In einem früheren Artikel habe ich die Verwendung der Kohortenanalyse beschrieben, um die Gründe für die Dynamik des Kundenstamms zu ermitteln. Heute ist es Zeit, über Datenvorbereitungstricks für die Kohortenanalyse zu sprechen.
Es ist einfach, Bilder zu zeichnen, aber damit sie „unter der Haube“ richtig gelesen und angezeigt werden können, muss noch viel Arbeit geleistet werden. In diesem Artikel werden wir über die Implementierung der Kohortenanalyse sprechen. Ich werde über die Implementierung mit Excel und in einem anderen Artikel mit R sprechen.
Ob es uns gefällt oder nicht, aber tatsächlich ist Excel ein Datenanalysetool. Mehr "arrogante" Analysten werden glauben, dass dies ein schwaches und nicht bequemes Werkzeug ist. Auf der anderen Seite führen Hunderttausende von Menschen Datenanalysen in Excel durch, und in dieser Hinsicht wird es R / Python leicht schlagen. Wenn wir über Fortschritte in der Analytik und im maschinellen Lernen sprechen, werden wir natürlich an R / Python arbeiten. Und ich möchte, dass die meisten Analysen nur mit diesen Tools durchgeführt werden. Es lohnt sich jedoch, die Fakten zu berücksichtigen, da die überwiegende Mehrheit der Unternehmen Daten in Excel verarbeitet und präsentiert. Dies ist das Tool, das normale Analysten, Manager und Produktbesitzer verwenden. Darüber hinaus ist Excel in Bezug auf Einfachheit und Klarheit des Prozesses schwer zu besiegen, weil Sie beherrschen Ihre Berechnungen und Modelle buchstäblich mit Ihren Händen.
Wie führen wir eine Kohortenanalyse in Excel durch? Um solche Probleme zu lösen, müssen Sie zwei Dinge bestimmen:
Welche Daten haben wir zu Beginn des Prozesses?
Wie unsere Daten am Ende des Prozesses aussehen sollten.
Um eine Kohortenanalyse zu erstellen, benötigen wir nicht nur Rückdaten zu Daten und Abteilungen. Wir brauchen Daten auf individueller Kundenebene. Zu Beginn des Prozesses brauchen wir:
Kalenderdatum
Kunden-ID
Registrierungsdatum des Kunden
Verkaufsvolumen dieses Kunden an diesem Kalendertag
Die erste Schwierigkeit, die überwunden werden muss, besteht darin, diese Daten zu erhalten. Wenn Sie den richtigen Speicher haben, sollten Sie ihn bereits haben. Wenn Sie jedoch bisher nur die Erfassung von Daten zum Gesamtumsatz pro Tag implementiert haben, verfügen Sie nur über Kundendaten zu „Produkt“. Für die Kohortenanalyse müssen Sie ETL implementieren und die Daten im Kontext von Clients in Ihrem Speicher ablegen, da Sie sonst keinen Erfolg haben. Und das Beste ist, wenn Sie "Produkt" und Analyse in verschiedene Datenbanken trennen, weil Analytische Aufgaben und die funktionierenden Aufgaben Ihres Produkts haben unterschiedliche Ziele: Wettbewerb um Ressourcen. Analysten benötigen für viele Benutzer schnelle Aggregate und Berechnungen. Das Produkt muss schnell einen bestimmten Benutzer bedienen. Ich werde einen separaten Artikel über die Speicherorganisation schreiben.
Sie haben also Startdaten:

Das erste, was wir tun müssen, ist, sie in „Leitern“ umzuwandeln. Dazu müssen Sie über dieser Tabelle eine Pivot-Tabelle erstellen, in Zeilen - dem Registrierungsdatum, in Spalten - dem Kalenderdatum, als Werte - der Anzahl der Client-IDs. Wenn Sie die Daten korrekt extrahiert haben, sollten Sie ein solches Dreieck / eine solche Leiter erhalten:
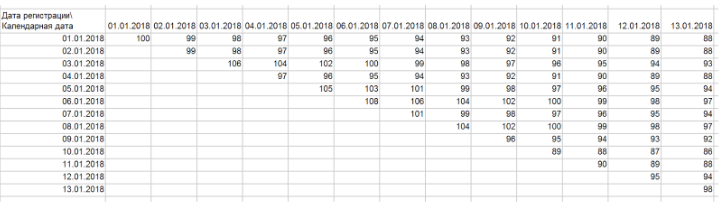
Im Allgemeinen ist eine Leiter unser Kohortendiagramm, in dem jede Zeile die Dynamik einer separaten Kohorte anzeigt. Clients in dieser Anzeige bewegen sich zeitlich nur innerhalb einer Zeile. Die Dynamik der Kohorte spiegelt somit die Entwicklung der Beziehungen zu einer Gruppe von Kunden wider, die in einem bestimmten Zeitraum kamen. Der Einfachheit halber und ohne Qualitätsverlust können Sie Kohorten häufig zu „Zeilenblöcken“ kombinieren. Sie können sie beispielsweise nach Woche und Monat gruppieren. Auf die gleiche Weise können Sie auch eine Spalte gruppieren. Möglicherweise erfordert Ihr Tempo bei der Produktentwicklung keine detaillierten Angaben bis zu Tagen.
