Massachusetts Institute of Technology. Vorlesung # 6.858. "Sicherheit von Computersystemen." Nikolai Zeldovich, James Mickens. 2014 Jahr
Computer Systems Security ist ein Kurs zur Entwicklung und Implementierung sicherer Computersysteme. Die Vorträge behandeln Bedrohungsmodelle, Angriffe, die die Sicherheit gefährden, und Sicherheitstechniken, die auf jüngsten wissenschaftlichen Arbeiten basieren. Zu den Themen gehören Betriebssystemsicherheit, Funktionen, Informationsflussmanagement, Sprachsicherheit, Netzwerkprotokolle, Hardwaresicherheit und Sicherheit von Webanwendungen.
Vorlesung 1: „Einführung: Bedrohungsmodelle“
Teil 1 /
Teil 2 /
Teil 3Vorlesung 2: „Kontrolle von Hackerangriffen“
Teil 1 /
Teil 2 /
Teil 3 Können Sie mir sagen, was das Fehlen eines Sicherheitsansatzes ist, der eine
Schutzseite verwendet ?
Teilnehmerin: Es dauert länger!
Professor: genau! Stellen Sie sich also vor, dieser Haufen ist sehr, sehr klein, aber ich habe eine ganze Seite ausgewählt, um sicherzustellen, dass dieses kleine Ding nicht von einem Zeiger angegriffen wurde. Dies ist ein sehr räumlich intensiver Prozess, und die Leute setzen so etwas nicht in einer Arbeitsumgebung ein. Dies kann nützlich sein, um "Fehler" zu testen, aber Sie würden dies niemals für ein echtes Programm tun. Ich denke, jetzt verstehen Sie, was ein
Elektrozaun- Speicher-Debugger ist.
Teilnehmerin: Warum sollte die
Schutzseite so groß sein?
Professor: Der Grund dafür ist, dass sie normalerweise auf Hardware wie den Schutz auf Seitenebene angewiesen sind, um die Seitengrößen zu bestimmen. Bei den meisten Computern werden jedem zugewiesenen Puffer 2 Seiten mit einer Größe von 4 KB zugewiesen, insgesamt 8 KB. Da der Heap aus Objekten besteht, wird jeder
Malloc- Funktion eine separate Seite zugewiesen. In einigen Modi gibt dieser Debugger den reservierten Speicherplatz nicht an das Programm zurück, sodass der
Elektrozaun in Bezug auf den Speicher sehr unersättlich ist und nicht mit Arbeitscode kompiliert werden sollte.
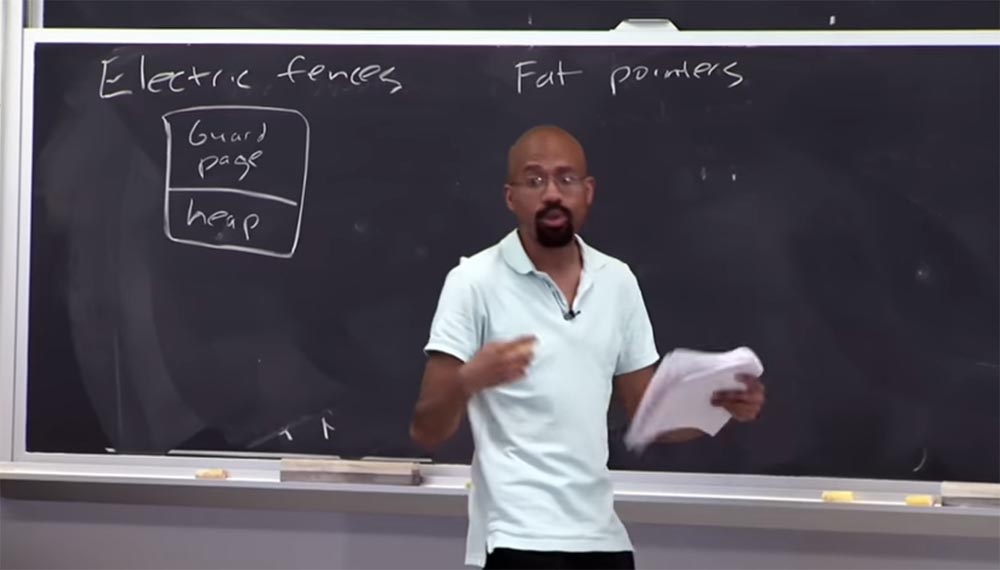
Ein weiterer Sicherheitsansatz, der einen Blick wert ist, heißt
Fat Pointers oder "Thick Pointers". In diesem Fall bedeutet der Begriff "dick", dass eine große Datenmenge an den Zeiger angehängt wird. In diesem Fall besteht die Idee darin, die Darstellung des Zeigers zu ändern, um Informationen über die Grenzen in seine Zusammensetzung aufzunehmen.
Ein regulärer 32-Bit-Zeiger besteht aus 32 Bit, und Adressen befinden sich darin. Wenn wir den "dicken Zeiger" betrachten, dann besteht er aus 3 Teilen. Der erste Teil ist eine 4-Byte-Basis, an die auch ein Ende von 4 Bytes angehängt ist. Im ersten Teil beginnt das Objekt, im zweiten endet es und im dritten, ebenfalls 4 Byte, ist die Adresse
cur eingeschlossen. Und innerhalb dieser gemeinsamen Grenzen befindet sich ein Zeiger.

