 Das ist eine echte Geschichte. Die in der Post beschriebenen Ereignisse ereigneten sich im 21. Jahrhundert in einem warmen Land. Nur für den Fall, dass die Namen der Charaktere geändert wurden. Aus Respekt vor dem Beruf wird alles so erzählt, wie es wirklich war.
Das ist eine echte Geschichte. Die in der Post beschriebenen Ereignisse ereigneten sich im 21. Jahrhundert in einem warmen Land. Nur für den Fall, dass die Namen der Charaktere geändert wurden. Aus Respekt vor dem Beruf wird alles so erzählt, wie es wirklich war.
Hallo Habr. In diesem Beitrag werden wir über die berüchtigten A / B-Tests sprechen, die leider auch im 21. Jahrhundert nicht vermieden werden können. Alternative Testoptionen gab es schon lange online und sie blühten auf, während sich Offline-Testoptionen an die jeweilige Situation anpassen müssen. Wir werden über eine solche Anpassung im Massen-Offline-Einzelhandel sprechen und die Erfahrung der Zusammenarbeit mit einem Top-Beratungsbüro im Allgemeinen unter cat.
Herausforderung
 In der Vergangenheit habe ich an einem Projekt in einem großen Unternehmen gearbeitet, das ein Netzwerk von Lebensmittelgeschäften besitzt, mehr als 500 Geschäfte. Ich befürchte, dass ich das Unternehmen nicht benennen sollte, wir werden diese Organisation das Unternehmen nennen. Das Fazit ist, dass die Geschäfte unterschiedliche Größen haben und zehnmal unterschiedlich groß sein können. Geschäfte können in verschiedenen Städten, Dörfern und Dörfern sein; Geschäfte können sich in verschiedenen Bereichen der Stadt mit ihrer eigenen Demografie befinden. Im Allgemeinen tendiere ich hier zu der Tatsache, dass es im A / B-Testparadigma fast unmöglich ist, dies zu tun, ohne das Geschäft erheblich zu schädigen, wenn Sie eine Hypothese testen müssen. Betrachten wir das Ganze am Beispiel des Bieres. Sobald das Beratungsbüro zum Unternehmen kommt, wissen Sie, dass diese von ganz oben kommen und sagen: „Aber Sie wissen, Liebes, Sie haben hier Bier, das nicht von den richtigen Marken in den Fenstern ist und im Allgemeinen nicht in der Reihenfolge, die Sie benötigen. Schicken Sie uns ein paar Kamaz-Goldstücke und wir werden Ihnen sagen, welche Marken Sie benötigen und wie Sie sie ausklappen können. Nach unseren Schätzungen werden Sie im ersten Jahr nach dem Pilotversuch eine Milliarde kanadische Dollar erhalten. " Das Büro wird respektiert, so dass es keinen Zweifel über eine Milliarde geben kann. Auch die Methoden des Amtes können nicht in Frage gestellt werden, da sie nicht lügen können. Nur nicht wir. Im Allgemeinen hat der Autor dieser Zeilen die Aufgabe "Nun, schauen Sie dort, wie sie den Piloten machen, helfen Sie, wenn sie etwas brauchen".
In der Vergangenheit habe ich an einem Projekt in einem großen Unternehmen gearbeitet, das ein Netzwerk von Lebensmittelgeschäften besitzt, mehr als 500 Geschäfte. Ich befürchte, dass ich das Unternehmen nicht benennen sollte, wir werden diese Organisation das Unternehmen nennen. Das Fazit ist, dass die Geschäfte unterschiedliche Größen haben und zehnmal unterschiedlich groß sein können. Geschäfte können in verschiedenen Städten, Dörfern und Dörfern sein; Geschäfte können sich in verschiedenen Bereichen der Stadt mit ihrer eigenen Demografie befinden. Im Allgemeinen tendiere ich hier zu der Tatsache, dass es im A / B-Testparadigma fast unmöglich ist, dies zu tun, ohne das Geschäft erheblich zu schädigen, wenn Sie eine Hypothese testen müssen. Betrachten wir das Ganze am Beispiel des Bieres. Sobald das Beratungsbüro zum Unternehmen kommt, wissen Sie, dass diese von ganz oben kommen und sagen: „Aber Sie wissen, Liebes, Sie haben hier Bier, das nicht von den richtigen Marken in den Fenstern ist und im Allgemeinen nicht in der Reihenfolge, die Sie benötigen. Schicken Sie uns ein paar Kamaz-Goldstücke und wir werden Ihnen sagen, welche Marken Sie benötigen und wie Sie sie ausklappen können. Nach unseren Schätzungen werden Sie im ersten Jahr nach dem Pilotversuch eine Milliarde kanadische Dollar erhalten. " Das Büro wird respektiert, so dass es keinen Zweifel über eine Milliarde geben kann. Auch die Methoden des Amtes können nicht in Frage gestellt werden, da sie nicht lügen können. Nur nicht wir. Im Allgemeinen hat der Autor dieser Zeilen die Aufgabe "Nun, schauen Sie dort, wie sie den Piloten machen, helfen Sie, wenn sie etwas brauchen".