Basierend auf dieser Leiter können Sie aus meinem Artikel ein Diagramm erstellen (ich habe wirklich darauf hingewiesen, dass ich mehrere Zeilen zu einer zusammengefasst habe, sodass die Kohorte kleiner war):
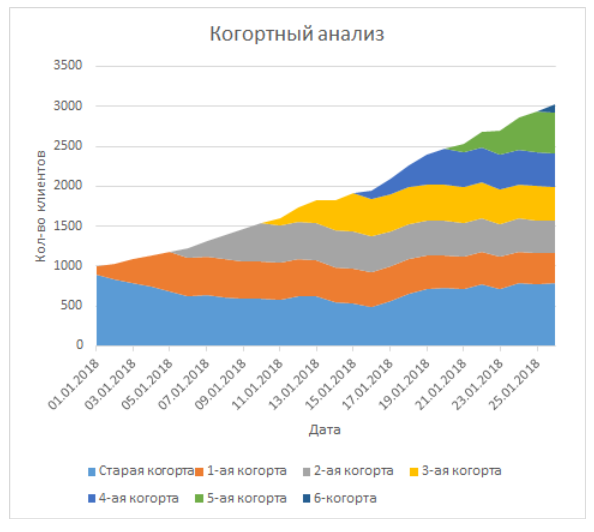
Dies ist ein Diagramm mit kumulativen Bereichen, in denen jede Zeile eine Zeile horizontal eines Datums ist.
Eine etwas kompliziertere Logik zur Implementierung des Zeitplans für "Flows". Für Threads müssen wir einige zusätzliche Berechnungen durchführen. In der Thread-Logik kommt jeder Client in verschiedenen Zuständen an:
- Neu - jeder Kunde, der einen Unterschied zwischen dem Registrierungsdatum und dem Kalenderdatum <7 Tage hat
- Reaktiviert - Jeder Kunde, der nicht mehr neu ist, aber im letzten Kalendermonat keine Einnahmen erzielt hat
- Gültig - jeder Kunde, der nicht neu ist, aber im Kalendermonat Umsatz generiert
- Abgereist - jeder Kunde, der 2 aufeinanderfolgende Monate lang keinen Umsatz erzielt
Zunächst sollten Sie diese Definitionen im Unternehmen korrigieren, damit Sie diese Logik korrekt implementieren und die Zustände automatisch berechnen können. Diese 4 Definitionen haben weitreichende Auswirkungen auf das Marketing im Allgemeinen. Ihre Strategien zur Gewinnung, Bindung und Rückkehr basieren auf dem Zustand, in dem sich der Kunde Ihrer Meinung nach befindet. Wenn Sie mit der Implementierung von Modellen für maschinelles Lernen beginnen, um Kundenabgänge vorherzusagen, werden Definitionen zu Ihrem Eckpfeiler für den Erfolg dieser Modelle. Im Allgemeinen werde ich einen separaten Artikel über die Organisation der Arbeit und die Bedeutung der analytischen Methodik schreiben. Oben habe ich nur ein Beispiel gegeben, wie diese Definitionen aussehen können.
In Excel müssen Sie eine zusätzliche Spalte erstellen, in die Sie die oben beschriebene Logik eingeben können. In unserem Fall müssen wir „schwitzen“. Wir haben zwei Arten von Kriterien:
- Die Differenz zwischen dem Registrierungsdatum und dem Kalenderdatum - jede Zeile enthält diese Daten, und Sie müssen sie nur noch berechnen (das Subtrahieren von Daten in Excel ergibt nur die Differenz in Tagen).
