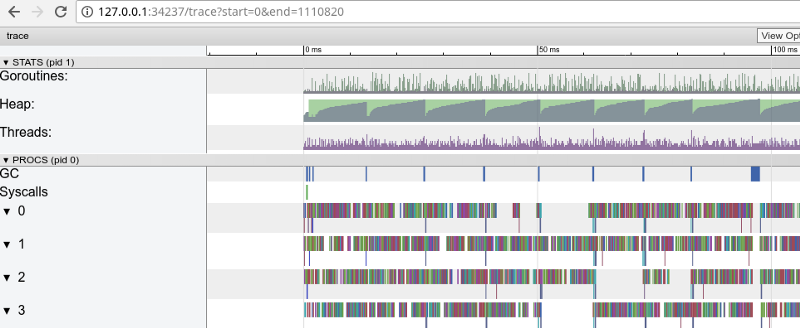 Regenbogenverfolgung: viele kleine Aufgaben (zum Öffnen klicken, funktioniert nur in Google Chrome)
Regenbogenverfolgung: viele kleine Aufgaben (zum Öffnen klicken, funktioniert nur in Google Chrome)Die Ablaufverfolgung bestätigt, dass alle Prozessorkerne ausgelastet sind (Zeilen unter 0, 1 usw.), und dies ist auf den ersten Blick gut. Sie zeigt aber auch Tausende kleiner Farbberechnungen und mehrere leere Bereiche, in denen die Kerne im Leerlauf waren. Vergrößern wir:
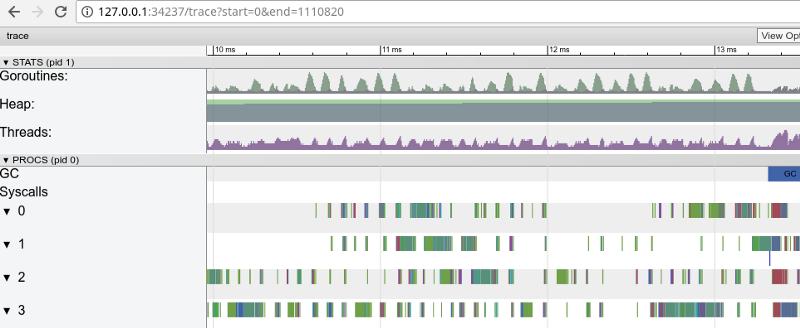 "Fenster" in 3 ms (zum Öffnen klicken, funktioniert nur in Google Chrome)
"Fenster" in 3 ms (zum Öffnen klicken, funktioniert nur in Google Chrome)Jeder Kern ist für einige Zeit im Leerlauf und „springt“ auch ständig zwischen Mikroaufgaben. Es scheint, dass die Granularität dieser Aufgaben nicht sehr optimal ist, was aufgrund der Synchronisation zu einer großen Anzahl von
Kontextwechseln und zu Konkurrenz führt.
Mal sehen, was der
Flugdetektor uns sagt. Gibt es Probleme beim synchronen Zugriff auf Daten (wenn es welche gibt, haben wir viel größere Probleme als die Leistung)?
$ go test -race PASS
Großartig! Alles ist richtig. Keine Flüge gefunden. Testfunktionen und Benchmark-Funktionen sind unterschiedliche Funktionen (
siehe Dokumentation ), aber hier wird dieselbe
ParseAdexpMessage- Funktion
aufgerufen. Was wir also durch Tests auf Datenflüge überprüft haben, ist in Ordnung.
