Das Material, dessen Übersetzung wir heute veröffentlichen, konzentriert sich darauf, was in einer Situation zu tun ist, in der die vom Server empfangenen Daten nicht den Anforderungen des Clients entsprechen. Zuerst werden wir ein typisches Problem dieser Art betrachten und dann verschiedene Wege analysieren, um es zu lösen.

Das Problem der ausgefallenen Server-API
Betrachten wir ein bedingtes Beispiel, das auf mehreren realen Projekten basiert. Angenommen, wir entwickeln eine neue Website für eine Organisation, die seit einiger Zeit besteht. Sie hat bereits REST-Endpunkte, aber sie sind nicht ganz auf das ausgelegt, was wir erstellen werden. Hier müssen wir nur auf den Server zugreifen, um den Benutzer zu authentifizieren, Informationen über ihn zu erhalten und eine Liste der nicht angezeigten Benachrichtigungen von diesem Benutzer herunterzuladen. Aus diesem Grund interessieren uns die folgenden Endpunkte der Server-API:
/auth : Autorisiert den Benutzer und gibt ein Zugriffstoken zurück./profile : Gibt grundlegende Benutzerinformationen zurück./notifications : Ermöglicht das Abrufen ungelesener Benutzerbenachrichtigungen.
Stellen Sie sich vor, unsere Anwendung muss immer alle diese Daten in einer einzigen Einheit empfangen, das heißt, im Idealfall wäre es schön, wenn wir anstelle von drei Endpunkten nur einen hätten.
Wir haben jedoch viel mehr Probleme als zu viele Endpunkte. Insbesondere sprechen wir darüber, dass die Daten, die wir erhalten, nicht optimal aussehen.
Beispielsweise wurde der Endpunkt
/profile in der Antike erstellt und nicht in JavaScript geschrieben. Daher sehen die Namen der Eigenschaften in den zurückgegebenen Daten für eine JS-Anwendung ungewöhnlich aus:
{ "Profiles": [ { "id": 1234, "Christian_Name": "David", "Surname": "Gilbertson", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/david.png" ] } ], "Last_Login": "2018-01-01" } ] }
Im Allgemeinen - nichts Gutes.
Richtig, wenn Sie sich ansehen, was der Endpunkt
/notifications erzeugen, werden die obigen Daten von
/profile ziemlich nett erscheinen:
{ "data": { "msg-1234": { "timestamp": "1529739612", "user": { "Christian_Name": "Alice", "Surname": "Guthbertson", "Enhanced": "True", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/alice.png" ] } ] }, "message_summary": "Hey I like your hair, it re", "message": "Hey I like your hair, it really goes nice with your eyes" }, "msg-5678": { "timestamp": "1529731234", "user": { "Christian_Name": "Bob", "Surname": "Smelthsen", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/smelth.png" ] } ] }, "message_summary": "I'm launching my own cryptocu", "message": "I'm launching my own cryptocurrency soon and many thanks for you to look at and talk about" } } }
Hier ist die Liste der Nachrichten ein Objekt, kein Array. Außerdem gibt es hier Benutzerdaten, die genauso unangenehm angeordnet sind wie im Fall des
/profile Endpunkts. Und - hier ist eine Überraschung - die
timestamp enthält die Anzahl der Sekunden seit Anfang 1970.
Wenn ich ein Diagramm der Architektur dieses höllisch unbequemen Systems zeichnen müsste, über das wir gerade gesprochen haben, würde es wie das in der folgenden Abbildung gezeigte aussehen. Die rote Farbe wird für diejenigen Teile dieser Schaltung verwendet, die schlecht vorbereiteten Daten für weitere Arbeiten entsprechen.
