Diese
Nachricht (+
Forschung ) über die Erfindung des Meme-Generators durch Wissenschaftler der Stanford University veranlasste mich, einen Artikel zu schreiben. In meinem Artikel werde ich versuchen zu zeigen, dass Sie kein Stanford-Wissenschaftler sein müssen, um interessante Dinge mit neuronalen Netzen zu tun. In dem Artikel beschreibe ich, wie wir 2017 ein neuronales Netzwerk auf einem Körper von ungefähr 30.000 Texten trainiert und es gezwungen haben, neue Internet-Memes und Memes (Kommunikationszeichen) im soziologischen Sinne des Wortes zu generieren. Wir beschreiben den von uns verwendeten Algorithmus für maschinelles Lernen sowie die technischen und administrativen Schwierigkeiten, auf die wir gestoßen sind.
Ein kleiner Hintergrund darüber, wie wir auf die Idee eines Neuroautors gekommen sind und woraus sie genau bestand. Im Jahr 2017 haben wir ein Projekt für eine öffentliche Vkontakte-Website erstellt, deren Namen und Screenshots die Habrahabr-Moderatoren nicht veröffentlichen durften, da sie als "Selbst" -PR erwähnt wurden. Public existiert seit 2013 und vereint Posts mit der allgemeinen Idee, Humor durch eine Linie zu zerlegen und die Linien durch das Symbol „@“ zu trennen:
@
@
Die Anzahl der Linien kann variieren, die Darstellung kann beliebig sein. Meistens sind dies Humor oder scharfe soziale Notizen über die weit verbreiteten Tatsachen der Realität. Im Allgemeinen wird dieses Design "buhurt" genannt.
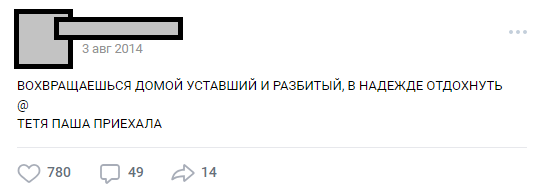 Einer der typischen Buhurts
Einer der typischen BuhurtsIm Laufe der Jahre hat sich die Öffentlichkeit zu einer internen Überlieferung (Charaktere, Handlungen, Orte) entwickelt, und die Anzahl der Beiträge hat 30.000 überschritten. Zum Zeitpunkt ihrer Analyse für die Anforderungen des Projekts betrug die Anzahl der Quellzeilen des Textes mehr als eine halbe Million.
Teil 0. Die Entstehung von Ideen und Teams
Im Zuge der großen Beliebtheit neuronaler Netze lag die Idee, ANN in unseren Texten zu trainieren, etwa sechs Monate in der Luft, wurde jedoch im Dezember 2016 schließlich mit E7su formuliert. Gleichzeitig wurde der Name erfunden („Neurobugurt“). Zu diesem Zeitpunkt bestand das an dem Projekt interessierte Team nur aus drei Personen. Wir waren alle Studenten ohne praktische Erfahrung in Algorithmen und neuronalen Netzen. Schlimmer noch, wir hatten nicht einmal eine einzige geeignete GPU für das Training. Wir hatten nur Begeisterung und Zuversicht, dass diese Geschichte interessant sein könnte.
Teil 1. Die Formulierung der Hypothese und Aufgaben
Unsere Hypothese stellte sich als die Annahme heraus, dass Sie, wenn Sie alle über dreieinhalb Jahre veröffentlichten Texte mischen und das neuronale Netzwerk in diesem Gebäude trainieren, Folgendes erhalten können:
a) kreativer als Menschen
b) lustig
Selbst wenn sich herausstellen sollte, dass die Wörter oder Buchstaben im Buhurt maschinell verwirrt und zufällig angeordnet sind, waren wir der Meinung, dass dies als Fan-Service funktionieren könnte und den Lesern dennoch gefallen würde.
