
Das akademische Design des Data Warehouse empfiehlt, alles in einer normalisierten Form mit Verbindungen zwischen ihnen zu halten. Das Rollback von Änderungen in der relationalen Mathematik bietet dann ein zuverlässiges Repository mit Transaktionsunterstützung. Atomizität, Konsistenz, Isolation, Haltbarkeit - das ist alles. Mit anderen Worten, das Repository wurde speziell entwickelt, um Daten sicher zu aktualisieren. Es ist jedoch überhaupt nicht optimal für die Suche, insbesondere mit einer breiten Geste über Tabellen und Felder hinweg. Benötigen Sie Indizes, viele Indizes. Das Volumen wächst, die Aufnahme verlangsamt sich. SQL LIKE ist nicht indiziert und JOIN GROUP BY sendet es zur Meditation an den Abfrageplaner.
Die zunehmende Belastung einer Maschine zwingt sie dazu, sich entweder vertikal in die Decke oder horizontal auszudehnen und ein paar weitere Knoten zu kaufen. Durch Failover-Anforderungen werden Daten auf mehrere Knoten verteilt. Das Erfordernis einer sofortigen Wiederherstellung nach einem Fehler ohne Denial-of-Service zwingt Sie dazu, den Maschinencluster so zu konfigurieren, dass jeder von ihnen jederzeit sowohl schreiben als auch lesen kann. Das heißt, bereits ein Meister zu sein oder ihn automatisch und sofort zu werden.
Das Problem der schnellen Suche wurde gelöst, indem ein zweites Repository installiert wurde, das für die Indizierung in der Nähe optimiert ist. Volltextsuche, facettiert, mit Stemming und Blackjack . Der zweite Speicher akzeptiert Einträge aus den Tabellen des ersten als Eingabe, analysiert und erstellt den Index. Daher wurde der Datenspeichercluster für die Suche durch einen anderen Cluster ergänzt. Mit einer ähnlichen Masterkonfiguration, die dem gesamten SLA entspricht . Alles ist in Ordnung, das Geschäft läuft gut, Administratoren schlafen nachts ... bis mehr als drei Maschinen im Master-Master-Cluster sind.
Elastisch
Die NoSQL- Bewegung hat den Skalenhorizont sowohl für kleine als auch für große Daten erheblich erweitert. Die NoSQL-Knoten des Clusters können Daten untereinander verteilen, sodass der Ausfall eines oder mehrerer von ihnen nicht zu einem Denial-of-Service für den gesamten Cluster führt. Die Zahlung für die hohe Verfügbarkeit verteilter Daten war die Unfähigkeit, ihre vollständige Konsistenz für die Aufzeichnung zu einem bestimmten Zeitpunkt sicherzustellen. Stattdessen spricht NoSQL von einer möglichen Konsistenz . Das heißt, es wird angenommen, dass eines Tages alle Daten auf die Knoten des Clusters verteilt werden und auf lange Sicht konsistent werden.
Das relationale Modell wurde also durch das nicht relationale Modell ergänzt und brachte viele Datenbank-Engines hervor, die die Probleme des CAP- Dreiecks mit einigem Erfolg lösen. Die Entwickler haben modische Werkzeuge in die Hand genommen, um ihre eigene ideale Persistenzschicht aufzubauen - für jeden Geschmack, jedes Budget und jedes Lastprofil.
ElasticSearch ist ein Vertreter von NoSQL, das mit einer RESTful JSON-API auf der Lucene-Engine, Open Source in Java, geclustert ist und nicht nur einen Suchindex erstellen, sondern auch das Originaldokument speichern kann. Eine solche Finte hilft dabei, die Rolle eines separaten DBMS zum Speichern von Originalen zu überdenken oder sogar aufzugeben. Das Ende der Einführung.