Nach einem kurzen Vortrag über die Funktionsweise ihrer Methode zur Erzeugung der Warenanzeige in einem Anzeigefenster verschwand der Wunsch, auf die Details des Algorithmus einzugehen. Ich habe mich entschlossen, mich auf die Messung der Qualität zu konzentrieren, was aus theoretischer Sicht viel interessanter ist. Es erlaubt dem Unternehmen auch, nicht in absichtlich unrentable Projekte zu investieren. Mit Zugang zu parallelen Universen wäre es möglich, einen A / B-Test durchzuführen, bei dem in Universum A alles wie zuvor läuft und in Universum B sich das Layout der Waren geändert hat. A / B-Tests sind eine Art kontrolliertes Experiment, bei dem Benutzer zufällig in Kontroll- und Testgruppen unterteilt werden. In der Testgruppe wird ein Eingriff vorgenommen, eine bestimmte Zeit gewartet, die Auswirkung eines solchen Eingriffs auf die Zielindikatoren gemessen und schließlich die Indikatoren der beiden Gruppen verglichen. Es wäre wünschenswert, die Vorspannung zwischen der Kontroll- und der Testgruppe relativ zueinander zu minimieren. Zum Beispiel, damit es in Gruppe A keine Städte gibt und in Gruppe B nur Dörfer. Bei Websites scheint das Problem des Versatzes leicht zu lösen zu sein: Zeigen Sie Benutzern mit einer geraden ID eine Version und mit einer ungeraden ID eine andere Version der Website. In einer Situation mit einer Kette von Geschäften ist nicht alles so einfach, egal wie Sie Benutzer oder Geschäfte aufteilen, es stellt sich immer heraus, dass die Gruppen A und B nicht gleich sind. Diese Gruppe A kommt tagsüber und abends in den Laden. Wenn Sie die Zeit ausrichten, stellt sich heraus, dass A an Wochenenden häufiger auftritt als B. Wenn Sie alle diese Details ausrichten, müssen Sie ein halbes Jahr warten und alle Marketingunternehmen stornieren, um statistisch signifikante Ergebnisse zu erzielen. Wenn Sie die Städte treffen, stellt sich heraus, dass Moskau in einer Gruppe präsent ist und in einer anderen abwesend ist. Im Allgemeinen gibt es immer eine Verschiebung in einer Gruppe relativ zu einer anderen. Überlagert sind verschiedene globale und lokale Marketingkampagnen, Feiertage und unvorhergesehene Umstände in Form von Parkreparaturen.
Sie erinnern sich, dass das Büro von der Spitze der Weltbüros stammt und natürlich eine Lösung für das Testproblem bietet. Betrachten Sie ihre Methodik mit einem lauten Marketingnamen - die Triple-Difference-Methodik.
Triple Difference Methodology
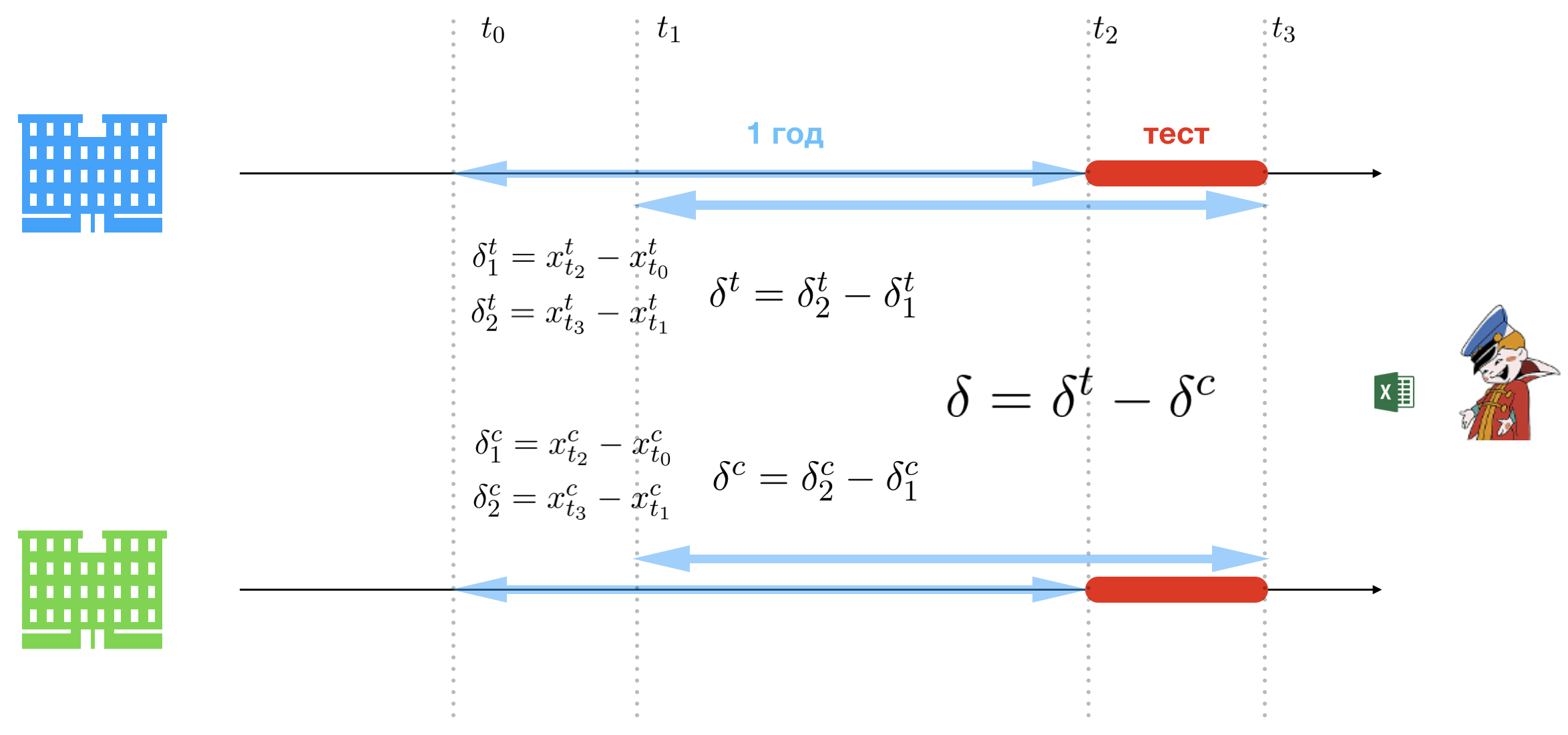