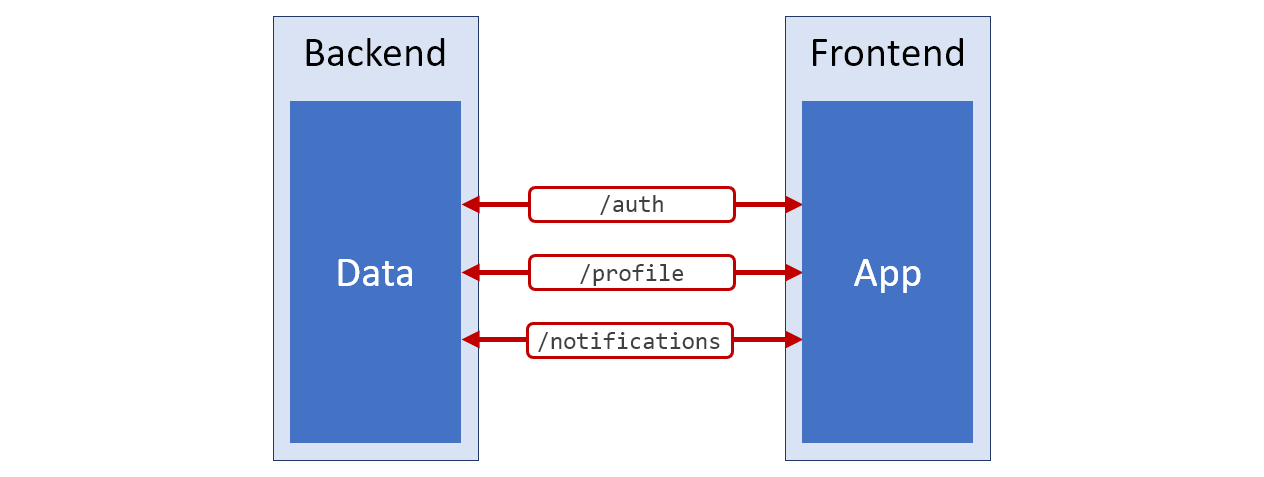 Systemdiagramm
SystemdiagrammUnter diesen Umständen bemühen wir uns möglicherweise nicht, die Architektur dieses Systems zu reparieren. Sie können einfach Daten von diesen drei APIs laden und diese Daten in der Anwendung verwenden. Wenn Sie beispielsweise den vollständigen Benutzernamen auf der Seite anzeigen müssen, müssen Sie die Eigenschaften
Christian_Name und
Surname kombinieren.
Hier möchte ich eine Bemerkung zu Namen machen. Die Idee, den vollständigen Namen einer Person in einen persönlichen Vor- und Nachnamen zu unterteilen, ist charakteristisch für westliche Länder. Wenn Sie etwas für den internationalen Gebrauch entwickeln, versuchen Sie, den vollständigen Namen der Person als unteilbare Zeichenfolge zu betrachten, und machen Sie keine Annahmen darüber, wie diese Zeichenfolge in kleinere Teile zerlegt werden kann, um zu verwenden, was an Orten passiert ist, an denen brauchen Kürze oder möchten den Benutzer in einem informellen Stil ansprechen.
Zurück zu unseren unvollständigen Datenstrukturen. Das erste offensichtliche Problem, das hier zu sehen ist, drückt sich in der Notwendigkeit aus, unterschiedliche Daten im Benutzeroberflächencode zu kombinieren. Es besteht in der Tatsache, dass wir diese Aktion möglicherweise an mehreren Stellen wiederholen müssen. Wenn Sie dies nur gelegentlich tun müssen, ist das Problem nicht so schwerwiegend, aber wenn Sie dies häufig benötigen, ist es viel schlimmer. Infolgedessen gibt es unerwünschte Phänomene, die durch die Nichtübereinstimmung der Anordnung der vom Server empfangenen Daten und ihrer Verwendung in der Anwendung verursacht werden.
Das zweite Problem ist die Komplexität des Codes, der zur Bildung der Benutzeroberfläche verwendet wird. Ich glaube, dass ein solcher Code zum einen so einfach wie möglich und zum anderen so klar wie möglich sein sollte. Je mehr interne Datentransformationen Sie auf dem Client durchführen müssen, desto komplexer und komplexer ist der Code, an dem sich normalerweise Fehler verstecken.
Das dritte Problem betrifft Datentypen. Anhand der obigen Codefragmente können Sie erkennen, dass beispielsweise Nachrichtenkennungen Zeichenfolgen und Benutzerkennungen Zahlen sind. Aus technischer Sicht ist alles in Ordnung, aber solche Dinge können den Programmierer verwirren. Schauen Sie sich auch die Präsentation der Daten an! Aber was ist mit dem Durcheinander in dem Teil der Daten, der sich auf das Profilbild bezieht? Schließlich brauchen wir nur eine URL, die zur entsprechenden Datei führt, und nicht etwas, aus dem wir diese URL selbst erstellen müssen, um durch den Dschungel verschachtelter Datenstrukturen zu waten.
