Dieser Artikel behandelt nicht die Grundlagen des Ruhezustands (Definieren einer Entität oder Schreiben von Kriterienabfragen). Hier werde ich versuchen, über interessantere Punkte zu sprechen, die bei der Arbeit wirklich nützlich sind. Informationen, die ich nicht an einem Ort getroffen habe.

Ich werde sofort reservieren. Alle folgenden Aussagen gelten für Hibernate 5.2. Fehler sind auch möglich, weil ich etwas falsch verstanden habe. Wenn Sie finden - schreiben Sie.
Probleme beim Zuordnen eines Objektmodells zu einem relationalen Modell
Beginnen wir jedoch mit den Grundlagen von ORM. ORM - Objekt-relationales Mapping - dementsprechend haben wir relationale und Objektmodelle. Und wenn wir uns gegenseitig anzeigen, gibt es Probleme, die wir selbst lösen müssen. Nehmen wir sie auseinander.
Nehmen wir zur Veranschaulichung das folgende Beispiel: Wir haben die Entität "Benutzer", die entweder ein Jedi oder ein Angriffsflugzeug sein kann. Die Jedi müssen Stärke und die Spezialisierung der Angriffsflugzeuge haben. Unten ist ein Klassendiagramm.
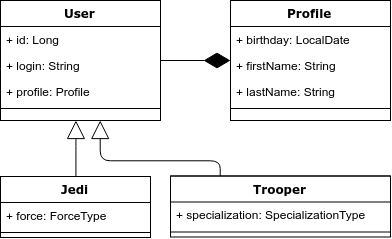
Problem 1. Vererbung und polymorphe Abfragen.
Es gibt Vererbung im Objektmodell, aber nicht im relationalen Modell. Dementsprechend ist dies das erste Problem - wie die Vererbung dem relationalen Modell korrekt zugeordnet werden kann.
Der Ruhezustand bietet drei Optionen zum Anzeigen eines solchen Objektmodells:
- Alle Erben befinden sich in derselben Tabelle:
@Inheritance (Strategie = InheritanceType.SINGLE_TABLE)

In diesem Fall liegen die gemeinsamen Felder und die Felder der Erben in einer Tabelle. Mit dieser Strategie vermeiden wir Verknüpfungen bei der Auswahl von Entitäten. Von den Minuspunkten ist anzumerken, dass wir erstens die Einschränkung „NOT NULL“ für die Spalte „force“ im relationalen Modell nicht festlegen können und zweitens die dritte Normalform verlieren. (Eine transitive Abhängigkeit von Nicht-Schlüsselattributen wird angezeigt: Kraft und Disc).
Übrigens, auch aus diesem Grund gibt es zwei Möglichkeiten, eine Feldbeschränkung ungleich Null anzugeben: NotNull ist für die Validierung verantwortlich. @Column (nullable = true) - verantwortlich für die Nicht-Null-Einschränkung in der Datenbank.
Meiner Meinung nach ist dies der beste Weg, ein Objektmodell einem relationalen Modell zuzuordnen.
- Entitätsspezifische Felder befinden sich in einer separaten Tabelle.
@Inheritance (Strategie = InheritanceType.JOINED)
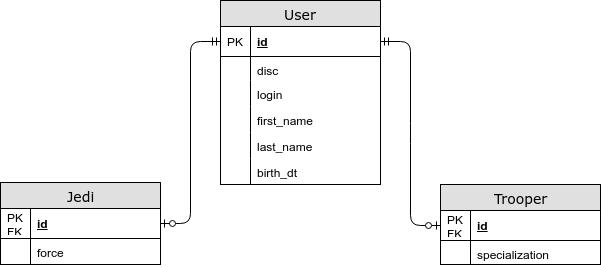
In diesem Fall werden allgemeine Felder in einer gemeinsamen Tabelle und spezifische für untergeordnete Entitäten in separaten Tabellen gespeichert. Mit dieser Strategie erhalten wir bei der Auswahl einer Entität einen JOIN. Jetzt speichern wir die dritte Normalform und können auch eine NOT NULL-Einschränkung in der Datenbank angeben. - Jede Entität hat eine eigene Tabelle.