Das Wesentliche der Triple-Difference-Methode ist die Einfachheit. Und damit die Spitzen des Unternehmens beim Anhören der Präsentation nicht belastet werden, wird diese Präsentation von einer Dame durchgeführt, die nicht schlecht aussieht. Einfachheit wird erreicht, indem die Einschränkungen des A / B-Tests gelockert werden. Die einzige Schwierigkeit, die auf dem Weg des Amtes verbleibt, ist die Wahl einer Kontroll- und Testgruppe, aber wir werden diesen Teil des Prozesses weglassen, da es nichts Interessantes gibt, außer einer großen Anzahl zweifelhafter Annahmen. Als Ergebnis einer gründlichen Analyse der vorhandenen Filialkette wählt das Büro zwei aus: eine für die Kontrollgruppe (grün) und eine für die Testgruppe (blau).
Wir führen die folgende Notation ein:
- : Startdatum des Piloten;
- : Pilotenddatum;
- : Datum, das dem Datum entspricht, an dem der Pilot im letzten Jahr begonnen hat;
- : Datum, das dem letzten Jahr des Piloten entspricht.
Wir haben also zwei Zeiträume:
- : Zeit des Piloten (Zeit des Experiments);
- : Zeitraum, der dem Zeitraum des Piloten im letzten Jahr entspricht.
Es wird vorgeschlagen, das Einkommen des Testgeschäfts und den Kontrollzeitraum für die Zeiträume des Piloten und vor einem Jahr zu vergleichen. Dazu müssen Sie drei Gruppen von Unterschieden zählen. Bezeichnen Sie Verkäufe pro Tag im Testgeschäft für und - in der Kontrolle. Die erste Gruppe legt die Basis fest, anhand derer das Umsatzwachstum oder der Umsatzrückgang in der Pilotphase gemessen wird:
- : die Umsatzdifferenz zwischen dem Start des Piloten und dem gleichen Datum vor einem Jahr im Testgeschäft;
- : Umsatzunterschied zwischen dem Ende des Pilotprojekts und dem gleichen Datum vor einem Jahr im Testgeschäft;
- : die Umsatzdifferenz zwischen dem Start des Pilotprojekts und dem gleichen Datum vor einem Jahr im Kontrollgeschäft;
- : die Umsatzdifferenz zwischen dem Ende des Pilotprojekts und dem gleichen Datum vor einem Jahr im Kontrollgeschäft.
Die zweite Gruppe von Unterschieden bestimmt das Wachstum oder den Rückgang des Umsatzes in der Pilotphase:
- : Umsatzunterschied zwischen dem Ende des Piloten und dem Beginn des Piloten im Testgeschäft (angepasst an die Daten vor einem Jahr);
- : Umsatzunterschied zwischen dem Ende des Piloten und dem Beginn des Piloten im Kontrollgeschäft (angepasst an die Daten vor einem Jahr).
Und schließlich bestimmt der entscheidende Unterschied, welches Geschäft in der Pilotphase besser funktioniert hat:
Nun, die Entscheidung, ein Projekt mit den Kosten von KAMAZ Gold umzusetzen, ist sehr einfach, wenn - Dies bedeutet, dass der Testladen mehr Bier verkauft hat. Daher funktioniert die Methodik des Amtes und wirkt sich positiv aus. Daher muss sie eingeführt werden. Das ist alles.
