
"Muster" im Kontext von C ++ beziehen sich normalerweise auf sehr spezifische Sprachkonstrukte. Es gibt einfache Vorlagen, die das Arbeiten mit demselben Codetyp vereinfachen - dies sind Klassen- und Funktionsvorlagen. Wenn eine Vorlage einen der Parameter für sich hat, kann dies als Vorlagen zweiter Ordnung bezeichnet werden, und sie generieren abhängig von ihren Parametern andere Vorlagen. Was aber, wenn ihre Fähigkeiten nicht ausreichen und es einfacher ist, den Quelltext sofort zu generieren? Viel Quellcode?
Fans von Python- und HTML-Layouts kennen ein Tool (Engine, Bibliothek) für die Arbeit mit Textvorlagen namens
Jinja2 . Bei der Eingabe erhält diese Engine eine Vorlagendatei, in der der Text mit Kontrollstrukturen gemischt werden kann. Die Ausgabe ist sauberer Text, in dem alle Kontrollstrukturen gemäß den von außen (oder von innen) angegebenen Parametern durch Text ersetzt werden. Grob gesagt ist dies so etwas wie ASP-Seiten (oder C ++ - Präprozessor), nur die Auszeichnungssprache ist anders.
Bisher war die Implementierung dieser Engine nur für Python. Jetzt ist es für C ++. Wie und warum es passiert ist und wird im Artikel besprochen.
Warum habe ich das überhaupt aufgegriffen?
In der Tat, warum? Schließlich gibt es dafür Python - eine hervorragende Implementierung, eine Reihe von Funktionen, eine vollständige Spezifikation für die Sprache. Nehmen und verwenden! Ich mag Python nicht - Sie können
Jinja2CppLight oder
inja , teilweise Jinja2-Ports in C ++ verwenden. Am Ende können Sie den C ++ - Port {{
Moustache }} übernehmen. Der Teufel steckt wie immer im Detail. Angenommen, ich benötigte die Funktionalität von Filtern aus Jinja2 und die Funktionen des Extended-Konstrukts, mit denen Sie erweiterbare Vorlagen (und auch Makros und Include, aber dies später) erstellen können. Und keine der genannten Implementierungen unterstützt dies. Könnte ich ohne all das auskommen? Auch eine gute Frage. Überzeugen Sie sich selbst. Ich habe ein
Projekt, dessen Ziel es ist, einen C ++ - zu C ++ - Boilerplate-Codegenerator zu erstellen. Dieser Autogenerator empfängt beispielsweise eine manuell geschriebene Header-Datei mit Strukturen oder Aufzählungen und generiert darauf basierend Funktionen der Serialisierung / Deserialisierung oder beispielsweise der Konvertierung von Aufzählungselementen in Zeichenfolgen (und umgekehrt). Weitere Details zu diesem Dienstprogramm finden Sie in meinen Berichten
hier (deu) oder
hier (rus).
Eine typische Aufgabe, die bei der Arbeit am Dienstprogramm gelöst wird, ist die Erstellung von Header-Dateien, von denen jede einen Header (mit ifdefs und Includes), einen Body mit dem Hauptinhalt und eine Fußzeile enthält. Darüber hinaus sind die generierten Deklarationen, die vom Namespace überfüllt sind, der Hauptinhalt. In der C ++ - Ausführung sieht der Code zum Erstellen einer solchen Header-Datei ungefähr so aus (und das ist noch nicht alles):
Viel C ++ - Codevoid Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
Von hier aus .
Darüber hinaus ändert sich dieser Code von Datei zu Datei kaum. Natürlich können Sie das Clang-Format für die Formatierung verwenden. Dies bricht jedoch nicht den Rest der manuellen Arbeit zum Generieren des Quelltextes ab.
Und dann, in einem schönen Moment, wurde mir klar, dass mein Leben vereinfacht werden sollte. Ich habe die Option, eine vollwertige Skriptsprache zu verwenden, aufgrund der Komplexität der Unterstützung des Endergebnisses nicht in Betracht gezogen. Aber um eine geeignete Template-Engine zu finden - warum nicht? Ich fand es nützlich zu suchen, ich fand es, dann fand ich die Jinja2-Spezifikation und erkannte, dass dies genau das ist, was ich brauche. In Übereinstimmung mit dieser Spezifikation würden Vorlagen zum Generieren von Headern folgendermaßen aussehen:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
Von hier aus .

Es gab nur ein Problem: Keine der gefundenen Engines unterstützte alle benötigten Funktionen. Natürlich hatte jeder einen
schwerwiegenden Standardfehler. Ich dachte ein wenig nach und entschied, dass eine andere Welt durch eine andere Implementierung der Template-Engine nicht schlechter werden würde. Darüber hinaus war die Grundfunktionalität Schätzungen zufolge nicht so schwer zu implementieren. Immerhin gibt es jetzt in C ++ reguläre Ausdrücke!