Das Wettbewerbsmodell in der „guten“ Version besteht darin, jede Zeile aus der Eingabedatei in einer separaten Goroutine zu verarbeiten (um alle Kerne zu verwenden). Die Intuition des Autors hat hier gut funktioniert, da Goroutinen für einfache und kostengünstige Funktionen bekannt sind. Aber wie viel gewinnen wir durch parallele Ausführung? Vergleichen wir mit demselben Code, verwenden jedoch keine Goroutinen (entfernen Sie einfach das Wort go, das vor dem Funktionsaufruf steht):

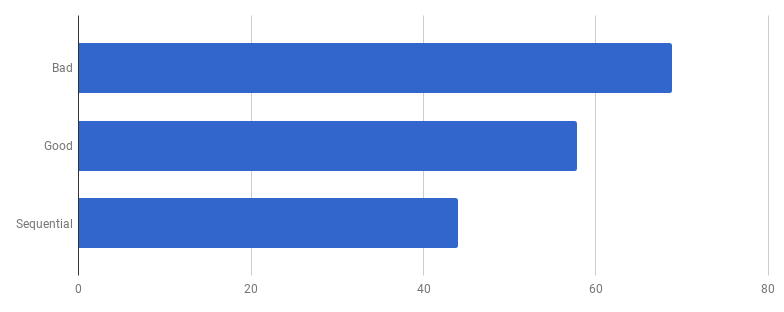
Hoppla, es scheint, dass der Code ohne Parallelität schneller geworden ist. Dies bedeutet, dass der Overhead (ungleich Null) für das Starten von Goroutinen die Zeit überschreitet, die wir durch die gleichzeitige Verwendung mehrerer Kerne gewonnen haben. Der nächste natürliche Schritt sollte darin bestehen, den Overhead (ungleich Null) zu entfernen, um Kanäle zum Senden der Ergebnisse zu verwenden. Ersetzen wir es durch ein reguläres Slice:
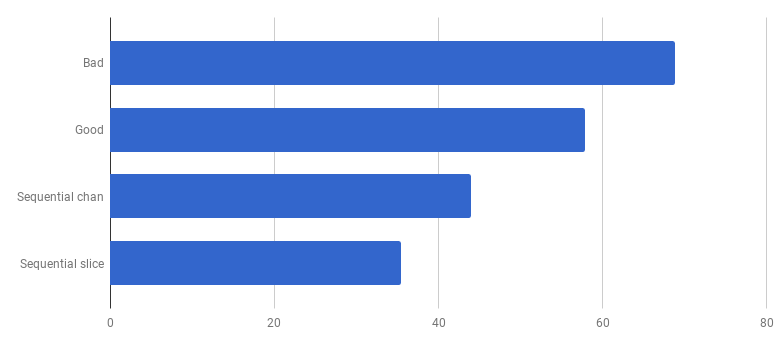 μs pro Anruf (weniger ist besser)
μs pro Anruf (weniger ist besser)Wir haben im Vergleich zur „guten“ Version eine Beschleunigung von ca. 40% erzielt, wodurch der Code vereinfacht und die Konkurrenz (
diff ) entfernt wurde.
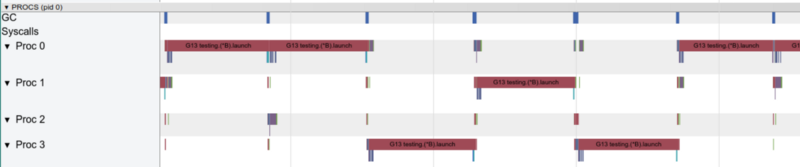 Mit einer Goroutine funktioniert immer nur ein Kern
Mit einer Goroutine funktioniert immer nur ein KernSchauen wir uns nun die Hot-Funktionen im pprof-Diagramm an:
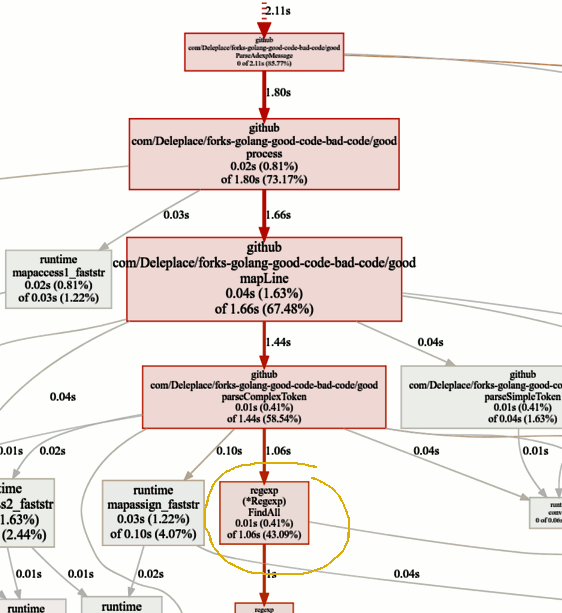 Auf der Suche nach Engpässen
Auf der Suche nach EngpässenDer Benchmark der aktuellen Version (sequentielle Operation, Slices) verbringt 86% der Zeit damit, Nachrichten zu analysieren, und dies ist normal. Wir werden jedoch schnell feststellen, dass 43% der Zeit für die Verwendung regulärer Ausdrücke und der Funktion
(* Regexp) .FindAll aufgewendet wird .
