Vorwort
Die hier beschriebene PHP-Trie-Implementierung macht das Wörterbuch bisher zu fett, was dementsprechend eine Weile dauert, bis es in den Speicher geladen ist, was die ziemlich gute Geschwindigkeit seiner Arbeit ausgleicht. Die Suchgeschwindigkeit beträgt ~ 80.000 Wörter pro Sekunde. Das Wörterbuch besteht aus der Liste der Deckspelzen des Wörterbuchs opencorpora.org und enthält 389844 Wörter. In unkomprimierter Form wiegt das Wörterbuch ~ 150 MB und komprimiertes gzip ~ 6 MB. Ziemlich gute Leistungsergebnisse beweisen jedoch, dass Sie in reinem PHP einen voll funktionsfähigen Trie-Präfixbaum erstellen können.
Ich bitte Programmierer im Voraus mit dem Zeug der Literaturkritiker, keine böswilligen Kommentare zu schreiben. Dieser Artikel sollte für Anfänger interessant sein, wie ich selbst. Zu faul zum Lesen, können Sie den Code sofort auf
Github sehen .
Wie alles begann
Seit geraumer Zeit habe ich die Idee, einen morphologischen Analysator für meine PHP-Projekte zu schreiben, der in der Lage ist, schnell morphologische Analysen bestimmter Wörter durchzuführen und Wörter in die gewünschte morphologische Form umzuwandeln.
PHP hat bereits eine ähnliche Bibliothek namens phpmorhy. Es funktioniert ziemlich schnell und ich würde es verwenden und nichts erfinden, aber der darin enthaltene Wörterbuch-Compiler ist als separate Nicht-PHP-Anwendung erstellt, was es mir unmöglich macht, diese Bibliothek zu verwenden. Die Bibliothek selbst basiert auf dem lang erwarteten AOT-Wörterbuch, wodurch ihre Nützlichkeit weiter verringert wird.
Wochen und Monate vergingen, ich las
einen Artikel von Khabrovchanin, dann
einen Artikel von I. Segalovich über einen schnellen morphologischen Algorithmus für eine Suchmaschine, dann eine Reihe verschiedener Artikel.
Nach und nach bin ich gereift, um meinen eigenen
Lunapark mit Blackjack und den Knochen eines morphologischen Analysators zu schreiben. Ich denke: "
Nun, der Fortschritt ist vorangekommen, in PHP können Sie bereits das menschliche Genom analysieren! "
Ich nahm das Wörterbuch opencorpora.org, legte es in MySQL ein und erreichte eine Suchgeschwindigkeit von zweitausend Wörtern pro Sekunde. Ich denke, es ist notwendig, das Wörterbuch in den Speicher zu laden. Und hier stellt sich heraus, dass Sie für ein Wörterbuch von 3 Millionen etwa 3 GB RAM speichern müssen, um reguläre Datenstrukturen in PHP wie ein Array oder ein Objekt verfügbar zu haben. Alle PHP-Trie-Implementierungen, die mir aufgefallen sind, waren nur als Tutorial geeignet, um die Logik der Arbeit zu demonstrieren, da sie selbst auf nativen PHP-Datenspeicherstrukturen aufgebaut waren.
Wörterbuchspeicher und Funktionsprinzip
Wo immer ich in der Lage war, den Trie-Präfixbaum zu lesen, zu hören oder zu betrachten, wird nicht genau erklärt, wie die Daten im Speicher gespeichert werden. Hier haben wir den Knoten, und hier sind seine Erben, und hier ist die Flagge des Wortendes, die nicht unter der Haube gezeigt wird. Deshalb musste ich selbst eine Speichermethode erfinden.
Wie Sie wissen, besteht der Trie-Präfixbaum aus Knoten. Ein Knoten speichert ein Präfix, Verknüpfungen zu nachfolgenden Knoten (Nachkommen) und einen Zeiger auf die Tatsache, dass dieses Präfix das letzte in der Kette ist. Der Inder sagt ganz verständlich über Trie
hier .