Wenn der Compiler einen Zugriffscode für diesen "dicken Zeiger" generiert, aktualisiert er den Inhalt des letzten Teils der
aktuellen Adresse und überprüft gleichzeitig den Inhalt der ersten beiden Teile, um sicherzustellen, dass während des Aktualisierungsvorgangs nichts Schlimmes mit dem Zeiger passiert ist.
Stellen Sie sich vor, ich habe diesen Code:
int * ptr = malloc (8) , dies ist ein Zeiger, dem 8 Bytes zugewiesen sind. Als nächstes habe ich eine
while-Schleife , die gerade dabei ist, dem Zeiger einen Wert zuzuweisen, und dann folgt das
ptr ++ - Zeigerinkrement. Jedes Mal, wenn dieser Code an der aktuellen Adresse des aktuellen Adresszeigers ausgeführt wird, wird geprüft, ob sich der Zeiger innerhalb der im ersten und zweiten Teil angegebenen Grenzen befindet.
Dies ist bei dem neuen Code der Fall, den der Compiler generiert. Eine Online-Gruppe wirft häufig die Frage auf, was „Werkzeugcode“ ist. Dies ist der Code, den der Compiler generiert. Als Programmierer sehen Sie nur das, was rechts angezeigt wird - diese 4 Zeilen. Vor dieser Operation fügt der Compiler jedoch einen neuen C-Code in die
aktuelle Adresse ein , weist dem Zeiger einen Wert zu und überprüft jedes Mal die Grenzen.

Und wenn bei Verwendung des neuen Codes der Wert die Grenzen überschreitet, wird die Funktion unterbrochen. Dies wird als "Werkzeugcode" bezeichnet. Dies bedeutet, dass Sie den Quellcode mit einem C-Programm verwenden, dann den neuen C-Quellcode hinzufügen und dann das neue Programm kompilieren. Die Grundidee hinter
Fat Pointers ist also ziemlich einfach.
Dieser Ansatz weist einige Nachteile auf. Der größte Nachteil ist die Größe des Zeigers. Dies bedeutet, dass Sie den "dicken Zeiger" nicht einfach unverändert außerhalb der Shell-Bibliothek übergeben können. Möglicherweise wird erwartet, dass der Zeiger eine Standardgröße hat, und das Programm stellt ihm diese Größe zur Verfügung, in die er „nicht passt“, wodurch alles explodiert. Es gibt auch Probleme, wenn Sie Zeiger dieses Typs in eine
Struktur oder ähnliches aufnehmen möchten, da sie die Größe der
Struktur ändern können.
Daher ist es in C-Code sehr beliebt, etwas von der Größe einer
Struktur zu nehmen und dann etwas basierend auf dieser Größe zu tun - reservieren Sie Speicherplatz für Strukturen dieser Größe und so weiter.
Und noch heikler ist, dass diese Zeiger in der Regel nicht atomar aktualisiert werden können. Für 32-Bit-Architekturen ist es typisch, eine atomare 32-Bit-Variable zu schreiben. "Dicke Zeiger" enthalten jedoch 3
Ganzzahlgrößen. Wenn Sie also Code haben, der erwartet, dass der Zeiger einen atomaren Wert hat, können Probleme auftreten. Denn um einige dieser Überprüfungen durchzuführen, müssen Sie sich die aktuelle Adresse und dann die Größen ansehen, und dann müssen Sie sie möglicherweise erhöhen, und so weiter und so fort. Dies kann daher zu sehr subtilen Fehlern führen, wenn Sie Code verwenden, der versucht, Parallelen zwischen regulären und dicken Zeigern zu ziehen. Daher können Sie in einigen Fällen
Fettzeiger wie
Elektrozäune verwenden , aber die Nebenwirkungen ihrer Verwendung sind so bedeutend, dass diese Ansätze in der normalen Praxis nicht verwendet werden.
Und jetzt werden wir über das Überprüfen von Grenzen in Bezug auf die Struktur von Schattendaten sprechen. Die Hauptidee der Struktur besteht darin, dass Sie wissen, wie groß jedes Objekt ist, das Sie platzieren möchten, dh dass Sie die Größe kennen, die Sie für dieses Objekt reservieren müssen. Wenn Sie beispielsweise einen Zeiger haben, den Sie mit der Funktion
malloc aufrufen, müssen Sie die Größe des Objekts angeben:
char xp = malloc (Größe) .

