
Im Bereich der Emotionserkennung ist die Stimme nach dem Gesicht die zweitwichtigste Quelle emotionaler Daten. Die Stimme kann durch mehrere Parameter charakterisiert werden. Die Tonhöhe ist eine der Hauptmerkmale dieser Art. Auf dem Gebiet der Akustiktechnologie ist es jedoch korrekter, diesen Parameter als Grundfrequenz zu bezeichnen.
Die Frequenz des Grundtons hängt direkt mit dem zusammen, was wir Intonation nennen. Und Intonation ist zum Beispiel mit den emotional ausdrucksstarken Eigenschaften der Stimme verbunden.
Dennoch ist die Bestimmung der Frequenz des Grundtons keine völlig triviale Aufgabe mit interessanten Nuancen. In diesem Artikel werden wir die Merkmale von Algorithmen für ihre Bestimmung diskutieren und vorhandene Lösungen mit Beispielen für bestimmte Audioaufnahmen vergleichen.
EinführungErinnern wir uns zunächst daran, was im Wesentlichen die Frequenz des Grundtons ist und für welche Aufgaben er möglicherweise benötigt wird.
Die Grundfrequenz , die auch als CHOT, Grundfrequenz oder F0 bezeichnet wird, ist die Frequenz der Stimmbänder, wenn sie stimmhafte Töne aussprechen. Wenn Sie nicht-tonige Töne aussprechen (stimmlos), z. B. flüsternd sprechen oder zischende und pfeifende Töne aussprechen, zögern die Bänder nicht, was bedeutet, dass diese Eigenschaft für sie nicht relevant ist.
* Bitte beachten Sie, dass die Unterteilung in Ton- und Nicht-Ton-Klänge nicht der Unterteilung in Vokale und Konsonanten entspricht.
Die Variabilität der Frequenz des Grundtons ist ziemlich groß und kann nicht nur zwischen Menschen stark variieren (für Männerstimmen mit niedrigerem Durchschnitt beträgt die Frequenz 70-200 Hz und für Frauenstimmen 400 Hz), sondern auch für eine Person, insbesondere bei emotionaler Sprache .
Die Bestimmung der Frequenz des Grundtons wird verwendet, um eine breite Palette von Problemen zu lösen:
- Erkennen von Emotionen, wie wir oben sagten;
- Geschlechtsbestimmung;
- Bei der Lösung des Problems, Audio mit mehreren Stimmen zu segmentieren oder Sprache in Phrasen zu unterteilen;
- In der Medizin zur Bestimmung der pathologischen Eigenschaften der Stimme (z. B. anhand der akustischen Parameter Jitter und Shimmer). Zum Beispiel die Identifizierung von Anzeichen der Parkinson-Krankheit [ 1 ]. Jitter und Shimmer können auch verwendet werden, um Emotionen zu erkennen [ 2 ].
Es gibt jedoch eine Reihe von Schwierigkeiten bei der Bestimmung von F0. Beispielsweise ist es häufig möglich, F0 mit Harmonischen zu verwechseln, was zu sogenannten Tonhöhenverdopplungs- / Tonhöhenhalbierungseffekten führen kann [
3 ]. Und bei Audioaufnahmen mit schlechter Qualität ist F0 ziemlich schwer zu berechnen, da die gewünschte Spitze bei niedrigen Frequenzen fast verschwindet.
Erinnerst du dich übrigens an die Geschichte von
Laurel und Yanny ? Die Unterschiede in den Wörtern, die Menschen beim Anhören derselben Audioaufnahme hören, sind genau auf den Unterschied in der Wahrnehmung F0 zurückzuführen, der von vielen Faktoren beeinflusst wird: dem Alter des Hörers, dem Ermüdungsgrad und dem Wiedergabegerät. Wenn Sie also Aufnahmen in Lautsprechern mit qualitativ hochwertiger Wiedergabe niedriger Frequenzen hören, hören Sie Laurel und in Audiosystemen, in denen niedrige Frequenzen schlecht wiedergegeben werden, Yanny. Der Übergangseffekt ist beispielsweise
hier auf einem Gerät zu sehen. In diesem
Artikel fungiert das neuronale Netzwerk als Zuhörer. In einem anderen
Artikel können Sie lesen, wie das Yanny / Laurel-Phänomen in Bezug auf die Sprachbildung erklärt wird.
