Was ist unangenehmer als der "rote Test"? Der Test ist entweder grün oder rot und es ist nicht klar warum. Auf unserer Heisenbug 2017 in Moskau sprach
Andrei Solntsev (Codeborne) darüber, warum sie entstehen könnten und wie sie ihre Anzahl reduzieren könnten. Beispiele in seinem Bericht sind solche, dass Sie den Schmerz direkt in der Haut fühlen, wenn Sie mit ihnen kollidieren. Die Tipps sind nützlich - und es lohnt sich, sowohl Tester als auch Entwickler kennenzulernen. Es gibt etwas Unerwartetes: Sie können herausfinden, wie manchmal Sie ein Problem herausfinden können, wenn Sie sich vom Bildschirm lösen und mit Ihrer Tochter Würfel spielen.
Infolgedessen schätzte das Publikum den Bericht und wir beschlossen, nicht nur das Video zu veröffentlichen, sondern auch eine Textversion des Berichts für Habr zu erstellen.
Flockentests sind meiner Meinung nach das relevanteste Thema in der Welt der Automatisierung. Denn die Frage "Was wird in der Welt gemacht, wie geht es Ihnen mit Automatisierung?" Alle antworten: „Es gibt keine Stabilität! Unsere Tests fallen regelmäßig. “
Sie haben einen Test bei Ihnen durchgeführt, es ist grün, noch zwei Tage grün, und dann einmal und plötzlich auf Jenkins gefallen. Sie versuchen es zu wiederholen, starten es und es ist wieder grün. Und am Ende weiß man nie: Ist es ein Fehler oder ist es nur ein Glucan-Test? Und jedes Mal, wenn Sie verstehen müssen.
Oft sieht der Tester nach einem nächtlichen Start von Tests an Jenkins zuerst "30 Tests sind gefallen, Sie müssen lernen", aber jeder weiß, was als nächstes passiert ...

Sie haben natürlich erraten, welches unanständige Wort getarnt ist: "Ich werde neu starten." "Heute gibt es keine Abneigung zu verstehen ..." So passiert es normalerweise und es ist eine echte Katastrophe.
Es gibt keine genauen Statistiken, aber ich habe oft von verschiedenen Leuten gehört, dass sie ungefähr 30% der Tests haben - schuppig. Grob gesagt starten sie tausend, von denen 300 regelmäßig rot sind, und prüfen dann mit ihren Händen, ob sie tatsächlich gefallen sind.
Google hat vor
ein paar Jahren
einen Artikel veröffentlicht: Es heißt, dass sie 1,5% der Flockentests haben und wie sie kämpfen, um ihre Anzahl zu reduzieren. Ich kann ein wenig prahlen und sagen, dass mein Projekt bei Codeborne jetzt 0,1% beträgt. Aber in der Tat ist das alles schlecht, sogar 0,1%. Warum?
Nehmen Sie 1,5%, diese Zahl scheint klein, aber was bedeutet es in der Praxis? Angenommen, ein Projekt enthält tausend Tests. Dies kann bedeuten, dass 15 Tests in einem Build gefallen sind, die nächsten 12, dann 18. Und das ist schrecklich schlecht, weil in diesem Fall fast alle Builds rot sind und Sie ständig mit Ihren Händen prüfen müssen, ob es wahr ist oder nicht.
Und selbst unsere 1 ppm (0,1%) sind immer noch schlecht. Angenommen, wir haben 1000 Tests, dann bedeutet 0,1%, dass regelmäßig einer von zehn Stürzen mit 1-2 roten Tests fällt. Hier ist das wirkliche Bild von unseren Jenkins, und es stellt sich heraus: Mit einem Lauf fiel ein Flockentest, mit einem anderen Start ein anderer.
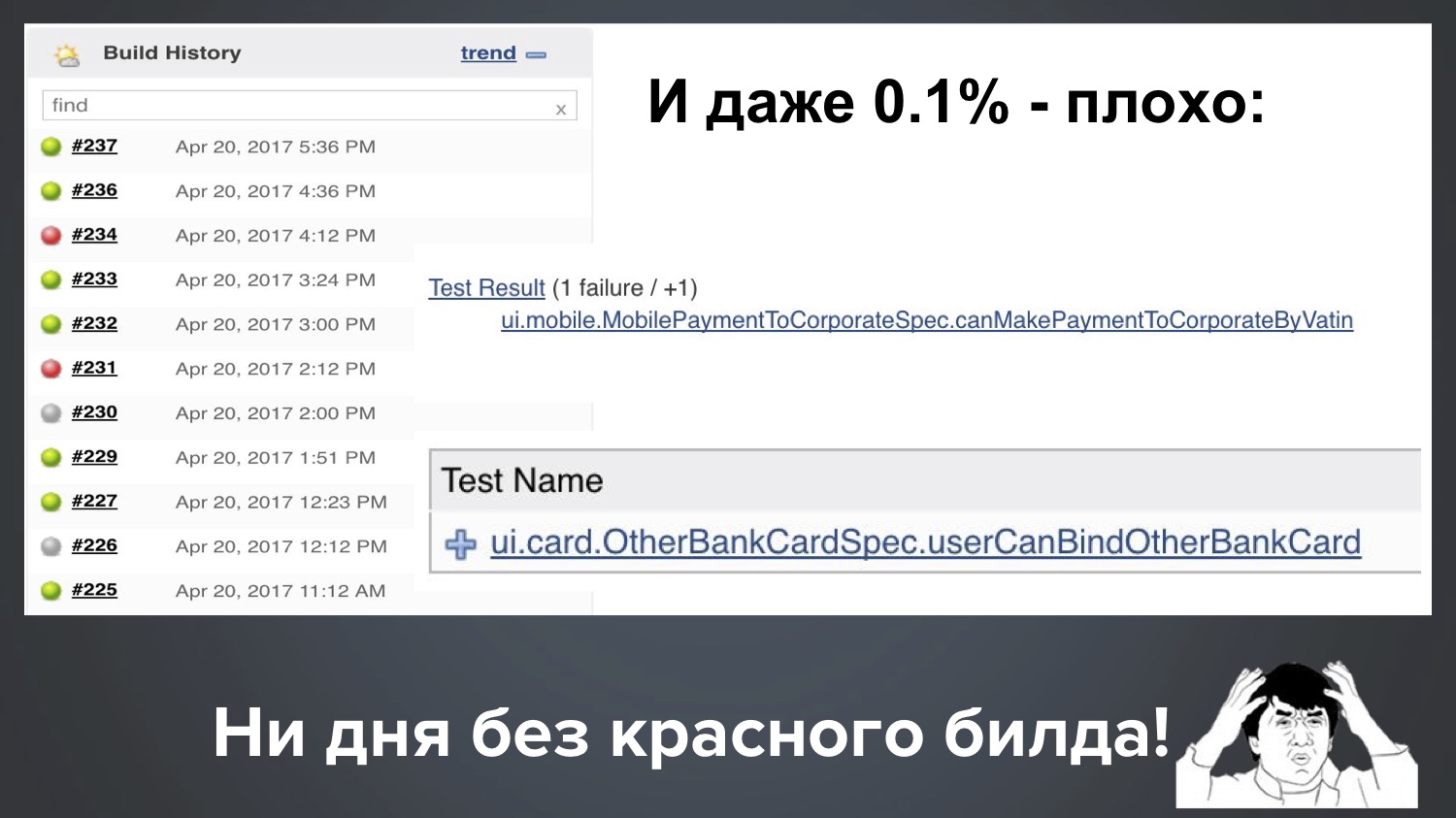
Es stellt sich heraus, dass wir keinen Tag ohne roten Körperbau haben. Da es viel Grün gibt, scheint alles in Ordnung zu sein, aber der Kunde hat das Recht, uns zu fragen: "Leute, wir zahlen dir Geld und du versorgst uns immer mit Rot!" Was machst du? "
