Kommentare in einer kürzlich erschienenen Veröffentlichung „Wie gut ist das Open-Source-Ökosystem von R für die Lösung von Geschäftsproblemen?“ Die Downloads in Excel führten zu der Idee, dass es sinnvoll ist, Zeit zu verbringen und einen der bewährten möglichen Ansätze zu beschreiben, die implementiert werden können, ohne R zu verlassen.
Die Situation ist ziemlich typisch. Das Unternehmen verfügt immer über N Methoden, mit denen Manager manuell versuchen, Berichte in Excel zu erstellen. Selbst wenn sie automatisiert sind, bleibt immer eine Situation bestehen, in der es dringend erforderlich ist, einen neuen willkürlichen Schnitt vorzunehmen oder eine Präsentation für einen bestimmten Manager in einer bestimmten Form zu erstellen.
Außerdem gibt es eine Reihe von manuell unterstützten Excel-Wörterbüchern, mit denen die Darstellung von Daten in Berichten und Beispielen in die richtige Terminologie umgewandelt werden kann.
Da kein geeignetes Werkzeug gefunden werden konnte (die Masse der zusätzlichen Nuancen wird geringer sein), musste ich den "Universalkonstruktor" auf Shiny + R stapeln. Aufgrund der Universalität und Parametrierbarkeit der Einstellungen kann ein solcher Konstruktor problemlos auf nahezu jedes System in jedem Themenbereich gepflanzt werden.
Es ist eine Fortsetzung früherer Veröffentlichungen .
Kurze Erklärung des Problems
- Als Quelle für technische Daten gibt es einen Hauptspeicher vom Typ OLAP (wir konzentrieren uns auf Clickhouse), mehrere zusätzliche (Postgre, MS SQL, REST-API) und manuelle XML-, JSON- und XLSX-Referenzen. Aufgrund der Tatsache, dass Ad-hoc-Analysen erforderlich sind, einschließlich der Berechnung eindeutiger Werte, muss nur mit den Quelldaten und nicht mit Aggregaten gearbeitet werden.