@ InheritanceType.TABLE_PER_CLASS
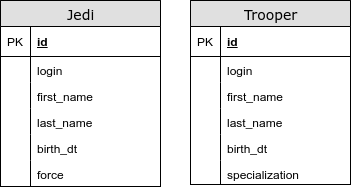
In diesem Fall haben wir keine gemeinsame Tabelle. Mit dieser Strategie verwenden wir UNION für polymorphe Abfragen. Wir haben Probleme mit Primärschlüsselgeneratoren und anderen Integritätsbeschränkungen. Von dieser Art der Vererbungszuordnung wird dringend abgeraten.
Für alle Fälle erwähne ich die Anmerkung - @MappedSuperclass. Es wird verwendet, wenn Sie allgemeine Felder für mehrere Entitäten des Objektmodells „ausblenden“ möchten. Darüber hinaus wird die mit Anmerkungen versehene Klasse selbst nicht als separate Einheit betrachtet.
Problem 2. Zusammensetzungsverhältnis in OOP
Zurück zu unserem Beispiel stellen wir fest, dass wir im Objektmodell das Benutzerprofil in eine separate Entität - Profil - aufgenommen haben. Im relationalen Modell haben wir jedoch keine separate Tabelle dafür ausgewählt.
Die OneToOne-Einstellung ist oft eine schlechte Praxis, weil In select haben wir einen ungerechtfertigten JOIN (in den meisten Fällen haben wir sogar fetchType = LAZY, wir werden JOIN haben - wir werden dieses Problem später diskutieren).
Es gibt @ Embedable- und @ Embeded-Annotationen, um eine Komposition in einer gemeinsamen Tabelle anzuzeigen. Der erste befindet sich über dem Feld und der zweite über der Klasse. Sie sind austauschbar.
Entity Manager
Jede Instanz von EntityManager (EM) definiert eine Interaktionssitzung mit der Datenbank. Innerhalb einer EM-Instanz gibt es einen Cache der ersten Ebene. Hier werde ich die folgenden wichtigen Punkte hervorheben:
- Erfassen der Datenbankverbindung
Dies ist nur ein interessanter Punkt. Der Ruhezustand erfasst die Verbindung nicht zum Zeitpunkt des Empfangs der EM, sondern beim ersten Zugriff auf die Datenbank oder beim Öffnen der Transaktion (obwohl dieses Problem gelöst werden kann ). Dies geschieht, um die Zeit der besetzten Verbindung zu verkürzen. Während des Empfangs von EM-a wird das Vorhandensein einer JTA-Transaktion überprüft. - Persistierte Entitäten haben immer eine ID
- Entitäten, die eine Zeile in der Datenbank beschreiben, entsprechen als Referenz
Wie oben erwähnt, verfügt EM über einen Cache der ersten Ebene. Die darin enthaltenen Objekte werden anhand der Referenz verglichen. Dementsprechend stellt sich die Frage: Welche Felder sollten verwendet werden, um Gleichheit und Hashcode zu überschreiben? Betrachten Sie die folgenden Optionen:
- Wie Flush funktioniert
Flush - führt akkumulierte Einfügungen, Aktualisierungen und Löschvorgänge in der Datenbank aus. Standardmäßig wird Flush in folgenden Fällen ausgeführt:
- Vor dem Ausführen der Abfrage (mit Ausnahme von em.get) ist dies erforderlich, um das ACID-Prinzip einzuhalten. Zum Beispiel: Wir haben das Geburtsdatum des Angriffsflugzeugs geändert und wollten dann die Anzahl der Angriffsflugzeuge für Erwachsene ermitteln.