Und so entstand das
Jinja2Cpp- Projekt. Auf Kosten der Komplexität der Implementierung der grundlegenden (sehr grundlegenden) Funktionalität hätte ich fast geraten. Insgesamt habe ich genau den quadratischen Pi-Koeffizienten übersehen: Ich habe etwas weniger als drei Monate gebraucht, um alles zu schreiben, was ich brauchte. Aber als alles fertig, fertig und in den "Auto Programmer" eingefügt war, wurde mir klar, dass ich es nicht umsonst versucht hatte. Tatsächlich erhielt das Dienstprogramm zur Codegenerierung eine leistungsstarke Skriptsprache in Kombination mit Vorlagen, die ihm völlig neue Entwicklungsmöglichkeiten eröffnete.
NB: Ich hatte eine Idee, Python (oder Lua) zu befestigen. Aber keine der vorhandenen vollwertigen Scripting-Engines löst "out of the box" -Probleme beim Generieren von Text aus Vorlagen. Das heißt, Python müsste immer noch den gleichen Jinja2 schrauben, aber für Lua suchen Sie nach etwas anderem. Warum brauchte ich diesen zusätzlichen Link?
Parser-Implementierung
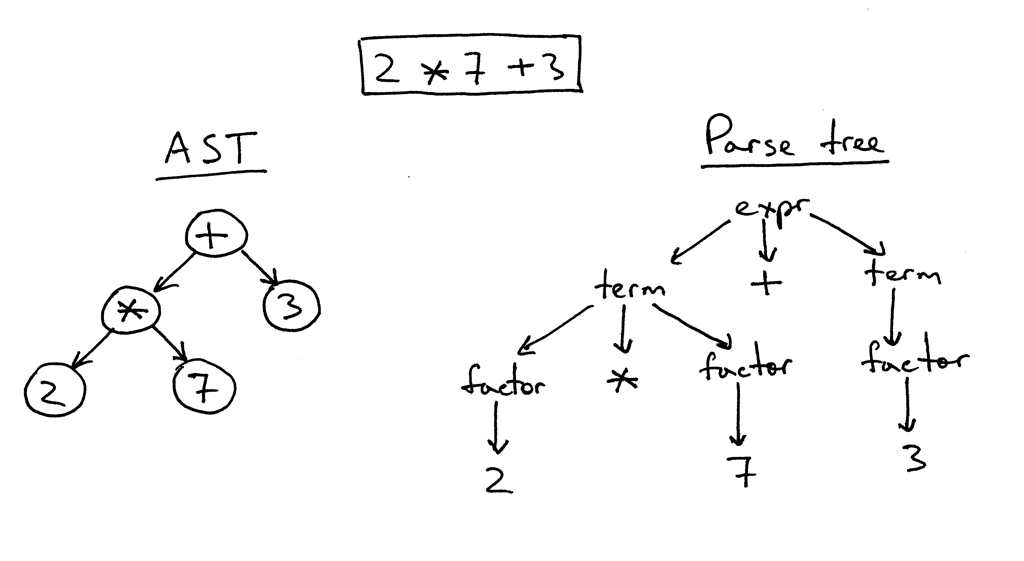
Die Idee hinter der Struktur von Jinja2-Vorlagen ist ziemlich einfach. Wenn der Text etwas enthält, das in einem Paar von "{{" / "}}" enthalten ist, dann ist dies "etwas" - ein Ausdruck, der ausgewertet, in eine Textdarstellung konvertiert und in das Endergebnis eingefügt werden muss. Innerhalb des Paares "{%" / "%}" befinden sich Operatoren wie for, if, set usw. Nun, in "{#" / "#}" gibt es Kommentare. Nachdem ich die Implementierung von Jinja2CppLight studiert hatte, entschied ich, dass es keine gute Idee war, alle diese Kontrollstrukturen manuell im Vorlagentext zu finden. Deshalb habe ich mich mit einem ziemlich einfachen regulären Ausdruck bewaffnet: ((\ \ {\ {) | (\} \}) | (\ {%) | (% \}) | (\ {#) | (# \}) | (\ n)), mit deren Hilfe er den Text in die notwendigen Fragmente zerlegte. Und nannte es die raue Phase des Parsens. In der Anfangsphase der Arbeit zeigte die Idee ihre Wirksamkeit (ja, tatsächlich zeigt sie es immer noch), aber in guter Weise muss sie in Zukunft überarbeitet werden, da dem Vorlagentext jetzt geringfügige Einschränkungen auferlegt werden: Fluchtpaare "{{" und "}}" im Text wird auch "Stirn" verarbeitet.
