Heute werden wir über Kubernetes sprechen, über den Rechen, der in seiner praktischen Verwendung gesammelt werden kann, und über die Entwicklungen, die dem Autor geholfen haben und die Ihnen auch helfen sollten. Wir werden versuchen, dies ohne k8s in der modernen Welt überall zu beweisen. Für Gegner von k8s bieten wir auch hervorragende Gründe, warum Sie nicht darauf umsteigen sollten. Das heißt, in der Geschichte werden wir Kubernetes nicht nur verteidigen, sondern ihn auch schelten. Von hier im Namen kam dies
[nicht] .
Dieser Artikel basiert auf einer
Präsentation von Ivan Glushkov (
gli ) auf der DevOops 2017-Konferenz. Iwans letzte beiden Arbeitsorte waren irgendwie mit Kubernetes verbunden: Er arbeitete in Infracommands sowohl in Postmates als auch in Machine Zone und sie wirken sich sehr stark auf Kubernetes aus. Außerdem leitet Ivan den
DevZen- Podcast. Weitere Präsentation wird im Namen von Ivan sein.

Zunächst werde ich kurz auf den Bereich eingehen, warum es für viele nützlich und wichtig ist, warum dieser Hype entsteht. Dann erzähle ich Ihnen von unseren Erfahrungen im Umgang mit Technologie. Nun, dann die Schlussfolgerungen.
In diesem Artikel werden alle Folien als Bilder eingefügt, aber manchmal möchten Sie etwas kopieren. Zum Beispiel wird es Beispiele mit Konfigurationen geben. PDF-Folien können hier heruntergeladen
werden .
Ich werde nicht unbedingt jedem sagen: Verwenden Sie unbedingt Kubernetes. Es gibt Vor- und Nachteile. Wenn Sie also nach Nachteilen suchen, werden Sie sie finden. Sie haben die Wahl, schauen Sie sich nur die Vor- und Nachteile an und schauen Sie sich im Allgemeinen alles zusammen an.
Simon Cat wird mir bei den Profis helfen, und die schwarze Katze wird die Straße überqueren, wenn es ein Minus gibt.

Warum ist dieser Hype überhaupt passiert, warum ist die X-Technologie besser als Y. Kubernetes ist genau das gleiche System, und es gibt viele mehr als eines. Es gibt Puppet, Chef, Ansible, Bash + SSH, Terraform. Mein Lieblings-SSH hilft mir jetzt, warum sollte ich irgendwohin gehen. Ich glaube, dass es viele Kriterien gibt, aber ich habe die wichtigsten hervorgehoben.
Die Zeit vom Commit bis zur Veröffentlichung ist eine sehr gute Marke, und die Jungs von Express 42 sind großartige Experten auf diesem Gebiet. Automatisierung der Montage, Automatisierung der gesamten Pipeline ist eine sehr gute Sache, man kann es nicht loben, es hilft tatsächlich. Kontinuierliche Integration, kontinuierliche Bereitstellung. Und natürlich, wie viel Aufwand Sie für alles aufwenden werden. Alles kann in Assembler geschrieben werden, wie ich bereits sagte, ein Bereitstellungssystem, aber es wird keinen Komfort hinzufügen.

Ich werde Ihnen keine kurze Einführung in Kubernetes geben, Sie wissen, was es ist. Ich werde auf diese Bereiche noch etwas näher eingehen.
Warum ist das alles für Entwickler so wichtig? Die Wiederholbarkeit ist für sie wichtig, dh wenn sie eine Anwendung geschrieben und einen Test ausgeführt haben, funktioniert dies für Sie, Ihren Nachbarn und die Produktion.
Die zweite ist eine standardisierte Umgebung: Wenn Sie Kubernetes studiert haben und zu einem benachbarten Unternehmen gehen, in dem sich Kubernetes befindet, ist alles gleich. Die Vereinfachung des Testverfahrens und der kontinuierlichen Integration ist kein direktes Ergebnis der Verwendung von Kubernetes, vereinfacht jedoch die Aufgabe, sodass alles bequemer wird.

Für Release-Entwickler gibt es viele weitere Vorteile. Erstens ist es eine unveränderliche Infrastruktur.
Zweitens ist Infrastruktur wie Code, der irgendwo gespeichert wird. Drittens Idempotenz, die Fähigkeit, eine Veröffentlichung mit einer Taste hinzuzufügen. Release-Rollbacks treten recht schnell auf, und die Selbstbeobachtung des Systems ist sehr praktisch. Natürlich kann dies alles auf Ihrem System durchgeführt werden, das auf das Knie geschrieben ist, aber Sie können es nicht immer richtig machen, und Kubernetes hat es bereits implementiert.
Was ist Kubernetes nicht und was darf es nicht? In dieser Hinsicht gibt es viele Missverständnisse. Beginnen wir mit den Containern. Kubernetes läuft auf ihnen. Container sind keine leichten virtuellen Maschinen, sondern eine völlig andere Einheit. Sie sind mit Hilfe dieses Konzepts leicht zu erklären, aber tatsächlich ist es falsch. Das Konzept ist völlig anders, es muss verstanden und akzeptiert werden.
Zweitens macht Kubernetes die Anwendung nicht sicherer. Es macht es nicht automatisch skalierbar.
Sie müssen sich bemühen, Kubernetes zu starten. Es wird nicht so sein, dass "ein Knopf gedrückt wurde und alles automatisch funktionierte". Es wird weh tun.

Unsere Erfahrung. Wir möchten, dass Sie und alle anderen nichts kaputt machen. Dazu müssen Sie sich genauer umsehen - und hier ist unsere Seite.

Erstens geht Kubernetes nicht alleine. Wenn Sie eine Struktur erstellen, die Releases und Bereitstellungen vollständig verwaltet, sollten Sie verstehen, dass Kubernetes ein Würfel ist und es 100 solcher Würfel geben muss. Um all dies zu erstellen, müssen Sie alles gründlich studieren. Anfänger, die in Ihr System kommen, werden auch diesen Stapel studieren, eine riesige Menge an Informationen.
Kubernetes ist nicht der einzige wichtige Block, es gibt viele andere wichtige Blöcke, ohne die das System nicht funktioniert. Das heißt, Sie müssen sich sehr um die Fehlertoleranz kümmern.

Aus diesem Grund ist Kubernetes ein Minus. Das System ist komplex, Sie müssen sich um viel kümmern.

Aber es gibt Pluspunkte. Wenn eine Person Kubernetes in einem Unternehmen studiert hat, stehen ihre Haare in einem anderen aufgrund des Freisetzungssystems nicht zu Berge. Mit der Zeit, wenn Kubernetes mehr Platz einnimmt, wird der Übergang von Personen und Schulungen einfacher. Und dafür - ein Plus.


Wir benutzen Helm. Dieses System, das auf Kubernetes basiert, ähnelt einem Paketmanager. Sie können auf die Schaltfläche klicken und sagen, dass Sie * Wine * auf Ihrem System installieren möchten. Kann in Kubernetes installiert werden. Es funktioniert, lädt automatisch herunter, startet und alles wird funktionieren. Es ermöglicht Ihnen die Arbeit mit Plug-Ins, Client-Server-Architektur. Wenn Sie mit ihm arbeiten, empfehlen wir Ihnen, einen Tiller im Namespace auszuführen. Dadurch wird der Namespace voneinander isoliert, und wenn Sie einen brechen, wird der andere nicht zerstört.