Da eine detaillierte Analyse aller Methoden zur Bestimmung von F0 zu umfangreich wäre, ist der Artikel übersichtlicher Natur und kann zur Navigation im Thema beitragen.
Methoden zur Bestimmung von F0Methoden zur Bestimmung von F0 können in drei Kategorien unterteilt werden: basierend auf der Zeitdynamik des Signals oder der Zeitdomäne; basierend auf der Frequenzstruktur oder dem Frequenzbereich sowie kombinierten Methoden. Wir empfehlen Ihnen, sich mit dem Übersichtsartikel zum Thema vertraut zu machen, in dem die angegebenen Methoden zum Extrahieren von F0 detailliert analysiert werden.
Beachten Sie, dass jeder der diskutierten Algorithmen aus drei Hauptschritten besteht:
Vorverarbeitung (Filtern des Signals, Aufteilen in Frames)
Suche nach möglichen Werten von F0 (Kandidaten)
Tracking ist die Wahl der wahrscheinlichsten Flugbahn F0 (da wir für jeden Moment mehrere konkurrierende Kandidaten haben, müssen wir die wahrscheinlichste Spur unter ihnen finden).
ZeitbereichWir skizzieren einige allgemeine Punkte. Vor der Anwendung der Zeitbereichsmethoden wird das Signal vorgefiltert, wobei nur niedrige Frequenzen übrig bleiben. Schwellenwerte werden festgelegt - die minimalen und maximalen Frequenzen, beispielsweise von 75 bis 500 Hz. Die Bestimmung von F0 erfolgt nur für Bereiche mit harmonischer Sprache, da dies für Pausen oder Rauschgeräusche nicht nur bedeutungslos ist, sondern auch Fehler in benachbarten Rahmen verursachen kann, wenn Interpolation und / oder Glättung angewendet werden. Die Rahmenlänge wird so ausgewählt, dass sie mindestens drei Punkte enthält.
Die Hauptmethode, auf deren Grundlage später eine ganze Familie von Algorithmen erschien, ist die Autokorrelation. Der Ansatz ist recht einfach - es ist notwendig, die Autokorrelationsfunktion zu berechnen und ihr erstes Maximum zu nehmen. Es wird die am stärksten ausgeprägte Frequenzkomponente im Signal angezeigt. Was könnte die Schwierigkeit bei der Verwendung der Autokorrelation sein und warum ist es bei weitem nicht immer so, dass das erste Maximum der gewünschten Frequenz entspricht? Selbst unter nahezu idealen Bedingungen bei Aufnahmen hoher Qualität kann das Verfahren aufgrund der komplexen Struktur des Signals falsch sein. Unter realitätsnahen Bedingungen, bei denen unter anderem bei verrauschten Aufnahmen oder Aufnahmen von anfänglich geringer Qualität das Verschwinden des gewünschten Peaks auftreten kann, steigt die Anzahl der Fehler stark an.
Trotz der Fehler ist die Autokorrelationsmethode aufgrund ihrer einfachen Einfachheit und Logik recht praktisch und attraktiv, weshalb sie in vielen Algorithmen, einschließlich YIN, als Grundlage dient. Sogar der Name des Algorithmus verweist auf das Gleichgewicht zwischen der Bequemlichkeit und Ungenauigkeit der Autokorrelationsmethode: "Der Name YIN von" Yin "und" Yang "der orientalischen Philosophie spielt auf das Zusammenspiel von Autokorrelation und Aufhebung an." [
4 ]
Die Macher von YIN versuchten, die Schwächen des Autokorrelationsansatzes zu beheben. Die erste Änderung ist die Verwendung der Funktion Cumulative Mean Normalized Difference, die die Empfindlichkeit gegenüber Amplitudenmodulationen verringern und die Peaks stärker machen soll:
\ begin {Gleichung}
d'_t (\ tau) =
\ begin {Fälle}
1, & \ tau = 0 \\
d_t (\ tau) \ bigg / \ bigg [\ frac {1} {\ tau} \ sum \ limit_ {j = 1} ^ {\ tau} d_t (j) \ bigg], & \ text {else}
\ end {Fälle}
\ end {Gleichung}
YIN versucht auch, Fehler zu vermeiden, die auftreten, wenn die Länge der Fensterfunktion nicht vollständig durch die Schwingungsdauer geteilt wird. Hierzu wird eine parabolische Minimalinterpolation verwendet. Im letzten Schritt der Audiosignalverarbeitung wird die Funktion "Beste lokale Schätzung" ausgeführt, um scharfe Sprünge in den Werten zu verhindern (ob gut oder schlecht - dies ist ein strittiger Punkt).
