Hallo! Unten finden Sie eine Abschrift des Videos der Rede auf der Apache Ignite-Kundgebung in St. Petersburg am 20. Juni. Sie können die Folien hier herunterladen.
Es gibt eine ganze Reihe von Problemen, mit denen Anfänger konfrontiert sind. Sie haben gerade Apache Ignite heruntergeladen, die ersten zwei, drei, zehn Mal ausgeführt und kommen mit Fragen zu uns, die auf ähnliche Weise gelöst werden. Daher schlage ich vor, eine Checkliste zu erstellen, die Ihnen viel Zeit und Nerven spart, wenn Sie Ihre ersten Apache Ignite-Anwendungen erstellen. Wir werden über Startvorbereitungen sprechen. wie man den Cluster zusammenbaut; wie man einige Berechnungen im Rechenraster startet; So bereiten Sie ein Datenmodell und einen Code vor, damit Sie Ihre Daten in Ignite schreiben und dann erfolgreich lesen können. Und vor allem: wie man von Anfang an nichts kaputt macht.
Vorbereitung für den Start - Konfigurieren Sie die Protokollierung
Wir brauchen Protokolle. Wenn Sie jemals eine Frage in der Apache Ignite-Mailingliste oder in StackOverflow gestellt haben, z. B. "Warum hat alles aufgelegt?", Wurden Sie höchstwahrscheinlich als erstes aufgefordert, alle Protokolle aller Knoten zu senden.
Natürlich ist die Apache Ignite-Protokollierung standardmäßig aktiviert. Aber es gibt Nuancen. Erstens schreibt Apache Ignite ein wenig in stdout . Standardmäßig startet es im sogenannten Ruhezustand. In stdout werden nur die schrecklichsten Fehler angezeigt, und alles andere wird in einer Datei gespeichert, deren Pfad Apache Ignite ganz am Anfang anzeigt (standardmäßig - ${IGNITE_HOME}/work/log ). Sie löschen es nicht und bewahren die Protokolle länger auf, es kann sehr nützlich sein.
stdout beim Standardstart entzünden
Um das Auffinden von Problemen zu vereinfachen, ohne in separate Dateien zu gelangen und eine separate Überwachung für Apache Ignite einzurichten, können Sie diese mit dem Befehl im ausführlichen Modus ausführen
ignite.sh -v
Anschließend schreibt das System zusammen mit dem Rest der Anwendungsprotokollierung über alle Ereignisse in stdout .
Überprüfen Sie die Protokolle! Sehr oft finden Sie in ihnen Lösungen für Ihre Probleme. Wenn der Cluster zusammengebrochen ist, sehen Sie sehr oft im Protokoll Meldungen wie „Erhöhen Sie das Zeitlimit in dieser und jener Konfiguration. Wir sind wegen ihm abgefallen. Er ist zu klein. Das Netzwerk ist nicht gut genug. “
Cluster-Assembly
Ungebetene Gäste
Das erste Problem, mit dem viele konfrontiert sind, sind die ungebetenen Gäste in Ihrem Cluster. Oder Sie selbst erweisen sich als ungebetener Gast: Starten Sie einen neuen Cluster, und plötzlich sehen Sie, dass Sie im ersten Topologie-Snapshot anstelle eines Knotens von Anfang an zwei Server haben. Wie so? Sie haben nur einen gestartet.
Eine Nachricht, die angibt, dass der Cluster zwei Knoten hat

Tatsache ist, dass Apache Ignite standardmäßig Multicast verwendet und beim Start nach allen anderen Apache Ignite sucht, die sich im selben Subnetz in derselben Multicast-Gruppe befinden. In diesem Fall wird versucht, eine Verbindung herzustellen. Und im Falle einer nicht erfolgreichen Verbindung wird sie überhaupt nicht gestartet. Daher werden im Cluster auf meinem funktionierenden Laptop regelmäßig zusätzliche Knoten aus dem Cluster auf dem Laptop des Kollegen angezeigt, was sicherlich nicht sehr praktisch ist.