Ich wäre beim Kunden unzufrieden, und zu erklären, "im Allgemeinen ist das in der Branche normal, alles ist für alle rot", ist nicht gut, oder? Daher ist dies meiner Meinung nach ein sehr dringendes Problem, und wir sollten gemeinsam verstehen, wie wir damit umgehen sollen.
Der Plan ist folgender:
- Meine Sammlung instabiler Tests (aus meiner Praxis, absolut reale Fälle, komplexe und interessante Detektivgeschichten)
- Ursachen der Instabilität (einige haben sogar Jahre gebraucht, um zu forschen)
- Wie gehe ich mit ihnen um? (hoffentlich ist dies der nützlichste Teil)
Beginnen wir also mit meiner Sammlung, die ich sehr schätze: Sie hat mich viele Nachtstunden Leben und Debuggen gekostet. Beginnen wir mit einem einfachen Beispiel.
Beispiel 1: klassisch
Für Saatgut - das klassische Selenium-Skript:
driver.navigate().to("https://www.google.com/"); driver.findElement(By.name("q")).sendKeys("selenide"); driver.findElement(By.name("btnK")).click(); assertEquals(9, driver.findElements(By.cssSelector("#ires .g")).size());
- Wir öffnen WebDriver.
- Suchen Sie das Element q, geben Sie das Wort ein, um dort zu suchen.
- Suchen Sie das Element "Button" und klicken Sie auf.
- Überprüfen Sie, ob die Antwort neun Ergebnisse enthält.
Frage: Welche Linie kann hier brechen?
Das stimmt, wir alle wissen genau, dass es welche gibt! Jede Linie kann aus ganz anderen Gründen brechen:
Die erste Zeile ist das langsame Internet, der Dienst ist abgestürzt, die Administratoren haben nichts konfiguriert.
Die zweite Zeile - das Element hatte noch keine Zeit zum Rendern, wenn es dynamisch gezeichnet wird.
Was könnte in der dritten Zeile brechen? Hier war es für mich unerwartet: Ich habe diesen Test für die Konferenz geschrieben, ihn lokal ausgeführt und er ist mit diesem Fehler in die dritte Zeile gefallen:

Dies besagt, dass das Element an dieser Stelle nicht anklickbar ist. Es scheint ein einfaches grundlegendes Google-Formular zu sein. Das Geheimnis war, dass wir in der zweiten Zeile das Wort getroffen haben und Google bei der Eingabe bereits die ersten Ergebnisse gefunden, die ersten Ergebnisse in einem solchen Popup angezeigt und die nächste Schaltfläche geschlossen hat. Und das passiert nicht in allen Browsern und nicht immer. Das ist mir mit diesem Skript ungefähr einmal von fünf passiert.
Die vierte Linie kann beispielsweise fallen, weil dieses Element dynamisch gezeichnet wird und noch keine Zeit zum Zeichnen hatte.
In diesem Beispiel möchte ich sagen, dass meiner Erfahrung nach 90% der Flockentests auf denselben Gründen beruhen:
- Ajax-Anforderungsgeschwindigkeit: Manchmal laufen sie langsamer, manchmal schneller.
- Die Reihenfolge der Ajax-Anfragen;
- Geschwindigkeit js.
Glücklicherweise gibt es aus diesen Gründen eine Heilung!
Selenid löst diese Probleme. Wie entscheidet es? Wir schreiben unseren Google-Test auf Selenide neu - fast alles sieht so aus, nur die $ -Zeichen werden verwendet:
@Test public void userCanLogin() { open(“http:
Dieser Test besteht immer. Aufgrund der Tatsache, dass die Methoden setValue (), click () und shouldHave () intelligent sind: Wenn etwas keine Zeit zum Malen hat, warten sie etwas und versuchen es erneut (dies wird als "intelligente Erwartungen" bezeichnet).
Wenn Sie etwas genauer hinschauen, sollten alle diese Methoden klug sein:

Sie können bei Bedarf warten. Standardmäßig warten sie bis zu 4 Sekunden, und dieses Zeitlimit ist natürlich konfigurierbar. Sie können jedes andere angeben. Beispiel: mvn -Dselenide.timeout = 8000.