A / B-Test mit ML-Basislinie
Nachdem ich die Methodik des dreifachen Unterschieds untersucht und festgestellt hatte, dass die Behörden diese Messmethode bereits genehmigt hatten und der Pilot mit der Planung begann, traf mich meine Hand schmerzhaft ins Gesicht. Es stellt sich heraus, dass das Büro uns anbietet, KAMAZ-Gold in das Projekt zu investieren, auch wenn die Methodik nicht funktioniert und der Umsatzunterschied zufällig 1 Rubel betrug. Es war dringend erforderlich, etwas zu entwickeln, das zumindest ein gewisses Vertrauen in die Wirksamkeit der neuen Art der Bierregulierung schafft. Wie Sie sich erinnern, ist eine der Möglichkeiten, einen ehrlichen A / B-Test offline durchzuführen, die Existenz paralleler Universen. In einer können wir die Bierberechnungsmethode einführen, in der zweiten lassen wir alles so wie es ist, warten eine Weile und vergleichen die Ergebnisse. Was aber, wenn wir parallele Universen mit maschinellem Lernen simulieren?

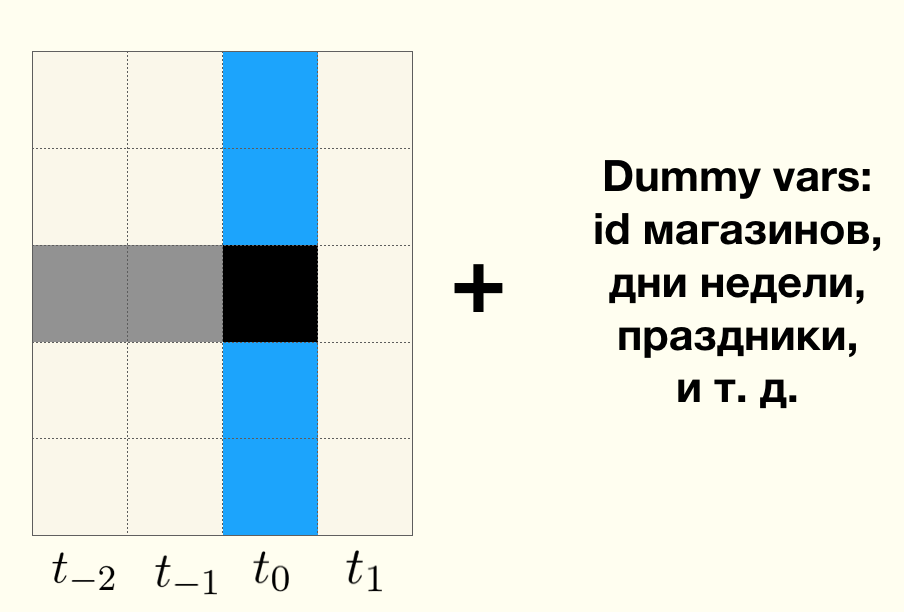
Angenommen, wir haben eine Zeitreihe der täglichen Verkäufe für jedes Geschäft. Die graue durchgezogene Linie teilt die Zeiträume
vor und
nach dem Piloten . Der Bereich zwischen der durchgezogenen grauen Linie und der gestrichelten grauen Linie ist der Zeitraum, in dem sich Käufer an den neuen Produktmix und neue Marken anpassen. Während dieses Zeitraums wirken sich Verkaufsdaten nicht auf das Testergebnis aus und werden einfach ignoriert. Festes Rot ist der tatsächliche Verkauf eines Geschäfts in der Zeit vor dem Piloten. Auf der rechten Seite befindet sich eine Kombination aus Testspeichern und Kontrolle. Die grüne gestrichelte Linie ist die Prognose für den Verkauf eines Geschäfts, wobei nur die Daten verwendet werden, die in der Zeit vor dem Start des Piloten verfügbar waren.
- Die rote Linie zeigt den tatsächlichen Umsatz des Kontrollgeschäfts in der Zeit nach dem Start des Piloten. Für Geschäfte aus der Kontrollgruppe beobachten wir in der Zeit nach dem Start des Pilotprojekts nur die Umsatzprognose (grün intermittierend) und die tatsächlichen Verkäufe (rot intermittierend).
- Durchgehend blau ist der tatsächliche Umsatz des Geschäfts mit der Testgruppe in der Zeit nach dem Start des Piloten. In Testgeschäften beobachten wir nur die Umsatzprognose (grün intermittierend) und den tatsächlichen Umsatz (durchgehend blau).
Die grüne gestrichelte Linie ist die Basislinie für maschinelles Lernen.
Wenn der Pilot erfolgreich war, d.h. Da sich die Testintervention in Form eines aktualisierten Sortiments und eines neuen Layouts positiv auf den täglichen Umsatz auswirkt, ist der reale Umsatz in Testgeschäften (durchgehend blau) im Durchschnitt höher als der tatsächliche Umsatz in Kontrollgeschäften (rot intermittierend).