Wenn wir diese Daten verarbeiten, an den Benutzeroberflächencode übergeben und dann die Module analysieren, können wir nicht sofort genau verstehen, womit wir dort arbeiten. Das Konvertieren der internen Datenstruktur und ihres Typs bei der Arbeit mit ihnen führt zu einer zusätzlichen Belastung für den Programmierer. Aber ohne all diese Schwierigkeiten ist das durchaus möglich.
In der Tat wäre es als Option möglich, ein statisches Typsystem zu implementieren, um dieses Problem zu lösen, aber eine strikte Typisierung ist nicht nur aufgrund ihrer Anwesenheit in der Lage, schlechten Code gut zu machen.
Nachdem Sie nun den Ernst des Problems sehen können, mit dem wir konfrontiert sind, sprechen wir über Möglichkeiten, es zu lösen.
Lösung 1: Ändern der Server-API
Wenn das unbequeme Gerät der vorhandenen API nicht aus wichtigen Gründen vorgegeben ist, hindert Sie nichts daran, eine neue Version zu erstellen, die den Anforderungen des Projekts besser entspricht, und diese neue Version beispielsweise unter
/v2 . Vielleicht kann dieser Ansatz als die erfolgreichste Lösung für die oben genannten Probleme bezeichnet werden. Das Schema eines solchen Systems ist in der folgenden Abbildung dargestellt. Die Datenstruktur, die perfekt zu den Anforderungen des Kunden passt, ist grün hervorgehoben.
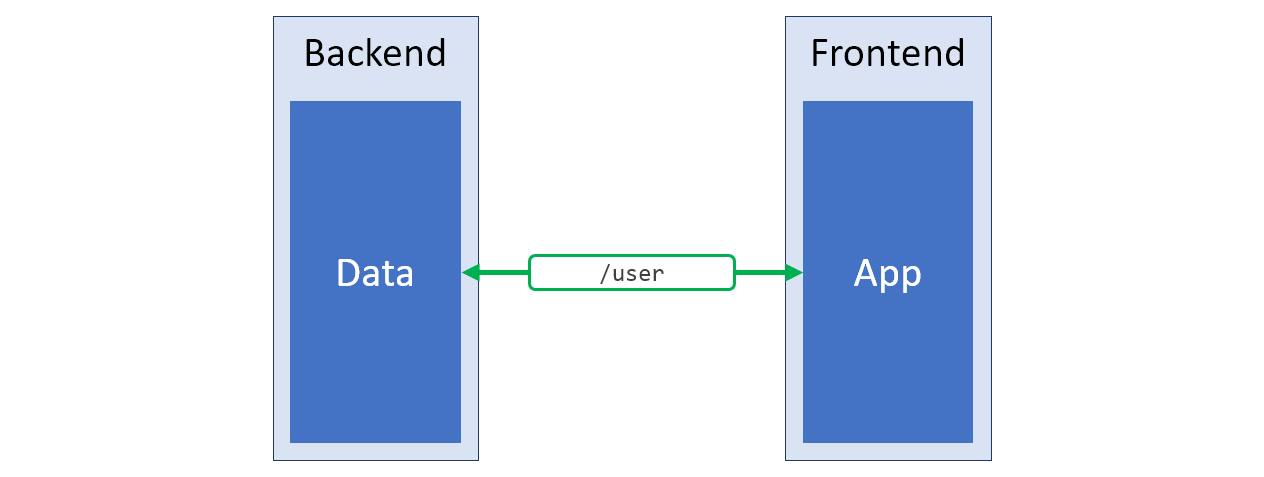 Die neue Server-API, die genau das produziert, was die Client-Seite des Systems benötigt
Die neue Server-API, die genau das produziert, was die Client-Seite des Systems benötigtIch beginne mit der Entwicklung eines neuen Projekts, dessen API zu wünschen übrig lässt, und bin immer an der Möglichkeit interessiert, den gerade beschriebenen Ansatz umzusetzen. Manchmal hat das API-Gerät jedoch einige wichtige Ziele, obwohl es unpraktisch ist, oder eine Änderung der Server-API ist einfach nicht möglich. In diesem Fall greife ich auf den folgenden Ansatz zurück.
Lösung 2: BFF-Muster
Dies ist ein gutes altes BFF
- Muster (
Backend-For-the-Frontend ). Mit diesem Muster können Sie von den komplizierten universellen REST-Endpunkten abstrahieren und dem Frontend genau das geben, was es benötigt. Hier ist eine schematische Darstellung einer solchen Lösung.
