In dem Artikel werden wir über die Verwendung von Faltungs-Neuronalen Netzen sprechen, um eine praktische Geschäftsaufgabe zu lösen, bei der ein Realogramm aus Fotografien von Regalen mit Waren wiederhergestellt wird. Mit der Tensorflow-Objekterkennungs-API trainieren wir das Such- / Lokalisierungsmodell. Wir werden die Qualität der Suche nach kleinen Produkten in hochauflösenden Fotos mithilfe eines schwebenden Fensters und eines nicht maximalen Unterdrückungsalgorithmus verbessern. Bei Keras implementieren wir einen Klassifizierer von Waren nach Marke. Parallel dazu werden wir Ansätze und Ergebnisse mit Entscheidungen von vor 4 Jahren vergleichen. Alle im Artikel verwendeten Daten stehen zum Download zur Verfügung. Der voll funktionsfähige Code befindet sich auf
GitHub und ist als Lernprogramm konzipiert.

Einführung
Was ist ein Planogramm? Das Layoutdiagramm der Warenanzeige auf den konkreten Handelsgeräten des Geschäfts.
Was ist ein Realogramm? Das Layout der Waren auf einem bestimmten Handelsgerät, das hier und jetzt im Geschäft vorhanden ist.
Planogramm - wie es sollte, Realogramm - was wir haben.

Bis jetzt ist in vielen Geschäften die Verwaltung der restlichen Waren in Regalen, Regalen, Theken und Regalen ausschließlich Handarbeit. Tausende Mitarbeiter prüfen die Verfügbarkeit von Produkten manuell, berechnen den Saldo, prüfen den Standort anhand der Anforderungen. Es ist teuer und Fehler sind sehr wahrscheinlich. Eine falsche Anzeige oder ein Mangel an Waren führt zu geringeren Umsätzen.
Außerdem schließen viele Hersteller Vereinbarungen mit Einzelhändlern, um ihre Waren auszustellen. Und da es viele Hersteller gibt, beginnt zwischen ihnen der Kampf um den besten Platz im Regal. Jeder möchte, dass sein Produkt in der Mitte gegenüber den Augen des Käufers liegt und die größtmögliche Fläche einnimmt. Es besteht Bedarf an einer kontinuierlichen Prüfung.
Tausende von Merchandisern ziehen von Geschäft zu Geschäft, um sicherzustellen, dass die Produkte ihres Unternehmens im Regal stehen und vertragsgemäß präsentiert werden. Manchmal sind sie faul: Es ist viel angenehmer, einen Bericht zu erstellen, ohne das Haus zu verlassen, als zu einer Verkaufsstelle zu gehen. Es ist eine ständige Prüfung der Abschlussprüfer erforderlich.
Die Aufgabe der Automatisierung und Vereinfachung dieses Prozesses ist natürlich schon lange gelöst. Einer der schwierigsten Teile war die Bildverarbeitung: das Finden und Erkennen von Produkten. Und erst vor relativ kurzer Zeit wurde diese Aufgabe so stark vereinfacht, dass für einen bestimmten Fall in vereinfachter Form die vollständige Lösung in einem Artikel beschrieben werden kann. Das werden wir tun.
Der Artikel enthält ein Minimum an Code (nur für Fälle, in denen der Code klarer als der Text ist). Die Komplettlösung ist als illustriertes Tutorial in
Jupyter-Notizbüchern verfügbar . Der Artikel enthält keine Beschreibung der Architektur neuronaler Netze, der Prinzipien von Neuronen und mathematischer Formeln. In diesem Artikel verwenden wir sie als Engineering-Tool, ohne zu sehr auf die Details des Geräts einzugehen.
Daten und Ansatz
Wie bei jedem datengesteuerten Ansatz erfordern neuronale Netzwerklösungen Daten. Sie können sie auch manuell zusammenstellen: um mehrere hundert Zähler zu erfassen und sie beispielsweise mit
LabelImg zu markieren . Sie können Markups beispielsweise bei Yandex.Tolok bestellen.
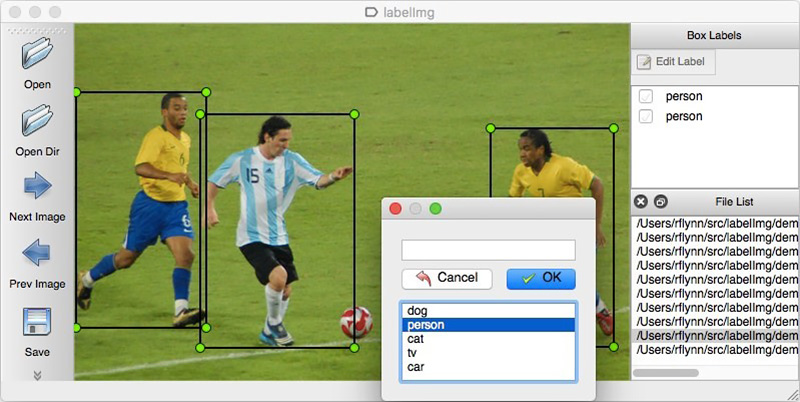
Wir können die Details eines realen Projekts nicht offenlegen, daher werden wir die Technologie anhand offener Daten erläutern. Es war zu faul, einkaufen zu gehen und Fotos zu machen (und wir würden uns dort nicht verstehen), und der Wunsch, die im Internet gefundenen Fotos selbst zu markieren, endete nach dem hundertsten klassifizierten Objekt. Zum Glück bin ich ganz zufällig auf das
Grocery Dataset- Archiv
gestoßen .
Im Jahr 2014 haben Mitarbeiter von Idea Teknoloji, Istanbul, Türkei, 354 Fotos aus 40 Geschäften hochgeladen, die mit 4 Kameras erstellt wurden. Auf jeder dieser Fotografien wurden insgesamt mehrere tausend Objekte mit Rechtecken hervorgehoben, von denen einige in 10 Kategorien eingeteilt wurden.
Dies sind Bilder von Zigarettenschachteln. Wir fördern oder fördern das Rauchen nicht. Es gab einfach nichts Neutraleres. Wir versprechen, dass wir überall im Artikel, wo es die Situation erlaubt, Fotos von Katzen verwenden werden.