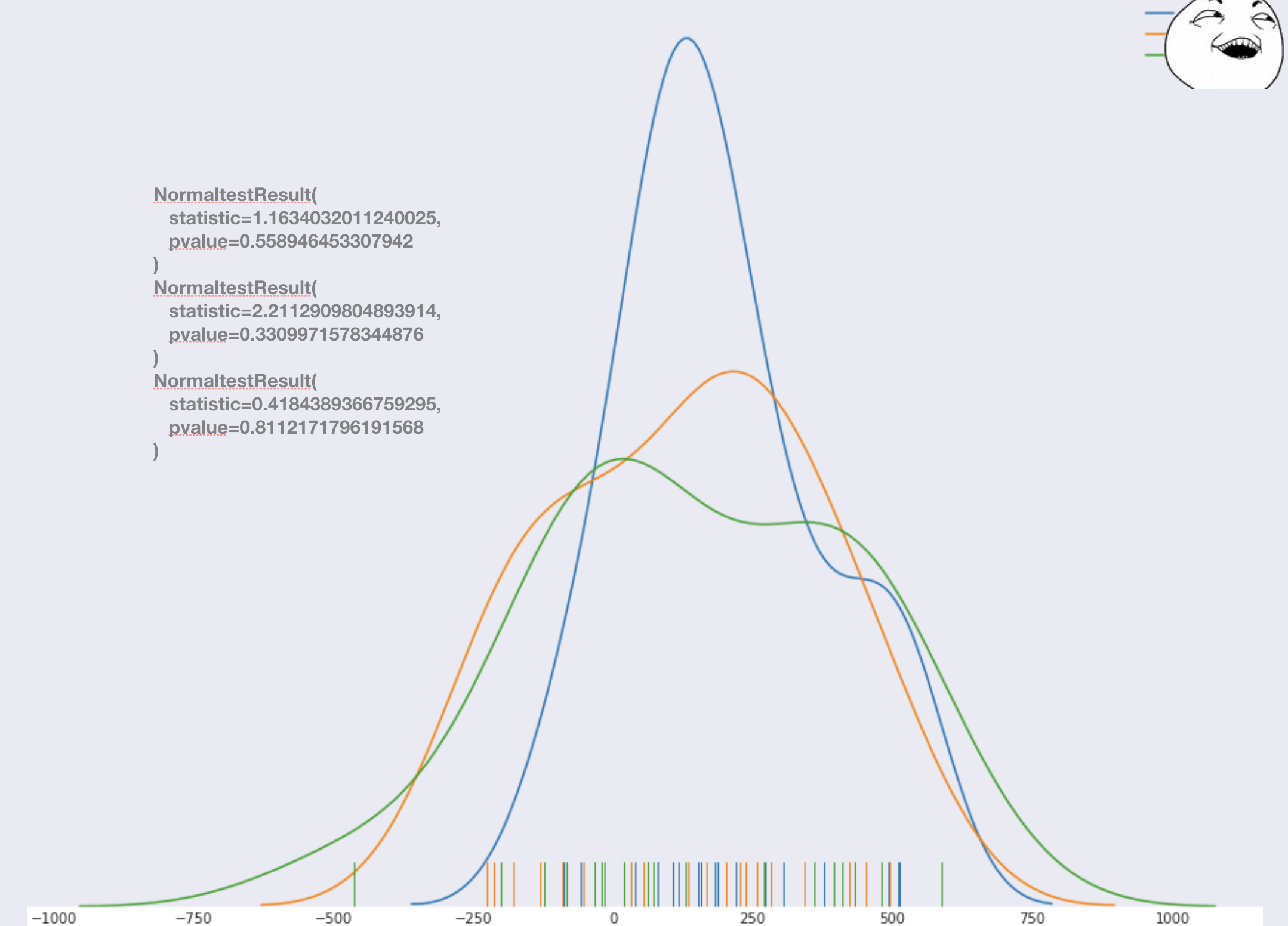
Mal sehen, was es im Durchschnitt bedeutet. Dazu müssen wir eine Annahme treffen, wir gehen davon aus, dass die Prognosefehler des Modells eine Normalverteilung haben:
 Fügen wir noch eine kühne Annahme hinzu: Nehmen wir an, dass die Verkäufe in der Kategorie, an der wir heute interessiert sind, linear von den Verkäufen in verwandten Kategorien heute und den Verkäufen in der Kategorie, an der wir gestern und in der jüngeren Vergangenheit interessiert sind, abhängen. Sie können dieser auch verschiedene Geschäftsmetadaten zuordnen, um Verzerrungen zu berücksichtigen in demografischen und anderen Attributen.
Fügen wir noch eine kühne Annahme hinzu: Nehmen wir an, dass die Verkäufe in der Kategorie, an der wir heute interessiert sind, linear von den Verkäufen in verwandten Kategorien heute und den Verkäufen in der Kategorie, an der wir gestern und in der jüngeren Vergangenheit interessiert sind, abhängen. Sie können dieser auch verschiedene Geschäftsmetadaten zuordnen, um Verzerrungen zu berücksichtigen in demografischen und anderen Attributen.