Wie können Sie sich davor schützen? Der einfachste Weg, um statische IP zu konfigurieren. Anstelle von TcpDiscoveryMulticastIpFinder , der standardmäßig verwendet wird, gibt es TcpDiscoveryVmIpFinder . Notieren Sie sich dort alle IP-Adressen und Ports, mit denen Sie eine Verbindung herstellen. Dies ist viel praktischer und schützt Sie vor einer Vielzahl von Problemen, insbesondere in Entwicklungs- und Testumgebungen.
Zu viele Adressen
Das nächste Problem. Sie haben Multicast deaktiviert, den Cluster gestartet und in einer einzigen Konfiguration eine angemessene Menge an IP aus verschiedenen Umgebungen festgelegt. Und es kommt vor, dass Sie den ersten Knoten in einem neuen Cluster für 5-10 Minuten starten, obwohl alle nachfolgenden Knoten in 5-10 Sekunden eine Verbindung zu ihm herstellen.
Nehmen Sie eine Liste mit drei IP-Adressen. Für jeden schreiben wir Bereiche von 10 Ports vor. Insgesamt werden 30 TCP-Adressen erhalten. Da Apache Ignite versuchen muss, eine Verbindung zu einem vorhandenen Cluster herzustellen, bevor ein neuer Cluster erstellt wird, überprüft es nacheinander jede IP. Auf Ihrem Laptop kann es nicht schaden, aber in einigen wolkigen Umgebungen ist der Schutz vor Port-Scans häufig enthalten. Das heißt, wenn Sie über eine IP-Adresse auf einen privaten Port zugreifen, erhalten Sie keine Antwort, bis das Zeitlimit abgelaufen ist. Standardmäßig sind es 10 Sekunden. Und wenn Sie 3 Adressen mit 10 Ports haben, erhalten Sie 3 * 10 * 10 = 300 Sekunden Wartezeit - dieselben 5 Minuten für die Verbindung.
Die Lösung liegt auf der Hand: Registrieren Sie keine unnötigen Ports. Wenn Sie drei IPs haben, brauchen Sie kaum einen Standardbereich von 10 Ports. Dies ist praktisch, wenn Sie etwas auf dem lokalen Computer testen und 10 Knoten ausführen. In realen Systemen reicht jedoch normalerweise ein einziger Port aus. Oder deaktivieren Sie den Schutz gegen Port-Scans im internen Netzwerk, wenn Sie eine solche Möglichkeit haben.
Das dritte häufige Problem ist IPv6. Sie können seltsame Netzwerkfehlermeldungen sehen: Konnte keine Verbindung herstellen, konnte keine Nachricht senden, Knoten segmentiert. Dies bedeutet, dass Sie vom Cluster gefallen sind. Sehr oft werden solche Probleme durch gemischte Umgebungen aus IPv4 und IPv6 verursacht. Dies bedeutet nicht, dass Apache Ignite IPv6 nicht unterstützt, aber im Moment gibt es bestimmte Probleme.
Die einfachste Lösung besteht darin, die Option an den Java-Computer zu übergeben
-Djava.net.preferIPv4Stack=true
Dann verwenden Java und Apache Ignite kein IPv6. Dies löst einen wesentlichen Teil der Probleme mit kollabierenden Clustern.
Vorbereitung der Codebasis - wir serialisieren korrekt
Der Cluster hat sich versammelt, es ist notwendig, etwas darin zu starten. Eines der wichtigsten Elemente bei der Interaktion Ihres Codes mit Apache Ignite-Code ist Marshaller oder Serialisierung. Um etwas in den Speicher zu schreiben, zu persistieren und über das Netzwerk zu senden, serialisiert Apache Ignite zuerst Ihre Objekte. Sie können Nachrichten sehen, die mit den Worten beginnen: "Kann nicht im Binärformat geschrieben werden" oder "Kann nicht mit BinaryMarshaller serialisiert werden". Es wird nur eine solche Warnung im Protokoll geben, die jedoch auffällt. Dies bedeutet, dass Sie Ihren Code etwas weiter optimieren müssen, um sich mit Apache Ignite anzufreunden.
