 Wie KI- Übersetzung lernen kann, Bilder von Katzen zu erzeugen
Wie KI- Übersetzung lernen kann, Bilder von Katzen zu erzeugen .
Die 2014 veröffentlichte GAN-Forschung (
Generative Adversarial Nets ) war ein Durchbruch auf dem Gebiet der generativen Modelle. Der leitende Forscher Yann Lekun bezeichnete gegnerische Netze als "die beste Idee für maschinelles Lernen in den letzten zwanzig Jahren". Dank dieser Architektur können wir heute eine KI erstellen, die realistische Bilder von Katzen erzeugt. Cool!
 DCGAN während des Trainings
DCGAN während des TrainingsDer gesamte Arbeitscode befindet sich im
Github-Repository . Es ist hilfreich für Sie, wenn Sie Erfahrung in der Python-Programmierung, im Deep Learning, in der Arbeit mit Tensorflow und in Faltungs-Neuronalen Netzen haben.
Und wenn Sie mit Deep Learning noch nicht vertraut sind, empfehle ich Ihnen, sich mit der hervorragenden Artikelserie vertraut zu machen.
Maschinelles Lernen macht Spaß!Was ist DCGAN?
Deep Convolutional Generative Adverserial Networks (DCGAN) ist eine Deep-Learning-Architektur, die Daten generiert, die den Daten aus dem Trainingssatz ähnlich sind.
Dieses Modell ersetzt die vollständig verbundenen Schichten des generativen gegnerischen Netzwerks durch Faltungsschichten. Um zu verstehen, wie DCGAN funktioniert, verwenden wir die Metapher der Konfrontation zwischen einem erfahrenen Kunstkritiker und einem Fälscher.
Der Fälscher („Generator“) versucht, ein gefälschtes Van-Gogh-Bild zu erstellen und es als echtes Bild auszugeben.
Ein Kunstkritiker („Diskriminator“) versucht, einen Fälscher zu verurteilen, indem er sein Wissen über die wirklichen Leinwände von Van Gogh nutzt.
Im Laufe der Zeit definiert der Kunstkritiker zunehmend Fälschungen, und der Fälscher macht sie alle perfekter.
 Wie Sie sehen können, bestehen DCGANs aus zwei getrennten neuronalen Deep-Learning-Netzen, die miteinander konkurrieren.
Wie Sie sehen können, bestehen DCGANs aus zwei getrennten neuronalen Deep-Learning-Netzen, die miteinander konkurrieren.- Der Generator versucht glaubwürdige Daten zu erstellen. Er weiß nicht, was die realen Daten sind, aber er lernt aus den Reaktionen des feindlichen neuronalen Netzwerks und ändert die Ergebnisse seiner Arbeit mit jeder Iteration.
- Der Diskriminator versucht, die gefälschten Daten zu bestimmen (im Vergleich zu den realen), wobei Fehlalarme in Bezug auf die realen Daten so weit wie möglich vermieden werden. Das Ergebnis dieses Modells ist eine Rückmeldung für den Generator.