FrequenzbereichWenn wir über den Frequenzbereich sprechen, tritt die harmonische Struktur des Signals in den Vordergrund, dh das Vorhandensein von Spektralspitzen bei Frequenzen, die ein Vielfaches von F0 sind. Sie können dieses periodische Muster mithilfe der Cepstral-Analyse zu einem klaren Peak „kollabieren“. Cepstrum - Fourier-Transformation des Logarithmus des Leistungsspektrums; Der Cepstral-Peak entspricht der periodischsten Komponente des Spektrums (man kann
hier und
hier darüber lesen).
Hybridmethoden zur Bestimmung von F0Der nächste Algorithmus, der näher untersucht werden sollte, trägt den sprechenden Namen YAAPT - ein weiterer Algorithmus für die Tonhöhenverfolgung - und ist in der Tat hybride, da er sowohl Frequenz- als auch Zeitinformationen verwendet. Eine vollständige Beschreibung finden Sie im
Artikel . Hier beschreiben wir nur die Hauptphasen.
 Abbildung 1. YAAPTalgo-Algorithmusdiagramm ( Link )
Abbildung 1. YAAPTalgo-Algorithmusdiagramm ( Link ) .
YAAPT besteht aus mehreren Hauptschritten, von denen der erste die Vorverarbeitung ist. In diesem Stadium werden die Werte des ursprünglichen Signals quadriert und eine zweite Version des Signals erhalten. Dieser Schritt verfolgt das gleiche Ziel wie die kumulative mittlere normalisierte Differenzfunktion in YIN - Verstärkung und Wiederherstellung von "gestauten" Autokorrelationsspitzen. Beide Versionen des Signals werden gefiltert - normalerweise reichen sie von 50 bis 1500 Hz, manchmal von 50 bis 900 Hz.
Dann wird die Basistrajektorie F0 aus dem Spektrum des umgewandelten Signals berechnet. Kandidaten für F0 werden unter Verwendung der Funktion Spectral Harmonics Correlation (SHC) bestimmt.
\ begin {Gleichung}
SHC (t, f) = \ Summe \ Grenzen_ {f '= - WL / 2} ^ {WL / 2} \ Produkt \ Grenzen_ {r = 1} ^ {NH + 1} S (t, rf + f')
\ end {Gleichung}
Dabei ist S (t, f) das Betragsspektrum für den Rahmen t und die Frequenz f, WL die Fensterlänge in Hz, NH die Anzahl der Harmonischen (die Autoren empfehlen die Verwendung der ersten drei Harmonischen). Die spektrale Leistung wird auch verwendet, um stimmhafte-stimmlose Frames zu bestimmen, wonach die optimalste Trajektorie gesucht wird, und die Möglichkeit der Tonhöhenverdopplung / Tonhöhenhalbierung wird berücksichtigt [
3 , Abschnitt II, C].
Ferner werden Kandidaten für F0 sowohl für das Anfangssignal als auch für das konvertierte Signal bestimmt, und anstelle der Autokorrelationsfunktion wird hier die normalisierte Kreuzkorrelation (NCCF) verwendet.
\ begin {Gleichung}
NCCF (m) = \ frac {\ sum \ begrenzt_ {n = 0} ^ {Nm-1} x (n) * x (n + m)} {\ sqrt {\ sum \ Grenzen_ {n = 0} ^ { Nm-1} x ^ 2 (n) * \ sum \ limit_ {n = 0} ^ {Nm-1} x ^ 2 (n + m)}} \ text {,} \ hspace {0,3 cm} 0 <m <M_ {0}
\ end {Gleichung}
Der nächste Schritt besteht darin, alle möglichen Kandidaten zu bewerten und ihre Signifikanz oder ihr Gewicht (Verdienst) zu berechnen. Das Gewicht der aus dem Audiosignal erhaltenen Kandidaten hängt nicht nur von der Amplitude des NCCF-Peaks ab, sondern auch von ihrer Nähe zur aus dem Spektrum bestimmten Trajektorie F0. Das heißt, der Frequenzbereich wird hinsichtlich der Genauigkeit als grob, aber als stabil angesehen [
3 , Abschnitt II, D].