Apache Ignite verwendet drei Mechanismen für die Serialisierung:
JdkMarshaller - reguläre Java-Serialisierung;OptimizedMarshaller - leicht optimierte Java-Serialisierung, aber die Mechanismen sind dieselben;BinaryMarshaller ist eine speziell für Apache Ignite geschriebene Serialisierung, die überall unter der Haube verwendet wird. Sie hat eine Reihe von Vorteilen. Irgendwo können wir zusätzliche Serialisierung und Deserialisierung vermeiden, und irgendwo können wir sogar ein nicht deserialisiertes Objekt in der API erhalten, das direkt im Binärformat arbeitet, wie bei etwas wie JSON.
BinaryMarshaller kann Ihre POJOs serialisieren und de-serialisieren, die nur Felder und einfache Methoden enthalten. Wenn Sie jedoch eine benutzerdefinierte Serialisierung über readObject() und writeObject() und Externalizable , wird BinaryMarshaller nicht bewältigen. Er wird feststellen, dass Ihr Objekt durch die übliche Aufzeichnung nicht transienter Felder nicht serialisiert werden kann, und wird aufgeben - es wird auf OptimizedMarshaller .
Um sich mit Apache Ignite mit solchen Objekten Binarylizable , müssen Sie die Binarylizable Schnittstelle implementieren. Er ist sehr einfach.
Zum Beispiel gibt es eine Standard- TreeMap von Java. Es verfügt über eine benutzerdefinierte Serialisierung und Deserialisierung über Lese- und Schreibobjekte. Es beschreibt zuerst einige Felder und schreibt dann die Länge und die Daten selbst in den OutputStream .
Implementierung von TreeMap.writeObject()
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
writeBinary() und readBinary() von Binarylizable funktionieren genauso: BinaryTreeMap verpackt sich in eine reguläre TreeMap und schreibt sie in OutputStream . Diese Methode ist einfach zu schreiben und erhöht die Produktivität erheblich.
Implementierung von BinaryTreeMap.writeBinary()
public void writeBinary(BinaryWriter writer) throws BinaryObjectException { BinaryRawWriter rewriter = writer. rewrite (); rawWriter.writeObject(map.comparator()); int size = map.size(); rawWriter.writeInt(size); for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) { rawWriter.writeObject(entry.getKey()); rawWriter.writeObject(entry.getValue()); } }
Starten Sie in Compute Grid
Mit Ignite können Sie nicht nur Daten speichern, sondern auch verteiltes Computing ausführen. Wie führen wir eine Art Lambda aus, damit alle Server gestreut und ausgeführt werden?
Was ist für den Anfang das Problem mit diesen Codebeispielen?
Was ist das Problem?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast( () -> doStuffWithFooAndBar(foo, bar) );
Und wenn ja?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast(new IgniteRunnable() { @Override public void run() { doStuffWithFooAndBar(foo, bar); } });
Wie Sie sich vorstellen können, besteht das Problem bei vielen, die mit den Fallstricken von Lambdas und anonymen Klassen vertraut sind, darin, Variablen von außen zu erfassen. Zum Beispiel versenden wir Lambda. Es werden einige Variablen verwendet, die außerhalb des Lambda deklariert sind. Dies bedeutet, dass diese Variablen mit ihr reisen und über das Netzwerk zu allen Servern fliegen. Und dann stellen sich alle die gleichen Fragen: BinaryMarshaller diese Objekte mit BinaryMarshaller befreundet? Wie groß sind sie? Wollen wir im Allgemeinen, dass sie irgendwohin übertragen werden, oder sind diese Objekte so groß, dass es besser ist, eine ID zu übergeben und die Objekte im Lambda bereits auf der anderen Seite neu zu erstellen?
