In den letzten beiden Artikeln haben wir über IIoT gesprochen - das industrielle Internet der Dinge -, das eine Architektur zum Empfangen von Daten von Sensoren erstellt und die Sensoren selbst verlötet hat. Der Eckpfeiler von IIoT-Architekturen und allen Architekturen, die mit BigData arbeiten, ist die Datenstromverarbeitung. Es basiert auf dem Konzept von Messaging und Warteschlangen. Der Standard für die Arbeit mit Messaging ist jetzt Apache Kafka. Um jedoch seine Vorteile (und seine Nachteile) zu verstehen, wäre es gut, die Grundlagen des Betriebs von Warteschlangensystemen als Ganzes, ihre Funktionsmechanismen, Verwendungsmuster und Grundfunktionen zu verstehen.

Wir haben eine ausgezeichnete Artikelserie gefunden, die die Funktionalität von Apache Kafka und einem anderen (unverdient ignorierten) Riesen unter den Warteschlangensystemen vergleicht - RabbitMQ. Wir haben diese Artikelserie übersetzt, kommentiert und ergänzt. Obwohl die Serie im Dezember 2017 geschrieben wurde, verändert sich die Welt der Messagingsysteme (und insbesondere von Apache Kafka) so schnell, dass sich bis zum Sommer 2018 einige Dinge geändert haben.
Quelle
RabbitMQ gegen Kafka
Messaging ist der zentrale Teil vieler Architekturen, und die beiden Säulen in diesem Bereich sind RabbitMQ und Apache Kafka. Bis heute hat sich Apache Kafka zu einem fast industriellen Standard in der Datenverarbeitung und -analyse entwickelt. In dieser Reihe werden wir RabbitMQ und Kafka im Zusammenhang mit ihrer Verwendung in Echtzeitinfrastrukturen näher betrachten.
Apache Kafka ist jetzt auf dem Vormarsch, aber es scheint, dass sie begonnen haben, RabbitMQ zu vergessen. Jeder Hype konzentrierte sich auf Kafka, und dies geschieht aus offensichtlichen Gründen, aber RabbitMQ ist immer noch eine gute Wahl für Messaging. Einer der Gründe, warum Kafka seine Aufmerksamkeit auf sich selbst gelenkt hat, ist seine allgemeine Besessenheit von Skalierbarkeit, und offensichtlich ist Kafka skalierbarer als RabbitMQ, aber die meisten von uns haben keine Bedenken hinsichtlich der Skalen, bei denen RabbitMQ Probleme hat. Die meisten von uns sind nicht Google oder Facebook. Die meisten von uns beschäftigen sich mit täglichen Nachrichtenmengen von Hunderttausenden bis Hunderten von Millionen und nicht mit Mengen von Milliarden bis Billionen (aber es gibt übrigens Fälle, in denen Menschen RabbitMQ auf Milliarden von täglichen Nachrichten skalierten).
Daher werden wir in unserer Artikelserie nicht über Fälle sprechen, in denen extreme Skalierbarkeit erforderlich ist (und dies ist das Vorrecht von Kafka), sondern uns auf die einzigartigen Vorteile konzentrieren, die jedes der betrachteten Systeme bietet. Interessanterweise hat jedes System seine eigenen Vorteile, aber gleichzeitig unterscheiden sie sich erheblich voneinander. Natürlich habe ich viel über RabbitMQ geschrieben, aber ich versichere Ihnen, dass ich dem keine besondere Präferenz gebe. Ich mag gut gemachte Dinge, und RabbitMQ und Kafka sind beide ziemlich ausgereifte, zuverlässige und, ja, skalierbare Messagingsysteme.
Wir werden auf der obersten Ebene beginnen und dann beginnen, die verschiedenen Aspekte dieser beiden Technologien zu untersuchen. Diese Artikelserie richtet sich an Fachleute, die mit der Organisation von Messagingsystemen befasst sind, oder an Architekten / Ingenieure, die die Details der unteren Ebene und ihre Anwendung verstehen möchten. Wir werden keinen Code schreiben, sondern uns auf die Funktionalität beider Systeme konzentrieren, auf die Messaging-Prozessvorlagen, die jeder von ihnen bietet, und auf die Entscheidungen, die Entwickler und Architekten treffen müssen.