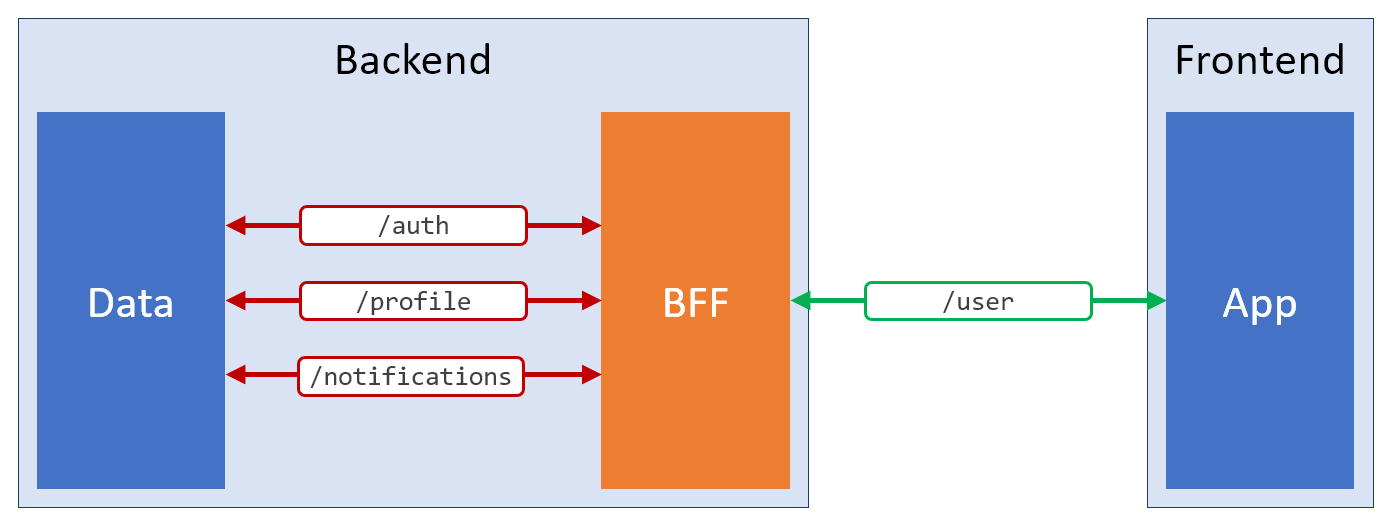 Anwenden des BFF-Musters
Anwenden des BFF-MustersDie Bedeutung der Existenz der BFF-Schicht besteht darin, die Bedürfnisse des Frontends zu befriedigen. Vielleicht verwendet er zusätzliche REST-Endpunkte oder GraphQL-Dienste oder Web-Sockets oder irgendetwas anderes. Das Hauptziel besteht darin, alles Mögliche für die Client-Seite der Anwendung zu tun.
Meine Lieblingsarchitektur ist NodeJS BFF, mit der Front-End-Entwickler das tun können, was sie benötigen, und großartige APIs für die von ihnen entwickelten Clientanwendungen erstellen. Im Idealfall befindet sich der entsprechende Code im selben Repository wie der Code des Frontends selbst. Dies vereinfacht die gemeinsame Nutzung von Code, um beispielsweise gesendete Daten sowohl auf dem Client als auch auf dem Server zu überprüfen.
Dies bedeutet außerdem, dass Aufgaben, die Änderungen am Client-Teil der Anwendung und ihrer Server-API erfordern, in einem Repository ausgeführt werden. Eine Kleinigkeit, wie sie sagen, aber nett.
BFF wird jedoch möglicherweise nicht immer verwendet. Und diese Tatsache führt uns zu einer anderen Lösung für das Problem der bequemen Verwendung fehlerhafter Server-APIs.
Lösung 3: BIF-Muster
Das BIF-Muster (Backend In the Frontend) verwendet dieselbe Logik, die mit BFF (Kombination mehrerer APIs und Datenbereinigung) angewendet werden kann. Diese Logik wird jedoch auf die Clientseite verschoben. Eigentlich ist diese Idee nicht neu, sie hätte vor zwanzig Jahren gesehen werden können, aber ein solcher Ansatz kann bei der Arbeit mit schlecht organisierten Server-APIs hilfreich sein. Deshalb sprechen wir darüber. So sieht es aus.