Dann wird für alle Paare der verbleibenden Kandidaten die Übergangskostenmatrix berechnet - der Übergangspreis, zu dem sie letztendlich die optimale Flugbahn finden [
3 , Abschnitt II, E].
BeispieleJetzt wenden wir alle oben genannten Algorithmen auf bestimmte Audioaufnahmen an. Als Ausgangspunkt werden wir
Praat verwenden , ein Werkzeug, das für viele
Sprachwissenschaftler von grundlegender Bedeutung ist. In Python werden wir uns dann die Implementierung von YIN und YAAPT ansehen und die erhaltenen Ergebnisse vergleichen.
Als Audiomaterial können Sie jedes verfügbare Audio verwenden. Wir haben mehrere Auszüge aus unserer
RAMAS- Datenbank
entnommen - ein multimodaler
Datensatz , der unter Beteiligung von VGIK-Akteuren erstellt wurde. Sie können auch Material aus anderen offenen Datenbanken wie
LibriSpeech oder
RAVDESS verwenden .
Als anschauliches Beispiel haben wir Auszüge aus mehreren Aufnahmen mit neutralen und emotional gefärbten Männer- und Frauenstimmen genommen und aus Gründen der Klarheit zu einer
Aufnahme zusammengefasst . Schauen wir uns unser Signal, sein Spektrogramm, seine Intensität (orange Farbe) und F0 (blaue Farbe) an. In Praat kann dies mit Strg + O (Öffnen - Aus Datei lesen) und dann mit der Schaltfläche Anzeigen und Bearbeiten erfolgen.
 Abbildung 2. Spektrogramm, Intensität (orange Farbe), F0 (blaue Farbe) in Praat.
Abbildung 2. Spektrogramm, Intensität (orange Farbe), F0 (blaue Farbe) in Praat.Das Audio zeigt ziemlich deutlich, dass in der emotionalen Sprache die Tonhöhe sowohl bei Männern als auch bei Frauen zunimmt. Gleichzeitig kann F0 für emotionale männliche Sprache gut mit F0 einer weiblichen Stimme verglichen werden.
TrackingWählen Sie im Praat-Menü die Registerkarte Periodizität analysieren - bis Tonhöhe (ac), dh die Definition von F0 mithilfe der Autokorrelation. Es erscheint ein Fenster zum Einstellen von Parametern, in dem 3 Parameter zum Bestimmen von Kandidaten für F0 und 6 weitere Parameter für den Pfadfinder-Algorithmus festgelegt werden können, der den wahrscheinlichsten Pfad F0 unter allen Kandidaten erstellt.
Viele Parameter (in Praat befindet sich ihre Beschreibung auch auf der Schaltfläche Hilfe)- Stille-Schwelle - Die Schwelle der relativen Amplitude des Signals zur Bestimmung der Stille. Der Standardwert beträgt 0,03.
- Sprachschwelle - das Gewicht des stimmlosen Kandidaten, der Maximalwert ist 1. Je höher dieser Parameter, desto mehr Frames werden als stimmlos definiert, dh ohne Tongeräusche. In diesen Rahmen wird F0 nicht bestimmt. Der Wert dieses Parameters ist der Schwellenwert für Spitzen der Autokorrelationsfunktion. Der Standardwert ist 0,45.
- Oktavkosten - bestimmt, wie viel mehr Gewicht die Hochfrequenzkandidaten im Vergleich zu den Niederfrequenzkandidaten haben. Je höher der Wert, desto mehr wird der Hochfrequenzkandidat bevorzugt. Der Standardwert ist 0,01 pro Oktave.
- Oktavsprungkosten - Mit einer Erhöhung dieses Koeffizienten nimmt die Anzahl der scharfen sprungartigen Übergänge zwischen aufeinanderfolgenden Werten von F0 ab. Der Standardwert ist 0,35.
- Voiced / Unvoiced-Kosten - Durch Erhöhen dieses Koeffizienten wird die Anzahl der Voiced / Unvoiced-Übergänge verringert. Der Standardwert ist 0,14.
- Tonhöhenobergrenze (Hz) - Kandidaten über dieser Frequenz werden nicht berücksichtigt. Der Standardwert ist 600 Hz.
Eine detaillierte Beschreibung des Algorithmus findet sich in
einem Artikel von 1993.