- Einträge in der Datenbank - Hunderte von Milliarden Zeilen pro mehrere hundert Spalten (Zeitereignisse), es wird empfohlen, die Analyse in einem Modus durchzuführen, der nicht länger als einige zehn Sekunden beträgt, Abfragen können völlig unvorhersehbar sein, Daten werden in technischer Form gespeichert (englische Abkürzungen, Anzahl der Wörterbucheinträge usw.). ) Im Zielzustand werden ~ 200 TB Rohdaten erwartet.
- Akkumulierte Ereignisse weisen Versionsspezifikationen auf, d.h. Während das System funktioniert, sammeln sich darin Informationen aus verschiedenen Versionen und Versionen von Quellen an, die auf verschiedene Weise über sich selbst berichten.
- Manager arbeiten gut in Excel, sollten jedoch die technische Komponente des Systems nicht kennen (und können dies physisch nicht).
So lösen Sie das Problem
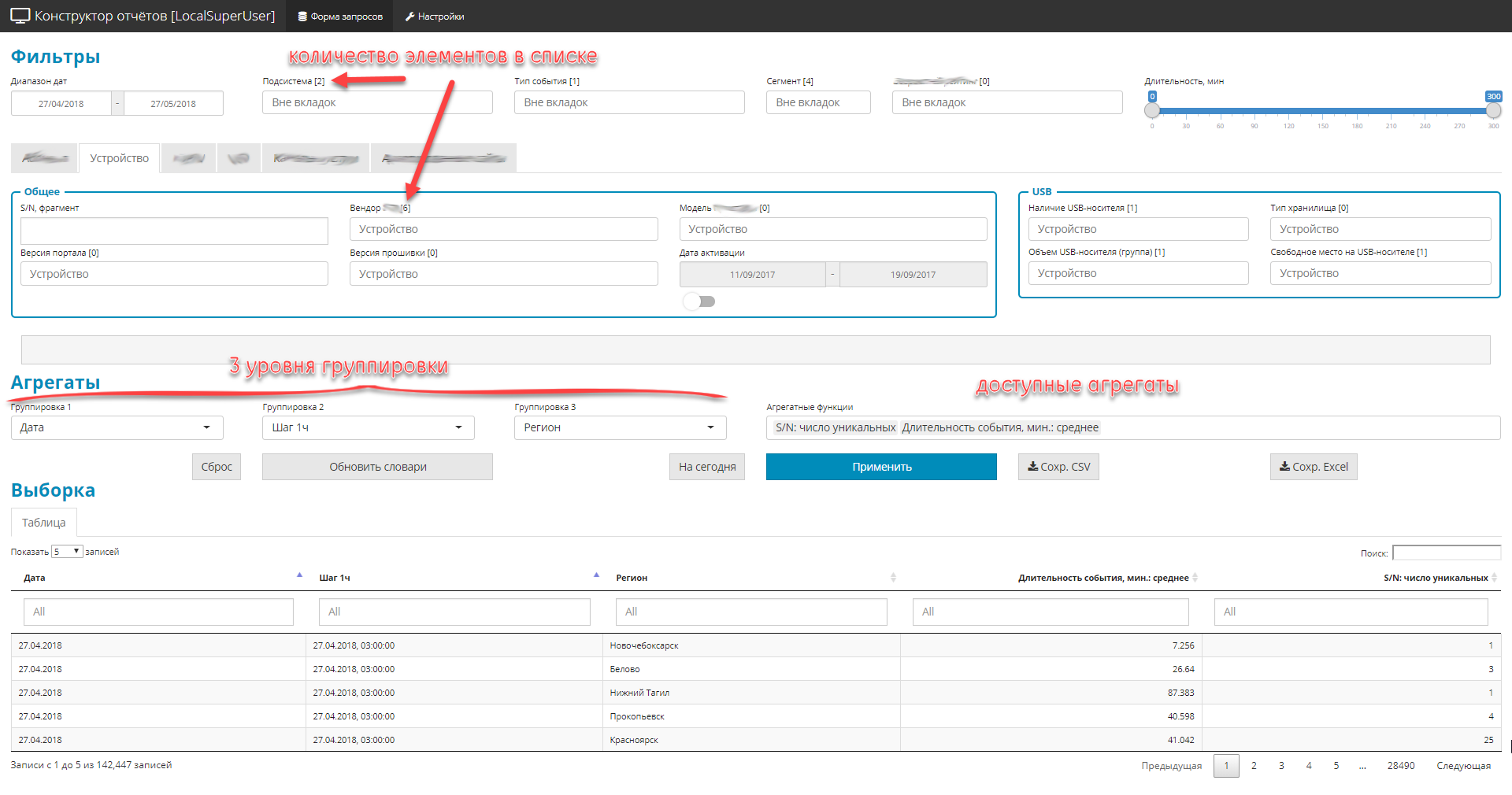
Das allgemeine Szenario der Arbeit ist recht einfach. Der Manager erhielt eine dringende Aufgabe für den analytischen Bereich - der Manager öffnet die Anwendung, bildet beliebige Stichproben in Bezug auf den Themenbereich - sieht und verdreht das tabellarische Ergebnis - entlädt das arrangierte Ergebnis in Excel - zeichnet ein Bild für das Management. Bequemlichkeit und Einfachheit der Benutzeroberfläche wurden als Nullpunkt gewählt.
- Alles ist als Einzelbild-Shiny-Anwendung mit Navigationsmenüs und Lesezeichen konzipiert.
- Alle Bedienelemente sind in 3 Teile unterteilt:
- Filter (global und privat). Begrenzen Sie den Auswahlbereich, es gibt 4 Typen: Dropdown-Listenwörterbuch, Datumsangaben, Textfragmente, digitaler Bereich.
- 3 Verschachtelungsebenen von Abfragegruppen
- Liste der Gesamtmengen (nämlich Mengen).
- Aufgrund der Tatsache, dass die ursprüngliche Quelle viele Felder enthält (ungefähr 2,5 Hundert), Sie jedoch alles anzeigen müssen, werden die Steuerelemente in thematische Blöcke gruppiert.