 Anwenden des BIF-Musters
Anwenden des BIF-Musters▍ Was ist ein BIF?
Wie aus dem vorherigen Abschnitt ersichtlich ist, ist BIF ein Muster, dh ein Ansatz zum Verständnis des Codes und seiner Organisation. Seine Verwendung führt nicht dazu, dass Logik aus dem Projekt entfernt werden muss. Es trennt lediglich die Logik eines Typs (Änderung von Datenstrukturen) von der Logik eines anderen Typs (Bildung der Benutzeroberfläche). Dies ähnelt der Idee einer „Aufgabentrennung“, die jeder hört.
An dieser Stelle möchte ich darauf hinweisen, dass ich, obwohl dies nicht als Katastrophe bezeichnet werden kann, häufig Analphabeten-BIF-Implementierungen sehen musste. Daher scheint es mir, dass viele daran interessiert sein werden, eine Geschichte darüber zu hören, wie dieses Muster richtig implementiert werden kann.
Der BIF-Code sollte als Code betrachtet werden, der einmal genommen und auf den Node.js-Server übertragen werden kann. Danach funktioniert alles auf die gleiche Weise wie zuvor. Oder übertragen Sie es sogar auf ein privates NPM-Paket, das in mehreren Front-End-Projekten im Rahmen eines Unternehmens verwendet wird, was einfach erstaunlich ist.
Denken Sie daran, dass wir oben die Hauptprobleme besprochen haben, die beim Arbeiten mit einer ausgefallenen Server-API auftreten. Dazu gehört ein zu häufiger Aufruf der API und die Tatsache, dass die von ihnen zurückgegebenen Daten nicht den Anforderungen des Frontends entsprechen.
Wir werden die Lösung für jedes dieser Probleme in separate Codeblöcke aufteilen, von denen jeder in einer eigenen Datei abgelegt wird. Infolgedessen besteht die BIF-Schicht des Client-Teils der Anwendung aus zwei Dateien. Zusätzlich wird ihnen eine Testdatei angehängt.
▍ API-Aufrufe kombinieren
Das Aufrufen der Server-APIs in unserem Client-Code ist kein so ernstes Problem. Ich möchte es jedoch abstrahieren, um es zu ermöglichen, eine einzelne „Anfrage“ (vom Anwendungscode bis zur BIF-Schicht) zu erfüllen und genau das zu erhalten, was als Antwort benötigt wird.
In unserem Fall gibt es natürlich kein Entrinnen, drei HTTP-Anforderungen an den Server zu senden, aber die Anwendung muss nichts darüber wissen.
Die API meiner BIF-Schicht wird als Funktionen dargestellt. Wenn die Anwendung einige Daten über den Benutzer benötigt, ruft sie daher die Funktion
getUser() , die diese Daten an sie
getUser() . So sieht diese Funktion aus:
import parseUserData from './parseUserData'; import fetchJson from './fetchJson'; export const getUser = async () => { const auth = await fetchJson('/auth'); const [ profile, notifications ] = await Promise.all([ fetchJson(`/profile/${auth.userId}`, auth.jwt), fetchJson(`/notifications/${auth.userId}`, auth.jwt), ]); return parseUserData(auth, profile, notifications); };
Hier wird zunächst eine Anforderung an den Authentifizierungsdienst gestellt, um ein Token zu erhalten, mit dem der Benutzer autorisiert werden kann (wir werden hier nicht über Authentifizierungsmechanismen sprechen, unser Hauptziel ist jedoch BIF).
Nach dem Empfang des Tokens können Sie gleichzeitig zwei Anforderungen ausführen, die Benutzerprofildaten und Informationen zu ungelesenen Benachrichtigungen erhalten.
Schauen Sie sich übrigens an, wie schön das Konstrukt
async/await aussieht, wenn Sie mit
Promise.all und destruktiver Zuweisung damit arbeiten.
Dies war also der erste Schritt. Hier haben wir von der Tatsache abstrahiert, dass der Zugriff auf den Server drei Anforderungen umfasst. Der Fall ist jedoch noch nicht abgeschlossen.
parseUserData() nämlich auf den Aufruf der Funktion
parseUserData() , die, wie Sie anhand ihres Namens
parseUserData() können, die vom Server empfangenen Daten
parseUserData() . Reden wir über sie.