Die Aufgabe wurde erheblich vereinfacht, da das Format der Buhurts im Wesentlichen textuell ist. Wir mussten uns also nicht auf Bildverarbeitung und andere komplexe Dinge einlassen. Eine weitere gute Nachricht war, dass der gesamte Textkörper sehr ähnlich ist. Dies ermöglichte es, zumindest in den frühen Stadien kein verstärktes Lernen einzusetzen. Gleichzeitig haben wir klar verstanden, dass es nicht so einfach ist, einen neuronalen Netzwerkschreiber mit mehr als einmal lesbarer Ausgabe zu erstellen. Das Risiko, ein Monster zur Welt zu bringen, das zufällig Buchstaben schleudert, war sehr groß.
Teil 2. Vorbereitung des Textkörpers
Es wird angenommen, dass die Vorbereitungsphase sehr lange dauern kann, da sie mit der Erfassung und Bereinigung von Daten verbunden ist. In unserem Fall stellte sich heraus, dass es ziemlich kurz war: Es wurde ein kleiner
Parser geschrieben, der ungefähr 30.000 Posts aus der Community-Wand
herauspumpte und sie in eine
txt-Datei legte .
Wir haben die Daten vor dem ersten Training nicht gelöscht. In Zukunft war dies ein grausamer Witz für uns, da wir aufgrund des Fehlers, der sich zu diesem Zeitpunkt eingeschlichen hatte, die Ergebnisse lange Zeit nicht in lesbare Form bringen konnten. Aber dazu später mehr.
 Bildschirmdatei mit Burgern
Bildschirmdatei mit BurgernTeil 3. Ankündigung, Verfeinerung der Hypothese, Wahl des Algorithmus
Wir haben eine zugängliche Ressource verwendet - eine große Anzahl öffentlicher Abonnenten. Die Annahme war, dass es unter 300.000 Lesern mehrere Enthusiasten gibt, die neuronale Netze auf einem ausreichenden Niveau besitzen, um die Wissenslücken unseres Teams zu schließen. Wir gingen von der Idee aus, den Wettbewerb umfassend anzukündigen und Enthusiasten des maschinellen Lernens für die Diskussion des formulierten Problems zu gewinnen. Nachdem wir die Texte geschrieben hatten, erzählten wir den Leuten von unserer Idee und hofften auf eine Antwort.
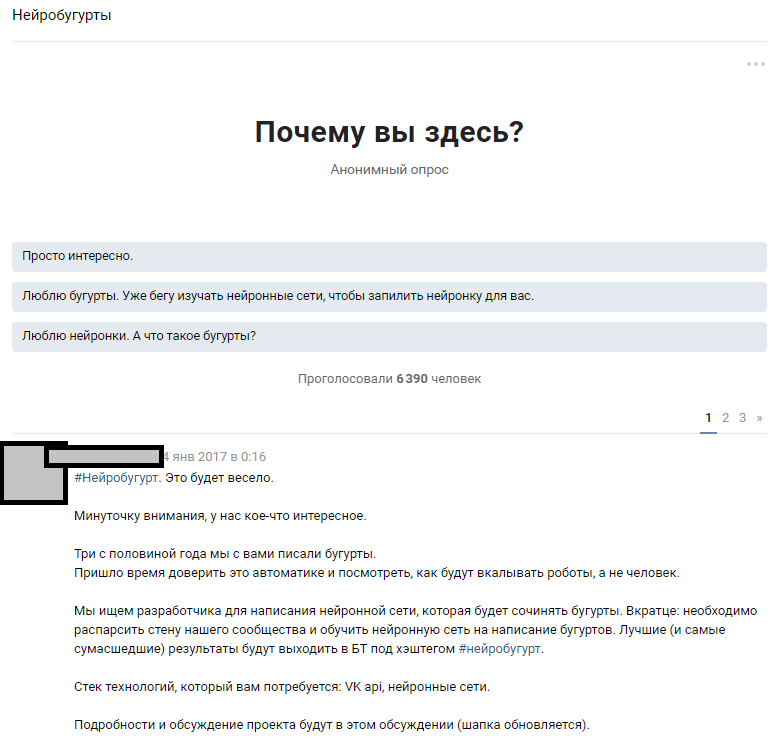 Ankündigung einer thematischen Diskussion
Ankündigung einer thematischen DiskussionDie Reaktion der Menschen hat unsere wildesten Erwartungen übertroffen. Die Diskussion über die Tatsache, dass wir ein neuronales Netzwerk trainieren werden, verbreitete den Holivar um fast 1000 Kommentare. Die meisten Leser verblassten einfach und versuchten sich vorzustellen, wie das Ergebnis aussehen würde. Ungefähr 6.000 Menschen schauten in die thematische Diskussion ein, und mehr als 50 interessierte Amateure hinterließen Kommentare, für die wir einen
Testsatz von
814 Buhurt-Linien für die Durchführung von ersten Tests und Schulungen gaben. Jede interessierte Person könnte einen Datensatz nehmen und den für sie interessantesten Algorithmus lernen und dann mit uns und anderen Enthusiasten diskutieren. Wir haben im Voraus angekündigt, dass wir weiterhin mit den Teilnehmern zusammenarbeiten werden, deren Ergebnisse am besten lesbar sind.