Zusätzlich zu den mit Tags versehenen Fotos der Regale verfassten sie einen Artikel zur
Erkennung von Einzelhandelsprodukten in Lebensmittelregalen mit einer Lösung für das Problem der Lokalisierung und Klassifizierung. Dies stellte eine Art Bezugspunkt dar: Unsere Lösung mit neuen Ansätzen sollte sich als einfacher und genauer herausstellen, da sie sonst nicht interessant ist. Ihr Ansatz besteht aus einer Kombination von Algorithmen:
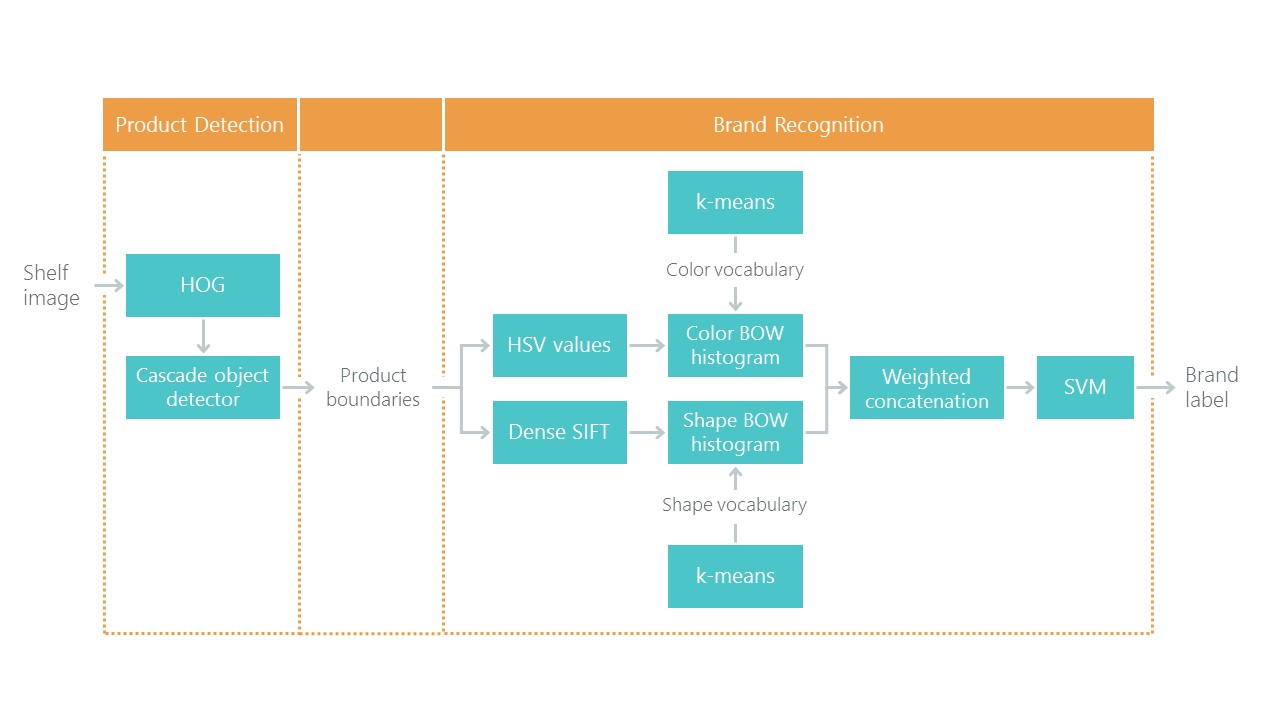
In jüngster Zeit haben Faltungs-Neuronale Netze (CNNs) das Gebiet der Bildverarbeitung revolutioniert und den Ansatz zur Lösung solcher Probleme grundlegend geändert. In den letzten Jahren sind diese Technologien für eine Vielzahl von Entwicklern verfügbar geworden, und APIs auf hoher Ebene wie Keras haben ihre Eintrittsschwelle erheblich gesenkt. Jetzt kann fast jeder Entwickler nach nur wenigen Tagen Datierung die volle Leistung von Faltungs-Neuronalen Netzen nutzen. Der Artikel beschreibt die Verwendung dieser Technologien anhand eines Beispiels und zeigt, wie eine ganze Kaskade von Algorithmen ohne Genauigkeitsverlust leicht durch nur zwei neuronale Netze ersetzt werden kann.
Wir werden das Problem in Schritten lösen:
- Datenaufbereitung. Wir pumpen die Archive aus und verwandeln sie in eine bequeme Ansicht für die Arbeit.
- Markenklassifizierung. Wir lösen das Klassifizierungsproblem mithilfe eines neuronalen Netzwerks.
- Suchen Sie nach Produkten auf dem Foto. Wir trainieren das neuronale Netz, um nach Waren zu suchen.
- Suche Implementierung. Wir werden die Erkennungsqualität mithilfe eines schwebenden Fensters und eines Algorithmus zur Unterdrückung von Nichtmaxima verbessern.
- Fazit Erklären Sie kurz, warum das wirkliche Leben viel komplizierter ist als dieses Beispiel.
Technologie
Die wichtigsten Technologien, die wir verwenden werden: Tensorflow, Keras, Tensorflow-Objekterkennungs-API, OpenCV. Obwohl sowohl Windows als auch Mac OS für die Arbeit mit Tensorflow geeignet sind, empfehlen wir weiterhin die Verwendung von Ubuntu. Selbst wenn Sie noch nie mit diesem Betriebssystem gearbeitet haben, sparen Sie durch die Verwendung eine Menge Zeit. Die Installation von Tensorflow für die Arbeit mit der GPU ist ein Thema, das einen separaten Artikel verdient. Glücklicherweise existieren solche Artikel bereits. Beispiel:
Installieren von TensorFlow unter Ubuntu 16.04 mit einer Nvidia-GPU . Einige Anweisungen davon sind möglicherweise veraltet.
Schritt 1. Daten vorbereiten ( Github-Link )Dieser Schritt dauert in der Regel viel länger als die Simulation selbst. Glücklicherweise verwenden wir vorgefertigte Daten, die wir in das von uns benötigte Formular konvertieren.
Sie können auf folgende Weise herunterladen und entpacken:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
Wir erhalten folgende Ordnerstruktur:
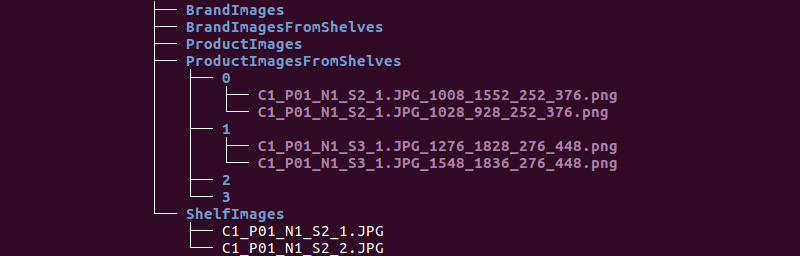
Wir verwenden Informationen aus den Verzeichnissen ShelfImages und ProductImagesFromShelves.
ShelfImages enthält Bilder der Regale selbst. Im Namen ist die Kennung des Racks mit der Kennung des Bildes codiert. Es können mehrere Bilder von einem Rack vorhanden sein. Zum Beispiel ein Foto in seiner Gesamtheit und 5 Fotos in Teilen mit Schnittpunkten.
Datei C1_P01_N1_S2_2.JPG (Rack C1_P01, Schnappschuss N1_S2_2):