Trotz der Tatsache, dass reguläre Ausdrücke eine bequeme und flexible Möglichkeit sind, Daten aus einfachem Text abzurufen, weisen sie Nachteile auf, einschließlich der Verwendung einer großen Anzahl von Ressourcen, eines Prozessors und eines Speichers. Sie sind ein mächtiges Werkzeug, aber oft ist ihre Verwendung unnötig.
In unserem Programm eine Vorlage
patternSubfield = "-.[^-]*"
Es ist hauptsächlich dazu gedacht, Befehle hervorzuheben, die mit einem Bindestrich (-) beginnen, und es können mehrere in der Zeile sein. Dies kann, nachdem ein kleiner Code gezogen wurde, mit
bytes.Split erfolgen . Passen wir den Code (
Commit ,
Commit ) an, um die regulären Ausdrücke in Split zu ändern:
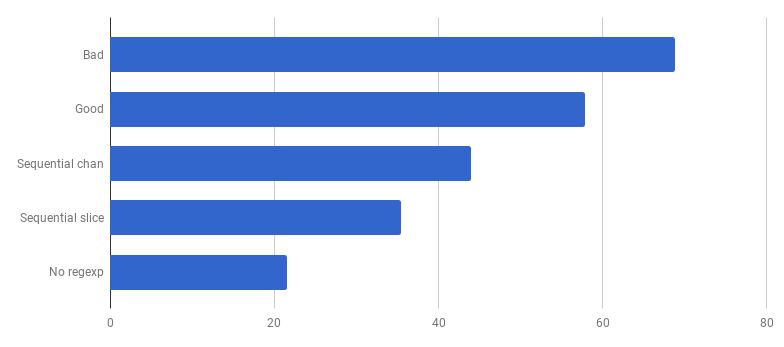 μs pro Anruf (weniger
μs pro Anruf (weniger ist
besser)Wow! 40% produktiverer Code! Das Diagramm zum CPU-Verbrauch sieht nun folgendermaßen aus:
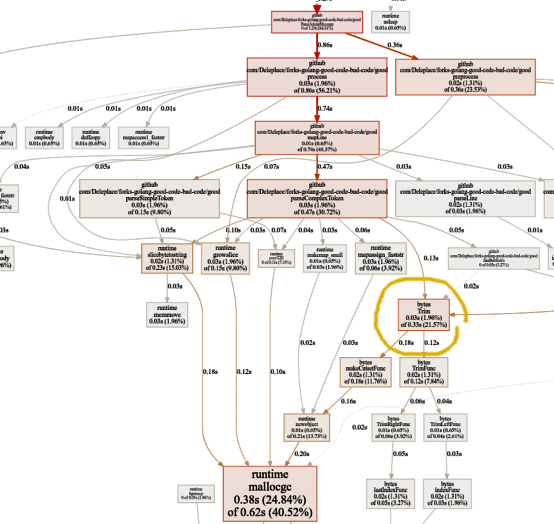
Keine Zeitverschwendung mehr für reguläre Ausdrücke. Ein wesentlicher Teil davon (40%) entfällt auf die Speicherzuweisung von fünf verschiedenen Funktionen. Interessanterweise werden jetzt 21% der Zeit für die
Bytes aufgewendet.
Trim- Funktion:
 Diese Funktion fasziniert mich. Was können wir hier machen?