Schnittstellenbeispiel
Beispieldatei mit Metainformationen
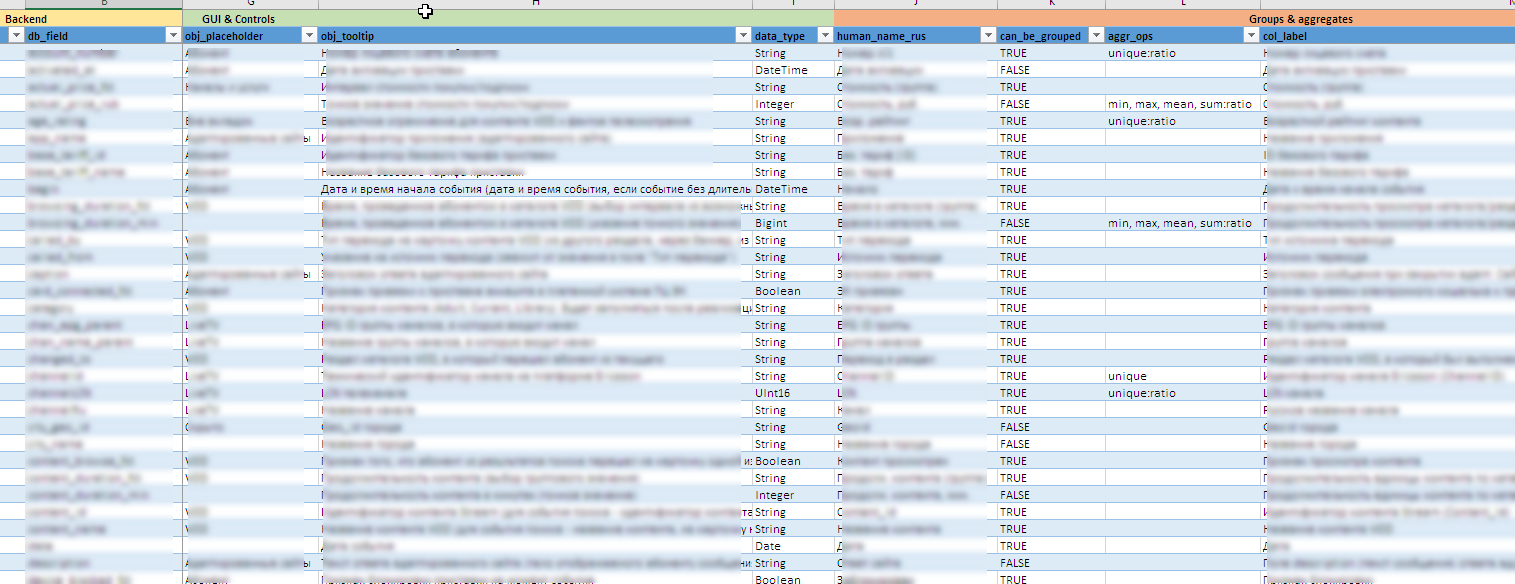
Nützliche "Chips" hinter den Kulissen:
- Während sich die Datenquellen weiterentwickeln, wird die gesamte Schnittstellenkonfiguration einschließlich der Erstellung von Steuerelementen, QuickInfos, des Inhalts verfügbarer Gruppierungen und Aggregate, Exportregeln in Excel usw. dekoriert als Metamodell in Form einer Excel-Datei. Auf diese Weise können Sie den "Designer" schnell für neue Felder oder Berechnungseinheiten ändern, ohne wesentliche Änderungen (oder überhaupt keine Änderungen) am Quellcode vorzunehmen.
- Es ist schwierig, im Voraus zu sagen, welche Werte in einem bestimmten Bereich auftreten können, und es ist noch schwieriger, einen zu finden, ich weiß nicht, was. Das manuelle Verwalten aller 90 dynamischen Steuerelemente ist nahezu unmöglich. In einigen Listen enthält das Vokabular mehrere hundert Bedeutungen. Daher werden Wörterbucheinträge für Steuerelemente im Hintergrund basierend auf den im Backend gesammelten Daten aktualisiert.
- Manager müssen alle Felder und Inhalte auf Russisch sehen. Und in den Quellen können diese Daten in offizieller Form gespeichert werden. Daher wird eine Kombination aus Clickhouse-Wörterbuchtechnologien und bidirektionaler Nachbearbeitung von Feldwerten auf Shiny-Ebene verwendet. Es bietet sofort die Verarbeitung aller Arten von Ausnahmen von den Regeln und versionierten Nuancen des Inhalts der Felder.