Tatsächlich ist das System sehr komplex. Ein System, das eine Abstraktion einer höheren Ebene und einfacher und verständlicher sein sollte, macht es nicht wirklich einfacher zu verstehen. Für dieses Minus.

Vergleichen wir die Konfigurationen. Höchstwahrscheinlich haben Sie auch einige Konfigurationen, wenn Sie Ihr System in der Produktion ausführen. Wir haben unser eigenes System namens BOOMer. Ich weiß nicht, warum wir sie so genannt haben. Es besteht aus Puppet, Chef, Ansible, Terraform und allem anderen gibt es eine große Flasche.

Mal sehen, wie es funktioniert. Hier ist ein Beispiel für eine reale Konfiguration, die derzeit in der Produktion arbeitet. Was sehen wir hier?
Erstens sehen wir, wo die Anwendung gestartet werden muss, zweitens, was gestartet werden muss und drittens, wie sie für den Start vorbereitet werden soll. In einer Flasche sind die Konzepte bereits gemischt.

Wenn wir weiter schauen, weil wir die Vererbung hinzugefügt haben, um komplexere Konfigurationen zu erstellen, sollten wir uns ansehen, was in der allgemeinen Konfiguration enthalten ist, auf die wir uns beziehen. Außerdem fügen wir Netzwerkkonfiguration, Zugriffsrechte und Lastplanung hinzu. All dies in einer Konfiguration, die wir benötigen, um eine echte Anwendung in der Produktion auszuführen, mischen wir eine Reihe von Konzepten an einem Ort.
Dies ist sehr schwierig, es ist sehr falsch und dies ist ein großes Plus für Kubernetes, da Sie darin einfach bestimmen, was ausgeführt werden soll. Das Netzwerk-Setup wurde während der Installation von Kubernetes durchgeführt, die gesamte Bereitstellung wurde mit dem Docker gelöst - Sie hatten eine Kapselung, alle Probleme wurden irgendwie getrennt, und in diesem Fall hat die Konfiguration nur Ihre Anwendung, und dafür gibt es ein Plus.

Schauen wir uns das genauer an. Hier haben wir nur eine Anwendung. Damit die Bereitstellung funktioniert, benötigen Sie eine ganze Reihe mehr, um zu funktionieren. Zunächst müssen Sie Dienste definieren. Wie Geheimnisse, ConfigMap, Zugriff auf Load Balancer zu uns kommen.

Vergessen Sie nicht, dass Sie mehrere Umgebungen haben. Es gibt Stage / Prod / Dev. Dies alles zusammen ist kein kleines Stück, das ich gezeigt habe, sondern eine riesige Reihe von Konfigurationen, was wirklich schwierig ist. Für dieses Minus.

Helmvorlage zum Vergleich. Die Kubernetes-Vorlagen werden vollständig wiederholt. Wenn sich in Kubernetes eine Datei mit der Bereitstellungsdefinition befindet, ist dies auch in Helm der Fall. Anstelle spezifischer Werte für die Umgebung haben Sie Vorlagen, die durch Werte ersetzt werden.
Sie haben eine separate Vorlage, separate Werte, die in dieser Vorlage ersetzt werden sollten.
Natürlich müssen Sie zusätzlich die unterschiedliche Infrastruktur von Helm selbst definieren, obwohl Sie in Kubernetes viele Konfigurationsdateien haben, die Sie per Drag & Drop in Helm ziehen müssen. Das ist alles sehr schwierig, wofür ein Minus.
Ein System, das vereinfachen sollte, erschwert tatsächlich. Für mich ist das ein klares Minus. Entweder müssen Sie etwas anderes hinzufügen oder nicht verwenden
Gehen wir tiefer, wir sind nicht tief genug.

Erstens, wie wir mit Clustern arbeiten. Ich habe den Google-Artikel
"Borg, Omega und Kubernetes" gelesen
, in dem das Konzept, dass Sie einen großen Cluster benötigen, nachdrücklich befürwortet wird. Ich war auch für diese Idee, aber am Ende haben wir sie verlassen. Aufgrund unserer Streitigkeiten verwenden wir vier verschiedene Cluster.
Der erste e2e-Cluster, der Kubernetes selbst testet und Skripts testet, die die Umgebung, Plug-Ins usw. bereitstellen. Das zweite ist natürlich Prod und Stage. Dies sind Standardkonzepte. Drittens ist dies der Administrator, in den alles andere geladen ist - insbesondere haben wir CI dort, und es scheint, dass dieser Cluster deswegen immer der größte sein wird.
Es gibt viele Tests: Durch Festschreiben, Zusammenführen macht jeder eine Reihe von Festschreibungen, sodass die Cluster einfach riesig sind.

Wir haben versucht, CoreOS zu betrachten, haben es aber nicht verwendet. Sie haben TF oder CloudFormation im Inneren und beide erlauben es uns sehr schlecht zu verstehen, was sich im inneren Zustand befindet. Aus diesem Grund treten beim Upgrade Probleme auf. Wenn Sie die Einstellungen Ihrer Kubernetes aktualisieren möchten, z. B. die Version, kann es vorkommen, dass das Update nicht in der falschen Reihenfolge auf diese Weise funktioniert. Dies ist ein großes Stabilitätsproblem. Das ist ein Minus.

Zweitens müssen Sie bei Verwendung von Kubernetes Bilder von irgendwoher herunterladen. Es kann sich um eine interne Quelle, ein Repository oder eine externe Quelle handeln. Wenn intern, gibt es Probleme. Ich empfehle die Verwendung von Docker Distribution, da es stabil ist und von Docker erstellt wurde. Der Supportpreis ist aber immer noch hoch. Damit es funktioniert, müssen Sie es fehlertolerant machen, da dies der einzige Ort ist, an dem Ihre Anwendungen Daten zum Arbeiten erhalten.

Stellen Sie sich vor, dass in dem entscheidenden Moment, in dem Sie einen Fehler in der Produktion festgestellt haben, Ihr Repository ausgefallen ist - Sie können die Anwendung nicht aktualisieren. Sie müssen es fehlertolerant machen und von allen möglichen Problemen, die nur sein können.
Zweitens, wenn die Masse der Teams, von denen jedes sein eigenes Image hat, sich sehr schnell ansammelt. Sie können Ihre Docker Distribution beenden. Es ist notwendig zu reinigen, Bilder zu löschen, Informationen für Benutzer zu erstellen, wann und was Sie reinigen werden.
Drittens, bei großen Bildern, sagen wir, wenn Sie einen Monolithen haben, ist die Bildgröße sehr groß. Stellen Sie sich vor, Sie müssen 30 Knoten freigeben. 2 Gigabyte pro 30 Knoten - Berechnen Sie, welcher Stream wie schnell auf alle Knoten heruntergeladen wird. Ich möchte, dass es einen Knopf drückt und sofort grün wird. Aber nein, Sie müssen zuerst warten, bis es heruntergeladen ist. Es ist notwendig, diesen Download irgendwie zu beschleunigen, und alles funktioniert von einem Punkt aus.