Die Arbeit begann: Jemand baute stillschweigend einen Generator an Markov-Ketten zusammen, jemand versuchte verschiedene Implementierungen mit einem Github und die meisten wurden in der Diskussion einfach verrückt und überzeugten uns mit Schaum im Mund, dass nichts daraus werden würde. Damit begann der technische Teil des Projekts.
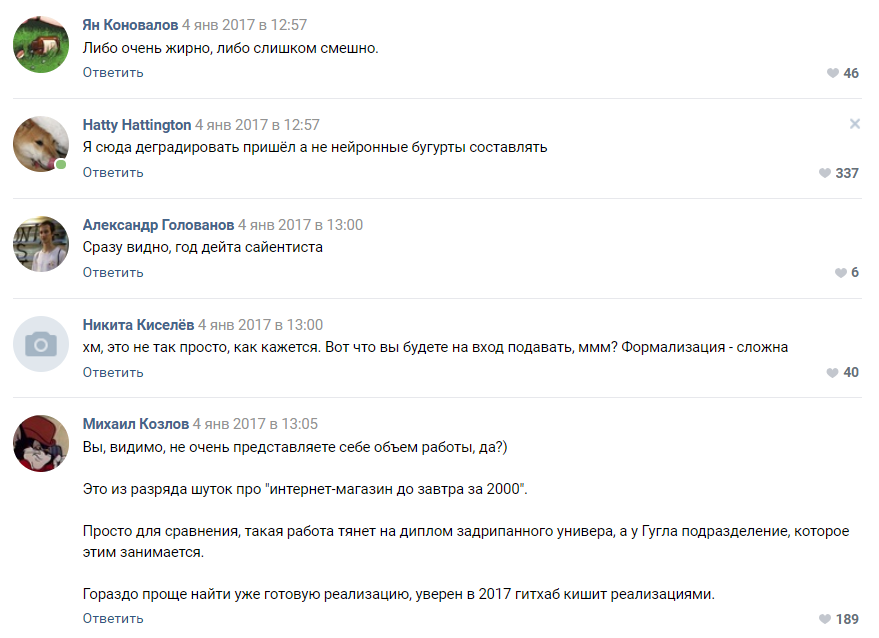
Einige Vorschläge von Enthusiasten
Die Leute boten Dutzende von Optionen für die Implementierung an:
- Markov-Ketten.
- Finden Sie eine vorgefertigte Implementierung von etwas ähnlichem wie GitHub und trainieren Sie es.
- Ein in Pascal geschriebener Zufallsgenerator.
- Holen Sie sich einen literarischen Neger, der zufälligen Unsinn schreibt, und wir werden dies als neuronale Netzwerkausgabe ausgeben.
