Vor einiger Zeit sagte einer meiner Kollegen, dass der Platz im DC knapp wird, es keinen Platz für den Server gibt und die Last wächst und es nicht klar ist, was zu tun ist, und dass Sie wahrscheinlich alle verfügbaren Server auf leistungsfähigere Server umstellen müssen.
Zu dieser Zeit war ich mit der Erstellung optimaler Zeitpläne beschäftigt und dachte - aber was ist, wenn wir Optimierungsalgorithmen anwenden, um die Servernutzung im DC zu erhöhen? Von hier aus wurde das Projekt geboren, über das ich schreiben möchte.
Für fortgeschrittene Benutzer sage ich sofort, dass wir in diesem Artikel über das Verpacken von Behältern sprechen werden. Für den Rest, der lernen möchte, wie mit relativ einfachen Berechnungen bis zu 30% der Serverressourcen eingespart werden können, ist cat willkommen.
Wir haben also einen DC mit ungefähr 100 Servern, auf denen ungefähr 7.000 virtuelle Maschinen gehostet werden. Was sich in den virtuellen Maschinen befindet - wir wissen es nicht und sollten es nicht wissen. Es ist erforderlich, virtuelle Maschinen auf Servern zu platzieren, um SLA durchzuführen und gleichzeitig die Mindestanzahl von Servern zu verwenden.
Wir wissen:
- Serverliste
- Anzahl der Ressourcen auf jedem Server (CPU-Zeit, CPU-Kerne, RAM, Festplatte, Festplatten-Io, Netzwerk-Io).
- Liste der virtuellen Maschinen (VM)
- Die Menge der von jeder virtuellen Maschine verbrauchten Ressourcen (CPU-Zeit, CPU-Kerne, RAM, Festplatte, Festplatten-Io, Netzwerk-Io).
- Ressourcenverbrauch durch das Hostsystem auf den Servern.
Wir müssen virtuelle Maschinen auf die Server verteilen, damit für jede der Ressourcen auf jedem Server die verfügbare Menge der Ressource nicht überschritten wird, und gleichzeitig die Mindestanzahl von Servern verwenden.
Diese Aufgabe wird in der wissenschaftlichen Literatur als Müllverpackungsproblem bezeichnet (wie wird es auf Russisch sein?). In einfachen Worten ist dies eine Aufgabe, wie kleine Kisten beliebiger Größe in große Kisten geschoben werden können und gleichzeitig die Mindestanzahl großer Kisten verwendet wird. Das in der Mathematik bekannte Problem NP-complete wird nur durch eine umfassende Suche präzise gelöst, deren Kosten kombinatorisch steigen.
Das folgende Bild zeigt die Essenz des Bin-Packing-Algorithmus für den eindimensionalen Fall:
 Abb. 1. Darstellung des Problems der Behälterverpackung, nicht optimale Platzierung
Abb. 1. Darstellung des Problems der Behälterverpackung, nicht optimale PlatzierungIn der ersten Abbildung sind die Gegenstände irgendwie auf die Körbe verteilt und 3 Körbe werden verwendet, um sie zu platzieren.
 Abb. 2. Darstellung des Problems der Behälterverpackung, optimale Platzierung
Abb. 2. Darstellung des Problems der Behälterverpackung, optimale PlatzierungDas zweite Bild zeigt die optimale Verteilung, für die Sie nur 2 Körbe benötigen.
Die Standardformulierung des Algorithmus zum Verpacken von Behältern geht auch davon aus, dass alle Körbe gleich sind. Unsere Server sind nicht gleich, da sie zu unterschiedlichen Zeiten gekauft wurden und ihre Konfiguration unterschiedlich ist - unterschiedliche Anzahl von Prozessorkernen, Speicher, Festplatte, unterschiedliche Prozessorleistung.
Eine suboptimale Lösung kann unter Verwendung von Heuristiken, genetischen Algorithmen, Monte-Carlo-Baumsuche und tiefen neuronalen Netzen erhalten werden. Wir haben uns für den heuristischen BestFit-Algorithmus entschieden, der zu einer Lösung konvergiert, die nicht mehr als 1,7-mal schlechter als die optimale ist, sowie für einige Variationen des genetischen Algorithmus. Im Folgenden werde ich die Ergebnisse ihrer Anwendung geben.
Lassen Sie uns zunächst diskutieren, was mit zeitvariablen Metriken wie CPU-Auslastung, Festplatten-Io und Netzwerk-Io zu tun ist. Am einfachsten ist es, die variable Metrik durch eine Konstante zu ersetzen. Aber wie wählt man den Wert dieser Konstante? Wir haben den Maximalwert der Metrik für einen charakteristischen Zeitraum verwendet (zuvor Ausreißer der Werte geglättet). Die Woche stellte sich in unserem Fall als charakteristischer Zeitraum heraus, da die Hauptsaisonalität der Ladung mit Arbeitstagen und freien Tagen verbunden war.
In diesem Modell wird jeder virtuellen Maschine ein Ressourcenstreifen mit der Größe des maximal verbrauchten Ressourcenwerts zugewiesen, und jede VM wird durch die Konstanten maximale CPU-Auslastung, RAM, Festplatte, maximale Festplatten-Io, maximale Netzwerk-Io beschrieben.
Als Nächstes verwenden wir den Algorithmus zur Berechnung der optimalen Packung und erhalten eine Karte des Standorts der VM auf physischen Servern.
Die Praxis zeigt, dass der Server überlastet wird, wenn Sie nicht für jede Ressource auf dem Server einen bestimmten Spielraum lassen. Wenn die VM dicht zugewiesen ist, wird sie überlastet. Für die CPU-Auslastung belassen wir daher einen Spielraum von 30%, für RAM 20%, für Festplatte io - 20% und für Netzwerk io - 20%. Diese Grenzwerte werden empirisch ausgewählt.