In diesem Teil werden wir uns ansehen, was RabbitMQ und Apache Kafka sind und wie sie mit Messaging umgehen. Beide Systeme nähern sich der Messaging-Architektur aus verschiedenen Blickwinkeln, von denen jedes Stärken und Schwächen aufweist. In diesem Kapitel werden wir keine wichtigen Schlussfolgerungen ziehen. Stattdessen schlagen wir vor, diesen Artikel als Technologiehandbuch für Anfänger zu verwenden, damit wir in den nächsten Artikeln der Reihe tiefer eintauchen können.
Rabbitmq
RabbitMQ ist ein Verwaltungssystem für verteilte Nachrichtenwarteschlangen. Verteilt, da es normalerweise als Cluster von Knoten funktioniert, bei denen Warteschlangen auf Knoten verteilt und optional repliziert werden, um fehlerresistent und hochverfügbar zu sein. Regelmäßig implementiert es AMQP 0.9.1 und bietet über zusätzliche Module andere Protokolle wie STOMP, MQTT und HTTP an.
RabbitMQ verwendet sowohl klassische als auch innovative Messaging-Ansätze. Klassisch in dem Sinne, dass es sich auf die Nachrichtenwarteschlange konzentriert und innovativ - in der Möglichkeit eines flexiblen Routings. Diese Routing-Funktion ist ihr einzigartiger Vorteil. Die Erstellung eines schnellen, skalierbaren und zuverlässigen verteilten Messaging-Systems ist an sich schon eine Errungenschaft, aber die Messaging-Routing-Funktionalität macht es unter vielen Messaging-Technologien wirklich herausragend.
Austausch und Warteschlangen
Super vereinfachte Überprüfung:
- Verlage (Verlage) senden Nachrichten an Börsen
- Exchange'i sendet Nachrichten in Warteschlangen und an andere Börsen
- RabbitMQ sendet nach Erhalt einer Nachricht Bestätigungen an die Herausgeber
- Empfänger (Verbraucher) unterhalten dauerhafte TCP-Verbindungen zu RabbitMQ und geben bekannt, welche Warteschlange (n) sie erhalten
- RabbitMQ sendet Nachrichten an Empfänger
- Empfänger senden Erfolgs- / Fehlerbestätigungen
- Nach erfolgreichem Empfang werden Nachrichten aus den Warteschlangen entfernt.
Diese Liste enthält eine Vielzahl von Entscheidungen, die Entwickler und Administratoren treffen müssen, um die erforderlichen Liefergarantien, Leistungsmerkmale usw. zu erhalten, auf die wir später noch eingehen werden.
Sehen wir uns ein Beispiel für die Arbeit mit einem Publisher, einem Exchange, einer Warteschlange und einem Empfänger an:

Abb. 1. Ein Verlag und ein Empfänger
Was tun, wenn Sie mehrere Herausgeber desselben haben?
Nachrichten? Was ist, wenn wir mehrere Empfänger haben, von denen jeder alle Nachrichten empfangen möchte?