▍ Datenbereinigung
Ich möchte sofort eine Empfehlung aussprechen, die meines Erachtens ein Projekt, das zuvor keine BIF-Schicht hatte, ernsthaft beeinträchtigen kann, insbesondere ein neues Projekt. Denken Sie eine Weile nicht darüber nach, was Sie vom Server erhalten. Konzentrieren Sie sich stattdessen darauf, welche Daten Ihre Anwendung benötigt.
Darüber hinaus ist es am besten, beim Entwerfen der Anwendung nicht zu versuchen, mögliche zukünftige Anforderungen zu berücksichtigen, beispielsweise im Zusammenhang mit 2021. Versuchen Sie einfach, die Anwendung genau so zu machen, wie sie heute sollte. Tatsache ist, dass übermäßige Begeisterung für die Planung und Versuche, die Zukunft vorherzusagen, der Hauptgrund für die ungerechtfertigte Komplikation von Softwareprojekten ist.
Also zurück zu unserem Geschäft. Jetzt wissen wir, wie die von den drei Server-APIs empfangenen Daten aussehen, und wir wissen, wie sie nach der Analyse umgewandelt werden sollen.
Es scheint, dass hier einer dieser seltenen Fälle ist, in denen die Verwendung von TDD wirklich Sinn macht. Daher werden wir einen langen Test für die Funktion
parseUserData() schreiben:
import parseUserData from './parseUserData'; it('should parse the data', () => { const authApiData = { userId: 1234, jwt: 'the jwt', }; const profileApiData = { Profiles: [ { id: 1234, Christian_Name: 'David', Surname: 'Gilbertson', Photographs: [ { Size: 'Medium', URLS: [ '/images/david.png', ], }, ], Last_Login: '2018-01-01' }, ], }; const notificationsApiData = { data: { 'msg-1234': { timestamp: '1529739612', user: { Christian_Name: 'Alice', Surname: 'Guthbertson', Enhanced: 'True', Photographs: [ { Size: 'Medium', URLS: [ '/images/alice.png' ] } ] }, message_summary: 'Hey I like your hair, it re', message: 'Hey I like your hair, it really goes nice with your eyes' }, 'msg-5678': { timestamp: '1529731234', user: { Christian_Name: 'Bob', Surname: 'Smelthsen', }, message_summary: 'I\'m launching my own cryptocu', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, }, }; const parsedData = parseUserData(authApiData, profileApiData, notificationsApiData); expect(parsedData).toEqual({ jwt: 'the jwt', id: '1234', name: 'David Gilbertson', photoUrl: '/images/david.png', notifications: [ { id: 'msg-1234', dateTime: expect.any(Date), name: 'Alice Guthbertson', premiumMember: true, photoUrl: '/images/alice.png', message: 'Hey I like your hair, it really goes nice with your eyes' }, { id: 'msg-5678', dateTime: expect.any(Date), name: 'Bob Smelthsen', premiumMember: false, photoUrl: '/images/placeholder.jpg', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, ], }); });
Und hier ist der Code der Funktion selbst:
const getPhotoFromProfile = profile => { try { return profile.Photographs[0].URLS[0]; } catch (err) { return '/images/placeholder.jpg'; // } }; const getFullNameFromProfile = profile => `${profile.Christian_Name} ${profile.Surname}`; export default function parseUserData(authApiData, profileApiData, notificationsApiData) { const profile = profileApiData.Profiles[0]; const result = { jwt: authApiData.jwt, id: authApiData.userId.toString(), // ID name: getFullNameFromProfile(profile), photoUrl: getPhotoFromProfile(profile), notifications: [], // , }; Object.entries(notificationsApiData.data).forEach(([id, notification]) => { result.notifications.push({ id, dateTime: new Date(Number(notification.timestamp) * 1000), // , , , Unix, name: getFullNameFromProfile(notification.user), photoUrl: getPhotoFromProfile(notification.user), message: notification.message, premiumMember: notification.user.Enhanced === 'True', }) }); return result; }
Ich möchte darauf hinweisen, dass, wenn es möglich ist, zweihundert Codezeilen an einem Ort zu sammeln, die für die Änderung der zuvor in der gesamten Anwendung verteilten Daten verantwortlich sind, dies ein wunderbares Gefühl hervorruft. Jetzt ist alles in einer Datei, Unit-Tests werden für diesen Code geschrieben und alle mehrdeutigen Momente werden mit Kommentaren versehen.