 Bewertung der Komplexität des Projekts von einem der Abonnenten
Bewertung der Komplexität des Projekts von einem der AbonnentenDie meisten Kommentatoren waren sich einig, dass unser Projekt zum Scheitern verurteilt ist und wir nicht einmal das Prototypenstadium erreichen werden. Wie wir später verstanden haben, neigen die Menschen immer noch dazu, neuronale Netze als eine Art schwarze Magie wahrzunehmen, die im „Kopf von Zuckerberg“ und in geheimen Abteilungen von Google vorkommt.
Teil 4. Algorithmusauswahl, Training und Teamerweiterung
Nach einiger Zeit begann die Kampagne, die wir für Crowdsourcing-Ideen für den Algorithmus gestartet hatten, erste Früchte zu tragen. Wir haben ungefähr 30 funktionierende Prototypen, von denen die meisten völlig unlesbaren Unsinn gaben.
Zu diesem Zeitpunkt stießen wir zunächst auf eine Demotivation des Teams. Alle Ergebnisse waren buhurts sehr schwach ähnlich und stellten am häufigsten Abrakadabra aus Buchstaben und Symbolen dar. Die Arbeit von Dutzenden von Enthusiasten ging zu Staub und dies demotivierte sowohl sie als auch uns.
Der pyTorch-basierte Algorithmus zeigte sich besser als andere. Es wurde beschlossen, diese Implementierung und den LSTM-Algorithmus als Grundlage zu nehmen. Wir haben den Abonnenten, der es vorgeschlagen hat, als Gewinner erkannt und gemeinsam mit ihm an der Verbesserung des Algorithmus gearbeitet. Unser verteiltes Team ist auf vier Personen angewachsen. Die lustige Tatsache hier ist, dass der
Gewinner des Wettbewerbs , wie sich herausstellte, erst 16 Jahre alt war. Der Sieg war sein erster wirklicher Preis auf dem Gebiet der Datenwissenschaft.
Für das erste Training wurde ein Cluster von 8 Grafikkarten GXT1080 gemietet.
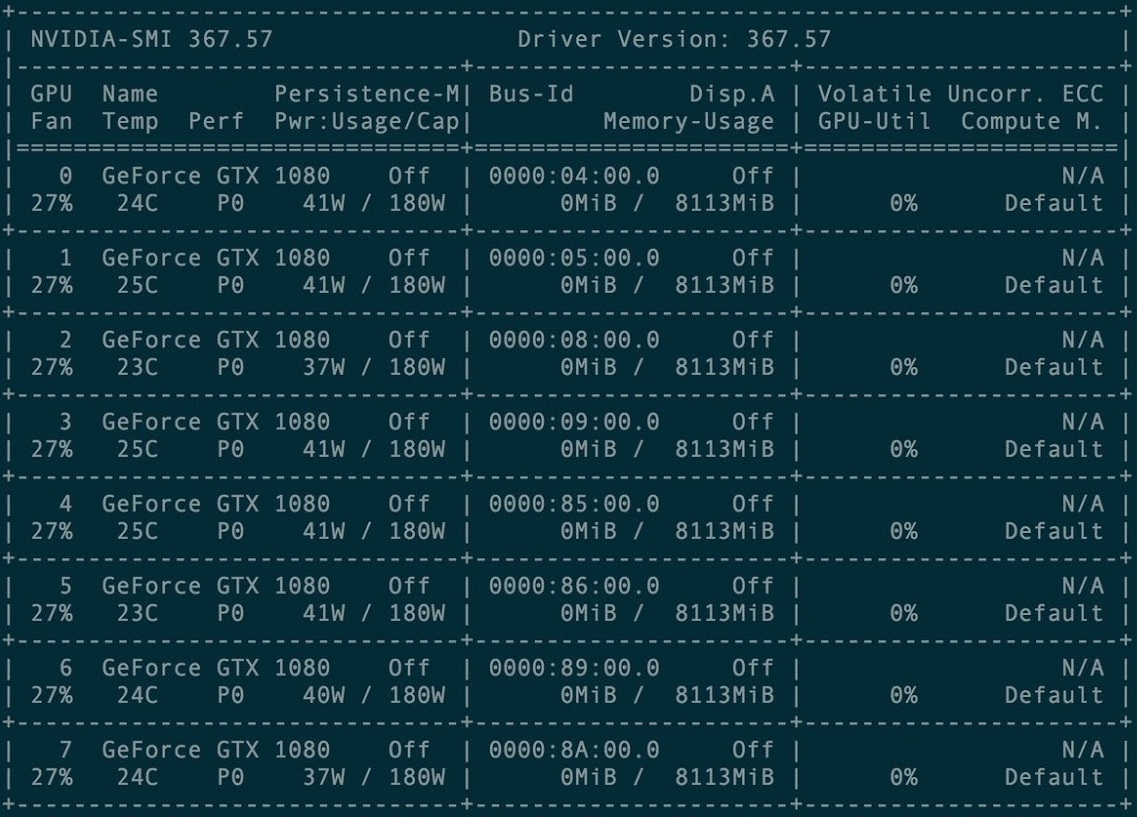 Kartencluster-Verwaltungskonsole
Kartencluster-VerwaltungskonsoleDas Original-Repository und alle Torch-rnn-Projekthandbücher finden Sie hier:
github.com/jcjohnson/torch-rnn . Auf dieser Grundlage haben wir später
unser Repository veröffentlicht , in dem sich unsere Quellen, ReadMe für die Installation, sowie die fertigen Neurobugurts selbst befinden.