Wenn es sich um CriteriaQuery oder JPQL handelt, wird Flush ausgeführt, wenn die Abfrage eine Tabelle betrifft, deren Entitäten sich im Cache der ersten Ebene befinden. - Beim Festschreiben einer Transaktion;
- Manchmal, wenn eine neue Entität beibehalten wird - in dem Fall, dass wir ihre ID nur durch Einfügen erhalten können.
Und jetzt ein kleiner Test. Wie viele UPDATE-Operationen werden in diesem Fall ausgeführt?
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
Eine interessante Funktion für den Ruhezustand ist unter dem Flush-Vorgang verborgen. Sie versucht, die Zeit zu verkürzen, die zum Sperren von Zeilen in der Datenbank erforderlich ist.
Beachten Sie auch, dass es unterschiedliche Strategien für den Spülvorgang gibt. Sie können beispielsweise das Zusammenführen von Änderungen an der Datenbank verbieten - dies wird als MANUAL bezeichnet (es deaktiviert auch den Mechanismus zur Überprüfung von Verschmutzungen).
- Schmutzige Überprüfung
Dirty Checking ist ein Mechanismus, der während eines Spülvorgangs ausgeführt wird. Der Zweck besteht darin, geänderte Entitäten zu finden und zu aktualisieren. Um einen solchen Mechanismus zu implementieren, muss der Ruhezustand die Originalkopie des Objekts speichern (womit das tatsächliche Objekt verglichen wird). Genauer gesagt speichert der Ruhezustand eine Kopie der Felder des Objekts, nicht des Objekts selbst.
Es ist anzumerken, dass der Vorgang der schmutzigen Prüfung teuer sein kann, wenn der Graph der Entitäten groß ist. Vergessen Sie nicht, dass im Ruhezustand 2 Kopien von Entitäten gespeichert werden (ungefähr).
Verwenden Sie die folgenden Funktionen, um die Kosten dieses Prozesses zu senken:
- em.detach / em.clear - Entitäten von EntityManager trennen
- FlushMode = MANUAL - nützlich bei Lesevorgängen
- Unveränderlich - vermeidet auch schmutzige Überprüfungsvorgänge
- Transaktionen
Wie Sie wissen, können Sie im Ruhezustand Entitäten nur innerhalb einer Transaktion aktualisieren. Lesevorgänge bieten mehr Freiheit - wir können sie ausführen, ohne eine Transaktion explizit zu öffnen. Aber genau das ist die Frage: Lohnt es sich, eine Transaktion explizit für Lesevorgänge zu öffnen?
Ich werde einige Fakten anführen:
- Jede Anweisung wird in der Datenbank innerhalb der Transaktion ausgeführt. Auch wenn wir es offensichtlich nicht geöffnet haben. (Auto-Commit-Modus).
- In der Regel sind wir nicht auf eine Abfrage an die Datenbank beschränkt. Beispiel: Um die ersten 10 Datensätze abzurufen, möchten Sie wahrscheinlich die Gesamtzahl der Datensätze zurückgeben. Und das sind fast immer 2 Anfragen.
- Wenn es sich um Federdaten handelt, sind die Repository-Methoden standardmäßig transaktional, während die Lesemethoden schreibgeschützt sind.
- Die Annotation @Transactional Spring (readOnly = true) wirkt sich auch auf den FlushMode aus, genauer gesagt, Spring versetzt ihn in den Status MANUAL, sodass der Ruhezustand keine Schmutzprüfung durchführt.
- Synthetische Tests mit einer oder zwei Datenbankabfragen zeigen, dass das automatische Festschreiben schneller ist. Im Kampfmodus ist dies jedoch möglicherweise nicht der Fall. ( ausgezeichneter Artikel zu diesem Thema , + siehe Kommentare)
Kurz gesagt: Es wird empfohlen, in einer Transaktion eine Kommunikation mit der Datenbank durchzuführen.