Es stellt sich als sehr bekanntes Modell heraus . Es ist anzumerken, dass die Wahl des Modells hier nicht besonders wichtig ist. Es ist wichtig, dass die Fehler eine Normalverteilung oder eine andere bekannte haben, um einen statistischen Test für die Gleichheit der Durchschnittswerte durchzuführen. Mit solchen Aussagen des Problems kann man im Stadium der Modellbildung immer einen Normalitätstest durchführen, und bei fast allen Modellen ist die Verteilung normal, gemäß der Version des Normtests wird sie überprüft.
Als Vorhersagemodell habe ich die lineare Regression verwendet, obwohl dies keine obligatorische Anforderung ist, und ich habe mich von der Einfachheit des Modells und der Interpretierbarkeit leiten lassen. Es ist erwähnenswert, dass das Modell prädiktiv ist, aber ich würde es als erklärend bezeichnen. Da wir die Zukunft nicht vorhersagen, sondern Verkäufe aus verwandten Kategorien am selben Tag verwenden, handelt es sich im Wesentlichen um eine Datenik. Vielmehr versuchen wir heute, den Bierverkauf durch den Verkauf im gesamten Geschäft zu erklären. Dies schafft ein neues Problem für uns - es ist notwendig, die im Modell verwendeten Funktionen sorgfältig auszuwählen. Funktionen, die sich auf die Kategorien verwandter Produkte beziehen, können in drei Gruppen unterteilt werden:
- Eine Gruppe von Waren, die für uns von Interesse sind (helles Bier, dunkles Bier, Nullbier, Kwas, vielleicht sogar ein Gelbwal). Einige dieser Zeichen bilden die Zielvariable, andere sind vollständig vom Modell ausgeschlossen.
- Warengruppen, die höchstwahrscheinlich etwas mit der Zielgruppe korrelieren, zum Beispiel die Akkordeongeschichte, dass der Verkauf von Windeln und Bier einen hohen positiven Korrelationskoeffizienten aufweist;
- Produktgruppen, die sicherlich keine signifikante Korrelation mit den Zielgruppen aufweisen. Dies ist eine solche Regularisierungsmethode, noch bevor das Modell erstellt wird, und es wird eine große Versuchung bestehen, für alle Fälle alles zur zweiten Gruppe hinzuzufügen.
Als erklärende Variablen fügen wir dem Modell Merkmale aus der zweiten Gruppe hinzu. Die Idee ist, dass wir davon ausgehen, dass Änderungen des Umsatzes in der zweiten Gruppe insgesamt einen signifikanten Einfluss auf die erste haben und Änderungen des Umsatzes in der ersten Gruppe keinen großen Einfluss auf die zweite Gruppe insgesamt haben (die zweite ist viel größer und vielfältiger).
Eine beliebte Frage bei der Vorstellung der Methode war: Was passiert, wenn im Test- / Kontrollgeschäft eine Parkreparatur durchgeführt wird, wird der Test abgebrochen? Die Antwort ist nein. Das Parken wirkt sich auf den Verkauf des gesamten Geschäfts aus, nicht speziell auf das Bier, und der Bierverkauf in unserem Land hängt vom Verkauf in anderen Kategorien ab und wird dementsprechend zusammen mit allen ausgegeben. Sie können ein paar Simulationen auf einem Retrodat überzeugend durchführen.
Es ist auch erwähnenswert, dass wir die Berechnung nach Methode A nicht gegen die Berechnung nach Methode B testen, sondern das neue Verhalten gegen das alte . Dies bedeutet, dass Geschäfte und die gesamte Gruppe keine geplanten Marketingkampagnen stornieren sollten, die zuvor verwendet wurden. Wenn Sie beispielsweise den Preis für starkes Bier in den letzten 6 Monaten in geraden Wochen um das Zweifache gesenkt haben, tun Sie dies weiterhin. Wenn Sie damit aufhören, ist das Verhalten anders. Führen Sie keine neuen Experimente in ausgewählten Geschäften durch.