- Zum Schutz vor falschen Auswahlen wurde eine Querverbindung zwischen Listen zur Gruppierung hergestellt. Stufe 2 kann nur ausgewählt werden, wenn Stufe 1 eingestellt ist, und Stufe 3 nur, wenn Stufe 2 eingestellt ist. Die Listen der verfügbaren Werte werden unter Berücksichtigung bereits ausgewählter Werte dynamisch reduziert.
- Ein wichtiges Element ist die Kontrolle über die Anzeige der Auswahl sowohl auf dem Bildschirm als auch beim anschließenden Hochladen auf Excel. Auch hier gibt es eine Reihe von Funktionen in der Nachbearbeitung, die auf die Benutzerfreundlichkeit des Tools für den Manager abzielen:
- organisierte Unterstützung für die „Sichtbarkeitsmatrix“ in Form einer Excel-Datei. Diese Matrix bestimmt das Ein- oder Ausblenden bestimmter Felder in der Auswahl, abhängig von den installierten Filtern.
- zeilenweise dynamische Änderung des Probeninhalts. Abhängig vom Inhalt verschiedener Felder kann der Inhalt eines anderen Feldes geändert werden (wenn beispielsweise im Feld „Bestellmenge“ 0 angegeben ist, wird im Feld „Bestellart“ eine leere Zeile angezeigt.
- Verwaltung der Anzeige personenbezogener Daten. abhängig von der konfigurierten Rolle Zugriffsrechte pers. Daten können sowohl angezeigt als auch teilweise mit
* maskiert werden. - Präzisionsmanagement. nur um es zu erwähnen. 10 Dezimalstellen anzeigen - Moveton, aber es gibt Situationen, in denen die Genauigkeit von 2 Dezimalstellen nicht ausreicht. 80% der Objekte haben beispielsweise einen Prozentsatz von
0.00% Sie müssen die signifikanten Zeichen beim Runden erhöhen, damit der Unterschied zwischen den Linien sichtbar wird. Und die Menge beim Entladen in Excel sollte konvergieren (die Menge über alle Zeilen in der Bruchspalte wird vernünftigerweise im Bereich von 100% erwartet). - Bereitstellung des Rollenzugriffs auf der Ebene der verfügbaren Inhaltskontrollen. Zugriffsrechte werden von der JSON-Konfigurationsdatei gesteuert.
- Dynamische Steuerung der Anforderungstiefe. Wenn keine Gruppierungen und Aggregate angegeben sind (die Studie läuft und Sie nur Rohdaten zurückgeben müssen, die unter die installierten Filter fallen), ist der Schutz vor Backend-Überlastung aktiviert. Der Benutzer kann den Zeitbereich für die Suche in 1 Jahr festlegen, benötigt jedoch wirklich die letzten 1000 Datensätze aus der Auswahl. In dem Wissen, dass täglich Millionen von Datensätzen eintreffen, wird zuerst (vor 3-7 Tagen) eine Testanforderung für eine reduzierte Tiefe durchgeführt. Wenn die empfangene Anzahl von Zeilen nicht ausreicht (strenge Filterbedingungen), wird eine vollständige Abfrage für den gesamten Zeitraum gestartet.
- Entladen der empfangenen Proben im Excel-Format. Alles ist formatiert, alles auf Russisch, wird von einem separaten Blatt begleitet, in dem alle Beispielparameter festgelegt sind, damit Sie leicht verstehen können, wie dieses oder jenes Ergebnis erzielt wurde.
- In der Anwendung wird ein detailliertes Protokoll geführt, damit Sie sich einen Überblick über die Aktionen des Benutzers und die Funktionsweise der Motorraummechanik verschaffen können.
In Erwartung möglicher Kommentare zum „Fahrrad“, falls es 100% geben sollte, empfehle ich sofort, diese mit einem Hinweis auf das Ihnen bekannte Open-Source-Produkt zu schreiben. Ich freue mich über neue Entdeckungen.