Abb. 2. Mehrere Verlage, mehrere unabhängige Empfänger
Wie Sie sehen können, senden Publisher ihre Nachrichten an denselben Austauscher, der jede Nachricht in drei Warteschlangen sendet, von denen jede einen Empfänger hat. Im Fall von RabbitMQ ermöglichen Warteschlangen verschiedenen Empfängern, alle Nachrichten zu empfangen. Vergleichen Sie mit der folgenden Tabelle:
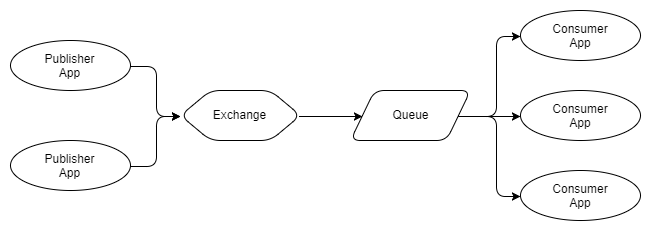
Abb. 3. Mehrere Herausgeber, eine Warteschlange mit mehreren konkurrierenden Empfängern
In Abbildung 3 sehen wir drei Empfänger, die dieselbe Warteschlange verwenden. Dies sind konkurrierende Empfänger, dh sie konkurrieren um den Empfang von Nachrichten aus der Warteschlange. Somit ist zu erwarten, dass durchschnittlich jeder Empfänger ein Drittel der Nachrichten in der Warteschlange empfängt. Wir verwenden konkurrierende Empfänger, um unser Nachrichtenverarbeitungssystem zu skalieren, und mit RabbitMQ ist dies sehr einfach: Hinzufügen oder Entfernen von Empfängern auf Anfrage. Unabhängig davon, wie viele konkurrierende Empfänger Sie haben, liefert RabbitMQ nur Nachrichten an einen Empfänger.
Wir können Reis kombinieren. 2 und 3, um mehrere Sätze konkurrierender Empfänger zu empfangen, wobei jeder Satz jede Nachricht empfängt.

Abb. 4. Mehrere Verlage, mehrere Warteschlangen mit konkurrierenden Empfängern
Die Pfeile zwischen Austauschern und Warteschlangen werden als Bindungen bezeichnet, und wir werden ausführlicher darauf eingehen.
Garantien
RabbitMQ gibt Garantien für "einmalige Lieferung" und "mindestens eine Lieferung", jedoch nicht "genau eine Lieferung".
Anmerkung des Übersetzers: Vor Kafka Version 0.11 war die Zustellung von Nachrichten mit genau einmaliger Zustellung nicht verfügbar. Derzeit ist in Kafka eine ähnliche Funktionalität vorhanden.
Nachrichten werden in der Reihenfolge zugestellt, in der sie in der Warteschlange ankommen (schließlich ist dies die Definition der Warteschlange). Dies garantiert nicht, dass der Abschluss der Nachrichtenverarbeitung mit derselben Reihenfolge übereinstimmt, wenn Sie konkurrierende Empfänger haben. Dies ist kein RabbitMQ-Fehler, sondern die grundlegende Realität der parallelen Verarbeitung eines geordneten Satzes von Nachrichten. Dieses Problem kann mit Consistent Hashing Exchange gelöst werden, wie Sie im nächsten Kapitel zu Vorlagen und Topologien sehen werden.
Push- und Prefetch-Empfänger
RabbitMQ sendet Nachrichten an Empfänger (es gibt auch eine API zum Abrufen von Nachrichten aus RabbitMQ, aber diese Funktionalität ist derzeit veraltet). Dies kann die Empfänger überfordern, wenn die Nachrichten schneller in der Warteschlange ankommen, als die Empfänger sie verarbeiten können. Um dies zu vermeiden, kann jeder Empfänger ein Prefetch-Limit festlegen (auch als QoS-Limit bezeichnet). Tatsächlich ist das QoS-Limit ein Limit für die Anzahl der Nachrichten, die vom akkumulierten Empfänger nicht bestätigt wurden. Es wirkt wie eine Sicherung, wenn der Empfänger zu verzögern beginnt.
Warum wurde entschieden, dass Nachrichten in der Warteschlange gepusht (Push) und nicht entladen (Pull) werden? Erstens, weil es weniger Verzögerungszeit gibt. Zweitens möchten wir im Idealfall, wenn wir konkurrierende Empfänger aus derselben Warteschlange haben, die Last gleichmäßig auf sie verteilen. Wenn jeder Empfänger Nachrichten anfordert / herunterlädt, kann die Arbeitsverteilung je nach Anforderung sehr ungleichmäßig werden. Je ungleichmäßiger die Verteilung der Nachrichten ist, desto größer ist die Verzögerung und der weitere Verlust der Reihenfolge der Nachrichten während der Verarbeitung. Diese Faktoren orientieren die RabbitMQ-Architektur an einem Push-Mechanismus für jeweils eine Nachricht. Dies ist eine der Einschränkungen bei der Skalierung von RabbitMQ. Die Einschränkung wird durch die Tatsache gemindert, dass Bestätigungen gruppiert werden können.