Wenn Sie so etwas wie eine statische Variable wie dieses
char p [256] haben , kann der Compiler automatisch herausfinden, welche Grenzen für seine Platzierung gelten sollen.
Daher müssen Sie für jeden dieser Zeiger zwei Operationen einfügen. Dies ist hauptsächlich eine Arithmetik wie
q = p + 7 oder ähnliches. Diese Einfügung erfolgt durch Dereferenzieren eines Links vom Typ
deref * q = 'q' . Sie fragen sich vielleicht, warum Sie sich beim Einfügen nicht auf den Link verlassen können? Warum müssen wir diese Arithmetik machen? Tatsache ist, dass Sie bei Verwendung von C und c ++ einen Zeiger haben, der auf einen Durchgang zum gültigen Ende des Objekts auf der rechten Seite zeigt. Danach verwenden Sie ihn als Stoppbedingung. Sie gehen also zum Objekt und sobald Sie diesen nachfolgenden Zeiger erreichen, stoppen Sie tatsächlich die Schleife oder brechen die Operation ab.
Wenn wir also die Arithmetik ignorieren, verursachen wir immer einen schwerwiegenden Fehler, bei dem der Zeiger die Grenzen überschreitet, was die Arbeit vieler Anwendungen tatsächlich stören kann. Wir können also nicht einfach den Link einfügen, denn woher wissen Sie, dass dies außerhalb der festgelegten Grenzen geschieht? Die Arithmetik erlaubt es uns zu sagen, ob es so ist oder nicht, und hier wird alles rechtmäßig und korrekt sein. Da Sie mit diesem Arithmetik-Keil verfolgen können, wo sich der Zeiger relativ zu seiner ursprünglichen Grundlinie befindet.
Die nächste Frage lautet also: Wie implementieren wir tatsächlich die Grenzvalidierung? Weil wir die spezifische Adresse des Zeigers irgendwie mit einer Art Grenzinformation für diesen Zeiger abgleichen müssen. Daher verwenden viele Ihrer vorherigen Entscheidungen Dinge wie beispielsweise eine Hash-Tabelle oder einen Baum, mit denen Sie die richtige Suche durchführen können. Angesichts der Adresse des Zeigers suche ich in dieser Datenstruktur und finde heraus, welche Grenzen sie hat. Angesichts dieser Grenzen entscheide ich, ob ich die Aktion zulassen kann oder nicht. Das Problem ist, dass dies eine langsame Suche ist, da diese Datenstrukturen verzweigt sind. Wenn Sie einen Baum untersuchen, müssen Sie eine Reihe solcher Verzweigungen untersuchen, bis Sie den richtigen Wert gefunden haben. Und selbst wenn es sich um eine Hash-Tabelle handelt, müssen Sie den Codeketten folgen und so weiter. Daher müssen wir eine sehr effektive Datenstruktur definieren, die ihre Grenzen verfolgt und die diese Überprüfung sehr einfach und klar macht. Also lasst uns gleich loslegen.
Aber bevor wir das tun, möchte ich Ihnen kurz erläutern, wie der Ansatz der
Buddy-Speicherzuweisung funktioniert. Weil dies eines der Dinge ist, die oft gefragt werden.
Die Buddy-Speicherzuweisung unterteilt den Speicher in Partitionen mit einem Vielfachen der Zweierpotenz und versucht, Speicheranforderungen in ihnen zuzuweisen. Mal sehen, wie es funktioniert. Zu Beginn behandelt die
Buddy-Zuweisung nicht zugewiesenen Speicher als einen großen Block - dies ist das obere 128-Bit-Rechteck. Wenn Sie dann einen kleineren Block für die dynamische Zuordnung anfordern, wird versucht, diesen Adressraum in Schritten von 2 in Teile aufzuteilen, bis ein für Ihre Anforderungen ausreichender Block gefunden wird.
Angenommen, eine Anforderung vom Typ
a = malloc (28) ist eingetroffen,
dh eine Anforderung zum Zuweisen von 28 Bytes. Wir haben einen 128-Byte-Block, der zu verschwenderisch ist, um ihn für diese Anforderung zuzuweisen. Daher ist unser Block in zwei Blöcke mit 64 Bytes unterteilt - von 0 bis 64 Bytes und von 64 Bytes bis 128 Bytes. Und diese Größe ist auch groß für unsere Anfrage, so dass
Buddy wieder einen Block von 64 Bytes in 2 Teile teilt und 2 Blöcke von 32 Bytes empfängt.