Ich habe vorhin gesagt, dass BFF mein bevorzugter Ansatz zum Kombinieren und Löschen von Daten ist, aber es gibt einen Bereich, in dem BIF BFF überlegen ist. Die vom Server empfangenen Daten können nämlich JavaScript-Objekte enthalten, die JSON nicht unterstützen, wie z. B.
Date oder
Map (dies ist möglicherweise eine der am wenigsten genutzten JavaScript-Funktionen). In unserem Fall müssen wir beispielsweise das Datum, das vom Server kam (ausgedrückt in Sekunden, nicht in Millisekunden), in ein JS-Objekt vom Typ
Date konvertieren.
Zusammenfassung
Wenn Sie der Meinung sind, dass Ihr Projekt etwas mit dem gemeinsam hat, bei dem wir die Probleme nicht erfolgreicher APIs untersucht haben, analysieren Sie den Code, indem Sie sich die folgenden Fragen zur Verwendung von Daten vom Server auf dem Client stellen:
- Müssen Sie Eigenschaften kombinieren, die niemals separat verwendet werden (z. B. Vor- und Nachname des Benutzers)?
- Muss der JS-Code mit Eigenschaftsnamen arbeiten, die so gebildet wurden, dass sie in JS nicht akzeptiert werden (so etwas wie PascalCase)?
- Was sind die Datentypen der verschiedenen Bezeichner? Vielleicht sind das manchmal Zeichenfolgen, manchmal Zahlen?
- Wie werden Termine in Ihrem Projekt dargestellt? Vielleicht sind dies manchmal
Date JS-Objekte, die für die Verwendung in der Benutzeroberfläche bereit sind, und manchmal Zahlen oder sogar Zeichenfolgen? - Müssen Sie häufig Eigenschaften auf ihre Existenz überprüfen oder prüfen, ob eine Entität ein Array ist, bevor Sie mit der Aufzählung der Elemente dieser Entität beginnen, um auf ihrer Basis ein Fragment der Benutzeroberfläche zu bilden? Könnte es sein, dass diese Entität kein Array ist, auch wenn sie leer ist?
- Müssen Sie beim Bilden der Schnittstelle Arrays sortieren oder filtern, die im Idealfall bereits korrekt sortiert und gefiltert sein sollten?
- Wenn sich herausstellt, dass beim Überprüfen der Eigenschaften auf ihre Existenz keine gesuchten Eigenschaften gesucht werden, müssen Sie dann auf einige Standardwerte umschalten (verwenden Sie beispielsweise ein Standardbild, wenn die vom Server empfangenen Daten kein Benutzerfoto enthalten)?
- Sind die Eigenschaften einheitlich benannt? Kommt es vor, dass dieselbe Entität unterschiedliche Namen haben kann, was möglicherweise durch die gemeinsame Verwendung von relativ alten "alten" und "neuen" Server-APIs verursacht wird?
- Müssen Sie zusammen mit nützlichen Daten Daten übertragen, die niemals verwendet werden, und zwar nur, weil sie von der Server-API stammen? Beeinträchtigen diese nicht verwendeten Daten das Debuggen?
Wenn Sie eine oder zwei Fragen aus dieser Liste positiv beantworten können, sollten Sie möglicherweise etwas nicht reparieren, das bereits ordnungsgemäß funktioniert.
Wenn Sie jedoch beim Lesen dieser Fragen in jedem von ihnen die Probleme Ihres Projekts herausfinden, wenn das Gerät Ihres Codes aufgrund all dessen unnötig kompliziert ist, wenn es schwer zu erkennen und zu testen ist, wenn es Fehler enthält, die schwer zu erkennen sind, schauen Sie sich das BIF-Muster an.
Abschließend möchte ich sagen, dass bei der Einführung der BIF-Schicht in vorhandene Anwendungen die Dinge einfacher sind, da dies schrittweise und in kleinen Schritten erfolgen kann. Nehmen wir an, die erste Version der Funktion zum Vorbereiten von Daten, nennen wir sie
parseData() , kann einfach ohne Änderungen zurückgeben, was zu ihrer Eingabe kommt. Anschließend können Sie die Logik schrittweise vom Code, der für die Erstellung der Benutzeroberfläche verantwortlich ist, zu dieser Funktion verschieben.
Liebe Leser! , BIF?