Wir haben auch verschiedene Arten von Festplatten (schnelle SSDs und langsame billige Festplatten). Für jede Art von Festplatte werden Festplatten- und Festplatten-Io-Metriken separat verwendet, sodass das endgültige Modell etwas komplizierter wird und mehr Dimensionen aufweist.
Das Ergebnis der Optimierung der VM-Platzierung ist in der folgenden Abbildung dargestellt:
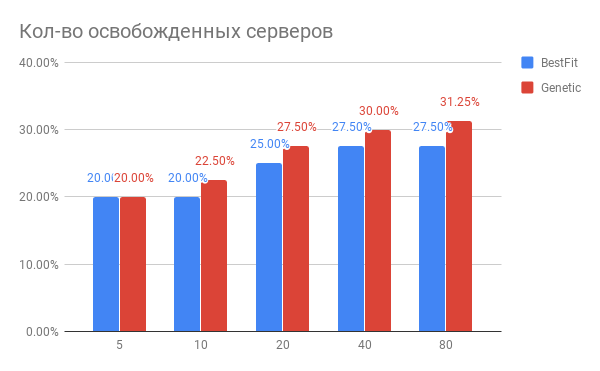 Abb. 3. Das Ergebnis der Optimierung der Platzierung von VMs auf Servern
Abb. 3. Das Ergebnis der Optimierung der Platzierung von VMs auf ServernHorizontal - die Anzahl der optimierten Server, vertikal - die Anzahl der freigegebenen Server für die BestFit-Heuristik und für den genetischen Algorithmus.
Welche Schlussfolgerungen können aus dem Diagramm gezogen werden?
- Für aktuelle Aufgaben können Sie 20 bis 30% weniger Server verwenden.
- Je mehr Server Sie gleichzeitig optimieren, desto mehr gewinnen Sie in%. Bei einer Anzahl von Servern ab 40 tritt eine Sättigung auf.
- Der genetische Algorithmus ist der heuristischen BestFit etwas überlegen. Wenn wir unsere Ergebnisse weiter verbessern wollen, werden wir in diese Richtung graben.
Welche anderen Probleme sind in der Praxis aufgetreten?
- Wenn Sie etwa 100 Server mit 7.000 virtuellen Maschinen aufrütteln möchten, ist das Migrationsvolumen sehr hoch, sodass die gesamte Idee nicht realisierbar ist. Wenn Sie jedoch mit Gruppen von 20 bis 40 Servern nacheinander arbeiten, ist der Effekt fast gleich, aber die Anzahl der Migrationen ist um ein Vielfaches geringer. Und Sie können Ihren DC in Teilen optimieren.
- Wenn Sie Live-Migrationen durchführen müssen, kann es vorkommen, dass die Migration nicht beendet werden kann. Dies bedeutet, dass innerhalb der VM ein intensives Schreiben auf die Festplatte erfolgt und / oder sich der Status des Speichers ändert und der VM-Status zwischen dem alten und dem neuen Replikat keine Zeit zum Synchronisieren hat, bis sich der Status des alten Replikats ändert. In diesem Fall müssen Sie solche VM-Maschinen vordefinieren und als nicht beweglich markieren. Dies erfordert wiederum eine Modifikation der Optimierungsalgorithmen. Was gefällt, ist, dass der Gesamtgewinn praktisch unabhängig von der Anzahl solcher Maschinen ist, wenn nicht mehr als 10-15% der Gesamtzahl der VMs vorhanden sind.
Wie ändert sich die Serverlast nach der Optimierung der VM-Platzierung?
Ok, wir haben die VM-Platzierung optimiert. Vielleicht ist der resultierende neue Zustand in Bezug auf die Zunahme der Last sehr fragil? Vielleicht laufen die Server bis zum Limit und jede Erhöhung der Last wird sie töten?
Wir haben die Auslastung der Serverressourcen vor und nach der Optimierung für einen Zeitraum von 1 Woche verglichen. Was passiert ist, ist in Abbildung 2 dargestellt:
 Abb. 4. Änderung der CPU-Auslastung nach Optimierung der VM-Zuordnung
Abb. 4. Änderung der CPU-Auslastung nach Optimierung der VM-ZuordnungLaut CPU-Auslastung: Die durchschnittliche CPU-Auslastung ist von 10% auf nur 18% gestiegen. Das heißt, Wir haben eine dreifache Marge der CPU-Leistung, während die Server in der sogenannten "grünen" Zone bleiben.
Wie wurde das in Software gemacht?
Wir erfassen die benötigten Metriken in Yandex.ClickHouse (wir haben InfluxDB ausprobiert, aber bei unseren Datenmengen werden Abfragen mit Aggregation zu langsam ausgeführt) mit einer Häufigkeit von 30 Sekunden. Von dort liest die Aufgabe der Berechnung des optimalen Zustands die Metriken, berechnet den maximalen Verbrauch daraus und generiert eine Berechnungsaufgabe, die in die Warteschlange gestellt wird. Sobald die Berechnungsaufgabe abgeschlossen ist, werden Tests ausgeführt, um sicherzustellen, dass das Ergebnis die angegebenen Grenzwerte nicht überschreitet.
Hat das schon jemand gemacht?
Nach den uns bekannten Algorithmen befinden sich ähnliche Algorithmen in VMware vSphere und Nutanix und erscheinen in OpenStack (OpenStack Watcher-Projekt).
Kann man es noch besser machen?
Ja, das kannst du. Im nächsten Artikel werde ich Ihnen erklären, wie Sie virtuelle Maschinen noch dichter packen können, ohne die SLA zu verletzen, und warum dafür Neuronen benötigt werden.