Weniger ist unmöglich, da 28 Bytes nicht passen und 32 die am besten geeignete Mindestgröße ist. Dieser 32-Byte-Block wird nun unserer Adresse a zugewiesen. Angenommen, wir haben eine andere Abfrage für
b = malloc (50) .
Buddy überprüft die ausgewählten Blöcke und setzt den Wert b in den Block ganz rechts, da 50 größer als die Hälfte von 64, aber kleiner als 64 ist.
Schließlich haben wir eine weitere Anforderung für 20 Bytes:
c = malloc (20) , dieser Wert wird in den mittleren Block gestellt.
 Buddy
Buddy hat eine interessante Eigenschaft: Wenn Sie Speicher in einem Block freigeben und daneben ein Block derselben Größe ist, kombiniert
Buddy nach dem Freigeben beider Blöcke zwei leere benachbarte Blöcke zu einem.

Wenn wir beispielsweise den Befehl
free © geben , wird
der mittlere Block freigegeben, aber die Vereinigung wird nicht stattfinden, sodass der Block daneben weiterhin beschäftigt ist. Nach dem Freigeben des ersten Blocks mit dem Befehl
free (a) werden beide Blöcke zu einem zusammengeführt. Wenn wir dann den Wert von b freigeben, werden die benachbarten Blöcke wieder zusammengeführt und wir erhalten einen ganzen Block mit einer Größe von 128 Bytes, wie es am Anfang war. Der Vorteil dieses Ansatzes besteht darin, dass Sie durch einfache Arithmetik leicht herausfinden können, wo sich der Kumpel befindet, und Speichergrenzen bestimmen können. So funktioniert die Speicherzuweisung mit dem
Buddy-Speicherzuweisungsansatz .
Allen meinen Vorträgen wird oft die Frage gestellt, ob ein solcher Ansatz nicht verschwenderisch ist. Stellen Sie sich vor, ich hätte zu Beginn eine Anfrage für 65 Bytes, ich müsste den gesamten Block von 128 Bytes dafür zuweisen. Ja, dies ist verschwenderisch. Tatsächlich verfügen Sie nicht über einen dynamischen Speicher und können keine Ressourcen mehr im selben Block zuweisen. Andererseits ist dies ein Kompromiss, da es sehr einfach ist, eine Berechnung durchzuführen, eine Fusion durchzuführen und dergleichen. Wenn Sie also eine genauere Speicherzuordnung wünschen, müssen Sie einen anderen Ansatz verwenden.
Was macht das
BBC-System (Buggy Bounce Checking) ?