Diese Funktion fasziniert mich. Was können wir hier machen?
bytes.Trim erwartet eine Zeichenfolge mit Zeichen, die als Argument "abgeschnitten" wird. Als Zeichenfolge übergeben wir jedoch eine Zeichenfolge mit nur einem Zeichen - einem Leerzeichen. Dies ist nur ein Beispiel dafür, wie Sie aufgrund der Komplexität eine Beschleunigung erzielen können: Erstellen wir unsere Trimmfunktion anstelle der Standardfunktion. Unsere benutzerdefinierte
Trimmfunktion funktioniert mit einem einzelnen Byte anstelle einer ganzen Zeile:

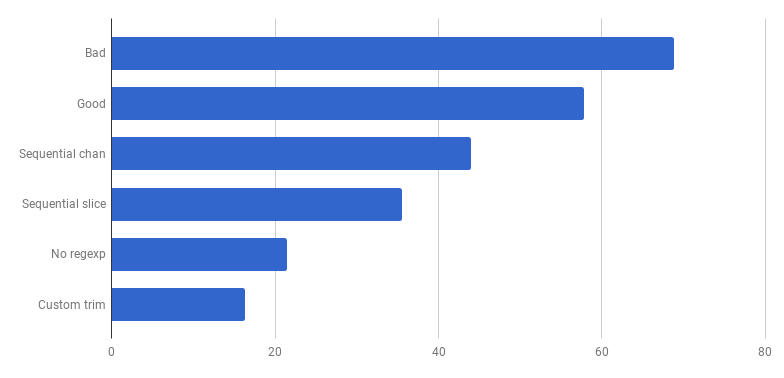 μs pro Anruf (weniger ist besser)
μs pro Anruf (weniger ist besser)Hurra, weitere 20% abgeschnitten! Die aktuelle Version ist viermal schneller als die ursprüngliche "schlechte" und verwendet gleichzeitig nur einen Kern. Nicht schlecht!
Früher haben wir die Wettbewerbsfähigkeit auf der Ebene der Linienverarbeitung aufgegeben, aber ich behaupte, dass eine Beschleunigung durch die Nutzung der Wettbewerbsfähigkeit auf einer höheren Ebene erreicht werden kann. Beispielsweise ist die Verarbeitung von 6.000 Dateien (6.000 Nachrichten) auf meinem Computer schneller, wenn jede Datei in einer eigenen Goroutine verarbeitet wird:
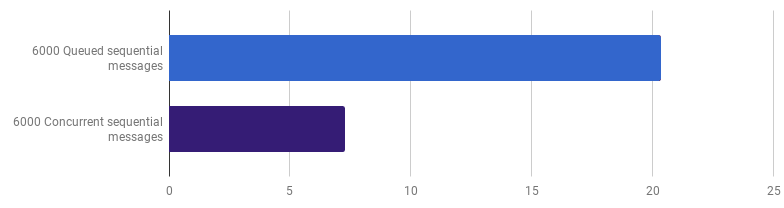 μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)
μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)Die Verstärkung beträgt 66% (dh dreimal Beschleunigung). Das ist gut, aber nicht sehr, wenn man bedenkt, dass alle 12 Prozessorkerne, die ich habe, verwendet werden. Dies kann bedeuten, dass der neue optimierte Code, der die gesamte Datei verarbeitet, immer noch eine „kleine Aufgabe“ ist, für die der Aufwand für die Erstellung von Goroutinen und die Kosten für die Synchronisierung nicht unerheblich sind. Interessanterweise hat die Erhöhung der Anzahl der Nachrichten von 6.000 auf 120.000 keine Auswirkungen auf die Single-Thread-Version und verringert die Leistung bei der Version "Eine Goroutine pro Nachricht". Dies liegt daran, dass trotz der Tatsache, dass das Erstellen einer so großen Anzahl von Goroutinen möglich und manchmal nützlich ist, der Laufzeit-
Sheduler-Bereich einen eigenen Overhead
verursacht .
Wir können die Ausführungszeit weiter reduzieren (nicht um das 12-fache, aber immer noch), indem wir nur wenige Mitarbeiter erstellen. Zum Beispiel 12 langlebige Goroutinen, von denen jede einen Teil der Nachrichten verarbeitet:
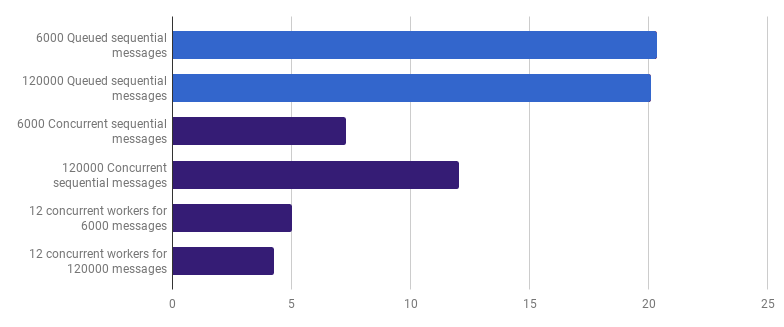 μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)
μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)Diese Option reduziert die Ausführungszeit um 79% im Vergleich zur Single-Threaded-Version. Beachten Sie, dass diese Strategie nur dann sinnvoll ist, wenn Sie viele Dateien verarbeiten müssen.