Routing
Exchange sind im Grunde Nachrichtenrouter für Warteschlangen und / oder andere Austausche. Damit eine Nachricht vom Austausch in eine Warteschlange oder in einen anderen Austausch verschoben werden kann, ist eine Bindung erforderlich. Unterschiedlicher Austausch erfordert unterschiedliche Bindungen. Es gibt vier Arten von Austausch und zugehörige Bindungen:
- Fanout Leitet alle Warteschlangen und Austauscher an, die zum Austausch des Standard-Submodells von Pub verpflichtet sind.
- Direkt (direkt). Leitet Nachrichten basierend auf dem vom Herausgeber festgelegten Routing-Schlüssel weiter, den die Nachricht enthält. Der Routing-Schlüssel ist eine kurze Zeichenfolge. Direkte Austauscher senden Nachrichten an / Exchange-Warteschlangen mit einem Pairing-Schlüssel, der genau mit dem Routing-Schlüssel übereinstimmt.
- Thema (thematisch). Leitet Nachrichten basierend auf dem Routing-Schlüssel weiter, ermöglicht jedoch die Verwendung eines unvollständigen Abgleichs (Platzhalter).
- Header (Header). Mit RabbitMQ können Sie Nachrichten Empfänger-Header hinzufügen. Header-Austausche senden Nachrichten gemäß diesen Header-Werten. Jede Bindung enthält eine genaue Übereinstimmung der Header-Werte. Sie können der Bindung mehrere Werte hinzufügen, wobei ALLE oder ALLE Werte für die Übereinstimmung erforderlich sind.
- Konsequentes Hashing. Dies ist ein Austauscher, der entweder einen Routing-Schlüssel oder einen Nachrichtenkopf hascht und nur in einer Warteschlange sendet. Dies ist nützlich, wenn Sie die Garantien für die Verarbeitung von Aufträgen einhalten und dennoch Empfänger skalieren müssen.

Abb. 5. Beispiel für einen Themenaustausch
Wir werden auch das Routing genauer betrachten, aber das Beispiel für den Themenaustausch ist oben angegeben. In diesem Beispiel veröffentlichen Publisher Fehlerprotokolle im Routing-Schlüsselformat LEVEL (Error Level) .AppName.
Warteschlange 1 empfängt alle Nachrichten, da eine Platzhalternummer mit mehreren Wörtern verwendet wird.
Warteschlange 2 erhält eine beliebige Stufe der ECommerce.WebUI-Anwendungsprotokollierung. Es verwendet Platzhalter * und erfasst so die Ebene einer einzelnen Themennamen (ERROR.Ecommerce.WebUI, NOTICE.ECommerce.WebUI usw.).
In Warteschlange 3 werden alle FEHLERMELDUNGEN einer beliebigen Anwendung angezeigt. Es verwendet Platzhalter #, um alle Anwendungen abzudecken (ERROR.ECommerce.WebUi, ERROR.SomeApp.SomeSublevel usw.).
Dank vier Methoden für das Weiterleiten von Nachrichten und der Möglichkeit, Nachrichten auszutauschen, um Nachrichten an andere Vermittlungsstellen zu senden, können Sie mit RabbitMQ einen leistungsstarken und flexiblen Satz von Vorlagen für den Nachrichtenaustausch verwenden. Darüber hinaus werden wir über den Austausch mit toten Briefen, über den Austausch und Warteschlangen ohne Daten (kurzlebiger Austausch und Warteschlangen) sprechen, und RabbitMQ wird sein volles Potenzial entfalten.