Beispiel 2: nbob
So werden 90% der Probleme mit Flockentests mit Selenide gelöst. 10% der viel komplexeren Fälle haben jedoch weiterhin komplexe und verwirrende Gründe. Genau über sie möchte ich heute sprechen, weil es so eine „Grauzone“ ist. Lassen Sie mich ein Beispiel geben: einen Flockentest, auf den ich in einem neuen Projekt sofort gestoßen bin. Auf den ersten Blick kann das einfach nicht passieren, aber das ist etwas Interessantes.
Wir haben die Tastaturanwendung für die Anmeldung an Kiosken getestet. Der Test wollte sich als Benutzer "bob" anmelden, dh drei Buchstaben in das Feld "login" eingeben: bob. Dazu wurden die Schaltflächen auf dem Bildschirm verwendet. In der Regel funktionierte dies, aber manchmal stürzte der Test ab und der Wert "nbob" blieb im Feld "login":

Natürlich haben Sie Schwierigkeiten, nach dem Code zu suchen, in den wir "nbob" hätten schreiben können - aber im gesamten Projekt ist dies überhaupt nicht der Fall (weder in der Datenbank noch im Code oder sogar in Excel-Dateien). Wie ist das möglich?
Wir schauen uns den Code genauer an - es scheint, dass alles einfach ist, keine Rätsel:
@Test public void loginKiosk() { open(“http:
Wir begannen weiter zu debattieren, Schritt für Schritt, und mit dieser Methode gelang es uns zu verstehen: Dieser Fehler erscheint manchmal nach der Zeile $ („body“). Click (). Das heißt, in diesem Schritt wird "n" im Feld "Login" angezeigt, und in den folgenden Schritten wird "bob" hinzugefügt. Wer hat schon erraten, woher "n" kommt?
So kam es, dass sich der Buchstabe N in der Mitte des Bildschirms befand und die Funktion click () zumindest in Chrome folgendermaßen funktioniert: Sie berechnet die zentrale Koordinate eines Elements und klickt darauf. Da der Körper ein großes Element ist, klickte sie in die Mitte des gesamten Bildschirms.
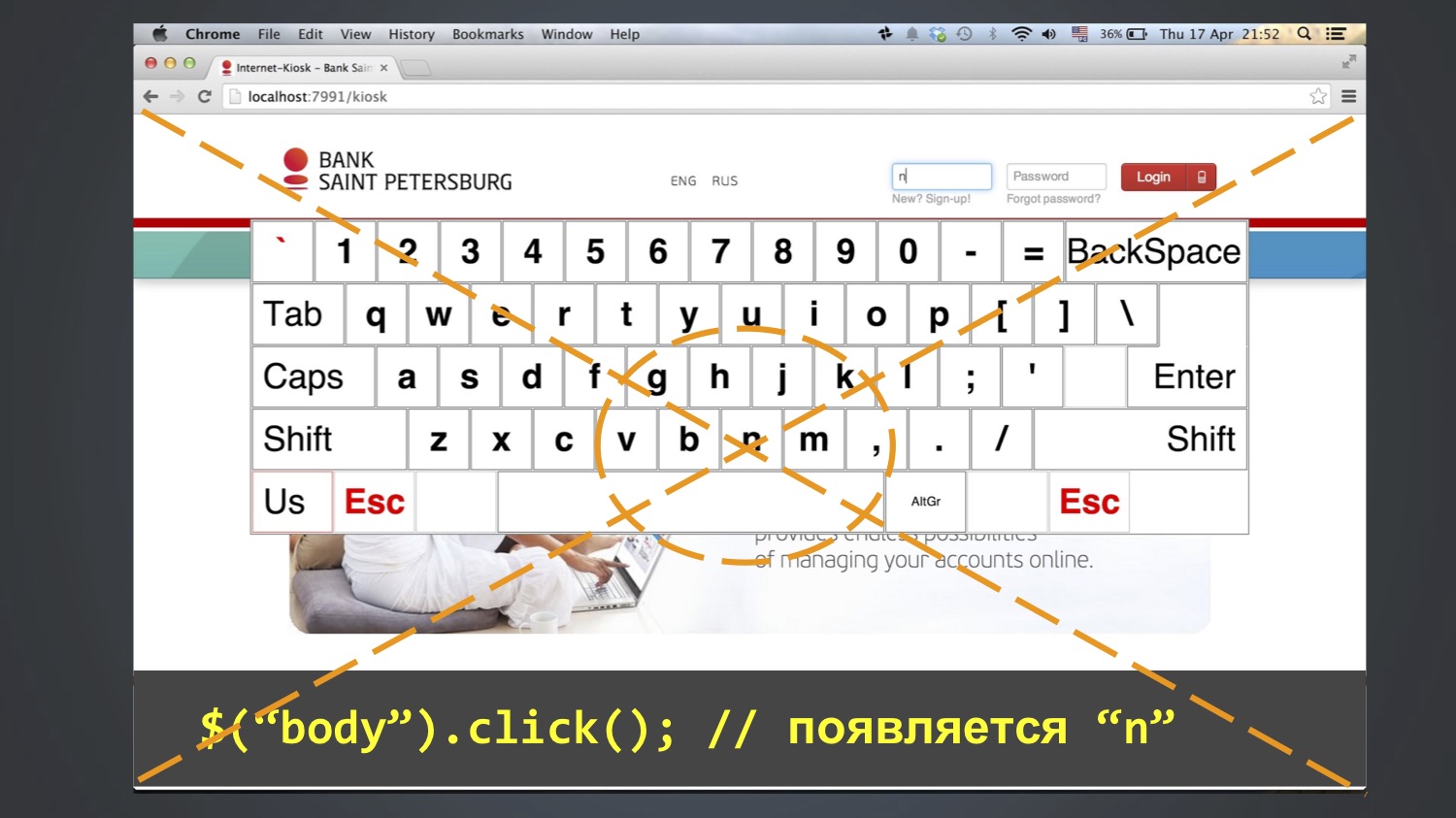
Und das ist nicht immer gefallen. Wer weiß warum? Tatsächlich weiß ich es selbst nicht ganz. Möglicherweise aufgrund der Tatsache, dass das Browserfenster ständig in verschiedenen Größen geöffnet wurde und dies nicht immer in den Buchstaben N fiel.