Die Knoten in meiner Trie-Implementierung sind Datenblöcke mit einer festen Länge von 154 Bytes. Die ersten 6 Bytes (48 Bits) enthalten die Bitmaske der Erben. Die ersten 46 Bits sind das russische Alphabet, Zahlen, Anführungszeichen, Bindestrich und Apostroph. Der Apostroph wurde hinzugefügt, weil im Wörterbuch opencorpora.org das Wort "cote d'ivoire" steht, das das Apostrophzeichen verwendet. Das 47. Bit wird zum Speichern des Wortendflags verwendet. Die folgenden 148 Bytes nach der Bitmaske werden verwendet, um Verweise auf die Erben des Knotens zu speichern. 3 Bytes pro Zeichen (46 * 3 = 148).
Knoten werden als Binärdaten in einer Zeichenfolge gespeichert. Der Zugriff auf den gewünschten Abschnitt erfolgt über die Funktion substr () und das anschließende Entpacken ().
Die Verwendung von Knoten fester Länge vereinfacht den Adressierungsprozess. Um zum gewünschten Knoten zu wechseln, reicht es aus, die Seriennummer (ID) und die Länge des Knotens zu kennen. Wir multiplizieren die Seriennummer mit der Länge und ermitteln den Versatz relativ zum Zeilenanfang - alles ist sehr einfach.
Abb. 1 Speicherschema
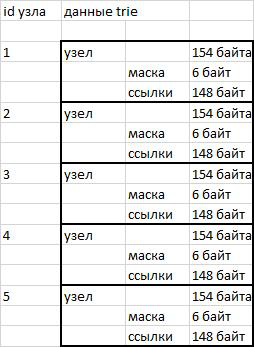
Nachteile
Das verwendete Speicherschema vereinfacht die Adressierung, beansprucht jedoch Speicherplatz. Die Speicherung von 380.000 Wörtern erfordert etwas mehr als eine Million Knoten. 154 Bytes * 1.000.000 Knoten = 146,86 Megabyte. Das heißt, ungefähr 400 Bytes pro Wort. Wenn Sie Wörter in eine einfache Textdatei schreiben, die in utf8 codiert ist, können dieselben 380.000 Wörter in 16 Megabyte passen.
Pläne
Um den Speicher rationaler zu nutzen, möchte ich zu einer variablen Länge von Knoten wechseln. Als Link muss ich dann nicht die Knoten-ID, sondern deren Position in Bytes aufzeichnen. Der Ort der Verbindung zum gewünschten Knoten wird wie folgt bestimmt. Am Beispiel des Wortes "abv."
Der Buchstabe "a" ist der erste im Alphabet, daher ist sein Knoten auch der erste bzw. Versatz 0. Lesen Sie 6 Bytes ab 0.
$str = substr($dic, 0, 6);
Packen Sie die Linie aus:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Wir betrachten die Maske des 2. Bits (Buchstabe "b")
bit_get($mask, 2);
Das Bit ist gesetzt, jetzt zählen wir die Anzahl der erhabenen Bits in der Maske auf 2. Nehmen wir an, das Bit des Buchstabens "a" wird auch an unserem Knoten angehoben, sodass unser Bit des Buchstabens "b" das zweite angehobene Bit ist. Zählversatz zum Lesen der Verbindung
$offset = 6 + 3;
6 Bytes Maske + 3 Bytes, die der erste Link belegt, ergibt 9 Bytes. Wir lesen das gewünschte Stück Schnur.
$str = substr($dic, $offset, 3);
Packen Sie den Link aus:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Gehen Sie zum nächsten Knoten und wiederholen Sie alles erneut. Im letzten Buchstaben prüfen wir, ob 47 Bits in der Maske vorhanden sind. Wenn diese gesetzt ist, enthält unser Versuch ein Suchwort.
Ich hoffe, dass es möglich sein wird, eine Geschwindigkeit von mindestens 50.000 Wörtern pro Sekunde aufrechtzuerhalten.
Danksagung
Ich möchte den Teilnehmern des Forums nulled.cc und php.ru für ihre Hilfe bei bitweisen Funktionen danken.