Generatoren
Generatoren werden benötigt, um zu beschreiben, wie die Primärschlüssel unserer Entitäten Werte erhalten. Lassen Sie uns kurz die Optionen durchgehen:
- GenerationType.AUTO - Die Auswahl des Generators basiert auf dem Dialekt. Nicht die beste Option, da hier nur die Regel „explizit ist besser als implizit“ gilt.
- GenerationType.IDENTITY ist der einfachste Weg, einen Generator zu konfigurieren. Es basiert auf der Spalte für die automatische Inkrementierung in der Tabelle. Um id mit persist zu erhalten, müssen wir daher einfügen. Aus diesem Grund wird die Möglichkeit einer verzögerten Persistenz und damit einer Chargenbildung ausgeschlossen.
- GenerationType.SEQUENCE ist der bequemste Fall, wenn wir die ID aus der Sequenz erhalten.
- GenerationType.TABLE - In diesem Fall emuliert der Ruhezustand eine Sequenz über eine zusätzliche Tabelle. Nicht die beste Option, weil In einer solchen Lösung muss der Ruhezustand eine separate Transaktion verwenden und pro Zeile sperren.
Lassen Sie uns etwas mehr über die Sequenz sprechen. Um die Betriebsgeschwindigkeit zu erhöhen, verwendet der Ruhezustand verschiedene Optimierungsalgorithmen. Alle zielen darauf ab, die Anzahl der Gespräche mit der Datenbank (die Anzahl der Hin- und Rückfahrten) zu reduzieren. Schauen wir sie uns genauer an:
- keine - keine Optimierungen. Für jede ID ziehen wir eine Sequenz.
- gepoolt und gepoolt - in diesem Fall sollte sich unsere Sequenz um ein bestimmtes Intervall erhöhen - N in der Datenbank (SequenceGenerator.allocationSize). Und in der Anwendung haben wir einen bestimmten Pool, die Werte, aus denen wir neuen Entitäten zuweisen können, ohne auf die Datenbank zuzugreifen.
- hilo - Um eine ID zu generieren, verwendet der hilo-Algorithmus zwei Zahlen: hi (in der Datenbank gespeichert - der Wert, der aus dem Sequenzaufruf erhalten wurde) und lo (nur in der Anwendung gespeichert - SequenceGenerator.allocationSize). Basierend auf diesen Zahlen wird das Intervall zum Erzeugen der ID wie folgt berechnet: [(hi - 1) * lo + 1, hi * lo + 1). Aus offensichtlichen Gründen wird dieser Algorithmus als veraltet angesehen und es wird nicht empfohlen, ihn zu verwenden.
Nun wollen wir sehen, wie der Optimierer ausgewählt wird. Der Ruhezustand verfügt über mehrere Sequenzgeneratoren. Wir werden an 2 von ihnen interessiert sein:
- SequenceHiLoGenerator ist ein alter Generator, der den Hilo-Optimierer verwendet. Standardmäßig ausgewählt, wenn die Eigenschaft hibernate.id.new_generator_mappings == false vorhanden ist.
- SequenceStyleGenerator - wird standardmäßig verwendet (wenn die Eigenschaft hibernate.id.new_generator_mappings == true ist). Dieser Generator unterstützt mehrere Optimierer, aber die Standardeinstellung ist zusammengefasst.
Sie können auch die Generator-Annotation @GenericGenerator konfigurieren.
Deadlock
Schauen wir uns ein Beispiel für eine Pseudocode-Situation an, die zu einem Deadlock führen kann:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
Um solche Probleme zu vermeiden, verfügt der Ruhezustand über einen Mechanismus, der Deadlocks dieses Typs vermeidet - den Parameter hibernate.order_updates. In diesem Fall werden alle Aktualisierungen nach ID sortiert und ausgeführt. Ich werde auch noch einmal erwähnen, dass der Ruhezustand versucht, die Erfassung der Verbindung und die Ausführung von Einfügungen und Aktualisierungen zu "verzögern".