Die ersten Male haben wir mit einer vorkonfigurierten Konfiguration auf einem kostenpflichtigen GPU-Cluster trainiert. Das Einrichten stellte sich als nicht so schwierig heraus - nur Anweisungen des Torch-Entwicklers und Hilfe der Hosting-Administration, die in der Zahlung enthalten ist, reichen aus.
Sehr schnell stießen wir jedoch auf Schwierigkeiten: Jedes Training kostete die GPU-Mietzeit - was bedeutet, dass das Projekt einfach kein Geld enthielt. Aus diesem Grund haben wir von Januar bis Februar 2017 Schulungen in den gekauften Einrichtungen durchgeführt und versucht, die Erzeugung auf unseren lokalen Maschinen zu starten.
Jeder Text ist für das Modelltraining geeignet. Vor dem Training müssen Sie es vorverarbeiten, für das Torch einen speziellen preprocess.py-Algorithmus hat, der Ihre my_data.txt in zwei Dateien konvertiert: HDF5 und JSON:
Das Vorverarbeitungsskript läuft folgendermaßen ab:
python scripts/preprocess.py \ --input_txt my_data.txt \ --output_h5 my_data.h5 \ --output_json my_data.json
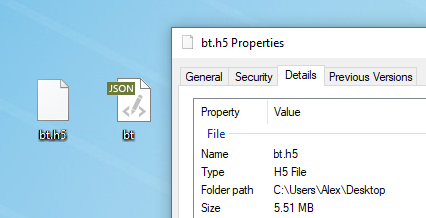 Nach der Vorverarbeitung erscheinen zwei Dateien, in denen das neuronale Netzwerk in Zukunft trainiert wird
Nach der Vorverarbeitung erscheinen zwei Dateien, in denen das neuronale Netzwerk in Zukunft trainiert wirdHier werden die verschiedenen Flags beschrieben, die in der Vorverarbeitungsphase geändert
werden können . Es ist auch möglich,
Torch von Docker aus auszuführen, aber der Autor des Artikels hat es nicht überprüft.
Neuronales Netzwerktraining
Nach der Vorverarbeitung können Sie mit dem Training des Modells fortfahren. In dem Ordner mit HDF5 und JSON müssen Sie das Dienstprogramm th ausführen, das bei korrekter Installation von Torch mit Ihnen angezeigt wurde:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
Das Training nimmt viel Zeit in Anspruch und generiert Dateien in der Form cv / checkpoint_1000.t7, die die „Gewichte“ unseres neuronalen Netzwerks darstellen. Diese Dateien wiegen beeindruckend viele Megabyte und enthalten die Stärke der Verknüpfungen zwischen bestimmten Buchstaben in Ihrem Originaldatensatz.