Die optimale Verwendung aller Prozessorkerne besteht darin, mehrere Goroutinen zu verwenden, von denen jede eine erhebliche Datenmenge ohne Interaktion oder Synchronisation verarbeitet, bevor die Arbeit abgeschlossen ist.
Normalerweise nehmen sie so viele Prozesse (Goroutine) wie die Kerne des Prozessors, aber dies ist nicht immer die beste Option: Alles hängt von der spezifischen Aufgabe ab. Wenn Sie beispielsweise etwas aus dem Dateisystem lesen oder viele Netzwerkanrufe tätigen, sollten Sie mehr Goroutinen als Ihre Kerne verwenden, um mehr Leistung zu erzielen.
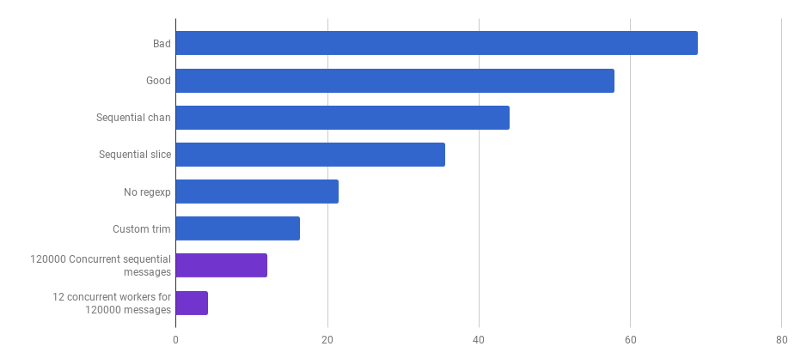 μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)
μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)Wir sind an einem Punkt angelangt, an dem es schwierig ist, die Parsing-Leistung mit einigen lokalisierten Änderungen zu steigern. Die Laufzeit wird von der Zeit für die Speicherzuweisung und die Speicherbereinigung dominiert. Dies klingt logisch, da die Speicherverwaltungsfunktionen ziemlich langsam sind. Die weitere Optimierung der mit Zuweisungen verbundenen Prozesse bleibt eine Hausaufgabe für die Leser.
Die Verwendung anderer Algorithmen kann ebenfalls zu einem großen Leistungsgewinn führen.
Hier wurde ich von einem Vortrag von Lexical Scanning in Go von Rob Pike inspiriert,
um einen benutzerdefinierten Lexer (
Quelle ) und einen benutzerdefinierten Parser (
Quelle ) zu erstellen. Dieser Code ist noch nicht fertig (ich verarbeite keine Eckfälle), er ist weniger klar als der ursprüngliche Algorithmus und manchmal ist es schwierig, die richtige Fehlerbehandlung zu schreiben. Aber es ist klein und 30% schneller als die am besten optimierte Version.
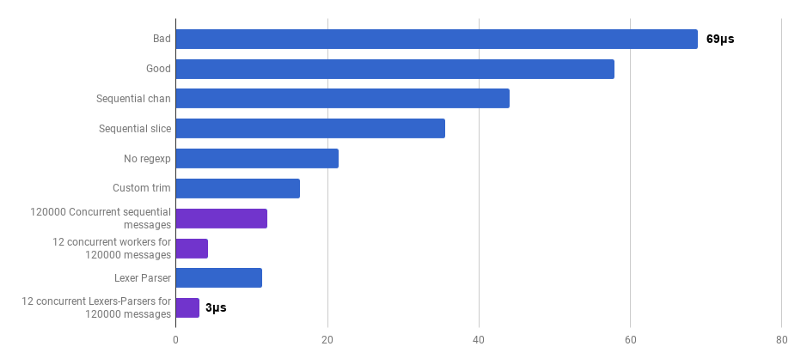 μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)
μs pro Anruf (weniger ist besser; lila ist eine wettbewerbsfähige Lösung)Ja Als Ergebnis haben wir eine 23-fache Beschleunigung im Vergleich zum Quellcode erhalten.