Bei externen Repositorys gibt es dieselben Probleme mit dem Garbage Collector, diese werden jedoch meistens automatisch ausgeführt. Wir benutzen Quay. Bei externen Repositorys handelt es sich um Dienste von Drittanbietern, bei denen die meisten Bilder öffentlich sind. Da es keine öffentlichen Bilder gab, ist es notwendig, Zugang zu gewähren. Wir brauchen Geheimnisse, Zugriffsrechte auf Bilder, all dies ist speziell konfiguriert. Dies kann natürlich automatisiert werden, aber im Falle eines lokalen Starts von Cuba auf Ihrem System müssen Sie es noch konfigurieren.

Um Kubernetes zu installieren, verwenden wir Kops. Dies ist ein sehr gutes System, wir sind frühe Benutzer aus der Zeit, als sie noch nicht in den Blog geschrieben hatten. Es unterstützt CoreOS nicht vollständig, funktioniert gut mit Debian, weiß, wie man Kubernetes-Masterknoten automatisch konfiguriert, arbeitet mit Add-Ons und kann während Kubernetes-Updates keine Ausfallzeiten verursachen.
All diese Funktionen sind sofort einsatzbereit, was ein großes und mutiges Plus darstellt. Tolles System!


Unter den Links finden Sie viele Optionen zum Einrichten eines Netzwerks in Kubernetes. Es gibt wirklich viele von ihnen, jeder hat seine eigenen Vor- und Nachteile. Kops unterstützt nur einen Teil dieser Optionen. Sie können es natürlich so konfigurieren, dass es über CNI funktioniert, aber es ist besser, die beliebtesten und Standard-Versionen zu verwenden. Sie werden von der Community getestet und sind höchstwahrscheinlich stabil.

Wir haben uns für Calico entschieden. Es hat von Grund auf gut funktioniert, ohne viele Probleme, verwendet BGP, schnellere Kapselung, unterstützt IP-in-IP, ermöglicht Ihnen die Arbeit mit Multi-Clouds, für uns ist dies ein großes Plus.
Eine gute Integration mit Kubernetes durch die Verwendung von Labels begrenzt den Datenverkehr. Dafür ist ein Plus.
Ich hatte nicht erwartet, dass Calico beim Einschalten in den Zustand kommt, und alles funktioniert ohne Probleme.

Hochverfügbarkeit, wie gesagt, wir machen durch Kops, Sie können 5-7-9 Knoten verwenden, wir verwenden drei. Wir sitzen auf etcd v2, wegen eines Fehlers wurden sie auf v3 nicht aktualisiert. Theoretisch wird dies einige Prozesse beschleunigen. Ich weiß es nicht, ich bezweifle es.

Ein kniffliger Moment, wir haben einen speziellen Cluster zum Experimentieren mit Skripten, das automatische Durchlaufen von CI. Wir glauben, dass wir vor völlig falschen Aktionen geschützt sind, aber für einige spezielle und komplexe Releases führen wir nicht jeden Tag Backups durch, falls wir Snapshots aller Festplatten erstellen.


Autorisierung ist eine ewige Frage. Wir bei Kubernetes verwenden den rollenbasierten RBAC-Zugriff. Es ist viel besser als ABAC, und wenn Sie es konfiguriert haben, verstehen Sie, was ich meine. Schauen Sie sich Konfigurationen an - seien Sie überrascht.
Wir verwenden Dex, einen OpenID-Anbieter, der alle Informationen aus einer Datenquelle pumpt.
Um sich bei Kubernetes anzumelden, gibt es zwei Möglichkeiten. Es ist notwendig, sich irgendwie in .kube / config zu registrieren, wohin es gehen soll und was es tun kann. Es ist notwendig, diese Konfiguration irgendwie zu bekommen. Oder der Benutzer wechselt zur Benutzeroberfläche, wo er sich anmeldet, Konfigurationen empfängt, diese nach / config kopiert und arbeitet. Dies ist nicht sehr praktisch. Wir sind nach und nach zu der Tatsache übergegangen, dass eine Person in die Konsole geht, auf die Schaltfläche klickt, sich anmeldet, Konfigurationen automatisch von ihr generiert und an der richtigen Stelle gestapelt werden. So viel bequemer, dass wir uns entschieden haben, auf diese Weise zu handeln.

Als Datenquelle verwenden wir Active Directory. Mit Kubernetes können Sie Informationen über die Gruppe durch die gesamte Berechtigungsstruktur übertragen, was sich in Namespace und Rollen niederschlägt. So unterscheiden wir sofort, wohin eine Person gehen kann, wohin sie kein Recht hat zu gehen und was sie freigeben kann.

In den meisten Fällen benötigen Benutzer Zugriff auf AWS. Wenn Sie nicht über Kubernetes verfügen, wird die Anwendung auf einem Computer ausgeführt. Es scheint, dass alles, was Sie brauchen, ist, die Protokolle zu bekommen, sie zu sehen und das war's. Dies ist praktisch, wenn eine Person zu ihrem Auto gehen und sehen kann, wie die Anwendung funktioniert. Aus Sicht von Kubernetes funktioniert alles in Containern. Es gibt einen Befehl `kubectl exec` - gehe in den Container in der Anwendung und sehe, was dort passiert. Daher müssen Sie nicht zu AWS-Instanzen wechseln. Wir haben allen den Zugriff verweigert, außer dem Infracommand.
Darüber hinaus haben wir langjährige Admin-Schlüssel und die Eingabe über Rollen verboten. Wenn es möglich ist, die Rolle des Administrators zu verwenden, bin ich der Administrator. Außerdem haben wir die Tastenrotation hinzugefügt. Es ist bequem, es über den Befehl awsudo zu konfigurieren. Dies ist ein Projekt auf dem Github. Ich kann es nur empfehlen. Es ermöglicht Ihnen, wie mit einem Sudo-Team zu arbeiten.



Quoten. Eine sehr gute Sache in Kubernetes, die sofort funktioniert. Sie begrenzen jeden Namespace beispielsweise durch die Anzahl der Objekte, des Speichers oder der CPU, die Sie verbrauchen können. Ich glaube, dass dies für alle wichtig und nützlich ist. Wir haben den Speicher und die CPU noch nicht erreicht, wir verwenden nur die Anzahl der Objekte, aber wir werden all dies hinzufügen.
Das große und fette Plus ermöglicht es Ihnen, viele knifflige Dinge zu tun.


Skalieren. Sie können die Skalierung nicht innerhalb und außerhalb von Kubernetes mischen. Innerhalb von Kubernetes erfolgt die Skalierung selbst. Es kann Pods automatisch erhöhen, wenn es eine große Last gibt.
Hier spreche ich über die Skalierung von Kubernetes-Instanzen selbst. Dies kann mit AWS Autoscaler erfolgen, dies ist ein Github-Projekt. Wenn Sie einen neuen Pod hinzufügen und dieser nicht gestartet werden kann, weil ihm in allen Instanzen Ressourcen fehlen, kann AWS Autoscaler automatisch Knoten hinzufügen. Es ermöglicht Ihnen, an Spot-Instanzen zu arbeiten, wir haben es noch nicht hinzugefügt, aber wir werden, es ermöglicht uns, viel zu sparen.