Nicht ausgelieferter Austausch
Anmerkung des Übersetzers: Wenn Nachrichten aus der Warteschlange aus dem einen oder anderen Grund nicht empfangen werden können (die Stromversorgung des Verbrauchers reicht nicht aus, Netzwerkprobleme usw.), können sie verzögert und separat verarbeitet werden.
Wir können Warteschlangen so konfigurieren, dass Nachrichten unter den folgenden Bedingungen zum Austausch gesendet werden:
- Die Warteschlange überschreitet die angegebene Anzahl von Nachrichten.
- Die Warteschlange überschreitet die angegebene Anzahl von Bytes.
- Die Nachrichtenübertragungszeit (TTL) ist abgelaufen. Der Herausgeber kann die Nachrichtenlebensdauer festlegen, und die Warteschlange selbst kann auch eine angegebene TTL für die Nachricht haben. In diesem Fall wird eine kürzere TTL der beiden verwendet.
Wir erstellen eine Warteschlange, die an den Austausch mit nicht zugestellten Nachrichten gebunden ist, und diese Nachrichten werden dort gespeichert, bis eine Aktion ausgeführt wird.
Wie bei vielen Funktionen von RabbitMQ können beim Austausch mit unzustellbaren Nachrichten Vorlagen verwendet werden, die ursprünglich nicht bereitgestellt wurden. Wir können TTL-Nachrichten verwenden und mit nicht zugestellten Nachrichten austauschen, um verzögerte Warteschlangen zu implementieren und Warteschlangen erneut zu versuchen.
Tauscher und Warteschlangen ohne Daten
Börsen und Warteschlangen können dynamisch erstellt werden, und Sie können Kriterien für ihre automatische Entfernung festlegen. Dies ermöglicht die Verwendung von Mustern wie nachrichtenbasierten RPCs.
Zusätzliche Module
Das erste Plug-In, das Sie wahrscheinlich installieren möchten, ist das Verwaltungs-Plugin, das einen HTTP-Server mit einer Webschnittstelle und einer REST-API bereitstellt. Es ist sehr einfach zu installieren und hat eine einfach zu bedienende Oberfläche. Das Bereitstellen von Skripten über die REST-API ist ebenfalls sehr einfach.
Außerdem:
- Konsistenter Hashing Exchange, Sharding Exchange und mehr
- Protokolle wie STOMP und MQTT
- Web-Hooks
- zusätzliche Arten von Wärmetauschern
- SMTP-Integration
Es gibt viele andere Dinge, die über RabbitMQ gesagt werden können, aber dies ist ein gutes Beispiel, mit dem Sie beschreiben können, was RabbitMQ tun kann. Jetzt schauen wir uns Kafka an, das einen völlig anderen Messaging-Ansatz verwendet und gleichzeitig seine eigenen charakteristischen Merkmale aufweist.
Apache kafka
Kafka ist ein verteiltes repliziertes Festschreibungsprotokoll. Kafka hat kein Konzept für Warteschlangen, was auf den ersten Blick seltsam erscheinen mag, da es als Nachrichtensystem verwendet wird. Warteschlangen sind seit langem ein Synonym für Messagingsysteme. Schauen wir uns zunächst an, was ein "verteiltes, repliziertes Änderungs-Commit-Protokoll" bedeutet:
- Verteilt, weil Kafka als Cluster von Knoten bereitgestellt wird, sowohl aus Gründen der Fehlertoleranz als auch zur Skalierung
- Repliziert, da Nachrichten normalerweise auf mehreren Knoten (Servern) repliziert werden.
- Ein Festschreibungsprotokoll, da Nachrichten in segmentierten Nur-Anhängen-Protokollen gespeichert werden, die als Themen bezeichnet werden. Dieses Protokollierungskonzept ist der wichtigste einzigartige Vorteil von Kafka.
Das Verständnis des Journals (und des Themas) und der Partitionen ist der Schlüssel zum Verständnis von Kafka. Wie unterscheidet sich ein partitioniertes Protokoll von einer Reihe von Warteschlangen? Stellen wir uns vor, wie es aussieht.