Das ist alles für heute. Ich hoffe du hast dieses Abenteuer genossen. Hier einige Anmerkungen und Schlussfolgerungen:
- Die Produktivität kann auf verschiedenen Abstraktionsebenen unter Verwendung verschiedener Techniken verbessert werden, und der Gewinn wird häufig erhöht.
- Die Optimierung muss mit Abstraktionen auf hoher Ebene beginnen: Datenstrukturen, Algorithmen, die korrekte Entkopplung von Modulen. Nehmen Sie später Abstraktionen auf niedriger Ebene auf: E / A, Stapelverarbeitung, Wettbewerbsfähigkeit, Verwendung der Standardbibliothek, Arbeiten mit Speicher, Zuweisen von Speicher.
- Die Big O- Analyse ist sehr wichtig, aber normalerweise nicht das am besten geeignete Werkzeug, um ein Programm zu beschleunigen.
- Benchmarks zu schreiben ist harte Arbeit. Verwenden Sie Profilerstellung und Benchmarks, um Engpässe zu finden und ein umfassenderes Verständnis der Vorgänge im Programm zu erlangen. Beachten Sie, dass die Benchmark-Ergebnisse nicht mit denen Ihrer Benutzer in der Praxis übereinstimmen.
- Glücklicherweise macht eine Reihe von Tools ( Bench , pprof , trace , Race Detector , Cover ) die Erforschung der Codeleistung erschwinglich und interessant.
- Gute, relevante Tests zu schreiben ist keine triviale Aufgabe. Aber sie sind verdammt wichtig, nicht in die Wildnis zu gehen. Sie können umgestalten, indem Sie sicherstellen, dass der Code korrekt bleibt.
- Halten Sie an und fragen Sie sich, wie schnell "schnell genug" ist. Verschwenden Sie keine Zeit damit, ein einmaliges Skript zu optimieren. Vergessen Sie nicht, dass die Optimierung nicht kostenlos ist: Zeit, Komplexität, Fehler und technische Schulden des Ingenieurs.
- Überlegen Sie zweimal, bevor Sie den Code komplizieren.
- Algorithmen mit der Komplexität Ω (n²) und höher sind normalerweise zu teuer.
- Algorithmen mit der Komplexität O (n) oder O (n log n) und darunter sind normalerweise in Ordnung.
- Verschiedene versteckte Faktoren können nicht ignoriert werden. Zum Beispiel wurden alle Verbesserungen in dem Artikel durch Reduzieren dieser Faktoren und nicht durch Ändern der Komplexitätsklasse des Algorithmus erzielt.
- E / A ist häufig ein Engpass: Netzwerkabfragen, Datenbankabfragen, Dateisystem.
- Reguläre Ausdrücke sind oft zu teuer und unnötig.
- Speicherzuordnungen sind teurer als Berechnungen.
- Ein auf dem Stapel zugewiesenes Objekt ist billiger als ein auf dem Heap zugewiesenes Objekt.
- Slices sind als Alternative zu teuren Speicherbewegungen nützlich.
- Strings sind schreibgeschützt (einschließlich Reslicing). In allen anderen Fällen sind [] Bytes effektiver.
- Es ist sehr wichtig, dass sich die von Ihnen verarbeiteten Daten in der Nähe befinden (Prozessor-Caches).
- Wettbewerbsfähigkeit und Parallelität sind sehr nützlich, aber schwer vorzubereiten.
- Wenn Sie tief und tief graben, denken Sie an den „Glasboden“, den Sie nicht in Go einbrechen möchten. Wenn Ihre Hände nach Assembler-Anweisungen oder SIMD-Anweisungen suchen, müssen Sie Go möglicherweise nur für das Prototyping verwenden und dann in eine niedrigere Sprache wechseln, um die vollständige Kontrolle über die Hardware und jede Nanosekunde zu erhalten!