Anonyme Klasse ist noch schlimmer. Wenn das Lambda dies nicht mitnehmen kann, werfen Sie es weg, wenn es nicht verwendet wird, dann wird die anonyme Klasse es sicher nehmen, und dies führt normalerweise zu nichts Gutem.
Das folgende Beispiel. Wieder Lambda, der aber ein bisschen die Apache Ignite API verwendet.
Die Verwendung von Ignite Inside Compute Closure ist falsch
ignite.compute().broadcast(() -> { IgniteCache foo = ignite.cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
In der Originalversion nimmt es den Cache und führt lokal eine Art SQL-Abfrage durch. Dies ist ein solches Muster, wenn Sie eine Aufgabe senden müssen, die nur mit lokalen Daten auf Remote-Knoten funktioniert.
Was ist das Problem hier? Das Lambda erfasst erneut die Verknüpfung, aber jetzt nicht zum Objekt, sondern zum lokalen Ignite auf dem Knoten, mit dem wir es senden. Und es funktioniert sogar, weil das Ignite-Objekt über eine readResolve() -Methode verfügt, mit der die Deserialisierung die über das Netzwerk readResolve() Ignite durch eine lokale auf dem Knoten ersetzen kann, an den wir sie gesendet haben. Dies führt aber manchmal auch zu unerwünschten Folgen.
Grundsätzlich übertragen Sie einfach mehr Daten über das Netzwerk, als Sie möchten. Wenn Sie von einem Code Ignintion.localIgnite() müssen, den Sie nicht steuern, um Apache Ignite oder einige seiner Schnittstellen zu starten, verwenden Sie am einfachsten die Methode Ignintion.localIgnite() . Sie können es von jedem von Apache Ignite erstellten Thread aus aufrufen und einen Link zu einem lokalen Objekt erhalten. Wenn Sie Lambdas, Dienste usw. haben und verstehen, dass Sie hier Ignite benötigen, empfehle ich diese Methode.
Wir verwenden Ignite Inside Compute Closure korrekt - über localIgnite()
ignite.compute().broadcast(() -> { IgniteCache foo = Ignition.localIgnite().cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
Und das letzte Beispiel in diesem Teil. Apache Ignite verfügt über ein Service Grid, mit dem Microservices direkt in einem Cluster bereitgestellt werden können. Apache Ignite hilft dabei, die richtige Anzahl von Instanzen online zu halten. Angenommen, wir benötigen in diesem Dienst auch einen Link zu Apache Ignite. Wie bekomme ich es? Wir könnten localIgnite() , aber dann muss dieser Link manuell im Feld gespeichert werden.
Der Dienst speichert Ignite falsch in einem Feld - nimmt es als Argument für den Konstruktor
MyService s = new MyService(ignite) ignite.services().deployClusterSingleton("svc", s); ... public class MyService implements Service { private Ignite ignite; public MyService(Ignite ignite) { this.ignite = ignite; } ... }
Es gibt einen einfacheren Weg. Wir haben immer noch vollständige Klassen und kein Lambda, daher können wir das Feld als @IgniteInstanceResource mit Anmerkungen @IgniteInstanceResource . Wenn der Dienst erstellt wird, wird Apache Ignite dort abgelegt, und Sie können ihn sicher verwenden. Ich rate Ihnen dringend, genau das zu tun und nicht zu versuchen, Apache Ignite und seine untergeordneten Elemente an den Konstruktor weiterzugeben.
Der Dienst verwendet @IgniteInstanceResource
public class MyService implements Service { @IgniteInstanceResource private Ignite ignite; public MyService() { } ... }
Daten schreiben und lesen
Achten Sie auf die Grundlinie
Jetzt haben wir einen Apache Ignite-Cluster und vorbereiteten Code.
Stellen wir uns dieses Szenario vor:
- Ein
REPLICATED Cache - Kopien von Daten sind auf allen Knoten verfügbar. - Die native Persistenz ist aktiviert - Schreiben auf die Festplatte.