Natürlich muss eine Verknüpfung zum Produkt hergestellt werden, wobei die gesamte Bandbreite der erweiterten Anforderungen berücksichtigt wird. Nun, vorzugsweise sofort mit der Bewertung der erforderlichen Infrastruktur. Für diese Option reichen zwei oder drei Server mittlerer Kapazität (64-128 GB; 12-20 CPU-Kern, Festplatte - basierend auf der Datenmenge) für den gesamten Komplex aus. ELK passte nicht, da die Hauptaufgabe die numerische Analyse ist und nicht mit Text funktioniert.
Detaillierte Anforderungen festgelegt
Im Folgenden finden Sie zur Information eine detaillierte Liste der Anforderungen an die Analyseeinheit im Teil der Schnittstellen Maschine-Maschine und Mensch-Maschine (der „Berichtsdesigner“ ist nur ein Teil).
Importieren \ Exportieren \ Umgebung
- Protokolldateien sind standardisiert und nur in Bezug auf Zeitstempel, Module und Subsysteme strukturiert. Das System sollte Protokolldateien mit einem beliebigen Inhalt des Nachrichteninhalts (Protokollkörper der Aufzeichnung) verarbeiten und sowohl strukturierten als auch unstrukturierten Protokollkörper der Aufzeichnung unterstützen.
- Um Daten anzureichern, muss das System über Importadapter für mindestens die folgenden Arten von Datenquellen verfügen:
- flache Dateien (csv, txt)
- strukturierte Dateien xml, json, xlsx
- odbc-kompatible Quellen, insbesondere MS SQL, MySQL, PostgreSQL
- Daten, die über die REST-API bereitgestellt werden.
- Das System sollte auf Wunsch des Benutzers sowohl den automatischen Import als auch den Import unterstützen. Beim Importieren von Benutzerdaten sollte das System Folgendes bereitstellen:
- die Möglichkeit der technischen Validierung importierter Daten (die Richtigkeit der Anzahl der Felder, ihre Art, Vollständigkeit, das Vorhandensein von Werten
- die Möglichkeit der logischen Validierung (Inhalt der Felder, Validierung, Kreuzvalidierung, ...)
- die Fähigkeit, Validierungsparameter (in beliebiger Form) gemäß der Logik des Importverfahrens zu konfigurieren;
- Ein detaillierter Bericht über erkannte technische und logische Fehler, der es dem Bediener ermöglicht, Fehlfunktionen in den importierten Daten schnell zu lokalisieren und zu beseitigen.
- Das System sollte den Export von Ergebnissen mindestens in den folgenden Formaten unterstützen:
- Datenexport in flache Dateien csv, txt
- Exportieren Sie Daten in strukturierte XML-, JSON- und XLSX-Dateien
- Datenexport in odbc-kompatible Quellen, insbesondere MS SQL, MySQL, PostgreSQL
- Bereitstellung des Zugriffs auf Daten über das REST-API-Protokoll
- Das System sollte über die folgenden Funktionen verfügen, um gedruckte Berichte zu erstellen:
- eine zusammenhängende Kombination von Text, tabellarischen Darstellungen und grafischen Darstellungen in einem einzigen Dokument gemäß einer vorgeformten Vorlage (Geschichtenerzählen);
- die Bildung aller berechneten Elemente (Tabellen, Grafiken) zum Zeitpunkt der Erstellung des Druckformulars;
- die Verwendung externer Quellen und Verzeichnisse, die für die Erstellung eines Berichts im On-the-Fly-Modus gemäß den oben genannten Protokollen erforderlich sind, ohne Integration und Vervielfältigung von Daten
- Export generierter Berichte in den Formaten HTML, DocX und PDF
- Die Bildung gedruckter Darstellungen sollte nach Bedarf sowohl nach Bedarf als auch im Hintergrund unterstützt werden.
- Das System sollte ein detailliertes Protokoll der Berechnungen, aktiven Benutzeraktionen oder der Interaktion mit externen Systemen führen.
- Das System muss vor Ort installiert werden.
- Die Installation und der anschließende Betrieb sollten unter vollständiger Isolierung des Systems vom Internet erfolgen.
Berechnungen
- Das System sollte die Berechnung aggregierter Metriken (Minimum, Maximum, Durchschnitt, Median, Quartile) für ein beliebiges Zeitintervall in einem Modus in einem Modus nahe der Echtzeit unterstützen.