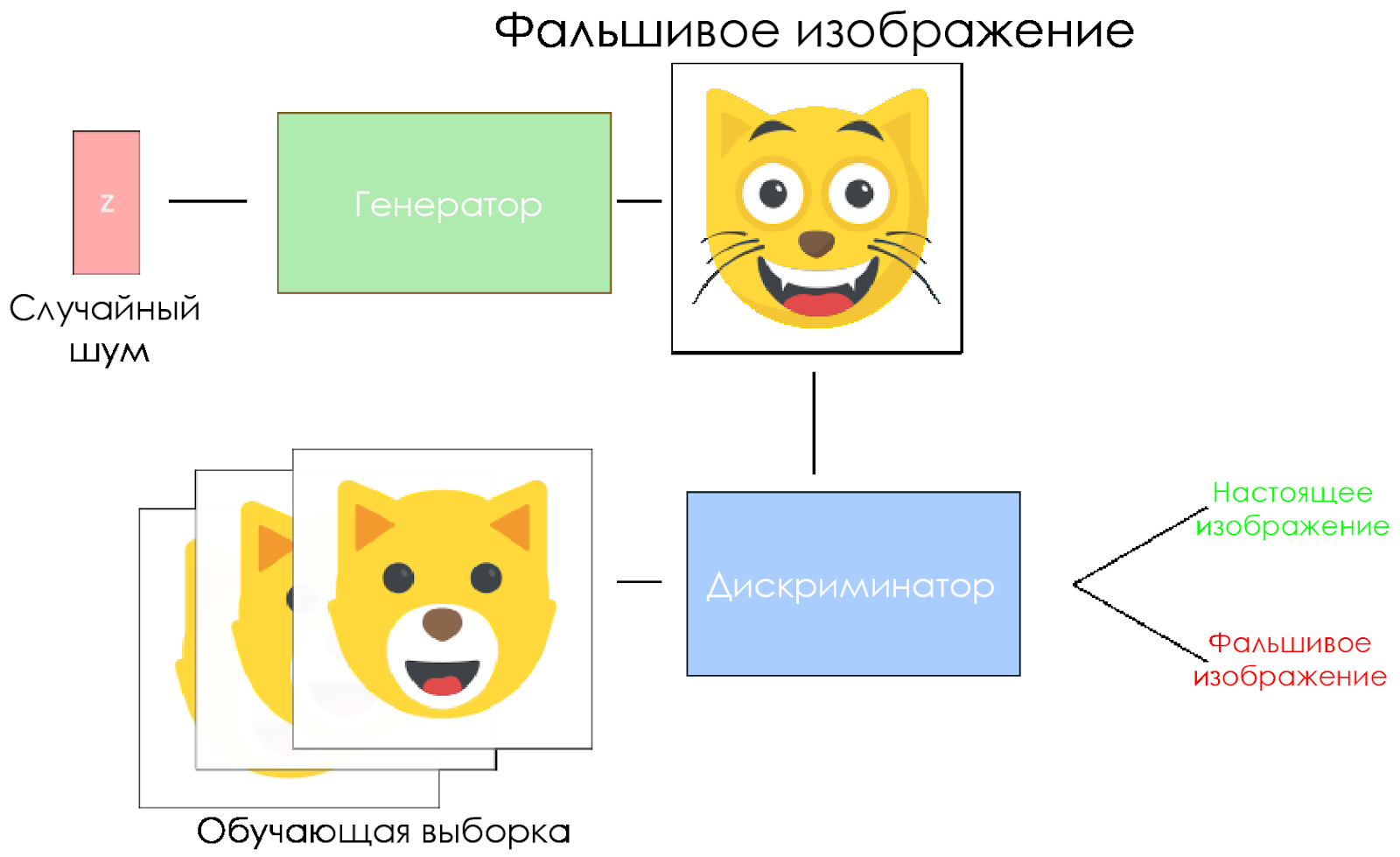 DCGAN-Schema.
DCGAN-Schema.- Der Generator nimmt einen zufälligen Rauschvektor und erzeugt ein Bild.
- Das Bild wird dem Diskriminator gegeben, er vergleicht es mit dem Trainingsmuster.
- Der Diskriminator gibt eine Zahl zurück - 0 (Fälschung) oder 1 (reales Bild).
Erstellen wir ein DCGAN!
Jetzt sind wir bereit, unsere eigene KI zu erstellen.
In diesem Teil konzentrieren wir uns auf die Hauptkomponenten unseres Modells. Wenn Sie den gesamten Code sehen möchten, klicken Sie
hier .
Daten eingeben
Erstellen Sie Stubs für den Eingang:
inputs_real für den Diskriminator und
inputs_z für den Generator. Bitte beachten Sie, dass wir zwei Lernraten haben, getrennt für den Generator und den Diskriminator.