 Ein neuronales Netzwerk wird oft mit dem menschlichen Gehirn verglichen, aber es scheint mir eine viel klarere Analogie zu einer mathematischen Funktion zu sein, die Parameter am Eingang (Ihren Datensatz) verwendet und das Ergebnis (neue Daten) am Ausgang liefert.
Ein neuronales Netzwerk wird oft mit dem menschlichen Gehirn verglichen, aber es scheint mir eine viel klarere Analogie zu einer mathematischen Funktion zu sein, die Parameter am Eingang (Ihren Datensatz) verwendet und das Ergebnis (neue Daten) am Ausgang liefert.In unserem Fall dauerte jedes Training auf einem Cluster von 8 GTX 1080 in einem Datensatz von 500.000 Zeilen ungefähr ein oder zwei Stunden, und ein ähnliches Training auf einer Art CPU i3-2120 dauerte ungefähr 80-100 Stunden. Bei längerem Training begann sich das neuronale Netzwerk starr neu zu trainieren - die Symbole wiederholten sich zu oft und fielen in lange Zyklen von Präpositionen, Konjunktionen und einleitenden Wörtern.
Es ist praktisch, dass Sie die Häufigkeit der Checkpoints auswählen können. Während eines Trainings erhalten Sie sofort viele Modelle: vom am wenigsten trainierten (checkpoint_1000) bis zum umgeschulten (checkpoint_1000000). Nur genug Platz wäre genug.
Neue Texterzeugung
Nachdem Sie mindestens eine vorgefertigte Datei mit Gewichten erhalten haben (Prüfpunkt _ *******), können Sie mit der nächsten und interessantesten Phase fortfahren: Beginnen Sie mit der Generierung von Texten. Für uns war es ein echter Moment der Wahrheit, denn zum ersten Mal haben wir ein greifbares Ergebnis erzielt - einen Bugurt, der von einer Maschine geschrieben wurde.
Zu diesem Zeitpunkt haben wir die Verwendung des Clusters endgültig eingestellt und alle Generationen wurden auf unseren Maschinen mit geringem Stromverbrauch ausgeführt. Beim Versuch, lokal zu starten, ist es uns jedoch nicht gelungen, die Anweisungen zu befolgen und Torch zu installieren. Das erste Hindernis war der Einsatz virtueller Maschinen. Unter virtuellem Ubuntu 16 hebt der Stick nicht ab - vergessen Sie es. StackOverflow kam oft zur Rettung, aber einige Fehler waren so trivial, dass die Antwort nur schwer zu finden war.
Die Installation von Torch auf einem lokalen Computer hat das Projekt für ein paar Wochen blockiert: Wir haben alle Arten von Fehlern bei der Installation zahlreicher erforderlicher Pakete festgestellt, wir hatten auch Probleme mit der Virtualisierung (virtualenv .env) und haben sie schließlich nicht verwendet. Mehrmals wurde der Stand auf das Niveau von sudo rm -rf abgerissen und einfach wieder installiert.
Mit der resultierenden Datei mit Gewichten konnten wir beginnen, Texte auf unserem lokalen Computer zu generieren:
 Eine der ersten Schlussfolgerungen
Eine der ersten SchlussfolgerungenTeil 5. Texte löschen
Eine weitere offensichtliche Schwierigkeit bestand darin, dass das Thema der Beiträge sehr unterschiedlich ist und unser Algorithmus keine Unterteilung beinhaltet und alle 500.000 Zeilen als einen einzigen Text betrachtet. Wir haben verschiedene Optionen für das Clustering des Datensatzes in Betracht gezogen und waren sogar bereit, den Textkörper manuell nach Themen- oder Platzierungs-Tags in mehreren tausend Buhurts aufzuteilen (hierfür war eine notwendige Personalressource erforderlich), hatten jedoch beim Erlernen von LSTM ständig technische Schwierigkeiten beim Einreichen von Clustern. Eine Änderung des Algorithmus und eine erneute Durchführung des Wettbewerbs schienen im Hinblick auf das Timing des Projekts und die Motivation der Teilnehmer nicht die sinnvollste Idee zu sein.