- Das System muss die Berechnung grundlegender Metriken (Anzahl der Werte, Anzahl der eindeutigen Werte) für ein beliebiges Zeitintervall in einem Modus nahe der Echtzeit unterstützen.
- Bei der Berechnung der aggregierten Daten sollten die Aggregationszeiträume vom Benutzer aus vordefinierten Bereichen festgelegt werden: 5 Minuten, 10 Minuten, 15 Minuten, 20 Minuten, 30 Minuten, 1 Stunde, 2 Stunden, 24 Stunden, 1 Woche, 1 Monat
- Das System sollte einen Konstruktor enthalten, um beliebige Stichproben zu bilden. Die Zusammensetzung möglicher Operationen sollte durch ein vordefiniertes Datenmetamodell bestimmt werden. Der Konstruktor muss die folgenden Mindesteinstellungen unterstützen:
- Filterunterstützung für Daten: [Beginn des Berichtszeitraums - Ende des Berichtszeitraums]
- Filterunterstützung (Dropdown-Listen) mit Mehrfachauswahl für aufgezählte Felder (z. B. Städte: Moskau, St. Petersburg, ...)
- Automatische Erstellung des Inhalts von Dropdown-Listen für Filter von Aufzählungsfeldern basierend auf dynamischen externen Verzeichnissen oder akkumulierten Daten.
- Unterstützung für mindestens drei Ebenen der sequentiellen Gruppierung von Daten in der angeforderten Stichprobe; Die Parameter für die Gruppierung selbst werden vom Benutzer aus der Liste der verfügbaren Datensätze auf Metamodellebene festgelegt.
- Einschränkung der Felder, die für die Gruppierung auf der einen oder anderen Ebene verfügbar sind, unter Berücksichtigung der Felder, die auf höheren Gruppierungsebenen ausgewählt wurden (wenn beispielsweise „Stadt“ auf der 1. Ebene ausgewählt wurde, sollte dieser Parameter auf der 2. oder 3. Ebene nicht verfügbar sein m Gruppierungsebenen)
- die Möglichkeit der Gruppierung nach erweiterten Zeitparametern: Wochentag, Stundengruppe (11-12; 12-13), Woche
- Unterstützung für berechnete Basisaggregate: (Minimum, Maximum, Durchschnitt, Median, Menge, Anzahl eindeutiger Aggregate);
- Unterstützung für Testfilter zur Bereitstellung einer Volltextsuche in der Auswahl;
- Unterstützung bei der Anzeige der Anreicherung und Transformation von Daten, die auf Anfrage auf der Grundlage von Daten aus externen Verzeichnissen oder Quellen erhalten wurden.
- Das System sollte über Mechanismen zur Berechnung von Metriken in Raumkoordinaten (sp = Raumpunkt) verfügen, um die Geoanalytik zu unterstützen.
- Für Zeitmetriken (Transaktionen, Operationen, Abfragen, ...) muss das System die Dichte der Verteilung der Abfrageausführungszeit berechnen und anzeigen.
- Alle berechneten Indikatoren sollten für alle Objekte als Ganzes sowie für vom Benutzer mithilfe von Filtern festgelegte Teilproben durchgeführt werden
- Das System muss alle Berechnungen im Speicher ausführen.
- Alle Ereignisse haben einen Zeitstempel, daher muss das System die Arbeit mit äquidistanten und willkürlichen Zeitreihen unterstützen.
- Das System sollte die Fähigkeit unterstützen, Mechanismen zum Wiederherstellen fehlender Daten in Zeitreihen (verschiedene Algorithmen), zum Ermitteln von Anomalien, zum Vorhersagen von Zeitreihen und zum Klassifizieren / Clustering zu konfigurieren und zu aktivieren.
Schnittstellenteil
- Die gesamte Benutzeroberfläche, einschließlich des Inhalts von Grafik- und Tabellenelementen, muss lokalisiert werden.
- Für Steuerelemente und Spalten mit tabellarischen Darstellungen sollte die Möglichkeit unterstützt werden, QuickInfos mit einer detaillierten Beschreibung (Schwebespitze) zu erstellen, die sowohl statisch als auch dynamisch erstellt werden (in der QuickInfo können beispielsweise die zur Berechnung verwendeten Parameter enthalten sein).
- Die Arbeitsplatzschnittstelle sollte nur unter Verwendung von HTML-, CSS- und JS-Technologien erstellt werden, ohne dass veraltete, plattformabhängige oder nicht portierbare Technologien wie Adobe Flash, MS Silverlight usw. verwendet werden.
- Die Zeit in den Diagrammen sollte im 24-Stunden-Format angezeigt werden.
- Parameter für die Anzeige von Daten auf Achsen sollten je nach Wertebereich die automatische Skalierung (Häufigkeit der Beschriftungen und Anzeigeformat) unterstützen. Ein typisches Beispiel ist die Anzeige von Stunden mit einem Messbereich innerhalb eines Tages, die Anzeige von Tagen mit einem Messbereich innerhalb einer Woche.
- Das System sollte mindestens die folgenden atomaren Grafikanzeigeformate unterstützen:
- Histogramm (Balken)
- Spot
- Linear
- Heatmap
- Konturen (Konturen)
- Kreisdiagramme
- Das System muss die Fähigkeit unterstützen, Markierungen (z. B. Werte) einer bestimmten Teilmenge von Punkten mit einer minimalen Überlappung dieser Markierungen intelligent automatisch zu platzieren.
- Das System sollte die Möglichkeit unterstützen, Daten aus verschiedenen Datenquellen in einer grafischen Darstellung zu kombinieren. Die Möglichkeit, für jede Datenquelle unterschiedliche atomare Grafikanzeigeformate anzugeben, sollte unterstützt werden, sofern die Koordinatenachsen und der Typ des Koordinatensystems übereinstimmen.
- Das System sollte die Facettenverteilung (Partitionierung von Graphen auf dem Gitter M x N) von Atomgraphen für eine gegebene Parametrisierungsvariable unterstützen. In der Facettenanzeige muss für jedes Diagramm eine unabhängige Skalierung sowohl der X-Achse als auch der Y-Achse möglich sein.
- Diagramme müssen die Parametrisierung der folgenden Merkmale unterstützen:
- Farbe
- Linien- oder Punkttyp
- Die Dicke der Linie oder des Umrisses des Punktes
- Punktgröße
- Transparenz
- Für die Aufgaben der Geoanalyse von Daten muss das System die Arbeit mit Shapefiles unterstützen, einschließlich Import, Anzeige und flächenparametrierter Farbgebung, und sicherstellen, dass dem generierten Geopod verschiedene grafische Elemente und berechnete Indikatoren überlagert werden.
- Steuerelemente der Benutzeroberfläche (Listen, Felder, Bedienfelder usw.) müssen die dynamische Änderung ihres Inhalts in Abhängigkeit vom Status anderer Elemente unterstützen. Wenn Sie beispielsweise eine bestimmte Region auswählen, sollte der Inhalt des Stadtauswahlelements auf die Liste der in der Region enthaltenen Städte beschränkt sein.
- Das Vorbild für den Zugriff auf Berichtsanwendungen sollte unterstützt werden:
- Unterstützung für Datenmetamodelle zur Bereitstellung des Rollenzugriffs auf URL-Ebene (möglich / unmöglich)
- Unterstützung eines Datenmetamodells zur Bereitstellung eines rollenbasierten Zugriffs auf Inhaltsebene eines Steuerelements (z. B. wird die Liste der verfügbaren Objekte in Dropdown-Listen durch die regionale Verantwortung des Managers bestimmt).
- Unterstützung des Datenmetamodells, um einen rollenbasierten Zugriff auf der Ebene der Visualisierung personenbezogener Daten sicherzustellen (z. B. Maskieren von „*“ eines bestimmten Teils von E-Mail-Nummern oder anderen Feldern)
Fazit
Der Hauptzweck der Veröffentlichung ist es zu zeigen, dass die Möglichkeiten von R ziemlich stark über die Grenzen der klassischen Statistik hinausgehen. Es wird praktisch geprüft, es ist nicht notwendig, Qualität oder Funktionalität zu opfern.
Vorheriger Beitrag - „Wie gut ist das Open-Source-Ökosystem von R zur Lösung von Geschäftsproblemen?“ .