Wir starten einen Knoten. Da die native Persistenz aktiviert ist, müssen wir den Cluster aktivieren, bevor wir damit arbeiten können. Aktivieren. Dann starten wir einige weitere Knoten.
Alles scheint zu funktionieren: Schreiben und Lesen sind in Ordnung. Alle Knoten haben Kopien der Daten, Sie können einen Knoten sicher stoppen. Wenn Sie jedoch den ersten Knoten stoppen, von dem aus Sie den Start gestartet haben, bricht alles zusammen: Die Daten verschwinden und die Vorgänge werden nicht mehr ausgeführt.
Der Grund dafür ist die Basistopologie - die vielen Knoten, auf denen Persistenzdaten gespeichert sind. Alle anderen Knoten haben keine persistenten Daten.
Dieser Satz von Knoten wird zum ersten Mal zum Zeitpunkt der Aktivierung bestimmt. Und die Knoten, die Sie anschließend hinzugefügt haben, sind nicht mehr in der Anzahl der Basisknoten enthalten. Das heißt, viele Basistopologien bestehen nur aus einem, dem allerersten Knoten. Wenn er stoppt, bricht alles. Um dies zu verhindern, starten Sie zuerst alle Knoten und aktivieren Sie dann den Cluster. Wenn Sie mit dem Befehl einen Knoten hinzufügen oder entfernen müssen
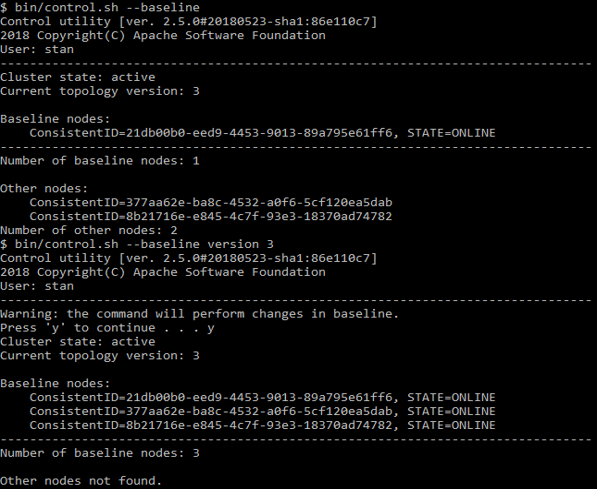
control.sh --baseline
Sie können sehen, welche Knoten dort aufgelistet sind. Das gleiche Skript kann die Baseline auf den aktuellen Status aktualisieren.
control.sh Beispiel
Datenkolokation
Jetzt wissen wir, dass die Daten gespeichert sind. Versuchen Sie, sie zu lesen. Wir haben SQL-Unterstützung, Sie können SELECT - fast wie in Oracle. Gleichzeitig können wir aber beliebig viele Knoten skalieren und ausführen, die Daten werden verteilt gespeichert. Schauen wir uns ein solches Modell an:
public class Person { @QuerySqlField public Long id; @QuerySqlField public Long orgId; } public class Organization { @QuerySqlField private Long id; }
Anfrage
SELECT * FROM Person as p JOIN Organization as o ON p.orgId = o.id
gibt nicht alle Daten zurück. Was ist los?
Person ( Person ) bezieht sich auf die Organisation ( Organization ) nach ID. Dies ist ein klassischer Fremdschlüssel. Wenn wir jedoch versuchen, die beiden Tabellen zu kombinieren und eine solche SQL-Abfrage zu senden, erhalten wir bei mehreren Knoten im Cluster nicht alle Daten.
Tatsache ist, dass SQL JOIN standardmäßig nur innerhalb eines einzelnen Knotens funktioniert. Wenn SQL ständig im gesamten Cluster Daten sammeln und das vollständige Ergebnis zurückgeben würde, wäre dies unglaublich langsam. Wir würden alle Vorteile eines verteilten Systems verlieren. Stattdessen betrachtet Apache Ignite nur lokale Daten.