Wenn Sie viele Benutzer und Benutzeranwendungen haben, müssen Sie diese irgendwie überwachen. Normalerweise ist dies Telemetrie, Protokolle, einige schöne Grafiken.

Aus historischen Gründen hatten wir Sensu, es war nicht sehr gut für Kubernetes geeignet. Ein stärker metrisch orientiertes Projekt war erforderlich. Wir haben uns den gesamten TICK-Stack angesehen, insbesondere InfluxDB. Gute Benutzeroberfläche, SQL-ähnliche Sprache, aber nicht genügend Funktionen. Wir sind zu Prometheus gewechselt.
Er ist gut Gute Abfragesprache, gute Warnungen und alles, was sofort einsatzbereit ist.

Um Telemetrie zu senden, haben wir Cernan verwendet. Dies ist unser eigenes Projekt in Rust. Dies ist das einzige Projekt auf Rust, das seit einem Jahr in unserer Produktion arbeitet. Es gibt mehrere Konzepte: Es gibt ein Datenquellenkonzept, Sie konfigurieren mehrere Quellen. Sie konfigurieren, wo die Daten zusammengeführt werden. Wir haben eine Konfiguration von Filtern, dh fließende Daten können auf irgendeine Weise verarbeitet werden. Sie können Protokolle in Metriken konvertieren, Metriken in Protokolle, was immer Sie wollen.
Trotz der Tatsache, dass Sie mehrere Eingaben und Schlussfolgerungen haben und zeigen, dass es dort, wo es hingeht, so etwas wie ein großes Grafiksystem gibt, ist es recht praktisch.

Wir wechseln jetzt nahtlos vom aktuellen Statsd / Cernan / Wavefront-Stack zu Kubernetes. Theoretisch möchte Prometheus Daten von Anwendungen selbst übernehmen, daher müssen Sie allen Anwendungen einen Endpunkt hinzufügen, von dem Metriken verwendet werden. Cernan ist die Übertragungsstrecke, sie sollte überall funktionieren. Es gibt zwei Möglichkeiten: Sie können Kubernetes auf jeder Instanz mithilfe des Sidecar-Konzepts ausführen, wenn in Ihrem Datenfeld ein anderer Container arbeitet, der Daten sendet. Wir machen dies und das.

Im Moment werden alle Protokolle an stdout / stderr gesendet. Alle Anwendungen sind dafür ausgelegt, daher ist eine der kritischen Anforderungen, dass wir dieses System nicht verlassen. Cernan sendet Daten an ElasticSearch, Ereignisse des gesamten Kubernetes-Systems werden dort mit Heapster gesendet. Dies ist ein sehr gutes System, das ich empfehlen kann.
Danach können Sie alle Protokolle an einem Ort anzeigen, z. B. in der Konsole. Wir benutzen Kibana. Es gibt ein wunderbares Stern-Produkt, nur für die Protokolle. Es ermöglicht Ihnen zu beobachten, malt verschiedene Hülsen in verschiedenen Farben, weiß, wie man sieht, wenn einer unter gestorben ist und der andere neu gestartet wurde. Sammelt automatisch alle Protokolle. Ein ideales Projekt, ich kann es nur empfehlen, es ist ein fettes Plus an Kubernetes, hier ist alles in Ordnung.


Geheimnisse Wir verwenden S3 und KMS. Wir denken darüber nach, in Kubernetes selbst zu Vault oder Geheimnissen zu wechseln. Sie befanden sich im Alpha-Zustand 1,7, aber damit muss etwas getan werden.