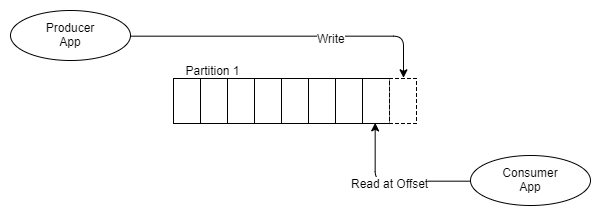
Abb. 6 Ein Produzent, ein Segment, ein Empfänger
Anstatt Nachrichten in die FIFO-Warteschlange zu stellen und den Status dieser Nachricht in der Warteschlange zu überwachen, wie es RabbitMQ tut, fügt Kafka sie einfach dem Protokoll hinzu, und das ist alles.
Die Nachricht bleibt bestehen, unabhängig davon, ob sie einmal oder mehrmals empfangen wurde. Es wird gemäß der Aufbewahrungsrichtlinie, auch Fensterzeitraum genannt, gelöscht. Wie werden Informationen aus dem Thema entnommen?
Jeder Empfänger verfolgt, wo er sich im Protokoll befindet: Es gibt einen Zeiger auf die zuletzt empfangene Nachricht, und dieser Zeiger wird als Offset-Adresse bezeichnet. Empfänger unterstützen diese Adresse über Clientbibliotheken. Abhängig von der Version von Kafka wird die Adresse entweder in ZooKeeper oder in Kafka selbst gespeichert.
Eine Besonderheit des Journaling-Modells besteht darin, dass es viele Schwierigkeiten hinsichtlich des Status der Nachrichtenübermittlung sofort beseitigt und es den Empfängern, was noch wichtiger ist, ermöglicht, Nachrichten an der vorherigen relativen Adresse zurückzuspulen, zurückzugeben und zu empfangen. Stellen Sie sich beispielsweise vor, Sie stellen einen Service bereit, der Rechnungen ausstellt, die Bestellungen von Kunden berücksichtigen. Der Dienst hat einen Fehler und berechnet nicht alle Rechnungen innerhalb von 24 Stunden korrekt. Mit RabbitMQ müssen Sie diese Bestellungen bestenfalls nur über den Kontoservice erneut veröffentlichen. Mit Kafka verschieben Sie einfach die relative Adresse für diesen Empfänger vor 24 Stunden.
Schauen wir uns also an, wie es aussieht, wenn es ein Thema gibt, in dem es eine Partition und zwei Empfänger gibt, von denen jeder jede Nachricht empfangen soll.

Abb. 7. Ein Produzent, eine Partition, zwei unabhängige Empfänger
Wie aus dem Diagramm ersichtlich, erhalten zwei unabhängige Empfänger dieselbe Partition, lesen jedoch an unterschiedlichen Versatzadressen. Möglicherweise dauert der Abrechnungsdienst länger, um Nachrichten zu verarbeiten, als der Push-Benachrichtigungsdienst. oder vielleicht war der Abrechnungsservice für einige Zeit nicht verfügbar und versuchte später aufzuholen. Oder vielleicht lag ein Fehler vor und die Offset-Adresse musste um einige Stunden verschoben werden.