Um die richtigen Ergebnisse zu erhalten, müssen wir Daten zusammenstellen (Colocation). Das heißt, für die richtige Kombination von Person und Organisation müssen die Daten beider Tabellen auf demselben Knoten gespeichert werden.
Wie kann man das machen? Die einfachste Lösung besteht darin, einen Affinitätsschlüssel zu deklarieren. Dies ist ein Wert, der bestimmt, auf welchem Knoten, in welcher Partition, in welcher Gruppe von Datensätzen sich dieser oder jener Wert befindet. Wenn wir die Organisations-ID Person als Affinitätsschlüssel deklarieren, bedeutet dies, dass sich Personen mit dieser Organisations-ID auf demselben Knoten wie die Organisation mit derselben ID befinden müssen.
Wenn Sie dies aus irgendeinem Grund nicht tun können, gibt es eine andere, weniger effektive Lösung: Aktivieren Sie verteilte Verknüpfungen. Dies erfolgt über die API, und die Vorgehensweise hängt davon ab, was Sie verwenden - Java, JDBC oder etwas anderes. Dann werden JOIN langsamer ausgeführt, aber dann werden die korrekten Ergebnisse zurückgegeben.
Lassen Sie uns überlegen, wie Sie mit Affinitätsschlüsseln arbeiten. Wie verstehen wir, dass eine solche und eine solche ID, ein solches und ein solches Feld zur Bestimmung der Affinität geeignet ist? Wenn wir sagen, dass alle Personen mit derselben orgId zusammen gespeichert werden, ist orgId eine unteilbare Gruppe. Wir können es nicht auf mehrere Knoten verteilen. Wenn die Datenbank 10 Organisationen enthält, gibt es 10 unteilbare Gruppen, die auf 10 Knoten platziert werden können. Wenn der Cluster mehr Knoten enthält, bleiben alle "zusätzlichen" Knoten ohne Gruppen. Dies ist in der Laufzeit sehr schwer zu definieren. Denken Sie also vorher darüber nach.
Wenn Sie eine große und 9 kleine Organisation haben, ist die Größe der Gruppen unterschiedlich. Apache Ignite berücksichtigt jedoch nicht die Anzahl der Datensätze in Affinitätsgruppen, wenn diese auf Knoten verteilt werden. Daher wird er nicht eine Gruppe auf einen Knoten setzen, sondern 9 andere auf einen anderen, um die Verteilung irgendwie auszugleichen. Vielmehr wird er sie 5 und 5 setzen (oder 6 und 4 oder sogar 7 und 3).
Wie können die Daten gleichmäßig verteilt werden? Mögen wir haben
- K Tasten;
- Eine Vielzahl von Affinitätsschlüsseln;
- P-Partitionen, dh große Datengruppen, die Apache Ignite zwischen den Knoten verteilt;
- N Knoten.
Dann ist es notwendig, dass die Bedingung
K >> A >> P >> N
Dabei ist >> "viel mehr" und die Daten werden relativ gleichmäßig verteilt.
Der Standardwert ist übrigens P = 1024.
Höchstwahrscheinlich wird es Ihnen nicht gelingen, eine gleichmäßige Verteilung zu erreichen. Dies war in Apache Ignite 1.x bis 1.9 der Fall. Dies wurde als FairAffinityFunction und funktionierte nicht sehr gut - es führte zu zu viel Verkehr zwischen Knoten. Jetzt heißt der Algorithmus RendezvousAffinityFunction . Es gibt keine absolut ehrliche Verteilung, der Fehler zwischen den Knoten beträgt plus oder minus 5-10%.
Checkliste für neue Apache Ignite-Benutzer
- Protokolle einrichten, lesen, speichern
- Deaktivieren Sie Multicast und notieren Sie nur die Adressen und Ports, die Sie verwenden
- Deaktivieren Sie IPv6
BinaryMarshaller Sie Ihre Klassen für BinaryMarshaller- Behalten Sie Ihre Grundlinie im Auge
- Richten Sie die Affinitätskollokation ein