Wir gehen alle Dateien durch und sammeln Informationen im Pandas-Datenrahmen photos_df:
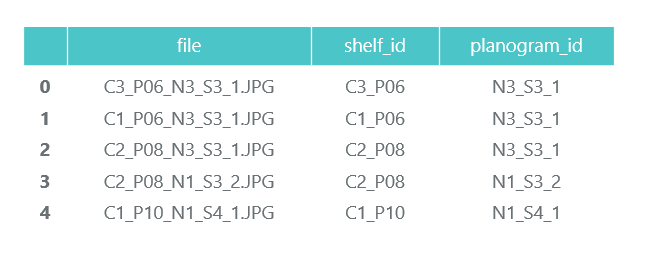
ProductImagesFromShelves enthält ausgeschnittene Fotos von Waren aus Regalen in 11 Unterverzeichnissen: 0 - nicht klassifiziert, 1 - Marlboro, 2 - Kent usw. Um sie nicht zu bewerben, verwenden wir nur Kategorienummern ohne Angabe von Namen. Dateien in den Namen enthalten Informationen über das Rack, die Position und Größe der Packung.
Datei C1_P01_N1_S3_1.JPG_1276_1828_276_448.png aus Verzeichnis 1 (Kategorie 1, Rack C1_P01, Bild N1_S3_1, Koordinaten der oberen linken Ecke (1276, 1828), Breite 276, Höhe 448):
Wir brauchen die Fotos der einzelnen Packungen selbst nicht (wir werden sie aus den Bildern der Regale ausschneiden) und sammeln Informationen über ihre Kategorie und Position im Pandas-Datenrahmen products_df:
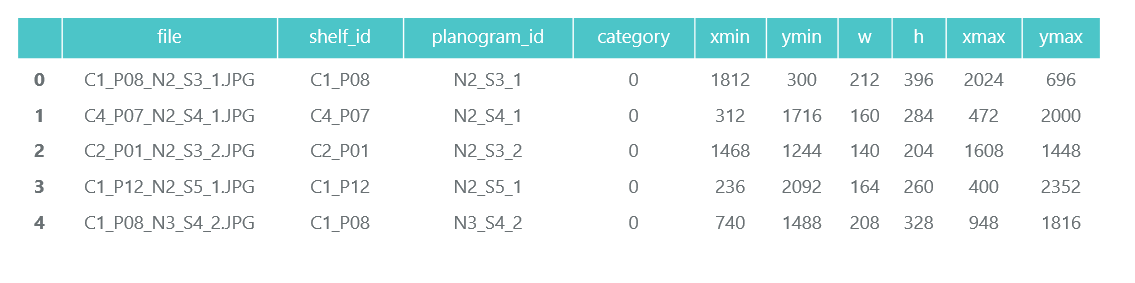
Im gleichen Schritt teilen wir alle unsere Informationen in zwei Abschnitte auf: Schulung für die Schulung und Validierung für die Überwachung der Schulung. In realen Projekten lohnt sich das natürlich nicht. Und vertraue auch nicht denen, die dies tun. Sie müssen mindestens einen weiteren Test für den endgültigen Test zuweisen. Aber auch bei diesem nicht sehr ehrlichen Ansatz ist es wichtig, dass wir uns nicht viel täuschen.
Wie bereits erwähnt, kann es mehrere Fotos von einem Rack geben. Dementsprechend kann dieselbe Packung in mehrere Bilder fallen. Wir empfehlen Ihnen daher, nicht nach Bildern, sondern vor allem nicht nach Packungen, sondern nach Gestellen aufzuschlüsseln. Dies ist notwendig, damit nicht dasselbe Objekt aus verschiedenen Blickwinkeln sowohl im Zug als auch in der Validierung landet.
Wir machen eine 70/30-Aufteilung (30% der Racks werden validiert, der Rest für das Training):
Wir werden sicherstellen, dass bei der Trennung genügend Vertreter jeder Klasse für Schulung und Validierung zur Verfügung stehen:

Die blaue Farbe zeigt die Anzahl der Produkte in der Kategorie für die Validierung und die orange für die Schulung. Mit der Kategorie 3 zur Validierung ist die Situation nicht sehr gut, aber im Prinzip gibt es nur wenige Vertreter.
In der Phase der Datenaufbereitung ist es wichtig, keinen Fehler zu machen, da alle weiteren Arbeiten auf den Ergebnissen basieren. Wir haben immer noch einen Fehler gemacht und viele glückliche Stunden damit verbracht zu verstehen, warum die Qualität der Modelle sehr mittelmäßig ist. Fühlte mich bereits als Verlierer der „Old School“ -Technologien, bis Sie versehentlich bemerkten, dass einige der Originalfotos um 90 Grad gedreht wurden und einige verkehrt herum gemacht wurden.
Gleichzeitig wird das Markup so erstellt, als ob die Fotos korrekt ausgerichtet wären. Nach einer schnellen Lösung ging es viel lustiger.
Wir speichern unsere Daten in pkl-Dateien, um sie in den folgenden Schritten zu verwenden. Insgesamt haben wir:
- Ein Verzeichnis von Fotos von Gestellen und ihren Teilen mit Bündeln,
- Ein Datenrahmen mit einer Beschreibung jedes Racks mit einem Hinweis, ob es für das Training vorgesehen ist.
- Ein Datenrahmen mit Informationen zu allen Produkten in den Regalen, in denen Position, Größe, Kategorie und Kennzeichnung angegeben sind, ob sie für Schulungen vorgesehen sind.
Zur Überprüfung zeigen wir ein Rack gemäß unseren Daten an:
 Schritt 2. Klassifizierung nach Marke ( Link auf Github )
Schritt 2. Klassifizierung nach Marke ( Link auf Github )Die Klassifizierung von Bildern ist die Hauptaufgabe im Bereich der Bildverarbeitung. Das Problem ist die „semantische Lücke“: Fotografie ist nur eine große Zahlenmatrix [0, 255]. Zum Beispiel 800x600x3 (3 RGB-Kanäle).

Warum diese Aufgabe schwierig ist:

Wie bereits erwähnt, haben die Autoren der von uns verwendeten Daten 10 Marken identifiziert. Dies ist eine äußerst vereinfachte Aufgabe, da viel mehr Zigarettenmarken in den Regalen stehen. Aber alles, was nicht in diese 10 Kategorien fiel, wurde an 0 gesendet - nicht klassifiziert:

""
Ihr Artikel bietet einen solchen Klassifizierungsalgorithmus mit einer Gesamtgenauigkeit von 92%:

Was werden wir tun:
- Wir werden die Daten für das Training vorbereiten,
- Wir trainieren ein neuronales Faltungsnetzwerk mit der ResNet v1-Architektur.
- Überprüfen Sie die Fotos zur Validierung.
Es klingt "voluminös", aber wir haben gerade Keras 'Beispiel "
Trainiert ein ResNet auf dem CIFAR10-Dataset " verwendet, das die Funktion zum Erstellen von ResNet v1 übernimmt.
Um den Trainingsprozess zu starten, müssen Sie zwei Arrays vorbereiten: x - Fotos von Packungen mit einer Dimension (Anzahl der Packungen, Höhe, Breite, 3) und y - ihre Kategorien mit einer Dimension (Anzahl der Packungen, 10). Das Array y enthält die sogenannten 1-Hot-Vektoren. Wenn die Kategorie eines Trainingspakets die Nummer 2 hat (von 0 bis 9), entspricht dies dem Vektor [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Eine wichtige Frage ist, was mit der Breite und Höhe zu tun ist, da alle Fotos mit unterschiedlichen Auflösungen aus unterschiedlichen Entfernungen aufgenommen wurden. Wir müssen eine feste Größe wählen, zu der wir alle unsere Bilder der Packungen bringen können. Diese feste Größe ist ein Metaparameter, der bestimmt, wie unser neuronales Netzwerk trainiert und funktioniert.
Einerseits möchte ich diese Größe so groß wie möglich machen, damit kein Detail des Bildes unbemerkt bleibt. Auf der anderen Seite kann dies bei unserer geringen Menge an Trainingsdaten zu einer schnellen Umschulung führen: Das Modell funktioniert perfekt mit Trainingsdaten, aber schlecht mit Validierungsdaten. Wir haben die Größe 120x80 gewählt, vielleicht würden wir bei einer anderen Größe ein besseres Ergebnis erzielen. Zoomfunktion:
Skalieren Sie eine Packung und zeigen Sie sie zur Überprüfung an. Der Name der Marke ist für eine Person schwer zu lesen. Lassen Sie uns sehen, wie das neuronale Netzwerk mit der Aufgabe der Klassifizierung fertig wird:

Nachdem wir uns gemäß dem im vorherigen Schritt erhaltenen Flag vorbereitet haben, teilen wir die x- und y-Arrays in x_train / x_validation und y_train / y_validation auf. Wir erhalten:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
Wenn die Daten vorbereitet sind, kopieren wir die Funktion des neuronalen Netzwerkkonstruktors der ResNet v1-Architektur aus dem Keras-Beispiel:
def resnet_v1(input_shape, depth, num_classes=10): …
Wir konstruieren ein Modell:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
Wir haben einen ziemlich begrenzten Datensatz. Um zu verhindern, dass das Modell während des Trainings jedes Mal dasselbe Foto sieht, verwenden wir Augmentation: Verschieben Sie das Bild nach dem Zufallsprinzip und drehen Sie es ein wenig. Keras bietet hierfür folgende Optionen:
Wir beginnen den Trainingsprozess.
Nach dem Training und der Bewertung erhalten wir eine Genauigkeit im Bereich von 92%. Möglicherweise erhalten Sie eine andere Genauigkeit: Es gibt nur sehr wenige Daten, daher hängt die Genauigkeit stark vom Erfolg der Partition ab. Auf dieser Partition haben wir keine wesentlich höhere Genauigkeit als im Artikel angegeben, aber wir haben selbst praktisch nichts getan und wenig Code geschrieben. Darüber hinaus können wir leicht eine neue Kategorie hinzufügen, und die Genauigkeit sollte (theoretisch) erheblich zunehmen, wenn wir mehr Daten vorbereiten.
Vergleichen Sie bei Interesse die Verwirrungsmatrizen:
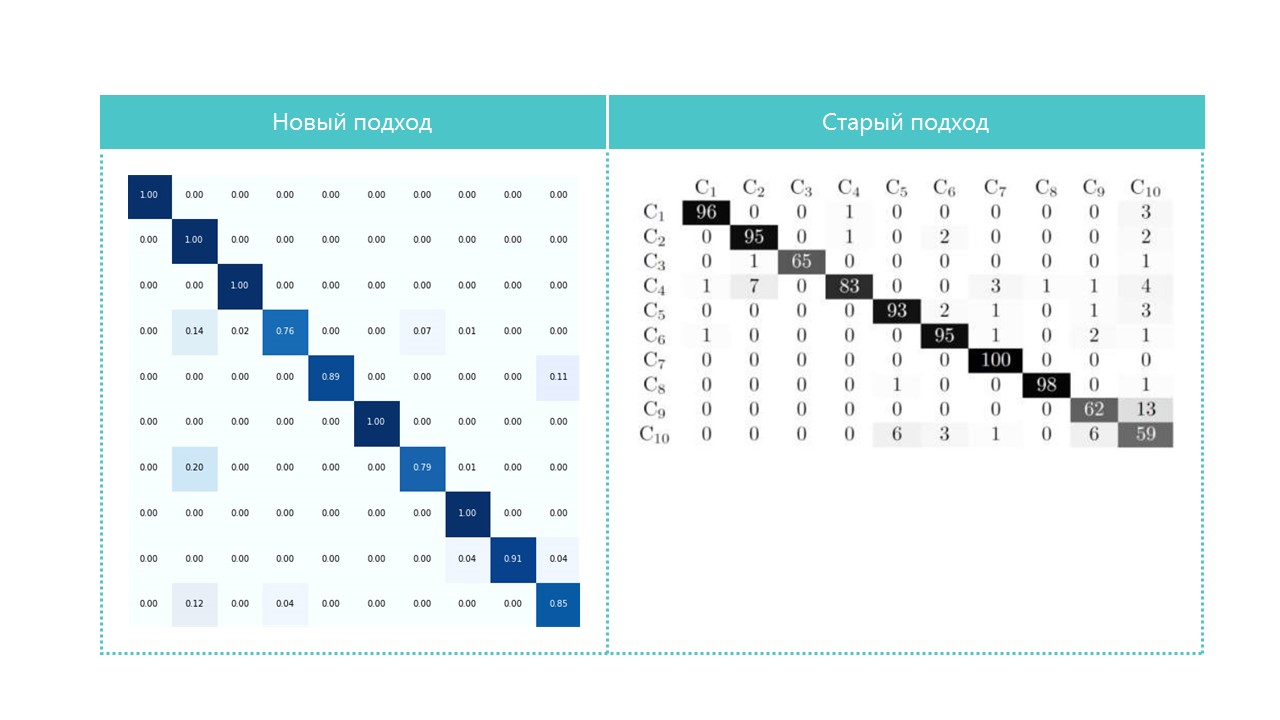
Fast alle Kategorien, die unser neuronales Netzwerk definiert, mit Ausnahme der Kategorien 4 und 7. Es ist auch nützlich, die hellsten Vertreter jeder Verwirrungsmatrixzelle zu betrachten:
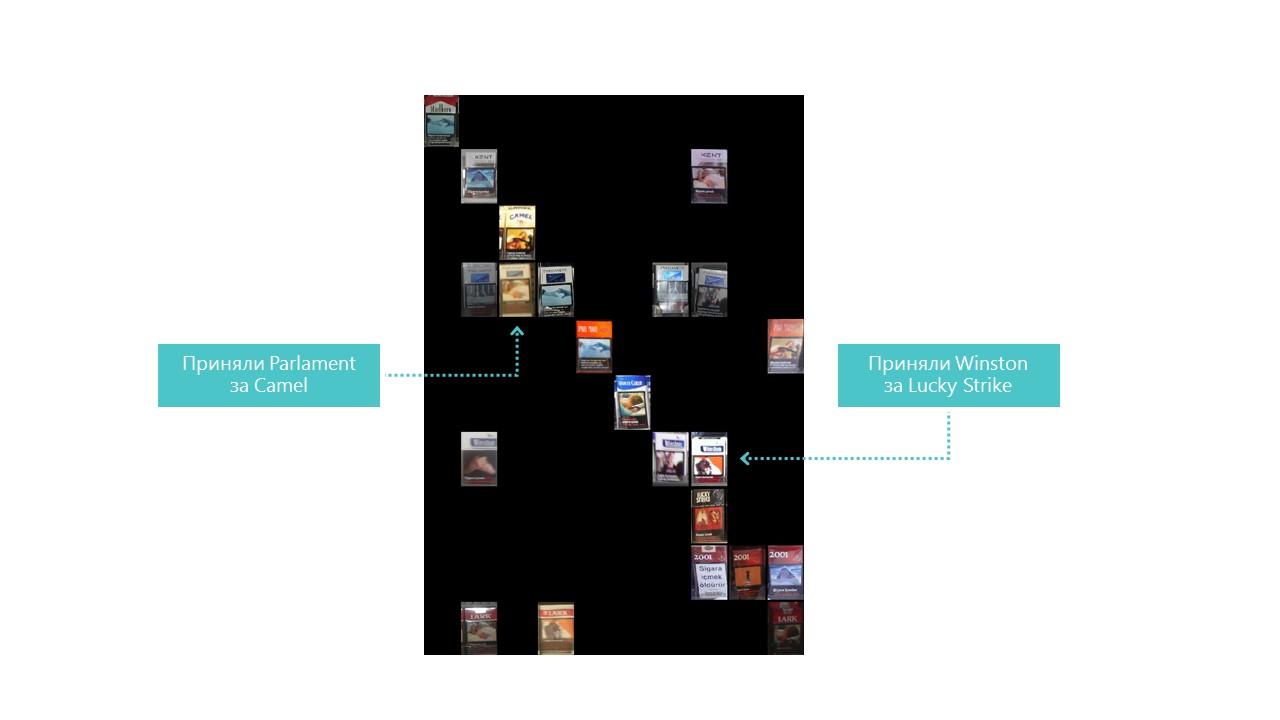
Sie können auch verstehen, warum das Parlament mit Camel verwechselt wurde, aber warum Winston mit Lucky Strike verwechselt wurde, ist völlig unverständlich, aber sie haben nichts gemeinsam. Dies ist das Hauptproblem neuronaler Netze - die vollständige Undurchsichtigkeit dessen, was im Inneren geschieht. Sie können natürlich einige Ebenen visualisieren, aber für uns sieht diese Visualisierung folgendermaßen aus:

Eine offensichtliche Möglichkeit, die Erkennungsqualität unter unseren Bedingungen zu verbessern, besteht darin, weitere Fotos hinzuzufügen.
Der Klassifikator ist also fertig. Gehe zum Detektor.
Schritt 3. Suchen Sie nach Produkten auf dem Foto ( Link auf Github )Die folgenden wichtigen Aufgaben im Bereich Computer Vision sind semantische Segmentierung, Lokalisierung, Objektsuche und Instanzsegmentierung.
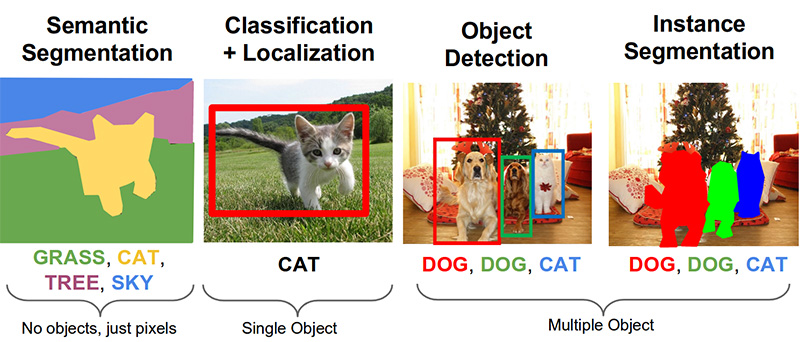
Unsere Aufgabe erfordert die Objekterkennung. Der Artikel von 2014 bietet einen Ansatz, der auf der Viola-Jones- und der HOG-Methode mit visueller Genauigkeit basiert:

Dank der Verwendung zusätzlicher statistischer Einschränkungen ist ihre Genauigkeit sehr gut:

Jetzt wird die Aufgabe der Objekterkennung mit Hilfe neuronaler Netze erfolgreich gelöst. Wir werden das Tensorflow Object Detection API-System verwenden und ein neuronales Netzwerk mit der Mobilenet V1 SSD-Architektur trainieren. Das Trainieren eines solchen Modells von Grund auf erfordert viele Daten und kann Tage dauern. Daher verwenden wir ein Modell, das auf COCO-Daten nach dem Prinzip des Transferlernens trainiert wurde.
Das Schlüsselkonzept dieses Ansatzes ist dies. Warum muss ein Kind nicht Millionen von Objekten zeigen, damit es lernt, einen Ball von einem Würfel zu finden und zu unterscheiden? Weil das Kind 500 Millionen Jahre Entwicklung des visuellen Kortex hat. Die Evolution hat das Sehen zum größten sensorischen System gemacht. Fast 50% (aber das ist nicht genau) der Neuronen des menschlichen Gehirns sind für die Bildverarbeitung verantwortlich. Eltern können nur den Ball und den Würfel zeigen und das Kind dann mehrmals korrigieren, damit es das eine perfekt findet und voneinander unterscheidet.
Aus philosophischer Sicht (mit mehr als allgemeinen technischen Unterschieden) funktioniert das Transferlernen in neuronalen Netzen auf ähnliche Weise. Faltungs-Neuronale Netze bestehen aus Ebenen, von denen jede immer komplexere Formen definiert: Sie identifizieren Schlüsselpunkte, kombinieren sie zu Linien, die sich wiederum zu Figuren verbinden. Und erst auf der letzten Ebene bestimmt aus der Gesamtheit der gefundenen Zeichen das Objekt.
Objekte der realen Welt haben viel gemeinsam. Beim Transferlernen verwenden wir die bereits trainierten Definitionsebenen der Grundfunktionen und trainieren nur die Ebenen, die für die Identifizierung von Objekten verantwortlich sind. Dazu reichen uns ein paar hundert Fotos und ein paar Betriebsstunden einer normalen GPU. Das Netzwerk wurde ursprünglich auf dem COCO-Datensatz (Microsoft Common Objects in Context) trainiert, der 91 Kategorien und 2.500.000 Bilder umfasst! Viele, wenn auch nicht 500 Millionen Jahre Evolution.
Mit Blick auf die Zukunft visualisiert diese GIF-Animation (etwas langsam, nicht sofort scrollen) vom Tensorboard den Lernprozess. Wie Sie sehen können, liefert das Modell fast sofort ein vollständig hochwertiges Ergebnis, und dann kommt das Schleifen:

Der „Trainer“ des Tensorflow-Objekterkennungs-API-Systems kann unabhängig voneinander eine Erweiterung durchführen, zufällige Teile von Bildern für das Training ausschneiden und „negative“ Beispiele auswählen (Fotoabschnitte, die keine Objekte enthalten). Theoretisch ist keine Fotovorverarbeitung erforderlich. Auf einem Heimcomputer mit Festplatte und wenig RAM weigerte er sich jedoch, mit hochauflösenden Bildern zu arbeiten: Zuerst hing er lange, raschelte mit einer Festplatte und flog dann heraus.
Infolgedessen haben wir die Fotos auf eine Größe von 1000 x 1000 Pixel komprimiert, während das Seitenverhältnis beibehalten wurde. Da jedoch beim Komprimieren eines großen Fotos viele Zeichen verloren gehen, wurden zunächst mehrere Quadrate einer zufälligen Größe aus jedem Foto des Racks ausgeschnitten und in 1000 x 1000 gepresst. Infolgedessen fielen Packs in hoher Auflösung (aber nicht genug) und in kleinen (aber vielen) in die Trainingsdaten. Wir wiederholen: Dieser Schritt ist erzwungen und höchstwahrscheinlich völlig unnötig und möglicherweise schädlich.
Die vorbereiteten und komprimierten Fotos werden in separaten Verzeichnissen (eval und train) gespeichert und ihre Beschreibung (mit den darin enthaltenen Bündeln) wird in Form von zwei Pandas-Datenrahmen (train_df und eval_df) gebildet:
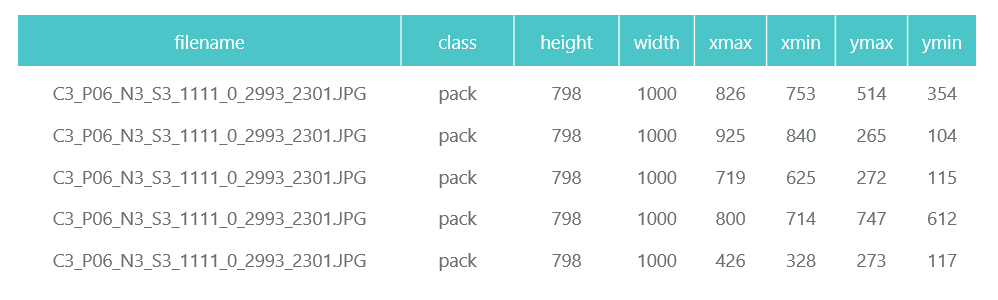
Das Tensorflow Object Detection API-System erfordert, dass Eingaben als tfrecord-Dateien dargestellt werden. Sie können sie mit dem Dienstprogramm erstellen, aber wir machen daraus einen Code:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
Es bleibt uns überlassen, ein spezielles Verzeichnis vorzubereiten und die Prozesse zu starten:
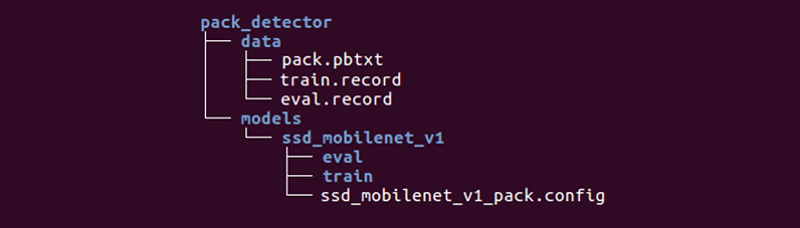
Die Struktur mag unterschiedlich sein, aber wir finden es sehr praktisch.
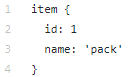
Das Datenverzeichnis enthält die Dateien, die wir mit tfrecords (train.record und eval.record) erstellt haben, sowie pack.pbtxt mit den Objekttypen, für die wir das neuronale Netzwerk trainieren werden. Wir müssen nur einen Objekttyp definieren, daher ist die Datei sehr kurz:
Das Modellverzeichnis (es kann viele Modelle zur Lösung eines Problems geben) im untergeordneten Verzeichnis ssd_mobilenet_v1 enthält die Einstellungen für das Training in der Datei .config sowie zwei leere Verzeichnisse: train und eval. Im Zug speichert der „Trainer“ die Modellkontrollpunkte, der „Bewerter“ nimmt sie auf, führt sie für die zu bewertenden Daten aus und legt sie im Bewertungsverzeichnis ab. Tensorboard verfolgt diese beiden Verzeichnisse und zeigt Prozessinformationen an.
Detaillierte Beschreibung der Struktur von Konfigurationsdateien usw. finden Sie
hier und