Set, Tasche, Liste
Hibernate bietet drei Möglichkeiten, um die OneToMany-Kommunikationssammlung zu präsentieren.
- Set - eine ungeordnete Menge von Entitäten ohne Wiederholungen;
- Tasche - eine ungeordnete Gruppe von Entitäten;
- Liste ist eine geordnete Menge von Entitäten.
Es gibt keine Klasse für Bag im Java-Kern, die eine solche Struktur beschreiben würde. Daher sind alle Listen und Sammlungen Taschen, es sei denn, Sie geben eine Spalte an, nach der unsere Sammlung sortiert wird (OrderColumn-Annotation. Nicht zu verwechseln mit SortBy). Ich empfehle dringend, die OrderColumn-Annotation nicht zu verwenden, da die Funktionen (meiner Meinung nach) schlecht implementiert sind - keine optimalen SQL-Abfragen, mögliche NULL-Werte im Blatt.
Die Frage stellt sich, aber was ist besser, Tasche oder Set zu verwenden? Bei der Verwendung einer Tasche sind zunächst folgende Probleme möglich:
- Wenn Ihre Version des Ruhezustands niedriger als 5.0.8 ist, gibt es beim Einfügen einer untergeordneten Entität einen ziemlich schwerwiegenden Fehler - HHH-5855 -, dessen Duplizierung möglich ist (im Fall von cascadType = MERGE und PERSIST).
- Wenn Sie bag für die ManyToMany-Beziehung verwenden, generiert der Ruhezustand beim Löschen einer Entität aus der Sammlung äußerst unangemessene Abfragen. Zuerst werden alle Zeilen aus der Verknüpfungstabelle entfernt und anschließend wird eine Einfügung ausgeführt.
- Der Ruhezustand kann nicht mehrere Beutel für dieselbe Entität gleichzeitig abrufen.
Wenn Sie der @ OneToMany-Verbindung eine weitere Entität hinzufügen möchten, ist die Verwendung von Bag rentabler, da Für diesen Vorgang müssen nicht alle zugehörigen Entitäten geladen werden. Sehen wir uns ein Beispiel an:
Kraftreferenzen
Referenz ist eine Referenz auf ein Objekt, für das wir das Laden verschoben haben. Im Fall von ManyToOnes Beziehung zu fetchType = LAZY erhalten wir eine solche Referenz. Die Initialisierung des Objekts erfolgt zum Zeitpunkt des Zugriffs auf die Felder der Entität mit Ausnahme der ID (da wir den Wert dieses Felds kennen).
Es ist anzumerken, dass sich die Referenz im Fall von Lazy Loading immer auf eine vorhandene Zeile in der Datenbank bezieht. Aus diesem Grund funktionieren die meisten Lazy Loading-Fälle in OneToOne-Beziehungen nicht. Der Ruhezustand muss auf JOIN eingestellt werden, um zu überprüfen, ob die Verbindung besteht und bereits ein JOIN vorhanden war. Anschließend wird der Ruhezustand in das Objektmodell geladen. Wenn wir in OneToOne nullable = true angeben, sollte LazyLoad funktionieren.
Mit der em.getReference-Methode können wir unsere eigene Referenz erstellen. In diesem Fall kann nicht garantiert werden, dass sich die Referenz auf eine vorhandene Zeile in der Datenbank bezieht.
Lassen Sie uns ein Beispiel für die Verwendung eines solchen Links geben:
Nur für den Fall, ich erinnere Sie daran, dass wir im Falle einer geschlossenen EM oder eines getrennten Links eine LazyInitializationException erhalten.
Datum und Uhrzeit
Trotz der Tatsache, dass Java 8 über eine hervorragende API für die Arbeit mit Datum und Uhrzeit verfügt, können Sie mit der JDBC-API nur mit der alten Datums-API arbeiten. Daher werden wir einige interessante Punkte analysieren.
Zunächst müssen Sie die Unterschiede zwischen LocalDateTime und Instant und ZonedDateTime klar verstehen. (Ich werde mich nicht dehnen, aber ich werde ausgezeichnete Artikel zu diesem Thema geben: den
ersten und den
zweiten )
Wenn kurzLocalDateTime und LocalDate repräsentieren ein reguläres Tupel von Zahlen. Sie sind nicht an eine bestimmte Zeit gebunden. Das heißt, Die Landezeit des Flugzeugs kann nicht in LocalDateTime gespeichert werden. Und das Geburtsdatum durch LocalDate ist ganz normal. Der Augenblick stellt einen Zeitpunkt dar, zu dem wir zu jedem Zeitpunkt auf dem Planeten die Ortszeit erhalten können.
Ein interessanterer und wichtigerer Punkt ist, wie die Daten in der Datenbank gespeichert werden. Wenn wir den Typ TIMESTAMP WITH TIMEZONE angebracht haben, sollte es keine Probleme geben, aber wenn TIMESTAMP (OHNE TIMEZONE) steht, besteht die Möglichkeit, dass das Datum falsch geschrieben / gelesen wird. (ohne LocalDate und LocalDateTime)
Mal sehen warum:
Wenn wir das Datum speichern, wird eine Methode mit der folgenden Signatur verwendet:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
Wie Sie sehen, wird hier die alte API verwendet. Das optionale Kalenderargument wird benötigt, um den Zeitstempel in eine Zeichenfolgendarstellung zu konvertieren. Dh es speichert die Zeitzone in sich. Wenn der Kalender nicht übertragen wird, wird der Kalender standardmäßig mit der JVM-Zeitzone verwendet.
Es gibt drei Möglichkeiten, um dieses Problem zu lösen:
- Stellen Sie die gewünschte Zeitzone JVM ein
- Verwenden Sie den Parameter hibernate - hibernate.jdbc.time_zone (hinzugefügt in 5.2) -, um nur ZonedDateTime und OffsetDateTime zu korrigieren
- Verwenden Sie den Typ TIMESTAMP WITH TIMEZONE
Eine interessante Frage, warum LocalDate und LocalDateTime nicht unter ein solches Problem fallen?
Die AntwortUm diese Frage zu beantworten, müssen Sie die Struktur der Klasse java.util.Date verstehen (java.sql.Date und java.sql.Timestamp, seine Erben und ihre Unterschiede in diesem Fall stören uns nicht). Datum speichert das Datum in Millisekunden seit 1970, ungefähr in UTC, aber die toString-Methode konvertiert das Datum gemäß der Systemzeitzone.
Wenn wir also ein Datum ohne Zeitzone aus der Datenbank erhalten, wird es einem Zeitstempelobjekt zugeordnet, sodass die toString-Methode den gewünschten Wert anzeigt. Gleichzeitig kann die Anzahl der Millisekunden seit 1970 unterschiedlich sein (abhängig von der Zeitzone). Deshalb wird immer nur die Ortszeit korrekt angezeigt.
Ich gebe auch ein Beispiel für den Code, der für die Konvertierung von Timesamp in LocalDateTime und Instant verantwortlich ist:
Batching
Standardmäßig werden Abfragen einzeln an die Datenbank gesendet. Wenn die Stapelverarbeitung aktiviert ist, kann der Ruhezustand mehrere Anweisungen in einer Abfrage an die Datenbank senden. (d. h. Batching reduziert die Anzahl der Roundtrips zur Datenbank)
Dazu müssen Sie:
- Aktivieren Sie die Stapelverarbeitung und legen Sie die maximale Anzahl von Anweisungen fest:
hibernate.jdbc.batch_size (5 bis 30 empfohlen) - Aktivieren Sie die Sortierung der Einfügungen und Aktualisierungen:
hibernate.order_inserts
hibernate.order_updates
- Wenn wir die Versionierung verwenden, müssen wir auch aktivieren
hibernate.jdbc.batch_versioned_data - Vorsicht, hier benötigen Sie den JDBC-Treiber, um die Anzahl der während der Aktualisierung betroffenen Zeilen angeben zu können.
Ich möchte Sie auch an die Effektivität der Operation em.clear () erinnern - sie bindet Entitäten von em, wodurch Speicherplatz frei wird und die Zeit für die schmutzige Überprüfung verkürzt wird.
Wenn wir Postgres verwenden, können wir auch Ruhezustand sagen, um
Multi-Raw-Insert zu verwenden .
N + 1 Problem
Dies ist ein ziemlich allgegenwärtiges Thema, gehen Sie es also schnell durch.
Ein N + 1-Problem ist eine Situation, in der anstelle einer einzelnen Anforderung zur Auswahl von N Büchern mindestens N + 1 Anforderungen auftreten.
Der einfachste Weg, um das N + 1-Problem zu lösen, besteht darin, verwandte Tabellen abzurufen. In diesem Fall können verschiedene andere Probleme auftreten:
- Paginierung. Bei OneToMany-Beziehungen kann der Ruhezustand keinen Versatz und keine Begrenzung angeben. Daher tritt eine Paginierung im Speicher auf.
- Das Problem eines kartesischen Produkts ist eine Situation, in der eine Datenbank N * M * K Zeilen zurückgibt, um N Bücher mit M Kapiteln und K Autoren auszuwählen.
Es gibt andere Möglichkeiten, das N + 1-Problem zu lösen.
- FetchMode - Mit dieser Option können Sie den Ladealgorithmus für untergeordnete Entitäten ändern. In unserem Fall interessieren uns folgende:
- FetchType.SUBSELECT - Lädt untergeordnete Datensätze in einer separaten Anforderung. Der Nachteil ist, dass die gesamte Komplexität der Hauptanforderung in der Unterauswahl wiederholt wird.
- BATCH (FetchType.SELECT + BatchSize-Annotation) - lädt auch Datensätze als separate Anforderung, stellt jedoch zusammen mit der Unterabfrage eine Bedingung wie WHERE parent_id IN (?,?,?, ..., N).
Es ist zu beachten, dass bei Verwendung von fetch in der Kriterien-API FetchType ignoriert wird - JOIN wird immer verwendet - JPA EntityGraph und Hibernate FetchProfile - ermöglichen es Ihnen, Entity- Laderegeln in eine separate Abstraktion zu verwandeln - meiner Meinung nach sind beide Implementierungen unpraktisch.
Testen
Im Idealfall sollte die Entwicklungsumgebung so viele nützliche Informationen wie möglich über den Betrieb des Ruhezustands und über die Interaktion mit der Datenbank bereitstellen. Nämlich:
- Protokollierung
- org.hibernate.SQL: Debug
- org.hibernate.type.descriptor.sql: trace
- Statistiken
- hibernate.generate_statistics
Von den nützlichen Dienstprogrammen kann Folgendes unterschieden werden:
- DBUnit - Mit dieser Option können Sie den Status der Datenbank im XML-Format beschreiben. Manchmal ist es bequem. Aber überlegen Sie besser noch einmal, ob Sie es brauchen.
- DataSource-Proxy
- p6spy ist eine der ältesten Lösungen. bietet erweiterte Abfrageprotokollierung, Laufzeit usw.
- com.vladmihalcea: db-util: 0.0.1 ist ein praktisches Dienstprogramm zum Auffinden von N + 1-Problemen. Außerdem können Sie Abfragen protokollieren. Die Komposition enthält eine interessante Annotation zum Wiederholen, mit der die Transaktion im Fall einer OptimisticLockException wiederholt wird.
- Sniffy - Ermöglicht es Ihnen, die Anzahl der Anforderungen durch die Anmerkung zu bestätigen. In gewisser Hinsicht eleganter als die Entscheidung von Vlad.
Aber ich wiederhole noch einmal, dass dies nur für die Entwicklung ist, dies sollte nicht in die Produktion aufgenommen werden.
Literatur