Sie haben wahrscheinlich eine Frage: Warum hat jemand $ ("body") gemacht. Click ()? Ich weiß es auch nicht bis zum Ende, aber ich nehme an, den Fokus vom Feld zu entfernen. In Selenium gibt es ein solches Problem, dass click () ist, unclick () jedoch nicht. Wenn das Feld einen Fokus enthält, kann dieser nicht entfernt werden. Sie können nur auf ein anderes Element klicken. Und da es keine anderen vernünftigen Elemente gab, klickten sie auf den Körper und erzielten einen solchen Effekt.
Daher die Moral: Fügen Sie nichts ein, was in den <body> gelangt. Mit anderen Worten, Sie müssen in Panik keine zusätzlichen Bewegungen ausführen. Tatsächlich passiert dies häufig: Da ich mich mit Selenide beschäftige, erhalte ich häufig Beschwerden, dass „etwas nicht funktioniert“, und dann stellt sich heraus, dass irgendwo in den Setup-Methoden 15 zusätzliche Zeilen vorhanden waren, die nichts Nützliches tun und stören . Keine Notwendigkeit, sich in Tests wie "plötzlich wird es zuverlässiger" zu beschäftigen und einzufügen.
Infolgedessen erweitern wir die Liste der Gründe für instabile Tests:
- Ajax-Anforderungsgeschwindigkeit;
- Die Reihenfolge der Ajax-Anfragen;
- Geschwindigkeit js;
- Browserfenstergröße;
- Eitelkeit!
Gleichzeitig empfehle ich: Führen Sie keine maximierten Tests durch (dh öffnen Sie den Browser nicht in einem vollständigen Fenster). In der Regel macht das jeder, und in Selenide war es standardmäßig (oder ist es immer noch). Stattdessen rate ich Ihnen, immer einen Browser mit einer genau definierten Bildschirmauflösung zu starten, da dieser Zufallsfaktor dann ausgeschlossen ist. Und ich rate Ihnen, die Mindestgröße, die Ihre Anwendung unterstützt, gemäß der Spezifikation festzulegen.
Beispiel 3: Phantomkonten
Ein Beispiel ist insofern interessant, als alles, was nur sofort zusammenfallen kann, zusammenfiel.
Bei einem Test wurde überprüft, ob auf diesem Bildschirm 5 Konten vorhanden sein sollten.

In der Regel war es grün, aber manchmal war nicht klar, unter welchen Bedingungen es fiel und es wurden nicht fünf, sondern sechs Zählungen auf dem Bildschirm angezeigt.
Ich begann zu recherchieren, woher die zusätzliche Rechnung kommt. Absolut unverständlich. Es stellte sich die Frage: Vielleicht haben wir einen anderen Test, der während des Tests ein neues Konto erstellt? Es stellte sich heraus, dass es einen solchen LoansTest gibt. Und zwischen ihm und dem fallenden AccountsTest (der fünf Accounts erwartet) gibt es möglicherweise eine Million anderer Tests.
Wir versuchen zu verstehen, wie es so ist: Sollte der LoansTest, der das Konto erstellt, es nicht am Ende löschen? Wir schauen uns den Code an - ja, das sollte es, am Ende gibt es eine After-Funktion dafür. Dann sollte theoretisch alles in Ordnung sein, was ist das Problem?
Vielleicht entfernt der Test es, aber es bleibt irgendwo zwischengespeichert? Wir sehen uns den Produktionscode an, der die Konten lädt - er enthält wirklich die Annotation @CacheFor und speichert die Konten fünf Minuten lang zwischen.
Es stellt sich die Frage: Sollte der Test diesen Cache nicht löschen? Es wäre logisch, kann es nicht so einen Pfosten geben? Wir sehen uns den Code an - ja, er löscht den Cache wirklich vor jedem Test. Was ist los? Hier sind Sie bereits verloren, weil die Hypothesen vorbei sind: Das Objekt wird gelöscht, der Cache wird geleert, Baumsticks, was könnte sonst noch ein Problem sein? Dann fing er an, den Code zu klettern, es dauerte einige Zeit, vielleicht sogar ein paar Tage. Bis ich mir endlich diese Klasse und Superklasse ansah und dort eine verdächtige Sache fand:

Jemand hat es schon bemerkt, oder? Das ist richtig: In der untergeordneten und in der übergeordneten Klasse gibt es eine Methode mit demselben Namen, die nicht super aufruft.
In Java ist dies sehr einfach: Drücken Sie Alt + Eingabetaste oder Strg + Einfügen in IntelliJ IDEA oder Eclipse. Standardmäßig wird die Methode setUp () für Sie erstellt, und Sie bemerken nicht, dass sie die Methode in der Oberklasse überschreibt. Das heißt, der Cache wurde immer noch nicht aufgerufen. Als ich das sah, war ich wild wütend. Es freut mich jetzt.
Daher die Moral:
- In Tests ist es sehr wichtig, den sauberen Code zu überwachen. Wenn im Produktionscode jeder darauf achtet, führt er eine Codeüberprüfung durch, dann in Tests - nicht immer.
- Wenn der Produktionscode durch Tests überprüft wird, wer testet dann die Tests? Daher ist es besonders wichtig, Überprüfungen in der IDE zu verwenden.
Nach diesem Vorfall habe ich in IDEA eine solche standardmäßig deaktivierte Überprüfung gefunden, die überprüft: Wenn die Methode irgendwo überschrieben wird, aber keine @ Overrid-Annotation vorhanden ist, wird dies als Fehler markiert. Jetzt überprüfe ich dieses Kästchen immer hysterisch.
Fassen wir noch einmal zusammen: Wie ist das passiert, warum ist der Test nicht immer fehlgeschlagen? Erstens hing es von der Reihenfolge dieser beiden Tests ab, sie laufen immer in zufälliger Reihenfolge ab. Ein weiterer Test hing davon ab, wie viel Zeit zwischen ihnen vergangen war. Konten werden fünf Minuten lang zwischengespeichert. Wenn mehr bestanden wurden, war der Test grün, und wenn weniger, fiel er, und dies geschah selten.