Zuordnung
Die Zuordnung in ElasticSearch ist so etwas wie ein Schema (Tabellenstruktur in Bezug auf SQL), das Ihnen genau sagt, wie eingehende Dokumente (Datensätze in Bezug auf SQL) indiziert werden. Die Zuordnung kann statisch, dynamisch oder nicht vorhanden sein. Die statische Zuordnung lässt sich nicht ändern. Mit Dynamic können Sie neue Felder hinzufügen. Wenn keine Zuordnung angegeben ist, führt ElasticSearch dies selbst durch, nachdem das erste Dokument zum Schreiben erhalten wurde. Es wird die Struktur der Felder analysieren, einige Annahmen über die darin enthaltenen Datentypen treffen, die Standardeinstellungen überspringen und aufschreiben. Ein solches schaltungsloses Verhalten erscheint auf den ersten Blick sehr praktisch. Tatsächlich eignet es sich jedoch eher zum Experimentieren als für Überraschungen in der Produktion.
Die Daten werden also indiziert, und dies ist ein Einwegprozess. Einmal erstellt, kann die Zuordnung in SQL nicht dynamisch als ALTER TABLE geändert werden. Weil die SQL-Tabelle das Originaldokument speichert, an das Sie den Suchindex binden können. Bei ElasticSearch ist das Gegenteil der Fall. Er selbst ist der Suchindex, an dem Sie das Originaldokument befestigen können. Aus diesem Grund ist das Indexschema statisch. Theoretisch könnte man entweder ein Feld in der Zuordnung erstellen oder es löschen. In der Praxis können Sie mit ElasticSearch nur Felder hinzufügen. Ein Versuch, ein Feld zu löschen, führt zu nichts.
Alias
Alias - Dies ist ein zusätzlicher Name für den ElasticSearch-Index. Es können mehrere Aliase für einen Index vorhanden sein. Oder ein Alias für mehrere Indizes. Dann werden die Indizes wie von außen logisch kombiniert und sehen aus wie einer. Alias ist sehr praktisch für Dienste, die während ihres gesamten Lebens mit dem Index kommunizieren. Beispielsweise können die Alias-Produkte sowohl products_v2 als auch products_v25 ausblenden, ohne die Namen im Service ändern zu müssen. Alias ist für die Datenmigration unverzichtbar, wenn sie bereits vom alten zum neuen Schema übertragen wurden und Sie die Anwendung wechseln müssen, um mit dem neuen Index zu arbeiten. Das Umschalten eines Alias von Index zu Index ist eine atomare Operation. Das heißt, es wird in einem Schritt ohne Verlust ausgeführt.
API neu indizieren
Das Datenlayout und die Zuordnung ändern sich von Zeit zu Zeit. Neue Felder werden hinzugefügt, unnötige werden gelöscht. Wenn ElasticSearch die Rolle des einzigen Repositorys spielt, benötigen Sie ein Tool, mit dem Sie die Zuordnung im laufenden Betrieb ändern können. Zu diesem Zweck gibt es einen speziellen Befehl zum Übertragen von Daten von einem Index zu einem anderen, die sogenannte _reindex-API . Es funktioniert mit einer vorgefertigten oder leeren Zuordnung des Empfängerindex auf der Serverseite und einer schnellen Indizierung in Stapeln von jeweils 1000 Dokumenten.
Durch die Neuindizierung kann eine einfache Feldtypkonvertierung durchgeführt werden. Zum Beispiel lang in Text und zurück in lang oder boolesch in Text und zurück in boolesch . Aber -9,99 in Booleschen wissen nicht mehr wie, Es ist nicht PHP für Sie . Andererseits ist die Typkonvertierung nicht sicher. Ein Dienst, der in einer Sprache mit dynamischer Typisierung geschrieben ist, kann für eine solche Sünde vergeben werden. Wenn die Neuindizierung den Typ jedoch nicht konvertieren kann, wird das Dokument einfach nicht geschrieben. Im Allgemeinen sollte die Datenmigration in drei Schritten erfolgen: Hinzufügen eines neuen Felds, Freigeben eines Dienstes damit, Bereinigen des alten.