Wir kamen zum interessanten Teil. Die Entwicklung von Kubernetes wird im Allgemeinen nicht viel berücksichtigt.
Grundsätzlich heißt es: "Kubernetes ist ein ideales System, alles ist in Ordnung, lasst uns weitermachen."Tatsächlich ist kostenloser Käse nur in einer Mausefalle und für Entwickler bei Kubernetes die Hölle. Nicht unter dem Gesichtspunkt, dass alles schlecht ist, sondern unter dem Gesichtspunkt, dass man die Dinge etwas anders betrachten muss. Ich vergleiche die Entwicklung in Kubernetes mit der funktionalen Programmierung: Bis Sie sie berühren, denken Sie in Ihrem imperativen Stil, dass alles in Ordnung ist. Um sich im Funktionalismus zu entwickeln, müssen Sie Ihren Kopf leicht auf die andere Seite drehen - das gleiche hier.
Nicht unter dem Gesichtspunkt, dass alles schlecht ist, sondern unter dem Gesichtspunkt, dass man die Dinge etwas anders betrachten muss. Ich vergleiche die Entwicklung in Kubernetes mit der funktionalen Programmierung: Bis Sie sie berühren, denken Sie in Ihrem imperativen Stil, dass alles in Ordnung ist. Um sich im Funktionalismus zu entwickeln, müssen Sie Ihren Kopf leicht auf die andere Seite drehen - das gleiche hier., , . -, Docker Way. , . , , SSH, : « - , ».
, Kubernetes , read only . , , , , , , , . Kubernetes , , , , -, .
Außerdem müssen Sie viele Entscheidungen treffen: Wenn Sie einige Änderungen vornehmen, wenn die Entwicklung lokal ist, müssen Sie sie irgendwie in das Repository übertragen, dann führt das Pipeline-Repository die Tests aus und sagt dann: "Oh, es gibt einen Tippfehler in einem Wort", Sie brauchen alles vor Ort tun. Hängen Sie den Ordner irgendwie ein, gehen Sie dort hinein, aktualisieren Sie das System, kompilieren Sie es zumindest. Wenn das lokale Ausführen von Tests unpraktisch ist, kann es zumindest in CI festschreiben, um einige lokale Aktionen zu überprüfen und sie dann zur Überprüfung an CI zu senden. Diese Entscheidungen sind ziemlich kompliziert.Es ist besonders schwierig, wenn Sie eine verzweigte Anwendung haben, die aus einhundert Diensten besteht. Damit einer von ihnen funktioniert, müssen Sie sicherstellen, dass alle anderen nebeneinander arbeiten. Sie müssen entweder die Umgebung emulieren oder irgendwie lokal ausführen. All diese Entscheidungen sind nicht trivial, der Entwickler muss gründlich darüber nachdenken. Dies führt zu einer negativen Einstellung gegenüber Kubernetes. Er ist natürlich gut - aber er ist schlecht, weil Sie viel nachdenken und Ihre Gewohnheiten ändern müssen.Deshalb rannten hier drei dicke Katzen über die Straße.
 Als wir uns Kubernetes angesehen haben, haben wir versucht zu verstehen, dass es vielleicht einige bequeme Systeme für die Entwicklung gibt. Insbesondere gibt es so etwas wie Deis, sicher haben Sie alles darüber gehört. Es ist sehr einfach zu bedienen und wir haben überprüft, dass alle einfachen Projekte sehr einfach zu Deis wechseln. Das Problem ist jedoch, dass komplexere Projekte möglicherweise nicht zu Deis wechseln.Wie gesagt, wir sind zu Helm Charts gewechselt. Das einzige Problem, das wir derzeit sehen, ist, dass eine Menge guter Dokumentation benötigt wird. Wir brauchen eine Anleitung, einige FAQ, damit eine Person schnell starten, die aktuellen Konfigurationen kopieren, ihre eigenen einfügen und die Namen ändern kann, damit alles korrekt ist. Es ist auch wichtig, dies im Voraus zu verstehen, und Sie müssen alles tun. Ich habe hier gängige Toolkits für die Entwicklung aufgelistet. Ich werde dies alles außer dem Mini-Cube nicht ansprechen.
Als wir uns Kubernetes angesehen haben, haben wir versucht zu verstehen, dass es vielleicht einige bequeme Systeme für die Entwicklung gibt. Insbesondere gibt es so etwas wie Deis, sicher haben Sie alles darüber gehört. Es ist sehr einfach zu bedienen und wir haben überprüft, dass alle einfachen Projekte sehr einfach zu Deis wechseln. Das Problem ist jedoch, dass komplexere Projekte möglicherweise nicht zu Deis wechseln.Wie gesagt, wir sind zu Helm Charts gewechselt. Das einzige Problem, das wir derzeit sehen, ist, dass eine Menge guter Dokumentation benötigt wird. Wir brauchen eine Anleitung, einige FAQ, damit eine Person schnell starten, die aktuellen Konfigurationen kopieren, ihre eigenen einfügen und die Namen ändern kann, damit alles korrekt ist. Es ist auch wichtig, dies im Voraus zu verstehen, und Sie müssen alles tun. Ich habe hier gängige Toolkits für die Entwicklung aufgelistet. Ich werde dies alles außer dem Mini-Cube nicht ansprechen. Minikube ist ein sehr gutes System in dem Sinne, dass es gut ist, aber es ist schlecht, dass es ist. Sie können Kubernetes lokal ausführen, alles auf Ihrem Laptop anzeigen, müssen auf SSH nirgendwo hingehen und so weiter.Ich arbeite unter MacOS, ich habe jeweils einen Mac, um eine lokale App auszuführen, muss ich den Docker lokal ausführen. Dies ist nicht möglich. Am Ende müssen Sie entweder virtualbox oder xhyve ausführen. Beide Dinge sind in der Tat Emulationen über meinem Betriebssystem. Wir verwenden xhyve, empfehlen jedoch die Verwendung von VirtualBox, da es viele Fehler gibt, die umgangen werden müssen.Aber die Idee, dass es Virtualisierung gibt und innerhalb der Virtualisierung eine andere Abstraktionsebene für die Virtualisierung gestartet wird, ist eine Art lächerliche, wahnhafte. Im Allgemeinen ist es gut, dass es irgendwie funktioniert, aber es wäre besser, wenn es abgeschlossen wäre.
Minikube ist ein sehr gutes System in dem Sinne, dass es gut ist, aber es ist schlecht, dass es ist. Sie können Kubernetes lokal ausführen, alles auf Ihrem Laptop anzeigen, müssen auf SSH nirgendwo hingehen und so weiter.Ich arbeite unter MacOS, ich habe jeweils einen Mac, um eine lokale App auszuführen, muss ich den Docker lokal ausführen. Dies ist nicht möglich. Am Ende müssen Sie entweder virtualbox oder xhyve ausführen. Beide Dinge sind in der Tat Emulationen über meinem Betriebssystem. Wir verwenden xhyve, empfehlen jedoch die Verwendung von VirtualBox, da es viele Fehler gibt, die umgangen werden müssen.Aber die Idee, dass es Virtualisierung gibt und innerhalb der Virtualisierung eine andere Abstraktionsebene für die Virtualisierung gestartet wird, ist eine Art lächerliche, wahnhafte. Im Allgemeinen ist es gut, dass es irgendwie funktioniert, aber es wäre besser, wenn es abgeschlossen wäre.