Sie führt mehrere Tricks aus, von denen einer die Trennung des Speicherblocks in zwei Teile ist, von denen einer ein Objekt enthält und der zweite eine Ergänzung dazu ist. Wir haben also zwei Arten von Grenzen - die Grenzen des Objekts und die Grenzen der Verteilung des Gedächtnisses. Der Vorteil ist, dass die Basisadresse nicht gespeichert werden muss und eine schnelle Suche anhand einer Linientabelle möglich ist.
Alle unsere Verteilungsgrößen sind 2 hoch
n , wobei
n eine ganze Zahl ist. Dieses
2n- Prinzip nennt man
Zweierpotenz . Daher brauchen wir nicht viele Bits, um uns vorzustellen, wie groß eine bestimmte Verteilungsgröße ist. Wenn die Clustergröße beispielsweise 16 ist, müssen Sie nur 4 Bits auswählen - dies ist das Konzept eines Logarithmus, dh 4 ist ein Exponent von
n , in dem Sie die Zahl 2 erhöhen müssen, um 16 zu erhalten.
Dies ist ein ziemlich wirtschaftlicher Ansatz für die Speicherzuweisung, da die Mindestanzahl von Bytes verwendet wird, diese jedoch ein Vielfaches von 2 sein muss, dh Sie können 16 oder 32, jedoch nicht 33 Bytes haben. Darüber hinaus können Sie mit der
Buggy-Bounce-Prüfung Informationen zu Grenzwerten in einem linearen Array (1 Byte pro Datensatz) speichern und Speicher in einem Steckplatz mit einer Größe von 16 Byte zuweisen. Ordnen Sie Speicher mit Steckplatzgranularität zu. Was bedeutet das?

Wenn wir einen 16-Byte-Steckplatz haben, in den wir den Wert
p = malloc (16) setzen , sieht der Wert in der Tabelle wie in
Tabelle [p / slot.size] = 4 aus .

Angenommen, wir müssen jetzt einen Wert von 32 Bytes in der Größe
p = malloc (32) platzieren . Wir müssen die Randtabelle aktualisieren, um sie an die neue Größe anzupassen. Dies geschieht zweimal: zuerst als
Tabelle [p / slot.size] = 5 und dann als
Tabelle [(p / slot.size) + 1] = 5 - das erste Mal für den ersten Steckplatz, der diesem Speicher zugewiesen ist, und den zweiten mal - für den zweiten Slot. Somit weisen wir 32 Bytes Speicher zu. So sieht das Größenverteilungsprotokoll aus. Somit wird für zwei Speicherzuweisungsschlitze die Begrenzungstabelle zweimal aktualisiert. Das ist klar? Dieses Beispiel richtet sich an Personen, die bezweifeln, ob Protokolle und Tabellen eine Bedeutung haben oder nicht. Weil Tabellen jedes Mal multipliziert werden, wenn eine Speicherzuweisung erfolgt.
Mal sehen, was mit der Grenztabelle passiert. Angenommen, wir haben einen Code C, der so aussieht:
p '= p + i , dh der Zeiger
p' wird aus
p durch Hinzufügen einer Variablen
i erhalten . Wie erhalten wir also die für
p zugewiesene Speichergröße? Dazu betrachten Sie die Tabelle unter den folgenden logischen Bedingungen:
size = 1 << table [p >> log von slot_size]
Rechts haben wir die Größe der für
p zugewiesenen Daten, die 1 sein sollte. Dann verschieben Sie sie nach links und sehen sich die Tabelle an, nehmen diese Zeigergröße und bewegen sich dann nach rechts, wo sich das Protokoll der Slot-Größentabelle befindet. Wenn die Arithmetik funktioniert, haben wir den Zeiger korrekt an die Randtabelle gebunden. Das heißt, die Größe des Zeigers muss größer als 1 sein, aber kleiner als die Größe des Schlitzes. Links haben wir den Wert und rechts die Größe des Slots und der Zeigerwert befindet sich zwischen ihnen.
Angenommen, die Größe des Zeigers beträgt 32 Byte, dann haben wir in der Tabelle in den Klammern die Nummer 5.
Angenommen, wir möchten das Basisschlüsselwort dieses Zeigers finden:
base = p & n (Größe - 1) . Was wir tun werden, gibt uns eine bestimmte Masse, und diese Masse wird es uns ermöglichen, die hier befindliche
Basis wiederherzustellen. Stellen Sie sich vor, unsere Größe ist 16, binär 16 = ... 0010000. Die Auslassungspunkte bedeuten, dass es immer noch viele Nullen gibt, aber wir interessieren uns für diese Einheit und die Nullen dahinter. Wenn wir (16 -1) betrachten, sieht es ungefähr so aus: (16-1) = ... 0001111. Im Binärcode sieht die Umkehrung folgendermaßen aus: ~ (16-1) ... 1110000.
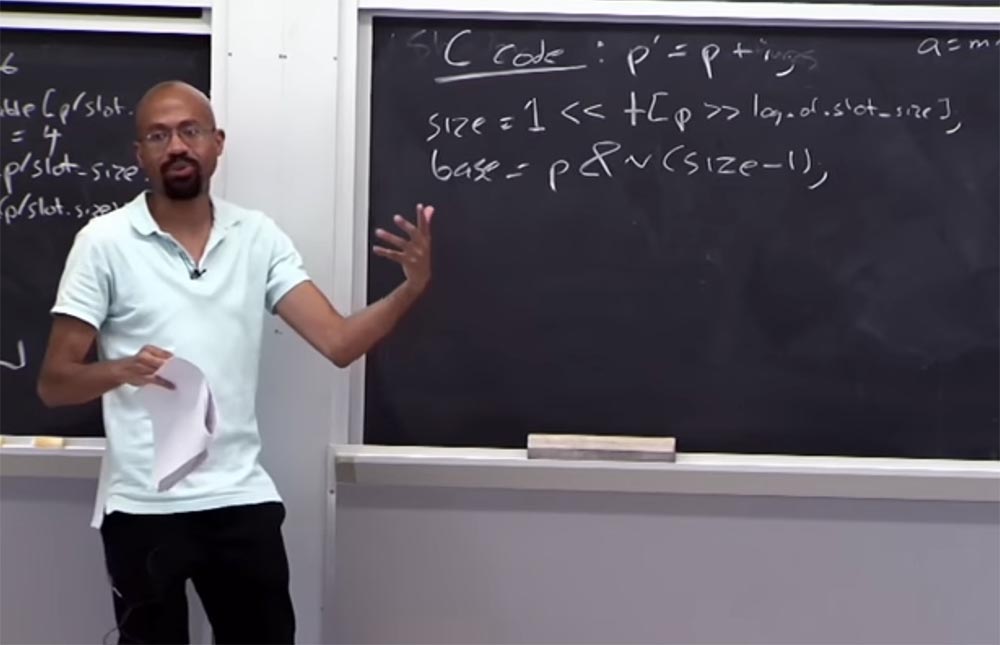