hier . Installationsanweisungen für die Tensorflow Object Detection API finden Sie
hier .
Wir gehen in das Verzeichnis models / research / object_detection und entleeren das vorab trainierte Modell:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
Dort kopieren wir das von uns erstellte Verzeichnis pack_detector.
Starten Sie zunächst den Trainingsprozess:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
Wir starten den Bewertungsprozess. Wir haben keine zweite Grafikkarte, daher starten wir sie auf dem Prozessor (mit der Anweisung CUDA_VISIBLE_DEVICES = ""). Aus diesem Grund wird er sehr spät in Bezug auf den Trainingsprozess sein, aber das ist nicht so schlimm:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
Wir starten den Tensorboard-Prozess:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
Danach können wir schöne Grafiken sowie die tatsächliche Arbeit des Modells an den geschätzten Daten sehen (GIF am Anfang):
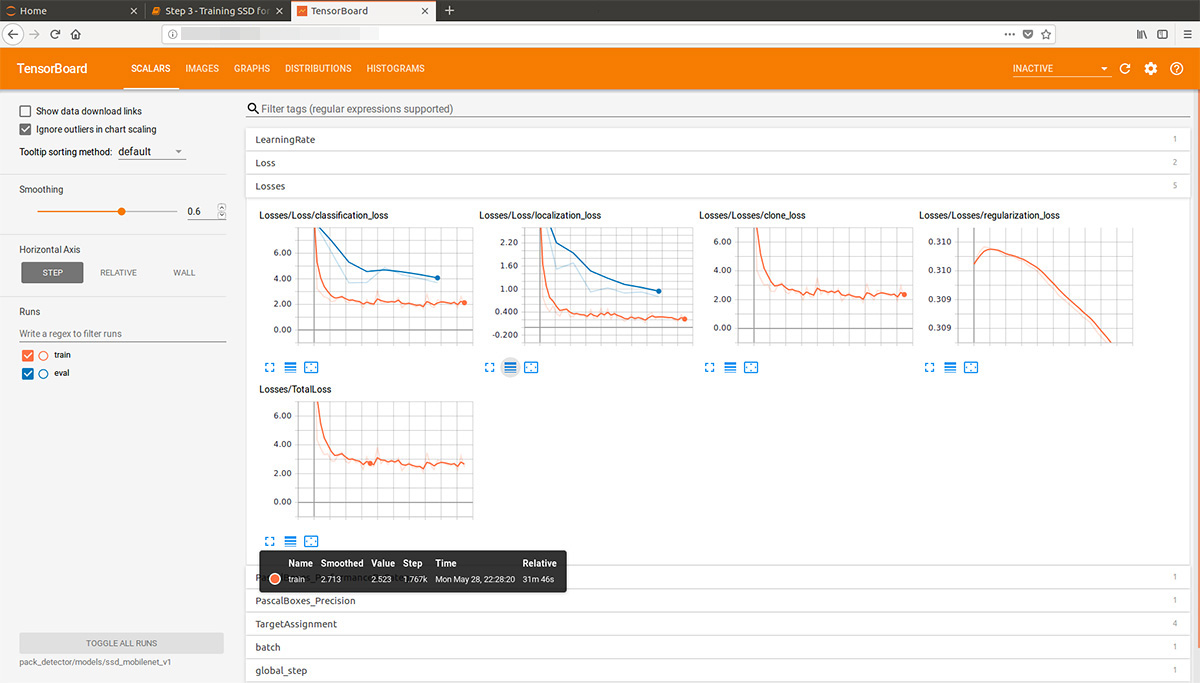
Der Trainingsprozess kann jederzeit gestoppt und fortgesetzt werden. Wenn wir glauben, dass das Modell gut genug ist, speichern wir den Prüfpunkt in Form eines Inferenzgraphen:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
In diesem Schritt haben wir also ein Inferenzdiagramm erhalten, mit dem wir nach Bündelobjekten suchen können. Wir gehen zu seiner Verwendung über.
Schritt 4. Implementierung der Suche ( Github-Link )Der Lade- und Initialisierungscode des Inferenzdiagramms befindet sich unter dem obigen Link. Wichtige Suchfunktionen:
Die Funktion findet begrenzte Kästchen für Packs nicht auf dem gesamten Foto, sondern in seinem Teil. Die Funktion filtert auch die gefundenen Rechtecke mit einer niedrigen Erkennungsbewertung heraus, die im Cutoff-Parameter angegeben ist.
Es stellt sich als Dilemma heraus. Einerseits verlieren wir mit einem hohen Cutoff viele Objekte, andererseits finden wir mit einem niedrigen Cutoff viele Objekte, die keine Bündel sind. Gleichzeitig finden wir immer noch nicht alles und nicht ideal:

Beachten Sie jedoch, dass die Erkennung mit Cutoff = 0,9 nahezu perfekt ist, wenn wir die Funktion für ein kleines Stück des Fotos ausführen.

Dies liegt an der Tatsache, dass das MobileNet V1 SSD-Modell 300 x 300 Fotos als Eingabe akzeptiert. Natürlich gehen bei einer solchen Komprimierung viele Zeichen verloren.
Diese Zeichen bleiben jedoch bestehen, wenn wir ein kleines Quadrat mit mehreren Packungen ausschneiden. Dies legt die Idee nahe, ein schwebendes Fenster zu verwenden: Wir laufen durch ein kleines Rechteck auf einem Foto und erinnern uns an alles, was wir gefunden haben.

: , . . : (detection score), , , overlapTresh ( ):
:

:

, , .
Fazit
«»: , . , , .. .
, , :
- 150 , , ,
- 3-7 ,
- 100 ,
- ,
- (),
- (, ),
- , «»,
- , , (SSD ),
- , ,
- .
, , .