Die Phase des Modellbaus kann auch nicht ohne Fallstricke auskommen. Die Test- und Kontrollgruppen können völlig unterschiedliche Geschäfte umfassen. Die Aufgabe unseres Modells besteht darin, alle Geschäfte so auszurichten, dass für jedes Geschäft ein zufälliger Prognosefehler auf Null zentriert (oder gleichermaßen von Null versetzt) wird. Zuerst erwartete ich, dass ich bei der Validierung alle Arten von Hyperparametern aussortieren müsste, bis das gewünschte Ergebnis erzielt wurde. Es stellte sich jedoch heraus, dass dies mit einem ausreichenden Satz von Merkmalen zum ersten Mal erreicht wird, was interessant ist, und dass sich die Varianz des Zufallsfehlers auch von Geschäft zu Geschäft nicht wesentlich unterschied. Dies ist wahrscheinlich eine der Schwächen der Methode, da nicht garantiert werden kann, dass solche Bedingungen erfüllt werden.  Eine Überprüfung der Literatur ergab ebenfalls keine Ergebnisse. Es scheint, dass viele Menschen eine Basis für maschinelles Lernen verwenden, aber theoretische Garantien sind nirgends zu finden. Im Allgemeinen erhalten wir nach all diesen Betrügereien ein Modell, das auf alle Daten in seiner Gesamtheit geschult ist, und wir können tägliche Umsatzprognosen für jedes ausgewählte Geschäft erstellen. Und wir sind nicht besonders besorgt über die Genauigkeit, sondern nur, wenn die Fehlerverteilung für alle Geschäfte gleichermaßen voreingenommen war (natürlich angenehmer, wenn nicht voreingenommen gegenüber Null). Und die Tatsache, dass die Varianz groß sein kann, wirkt sich nur auf die Größe des Datensatzes aus, der für die statistische Signifikanz des Testergebnisses erforderlich ist (was bedeutet, dass bei gegebener a priori statistischer Signifikanz und statistischer Aussagekraft des Tests die Anzahl der Beobachtungen, die erforderlich sind, um solche Ergebnisse zu erhalten, von der Varianz abhängt )
Eine Überprüfung der Literatur ergab ebenfalls keine Ergebnisse. Es scheint, dass viele Menschen eine Basis für maschinelles Lernen verwenden, aber theoretische Garantien sind nirgends zu finden. Im Allgemeinen erhalten wir nach all diesen Betrügereien ein Modell, das auf alle Daten in seiner Gesamtheit geschult ist, und wir können tägliche Umsatzprognosen für jedes ausgewählte Geschäft erstellen. Und wir sind nicht besonders besorgt über die Genauigkeit, sondern nur, wenn die Fehlerverteilung für alle Geschäfte gleichermaßen voreingenommen war (natürlich angenehmer, wenn nicht voreingenommen gegenüber Null). Und die Tatsache, dass die Varianz groß sein kann, wirkt sich nur auf die Größe des Datensatzes aus, der für die statistische Signifikanz des Testergebnisses erforderlich ist (was bedeutet, dass bei gegebener a priori statistischer Signifikanz und statistischer Aussagekraft des Tests die Anzahl der Beobachtungen, die erforderlich sind, um solche Ergebnisse zu erhalten, von der Varianz abhängt )
Kehren wir mit roten, grünen und blauen Linien zum obigen Diagramm zurück und führen schließlich das Konzept eines durchschnittlichen höheren oder niedrigeren Durchschnitts ein . Für Kontrollgeschäfte können wir vom tatsächlichen Tagesumsatz (rote gestrichelte Linie) den vom Modell vorhergesagten Tagesumsatz (grüne gestrichelte Linie) abziehen. Als Ergebnis erhalten wir eine Normalverteilung von Fehlern, die bei Null zentriert sind, sodass sich an ihnen nichts geändert hat und das Modell im Durchschnitt mit der Realität übereinstimmt. Für Geschäfte aus der Testgruppe subtrahieren wir auch die tatsächlichen täglichen Verkäufe (blaue durchgezogene Linie), die täglichen Verkäufe von Verkaufsmodellen (grün intermittierend) und erhalten auch eine Normalverteilung. Wenn sich dann nichts geändert hat, liegt das Zentrum irgendwo um Null; Wenn sich der Umsatz verbessert hat, wird er nach rechts verschoben, wenn er sich verschlechtert hat, nach links. So sieht es bei simulierten Daten aus.

Und hier befinden wir uns unter den Bedingungen des üblichen statistischen Tests für die Gleichheit des Mittelwerts zweier Verteilungen, und nichts hindert uns daran, diesen Test durchzuführen. Für den Stat-Test müssen wir Folgendes wissen:
- und : Wählen Sie sich selbst, oder wenn Sie Glück haben und gebildete Leute im Marketing sitzen, dann wählen wir zusammen mit ihnen;
- Dispersion: entnommen aus einem Retrodat;
- Aufzug: Wird benötigt, um nicht nur die Gleichstellung zu testen, sondern auch, dass das Umsatzwachstum in der Testgruppe nicht weniger als einen bestimmten Betrag an bedingten kanadischen Dollar beträgt. Wir wollen kein Projekt im Wert von Kamaz Gold umsetzen, aber damit es kostengünstig ist und sich in hundert Jahren nicht amortisiert, bauen wir keine Brücke zur Krim.
Diese Daten reichen aus, um die für den Piloten erforderliche Anzahl von Tagen zu berechnen. Ein weiterer Vorteil dieses Ansatzes ist die Skalierbarkeit. In unserem Fall ergab der Test 60 Tage, d.h. Wir benötigen 60-Tage-Beobachtungen für den Test und 60-Tage-Beobachtungen für die Kontrollgruppe, um statistisch signifikante Testergebnisse zu erhalten. Wir können ein Geschäft in jeder Gruppe auswählen und 2 Monate oder zwei in jeder Gruppe warten und 1 Monat warten und so weiter. Natürlich hängt das Budget des Experiments von der Hinzufügung neuer Geschäfte zur Testgruppe ab, aber dies ist Ihre Aufgabe, wie Sie ein solches Gleichgewicht auswählen können. Ich empfehle Ihnen, dieses Material zu studieren, um die Methode zur Berechnung der erforderlichen Anzahl von Beobachtungen zu verstehen.