DCGANs reagieren sehr empfindlich auf Hyperparameter, daher ist es sehr wichtig, sie zu optimieren.
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
Diskriminator und Generator
Wir verwenden
tf.variable_scope aus zwei Gründen.
Stellen Sie zunächst sicher, dass alle Variablennamen mit Generator / Diskriminator beginnen. Dies wird uns später beim Training von zwei neuronalen Netzen helfen.
Zweitens werden wir diese Netzwerke mit unterschiedlichen Eingabedaten wiederverwenden:
- Wir werden den Generator trainieren und dann eine Probe der von ihm erzeugten Bilder nehmen.
- Im Diskriminator teilen wir Variablen für gefälschte und echte Eingabebilder.

Lassen Sie uns einen Diskriminator erstellen. Denken Sie daran, dass als Eingabe ein echtes oder falsches Bild aufgenommen wird und als Antwort 0 oder 1 zurückgegeben wird.
Ein paar Anmerkungen:
- Wir müssen die Filtergröße in jeder Faltungsschicht verdoppeln.
- Die Verwendung von Downsampling wird nicht empfohlen. Stattdessen sind nur abgestreifte Faltungsschichten anwendbar.
- In jeder Schicht verwenden wir die Batch-Normalisierung (mit Ausnahme der Eingabeebene), da dies die Kovarianzverschiebung verringert. Lesen Sie mehr in diesem wunderbaren Artikel .
- Wir werden Leaky ReLU als Aktivierungsfunktion verwenden, um den Effekt des "Verschwindens" des Gradienten zu vermeiden.
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
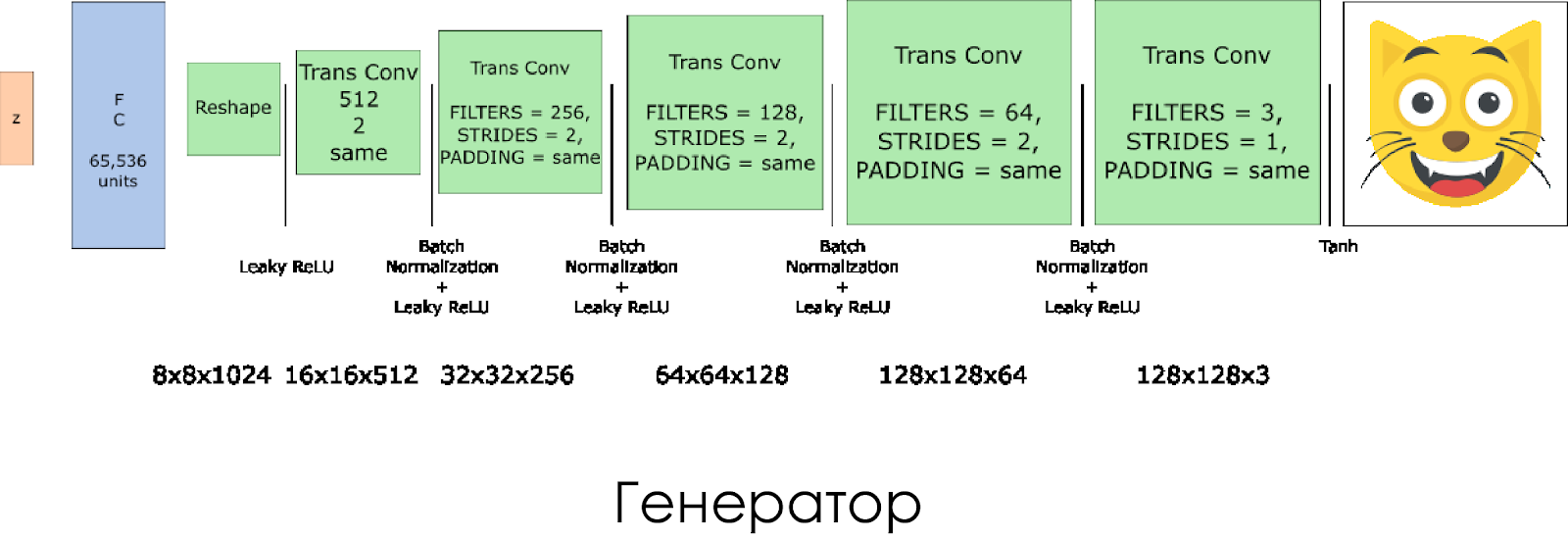
Wir haben einen Generator erstellt. Denken Sie daran, dass der Rauschvektor (z) als Eingabe verwendet wird und dank der transponierten Faltungsschichten ein falsches Bild erstellt wird.