Es schien, als wären wir in einer Sackgasse - wir konnten keine Buhurts gruppieren, und das Training an einem einzigen riesigen Datensatz führte zu zweifelhaften Ergebnissen. Ich wollte keinen Schritt zurücktreten und den fast rasanten Algorithmus und die Implementierung ändern - das Projekt könnte einfach ins Koma fallen. Das Team hatte verzweifelt nicht genug Wissen, um die Situation normal zu lösen, aber der gute alte KMU-KAL-OCHK-A kam zur Rettung. Die endgültige Lösung für die
Krücke erwies sich als genial einfach: Trennen Sie im ursprünglichen Datensatz die vorhandenen Buhurts mit leeren Zeilen voneinander und trainieren Sie LSTM erneut.
Wir haben die Beats nach jedem Buhurt in 10 vertikalen Räumen angeordnet, das Training wiederholt und während der Generierung eine Grenze für das Ausgabevolumen von 500 Zeichen festgelegt (die durchschnittliche Länge eines Buhurt-Plots im Originaldatensatz).
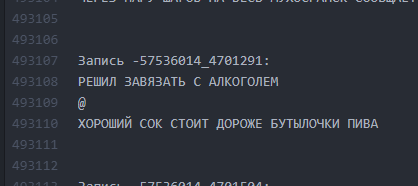 Wie es war. Die Intervalle zwischen den Texten sind minimal.
Wie es war. Die Intervalle zwischen den Texten sind minimal.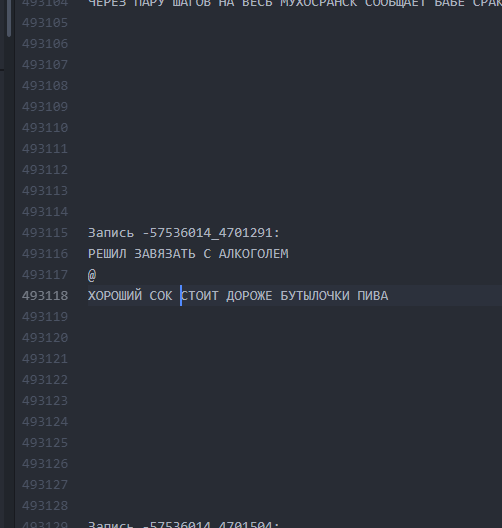 Wie ist es geworden? Intervalle von 10 Zeilen lassen LSTM „verstehen“, dass ein Bogurt vorbei ist und ein anderer begonnen hat.
Wie ist es geworden? Intervalle von 10 Zeilen lassen LSTM „verstehen“, dass ein Bogurt vorbei ist und ein anderer begonnen hat.Auf diese Weise konnte erreicht werden, dass etwa 60% aller erzeugten Buhurts von Anfang bis Ende eine lesbare (wenn auch oft sehr wahnhafte) Darstellung über die gesamte Länge des Buhurts aufwiesen. Die Länge einer Parzelle betrug durchschnittlich 9 bis 13 Linien.
Teil 6. Umschulung
Nachdem wir die Wirtschaftlichkeit des Projekts geschätzt hatten, beschlossen wir, kein Geld mehr für die Anmietung eines Clusters auszugeben, sondern in den Kauf eigener Karten zu investieren. Die Lernzeit würde sich erhöhen, aber wenn wir einmal eine Karte gekauft haben, können wir ständig neue Buurts generieren. Gleichzeitig war es oft nicht mehr nötig, Schulungen durchzuführen.
 Kampfeinstellungen auf dem lokalen Computer
Kampfeinstellungen auf dem lokalen ComputerTeil 7. Ergebnisse ausgleichen
Von März bis April 2017 haben wir das neuronale Netz neu trainiert und dabei die Temperaturparameter und die Anzahl der Trainingszeiten angegeben. Infolgedessen hat sich die Qualität der Ausgabe leicht erhöht.