Echte Daten
Betrachten Sie zwei Bilder mit echten Verkäufen, das Modell ist auf mehrere Jahre Retro-Verkauf geschult. Shop Nummer eins:
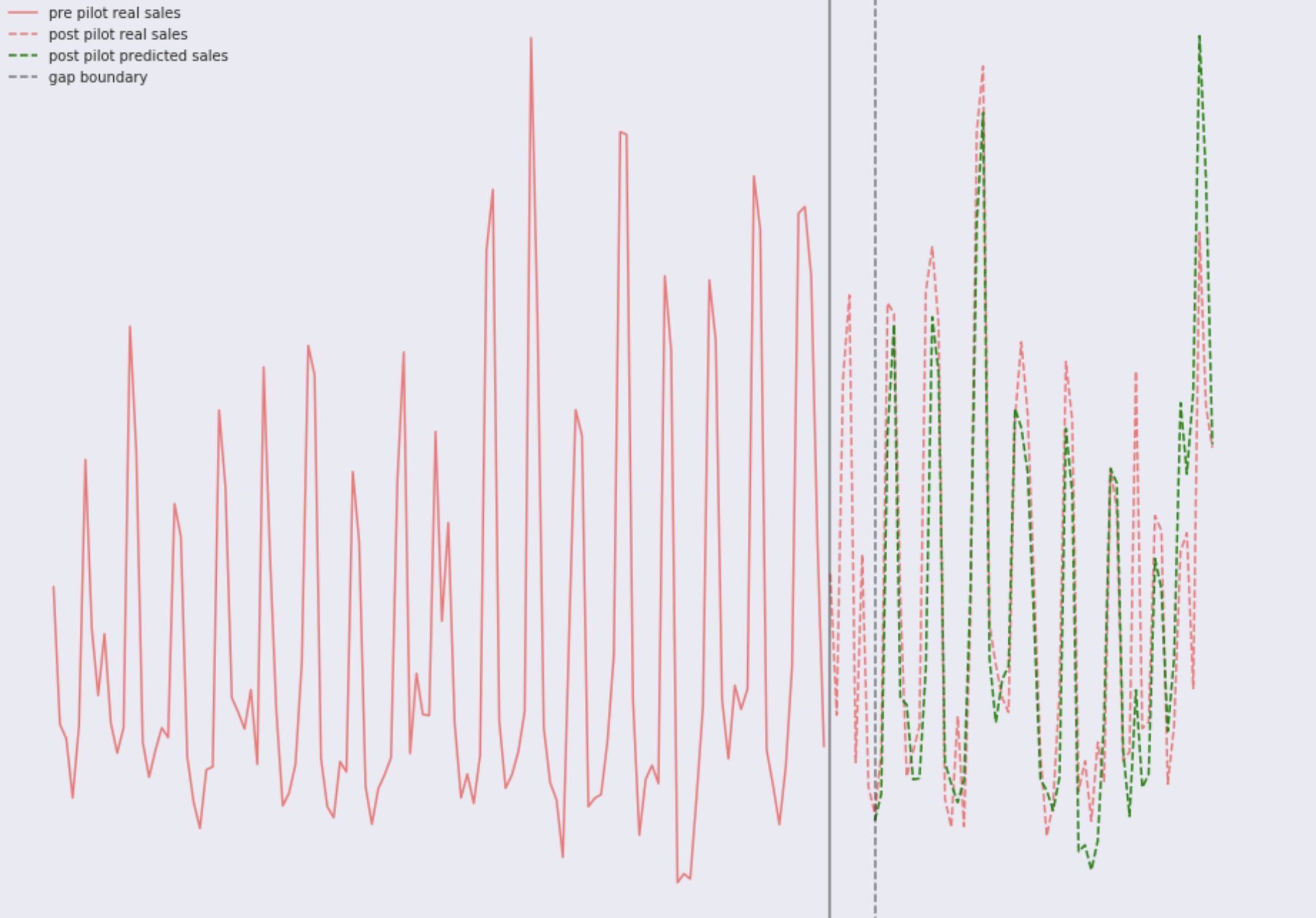
Und speichern Sie Nummer zwei:

Wie Sie sehen können
, ist alles sehr gut
für das Auge . Sie werden leicht wöchentliche Muster bemerken, und in letzter Zeit ist in einem der Geschäfte eindeutig etwas passiert. Die Dynamik hat sich geändert. Wenn Sie genau hinschauen, können Sie feststellen, dass das Modell in beiden Geschäften mehrmals einen erheblichen Fehler macht. In diesem Fall gibt es zwei Möglichkeiten:
:
. ,
. , , . , , ( , , ). .
, , , . .

, , . , . , , , … .
Fazit
— ? , , 1-2 . - , — . , , , , . :
, - , . , , , , . , , , , .
? , , . -, . , .
, , , , . , .