Wir erweitern die Liste, warum Tests instabil sein können:
- Ajax-Anforderungsgeschwindigkeit;
- Die Reihenfolge der Ajax-Anfragen;
- Geschwindigkeit js;
- Browserfenstergröße;
- Anwendungscache;
- Daten aus früheren Tests;
- Zeit.
Beispiel 4: Java-Zeit
Es gab einen Test, der auf allen unseren Computern und auf unseren Jenkins funktionierte, aber manchmal bei einem Jenkins-Kunden abstürzte. Wir schauen uns den Test an, verstehen warum. Es stellte sich heraus, dass es fiel, denn bei der Überprüfung "das Zahlungsdatum sollte jetzt oder in der Vergangenheit sein" stellte sich heraus, dass es "in der Zukunft" war.
assert payment.time <= new Date();
Wir schauen in den Code. Können wir unter bestimmten Umständen plötzlich ein Datum für die Zukunft festlegen? Wir können nicht: An dem einzigen Ort, an dem die Zahlungszeit initialisiert wird, wird neues Datum () verwendet, und dies ist immer die aktuelle Zeit (in extremen Fällen kann es in der Vergangenheit liegen, wenn der Test sehr langsam war). Wie ist das überhaupt möglich? Sie schlugen sich lange auf den Kopf, sie konnten es nicht verstehen.
Und einmal haben sie in das Anwendungsprotokoll geschaut. Daher die erste Moral - es ist sehr nützlich, wenn Sie Tests untersuchen, um in das Protokoll der Anwendung selbst zu schauen. Hebe deine Hände, wer macht das? Im Allgemeinen leider nicht die Mehrheit. Und es gibt nützliche Informationen: Zum Beispiel das Anforderungsprotokoll, die eine oder andere URL wurde zu einem solchen Zeitpunkt ausgeführt und gab die eine oder andere Antwort.

Gibt es hier etwas Verdächtiges? Wir schauen auf die Zeit: Diese Anfrage wurde minus drei Sekunden bearbeitet. Wie kann das sein? Sie kämpften lange, konnten nicht verstehen. Als uns schließlich die Theorie ausgegangen war, trafen wir eine dumme Entscheidung: Jenkins schrieb ein einfaches Skript, das die aktuelle Zeit in einem Zyklus einmal pro Sekunde protokolliert. Startete es. Am nächsten Tag, als dieser schuppige Test einmal in der Nacht fiel, begannen sie, einen Auszug aus dieser Akte für die Zeit anzusehen, als er fiel:

Also: 34 Sekunden, 35, 36, 37, 35, 39 ... Es ist cool, dass wir es gefunden haben, aber wie ist das überhaupt möglich? Die Theorien endeten erneut, weitere zwei Tage kratzten sich am Kopf. Das ist wirklich der Fall, wenn die Matrix mit Ihnen scherzt, oder?
Bis mich endlich eine Idee traf ... Und das stellte sich heraus. Linux verfügt über einen Zeitsynchronisierungsdienst, der auf einem zentralen Server ausgeführt wird und fragt, wie viele Millisekunden jetzt sind. Und es stellt sich heraus, dass zwei verschiedene Dienste für diesen speziellen Jenkins gestartet wurden. Der Test stürzte ab, als Ubuntu auf diesem Server aktualisiert wurde.
Dort wurde zuvor ein NTP-Dienst konfiguriert, der auf einen speziellen Bankenserver zugegriffen hat und von dort aus einige Zeit in Anspruch genommen hat. Und mit der neuen Version von Ubuntu wurde standardmäßig ein neuer Lightweight-Service hinzugefügt, beispielsweise systemd-timesyncd. Und beide haben funktioniert. Niemand hat das bemerkt. Aus irgendeinem Grund gaben der Zentralbankserver und ein zentraler Ubuntu-Server eine Antwort mit einer Differenz von 3 Sekunden aus. Natürlich haben sich diese beiden Dienste gegenseitig gestört. Irgendwo tief in der Ubuntu-Dokumentation heißt es, dass man diese Situation natürlich nicht zulässt ... Nun, danke für die Info :)
Gleichzeitig lernte ich eine interessante Nuance von Java, die ich vorher trotz meiner langjährigen Erfahrung nicht kannte. Eine der grundlegendsten Methoden in Java heißt System.currentTimeMillis (), mit deren Hilfe normalerweise etwas aufgerufen wird. Viele haben solchen Code geschrieben:
long start = System.currentTimeMillis();
Dieser Code befindet sich in den Bibliotheken von Apache Commons, Guava. Das heißt, wenn Sie feststellen müssen, wie viele Millisekunden benötigt wurden, um etwas aufzurufen, tun sie dies normalerweise. Und viele haben wahrscheinlich gehört, dass dies nicht getan werden sollte. Ich hörte auch, wusste aber nicht warum und zu faul, um es zu verstehen. Ich dachte, die Frage war genau, weil System.nanoTime () in einer Java-Version vorkam - es ist genauer, es erzeugt Nanosekunden, die millionenfach genauer sind. Und da meine Anrufe in der Regel eine Sekunde oder eine halbe Sekunde dauern, ist diese Genauigkeit für mich nicht wichtig, und ich habe weiterhin System.currentTimeMillis () verwendet, das wir im Protokoll mit -3 Sekunden gesehen haben. Der richtige Weg ist also, und jetzt habe ich herausgefunden, warum:
long start = System.nanoTime();
Eigentlich ist dies in der Dokumentation der Methoden geschrieben, aber ich habe es einfach nie gelesen. Ich habe mein ganzes Leben lang gedacht, dass System.currentTimeMillis () und System.nanoTime () dasselbe sind, nur mit einem millionenfachen Unterschied. Es stellte sich jedoch heraus, dass dies grundlegend unterschiedliche Dinge sind.
System.currentTimeMillis () gibt das aktuelle Datum zurück - wie viele Millisekunden sind jetzt seit dem 1. Januar 1970. Und System.nanoTime () ist eine Art abstrakter Zähler, der nicht an Echtzeit gebunden ist: Ja, es wächst garantiert jede Nanosekunde pro Einheit, aber es ist nicht mit der aktuellen Zeit verbunden, es kann sogar negativ sein. Zu Beginn der JVM wird ein Zeitpunkt zufällig ausgewählt und beginnt zu wachsen. Es war eine Überraschung für mich. Für dich auch? Nun, es ist nicht umsonst, dass er angekommen ist.