- Umsatzdaten für den aktuellen und letzten Monat. Diese Daten stehen uns in der Zeile nicht zur Verfügung. Unter Berücksichtigung der Tatsache, dass die Bestellung in unserer Tabelle nicht garantiert ist, können Sie nicht genau sagen, wo Sie Daten an anderen Tagen des Monats für diesen Kunden haben.
Es gibt zwei Möglichkeiten, um das Problem zweier Arten von Kriterien zu lösen:
- Bitten Sie darum, dies in der Datenbank zu tun. SQL ermöglicht die Verwendung der Analysefunktion, um für jeden Kunden die Höhe des Umsatzes für den aktuellen und den letzten Monat zu berechnen (für den aktuellen Monat SUMME (Umsatz) ÜBER (PARTITION NACH client_id, calendar_month und dann LAG, um den Offset für den letzten Monat zu erhalten):
- In Excel müssen Sie es folgendermaßen implementieren:
- Für den aktuellen Monat: SUMMES () sind die Kriterien die Client-ID und der Monat der Kalendertagzelle
- Für den letzten Monat: SUMMES () sind die Kriterien die Client-ID und der Monat der Kalendertagzelle minus genau 1 Kalendermonat. In diesem Fall mache ich darauf aufmerksam, dass Sie den Kalendermonat und nicht 30 Tage abziehen müssen. Andernfalls besteht die Gefahr, dass Sie aufgrund der ungeraden Anzahl von Tagen in den Monaten ein verschwommenes Bild erhalten. Verwenden Sie auch die Funktion IF ERROR, um fehlerhafte Werte für Kunden zu ersetzen, die den letzten Monat nicht hatten.
Durch Hinzufügen der Umsatzspalten des aktuellen Monats des letzten Monats können Sie eine eingebettete Bedingung erstellen, wenn alle Faktoren (Datumsunterschiede und Umsatzbetrag im aktuellen / letzten Monat) berücksichtigt werden:
IF (Datumsdifferenz <7; "neu";
IF (AND (Umsatz des letzten Monats = 0; Umsatz des aktuellen Monats> 0); „Reaktivierung“;
IF (AND (Umsatz im letzten Monat> 0; Umsatz im laufenden Monat> 0); „aktuell“
IF (AND (Umsatz des letzten Monats = 0; Umsatz des aktuellen Monats = 0); "abgereist"; "Fehler")))
"Fehler" wird hier nur benötigt, um zu kontrollieren, dass Sie sich bei der Aufnahme nicht geirrt haben. Die Logik der MECE-Zustandskriterien ( https://en.wikipedia.org/wiki/MECE_principle ), d.h. Wenn alles richtig gemacht ist, wird jedem von ihnen ein Zustand von 4 hinzugefügt
Sie sollten es so bekommen:

Jetzt kann diese Tabelle mithilfe einer Pivot-Tabelle in eine Tabelle zum Plotten umgebaut werden. Sie müssen es in eine Tabelle umwandeln:
Kalenderdatum (Spalten)
Zustand (Zeilen)
Anzahl der Client-IDs (Werte in Zellen)
Als nächstes müssen wir einfach ein Balkendiagramm auf der Grundlage von Daten erstellen, mit Akkumulationen, auf der X-Achse das Kalenderdatum, Zeilen sind Zustände, Anzahl der Clients ist Spaltenhöhe. Sie können die Reihenfolge der Zustände im Diagramm ändern, indem Sie die Reihenfolge der Zeilen im Menü „Daten auswählen“ ändern. Als Ergebnis erhalten wir folgendes Bild:
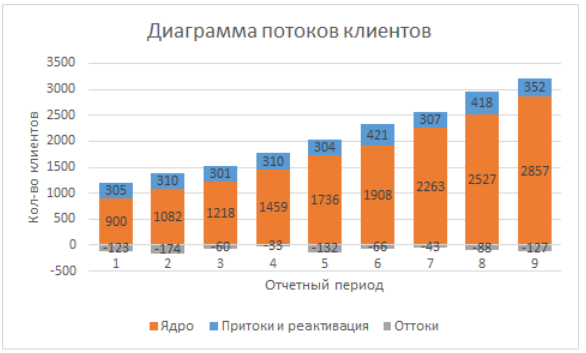
Jetzt können wir anfangen zu interpretieren und zu analysieren.