Eine der beliebtesten und am meisten diskutierten Nachrichten der letzten Jahre ist, wer künstliche Intelligenz hinzugefügt hat, wo und welche Hacker was und wo gebrochen haben. Durch die Kombination dieser Themen erscheinen sehr interessante Studien, und es gab bereits mehrere Artikel auf dem Hub, die Modelle für maschinelles Lernen täuschen konnten, zum Beispiel: einen Artikel über die Grenzen des tiefen Lernens und darüber, wie man neuronale Netze anlockt . Des Weiteren möchte ich dieses Thema unter dem Gesichtspunkt der Computersicherheit genauer betrachten:

Berücksichtigen Sie die folgenden Punkte:
- Wichtige Begriffe.
- Was ist maschinelles Lernen, wenn Sie es plötzlich noch nicht wussten?
- Was hat Computersicherheit damit zu tun ?!
- Ist es möglich, das Modell des maschinellen Lernens zu manipulieren, um einen gezielten Angriff durchzuführen?
- Kann die Systemleistung beeinträchtigt werden?
- Kann ich die Einschränkungen von Modellen für maschinelles Lernen nutzen?
- Kategorisierung von Angriffen.
- Schutzmöglichkeiten.
- Mögliche Folgen.
1. Das erste, mit dem ich beginnen möchte, ist die Terminologie.
Diese mögliche Aussage kann aufgrund der bereits in russischer Sprache verfassten Artikel zu einem großen Holivar sowohl in der Wissenschaft als auch in der Fachwelt führen. Ich möchte jedoch darauf hinweisen, dass der Begriff „gegnerische Intelligenz“ als „feindliche Intelligenz“ übersetzt wird. Und das Wort "Widersacher" selbst sollte nicht mit dem juristischen Begriff "Widersacher" übersetzt werden, sondern mit einem geeigneteren Begriff aus dem Sicherheitsbereich "bösartig" (es gibt keine Beschwerden über die Übersetzung des Namens der Architektur des neuronalen Netzwerks). Dann haben alle verwandten Begriffe auf Russisch eine viel hellere Bedeutung, wie z. B. „gegnerisches Beispiel“ - eine böswillige Dateninstanz, „widersprüchliche Einstellungen“ - eine böswillige Umgebung. Und genau der Bereich, den wir als „kontroverses maschinelles Lernen“ betrachten werden, ist böswilliges maschinelles Lernen.
Zumindest im Rahmen dieses Artikels werden solche Begriffe in russischer Sprache verwendet. Ich hoffe, dass gezeigt werden kann, dass es in diesem Thema viel mehr um Sicherheit geht, um Begriffe aus diesem Bereich fair zu verwenden, als um das erste Beispiel eines Übersetzers.
Nun, da wir bereit sind, dieselbe Sprache zu sprechen, können wir im Wesentlichen anfangen :)
2. Was ist maschinelles Lernen, wenn Sie es plötzlich noch nicht wussten?
Na ja, noch im WissenMit Methoden des maschinellen Lernens meinen wir normalerweise Methoden zum Konstruieren von Algorithmen, die lernen und handeln können, ohne ihr Verhalten explizit auf vorgewählten Daten zu programmieren. Mit Daten können wir alles meinen, wenn wir es mit einigen Zeichen beschreiben oder messen können. Wenn es ein Zeichen gibt, das für einige Daten unbekannt ist, das wir aber wirklich benötigen, verwenden wir Methoden des maschinellen Lernens, um dieses Zeichen basierend auf bereits bekannten Daten wiederherzustellen oder vorherzusagen.
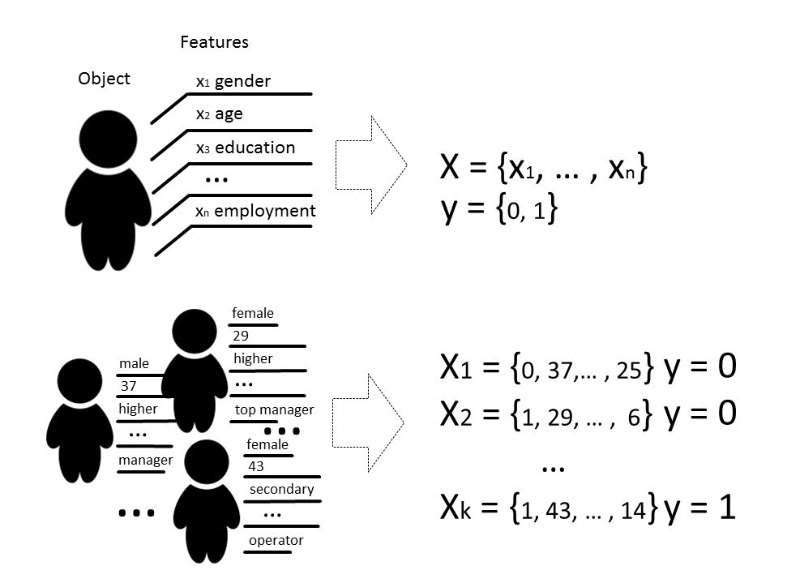
Es gibt verschiedene Arten von Problemen, die mit Hilfe des maschinellen Lernens gelöst werden können, aber wir werden hauptsächlich über das Klassifizierungsproblem sprechen.
Klassischerweise besteht der Zweck der Trainingsphase des Klassifikatormodells darin, eine Beziehung (Funktion) auszuwählen, die die Entsprechung zwischen den Merkmalen eines bestimmten Objekts und einer der bekannten Klassen zeigt. In einem komplexeren Fall ist eine Vorhersage der Wahrscheinlichkeit einer Zugehörigkeit zu einer bestimmten Kategorie erforderlich.
Das heißt, die Klassifizierungsaufgabe besteht darin, eine solche Hyperebene zu erstellen, die den Raum teilt, wobei seine Dimension in der Regel die Größe des Merkmalsvektors ist, so dass Objekte verschiedener Klassen auf gegenüberliegenden Seiten dieser Hyperebene liegen.
Für einen zweidimensionalen Raum ist eine solche Hyperebene eine Linie. Betrachten Sie ein einfaches Beispiel:

Auf dem Bild sehen Sie zwei Klassen, Quadrate und Dreiecke. Es ist unmöglich, die Abhängigkeit zu finden und sie am genauesten durch eine lineare Funktion zu teilen. Daher kann mit Hilfe des maschinellen Lernens eine nichtlineare Funktion ausgewählt werden, die am besten zwischen diesen beiden Sätzen unterscheidet.
Die Klassifizierungsaufgabe ist eine ziemlich typische Unterrichtsaufgabe mit einem Lehrer. Um das Modell zu trainieren, ist ein solcher Datensatz erforderlich, damit die Merkmale des Objekts und seiner Klasse unterschieden werden können.
3. Was hat Computersicherheit damit zu tun ?!
In der Computersicherheit werden seit langem verschiedene Methoden des maschinellen Lernens bei der Spam-Filterung, der Verkehrsanalyse und der Erkennung von Betrug oder Malware verwendet.
In gewisser Weise ist dies ein Spiel, bei dem Sie nach einem Zug erwarten, dass der Feind reagiert. Daher müssen Sie bei diesem Spiel die Modelle ständig anpassen, neue Daten lehren oder sie vollständig ändern, um die neuesten wissenschaftlichen Erkenntnisse zu berücksichtigen.
Während Antivirenprogramme beispielsweise Signaturanalysen, manuelle Heuristiken und Regeln verwenden, die nur schwer zu warten und zu erweitern sind, streitet die Sicherheitsbranche immer noch über die tatsächlichen Vorteile von Antivirenprogrammen, und viele betrachten Antivirenprogramme als totes Produkt. Angreifer umgehen all diese Regeln beispielsweise mit Hilfe von Verschleierung und Polymorphismus. Aus diesem Grund werden Tools bevorzugt, die intelligentere Techniken verwenden, z. B. Methoden des maschinellen Lernens, mit denen Funktionen automatisch ausgewählt werden (auch solche, die nicht vom Menschen interpretiert werden), große Informationsmengen schnell verarbeiten, verallgemeinern und schnell Entscheidungen treffen können.
Das heißt, einerseits wird maschinelles Lernen als Schutzinstrument eingesetzt. Andererseits wird dieses Tool auch für intelligentere Angriffe verwendet.
Mal sehen, ob dieses Tool anfällig sein kann?
Für jeden Algorithmus ist nicht nur die Auswahl der Parameter sehr wichtig, sondern auch die Daten, auf denen der Algorithmus trainiert wird. In einer idealen Situation ist es natürlich notwendig, dass genügend Daten für das Training vorhanden sind, die Klassen ausgewogen sind und die Zeit für das Training unbemerkt bleibt, was im wirklichen Leben praktisch unmöglich ist.
Unter der Qualität eines trainierten Modells wird normalerweise die Genauigkeit der Klassifizierung von Daten verstanden, die das Modell im allgemeinen Fall noch nicht „gesehen“ hat, als ein bestimmtes Verhältnis korrekt klassifizierter Datenkopien zur Gesamtmenge der Daten, die wir an das Modell übertragen haben.
Im Allgemeinen stehen alle Qualitätsbewertungen in direktem Zusammenhang mit Annahmen über die erwartete Verteilung der Eingabedaten des Systems und berücksichtigen nicht die schädlichen Umgebungsbedingungen ( widersprüchliche Einstellungen ), die häufig über die erwartete Verteilung der Eingabedaten hinausgehen. Unter einer böswilligen Umgebung wird eine Umgebung verstanden, in der es möglich ist, mit dem System zu konfrontieren oder mit ihm zu interagieren. Typische Beispiele für solche Umgebungen sind Spamfilter, Betrugserkennungsalgorithmen und Malware-Analysesysteme.
Somit kann die Genauigkeit als Maß für die durchschnittliche Systemleistung bei durchschnittlicher Nutzung angesehen werden, während die Sicherheitsbewertung an der schlechtesten Implementierung interessiert ist.
Das heißt, normalerweise werden Modelle für maschinelles Lernen in einer ziemlich statischen Umgebung getestet, in der die Genauigkeit von der Datenmenge für jede bestimmte Klasse abhängt, in Wirklichkeit jedoch nicht die gleiche Verteilung garantiert werden kann. Und wir sind daran interessiert, das Modell falsch zu machen. Dementsprechend ist es unsere Aufgabe, so viele Vektoren wie möglich zu finden, die das falsche Ergebnis liefern.
Wenn sie über die Sicherheit eines Systems oder Dienstes sprechen, bedeutet dies normalerweise, dass es unmöglich ist, eine Sicherheitsrichtlinie innerhalb eines bestimmten Bedrohungsmodells in Hardware oder Software zu verletzen, indem versucht wird, das System sowohl in der Entwicklungsphase als auch in der Testphase zu überprüfen. Heutzutage arbeiten jedoch eine Vielzahl von Diensten auf der Grundlage von Datenanalysealgorithmen. Die Risiken liegen daher nicht nur in der anfälligen Funktionalität, sondern auch in den Daten selbst, auf deren Grundlage das System Entscheidungen treffen kann.
Niemand steht still und Hacker beherrschen auch etwas Neues. Und die Methoden, die helfen, Algorithmen für maschinelles Lernen auf die Möglichkeit eines Kompromisses durch einen Angreifer zu untersuchen, der Kenntnisse über die Funktionsweise des Modells nutzen kann, werden als kontroverses maschinelles Lernen bezeichnet , oder auf Russisch handelt es sich immer noch um böswilliges maschinelles Lernen .
Wenn wir über die Sicherheit von Modellen des maschinellen Lernens unter dem Gesichtspunkt der Informationssicherheit sprechen, möchte ich konzeptionell mehrere Aspekte berücksichtigen.
4. Ist es möglich, das Modell des maschinellen Lernens zu manipulieren, um einen gezielten Angriff durchzuführen?
Hier ist ein gutes Beispiel für die Suchmaschinenoptimierung. Die Leute untersuchen, wie intelligente Suchmaschinenalgorithmen funktionieren, und manipulieren die Daten auf ihren Websites, um im Suchranking höher zu sein. Die Frage nach der Sicherheit eines solchen Systems ist in diesem Fall erst dann so akut, wenn einige Daten kompromittiert oder schwerwiegende Schäden verursacht wurden.
Als Beispiel für ein solches System können Dienste angeführt werden, die im Wesentlichen Online-Modelltraining verwenden, dh Training, bei dem das Modell Daten in einer sequentiellen Reihenfolge empfängt, um die aktuellen Parameter zu aktualisieren. Wenn Sie wissen, wie das System trainiert ist, können Sie den Angriff planen und das System mit vorbereiteten Daten versorgen.
Auf diese Weise werden beispielsweise biometrische Systeme getäuscht , die ihre Parameter schrittweise aktualisieren, wenn kleine Änderungen im Aussehen einer Person auftreten , beispielsweise mit einer natürlichen Änderung des Alters , was in diesem Fall eine absolut natürliche und notwendige Funktionalität des Dienstes ist. Mit dieser Eigenschaft des Systems können Sie die Daten vorbereiten und an das biometrische System senden. Dabei wird das Modell aktualisiert, bis die Parameter an eine andere Person aktualisiert werden. Auf diese Weise trainiert der Angreifer das Modell neu und kann sich anstelle des Opfers identifizieren.

Dieses Problem ergibt sich ganz natürlich aus der Tatsache, dass das Modell des maschinellen Lernens häufig in einer eher statischen Umgebung getestet wird und seine Qualität durch die Verteilung der Daten bewertet wird, auf denen das Modell trainiert wurde. Gleichzeitig werden sehr oft sehr spezifische Fragen an Datenanalysespezialisten gestellt, die das Modell beantworten muss:
- Ist die Datei bösartig?
- Gehört diese Transaktion zum Betrug?
- Ist der aktuelle Verkehr legitim?
Und es wird erwartet, dass der Algorithmus nicht 100% genau sein kann, sondern nur mit einer gewissen Wahrscheinlichkeit das Objekt einer Klasse zuordnen kann. Daher müssen wir bei Fehlern der ersten und zweiten Art nach Kompromissen suchen, wenn unser Algorithmus nicht ganz sicher sein kann in seiner Wahl und immer noch falsch.
Nehmen Sie ein System, das sehr oft Fehler der ersten und zweiten Art erzeugt. Beispielsweise hat das Antivirenprogramm Ihre Datei blockiert, weil es als bösartig eingestuft wurde (obwohl dies nicht der Fall ist), oder das Antivirenprogramm hat eine böswillige Datei übersprungen. In diesem Fall hält der Benutzer des Systems es für ineffektiv und schaltet es meistens einfach aus, obwohl es wahrscheinlich ist, dass ein Satz solcher Daten gerade abgefangen wurde.
Und der Datensatz, auf dem das Modell das schlechteste Ergebnis zeigt, existiert immer. Die Aufgabe des Angreifers besteht darin, nach solchen Daten zu suchen, um das System auszuschalten. Solche Situationen sind eher unangenehm, und das Modell sollte sie natürlich vermeiden. Und Sie können sich das Ausmaß der Folgen der Untersuchung aller falschen Vorfälle vorstellen!
Fehler der ersten Art werden als Zeitverschwendung wahrgenommen, während Fehler der zweiten Art als verpasste Gelegenheit wahrgenommen werden. Obwohl in der Tat die Kosten für diese Arten von Fehlern für jedes spezifische System unterschiedlich sein können. Wenn ein Antivirenprogramm billiger sein kann, kann es ein Fehler der ersten Art sein, da es besser ist, auf Nummer sicher zu gehen und zu sagen, dass die Datei bösartig ist. Wenn der Client das System herunterfährt und sich herausstellt, dass die Datei wirklich böswillig ist, bleibt das Antivirenprogramm „wie gewarnt“ und die Verantwortung beim Benutzer. Wenn wir zum Beispiel ein System für die medizinische Diagnostik verwenden, sind beide Fehler ziemlich teuer, da der Patient in jedem Fall dem Risiko einer falschen Behandlung und eines Gesundheitsrisikos ausgesetzt ist.
6. Kann ein Angreifer die Eigenschaften einer maschinellen Lernmethode verwenden, um das System zu stören? Das heißt, ohne den Lernprozess zu stören, finden Sie solche Modellbeschränkungen, die offensichtlich falsche Vorhersagen liefern.
Es scheint, dass Deep-Learning-Systeme praktisch vor menschlichen Eingriffen in die Auswahl von Zeichen geschützt sind, so dass man sagen kann, dass es keinen menschlichen Faktor gibt, wenn Entscheidungen durch das Modell getroffen werden. Der ganze Reiz des tiefen Lernens besteht darin, dass es ausreicht, die Eingabe des Modells fast als „Rohdaten“ zu betrachten, und das Modell selbst hebt durch mehrere lineare Transformationen die Merkmale hervor, die es als am wichtigsten erachtet und eine Entscheidung trifft. Aber ist es wirklich so gut?
Es gibt Arbeiten, die die Methoden zur Vorbereitung solcher böswilligen Beispiele im Deep-Learning-Modell beschreiben, das das System falsch klassifiziert. Eines der wenigen, aber beliebten Beispiele ist ein Artikel über effektive physische Angriffe auf Deep-Learning-Modelle.
Die Autoren führten Experimente durch und schlugen Methoden zur Umgehung von Modellen vor, die auf der Einschränkung des tiefen Lernens basieren und das "Vision" -System am Beispiel der Erkennung von Verkehrszeichen täuschen. Für ein positives Ergebnis reicht es für die Angreifer aus, solche Bereiche auf dem Objekt zu finden, die den Klassifikator am stärksten niederschlagen, und es ist falsch. Die Experimente wurden an der Marke „STOP“ durchgeführt, die aufgrund von Änderungen bei den Forschern das Modell als Marke „SPEED LIMIT 45“ qualifizierte. Sie testeten ihren Ansatz an anderen Zeichen und erzielten ein positives Ergebnis.
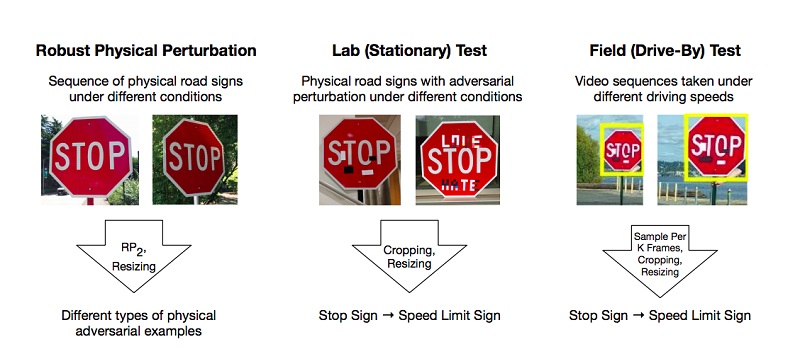
Infolgedessen schlugen die Autoren zwei Möglichkeiten vor, mit denen das maschinelle Lernsystem ausgetrickst werden kann: Poster-Druck-Angriff, der eine Reihe kleiner Änderungen am gesamten Umfang der Marke impliziert, Tarnung genannt, und Aufkleber-Angriffe, wenn einige Aufkleber in bestimmten Bereichen auf die Marke geschichtet wurden.
Aber das sind ganz Lebenssituationen - wenn sich das Schild im Schmutz von Straßenstaub befindet oder wenn junge Talente ihre Arbeit daran aufgeben. Es ist wahrscheinlich, dass künstliche Intelligenz und Kunst keinen Platz in einer Welt haben.

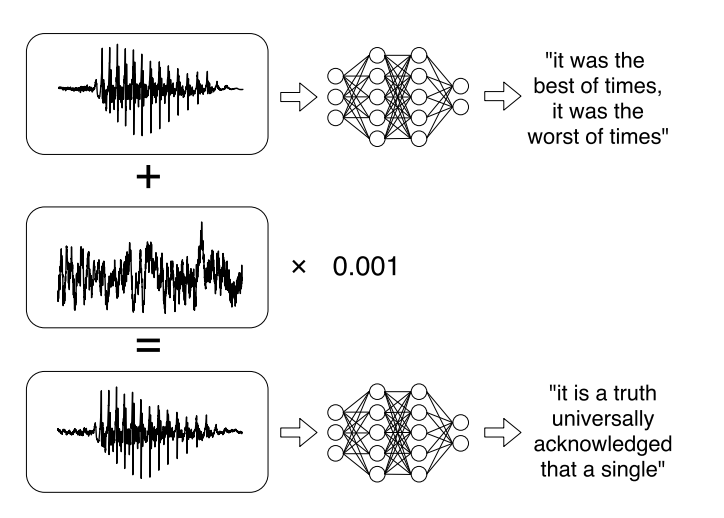
Oder neuere Forschungen zu gezielten Angriffen auf automatische Spracherkennungssysteme . Sprachnachrichten sind bei der Kommunikation in sozialen Netzwerken zu einem Trend geworden, aber das Abhören ist nicht immer bequem. Daher gibt es Dienste, mit denen Sie eine Audioaufnahme in Text übertragen können. Die Autoren der Arbeit lernten, das Original-Audio zu analysieren, das Tonsignal zu berücksichtigen und dann ein weiteres Tonsignal zu erzeugen, das dem Original zu 99% ähnlich ist, indem sie eine kleine Änderung hinzufügten. Infolgedessen entschlüsselt der Klassifizierer den Datensatz wie vom Angreifer gewünscht.
7. In dieser Hinsicht wäre es möglich, bestehende Angriffe auf verschiedene Arten zu kategorisieren:
Nach der Expositionsmethode (Einfluss):
- Verursachende Angriffe wirken sich auf das Modelltraining durch Interferenzen im Trainingssatz aus.
- Explorative Angriffe verwenden Klassifikatorfehler, ohne den Trainingssatz zu beeinflussen.
Sicherheitsverletzung:
- Integritätsangriffe gefährden das System durch Fehler der zweiten Art.
- Verfügbarkeitsangriffe führen zu einem Herunterfahren des Systems, normalerweise basierend auf Fehlern der ersten Art.
Spezifität:
- Gezielter Angriff (gezielter Angriff) zielt darauf ab, die Vorhersage des Klassifikators auf eine bestimmte Klasse zu ändern.
- Massenangriff (wahlloser Angriff) zielt darauf ab, die Reaktion des Klassifikators auf eine andere Klasse als die richtige zu ändern.
Der Zweck der Sicherheit besteht darin, Ressourcen vor einem Angreifer zu schützen und Anforderungen einzuhalten, deren Verstöße zu einer teilweisen oder vollständigen Gefährdung einer Ressource führen.
Aus Sicherheitsgründen werden verschiedene Modelle für maschinelles Lernen verwendet. Virenerkennungssysteme zielen beispielsweise darauf ab, die Anfälligkeit für Viren zu verringern, indem sie erkannt werden, bevor das System infiziert wird, oder ein vorhandenes Virus zum Entfernen zu erkennen. Ein weiteres Beispiel ist das Intrusion Detection System (IDS), das erkennt, dass ein System durch Erkennen von böswilligem Datenverkehr oder verdächtigem Verhalten im System kompromittiert wurde. Eine weitere enge Aufgabe ist das Intrusion Prevention System (IPS), das Intrusionsversuche erkennt und das Eindringen in das System verhindert.
Im Zusammenhang mit Sicherheitsproblemen besteht das Ziel von Modellen für maschinelles Lernen im Allgemeinen darin, böswillige Ereignisse zu trennen und zu verhindern, dass sie das System stören.
Im Allgemeinen kann das Ziel in zwei Teile geteilt werden:
Integrität : Verhindert, dass ein Angreifer auf Systemressourcen zugreift
Zugänglichkeit : Verhindern Sie, dass ein Angreifer den normalen Betrieb stört.
Es besteht ein eindeutiger Zusammenhang zwischen Fehlern des zweiten Typs und Integritätsverletzungen: Böswillige Instanzen, die in das System übertragen werden, können schädlich sein. Genau wie Fehler der ersten Art normalerweise die Zugänglichkeit verletzen, weil das System selbst zuverlässige Kopien der Daten ablehnt.
8. Wie kann man sich vor Cyberkriminellen schützen, die Modelle des maschinellen Lernens manipulieren?
Derzeit ist es schwieriger, ein Modell für maschinelles Lernen vor böswilligen Angriffen zu schützen, als es anzugreifen. Nur weil das Modell unabhängig davon, wie viel wir trainieren, immer einen Datensatz enthält, für den es am schlechtesten funktioniert.
Und heute gibt es keine ausreichend effektiven Möglichkeiten, um das Modell mit 100% iger Genauigkeit arbeiten zu lassen. Es gibt jedoch einige Tipps, die das Modell widerstandsfähiger gegen böswillige Beispiele machen können.
Hier ist das Wichtigste: Wenn es möglich ist, maschinelle Lernmodelle in einer böswilligen Umgebung nicht zu verwenden, ist es besser, sie nicht zu verwenden. Es macht keinen Sinn, maschinelles Lernen abzulehnen, wenn Sie vor der Aufgabe stehen, Bilder zu klassifizieren oder Memes zu generieren. Es ist kaum möglich, einen signifikanten Schaden zuzufügen, der im Falle eines vorsätzlichen Angriffs zu sozial oder wirtschaftlich bedeutenden Konsequenzen führen würde. , , , , , .
, , , . .
, , . , , , , , , , . , , , , , , .
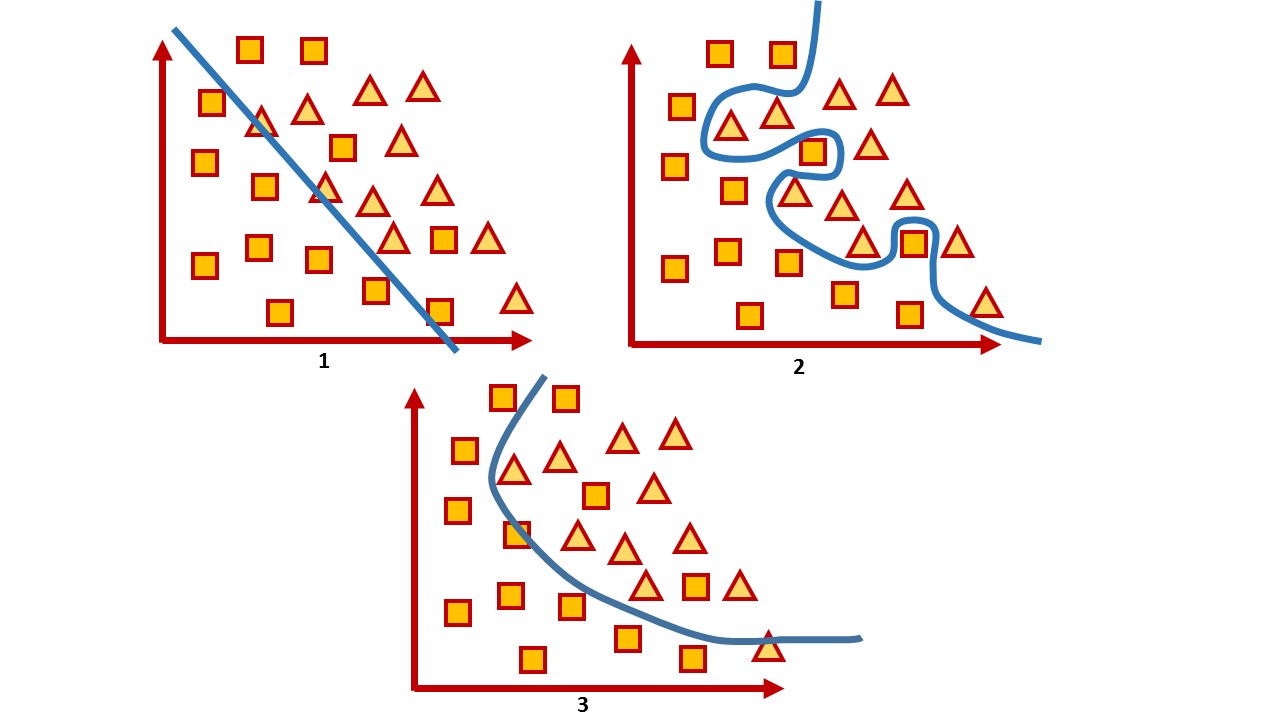
1 — , 2 — , 3 —
, , : . . , .
. , . , . 100%- - , .
- , — . , — , . , .
, , .
9. ?
. : , , , , .
, . . , . , , , «».
, - , . , , . - Twitter, Microsoft, .
? , , — , , . , , , — , , .
, , , « — , »?