Wie das Ergebnis des Trackers (Pfadfinder) aussieht, können Sie sehen, indem Sie auf OK klicken und dann die resultierende Pitch-Datei anzeigen (Anzeigen & Bearbeiten). Es ist ersichtlich, dass es zusätzlich zu der ausgewählten Flugbahn noch ziemlich signifikante Kandidaten mit einer niedrigeren Frequenz gab.
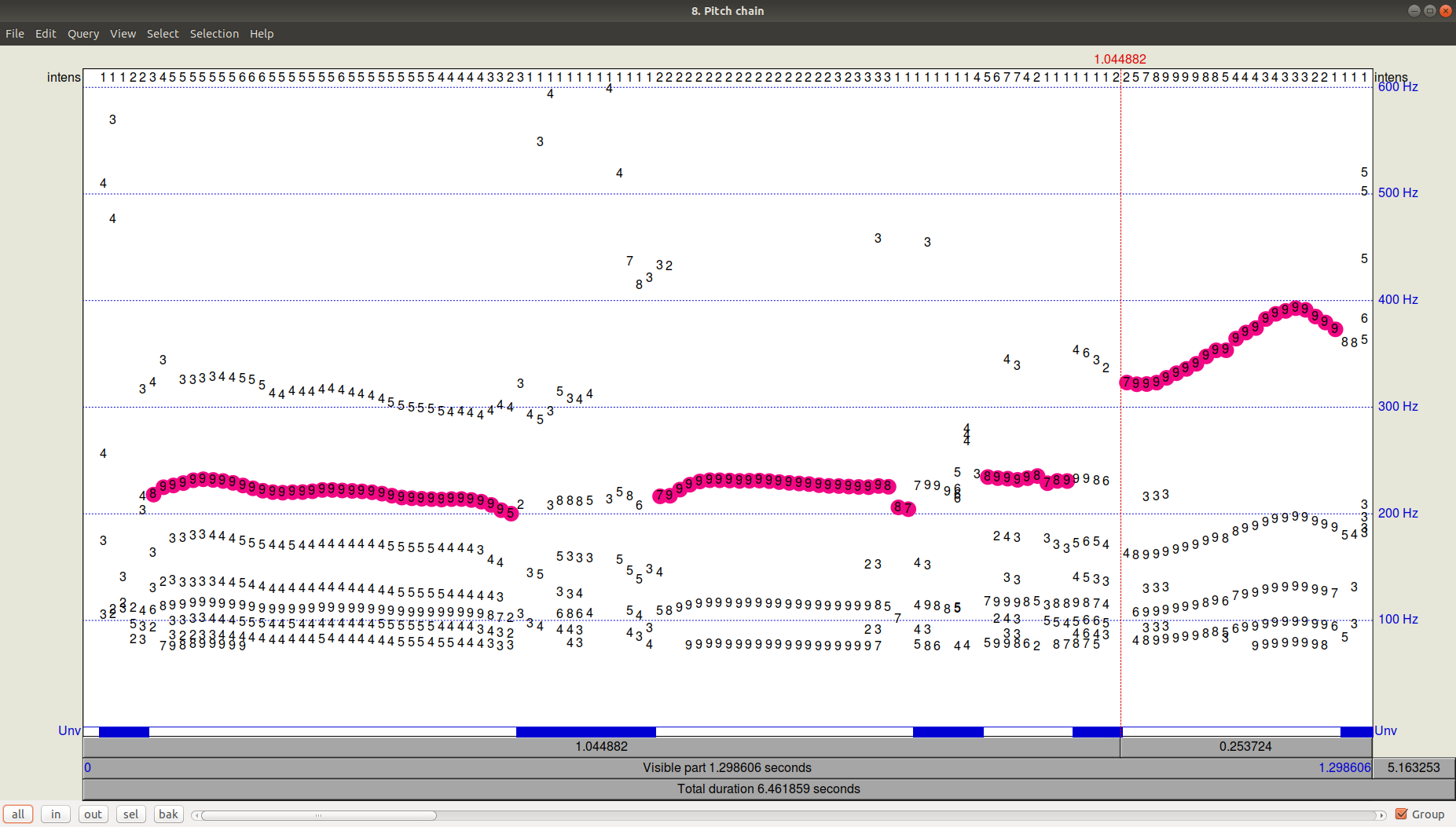 Abbildung 3. PitchPath für die ersten 1,3 Sekunden der Audioaufnahme.Aber was ist mit Python?
