Hallo! In diesem Artikel werde ich über den Bayes'schen Klassifikator als eine der Optionen zum Filtern von Spam-E-Mails sprechen. Lassen Sie uns die Theorie durchgehen und sie dann mit der Praxis korrigieren. Am Ende werde ich meine Skizze des Codes in meiner geliebten Sprache R geben. Ich werde versuchen, mit Ausdrücken und Formulierungen so leicht wie möglich zu erklären. Fangen wir an!

Keine Formeln irgendwo, na ja, eine kurze Theorie
Der Bayes'sche Klassifikator gehört zur Kategorie des maschinellen Lernens. Das Fazit lautet: Das System, das vor der Aufgabe steht, festzustellen, ob der nächste Buchstabe Spam ist, wurde im Voraus durch eine bestimmte Anzahl von Buchstaben geschult, die genau wissen, wo "Spam" und wo "kein Spam". Es ist bereits klar geworden, dass dies ein Unterricht mit einem Lehrer ist, bei dem wir die Rolle eines Lehrers spielen. Der Bayes'sche Klassifikator präsentiert ein Dokument (in unserem Fall einen Buchstaben) in Form einer Reihe von Wörtern, die angeblich nicht voneinander abhängen (und genau diese Naivität folgt aus hier).
Es ist notwendig, die Note für jede Klasse (Spam / Nicht-Spam) zu berechnen und die maximale zu wählen. Verwenden Sie dazu die folgende Formel:
- Wortvorkommen
in Klassendokument
(mit Glättung) *
- die Anzahl der Wörter, die im Klassendokument enthalten sind
M - die Anzahl der Wörter aus dem Trainingssatz
- die Anzahl der Vorkommen des Wortes
in Klassendokument
- Parameter zum Glätten
Wenn das Volumen des Textes sehr groß ist, müssen Sie mit sehr kleinen Zahlen arbeiten. Um dies zu vermeiden, können Sie die Formel gemäß der Logarithmus-Eigenschaft ** konvertieren:
Ersetzen und erhalten:
* Während der Berechnungen stoßen Sie möglicherweise auf ein Wort, das sich noch nicht im Trainingsstadium des Systems befand. Dies kann dazu führen, dass die Bewertung gleich Null ist und das Dokument keiner der Kategorien (Spam / Nicht-Spam) zugeordnet werden kann. Egal wie Sie möchten, Sie bringen Ihrem System nicht alle möglichen Wörter bei. Zu diesem Zweck müssen alle Wahrscheinlichkeiten von Wörtern, die in das Dokument eingegeben werden, geglättet oder vielmehr geringfügig korrigiert werden. Der Parameter 0 <α ≤ 1 wird ausgewählt (wenn α = 1 ist, ist dies Laplace-Glättung).
** Der Logarithmus ist eine monoton ansteigende Funktion. Wie aus der ersten Formel hervorgeht, suchen wir das Maximum. Der Logarithmus der Funktion erreicht den gleichen Punkt (Abszisse) wie die Funktion selbst. Dies vereinfacht die Berechnung, da sich nur der numerische Wert ändert.
Von der Theorie zur Praxis
Lassen Sie unser System aus den folgenden Buchstaben lernen, die im Voraus bekannt sind, wo "Spam" und wo "kein Spam" (Schulungsbeispiel):
Spam- "Gutscheine zu einem günstigen Preis"
- „Beförderung! Kaufen Sie eine Tafel Schokolade und verschenken Sie ein Telefon »
Kein Spam:- "Das Treffen wird morgen stattfinden"
- "Kaufen Sie ein Kilogramm Äpfel und eine Tafel Schokolade"
Aufgabe: Bestimmen Sie, zu welcher Kategorie der folgende Buchstabe gehört:
- „Der Laden hat einen Berg von Äpfeln. Kaufen Sie sieben Kilogramm und eine Tafel Schokolade. “
Lösung:Wir machen einen Tisch. Wir entfernen alle „Stoppwörter“, berechnen die Wahrscheinlichkeiten und nehmen den Parameter für die Glättung als einen.
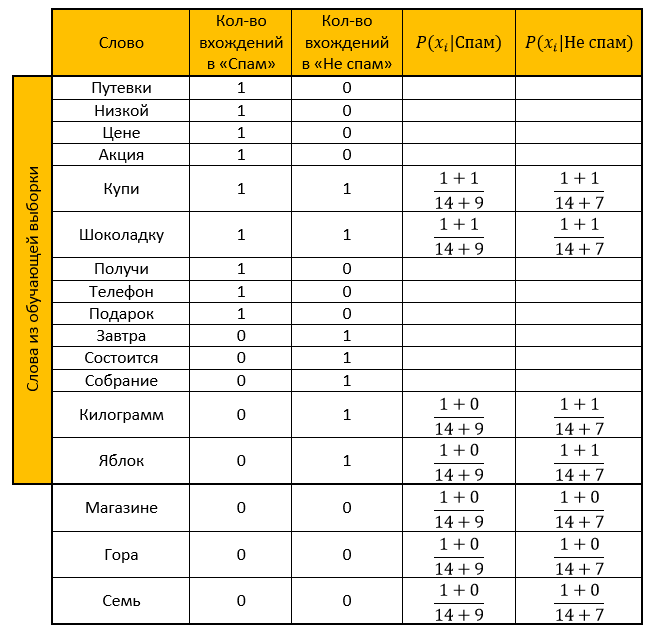
Bewertung für Kategorie Spam:
Bewertung für die Kategorie „Nicht-Spam“:
Antwort: Die Bewertung "Nicht Spam" ist höher als die Bewertung "Spam". Das Bestätigungsschreiben ist also kein Spam!
Wir berechnen dasselbe mit Hilfe einer Funktion, die durch die Eigenschaft des Logarithmus transformiert wird:
Bewertung für Kategorie Spam:
Bewertung für die Kategorie „Nicht-Spam“:
Antwort: ähnlich der vorherigen Antwort. Bestätigungs-E-Mail - kein Spam!
Implementierung der Programmiersprache R.
Er hat fast jede Aktion kommentiert, weil ich weiß, wie oft ich den Code eines anderen nicht verstehen möchte. Ich hoffe, dass das Lesen meines Codes Ihnen keine Schwierigkeiten bereitet. (oh wie ich hoffe)
Und hier tatsächlich der Code selbstlibrary("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
Vielen Dank für Ihre Zeit beim Lesen meines Artikels. Ich hoffe, Sie haben etwas Neues für sich selbst gelernt oder einfach Licht in Momente gebracht, die Ihnen nicht klar sind. Viel Glück
Quellen:- Ein sehr guter Artikel über den naiven Bayes-Klassifikator
- Abgeleitetes Wissen aus dem Wiki: hier , hier und hier
- Vorträge zum Data Mining Chubukova I.A.