Ein Feld wird wie folgt hinzugefügt. Das Quellindexschema wird übernommen, eine neue Eigenschaft eingegeben, ein leerer Index erstellt. Dann beginnt die Neuindizierung:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
Das Feld wird auf ähnliche Weise gelöscht. Das Quellindexschema wird übernommen, das Feld wird entfernt, ein leerer Index wird erstellt. Anschließend wird die Neuindizierung mit einer Liste der zu kopierenden Felder gestartet:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
Der Einfachheit halber werden beide Fälle in Kaizen, einem Desktop-Client für ElasticSearch, zu einer Klonfunktion zusammengefasst. Das Klonen kann an die Zuordnung des Zielindex angepasst werden. Das folgende Beispiel zeigt, wie ein Teilklon aus einem Index mit drei Sammlungen (Typen in Bezug auf ElasticSearch) erstellt wird: act , line , scene . Es bleibt nur eine Zeile mit zwei Feldern übrig, die statische Zuordnung ist aktiviert und das Feld language_number aus Text wird lang .
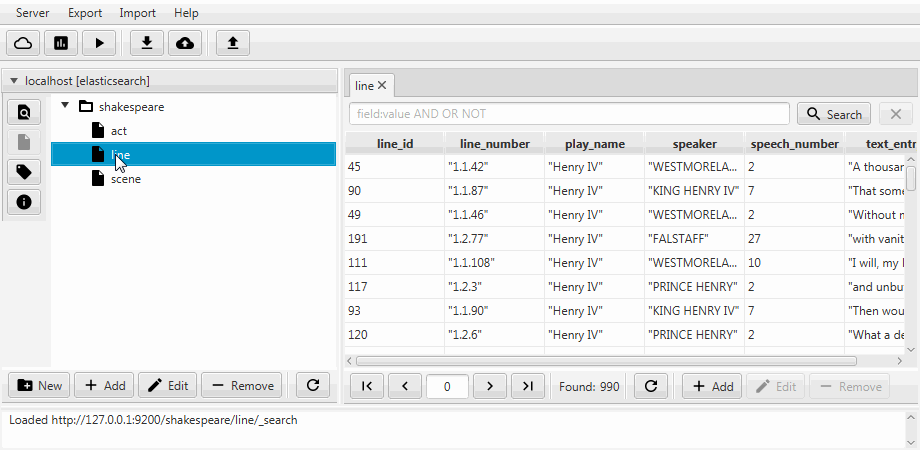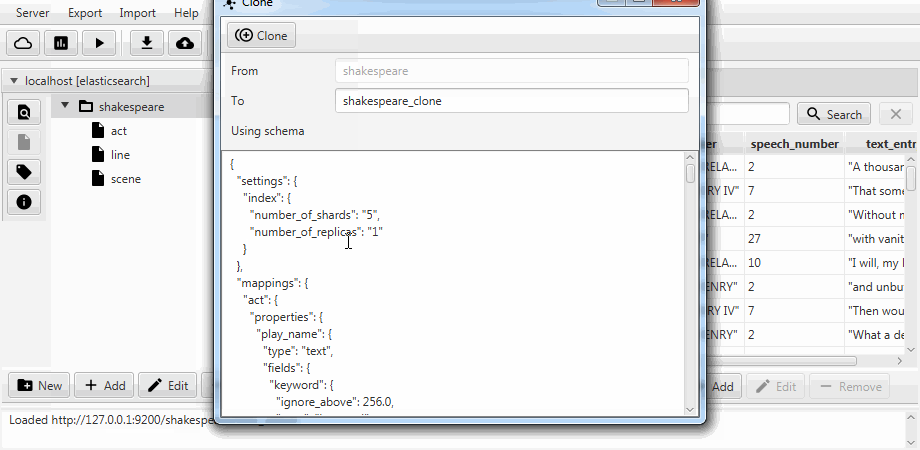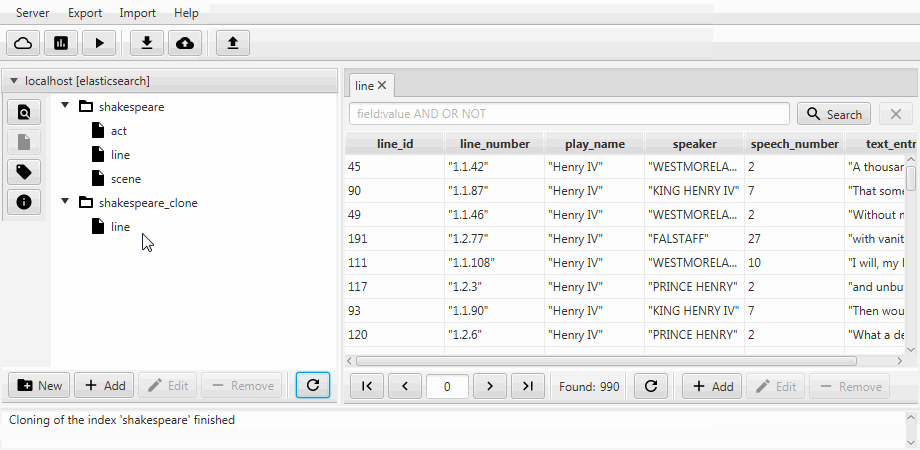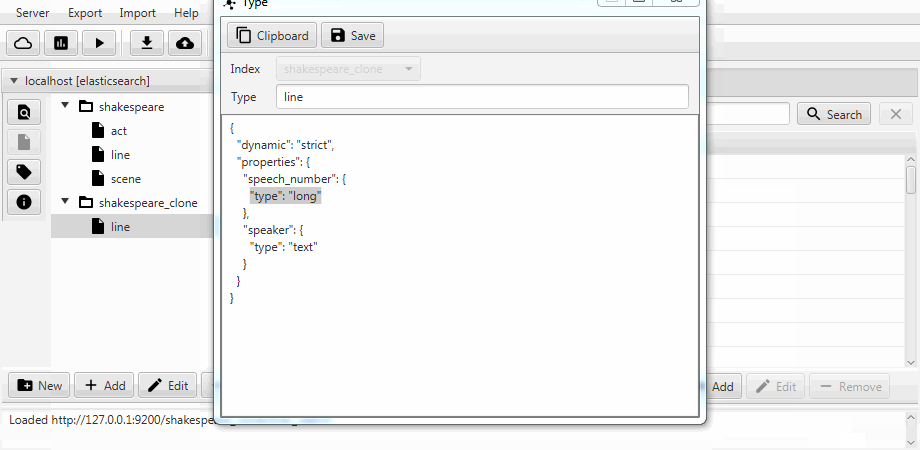
Die Migration
Die Reindex-API hat eine unangenehme Funktion: Sie kann Änderungen im Quellindex nicht überwachen. Wenn sich dort nach Beginn der Neuindizierung etwas ändert, werden die Änderungen nicht im Empfängerindex wiedergegeben. Um dieses Problem zu lösen, wurde das ElasticSearch FollowUp Plugin entwickelt, das Protokollierungsbefehle hinzufügt. Das