Beispiel 5: Der Fluch des grünen Knopfes
Hier füllt unser Test ein bestimmtes Formular aus, klickt auf die grüne Schaltfläche Bestätigen und geht manchmal nicht weiter. Warum es nicht geht, ist unverständlich.
Wir fahren in vier Nullen und hängen, gehen nicht zur nächsten Seite. Das Klicken erfolgt fehlerfrei. Ich habe mir alles angesehen: Ajax-Anfragen, Warten, Zeitüberschreitungen, Anwendungsprotokolle, Cache - ich habe nichts gefunden. Die von Sergey Pirogov geschriebene
Videorecorder- Bibliothek ist noch nicht erschienen. Durch Hinzufügen einer Anmerkung zum Code können Sie Videos aufnehmen. Dann konnte ich ein
Video von diesem Test aufnehmen, es in Zeitlupe ansehen, und dies verdeutlichte schließlich die Situation, die ich einige Monate vor dem Video nicht lösen konnte.

Der Fortschrittsbalken blockierte die Schaltfläche für den Bruchteil einer Sekunde, und der Klick funktionierte genau in diesem Moment und traf diesen Fortschrittsbalken. Das heißt, der Fortschrittsbalken hat geklickt und ist verschwunden! Und es wird in keinem Screenshot, in keinem Protokoll sichtbar sein, Sie werden nie wissen, was passiert ist.
Im Prinzip handelt es sich in gewisser Weise um einen Anwendungsfehler: Ein Fortschrittsbalken wurde angezeigt, weil die Anwendung wirklich aus dem Bildschirmrand kriecht, und wenn Sie einen Bildlauf durchführen, stellt sich heraus, dass es sich um viele nützliche Daten handelt. Aber die Benutzer haben sich nicht darüber beschwert, weil alles auf den großen Bildschirm passte, es passte nicht nur auf den kleinen.
Beispiel 6: Warum friert Chrome ein?
Eine zweijährige Detektivuntersuchung ist ein absolut realer Fall. Die Situation ist folgende: Unsere Tests waren ziemlich oft schuppig und fielen, und in den Stapelspuren war klar, dass Chrome einfriert: nicht unser Test, nämlich Chrome. In den Protokollen war zu sehen, dass "Build läuft 36 Stunden ...". Sie begannen, Thread-Dumps und Stack-Traces zu entfernen. Sie zeigen, dass in den Tests alles in Ordnung ist, der Aufruf von Chromedriver hängt und in der Regel zum Zeitpunkt des Abschlusses (wir nennen die Methode close). und diese Methode macht nichts, hängt 36 Stunden). Wenn es interessant ist, sieht die Stapelverfolgung folgendermaßen aus:

Wir haben versucht, alles zu tun, was uns nur in den Sinn kam:
- Konfigurieren Sie das Zeitlimit für das Öffnen / Schließen des Browsers (wenn Sie den Browser nicht in 15 Sekunden öffnen / schließen konnten, versuchen Sie es nach 15 Sekunden erneut, bis zu drei Versuche). Öffnen und schließen Sie den Browser in einem separaten Thread. Ergebnis: Alle drei Versuche hingen gleich.
- Beenden Sie alte Chrome-Prozesse. Sie haben einen separaten Job in Jenkins 'Kill-Chrome' erstellt. So können Sie beispielsweise alle Prozesse "beenden", die älter als eine Stunde sind:
killall - älter als 1 Stunde Chromedriver
killall - älter als 1h Chrom
Dies gab zumindest Speicher frei, gab aber keine Antwort auf die Frage „Was passiert?“. Tatsächlich hat uns dieses Ding nur den Moment der Entscheidung verzögert. - Aktivieren Sie Debug-Anwendungsprotokolle.
- Aktivieren Sie WebDriver-Debugprotokolle.
- Öffnen Sie den Browser nach jeweils 20 Tests erneut. Es mag lächerlich erscheinen, aber der Gedanke war: "Was ist, wenn Chrome einfriert, weil es müde ist?" Nun, ein Speicherverlust oder etwas anderes.
Das Ergebnis des letzten Versuchs war völlig unerwartet: Das Problem begann sich häufiger zu wiederholen! Und wir hatten gehofft, dass dies dazu beitragen würde, Chrome zu stabilisieren, damit es besser funktioniert. Dies ist im Allgemeinen ein Gehirn-Imbiss. Aber in der Tat, wenn das Problem öfter wieder auftritt, sollte man nicht traurig sein, sondern sich freuen! Dies macht es möglich, es besser zu studieren. Wenn sie sich öfter zu wiederholen begann, sollte man sich daran festhalten: "Ja, ja, jetzt füge ich noch etwas hinzu, Protokolle, Haltepunkte ..."
Wir versuchen, das Problem zu wiederholen: Wir schreiben einen Zyklus von 1 bis 1000, in dem Zyklus öffnen wir einfach den Browser und schließen die erste Seite in unserer Anwendung. Wir haben so einen Zyklus geschrieben und ... Bingo! Ergebnis: Das Problem begann sich stabil zu wiederholen (allerdings ungefähr alle 80 Iterationen)! Cool! Diese Leistung hat zwar lange Zeit nichts gebracht. Sie haben es gestartet, auf die 80. Iteration gewartet, Chrome ist abgestürzt ... und was ist dann zu tun? Sie sehen sich Stapelspuren, Speicherauszüge und Protokolle an - dort gibt es nichts Nützliches. Entwicklertools in Chrome könnten helfen, aber bis September 2017 funktionierten diese Tools nicht mit Selenium (die Ports standen in Konflikt: Sie starten Chrome von Selenium und DevTools werden nicht geöffnet). Lange konnte ich mir nicht vorstellen, was ich tun sollte.