 CI ist nicht direkt mit Kubernetes verbunden, aber es ist ein sehr wichtiges System, insbesondere wenn Sie Kubernetes haben. Wenn Sie es integrieren, können Sie sehr gute Ergebnisse erzielen. Wir haben Concourse for CI verwendet, eine sehr umfangreiche Funktionalität. Sie können beängstigende Diagramme erstellen, was, wo, wie es beginnt, wovon es abhängt. Aber die Concourse-Entwickler sind sehr seltsam in Bezug auf ihr Produkt. Angenommen, beim Wechsel von einer Version zu einer anderen haben sie die Abwärtskompatibilität unterbrochen und die meisten Plugins nicht neu geschrieben. Außerdem wurde die Dokumentation nicht fertiggestellt, und als wir versuchten, etwas zu tun, funktionierte überhaupt nichts.In allen CIs gibt es im Allgemeinen nur wenig Dokumentation. Sie müssen den Code lesen, und im Allgemeinen haben wir Concourse aufgegeben. Wir haben zu Drone.io gewechselt - es ist klein, sehr leicht, flink, die Funktionalität ist viel geringer, aber öfter ist es genug. Ja, es wäre praktisch, große und gewichtige Abhängigkeitsdiagramme zu haben, aber Sie können auch an kleinen arbeiten. Auch eine kleine Dokumentation, wir lesen den Code, aber es ist in Ordnung.Jede Stufe der Pipeline arbeitet in einem eigenen Docker-Container, was den Wechsel zu Kubernetes erheblich erleichtert. Wenn Sie eine Anwendung haben, die auf einem realen Computer ausgeführt wird, verwenden Sie den Docker-Container, um sie zu CI hinzuzufügen. Danach ist der Wechsel zu Kubernetes einfach.Wir haben die automatische Freigabe des Admin- / Stage-Clusters konfiguriert, haben jedoch Angst, die Einstellung dem Produktionscluster hinzuzufügen. Außerdem gibt es ein Plugin-System.Dies ist ein Beispiel für eine einfache Drone-Konfiguration. Aus dem fertigen Arbeitssystem entnommen, befinden sich in diesem Fall fünf Schritte in der Pipeline. Jeder Schritt führt etwas aus: Sammeln, Testen usw. Mit diesem Funktionsumfang in Drone halte ich es für eine gute Sache.
CI ist nicht direkt mit Kubernetes verbunden, aber es ist ein sehr wichtiges System, insbesondere wenn Sie Kubernetes haben. Wenn Sie es integrieren, können Sie sehr gute Ergebnisse erzielen. Wir haben Concourse for CI verwendet, eine sehr umfangreiche Funktionalität. Sie können beängstigende Diagramme erstellen, was, wo, wie es beginnt, wovon es abhängt. Aber die Concourse-Entwickler sind sehr seltsam in Bezug auf ihr Produkt. Angenommen, beim Wechsel von einer Version zu einer anderen haben sie die Abwärtskompatibilität unterbrochen und die meisten Plugins nicht neu geschrieben. Außerdem wurde die Dokumentation nicht fertiggestellt, und als wir versuchten, etwas zu tun, funktionierte überhaupt nichts.In allen CIs gibt es im Allgemeinen nur wenig Dokumentation. Sie müssen den Code lesen, und im Allgemeinen haben wir Concourse aufgegeben. Wir haben zu Drone.io gewechselt - es ist klein, sehr leicht, flink, die Funktionalität ist viel geringer, aber öfter ist es genug. Ja, es wäre praktisch, große und gewichtige Abhängigkeitsdiagramme zu haben, aber Sie können auch an kleinen arbeiten. Auch eine kleine Dokumentation, wir lesen den Code, aber es ist in Ordnung.Jede Stufe der Pipeline arbeitet in einem eigenen Docker-Container, was den Wechsel zu Kubernetes erheblich erleichtert. Wenn Sie eine Anwendung haben, die auf einem realen Computer ausgeführt wird, verwenden Sie den Docker-Container, um sie zu CI hinzuzufügen. Danach ist der Wechsel zu Kubernetes einfach.Wir haben die automatische Freigabe des Admin- / Stage-Clusters konfiguriert, haben jedoch Angst, die Einstellung dem Produktionscluster hinzuzufügen. Außerdem gibt es ein Plugin-System.Dies ist ein Beispiel für eine einfache Drone-Konfiguration. Aus dem fertigen Arbeitssystem entnommen, befinden sich in diesem Fall fünf Schritte in der Pipeline. Jeder Schritt führt etwas aus: Sammeln, Testen usw. Mit diesem Funktionsumfang in Drone halte ich es für eine gute Sache.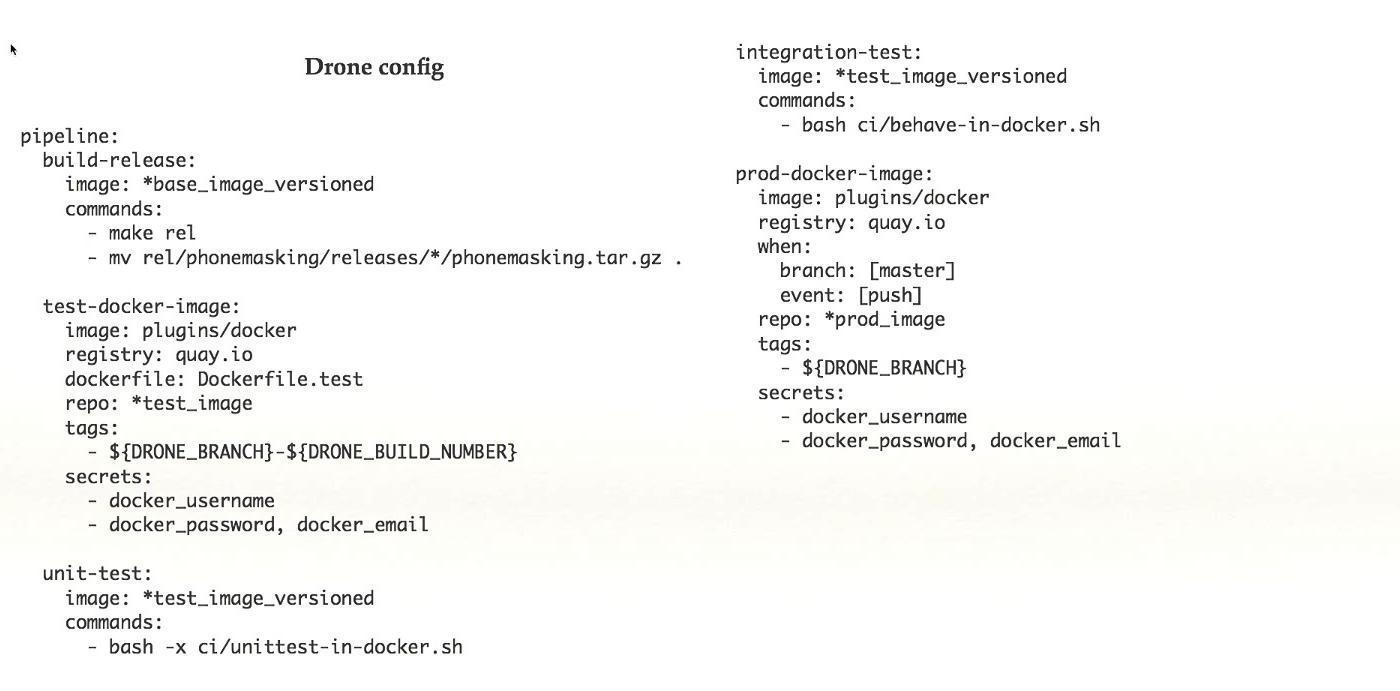
 Wir haben viel darüber gestritten, wie viele Cluster wir haben sollen: einen oder mehrere. Als wir auf die Idee mehrerer Cluster kamen, begannen wir, weiter in diese Richtung zu arbeiten, erstellten einige Skripte und richteten eine Reihe anderer Cubes für unsere Kubernetes ein. Danach kamen sie zu Google und fragten um Rat. Haben alle das getan? Vielleicht muss etwas repariert werden.Google stimmte zu, dass die Idee eines einzelnen Clusters in Kubernetes nicht anwendbar ist. Es gibt viele Unvollkommenheiten, insbesondere bei der Arbeit mit Geolokalisierungen. Es stellt sich heraus, dass die Idee wahr ist, aber es ist zu früh, um darüber zu sprechen. Vielleicht später. Während Service Mesh helfen kann.
Wir haben viel darüber gestritten, wie viele Cluster wir haben sollen: einen oder mehrere. Als wir auf die Idee mehrerer Cluster kamen, begannen wir, weiter in diese Richtung zu arbeiten, erstellten einige Skripte und richteten eine Reihe anderer Cubes für unsere Kubernetes ein. Danach kamen sie zu Google und fragten um Rat. Haben alle das getan? Vielleicht muss etwas repariert werden.Google stimmte zu, dass die Idee eines einzelnen Clusters in Kubernetes nicht anwendbar ist. Es gibt viele Unvollkommenheiten, insbesondere bei der Arbeit mit Geolokalisierungen. Es stellt sich heraus, dass die Idee wahr ist, aber es ist zu früh, um darüber zu sprechen. Vielleicht später. Während Service Mesh helfen kann. Wenn Sie sehen möchten, wie unser System funktioniert, achten Sie im Allgemeinen auf Geodesic. Dies ist ein Produkt ähnlich dem, was wir tun. Es ist Open Source, eine sehr ähnliche Wahl des Designkonzepts. Wir denken darüber nach, uns zusammenzuschließen und sie möglicherweise zu nutzen.
Wenn Sie sehen möchten, wie unser System funktioniert, achten Sie im Allgemeinen auf Geodesic. Dies ist ein Produkt ähnlich dem, was wir tun. Es ist Open Source, eine sehr ähnliche Wahl des Designkonzepts. Wir denken darüber nach, uns zusammenzuschließen und sie möglicherweise zu nutzen. Ja, in unserer Praxis, mit Kubernetes zu arbeiten, gibt es auch Probleme.Es gibt Schmerzen mit lokalen Namen, mit Zertifikaten. Es gibt ein Problem beim Herunterladen großer Bilder und ihrer Arbeit, möglicherweise im Zusammenhang mit dem Dateisystem, das wir dort noch nicht ausgegraben haben. Es gibt bereits drei verschiedene Möglichkeiten, Kubernetes-Erweiterungen zu installieren. Wir arbeiten seit weniger als einem Jahr an diesem Projekt und haben bereits drei verschiedene Möglichkeiten: Jahresringe wachsen.