Plugin kann den Index überwachen und die für Dokumente ausgeführten Aktionen im JSON-Format in chronologischer Reihenfolge zurückgeben. Der Index, der Typ, die Dokumentkennung und die Operation darauf - INDEX oder DELETE - werden gespeichert. Das FollowUp Plugin wird auf GitHub veröffentlicht und für fast alle Versionen von ElasticSearch kompiliert.
Für eine verlustfreie Datenmigration muss FollowUp auf dem Knoten installiert sein, auf dem die Neuindizierung beginnt. Es wird davon ausgegangen, dass der Index bereits über einen Alias verfügt und von allen Anwendungen verarbeitet wird. Kurz vor der Neuindizierung wird das Plugin aktiviert. Wenn die Neuindizierung abgeschlossen ist, wird das Plugin heruntergefahren und der Alias wird auf den neuen Index gespiegelt. Dann werden die aufgezeichneten Aktionen im Empfängerindex reproduziert und holen seinen Status ein. Trotz der hohen Geschwindigkeit der Neuindizierung können während der Wiedergabe zwei Arten von Kollisionen auftreten:
- Es gibt kein Dokument mehr mit einer solchen _id im neuen Index. Sie konnten das Dokument löschen, nachdem der Alias auf den neuen Index umgestellt wurde.
- Im neuen Index gibt es ein Dokument mit einer solchen _id , jedoch mit einer höheren Versionsnummer als im Quellindex . Sie konnten das Dokument aktualisieren, nachdem der Alias auf den neuen Index umgestellt wurde.
In diesen Fällen sollte die Aktion nicht im Zielindex reproduziert werden. Andere Änderungen werden reproduziert.
Viel Spaß beim Codieren!