In der zweiten Phase wird nur das, was sich in den „Klammern“ befindet, detailliert analysiert. Und hier musste ich basteln. Mit inja und Jinja2CppLight ist der Ausdrucksparser ziemlich einfach. Im ersten Fall - auf der gleichen Regexp'ah, im zweiten - handgeschrieben, aber nur sehr einfache Designs unterstützend. Unterstützung für Filter, Tester, komplexe Arithmetik oder Indizierung kommt nicht in Frage. Und genau diese Funktionen von Jinja2 wollte ich am meisten. Daher hatte ich keine andere Wahl, als einen vollwertigen LL (1) -Parser (an einigen Stellen - kontextsensitiv) zu kräuseln, der die erforderliche Grammatik implementiert. Vor ungefähr zehn bis fünfzehn Jahren würde ich wahrscheinlich Bison oder ANTLR dafür nehmen und mit ihrer Hilfe einen Parser implementieren. Vor ungefähr sieben Jahren hätte ich Boost.Spirit ausprobiert. Jetzt habe ich nur den Parser implementiert, den ich benötige, und zwar nach der Methode des rekursiven Abstiegs, ohne unnötige Abhängigkeiten zu generieren und die Kompilierungszeit erheblich zu verlängern, wie dies bei Verwendung externer Dienstprogramme oder Boost.Spirit der Fall wäre. Am Ausgang des Parsers erhalte ich einen AST (für Ausdrücke oder für Operatoren), der als Vorlage gespeichert wird und für das nachfolgende Rendern bereit ist.
Ein Beispiel für die Parsing-Logik ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
Von hier aus .
Fragment von AST-Ausdrucksbaumklassen class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
Von hier aus .
Beispielklassen von AST-Baumoperatoren struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
Von hier aus .
AST-Knoten sind nur dem Text der Vorlage zugeordnet und werden zum Zeitpunkt des Renderns unter Berücksichtigung des aktuellen Renderkontexts und seiner Parameter in Gesamtwerte konvertiert. Dadurch konnten wir fadensichere Muster erstellen. Aber mehr dazu in Bezug auf das eigentliche Rendering.
Als primären Tokenizer habe ich die
Lexertk- Bibliothek ausgewählt. Es hat die Lizenz, die ich brauche und nur Header. Es stimmt, ich musste alle Schnickschnack abschneiden, um das Gleichgewicht der Klammern usw. zu berechnen, und nur den Tokenizer selbst belassen, der (nach einigem Begradigen mit einer Datei) gelernt hatte, nicht nur mit char, sondern auch mit wchar_t-Zeichen zu arbeiten. Zusätzlich zu diesem Tokenizer habe ich eine weitere Klasse eingeschlossen, die drei Hauptfunktionen ausführt: a) Sie abstrahiert den Parser-Code von der Art der Zeichen, mit denen wir arbeiten, b) erkennt für Jinja2 spezifische Schlüsselwörter und c) bietet eine praktische Schnittstelle für die Arbeit mit dem Token-Stream:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
Von hier aus .
Trotz der Tatsache, dass die Engine sowohl mit char- als auch mit wchar_t-Vorlagen arbeiten kann, hängt der Hauptparsing-Code nicht von der Art des Zeichens ab. Aber mehr dazu im Abschnitt über Abenteuer mit Charaktertypen.
Separat musste ich an den Kontrollstrukturen basteln. In Jinja2 sind viele von ihnen gepaart. Zum Beispiel für / endfor, if / endif, block / endblock usw. Jedes Element des Paares wird in eigene "Klammern" gesetzt, und zwischen den Elementen kann eine Reihe von allem stehen: nur Text und andere Steuerblöcke. Daher musste der Algorithmus zum Parsen der Vorlage auf der Grundlage des Stapels durchgeführt werden, an dessen aktuellem oberen Element alle neu gefundenen Konstruktionen und Anweisungen sowie Fragmente einfachen Textes zwischen ihnen „haften“. Bei Verwendung desselben Stapels wird das Fehlen einer Unwucht des Typs if-for-endif-endfor überprüft. Infolgedessen stellte sich heraus, dass der Code nicht so "kompakt" war wie beispielsweise Jinja2CppLight (oder inja), bei dem sich die gesamte Implementierung in einer Quelle (oder einem Header) befindet. Die Parsing-Logik und tatsächlich die Grammatik im Code sind jedoch deutlicher sichtbar, was die Unterstützung und Erweiterung vereinfacht. Zumindest habe ich das angestrebt. Es ist immer noch nicht möglich, die Anzahl der Abhängigkeiten oder die Menge des Codes zu minimieren. Sie müssen ihn daher verständlicher machen.
Im
nächsten Teil werden wir über den Prozess des Renderns von Vorlagen sprechen, aber vorerst - Links:
Jinja2-Spezifikation:
http://jinja.pocoo.org/docs/2.10/templates/Implementierung von Jinja2Cpp:
https://github.com/flexferrum/Jinja2CppImplementierung von Jinja2CppLight:
https://github.com/hughperkins/Jinja2CppLightVerletzte Implementierung:
https://github.com/pantor/injaDienstprogramm zum Generieren von Code basierend auf Jinja2-Vorlagen:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor