
Die
Qualifizierungsphase von DataScienceGame2018, die im kaggle InClass-Format stattfand, wurde kürzlich beendet.
DataScienceGame ist ein internationaler Studentenwettbewerb, der jährlich stattfindet. Unser Team hat es geschafft, unter mehr als 100 Teams den 3. Platz zu belegen und gleichzeitig NICHT die Endphase zu erreichen.
Teaminteraktion

Bei großen Kaggle-Wettbewerben werden Teams normalerweise auf dem Weg von Personen gebildet, die einen knappen Vorsprung in der Rangliste haben (ein
typisches Beispiel für ein Team ) und daher unterschiedliche Städte und häufig unterschiedliche Länder repräsentieren. Gemäß den Wettbewerbsbedingungen sollte jedes Team sofort aus 4 Personen einer Bildungseinrichtung bestehen (wir haben MIPT vertreten). Und das bedeutet, dass die meisten Teilnehmer, so scheint es mir, alle Diskussionen offline stattfanden. Zum Beispiel lebte das gesamte Team auf einer Etage des Hostels, also versammelten wir uns abends mit jemandem im Raum.
Wir hatten keine Trennung von Aufgaben, Planung oder Teambildung. Zu Beginn des Wettbewerbs saßen wir nur im Kreis, diskutierten, was wir in Zukunft tun können und was nicht. Der Code wurde von einer Person geschrieben, und der Rest zu dieser Zeit schaute einfach und gab Ratschläge. Ich schreibe nicht wirklich gerne Code, daher hat mir diese Interaktion gefallen, obwohl sie offensichtlich nicht die beste war. Da die Qualifikationsphase jedoch genau auf die Sitzung an der Universität fiel, konnte ein Teil des Teams nicht viel Zeit aufwenden und ich musste den Code trotzdem selbst schreiben.
Aufgabenbeschreibung
Laut der von BNP bereitgestellten Historie musste vorhergesagt werden, ob der Benutzer nächste Woche an einer gewissen Sicherheit (Isin) interessiert sein würde oder nicht. Gleichzeitig wurde "Interesse" durch die TradeStatus-Spalte ermittelt, die den Status der Transaktion beschrieb und die folgenden eindeutigen Werte aufwies:
- Die Transaktion wurde abgeschlossen (dh der Benutzer hat Papier gekauft / verkauft).
- Der Benutzer sah sich das Papier an, schloss jedoch keine Transaktion ab
- Der Benutzer legt Papier für den zukünftigen Kauf / Verkauf beiseite
- Die Transaktion wurde aus technischen Gründen nicht abgeschlossen.
- Halten
Wenn TradeStatus also den Wert 1) -4) annimmt, wird davon ausgegangen, dass der Benutzer an diesem Dokument interessiert war und nicht an allen anderen Fällen. Gleichzeitig wurde in Absatz 4) darauf hingewiesen, dass die Linie mit dieser Transaktion fiktiv war und für eine bequeme Berichterstattung erstellt wurde. Am Ende eines jeden Monats wurde nämlich der Status des Portfolios jedes Benutzers mit seinem Status vor einem Monat verglichen, und wenn sich beispielsweise der Benutzer irgendwie im Portfolio befand, erhöhte sich der Betrag eines bestimmten Wertpapiers um 10.000, und genau diese Zeile war mit „Kauf“ gekennzeichnet. Und mit einem Nennwert von 10k. Mit "Halten" gekennzeichnete Zeilen hatten eine Zielvariable von 0 (der Benutzer war nicht interessiert).
Wenn Sie darüber nachdenken, können Sie verstehen, dass der Datensatz wie folgt ablief: Benutzer waren auf der Website der Bank aktiv - sie haben Papiere gesucht / gekauft, und alle diese Aktionen wurden in der Datenbank aufgezeichnet. Beispielsweise hat ein Benutzer mit der ID = 15 beschlossen, Papier mit der ID = 7 für zukünftige Einkäufe zu verschieben. Unmittelbar in der Datenbank erschien die entsprechende Zeile mit Ziel 1 (der Benutzer wurde interessiert)
| Benutzer-ID | Sicherheits-ID | Art der Transaktion | Deal Status | Zusätzliche Felder | Ziel |
|---|
| 15 | 7 | Kauf | Für die Zukunft beiseite legen | ... | 1 |
Außerdem wurden monatliche Datensätze mit dem Status "Halten" und "Ziel 0" hinzugefügt. Beispielsweise erhöhte Benutzer 15 aus irgendeinem Grund die Anzahl der Aktien 93 (möglicherweise hat er sie auf einer anderen Website gekauft), während er selbst diese Sicherheit auf der BNP-Website nicht hatte interagiert (nicht interessiert).
| Benutzer-ID | Sicherheits-ID | Art der Transaktion | Deal Status | Zusätzliche Felder | Ziel |
|---|
| 15 | 93 | Kauf | Halten | ... | 0 |
Für BNP ist es jedoch offensichtlich sinnlos, dieselben Bestände vorherzusagen, da sie von der Basis aus eindeutig wiederhergestellt werden können. Dies bedeutet, dass es eine andere Art von Token gibt, die nicht in der Trainingstabelle enthalten sind, nämlich alle dreifachen "Benutzer - Papier - Art der Transaktion", die nicht in der Datenbank angezeigt wurden. Das heißt, der Benutzer war NICHT an einer bestimmten Aktion interessiert, dh er hat im BNP-System nicht mit ihr interagiert, sodass die entsprechende Zeile nicht in der Datenbank angezeigt wurde. Dies bedeutet, dass sie ein Ziel von 0 haben sollte. Dies bedeutet, dass Sie solche Zeilen für das Training selbst generieren müssen ( siehe Abschnitt „Zusammenstellen eines Trainingsbeispiels“). All dies könnte zu Verwirrung führen, da viele Teilnehmer wahrscheinlich dachten - es gibt einen Datensatz, es gibt Nullen und Einsen -, die Sie vorhersagen können. Aber nicht so einfach.
Im Zug gibt es also eine Tabelle mit der Historie der Transaktionen (dh der Interaktion „Benutzer - Papier - Transaktionstyp“ und einige zusätzliche Informationen dazu) und eine Reihe anderer Kennzeichen mit den Merkmalen des Benutzers, der Aktie und der globalen Marktbedingungen. Im Test gibt es nur dreifache "Benutzer - Papier - Art der Transaktion" und für jedes dieser drei müssen Sie vorhersagen, ob es nächste Woche erscheinen wird. Sie müssen beispielsweise vorhersagen, ob die Benutzer-ID = 8 an der Aktions-ID = 46 mit dem Transaktionstyp "Verkauf" interessiert ist.
| Benutzer-ID | Sicherheits-ID | Art der Transaktion | Ziel |
|---|
| 8 | 46 | Zu verkaufen | ? |
Funktionen zum Erstellen eines Datensatzes
Da es, wie ich bereits sagte, in der realen BNP-Datenbank keine Zeilen mit „nicht haltenden“ Nullen gab, haben die Organisatoren solche Zeilen für den Test selbst generiert. Und wo künstliche Daten generiert werden, gibt es häufig Gesichter und andere implizite Informationen, die das Ergebnis erheblich verbessern können, ohne die Modelle / Funktionen zu ändern. In diesem Abschnitt werden einige Funktionen zum Erstellen eines Datensatzes beschrieben, die wir verstanden haben, die uns jedoch leider in keiner Weise geholfen haben.

Wenn Sie sich die Tripel „Benutzer - Papier - Transaktionstyp“ aus der Testtabelle ansehen, ist leicht zu erkennen, dass die Anzahl der Transaktionen mit den Typen „Kauf“ und „Verkauf“ genau gleich ist und die Tabelle streng nach diesem Attribut sortiert ist: zuerst alle Käufe, dann alle Verkäufe. Offensichtlich ist dies kein Unfall und es stellt sich die Frage: Wie könnte das passieren? Zum Beispiel auf diese Weise: Die Organisatoren haben alle realen Datensätze aus ihrer Datenbank für die Woche, die wir für eine Vorhersage benötigen (solche Linien haben ein Ziel von 1), irgendwie neue Linien generiert (ihr Ziel ist 0), die nicht mit den oben beschriebenen übereinstimmen. So stellte sich eine Tabelle heraus, in der die Arten von Transaktionen (Kauf / Verkauf) in zufälliger Reihenfolge angeordnet sind:
| Benutzer-ID | Sicherheits-ID | Art der Transaktion | Ziel |
|---|
| 8 | 46 | Zu verkaufen | 1 |
| 2 | 6 | Kauf | 1 |
| 158 | 73 | Kauf | 1 |
| 3 | 29 | Zu verkaufen | 0 |
| 67 | 9 | Kauf | 0 |
| 17 | 465 | Zu verkaufen | 0 |
Jetzt ist es möglich, den Kauftyp auf alle Zeilen mit dem Transaktionstyp "Verkauf" festzulegen. Wenn das Ziel eins war, wird es Null (in den meisten Fällen war der Benutzer an Papier mit nur einem Status interessiert: entweder Kauf oder Verkauf). Dies führt zu folgender Tabelle:
| Benutzer-ID | Sicherheits-ID | Art der Transaktion | Ziel |
|---|
| 8 | 46 | Kauf | 0 |
| 2 | 6 | Kauf | 1 |
| 158 | 73 | Kauf | 1 |
| 3 | 29 | Kauf | 0 |
| 67 | 9 | Kauf | 0 |
| 17 | 465 | Kauf | 0 |
Der letzte Schritt bleibt: das Gleiche zu tun, aber den "Kauf zum Verkauf" zu ersetzen und die richtigen Ziele zu vereinbaren:
| Benutzer-ID | Sicherheits-ID | Art der Transaktion | Ziel |
|---|
| 8 | 46 | Zu verkaufen | 1 |
| 2 | 6 | Zu verkaufen | 0 |
| 158 | 73 | Zu verkaufen | 0 |
| 3 | 29 | Zu verkaufen | 0 |
| 67 | 9 | Zu verkaufen | 0 |
| 17 | 465 | Zu verkaufen | 0 |
Wenn wir die Tabelle mit „Einkäufen“ und die Tabelle mit „Verkäufen“ verketten, erhalten wir (wenn wir die Organisatoren wären) eine Tabelle, wie sie uns im Test gegeben wurde. Es ist leicht zu verstehen, dass die erste und die zweite Hälfte der auf diese Weise aufgebauten Tabellen dieselbe Reihenfolge von Benutzer-Papier-Paaren aufweisen, wie sich in der Testtabelle tatsächlich herausstellte.
Ein weiteres Merkmal war, dass der Trainingsdatensatz viele Zeilen enthielt, in denen der Benutzerindex mehrmals hintereinander wiederholt wurde, obwohl der Datensatz nicht nach einem der Zeichen sortiert war:
| Benutzer-ID | Sicherheits-ID | Art der Transaktion | Ziel |
|---|
| 8 | 46 | Zu verkaufen | ? |
| 8 | 152 | Zu verkaufen | ? |
| 8 | 73 | Kauf | ? |
Der Teamkollege hielt dies für normal, und der Datensatz wurde anfangs nach Benutzer-ID sortiert, und die Organisatoren haben ihn einfach stark durcheinander gebracht (z. B. wenn das Mischen auf zufälligen Permutationen angeordnet war und nicht genügend solche Permutationen vorhanden waren). Um dies sicherzustellen, durchlief er vier Mischungen aus verschiedenen Bibliotheken, aber nirgends traten so häufige Wiederholungen auf. Der Test hatte auch diese Funktion. Es gab eine Idee, dass die Organisatoren die Nullen nicht generierten, sondern einfach die alten Paare aus dem Zug nahmen. Um dies zu überprüfen, entschied ich mich für Folgendes: Vergleichen Sie für jedes Paar „Benutzerpapier“ aus dem Test die Zeilennummer aus dem Zug, als sich dieses Paar zum ersten Mal traf, und machen Sie daraus eine Handlung. Das heißt, wir schauen uns zum Beispiel die erste Zeile im Test an, lassen sie eine Benutzer-ID = 8 und eine ID = Papier = 15 haben. Jetzt gehen wir die Trainingstabelle von oben nach unten durch und suchen, wann dieses Paar zum ersten Mal aufgetaucht ist, sei es zum Beispiel 51. Zeile. Wir haben einen Vergleich: Die erste Linie im Test war im 51. Zug, also zeichnen wir den Punkt mit den Koordinaten (1, 51) auf der Karte. Wir machen das für den gesamten Test und erhalten die folgende Grafik:
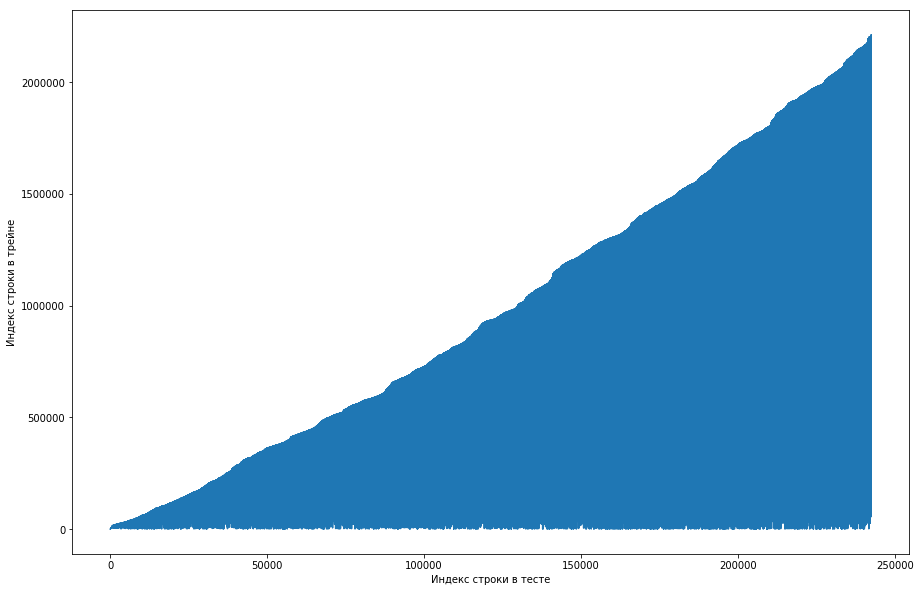
Daraus ist ersichtlich, dass, wenn sich ein Paar zuvor im Zug getroffen hat, seine Position im Testtisch höher ist. Gleichzeitig gibt es einige Spannungsspitzen in der Grafik (es gibt tatsächlich nicht so viele davon, aber aufgrund der Auflösung der Bildschirme scheint es ein ausgefülltes Dreieck zu geben). Darüber hinaus stimmte die Anzahl der Emissionen ungefähr mit der erwarteten Anzahl der Einheiten im Test überein. Natürlich haben wir versucht, Emissionen als Einheiten zu kennzeichnen und an die Rangliste zu senden, aber leider hat es nicht funktioniert. Aber es schien mir immer noch, dass es eine Art Gesicht geben könnte (), und als Mannschaftskapitän schlug ich vor, mehr Zeit damit zu verbringen, zu verstehen, wie dies geschehen könnte, und wir haben immer noch Zeit, die Modelle zu trainieren und die Zeichen zu generieren. Haftungsausschluss: Wir haben viel Zeit damit verbracht, aber eine Woche vor dem Ende des Wettbewerbs haben die Organisatoren im Forum geschrieben, dass in den letzten 6 Monaten nur Dreifache und nicht alle in den Testdatensatz aufgenommen wurden. Nun, wenn Sie die oben beschriebenen Operationen ausführen, aber in den letzten 6 Monaten und nicht nur den Datensatz, erhalten Sie eine flache monotone Kurve:
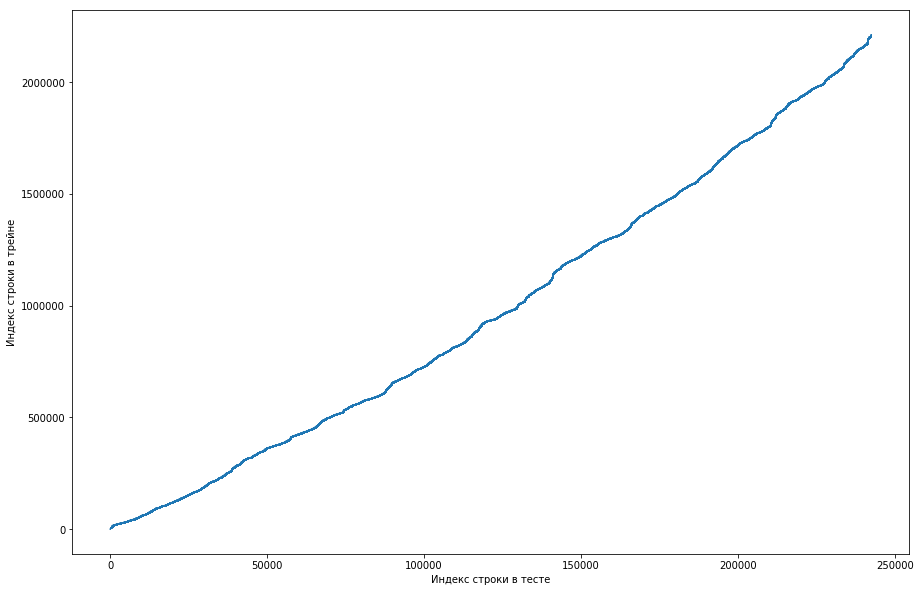
Und das bedeutet, dass es hier kein Gesicht gibt und nicht sein kann.
Training eingerichtet
Da Sie im Test eine Woche lang eine Vorhersage für Tripel treffen müssen, teilen wir den Trainingsdatensatz in Wochen auf (gleichzeitig gibt es jede Woche durchschnittlich 20.000 Dreifach-Transaktionen vom Typ "Benutzer - Papier - Typ"). Jetzt können wir für drei sagen, ob sie sich in einer bestimmten Woche getroffen hat oder nicht. Gleichzeitig haben wir bereits positive Tripel (dies sind alles Einträge aus dieser Woche in der Zugtabelle), und negative müssen irgendwie generiert werden. Dafür gibt es viele Möglichkeiten. Beispielsweise können Sie im Trainingsdatensatz absolut alle Tripel aussortieren, die für eine bestimmte Woche nicht vorhanden waren. Es ist klar, dass die Probe dann sehr unausgeglichen ist, und das ist schlecht. Sie können Benutzer zuerst proportional zur Häufigkeit ihres Auftretens im Dataset generieren und ihnen dann irgendwie Werbeaktionen hinzufügen. Bei diesem Ansatz wird es jedoch eine Reihe von Zeilen geben, für die keine vernünftigen Statistiken berechnet werden können, was ebenfalls schlecht ist. Wie wir es getan haben: Wir haben alle Arten von Tripeln genommen, die zuvor im Zug angetroffen wurden, sie kopiert, Kauf / Verkauf durch die andere ersetzt und diese beiden Tabellen verkettet. Es ist klar, dass Duplikate auf diese Weise aufgetreten sein könnten (zum Beispiel, wenn der Benutzer jemals eine Aktie gekauft und verkauft hätte), aber es gab nur wenige davon, und nach dem Löschen wurde eine Tabelle mit 500.000 eindeutigen Tripeln erhalten. Das ist alles, jetzt kann man für jede Woche für jedes solche Triple sagen, ob sie sich getroffen hat oder nicht (und wie oft?).
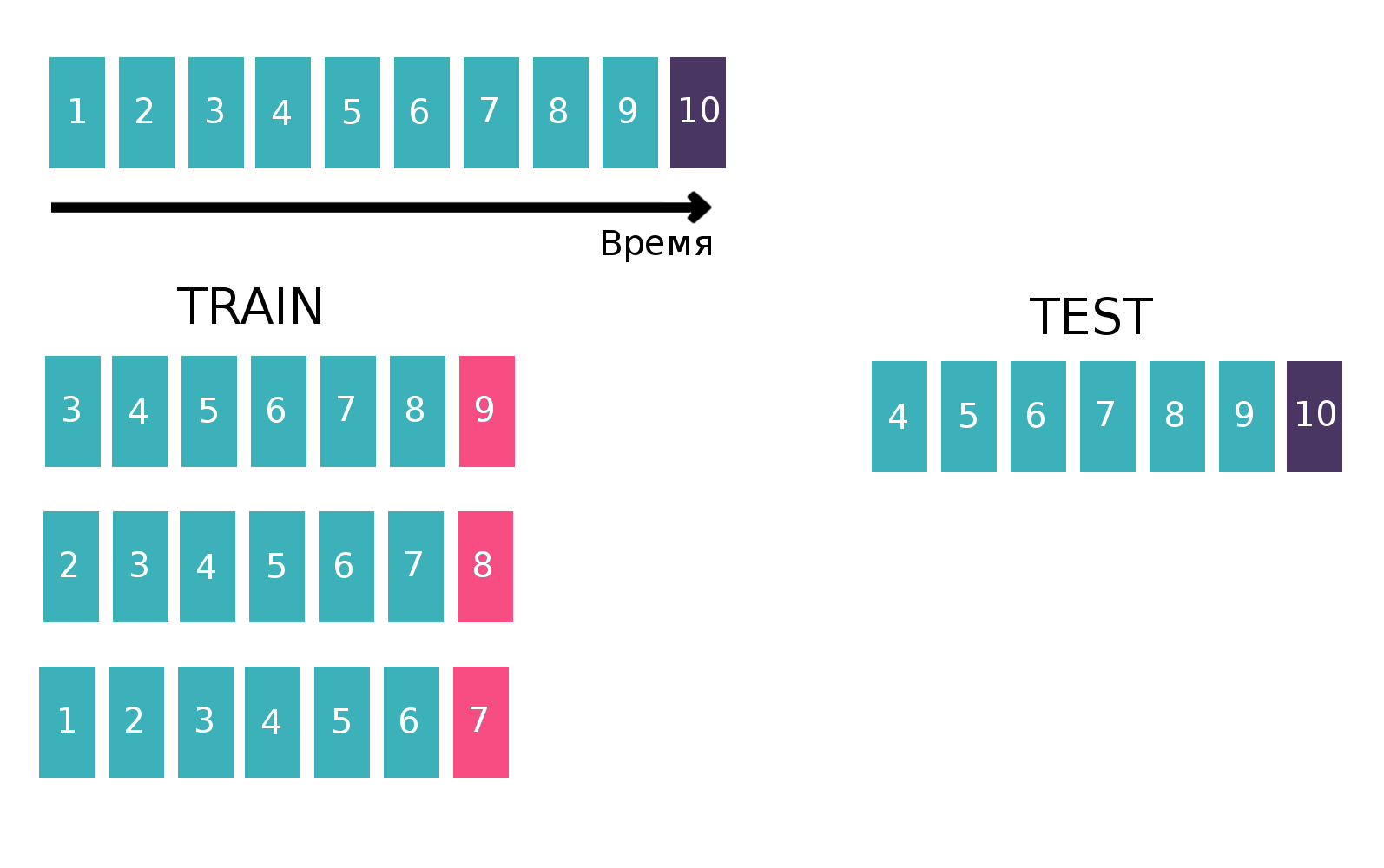
Da es sich im Wesentlichen um Zeitreihen handelt - ein Nutzer sieht sich eine bestimmte Anzeige mehrmals pro Woche an -, erstellen wir eine Tabelle, um den Klassifikator auf klassische Weise für Zeitreihen zu trainieren. Wir werden nämlich die letzte verfügbare Woche aus dem Zug nehmen, um zu sehen, ob sich alle drei "Kunden - isin - kaufen oder verkaufen" diese Woche getroffen haben. Es wird ein Ziel sein. Und wir werden verschiedene Statistiken beispielsweise in den letzten 6 Wochen als Funktionen zählen (weitere Informationen zu Statistiken finden Sie im Abschnitt "Zeichen"). Vergessen wir nun die Existenz der letzten Woche und machen dasselbe, aber für die vorletzte Woche und verketten die Tabellen. Dies kann mehrmals durchgeführt werden, wodurch der „Höhenzug“ erhöht wird, aber gleichzeitig verringert sich natürlich das Intervall, über das wir Statistiken betrachten. Wir haben diesen Vorgang zehnmal wiederholt, denn wenn wir mehr tun würden, würden die Neujahrsfeiertage und die damit verbundenen Probleme gezielt behandelt, was die endgültige Qualität des Modells verschlechtern würde. Erklärendes Bild:
Weitere Informationen zu Zeitreihen und zur Validierung von Zeitreihen finden Sie
hier .
Zeichen
Wie gesagt, es gab viele Tabellen, die die Benutzer-, Aktien- oder globalen Marktbedingungen (Hauptwährungen und einige Indikatoren) irgendwie charakterisierten. Aber alle haben die Qualität fast nicht verbessert, und die Hauptzeichen waren Statistiken, die für die Paare „Kunde - isin“ und die dreifachen „Kunde - isin - kaufen oder verkaufen“ berechnet wurden, zum Beispiel:
- Wie oft haben sich ein Paar / drei in den letzten 1, 2, 5, 20, 100 Wochen getroffen?
- Statistik über Zeitintervalle zwischen Besprechungen eines Paares / Dreiergruppen in einem Datensatz (Mittelwert, Standard, Max, Min)
- Die zeitliche Entfernung zum ersten / letzten Mal, als sich ein Paar / drei trafen
- Der Anteil jedes TradeStatus-Werts für ein Paar / Tripel
- Statistiken darüber, wie oft pro Woche ein Paar / Dreifach auftritt (Mittelwert, Standard, Maximum, Min)
Außerdem habe ich am letzten Tag des Wettbewerbs auf dem Formular gelesen, dass man eine Aktie zuerst kaufen muss, um sie zu verkaufen. Dieses Wissen ermöglicht es Ihnen, viele weitere nützliche Zeichen zu finden, aber aus irgendeinem Grund war es für mich nicht offensichtlich.
Im Code wurde dies alles durch eine Funktion von 200 Zeilen Länge ausgedrückt, die ähnliche Zeichen für jedes der zehn Zugstücke erzeugte (für den Teil, in dem das Ziel, beispielsweise Woche 7, sollten wir die Informationen für die 8. und 9. nicht verwenden). Unter Berücksichtigung zusätzlicher Tabellen wurden etwa 300 Zeichen rekrutiert. Wie ich bereits sagte, haben wir 500.000 eindeutige Tripel generiert und die letzten 10 Wochen als Ziele festgelegt. Daher betrug der „hohe“ Trainingstisch 500.000 * 10 = 5.000 Zeilen.
Einige weitere Geständnisse wurden in
der Entscheidung über den zweiten Platz beschrieben . Die Jungs bauten einen Benutzer- / Papiertisch, an dem sich in jeder Zelle eine Einheit befand, falls der Benutzer jemals an diesem Papier interessiert war, und ansonsten Null. Durch Berechnen des Kosinusabstands zwischen Benutzern in dieser Tabelle können Sie die Konvergenz der Benutzer untereinander ermitteln. Wenn Sie die PCA auf die resultierende Ähnlichkeitstabelle anwenden, erhalten Sie eine Reihe von Funktionen, die den Benutzer auf irgendeine Weise charakterisieren.
Modelle oder Kampf um Tausendstel
Es ist erwähnenswert, dass fast drei Wochen lang niemand die Basislinie von BNP übertreffen konnte, die eine Geschwindigkeit von 0,794 (ROC AUC) auf der Rangliste hatte, und dies trotz der Tatsache, dass die Entscheidung, „einfach zu zählen, wie oft sich das Paar früher getroffen hat“, 0,71 auf der Rangliste ergab, und einige Die Teilnehmer erhielten alle 0,74 ohne maschinelles Lernen.