Ja, in unserer Praxis, mit Kubernetes zu arbeiten, gibt es auch Probleme.Es gibt Schmerzen mit lokalen Namen, mit Zertifikaten. Es gibt ein Problem beim Herunterladen großer Bilder und ihrer Arbeit, möglicherweise im Zusammenhang mit dem Dateisystem, das wir dort noch nicht ausgegraben haben. Es gibt bereits drei verschiedene Möglichkeiten, Kubernetes-Erweiterungen zu installieren. Wir arbeiten seit weniger als einem Jahr an diesem Projekt und haben bereits drei verschiedene Möglichkeiten: Jahresringe wachsen. Lassen Sie uns wie alle Nachteile sein.Daher denke ich, dass einer der Hauptnachteile die große Menge an zu untersuchenden Informationen ist, nicht nur neue Technologien, sondern auch neue Konzepte und Gewohnheiten. Es ist wie das Erlernen einer neuen Sprache: Im Prinzip ist es nicht schwierig, aber es ist schwierig, allen Benutzern den Kopf ein wenig zu drehen. Wenn Sie zuvor noch nicht mit ähnlichen Konzepten gearbeitet haben, ist der Wechsel zu Kubernetes schwierig.Kubernetes sind nur ein kleiner Teil Ihres Systems. Jeder glaubt, dass er Kubernetes installieren wird und alles sofort funktionieren wird. Nein, dies ist ein kleiner Würfel, und es wird viele solcher Würfel geben.Einige Anwendungen lassen sich im Allgemeinen nur schwer auf Kubernetes ausführen - und es ist besser, sie nicht auszuführen. Auch sehr schwere und große Konfigurationsdateien und in Konzepten über Kubernetes sind sie noch komplizierter. Alle aktuellen Lösungen sind roh.All diese Nachteile sind natürlich widerlich.Kompromisse und ein schwieriger Übergang führen zu einem negativen Image von Kubernetes, und ich weiß nicht, wie ich damit umgehen soll. Wir konnten nicht viel überwinden, es gibt Menschen, die die ganze Bewegung hassen, ihre Vorteile nicht wollen und nicht verstehen.Um Minikube ausführen zu können, muss Ihr System hart arbeiten, damit alles funktioniert. Wie Sie sehen, gibt es viele Nachteile, und diejenigen, die nicht mit Kubernetes arbeiten möchten, haben ihre eigenen Gründe. Wenn Sie nichts über die Profis hören möchten, schließen Sie Ihre Augen und Ohren, da diese noch weiter gehen.
Lassen Sie uns wie alle Nachteile sein.Daher denke ich, dass einer der Hauptnachteile die große Menge an zu untersuchenden Informationen ist, nicht nur neue Technologien, sondern auch neue Konzepte und Gewohnheiten. Es ist wie das Erlernen einer neuen Sprache: Im Prinzip ist es nicht schwierig, aber es ist schwierig, allen Benutzern den Kopf ein wenig zu drehen. Wenn Sie zuvor noch nicht mit ähnlichen Konzepten gearbeitet haben, ist der Wechsel zu Kubernetes schwierig.Kubernetes sind nur ein kleiner Teil Ihres Systems. Jeder glaubt, dass er Kubernetes installieren wird und alles sofort funktionieren wird. Nein, dies ist ein kleiner Würfel, und es wird viele solcher Würfel geben.Einige Anwendungen lassen sich im Allgemeinen nur schwer auf Kubernetes ausführen - und es ist besser, sie nicht auszuführen. Auch sehr schwere und große Konfigurationsdateien und in Konzepten über Kubernetes sind sie noch komplizierter. Alle aktuellen Lösungen sind roh.All diese Nachteile sind natürlich widerlich.Kompromisse und ein schwieriger Übergang führen zu einem negativen Image von Kubernetes, und ich weiß nicht, wie ich damit umgehen soll. Wir konnten nicht viel überwinden, es gibt Menschen, die die ganze Bewegung hassen, ihre Vorteile nicht wollen und nicht verstehen.Um Minikube ausführen zu können, muss Ihr System hart arbeiten, damit alles funktioniert. Wie Sie sehen, gibt es viele Nachteile, und diejenigen, die nicht mit Kubernetes arbeiten möchten, haben ihre eigenen Gründe. Wenn Sie nichts über die Profis hören möchten, schließen Sie Ihre Augen und Ohren, da diese noch weiter gehen. Das erste Plus ist, dass Anfänger mit der Zeit weniger lernen müssen. Es kommt oft vor, dass ein Neuling, wenn er in das System kommt, anfängt, sich die Haare auszureißen, weil er in den ersten 1-2 Monaten versucht, herauszufinden, wie er alles entfesseln kann, wenn das System groß ist und lange lebt, sind viele Jahresringe gewachsen. Kubernetes macht es einfacher.Zweitens macht Kubernetes das nicht selbst, sondern ermöglicht Ihnen einen kurzen Release-Zyklus. Ein Commit erstellte CI, CI erstellte ein Image, wurde automatisch hochgepumpt, Sie drückten einen Knopf und alles ging in Produktion. Dies reduziert die Release-Zeit erheblich.Das Folgende ist die Code-Aufteilung. Unser System und die meisten Ihrer Systeme sammeln Konfigurationen verschiedener Ebenen an einem Ort, dh Sie haben einen Infrastrukturcode, einen Geschäftscode, alle Logiken sind an einem Ort gemischt. In Kubernetes ist dies nicht sofort einsatzbereit. Die Auswahl des richtigen Konzepts hilft, dies im Voraus zu vermeiden.Eine große und sehr aktive Community, die eine Vielzahl von Veränderungen bedeutet. Das meiste, was ich in den letzten zwei Jahren erwähnt habe, ist so stabil geworden, dass es in die Produktion freigegeben werden kann. Vielleicht erschienen einige von ihnen früher, waren aber nicht sehr stabil.Ich halte es für ein großes Plus, dass Sie an einer Stelle sowohl die Anwendungsprotokolle als auch die Protokolle von Kubernetes sehen können, die mit Ihrer Anwendung arbeiten, was von unschätzbarem Wert ist. Und es gibt keinen Zugriff auf Knoten. Wenn wir den Benutzern den Zugriff auf Knoten entzogen haben, wurde dadurch sofort eine große Klasse von Problemen abgeschnitten.
Das erste Plus ist, dass Anfänger mit der Zeit weniger lernen müssen. Es kommt oft vor, dass ein Neuling, wenn er in das System kommt, anfängt, sich die Haare auszureißen, weil er in den ersten 1-2 Monaten versucht, herauszufinden, wie er alles entfesseln kann, wenn das System groß ist und lange lebt, sind viele Jahresringe gewachsen. Kubernetes macht es einfacher.Zweitens macht Kubernetes das nicht selbst, sondern ermöglicht Ihnen einen kurzen Release-Zyklus. Ein Commit erstellte CI, CI erstellte ein Image, wurde automatisch hochgepumpt, Sie drückten einen Knopf und alles ging in Produktion. Dies reduziert die Release-Zeit erheblich.Das Folgende ist die Code-Aufteilung. Unser System und die meisten Ihrer Systeme sammeln Konfigurationen verschiedener Ebenen an einem Ort, dh Sie haben einen Infrastrukturcode, einen Geschäftscode, alle Logiken sind an einem Ort gemischt. In Kubernetes ist dies nicht sofort einsatzbereit. Die Auswahl des richtigen Konzepts hilft, dies im