Angenommen, der Abrechnungsservice muss in drei Teile unterteilt werden, da er nicht mit der Geschwindigkeit der Nachricht Schritt halten kann. Mit RabbitMQ stellen wir einfach zwei weitere Abrechnungsdienstanwendungen bereit, die aus der Abrechnungswarteschlange stammen. Kafka unterstützt jedoch keine konkurrierenden Empfänger in derselben Partition, da der Kafka-Parallelitätsblock die Partition selbst ist. Wenn wir also drei Empfänger von Rechnungen benötigen, benötigen wir mindestens drei Partitionen. Jetzt haben wir also:
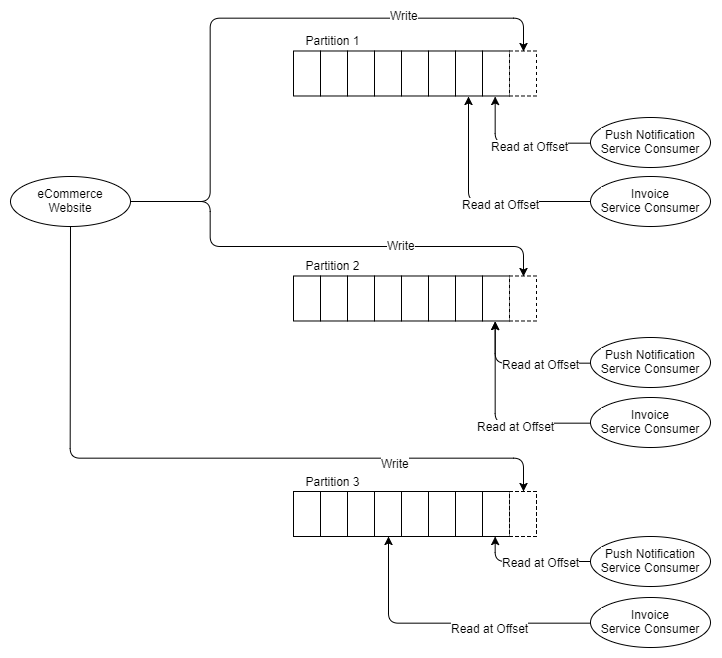
Abb. 8. Drei Partitionen und zwei Gruppen von drei Empfängern
Es versteht sich daher, dass Sie mindestens so viele Partitionen benötigen wie der am meisten skalierte horizontale Empfänger. Lassen Sie uns ein wenig über Partitionen sprechen.
Partitionen und Empfängergruppen
Jede Partition ist eine separate Datei, in der die Reihenfolge der Nachrichten garantiert ist. Dies ist wichtig zu beachten: Die Nachrichtenreihenfolge ist nur in einer Partition garantiert. In Zukunft kann dies zu einem gewissen Widerspruch zwischen den Anforderungen für die Nachrichtenwarteschlange und den Anforderungen für die Leistung führen, da die Leistung in Kafka auch durch Partitionen skaliert wird. Die Partition kann keine konkurrierenden Empfänger unterstützen, daher kann unsere Abrechnungsanwendung nur einen Teil für jeden Abschnitt verwenden.
Nachrichten können durch einen zyklischen Algorithmus oder über eine Hash-Funktion in Segmente umgeleitet werden: Hash (Nachrichtenschlüssel)% Anzahl der Partitionen. , , , , , , . .
RabbitMQ. . , RabbitMQ , . , .
RabbitMQ . Kafka , .
, , Kafka , RabbitMQ — . RabbitMQ , . Kafka , . , , Kafka , .
, , , ( ). , , . , , , .
RabbitMQ — Consistent Hashing exchange, . Kafka' , Kafka , , , , , -. RabbitMQ , , , .
: , , Id 1000 , Id 1000 . , , . , .
(push) (pull)
RabbitMQ (push) , , . RabbitMQ . , Kafka (pull), . , , Kafka long-polling.
(pull) Kafka - . Kafka , , .
RabbitMQ, , , , . Kafka , .
Kafka /» , , . , .
Abb. 9.
, , Kafka :
Abb. 10. ,

, :

Abb. 11.
, , .
, , , , .

Abb. 12.
. .

:
, . , , .
Kafka – , , , , , . . , . , , .
— . , 50 . – . , , , .
, , . , , . , . , , , .
. , , .
, RabbitMQ, Kafka, Kafka . RabbitMQ , , ZooKeeper Consul.
RabbitMQ , Kafka. RabbitMQ, , . : .
. , . . , . . . , , - .
, Kafka, . . , , .
, . RabbitMQ , Kafka .
Schlussfolgerungen
RabbitMQ , . , , . , . , , .
Kafka . , . Kafka , RabbitMQ . , Kafka , RabbitMQ, , .
RabbitMQ.
, , IoT , . : t.me/justiothings