Auf diese Weise können wir das Bit, das im Wesentlichen vom aktuellen Zeiger gerendert wird, im Grunde löschen und uns seine
Basis geben . Dank dessen ist es für uns sehr einfach zu überprüfen, ob sich dieser Zeiger innerhalb der Grenzen befindet. Wir können also einfach überprüfen, ob
(p ')> = Basis ist und ob der Wert (
p' - Basis) kleiner als die ausgewählte Größe ist.

Dies ist eine ziemlich einfache Sache, um herauszufinden, ob sich der Zeiger innerhalb der Speichergrenzen befindet. Ich werde nicht auf Details eingehen, es genügt zu sagen, dass alle binären Arithmetiken auf die gleiche Weise aufgelöst werden. Mit solchen Tricks können Sie komplexere Berechnungen vermeiden.
Es gibt noch eine fünfte Eigenschaft der
Buggy-Bounce-Prüfung : Sie verwendet ein virtuelles Speichersystem, um zu verhindern, dass die für den Zeiger festgelegten Grenzen überschritten werden. Die Hauptidee ist, dass wir, wenn wir eine solche Arithmetik für den Zeiger haben, mit dem wir den Ausweg bestimmen, ein Bit höherer Ordnung für den Zeiger setzen können.

Auf diese Weise stellen wir sicher, dass die Dereferenzierung des Zeigers keine Hardwareprobleme verursacht. Das Setzen des
Bits hoher Ordnung allein verursacht keine Probleme, die Dereferenzierung des Zeigers kann ein Problem verursachen.
Die Vollversion des Kurses finden Sie
hier .
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder sie Ihren Freunden empfehlen.
Habr-Benutzer erhalten 30% Rabatt auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?