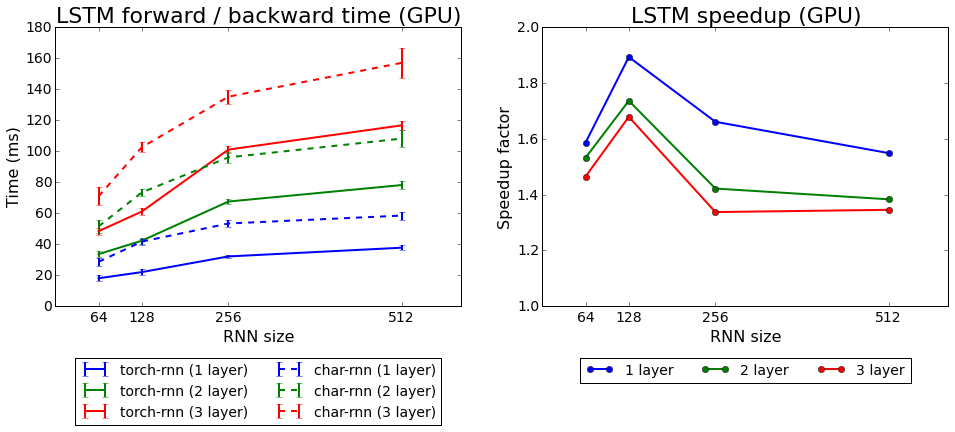 Fackel-Lerngeschwindigkeit im Vergleich zu Charakter
Fackel-Lerngeschwindigkeit im Vergleich zu CharakterWir haben beide mit Torch gelieferten Algorithmen getestet: rnn und LSTM. Der zweite erwies sich als besser.
Teil 8. Was haben wir erreicht?
Der erste Neurobugurt wurde am 17. Januar 2017 veröffentlicht - unmittelbar nach dem Training im Cluster - und am ersten Tag wurden mehr als 1000 Kommentare gesammelt.
 Einer der ersten Neurobugurts
Einer der ersten NeurobugurtsNeurobugurts erreichten das Publikum so gut, dass sie zu einer separaten Sektion wurden, die das ganze Jahr über unter dem Hashtag # neurobugurt herauskam und Abonnenten amüsierte. Insgesamt haben wir 2017 und Anfang 2018 mehr als
18.000 Neurobugurts mit durchschnittlich jeweils 500 Zeichen generiert. Darüber hinaus erschien eine ganze Bewegung öffentlicher Parodien, deren Teilnehmer Neurobuguren darstellten und Phrasen an bestimmten Stellen zufällig neu anordneten.

Teil 9. Anstelle einer Schlussfolgerung
Mit diesem Artikel wollte ich zeigen, dass diese Trauer kein Problem ist, auch wenn Sie keine Erfahrung mit neuronalen Netzen haben. Sie müssen nicht bei Stanford arbeiten, um einfache, aber interessante Dinge mit neuronalen Netzen zu tun. Alle Teilnehmer an unserem Projekt waren normale Studenten mit ihren aktuellen Aufgaben, Diplomen und Arbeiten, aber die gemeinsame Sache ermöglichte es uns, das Projekt ins Finale zu bringen. Dank der durchdachten Idee, Planung und Energie der Teilnehmer konnten wir die ersten vernünftigen Ergebnisse in weniger als einem Monat nach der endgültigen Formulierung der Idee erzielen (der größte Teil der technischen und organisatorischen Arbeit fiel in die Winterferien 2017).
 Über 18.000 maschinengenerierte Buhurts
Über 18.000 maschinengenerierte BuhurtsIch hoffe, dieser Artikel hilft jemandem, sein eigenes ehrgeiziges Projekt mit neuronalen Netzen zu planen. Ich bitte nicht streng zu urteilen, da dies mein erster Artikel über Habré ist. Wenn Sie, wie ich, ein ML-Enthusiast sind, lassen Sie uns
Freunde sein .