Auf jeder Ebene halbieren wir die Größe des Filters und verdoppeln auch die Größe des Bildes.
Der Generator funktioniert am besten, wenn
tanh als Ausgangsaktivierungsfunktion verwendet wird.
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
Verluste im Diskriminator und Generator
Da wir sowohl den Generator als auch den Diskriminator trainieren, müssen wir die Verluste für beide neuronalen Netze berechnen. Der Diskriminator sollte 1 geben, wenn er das Bild als echt betrachtet, und 0, wenn das Bild gefälscht ist. Entsprechend müssen Sie den Verlust konfigurieren. Der Diskriminatorverlust wird als Summe der Verluste für das reale und das falsche Bild berechnet:
d_loss = d_loss_real + d_loss_fakeDabei ist
d_loss_real der Verlust, wenn der Diskriminator das Bild als falsch betrachtet, es aber tatsächlich real ist. Es wird wie folgt berechnet:
- Wir verwenden
d_logits_real , alle Labels sind gleich 1 (da alle Daten real sind). labels = tf.ones_like(tensor) * (1 - smooth) . Verwenden wir die Etikettenglättung: Verringern Sie die Etikettenwerte von 1,0 auf 0,9, damit der Diskriminator besser verallgemeinern kann.
d_loss_fake ist ein Verlust, wenn der Diskriminator das Bild als real betrachtet, es aber tatsächlich gefälscht ist.
- Wir verwenden
d_logits_fake , alle Labels sind 0.
Um den Generator zu verlieren, wird
d_logits_fake vom Diskriminator verwendet. Dieses Mal sind alle Bezeichnungen 1, weil der Generator den Diskriminator austricksen will.
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
Optimierer
Nach der Berechnung der Verluste müssen Generator und Diskriminator einzeln aktualisiert werden. Verwenden Sie dazu
tf.trainable_variables() um eine Liste aller in unserem Diagramm definierten Variablen
tf.trainable_variables() erstellen.
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
Schulung
Jetzt implementieren wir die Trainingsfunktion. Die Idee ist ziemlich einfach:
- Wir speichern unser Modell alle fünf Perioden (Epoche).
- Wir speichern das Bild alle 10 trainierten Stapel im Ordner mit Bildern.
- Alle 15 Perioden zeigen wir
g_loss , d_loss und das generierte Bild an. Dies liegt daran, dass das Jupyter-Notebook abstürzen kann, wenn zu viele Bilder angezeigt werden. - Oder wir können direkt echte Bilder erzeugen, indem wir ein gespeichertes Modell laden (dies spart 20 Stunden Training).
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
Wie man läuft
All dies kann direkt auf Ihrem Computer ausgeführt werden, wenn Sie bereit sind, 10 Jahre zu warten. Daher ist es besser, Cloud-basierte GPU-Dienste wie AWS oder FloydHub zu verwenden. Persönlich habe ich dieses DCGAN 20 Stunden lang auf Microsoft Azure und ihrer
Deep Learning Virtual Machine trainiert. Ich habe keine Geschäftsbeziehung mit Azure, ich mag nur den Kundenservice.
Wenn Sie Probleme beim Ausführen in einer virtuellen Maschine haben, lesen Sie diesen wunderbaren
Artikel .
Wenn Sie das Modell verbessern, können Sie eine Pull-Anfrage stellen.