Voraus zu vermeiden.Eine große und sehr aktive Community, die eine Vielzahl von Veränderungen bedeutet. Das meiste, was ich in den letzten zwei Jahren erwähnt habe, ist so stabil geworden, dass es in die Produktion freigegeben werden kann. Vielleicht erschienen einige von ihnen früher, waren aber nicht sehr stabil.Ich halte es für ein großes Plus, dass Sie an einer Stelle sowohl die Anwendungsprotokolle als auch die Protokolle von Kubernetes sehen können, die mit Ihrer Anwendung arbeiten, was von unschätzbarem Wert ist. Und es gibt keinen Zugriff auf Knoten. Wenn wir den Benutzern den Zugriff auf Knoten entzogen haben, wurde dadurch sofort eine große Klasse von Problemen abgeschnitten. Der zweite Teil der Pluspunkte ist etwas konzeptioneller. Der Großteil der Kubernetes-Community sieht den technologischen Teil. Aber wir haben den konzeptionellen Managementteil gesehen. Nachdem Sie zu Kubernetes gewechselt haben und es richtig eingerichtet ist, wird der Infracommand (oder das Backend - ich weiß nicht, wie Sie es richtig nennen) nicht mehr benötigt, um Anwendungen freizugeben.Der Benutzer möchte die Anwendung entladen, er wird nicht danach fragen, sondern einfach einen neuen Pod starten, dafür gibt es einen Befehl. Das Infrastruktur-Team wird nicht benötigt, um Probleme zu untersuchen. Es reicht aus, sich die Protokolle anzusehen, unsere Entwürfe sind nicht so groß, es gibt eine Liste, anhand derer das Problem sehr leicht zu finden ist. Ja, manchmal ist Unterstützung erforderlich, wenn das Problem in einigen Fällen in Kubernetes auftritt, aber häufiger bei Anwendungen.Wir haben das Fehlerbudget hinzugefügt. Dies ist das folgende Konzept: Jedes Team verfügt über Statistiken darüber, wie viele Probleme in der Produktion auftreten. Wenn es zu viele Probleme gibt, schneidet das Team die Veröffentlichungen, bis es einige Zeit dauert. Dies ist gut, da das Team ernsthaft überwachen wird, dass ihre Veröffentlichungen sehr stabil sind. Benötigen Sie neue Funktionen - bitte freigeben. Willst du um zwei Uhr morgens loslassen - bitte. Wenn Sie nach Veröffentlichungen nur "neun" in SLA haben - tun Sie, was Sie wollen, alles ist stabil, Sie können alles tun. Wenn sich die Situation jedoch verschlechtert, dürfen wir höchstwahrscheinlich nur Korrekturen veröffentlichen.Dies ist sowohl für die Stabilität des Systems als auch für die Stimmung im Team von Vorteil. Wir hören auf, die "Moralpolizei" zu sein, und hindern uns daran, sie spät in der Nacht freizulassen. Tun Sie, was Sie wollen, während Sie ein gutes Budget an Fehlern haben. Dies reduziert den Stress im Unternehmen erheblich.Sie können mich per E-Mail oder Tweet kontaktieren : @gliush .Und am Ende gibt es viele Links für Sie, die Sie herunterladen und alles selbst sehen können:
Der zweite Teil der Pluspunkte ist etwas konzeptioneller. Der Großteil der Kubernetes-Community sieht den technologischen Teil. Aber wir haben den konzeptionellen Managementteil gesehen. Nachdem Sie zu Kubernetes gewechselt haben und es richtig eingerichtet ist, wird der Infracommand (oder das Backend - ich weiß nicht, wie Sie es richtig nennen) nicht mehr benötigt, um Anwendungen freizugeben.Der Benutzer möchte die Anwendung entladen, er wird nicht danach fragen, sondern einfach einen neuen Pod starten, dafür gibt es einen Befehl. Das Infrastruktur-Team wird nicht benötigt, um Probleme zu untersuchen. Es reicht aus, sich die Protokolle anzusehen, unsere Entwürfe sind nicht so groß, es gibt eine Liste, anhand derer das Problem sehr leicht zu finden ist. Ja, manchmal ist Unterstützung erforderlich, wenn das Problem in einigen Fällen in Kubernetes auftritt, aber häufiger bei Anwendungen.Wir haben das Fehlerbudget hinzugefügt. Dies ist das folgende Konzept: Jedes Team verfügt über Statistiken darüber, wie viele Probleme in der Produktion auftreten. Wenn es zu viele Probleme gibt, schneidet das Team die Veröffentlichungen, bis es einige Zeit dauert. Dies ist gut, da das Team ernsthaft überwachen wird, dass ihre Veröffentlichungen sehr stabil sind. Benötigen Sie neue Funktionen - bitte freigeben. Willst du um zwei Uhr morgens loslassen - bitte. Wenn Sie nach Veröffentlichungen nur "neun" in SLA haben - tun Sie, was Sie wollen, alles ist stabil, Sie können alles tun. Wenn sich die Situation jedoch verschlechtert, dürfen wir höchstwahrscheinlich nur Korrekturen veröffentlichen.Dies ist sowohl für die Stabilität des Systems als auch für die Stimmung im Team von Vorteil. Wir hören auf, die "Moralpolizei" zu sein, und hindern uns daran, sie spät in der Nacht freizulassen. Tun Sie, was Sie wollen, während Sie ein gutes Budget an Fehlern haben. Dies reduziert den Stress im Unternehmen erheblich.Sie können mich per E-Mail oder Tweet kontaktieren : @gliush .Und am Ende gibt es viele Links für Sie, die Sie herunterladen und alles selbst sehen können:- Container-Native Networking - Vergleich
- Kontinuierliche Lieferung von Jez Humble, David Farley.
- Container sind keine VMs
- Docker Distribution (Bildregistrierung)
- Kai - Image Registry als Service
- etcd-operator - Manager des etcd-Clusters auf Kubernetes
- Dex - OpenID Connect Identity (OIDC) und OAuth 2.0-Anbieter mit steckbaren Anschlüssen
- awsudo - sudo-ähnliches Dienstprogramm zum Verwalten von AWS-Anmeldeinformationen
- Autoscaling-related components for Kubernetes
- Simon's cat
- Helm: Kubernetes package manager
- Geodesic: framework to create your own cloud platform
- Calico: Configuring IP-in-IP
- Sensu: Open-core monitoring system
- InfluxDB: Scalable datastore for metrics, events, and real-time analytics
- Cernan: Telemetry and logging aggregation server
- Prometheus: Open Source monitoring solution
- Heapster: Compute Resource Usage Analysis and Monitoring of Container Clusters
- Stern: Multi pod and container log tailing for Kubernetes
- Minikube: tool to run Kubernetes locally
- Docker machine driver fox xhyve native OS X Hypervisor
- Drone: Continuous Delivery platform built on Docker, written in Go
- Borg, Omega and Kubernetes
- Container-Native Networking — Comparison
- Bug in minikube when working with xhyve driver.
Minute der Werbung. Wenn Ihnen dieser Bericht von der DevOops- Konferenz gefallen hat , beachten Sie, dass am 14. Oktober die neuen DevOops 2018 in St. Petersburg stattfinden werden. Das Programm enthält viele interessante Dinge. Die Seite hat bereits die ersten Redner und Berichte.