Darüber hinaus haben wir am letzten Tag des Wettbewerbs (der zufällig mit dem Ende der Sitzung zusammenfiel) maschinelles Lernen angewendet. Wir haben beschlossen, aufzuhören,
wenn Sie wissen, was ich meine, und eine große Mischung verschiedener Modelle zu erstellen, die auf verschiedenen Teilmengen von Zeichen mit unterschiedlicher Anzahl von Wochen trainiert wurden Zug. Wie ich bereits sagte, bestand unsere Trainingsstichprobe aus 1,5.000 Linien, von denen ein Ziel etwa 150.000 war. Die Größe des Tests betrug 400.000, während die geschätzte Anzahl der Einheiten 20.000 betrug (im Durchschnitt gibt es tatsächlich so viele einzigartige Tripel). Das heißt, der Anteil der Einheiten im Test war signifikant höher als im Zug. Daher haben wir in allen unseren Modellen den Parameter scale_pos_weight angepasst, mit dem die Klassen gewichtet werden. Weitere Informationen zu diesem Parameter finden Sie in der
Analyse der besten Lösung eines der DataScienceGame des letzten Jahres. Die Korrelationsmatrix der Vorhersagen unserer Modelle ist in der Abbildung dargestellt:
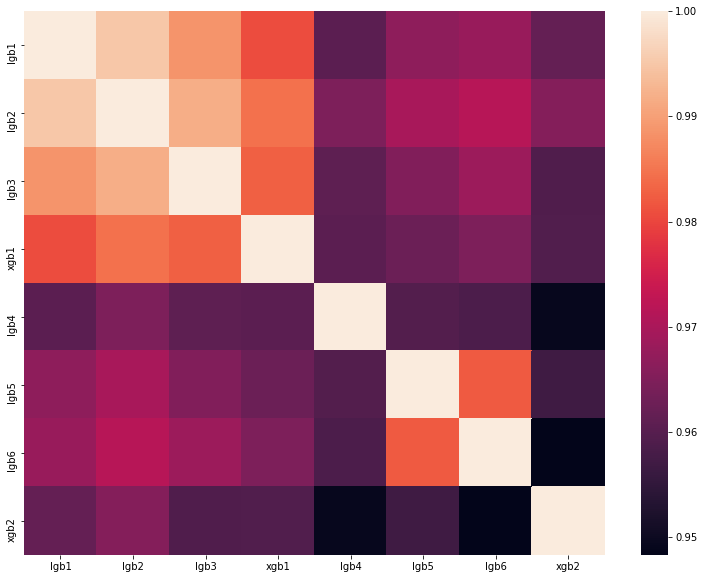
Wie Sie sehen können, hatten wir viele ganz unterschiedliche Modelle, die es uns ermöglichten, eine Geschwindigkeit von 0,80204 in der Rangliste zu erreichen.
Warum gehen wir nicht für die letzte Etappe nach Frankreich?
Als Ergebnis zeigten wir ein gutes Ergebnis und belegten den dritten Platz in der Rangliste. Die Organisatoren legen jedoch die folgenden Regeln für die Auswahl der Finalisten fest:
- Nicht mehr als 20 beste Teams
- Nicht mehr als 5 beste Teams aus dem Land
- Nicht mehr als 1 Team einer Bildungseinrichtung
Und alles wäre in Ordnung, wenn ein anderes Team des Moskauer Instituts für Physik und Technologie mit einer Geschwindigkeit von 0,80272 nicht auf dem zweiten Platz wäre. Das heißt, wir sind nur 0,00068 zurück. Es ist eine Schande, aber es gibt nichts zu tun. Höchstwahrscheinlich haben die Organisatoren solche Regeln aufgestellt, damit sich die Mitarbeiter einer Universität in keiner Weise gegenseitig halfen. In unserem Fall wussten wir jedoch nichts über das benachbarte Team und haben es in keiner Weise kontaktiert.
Zusammenfassung
In diesem Jahr werden im September in Paris 5 Teams aus Russland, eines aus der Ukraine und zwei Teams aus Deutschland und Finnland, bestehend aus russischsprachigen Studenten, um den ersten Platz kämpfen. Insgesamt 8 Teams der Ru-Community, was erneut die Dominanz des Ru-Segments der Datasaens beweist. Und ich werde
nach Sharaga versetzt, trainiere und arbeite an mir selbst, damit ich nächstes Jahr die Qualifikationsphase noch überwinden kann.