Und hier in dieser Geschichte beginnt ein fabelhafter Moment. Einmal, nach einer unendlichen Anzahl von Versuchen, habe ich diese Tests erneut ausgeführt. Bei einer Iteration wie der 56. hängt sie erneut. Ich denke, "lasst uns etwas anderes graben" (obwohl ich nicht weiß, wo ich den Haltepunkt setzen soll oder was ein Protokoll hinzufügen). In diesem Moment bietet meine Tochter an, Würfel zu spielen, aber mein Test hängt nur hier. Ich sage: "Warte", sagte sie zu mir: "Was, du verstehst nicht, ich habe hier
ein b und ein a !"
Was zu tun ist, leider den Computer verlassen, Würfel spielen ... Und plötzlich, nach ungefähr 20 Minuten, schaue ich versehentlich auf den Bildschirm und sehe ein völlig unerwartetes Bild:

Was passiert: Es gibt einen Countdown, nach wie vielen Minuten die Sitzung abläuft und ich einen Turm aus Würfeln baue, es gibt zwei, eine ... die Sitzung läuft ab, der Test wird fortgesetzt, läuft bis zum Ende und fällt ab (es gibt kein Element mehr, die Sitzung ist abgelaufen).
Was passiert: Chrome ist nicht wirklich eingefroren, wie wir die ganze Zeit dachten, es hat die ganze Zeit auf etwas gewartet. Als die Sitzung abgelaufen war, wartete, ging es weiter. Was genau Chrome erwartet hatte - es ist völlig unverständlich, dies zu verstehen. Ich musste den gesamten Code mit der binären Suchmethode schaufeln: die Hälfte von JavaScript und HTML wegwerfen, versuchen, 80 Iterationen erneut zu wiederholen - es hing nicht, oh, das bedeutet irgendwo da draußen ... Im Allgemeinen haben wir experimentell verstanden dass das Problem hier ist:
var timeout = setTimeout(sessionWatcher);
Auf allen unseren Seiten gab es JavaScript - das zeigt das Fenster, in dem die Sitzung abläuft. Wahrscheinlich wissen alle JavaScript-Programmierer, dass dies nicht sehr korrekt ist: Alles, was in den <script> -Tags ausgeführt wird, beginnt sofort. Und dies ist normalerweise unsicher, da es möglicherweise nicht funktioniert, wenn Elemente verwendet werden, die noch nicht geladen wurden. Daher wird immer empfohlen, JavaScript zu verpacken. Wenn Sie jQuery verwenden, dann in $, und alles im Funktionsblock beginnt erst, wenn alle Elemente bis zum Ende geladen sind: var timeout; $(function() { timeout = setTimeout(...); });
Dies ist das ABC der Webprogrammierung, das wahrscheinlich jeder kennt. Und wir hatten es nicht, wir hatten es falsch. Als ich dies änderte und das Experiment für 1000 Iterationen wiederholte, hing es nicht mehr.Zwar kenne ich nicht alle Antworten vollständig: Ich weiß zum Beispiel nicht, warum es nicht immer hing, sondern nur manchmal sehr selten. Vielleicht ist das ein Chrome-Bug, verdammt. Ja, es hat wirklich zwei Jahre gedauert, um dieses Problem zu untersuchen.Dies bedeutet, dass einige Fälle mit schuppigen Tests so unrealistisch sind, dass vielleicht nicht jeder sein Leben damit ruinieren möchte. Wenn Sie versuchen, daraus zu schließen, ist es im Allgemeinen interessant, dass sich der lächerlichste und dümmste, lustigste und sinnloseste Versuch (einen müden Browser neu zu starten) als erfolgreich erwiesen hat. Es war völlig dumm, führte aber plötzlich unerwartet zum Erfolg. Ich weiß nicht, welche Moral ich daraus ableiten soll: dumme Versuche machen?In Chrome hatten wir lange Zeit auch einen solchen Grund für Flockentests: Er wusste nicht immer, wie man native Alarmfenster schließt, manchmal nicht, und der Prozess blieb hängen, niemand tötete ihn.Manchmal wirken sich auch UI-Effekte aus: Sie möchten auf eine Schaltfläche klicken, und in diesem Moment bewegt sie sich oder bewegt sich von einer Ecke zur anderen. Sie rufen die click () -Methode auf, sie berechnet die Koordinaten des Mittelpunkts dieser Schaltfläche und der Feigen dort, und die Schaltfläche ist zu diesem Zeitpunkt bereits verlassen. Und vor allem, was passiert: Die click () -Methode hat fehlerfrei funktioniert, und Sie befinden sich nicht auf der nächsten Seite. Jemand hat wieder geklickt, oder? :) :)
Wenn Browser parallel gestartet werden, verlieren sie den Fokus. Wenn es Funktionen gibt, die für den Fokus ausgelegt sind, schweben Sie, dann fallen sie auch, wenn sie parallel gestartet werden. Dementsprechend rate ich, sie entweder nicht zu verwenden oder Lösungen zu verwenden, bei denen die Browser wirklich getrennt sind und auf verschiedenen Displays oder in verschiedenen Dockern ausgeführt werden.Die Beispiele sind vorbei. Lassen Sie uns nun eine Theorie geben, warum Tests instabil sind. Erinnern wir uns an die typischen Probleme:- Ajax-Anforderungsgeschwindigkeit;
- Die Reihenfolge der Ajax-Anfragen;
- Geschwindigkeit js;
- Browserfenstergröße;
- Anwendungscache;
- Daten aus früheren Tests;
- Zeit;
- Browser-Stabilität;
- UI-Effekte
- Parallele Browser (Fokusverlust).