Abbildung 3. PitchPath für die ersten 1,3 Sekunden der Audioaufnahme.Aber was ist mit Python?Nehmen wir zwei Bibliotheken, die Pitch Tracking anbieten -
Aubio , in dem der Standardalgorithmus YIN ist, und die Bibliothek
AMFM_decompsition , in der der YAAPT-Algorithmus implementiert ist.
Fügen Sie in der separaten Datei (Datei
PraatPitch.txt )
die F0-Werte von Praat ein (dies kann manuell erfolgen:
Wählen Sie die Audiodatei aus, klicken Sie auf Anzeigen und Bearbeiten, wählen Sie die gesamte Datei aus und wählen Sie im oberen Menü die Liste Pitch-Pitch aus).
Vergleichen Sie nun die Ergebnisse für alle drei Algorithmen (YIN, YAAPT, Praat).
Viel Codeimport amfm_decompy.basic_tools as basic import amfm_decompy.pYAAPT as pYAAPT import matplotlib.pyplot as plt import numpy as np import sys from aubio import source, pitch
 Abbildung 4. Vergleich der Funktionsweise der Algorithmen YIN, YAAPT und Praat.
Abbildung 4. Vergleich der Funktionsweise der Algorithmen YIN, YAAPT und Praat.Wir sehen, dass YIN mit den Standardparametern ziemlich ausgeschlagen ist, eine sehr flache Flugbahn mit Werten unter Praat erhält und die Übergänge zwischen männlichen und weiblichen Stimmen sowie zwischen emotionaler und nicht emotionaler Sprache vollständig verliert.
YAAPT hat einen sehr hohen Ton in der emotionalen weiblichen Sprache gekürzt, aber insgesamt deutlich besser abgeschnitten. Aufgrund seiner spezifischen Funktionen funktioniert YAAPT besser - Sie können natürlich nicht sofort antworten, aber Sie können davon ausgehen, dass die Rolle darin besteht, Kandidaten aus drei Quellen zu erhalten und ihr Gewicht genauer zu berechnen als in YIN.
FazitDa sich die Frage, die Frequenz des Grundtons (F0) in der einen oder anderen Form zu bestimmen, vor fast jedem stellt, der mit Klang arbeitet, gibt es viele Möglichkeiten, ihn zu lösen. Die Frage nach der erforderlichen Genauigkeit und den Merkmalen des Audiomaterials bestimmt jeweils, wie sorgfältig Parameter ausgewählt werden müssen. In einem anderen Fall können Sie sich auf eine Basislösung wie YAAPT beschränken. Wenn wir Praat als Standardalgorithmus für die Sprachverarbeitung verwenden (dennoch verwenden es eine große Anzahl von Forschern), können wir daraus schließen, dass YAAPT in erster Näherung zuverlässiger und genauer als YIN ist, obwohl sich unser Beispiel als kompliziert herausstellte.
Gepostet von
Eva Kazimirova , Neurodata Lab Researcher, Sprachverarbeitungsspezialistin.
Offtop : Gefällt dir der Artikel? Tatsächlich haben wir eine Reihe solcher interessanten Aufgaben in den Bereichen ML, Mathematik und Programmierung, und wir brauchen ein Gehirn. Interessieren Sie sich dafür? Komm zu uns! E-Mail: hr@neurodatalab.com
Referenzen- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Quantitative akustische Messungen zur Charakterisierung von Sprach- und Stimmstörungen bei der frühen unbehandelten Parkinson-Krankheit. Das Journal der Acoustical Society of America, vol. 129, Ausgabe 1 (2011), pp. 350-367. Zugang
- Farrús, M., Hernando, J., Ejarque, P. Jitter und Schimmermessungen für die Sprechererkennung. Tagungsband der Jahreskonferenz der International Speech Communication Association, INTERSPEECH, vol. 2 (2007), pp. 1153-1156. Zugang
- Zahorian, S., Hu, HA. Spektrale / zeitliche Methode zur robusten Grundfrequenzverfolgung. Das Journal der Acoustical Society of America, vol. 123, Ausgabe 6 (2008), pp. 4559-4571. Zugang
- De Cheveigné, A., Kawahara, H. YIN, ein grundlegender Frequenzschätzer für Sprache und Musik. Das Journal der Acoustical Society of America, vol. 111, Ausgabe 4 (2002), pp. 1917-1930. Zugang