Es gibt auch echte Fehler für schuppige Tests, wie Sie sie finden können. Es kommt vor, dass Fehler und Bugs entdeckt werden, und dies ist ein einfacher Fall: Sie erhalten einen Fehler, sie beheben ihn.Auch für uns treten schwer reproduzierbare Fälle auf. Es gibt "unrealistische" Fehler. Wir hatten Fälle, in denen der Flockentest abgebrochen wurde, weil der Schutz der Anzahl der Klicks pro Sekunde auf die Schaltfläche mit derselben ID funktionierte und der Flockentest viele Male klicken konnte. Der echte Benutzer wird jedoch niemals Zeit dafür haben.Es gibt echte Fehler, aber unkritisch: Sie haben einen Test, der manchmal rot ist, aber niemand wird ihn beheben.Es kommt häufig vor, dass ein Flockentest über ein Problem mit der Benutzerfreundlichkeit spricht, beispielsweise über einen Fortschrittsbalken, bei dem ein Teil des Bildschirms geschlossen wurde und der Flockentest dies zeigte. Manchmal muss man den Falltest also aus einem solchen Blickwinkel betrachten.Das Problem ist, dass, wenn Sie es nicht richtig rechtfertigen, niemand etwas korrigieren wird ... In jüngerer Zeit hatten wir einen Fall, als wir anfingen zu graben. Wir stellten fest, dass der schuppige Test einen Sicherheitsfehler fand, den gewöhnliche Tests nicht bemerkten. Aber ich werde es heute nicht sagen, da es noch nicht repariert wurde!Lassen Sie uns darüber sprechen, was Sie tun können, um die Anzahl der Flockentests zu minimieren:- Testpyramide;
- Selenid
- Service-Emulatoren;
- Eine saubere Basis vor jedem Test.
Die Pyramide ist eine ewige Wahrheit. Warum ist es gerade im Hinblick auf Flockentests wichtig, dass es eine Größenordnung mehr Komponententests als UI-Tests gibt? Nicht weil sie schneller sind (obwohl dies wichtig ist), sondern weil sie viel stabiler sind und viel weniger schuppig sind.Über Selenide schon gesagt.Emulatoren. Während der Tests können Sie in keinem Fall auf echte externe Dienste zugreifen (z. B. während der Tests echte SMS / Briefe senden). Dies ist kein Scherz, ich höre oft Fragen wie "Wie lese ich einen Brief aus einem Test?". Verwenden Sie für diese Dienste unbedingt Emulatoren, insbesondere da diese einfach zu erstellen sind. Artyom Eroshenko in seinem Bericht zeigte, ich werde nicht aufhören.Setzen Sie im Idealfall vor jedem Test den Status der Daten zurück und bereinigen Sie den Status der Datenbank. Wie genau dies zu tun ist, möchte ich jetzt nicht sagen, dies ist ein technisches Problem, aber es gibt Optionen, wie dies ganz einfach zu tun ist. Bei uns passiert das wirklich: Vor jedem Test ist die Datenbank „von Grund auf neu“, neu, immer mit demselben Datensatz (10 Benutzer, 20 Konten, einer mit einer Million, der andere mit zehn Rubel). Es kann garantiert werden, dass alle Tests dafür zählen, und aufgrund der Daten sind keine Flocken vorhanden.Was Sie anwenden müssen, um Flockentests genauer zu untersuchen:- Protokolle früherer Builds;
- Screenshots
- Video
Der Punkt „Speichern der Protokolle früherer Builds“ mag ebenfalls offensichtlich erscheinen, aber in jedem Projekt, in das ich gekommen bin, habe ich diese Situation gesehen: Einige Fehler und Screenshots sind nur im letzten Build zu sehen. Wenn Ihr letzter Build "grün" und der vorherige "rot" war, ist das alles: Es gab einen Flockentest, aber Sie können nicht mehr erfahren, warum er flockig war. Keine Protokolle, nichts wurde aufbewahrt, und dies ist eine Katastrophe. Und das geht sehr einfach. Wenn Sie beispielsweise die Jenkins-Pipeline verwenden, reicht es in Jenkins aus, einen solchen Code zu schreiben: finally { stage("Reports") { junit 'build/test-results/**/*.xml' artifacts = 'build./reports/**/*,build/test-results/**/*,logs/**/*' archiveArtifacts artifacts: artifacts } }
finally , . : - - . Jenkins , . , Jenkins , . , .
(Selenide , ). flaky-. ,
Video Recorder , :
video — , !
Eine Alternative für diejenigen, die bereit sind, Tests in Docker auszuführen: Es gibt eine gute Bibliothek TestContainers (es gab einen Bericht darüber zu diesem Heisenbug ). Dort fügen Sie auch eine Regel und eine Anmerkung in den Test ein. Vor dem Test selbst wird der Docker mit der gewünschten Version des Browsers bereitgestellt, das Video aufgezeichnet und am Ende des Tests beendet. In diesem Fall haben Sie auch ein Video über den fehlgeschlagenen Test. @Rule public BrowserWebDriverContainer chrome = new BrowserWebDriverContainer() .withRecordingMode(RECORD_ALL, new File("build")) .withDesiredCapabilities(chrome());
Die letzte Nachricht.Zuerst möchte ich die Entwickler kontaktieren. Entwickler, meine Lieben, sollten unbedingt an Tests teilnehmen, Tests schreiben, Nachforschungen anstellen und interessierten Testern beim Lesen von Protokollen helfen. Weil sie solche schuppigen Tests in ihrem Leben niemals bewältigen können.Manager, Chefs dieser Entwickler! In der Regel liegt das Problem bei Ihnen :) Lassen Sie die Entwickler und ermutigen Sie die Entwickler, an Tests teilzunehmen. Wenn Sie dies nicht tun und sagen: "Sie haben keine Zeit dafür, sie müssen Code schreiben, sie sind teuer", verschwenden Sie Geld für die Automatisierung, da die Automatisierungseffizienz gering ist.Und die wichtigste Botschaft ist für die Automatisierungsexperten, die an Tests beteiligt sind, Falltests untersuchen und etwas mit ihnen unternehmen. Wenn Sie zur Arbeit zurückkehren, führen Sie die beschriebenen vorbeugenden Arbeiten durch, bewaffnen Sie sich mit den oben genannten Mitteln und ... warten Sie! :) Und wenn dein Flockentest das nächste Mal fällt - freue dich: du gehst auf die Jagd!Wenn Ihnen dieser Bericht gefallen hat, achten Sie darauf: Am 6. und 7. Dezember kommt Heisenbug wieder nach Moskau. Es wird wieder nützliche Tipps und erstaunliche Geschichten geben, und die Welten der Tester und Entwickler werden wieder in Kontakt treten. Sie können den aktuellen Status des Programms jederzeit auf der Konferenzwebsite anzeigen (und auf Wunsch ein Ticket kaufen) .